罗马5期耀变体多波段目录BZUs的分类*
2021-01-19朱惊天樊军辉蔡金庭
朱惊天,樊军辉,蔡金庭
(1. 广州大学天体物理中心,广东 广州 510006;2. 广东省高校天文观测与技术重点实验室,广东 广州 510006;3. 广州天文观测与技术重点实验室,广东 广州 510006)

5BZCAT[7], 3FGL[8]和4FGL[9]源表均包含1 000多个耀变体以及它们的红移、同步峰频、多波段流量/流量密度、多波段有效谱指数等观测数据,这些源表为研究耀变体的性质提供了大样本。同时,这些源表中也包含了数百个未知类型的耀变体。对未知类型的耀变体的分类已经引起不少学者的兴趣,随着机器学习(Machine Learning, ML)方法在天文领域的广泛应用[10-12],很多未知类型的耀变体的分类工作也使用了这些方法[13-19]。例如,Fermi/LAT 3期活动星系核源表(3LAC)[20]中的高置信度样本(3LAC Clean Sample)共有402个未知类型的耀变体,文[15]对其中无缺失数据的400个未知类型的耀变体进行了分类,他们用了4种机器学习分类方法,综合这些分类器的结果,获得了246个蝎虎天体候选体和74个平谱射电类星体候选体;Fermi/LAT 4期源表(4FGL)中共有1 312个未知类型的耀变体,文[16]用3种机器学习分类方法对它们进行分类,同时考虑3种分类方法的结果,得到724个蝎虎天体候选体和332个平谱射电类星体候选体,仍有256个未知类型的耀变体没有给出明确的光学分类。为了对罗马5期耀变体多波段目录中不确定类型的耀变体的光学分类进行评估,本文使用支持向量机、随机森林、集成学习和多层感知机这4种机器学习分类方法,将不确定类型的耀变体分类为蝎虎天体候选体和平谱射电类星体候选体。
1 样 本
2 分类方法
机器学习是人工智能领域一种新兴的方法,包含多种分类模型(分类器)和回归模型,这些模型能从已知数据中学到某种规律,并应用到新数据。机器学习方法在天文领域的分类和回归研究中有良好的表现[10-12]。Scikit-learn(sklearn)[21]是Python提供的机器学习模块,其中包含许多机器学习算法,例如数据预处理方法和多种机器学习分类器。分类器通过学习已知类别的数据获得分类标准,然后用于未知类别的数据。通常已知类别的数据按一定比例随机划分为训练集和测试集,未知类别的数据则作为预测集。训练集用来训练分类器,在分类过程中学习训练集的参数蕴含的信息,确定不同类别的区分标准;测试集用来测试分类器的性能,利用优化分类模型(标准)来评估预测集的分类结果。
