基于GPU的非相干消色散算法*
2021-01-19托乎提努尔张海龙冶鑫晨
托乎提努尔,张海龙,王 杰,冶鑫晨
(1. 中国科学院新疆天文台,新疆 乌鲁木齐 830011;2. 中国科学院射电天文重点实验室,江苏 南京 210008;3. 国家天文科学数据中心,北京 100101)
宇宙空间中的星际介质(Inter-Stellar Medium, ISM)[1]包含大量电离气体云、中性尘埃粒子和自由电子等物质。脉冲星信号在宇宙空间传播时因为星际介质色散的影响而降低速度,高频无线电波传播速度比低频快,所以高频和低频电磁波到达射电望远镜的时间不一致,脉冲星信号因此出现能量分散而使脉冲轮廓加宽,信噪比下降,甚至脉冲信号消失。
为了解决脉冲星信号色散问题,天文学家研究了消除色散的方法[2-3]及高速消色散处理技术。利用多通道滤波器组[4]对脉冲星信号进行通道划分,生成多个窄带信号,针对窄带信号进行时间延迟处理,每个通道延迟时间可以通过色散公式计算,最后将所有窄带通道累加,获得高信噪比的脉冲信号。
非相干消色散是脉冲星观测数据处理中最常用的色散处理方法,具有实现简单、速度快、数据后期处理灵活等优势。在脉冲星搜寻中,随着色散量(Dispersion Measure, DM)、数据通道及采样数量的增加,非相干消色散算法的计算量迅速增加,通常的计算平台难以实现脉冲星数据的实时处理。近年来,图形处理器[5-6]的可编程能力及并行处理能力迅速提高,应用范围不断扩展,在中央处理器 + 图形处理器混合计算系统中,图形处理器的加入大大提高了整个系统的数据处理能力。高性能图形处理器集群可提供强大的计算资源,能够满足海量天文数据实时处理的需求,从而解决脉冲星消色散算法计算量巨大、无法实时处理的问题。
