基于便携式排放测试系统与BP神经网络的大型客车排放预测*
2021-01-24李昌庆谢小平
李昌庆 谢小平
(湖南大学,汽车车身先进设计制造国家重点实验室,长沙 410082)
主题词:车载排放测试 聚类分析 比功率 BP神经网络 排放预测
1 前言
近年来,我国民用大型载客汽车的拥有量逐年递增,高能耗、噪声污染以及尾气排放等问题进一步加深。因此,大型客车尾气排放特性预测模型的建立具有一定的理论研究意义和工程应用价值。
1999 年,Jiménez-Palacios[1]首次提出了机动车比功率(Vehicle Specific Power,VSP)的概念,此后,众多国内外学者对此展开了深入的研究。Frey等[2]依次探究了速度、加速度、道路等级等关键因素对汽车燃油消耗量的影响,并借助机动车比功率模拟柴油公共汽车的燃油消耗情况。宋国华等[3]利用城市快速路上大量的浮动车数据,构建出不同行程速度下对应的VSP 分布。刘娟娟[4]利用大量车载排放检测数据分析了速度与油耗和排放之间的关系,构建了基于VSP分布和速度的燃油消耗量和污染物排放量的修正模型。郭栋等[5]以部分轻型车和中型车为研究对象进行实际道路排放测试,并比较不同类型轻型车的污染物排放量随比功率和速度的变化关系。赵琦等[6]建立了高速公路上轻型车和重型车的VSP分布,借助从MOVES(Motor Vehicle Emission Simulator)模型中提取到的油耗率,利用轻型车的VSP分布分析重型车油耗测算所产生的误差。综上所述,比功率已成为油耗和排放测算领域极其重要的参数。
本文以某大型客车为研究对象,在长沙市不同道路工况下进行车载排放测试,推导其VSP 计算公式,求出对应的比功率值,分析不同道路工况下大型客车VSP分布特征,以及其尾气排放因子与比功率区间的关系,并参考多位学者的预测模型建立方法[7-9],以逐秒的速度、加速度、比功率值和油耗数据为输入,以CO2、CO和NOx的排放因子为输出,建立基于BP神经网络的预测模型,并用部分试验数据对该模型进行验证。