样本中227个不确定类型的耀变体作为预测集。利用klearn.train_test_split函数将已知类别的3 334个耀变体(1 425个蝎虎天体和1 909个平谱射电类星体)按7∶3的比例随机划分为训练集和测试集。每次划分训练集和测试集时,为确保训练集和测试集中的蝎虎天体和平谱射电类星体的数量比例与样本相同,设置随机种子为固定值(如random_state=1)。文中,训练集有2 333个耀变体(997个蝎虎天体和1 336个平谱射电类星体),测试集有1 001个耀变体(428个蝎虎天体和573个平谱射电类星体)。为了确保结果的稳定性,对sklearn.train_test_split函数中random_state(随机数种子)取5个不同值:0、1、2、3、4,用这5个数随机划分训练集和测试集,得到5个不同的训练集和对应的测试集;训练集1、测试集1,…,训练集5、测试集5。在5个训练集上分别训练分类器,得到5个不同的候选分类器,利用5个测试集测试5个候选分类器的性能,然后选择性能最优的1个用于预测227个不确定类型的耀变体(预测集)的分类。
2.1 分类器
支持向量机、随机森林、多层感知机和集成学习的介绍如下。
(1)对于线性可分的两类样本,可以在参数空间找到无穷多个超平面,将两类样本分隔在超平面两侧,其中距离超平面最近的样本点称为支持向量(Support Vector, SV)。支持向量机的原理是寻找唯一的最优超平面,使得支持向量到该最优超平面的距离最大。如果两类样本是非线性可分的,支持向量机可以将样本映射到高维(甚至无穷维)空间,然后寻找高维空间的最优超平面。
(2)决策树(Decision tree, DT)的结构是二叉树,分类时,信息进入节点时进行二元判断,当一个节点无法判断类别,则分裂为两个,直至判断出类别为止。由于决策树容易陷入节点过度分裂,导致分类器泛化性差。随机森林由大量决策树构成,决策树之间相互独立,给每个决策树随机划分训练集和参数,分类结果由所有决策树投票决定,随机森林的泛化性能往往优于单个决策树。
(3)多层感知机是人工神经网络(Artificial Neural Network, ANN)的一种。人工神经网络是一系列模仿生物神经网络结构的算法,这些结构由多个人工神经层组成,包括一个输入层、一个或多个隐藏层和一个输出层。每个人工神经层可以识别数据中的特定元素,然后将结果传输到下一人工神经层。通过综合每个神经层的结果,人工神经网络可以学习识别数据中的复杂特性。