1 非相干消色散
非相干消色散算法根据色散公式计算每个通道的延迟时间,然后加上各个通道的延迟,并把所有通道叠加在一起,即可消除数据的色散影响。非相干消色散原理如图1。
非相干消色散采用多通道滤波器组实现,消色散处理过程主要包括:(1)通道划分,使用滤波器组把观测的天文信号总带宽分成若干个相互独立的狭窄通道;(2)补充时间延迟,根据色散公式计算每个通道的时间延迟,按延迟进行通道平移,将各个窄带通道的脉冲信号在同一时刻对齐;(3)通道累加,将所有通道时间序列叠加在一起。

图1 非相干消色散原理Fig.1 The principle of incoherent de-dispersion
图1说明了非相干消色散的处理过程。图1(a)未进行消色散,图1(b)是消色散处理后的结果。从图1可以看出,消色散前,通道累加之后脉冲宽度被展宽,输出信号信噪比下降,消色散之后可以得到信噪比大幅提高的脉冲星轮廓。
非相干消色散已经广泛应用于脉冲星、快速射电爆[7]搜寻。非相干消色散方法处理后的脉冲星数据,各个子通道内的色散延迟依旧存在,不能得到脉冲星的真实轮廓,随着频谱通道数的增加,每个通道的带宽变小,带内的色散效应相应降低,低频信号f1和高频信号f2在星际介质中的传播时间差为
(1)
其中,c为光在真空中的传播速度;e为电子电荷;D为色散量;m为电子质量。D可表示为
(2)
其中,ne为电子密度;d为电磁波实际经过的路径。