2 车载排放测试
2.1 测试方案
本文选用的大型普通客车基本信息如表1所示。
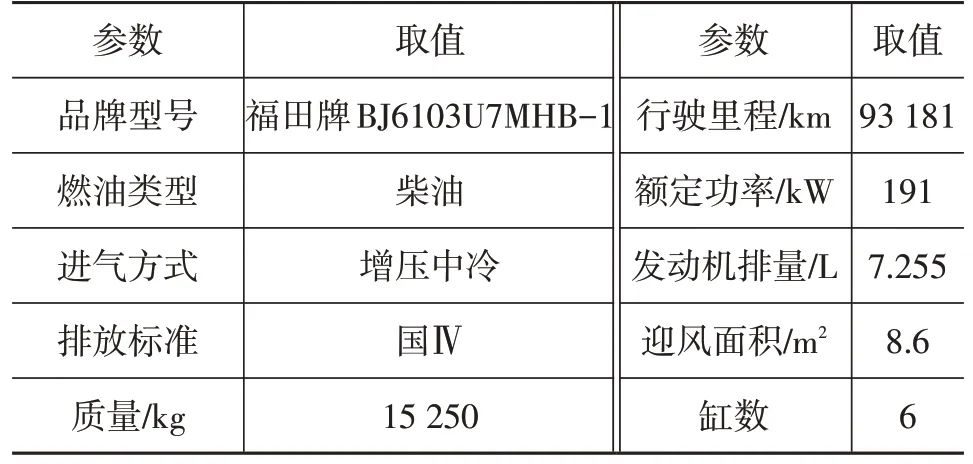
表1 测试车辆信息
研究中使用的便携式排放测试系统(Portable Emission Measurement System,PEMS)包括车载气态污染物测量仪OBS-2200 和电子低压冲击仪(Electrical Low Pressure Impactor,ELPI)[10]。气态污染物测量仪借助与汽车排气尾管相连的探针采集污染物的浓度,利用非分散红外光(Non-Dispersive Infrared,NDIR)技术检测CO 和CO2,利用非分散紫外光(Non-Dispersive Ultraviolet,NDUV)技术同时直接检测NO 和NO2,并计算出NOx的排放量。同时,通过连接车载诊断(On Board Diagnostics,OBD)系统接口获取机动车及其发动机的相关技术参数,如进气管压力和温度、发动机转速以及车辆的瞬时速度等。PEMS 在大型客车上的安装情况如图1所示。

图1 大型客车PEMS安装位置
2.2 测试路线
受人力和物力的限制,测试路线不可能实现对长沙市所有路段的全面覆盖。因此,为了能够准确获得大型客车在城区道路、郊区道路和高速道路工况下的行驶数据、排放数据和噪声数据,并满足不同道路工况下的速度要求(城区道路0~50 km/h,郊区道路50~75 km/h,高速道路75~100 km/h),本文有针对性地挑选了与之逐一匹配的路线,如图2所示。
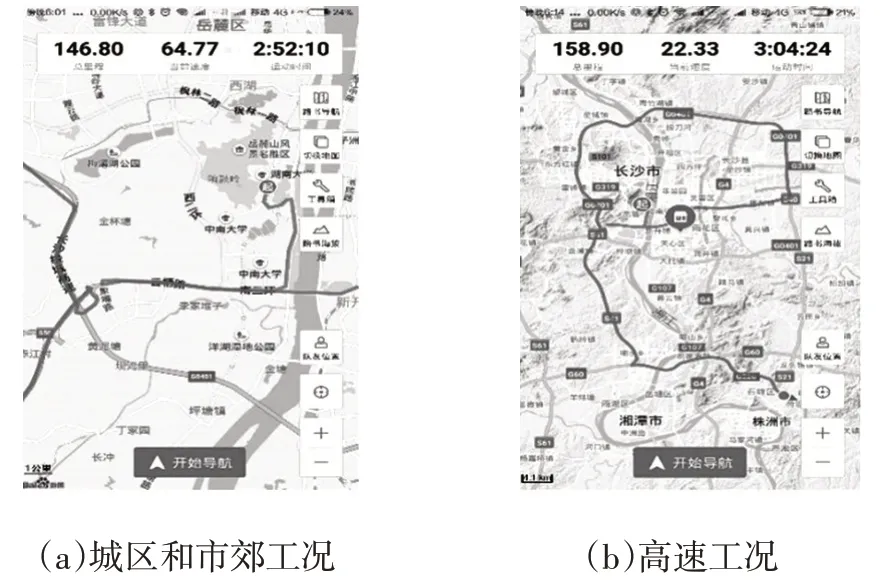
图2 大型客车行驶路线
2.3 数据收集及预处理