(4)集成学习通过某种集成规则,将一组基评估器的结果集成,其性能往往优于单个基评估器。本文将支持向量机、随机森林、多层感知机作为集成学习的基评估器,集成规则为软投票,即给每个基评估器输出的类别概率一个权重,权重在[0, 1]区间,然后对基评估器的类别概率加权求和,作为集成学习输出的类别概率。本文尝试了多种权重组合,并选取其中最优的一个。
2.2 性能指标
机器学习常用的性能指标有准确率(Accruacy)、精准率(Precision)、召回率(Recall)等。本文只考虑准确率:
(1)
其中,TP(True Positive)是正确分类的正类别样本点数;TN(True Negative)是正确分类的负类别样本点数;FP(False Positive)是误分类的正类别样本点数;FN(False Negative)是误分类的负类别样本点数。准确率代表正确分类的样本点数占样本容量的比重。
2.3 数据集转换和特征选择
机器学习中,描述样本点属性的参数称为特征,本文分类所用的特征是罗马5期耀变体多波段目录中的8个参数。真实样本的特征往往还包含缺失值、噪声、无关信息、冗余信息等,它们会影响机器学习分类器的性能。因此,在使用机器学习分类器之前,需要先对原始数据进行数据集转换和特征选择,目的是保证最大限度地从原始数据中提取有效特征供机器学习分类器学习。数据集转换通常包括数据预处理和无监督降维,特征选择和无监督降维都是降维方法,可以减少特征数。
(1)数据预处理一般包括缺失值补全和标准化。本文中,若某个特征有缺失值,用同类特征的平均值填充。标准化是将所有特征映射到相同区间,以免某些特征的量级比其他特征小,导致分类器只学习量级大的特征。用sklearn中的preprocessing.StandardScaler将所有特征化为标准正态分布。
(2)降维一般包括特征选择和无监督降维,可以降低特征维度,减少计算成本,并提升分类器性能。本文采用的特征选择和无监督降维分别为序列向后选择(Sequential Backward Selection, SBS)和主成分分析(Principal Component Analysis, PCA),其中,序列向后选择是选取原特征集的子集,而主成分分析是将原特征映射到新空间,再选取新特征集的子集。