脉冲星消色散处理中,一个频率通道fchan相对于参考通道fref(通常是观测带宽中心频率)的时间延迟可以根据色散量公式计算:
(3)
其中,KDM为色散量常数;D为观测脉冲星信号的色散量,单位为cm-3·pc;频率单位为MHz。色散量常数为
(4)
在观测中,观测频率f往往远大于划分的通道带宽Δf,如果f≫ Δf时,频率通道的延迟时间可以写为
tDM=8.3×106DΔff-3ms ,
(5)
(5)式说明通道带宽和色散延迟时间成正比,为了得到更小的色散延迟,需要划分很细的窄带通道,尽量减小单通道信号带宽。
2 非相干消色散算法的图形处理器实现
图形处理器是现代计算机中常见的设备,专为执行复杂的数学计算而设计的一种高度并行化、多线程的多核处理器,可以高速实现图形渲染。基于图形处理器的通用计算技术已经成为高性能并行计算领域的研究热点。图形处理器由于具备多个核心,更适合计算密集型数据。图形处理器的内核相当于中央处理器的多个线程,这些线程可以并行运行完成指定的计算任务,而且数值计算的速度远远优于中央处理器。图形处理器的线程结构如图2。
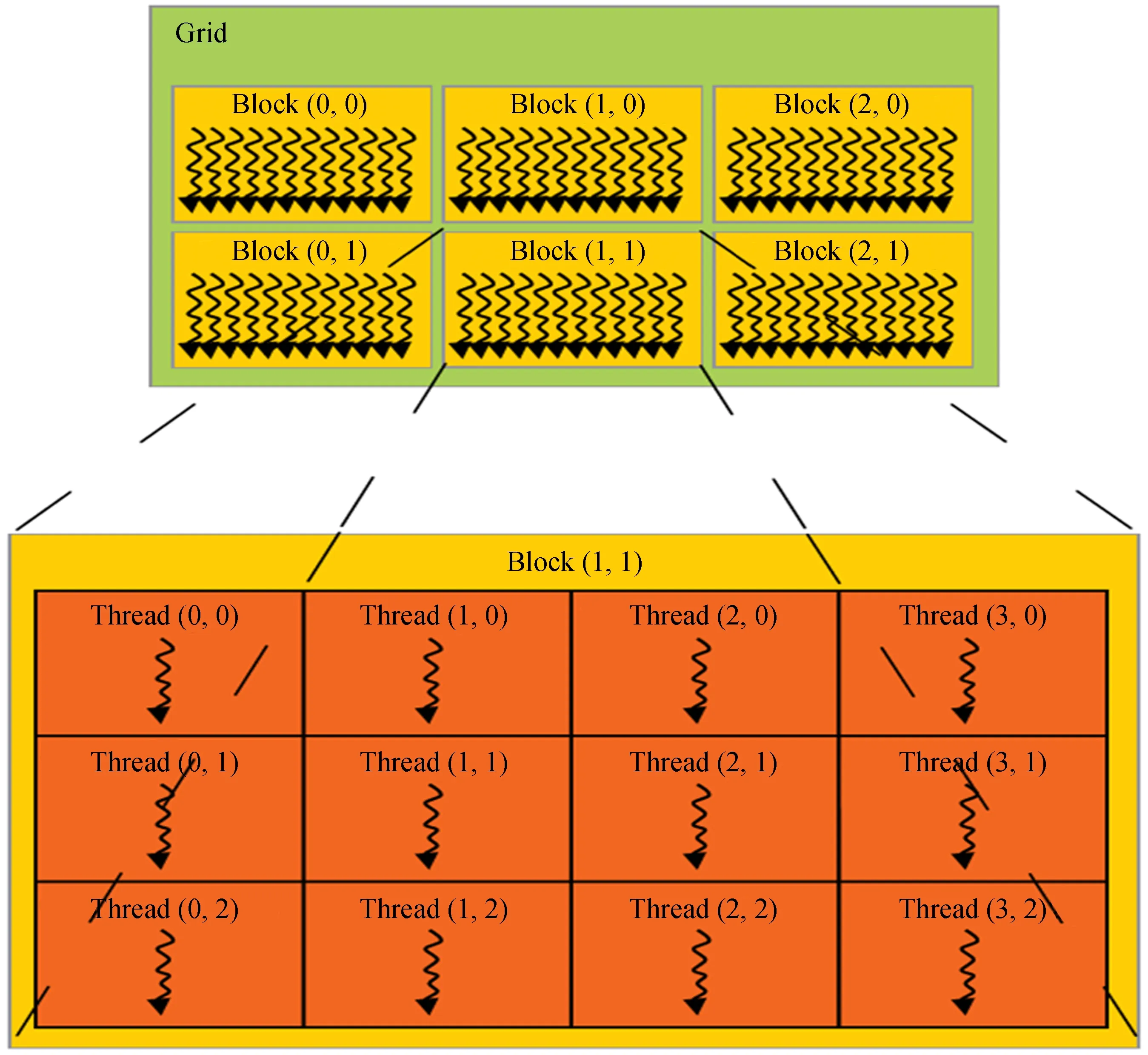
图2 图形处理器的线程结构Fig.2 GPU thread structure
图形处理器的开发使用统一计算设备架构(Compute Unified Device Architecture, CUDA)[8],它是一种由英伟达(NVIDIA)推出的通用并行计算平台和编程模型,使图形处理器能够解决复杂的计算问题。