道路试验过程中,测试车辆在不同道路工况下正常行驶,OBS-2200按照1 Hz 的频率对各种污染物浓度数据进行逐一采集、测量和记录。整合了GPS接收模块的OBS-2200还能够收集大型客车在行驶过程中的地理位置相关信息,包括车速、海拔高度和经纬度。
由于不同的原因,在PEMS实时采集和记录数据过程中,难免出现数据坏点或更严重的成段数据异常等状况,严重影响计算分析结果,需对其进行甄别,并加以修正或剔除。针对这些数据的预处理主要有车速修正、延迟时间修正[11]和数据质量控制3 个步骤。例如:首先,通过行驶工况跟踪仪测得的车速对由于信号接收不良导致GPS 记录出错的数据进行核正,解决车速数据“冻滞”问题;然后,保证PEMS 设备收集的车辆排放特征数据与行驶工况数据时间同步;最后,对数据进行质量控制,包括缺失值插值处理和突变值平滑等,确保数据精度。
3 测试结果与分析
3.1 大型客车的VSP公式推导
VSP 被定义为机动车发动机每移动1 t 质量(含自重)所输出的功率。比功率考虑了机动车发动机为车辆的动能和势能变化提供所需要的能量,以及发动机克服车轮旋转阻力和空气动力学阻力做功,以及内摩擦阻力造成传动系统的机械损失等因素,往往既能反映车辆的行驶特征,又与车辆的油耗排放状况紧密相关。本文依据Andrei[12]给出的大型柴油客车的VSP计算公式,再结合汽车理论常用功率的定义推导适合本文研究对象的比功率VH计算公式:
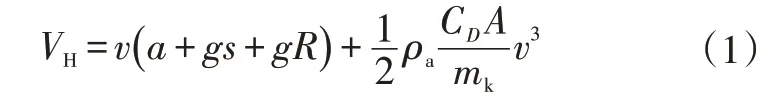
式中,v为车速;a为瞬时加速度;g为重力加速度;s为道路坡度;R为轮胎滚动阻力系数;ρa为环境空气密度;CD为空气阻力系数;A为车辆迎风面积;mk为整车质量。
本研究在中南地区进行,该地区属大陆性中亚热带季风湿润气候,则空气密度为:

式中,P为大气压力;T为气温;φ为相对湿度;ρb为饱和水蒸汽压力。
将PEMS 实测数据代入式(2),求得ρa约为1.189 96 kg/m3,本研究中道路坡道s取值为0,长沙市的重力加速度g取值为9.79 m/s2,将有关数据代入式(1),可得本研究中大型客车的比功率。