序列向后选择不断从当前全部特征中舍去一个特征,直到所剩特征数量满足要求,被舍弃的特征与舍弃其他特征相比,舍弃该特征后分类器的性能损失最小。主成分分析不依赖分类器,它将样本点从原n维特征空间映射到新的n维正交空间,得到n个两两线性无关的新特征。新空间中,每个坐标轴称为主成分,在每个主成分方向上,样本点的分离达到最大。第1个主成分代表样本方差最大的方向为第1主成分,其余坐标轴称为第2,第3,…,第n主成分,每个主成分均为n个原特征的线性组合,它们对样本方差的贡献率依次递减,可根据需要取前k个主成分,k≤n。
对支持向量机和随机森林做序列向后选择和主成分分析,并将分类准确率与不做降维的分类准确率进行比较。在八维原特征空间的训练集1上用序列向后选择筛选特征,序列向后选择每次减少1个特征直至只剩1个特征,在此过程中观察分类器在不同维度特征空间的性能,选出最优的特征空间。主成分共有8个,舍弃第8主成分,其方差贡献率只有0.030 5%,其余主成分的方差贡献率均大于5%。序列向后选择和主成分分析的结果分别如图1、图2。图1为支持向量机和随机森林的序列向后选择结果,横坐标为特征数量,纵坐标为对应的分类器准确率。图2为主成分分析的结果,横坐标为各主成分,纵坐标为对应的方差贡献率,为了便于观察,图中第8主成分的方差贡献率放大了50倍。多层感知机的一个优势是无需做太多特征工程,因为人工神经网络的隐藏层能自动提取有效特征,并能自适应特征间的非线性关系,因此,没有对多层感知机做数据降维。对于集成学习,在每个训练集上将性能最优的支持向量机、随机森林、多层感知机分类器以最优的权重集成。

图1 序列向后选择结果图。(a)支持向量机的序列向后选择结果;(b)随机森林的序列向后选择结果Fig.1 The result graph of SBS. (a) SBS for SVM; (b) SBS for RF
2.4 超参数(Hyper Parameters, HPs)
在sklearn提供的机器学习和分类器中,有部分函数参数属于自由变量,称为超参数。超参数不能通过训练分类器得到,而要在训练分类器前人为赋值。本文使用网格搜索方法(Grid Search, GS)找出超参数的最优值,具体来说,指定一组候选值,网格搜索以暴力穷举的方式选出能最大化分类器准确率的值。本文对4种分类器中较重要的超参数使用了网格搜索,例如支持向量机中的C和多层感知机中的α,这两个超参数可以提高模型的泛化性能。
3 结果与讨论