CUDA提供了硬件的直接访问接口,不依赖图形应用程序接口实现图形处理器访问,在架构上采用全新的计算体系结构来使用图形处理器提供的硬件资源。CUDA采用标准C语言的扩展作为编程语言提供大量的高性能计算指令,能够在图形处理器强大的计算能力基础上实现效率更高的密集数据计算算法。
本文分析和研究非相干消色散算法的结构,把计算量大的任务部分映射到图形处理器的多线程进行处理。非相干消色散算法复杂度为O(NdNsNc),其中,Nd为色散量总数;Nc为通道数;Ns为采样数,算法数学模型计算量较大,但是通过图形处理器可以得到很高的加速比。在算法中,对非相干消色散的色散量和时间维度进行并行化,频率通道累加采用串行的处理方法,即使用图形处理器的单线程实现了Nc个通道的相加计算。在整个消色散过程中,中央处理器负责系统的初始化和输入数据读取,图形处理器负责并行消色散处理,中央处理器接收消色散后的时间序列并输出到数据文件。非相干消色散算法CUDA程序流程图如图3。
首先在中央处理器内存中开辟缓冲区,写入需要处理的数据。缓冲区暂存的采样都存在一定的色散,因此,需要对各个频率通道进行位移和累加运算,随着时间延迟增大,通道位移也增大,低频通道的位移量更大。为了减小中央处理器和图形处理器之间频繁的数据传输对算法计算性能的影响,在图形处理器中设置全局内存缓冲区,尽量把大量数据一次性复制过去,并且为写入和读取数据保留足够的存储空间。图形处理器 kernel函数执行过程中,使用共享内存减小全局内存的延迟,提高运行速度。

图3 非相干消色散CUDA程序流程图Fig.3 Flow chart of CUDA program for incoherent de-dispersion