3.2 大型客车的VSP分布特征
本研究的大型客车在实际道路中共行驶了143.3 km,其中城区道路占比45.14%,郊区道路占比25.38%,高速道路占比29.48%,得到原始数据(包括车速和尾气质量排放率等)共11 064组。经过一系列的筛选和优化,最终得到可用数据约10 000组。由大型客车的瞬时速度数据即可求得其对应的瞬时加速度,然后借助式(1)求出对应的比功率。为了方便探究其VSP分布与尾气排放的关系,先对比功率进行聚类分析,即VSP按照数值进行分区,本文按1 kW/t进行等间隔的区间划分,如表2所示。
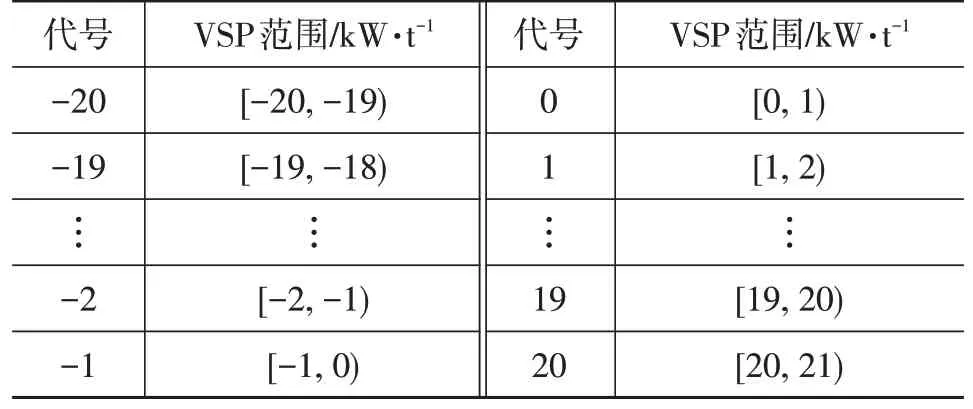
表2 VSP的区间划分
本文分别计算了城区、郊区和高速道路工况下大型客车的比功率,得到每个VSP区间在不同道路工况下所占的时间比例,即大型客车在不同公路工况下的VSP分布状态,如图3所示。

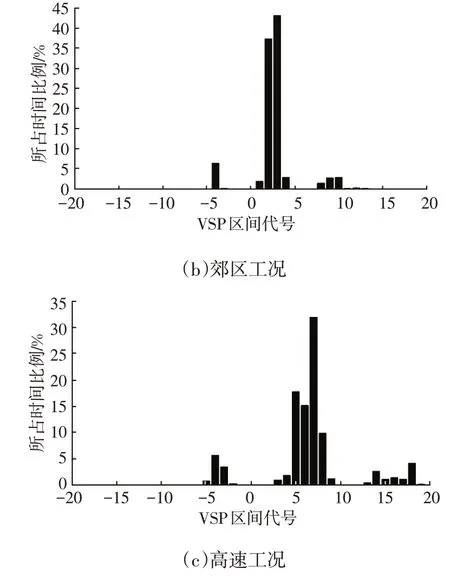
图3 不同工况下大型客车的VSP区间分布
由图3 可知:不同道路工况下,大型客车VSP 都在-20~20 kW/t 范围内,而且其VSP 区间范围随道路工况复杂程度的加深而收缩;在3 种道路工况下,大型客车的VSP区间分布均有集中的现象,且道路工况越复杂时越明显,城区工况下,峰值出现在VSP 划分代号为0的区间内,其峰值明显随道路工况复杂性的加深而逐渐向比功率大的区间偏移。
3.3 大型客车随VSP变化的排放规律
由式(1)计算得到的VH与其尾气污染物(CO 和NOx)逐一对应。同样,大型客车发动机产生的CO2也与其比功率密切相关。不同道路工况下大型客车的尾气质量排放率随比功率区间的变化规律如图4所示。
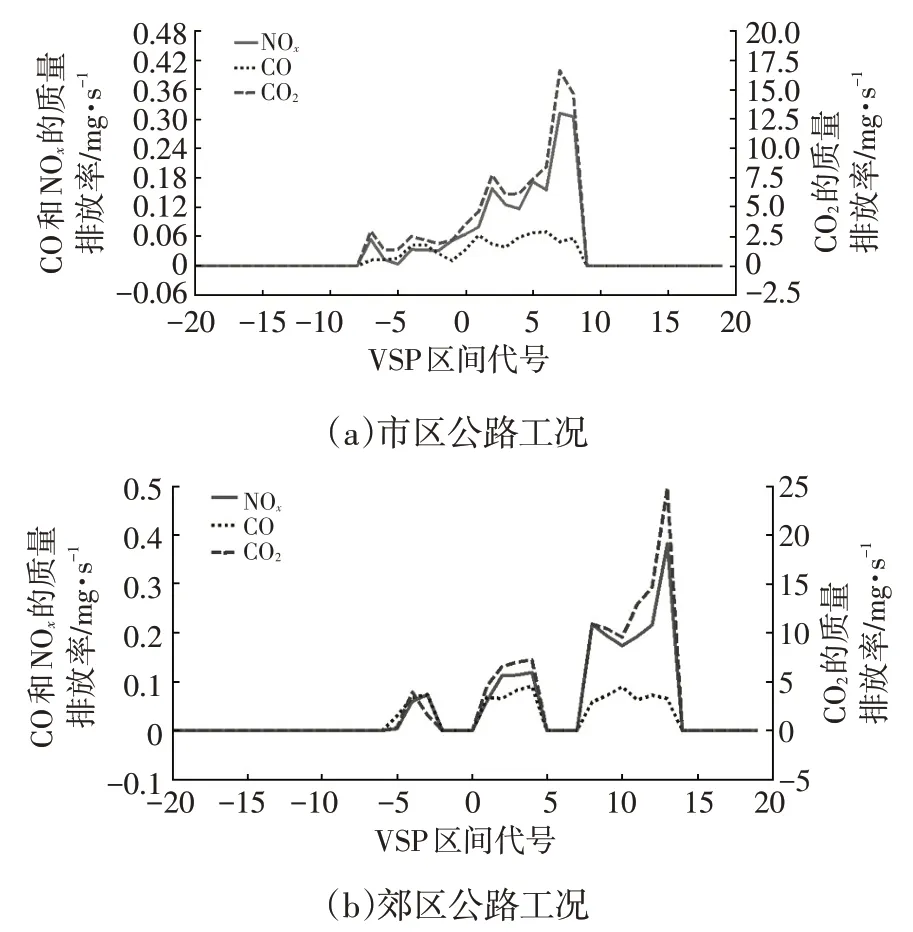