机器学习分类器的性能见表1,表1第1列为分类器名称; 第2列为测试集名称; 第3~5列分别为八维原特征空间、序列向后选择选取的子特征空间、七维主成分空间中的分类器准确率;第6列为集成学习分类器准确率。4种分类器的准确率见图3,4种分类器在测试集上的准确率和不确定类型的耀变体的分类结果概述如下:
(1)对于支持向量机,分类结果显示,训练集3上,八维原特征空间的分类器准确率最高,为84.62%(见表1、图3)。在所有训练集上,主成分分析选取的七维子主成分空间的分类器准确率均不如其他特征空间。

图2 主成分分析结果图。第8主成分放大50倍

(3)对于多层感知机,分类结果显示,在训练集5上,八维原特征空间的分类器准确率最高,为94.21%。
(4)对于集成学习,在每个训练集上,选取准确率最高的支持向量机、随机森林、多层感知机分类器集成。分类结果显示,在训练集5上分类器准确率最高,为94.81%(见表1、图3)。此时成员分类器支持向量机、随机森林、多层感知机的权重分别为0、0.62和0.38。
分类器在5个测试集上的准确率表明,对于同一种分类器和同一个特征空间,5个测试集上分类器的准确率相近,说明本文的分类结果稳定,并且对于随机森林,当序列向后选择将8个特征减少到5个时,最大程度地提高了分类器的准确率。相反地,支持向量机和随机森林使用主成分分析后性能均明显下降,这可能是由于原特征间有非线性关系,不能很好地分离成两两线性无关的新特征。分类结果显示,4种分类器中,支持向量机的准确率明显低于其余3种,原因可能是在8参数空间,蝎虎天体和平谱射电类星体不能很好地被线性边界分开,而随机森林、多层感知机和集成学习分类器能很好地捕捉非线性分类边界,因此,其性能良好且优于支持向量机。4种分类器的最优超参数见表2,表2第1列为分类器名称; 第2列为测试集名称;第3~7列分别为八维原特征空间、序列向后选择选取的子特征空间、七维主成分空间中分类器的最优超参数。图3展示了4种分类器的准确率,可以更直观地看到每种分类器在每个训练集上的准确率。图3中4张子图的横轴均为测试集名称,纵轴为分类器的准确率; 图3上半部分两张子图,从左到右分别为支持向量机和随机森林分类器,其中蓝色、橘色、绿色柱状图分别代表八维原特征空间、序列向后选择选取的子特征空间、七维主成分空间分类器的准确率; 图3下半部分两张子图,从左到右分别为多层感知机在八维原特征空间和集成学习分类器的准确率。

表1 机器学习分类器性能Table 1 Accuracy for ML classifiers