为了提高算法的并行化加速,将非相干消色散算法的计算分为两部分,在中央处理器上执行计算的第1部分所需的时间
tchan=4.15×103(f1-2-f2-2),
(6)
其中,f1,f2的单位为MHz;tchan的计算与色散量无关,使用图形处理器的常量内存存储。在图形处理器上执行计算的第2部分所需的时间
(7)
其中,tsamp为采样时间,单位为ms。
根据非相干消色散算法的特性,图形处理器kernel函数中定义了两个缓冲区:共享内存和常量内存,其中共享内存用于存储积分运算的结果,常量内存用于存储DM_shift。为了加快通道累加,使用共享内存隐藏全局内存的访问延迟。一个线程块里面的所有线程获取色散量平移值,并且存储到共享内存。对于每一个色散量,在共享内存中进行积分运算,并把消色散处理结果写入图形处理器的全局内存。
3 实验分析
本次实验平台使用Intel Xeon E5-1620,TITAN V,CUDA 10.0及Ubuntu 18.04。TITAN V是一款NVIDIA GeForce系列高端图形处理器,拥有5 120个CUDA核,内存访问带宽为652.8 GB/s。
为了验证图形处理器并行算法的性能,首先分别模拟生成了32、64、128、256、512及1 024通道脉冲星数据,其中心频率为420 MHz,带宽为6 MHz,采样间隔时间为165 μs,脉冲星信号周期为0.1 s,然后将每一块数据单独读取并加载到图形处理器中进行处理。实验结果如表1、表2、表3及表4。
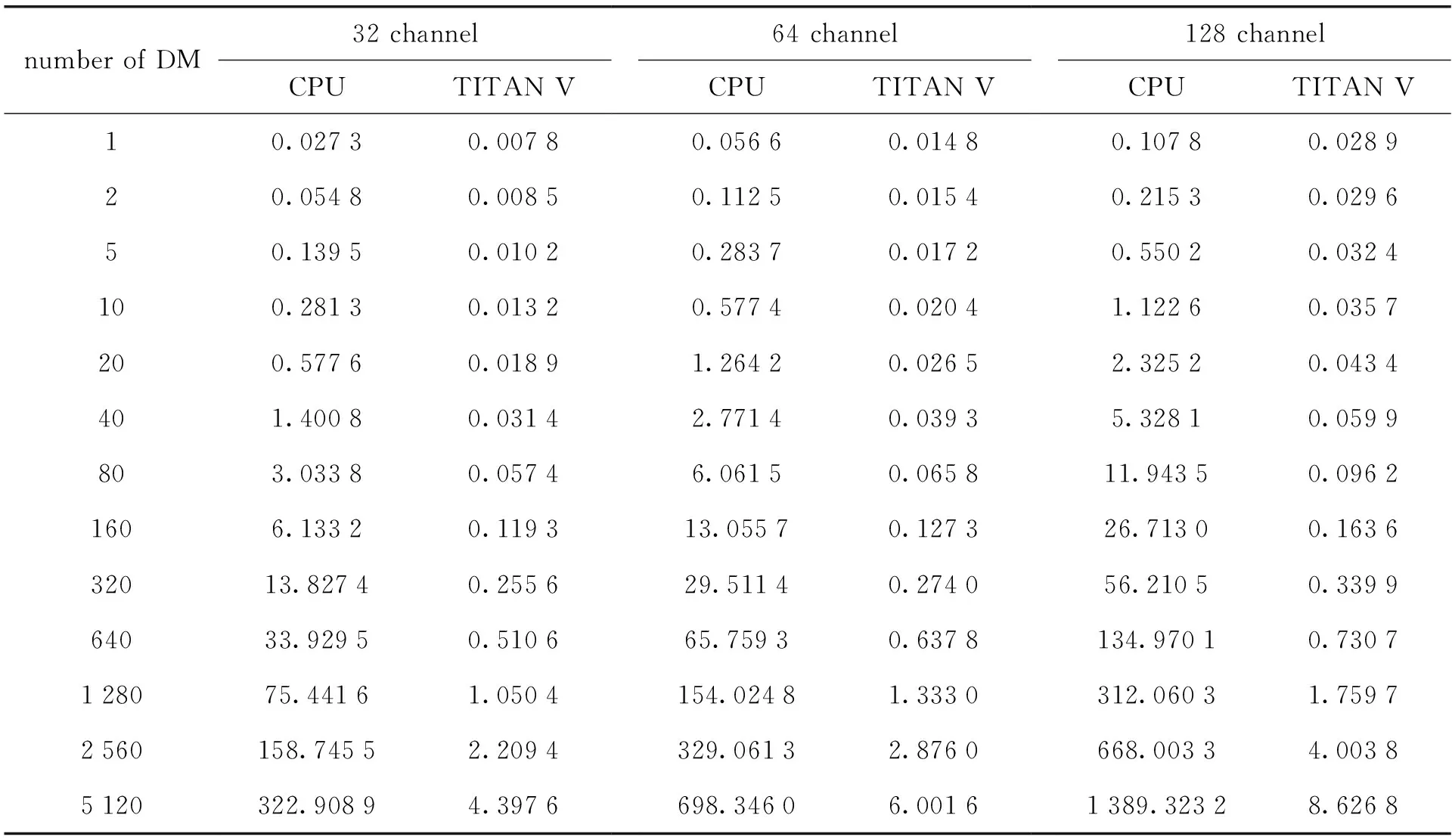