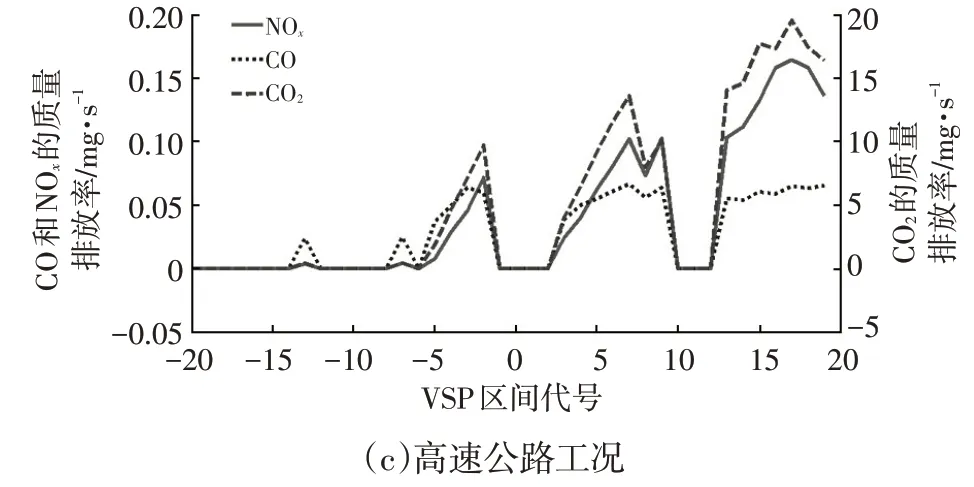
图4 不同工况下尾气质量排放率随VSP区间变化规律
由图4 可知:不同道路工况下,大型客车尾气污染物中CO 的质量排放率在VH为正的区间内明显较NOx小,而随着公路工况复杂程度的增加,CO 和NOx在不同VSP 区间范围的平均质量排放率先增大后减小,即在不同VSP区间范围内,2种污染物的平均质量排放率都在郊区工况下达到最大值;随着道路工况复杂程度的降低,不同VSP 区间范围CO2的平均质量排放率明显逐渐增大;不同道路工况下,随VSP 区间的增大,CO2和NOx的质量排放率增大,且变化几乎同步,但CO 质量排放率变化较平缓,基本在(0.05±0.02) mg/s 范围内浮动。
4 大型客车尾气预测模型构建
误差反向传播网络(BP神经网络)因其突出的非线性映射能力、较好的泛化能力和容错能力得到广泛应用。本文选取BP神经网络构建大型客车的尾气预测模型。
4.1 BP神经网络算法
单隐含层网络在BP 神经网络中最为普遍,为包括输入层、隐含层和输出层的3层感知器。对于3层感知器,一般设X=(x1,x2,…,xi,…xn)T为输入向量、Y=(y1,y2,…,yj,…ym)T为隐含层的输出向量、O=(o1,o2,…,ok,…ol)T为输出层的输出向量、d=(d1,d2,…,dk,…dl)T为期望的输出向量、V=(v1,v2,…,vj,…vm)T为输入层与隐含层之间的权值矩阵、W=(w1,w2,…,wk,…wl)T为隐含层与输出层间的权值矩阵。其中,vj为隐含层第j个神经元输入对应的权值向量,wk为输出层第k个神经元输出对应的权值向量,信号正向传播时,不同层间的关系如式(3)~式(9)所示:
输入层与隐含层之间的数学表达式为:

式中,Nj为第j个神经元;vij为权值向量vj的第i个元素;n为输入向量的元素个数;m为权值向量V的行数。