表1 采样数固定时非相干消色散处理时间(单位:s,采样:131 072)

表2 采样数固定时非相干消色散处理时间(单位:s,采样:131 072)
表1、表2是在采样数为131 072(单通道采样),通道和色散量都变化的情况下图形处理器并行算法和中央处理器串行算法的非相干消色散处理消耗时间。从表中可以看出,当通道数量固定时,随着色散量的增加,图形处理器和中央处理器的数据处理时间线性增加,图形处理器的消色散处理时间远远少于中央处理器的;当色散量固定时,随着数据通道数量的增加,中央处理器和图形处理器的处理时间增加,但是中央处理器的计算时间比图形处理器大得多。
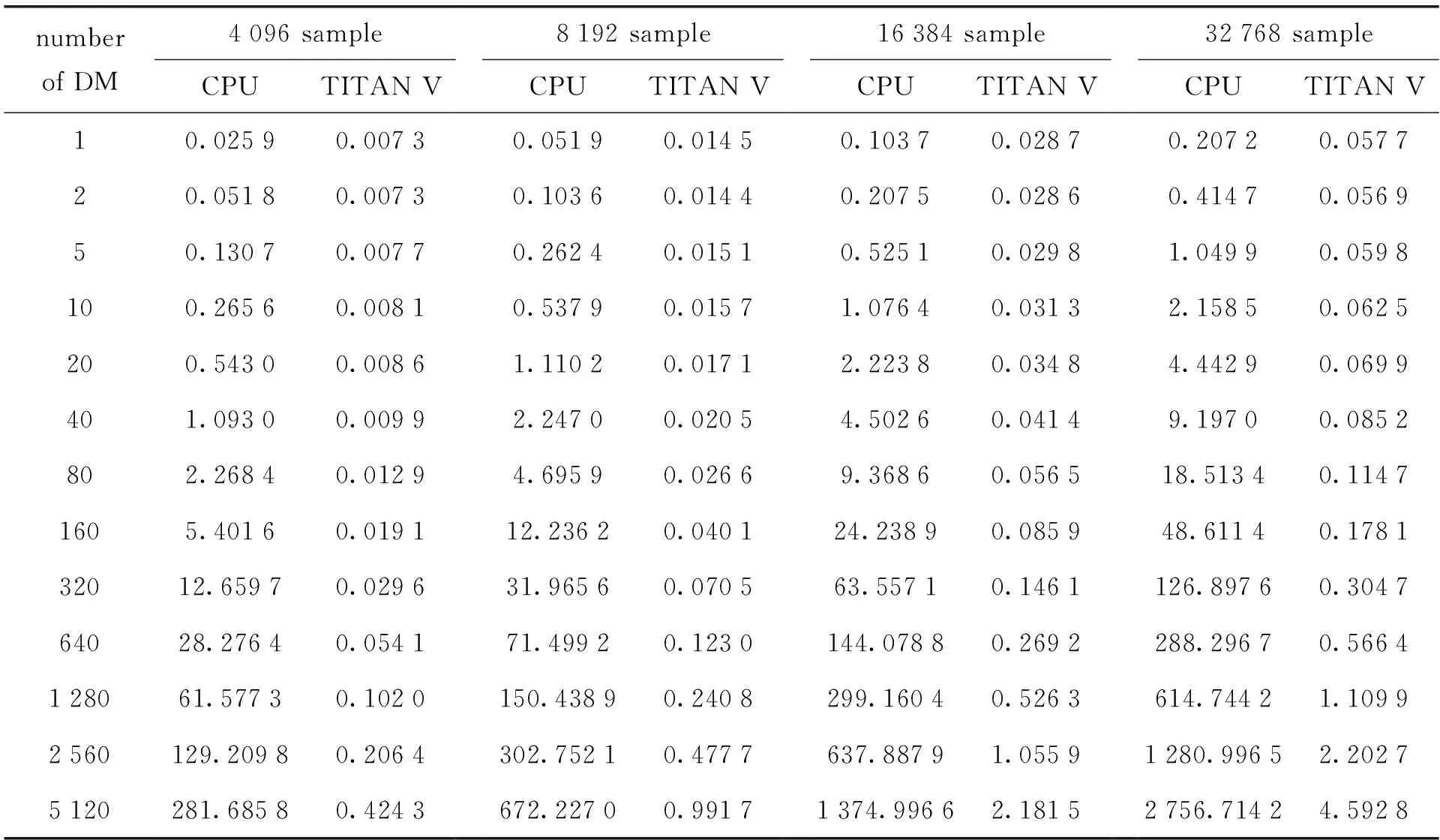
表3 通道数固定时非相干消色散处理时间(单位:s,通道:1 024)
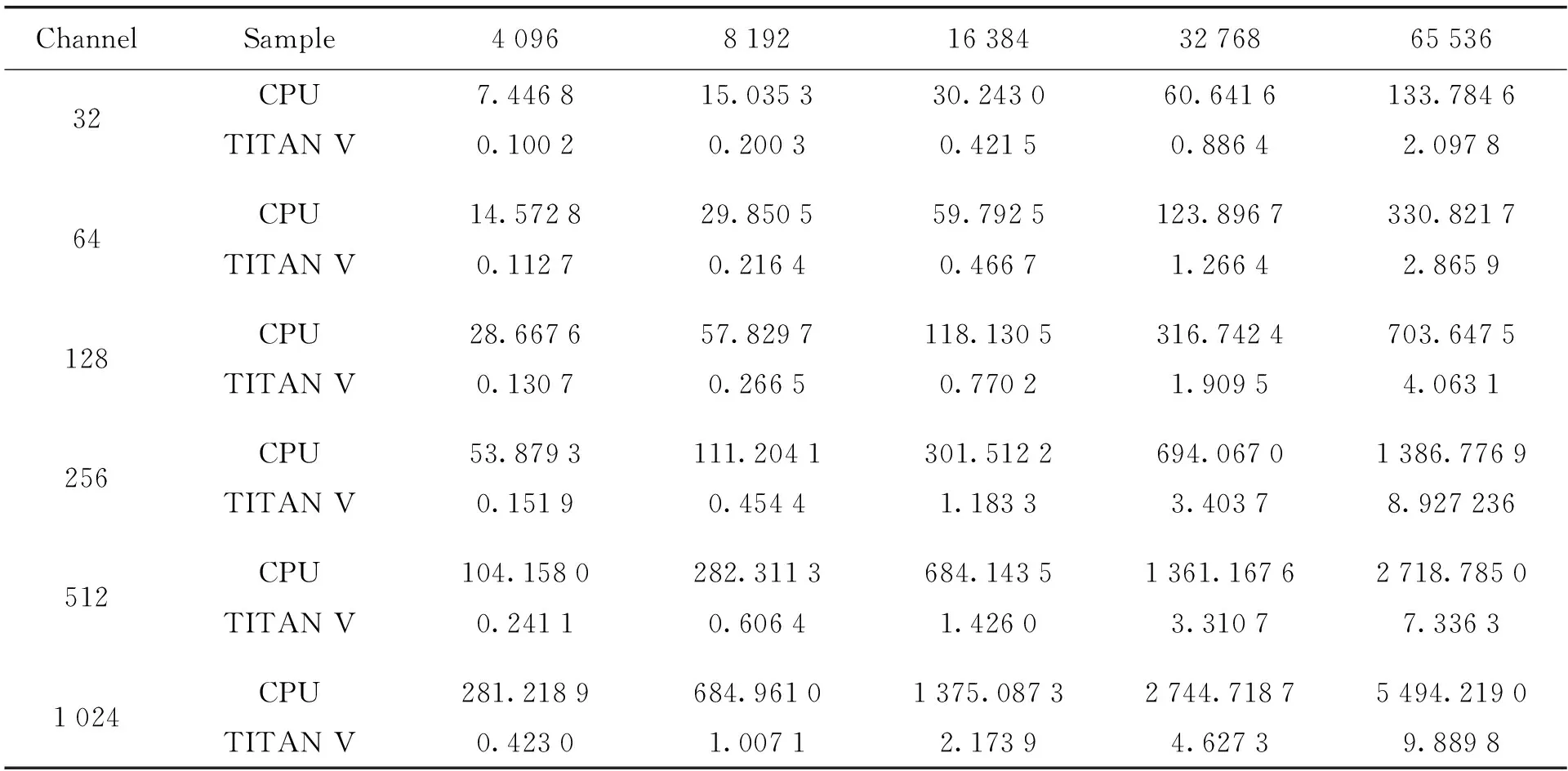
表4 色散量固定时非相干消色散处理时间(单位:s,色散量:5 120)
表3是通道数为1 024、采样数和色散量都变化的情况下,图形处理器并行算法和中央处理器串行算法的非相干消色散处理消耗时间。当采样数固定时,随着色散量的增加,图形处理器和中央处理器的数据处理时间增加;当色散量固定时,随着采样数的增加,并行和串行算法处理时间增加,但是,图形处理器的计算时间少于中央处理器的,计算速度有几百倍的差距。从表中可以看出,图形处理器大大缩短了非相干消色散的执行时间。