隐含层与输出层之间的数学表达式为:
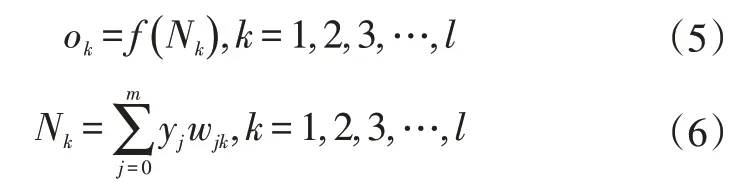
式中,Nk为第k个神经元;wjk为权值向量wk的第j个元素;l为权值向量W的行数。
单极性和双极性Sigmoid函数分别为:
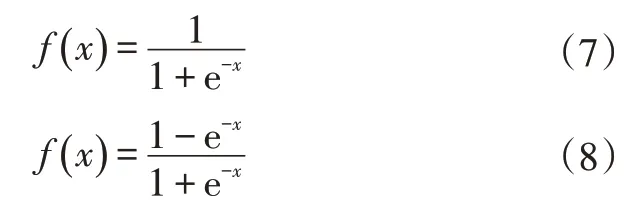
f(x)满足连续、可导:
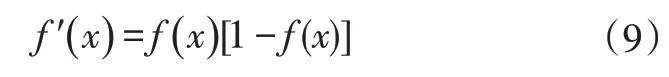
而当网络输出与期望输出不符时,其误差E为:

由于误差会反向传播,故此时各层之间的关系为:
当误差定义扩展至隐含层时:

继续扩展至隐含层输入层时:
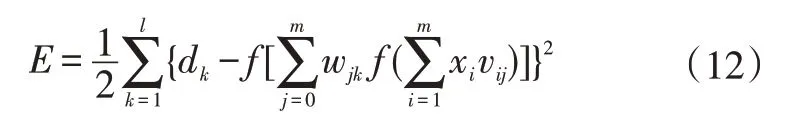
从式(12)可以看出,误差E与各层权值的wjk、vij紧密相关,故通过调整各层之间的权值即可不断变小误差E。而权值的调整量与误差的下降梯度成正比,则有:
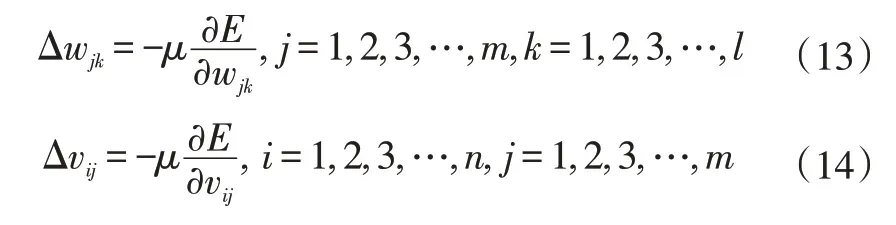
式中,μ∈[0,1]为比例系数,它是学习效率的反映;负号是指梯度下降。
4.2 大型客车尾气排放预测模型建立
本文以大型客车行驶状况参数(行驶速度、加速度、VH以及逐秒油耗值)作为输入层,以大型客车CO2、CO和NOx尾气排放因子作为输出层,再利用单隐含层BP神经网络算法建立模型。其中,输入层可用数据为4×10 000组,输出层可用数据为3×10 000组。为方便对所建立的模型进行检验,采用等距抽样方法,对全部数据从每10组中抽取1组作为对比检验组,其余数据作为模型训练组。模型训练结束后,用对比检验组的数据进行预测,并把预测结果与期望输出作比较,以此评判模型优劣。
对于BP神经网络算法,在对样本数据进行训练前,应对输入层和输出层的数据进行归一化预处理,以此平衡它们之间的差距。本文的归一化公式为:
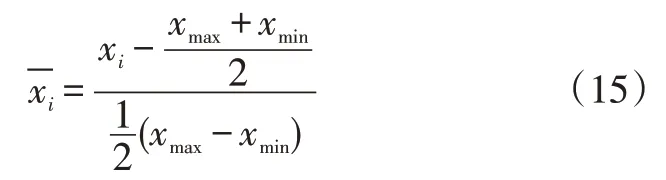
归一化后,还需要确定BP 神经网络的训练参数。对于本文,输入层、输出层的激活函数(传递函数)选择连续可微的tansig 函数(双曲线正切S 型函数),学习函数选择可以实现梯度下降的learngd 函数,训练函数选择内存需求大,但收敛速度较快的trainlm 函数。此外,在本文的预测模型中,学习率设为0.01,最大训练次数设置为100 000 次,最大失误次数设为10 次,学习训练的精度设为0.000 1。
在已选定BP 神经网络层数的情况下,其隐层节点数的选择至关重要,因为其在BP 神经网络中储存权值和阈值,记录输入和输出规律。一般用试凑法确定隐层节点数,本文采用的经验公式为:
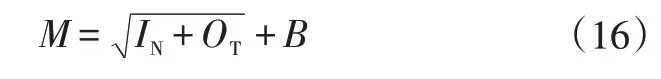
式中,M为隐层节点数;IN为输入层节点数;OT为输出层节点数;B为1~10的常数。
显然,在本文的预测模型中,IN=4,OT=3,故M的取值范围为4~13。为了确定最佳的隐层节点数,还需要一些综合评估指标来筛选最佳预测结果。本文采用的评估指标是平均均方根误差(Root Mean Square Error,RMSE),即平均均方误差(Mean-Square Error,MSE)开根号的结果,以及多重相关系数R:
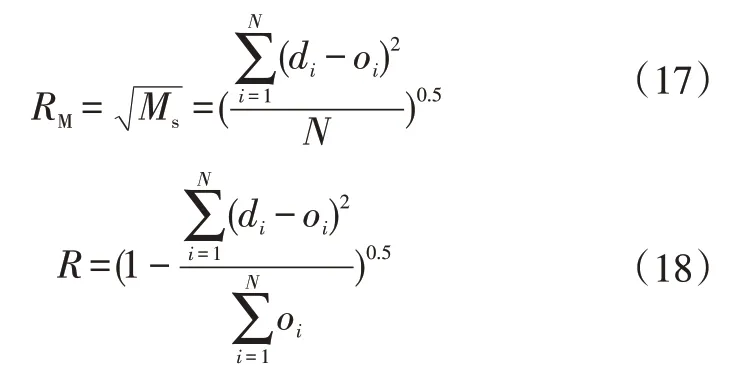
式中,RM为平均均方根误差;Ms为平均均方误差;di为期望输出值;oi为BP神经网络预测值;N为样本数量。
不同的隐层节点数与其对应的网络误差参数如表3 所示。
一般来说,RM越小,网络误差就越小,而多重相关系数R越接近1,就代表预测越准确。由表3 可知,当隐层节点数量为13 个时,总体RM值低至1.792 8,而总体的多重相关系数R=0.916 7,大于0.9,故本文最终确定的大型客车尾气预测模型的BP 神经网络结构为4-13-3,如图5 所示。样本数据在训练、验证、测试以及全部输出过程中MSE 的变化和多重相关系数如图6所示。