表4是色散量为5 120、采样数和通道数都变化的情况下,图形处理器并行算法和中央处理器串行算法的非相干消色散处理消耗时间。当采样数固定时,随着通道数的增加,图形处理器和中央处理器的数据处理时间增加;当通道数固定时,随着采样数的增加,并行和串行算法处理时间增加。在通道数或采样数变化的情况下,图形处理器的运算时间均小于中央处理器,且消耗时间差距明显。
和中央处理器相比,图形处理器非相干消色散的数据处理能力达到几百倍的加速比,具有显著的加速优势。图形处理器并行算法的加速比性能如图4、图5及图6。

图4 采样数为131 072时图形处理器算法加速比Fig.4 GPU algorithm speed-up when the number of samples is 131 072

图5 色散量为5 120时图形处理器算法加速比Fig.5 GPU algorithm speed-up when the number of DMs is 5 120
图4是采样数为131 072、通道数和色散量均变化的情况下,图形处理器并行算法的加速比。从图中可以看出,随着色散量的增加,并行算法的加速比提高。当色散量个数为2 560时,TITAN V的加速比最高(即达到中央处理器速度的538倍),然后加速比开始下降。如图4,通道数量越多,图形处理器算法的加速比越大,加速性能越好。当通道数为1 024时加速比最高,当通道数为32时加速比最小。
图5是色散量为5 120、通道数和采样数都变化的情况下,图形处理器并行算法的加速比。从图中可以看出,随着采样数的增加,并行算法的加速比有所下降,但算法加速高达550多倍。当通道数为1 024时,TITAN V达到最高的加速比。当通道数为1 024、采样数为8 192时,图形处理器并行算法的速度是中央处理器串行算法的780多倍。
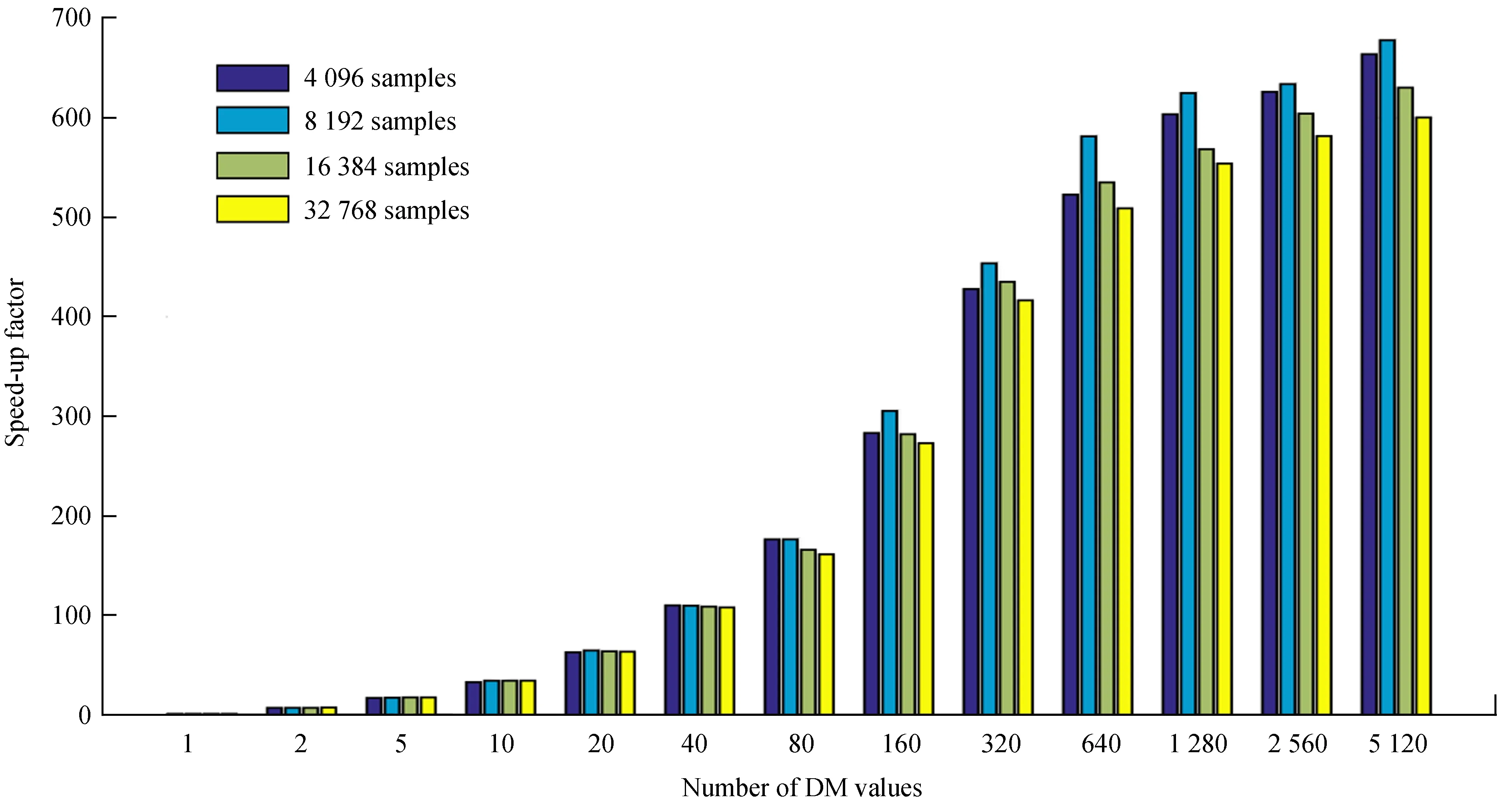
图6 通道数为1 024时图形处理器算法加速比Fig.6 GPU algorithm speed-up when the number of channels is 131 072
图6是通道数为1 024、采样数和色散量都变化的情况下,图形处理器并行算法的加速比。从图中可以看出,色散量个数对图形处理器非相干消色散算法加速比影响最大。随着色散量的增加,图形处理器并行算法的加速比迅速提高。如图6,色散量个数越大,计算消耗时间越多,当色散量为5 120时加速比最大。
实验结果表明,采样数、通道数及色散量个数都是影响图形处理器算法加速性能的关键因素。非相干算法执行过程中,图形处理器展示了强大的并行化处理优势,节省了大量重复计算时间,提升了算法的计算效率。
4 总 结
本文研究基于图形处理器的非相干消色散算法,提出了相关算法的图形处理器并行化加速方案,分析了算法的密集型计算部分,研究了图形处理器多线程任务分配、管理及存器层次的优化方法,提高了图形处理器资源利用率,显著提升了算法的计算性能。在图形处理器算法的实现过程中,我们深入分析了影响并行算法性能的主要因素,优化了CUDA程序,大大减少了算法执行的时间,图形处理器消色散算法加速比接近700倍,解决了算法在中央处理器上计算量巨大、无法实时处理的问题,通过实验分析算法的数据处理时间和加速比,验证了并行算法性能。