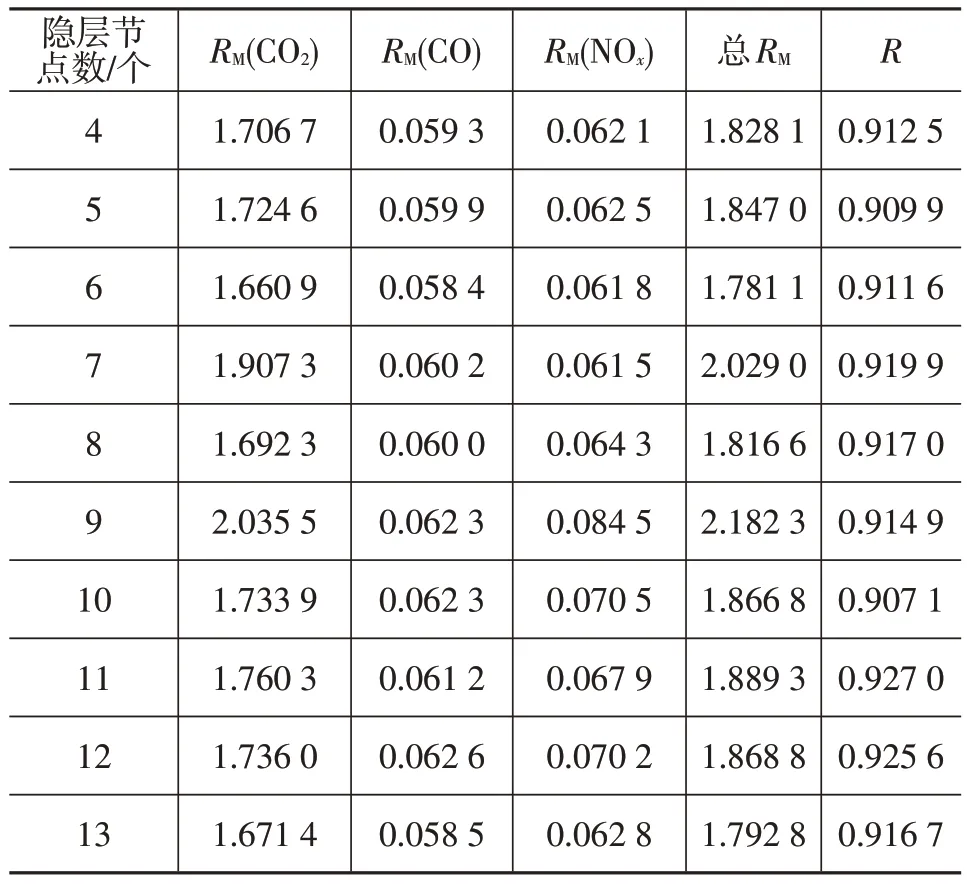
表3 不同的隐层节点数与其对应的网络误差参数

图5 大型客车尾气预测模型的BP神经网络结构
由图6可知,当训练步数为51步时,训练的Ms值达到0.004 176 9,训练样本R=0.920 25,检验样本R=0.916 56,多重相关系数都在0.9 以上,比较接近于1,说明所建立的BP网络预测的准确度较高,也就是说,模型预测的输出结果和目标期望之间的相关性较好。
此外,利用搭建好的大型客车尾气排放模型求出CO2、CO 和NOx尾气的瞬时排放因子,并以相对误差作为评价指标,来检验所建模型的总体预测误差。其中,相对误差Er的数学表达式为:

式中,Tr为实测数据;Pr为预测模型输出的结果。
本文测试的大型客车实际道路总行驶里程143.3 km,总的行驶时间110 60 s,平均车速46.64 km/h,其尾气CO2、CO 和NOx的总体预测情况如表4 所示。
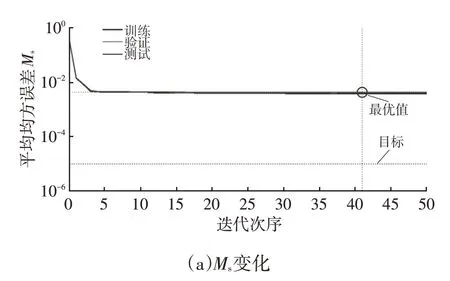

图6 样本的Ms变化和多重相关系数

表4 3种尾气的总体预测结果
由表4 可知,尾气CO2、CO 和NOx排放因子的总体预测相对误差均较小。总的来说,在误差允许范围内,本文所建的模型对大型客车尾气中CO2、CO和NOx排放特性的预测均有较高的准确性。
5 结束语
本文以逐秒的速度、加速度、比功率和油耗数据为输入,建立了基于BP神经网络算法的大型客车尾气排放预测模型,并进行了验证。结果表明,该模型预测准确性较好,可用于预测实际行驶过程中的尾气排放情况。
尾气中3种污染物的预测结果均小于实际值,这可能是建立模型时未考虑道路测试时的坡度、海拔高度、风速、驾驶员行为习惯等因素所致,故本文的预测模型存在一定的局限性,还需要后续研究进行完善。