选择在测试集上准确率最高的4个分类器,用它们对227个不确定类型的耀变体进行分类,得到每个不确定类型的耀变体为蝎虎天体的概率。若将判别概率的阈值设为p0=0.5,即某个源的pBL Lacs> 0.5判为蝎虎天体,否则判为平谱射电类星体。支持向量机、随机森林、多层感知机、集成学习分别给出116、106、112、112个蝎虎天体候选体和111、121、115、115个平谱射电类星体候选体。将4种分类器的分类结果与3FGL,4FGL和文[15-16]中的蝎虎天体和平谱射电类星体进行比较发现,本文的分类结果与其他文献并不完全一致,例如,对于集成学习的分类结果,分别有8、10、9、14个不确定类型的耀变体的分类与3FGL,4FGL和文[15-16]中的分类不同。本文尝试进一步改进分类方法,以减少与其他文献分类不一致的不确定类型的耀变体数量:(1)对p0分别取0.5、0.6、0.7、0.8、0.9、0.95这6个不同值,并比较分别取6个值时4个分类器的不匹配源的数量,即对p0做网格搜索。比较结果显示,当p0=0.7和p0=0.8,与3FGL对比分类结果时,支持向量机和随机森林的不匹配源的数量明显下降,其余情况下,不匹配源的数量随p0取值不同没有显著变化。(2)对于某个不确定类型的耀变体的预测类别,同时考虑4个分类器的分类结果,即只有当4个分类器的预测类别一致时,才认为该未知类型的耀变体属于该预测类别,否则认为该未知类型的耀变体的类别是不确定的。即对于某个源,只有当4个分类器同时预测其类别为蝎虎天体或平谱射电类星体时,本文才认为该源是蝎虎天体候选体或平谱射电类星体候选体,否则认为该源的类别是不确定源。依此标准,再次比较当p0取方法(1)中的6个不同值时不匹配源的数量,此时的比较结果表明,6个不同p0的不匹配源的数量相当,且均显著小于方法(1)中不匹配源的数量,当p0=0.8和p0=0.9时,不确定源的数量最少。综合以上两种分类改进方法,本文使用的分类改进方法是p0取0.8时,由4个分类器共同决定每个未知类型的耀变体的类别。
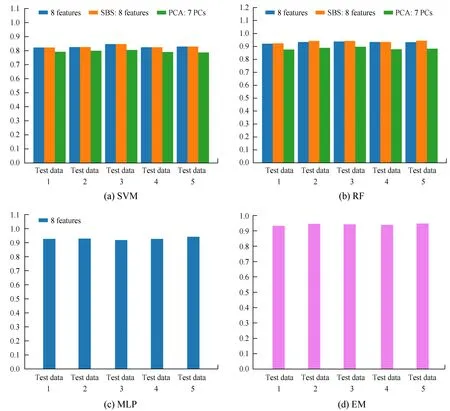
图3 4种分类器的准确率Fig.3 The accuracy graph of 4 classifiers
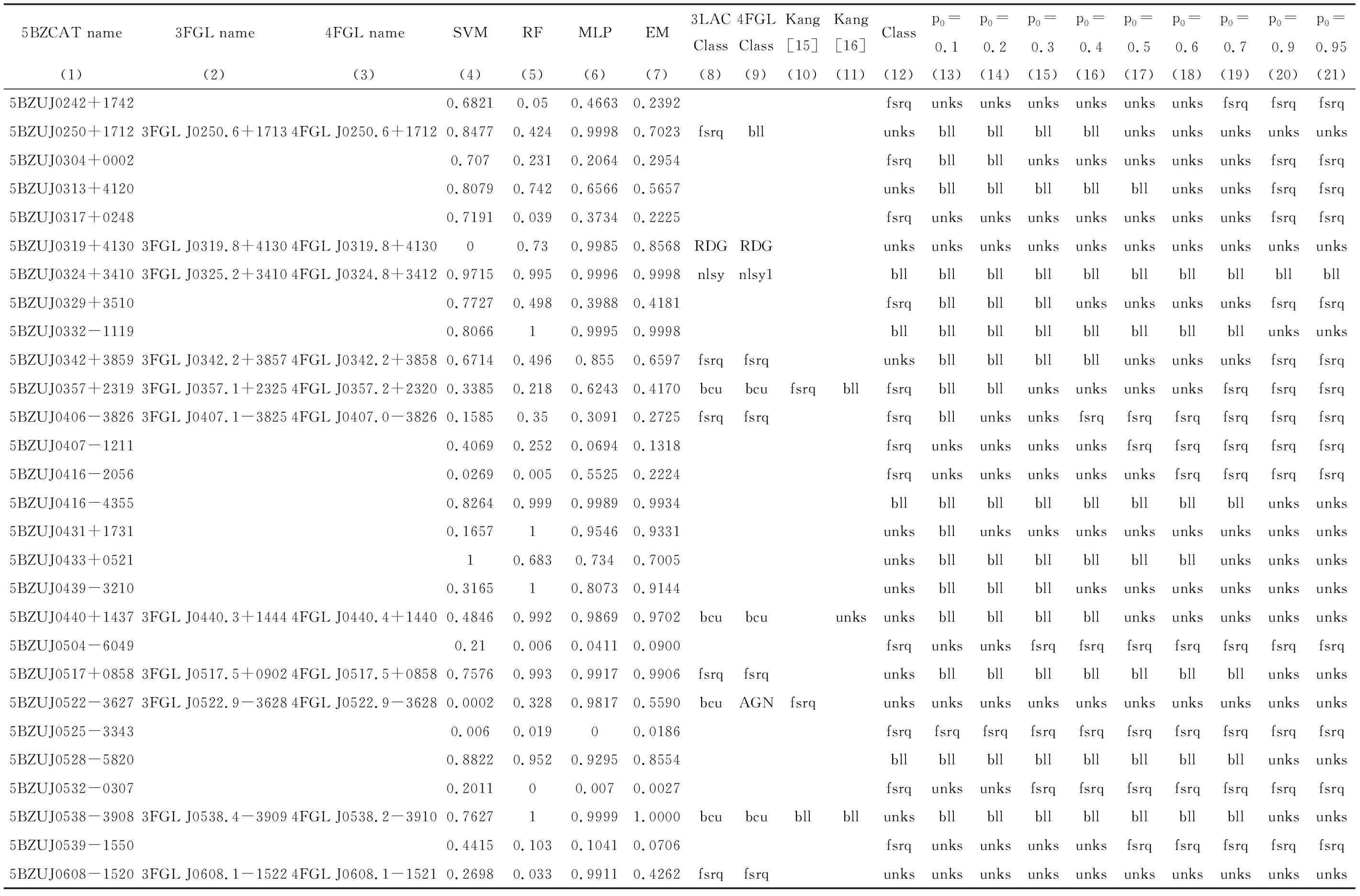
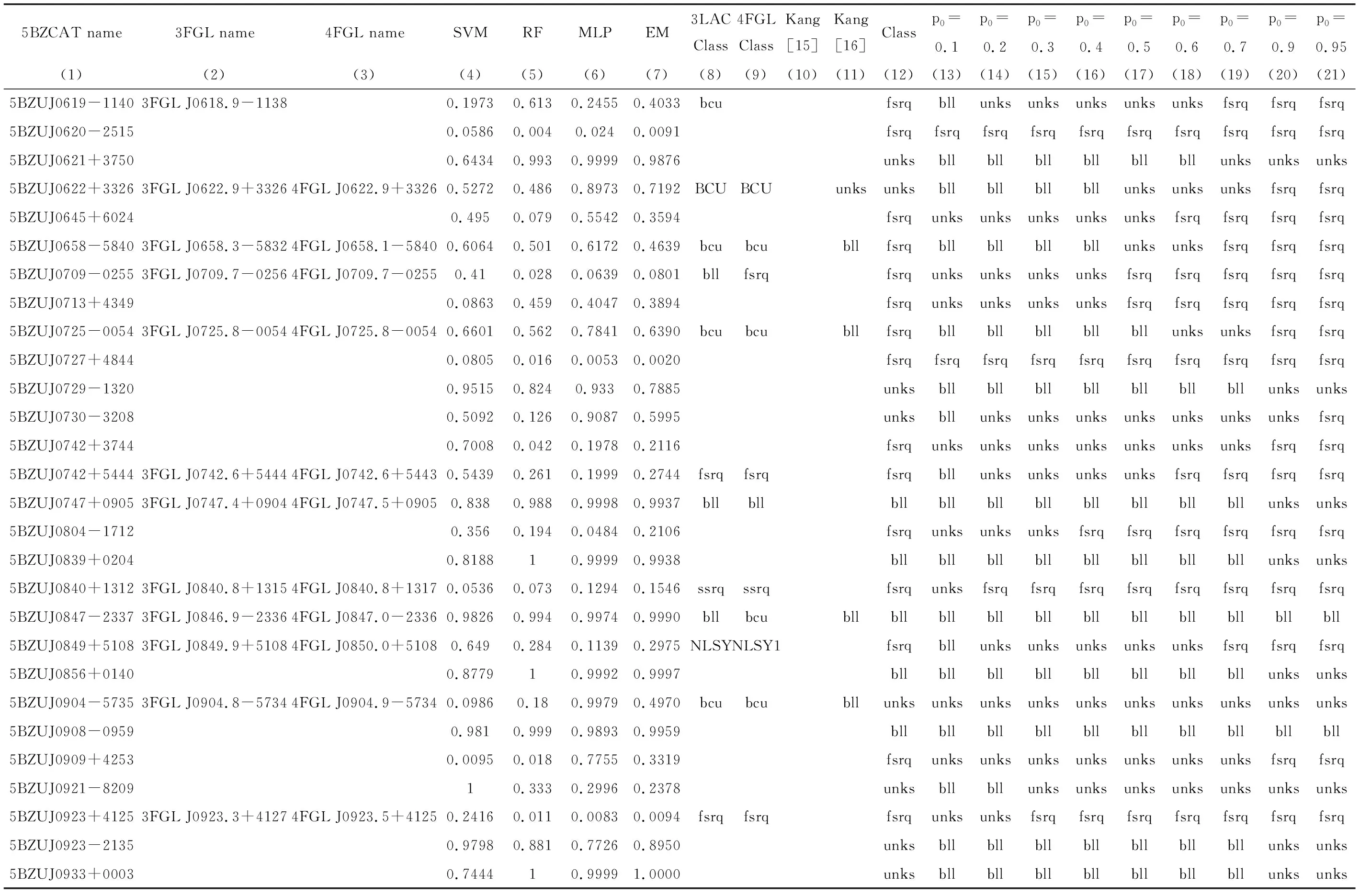
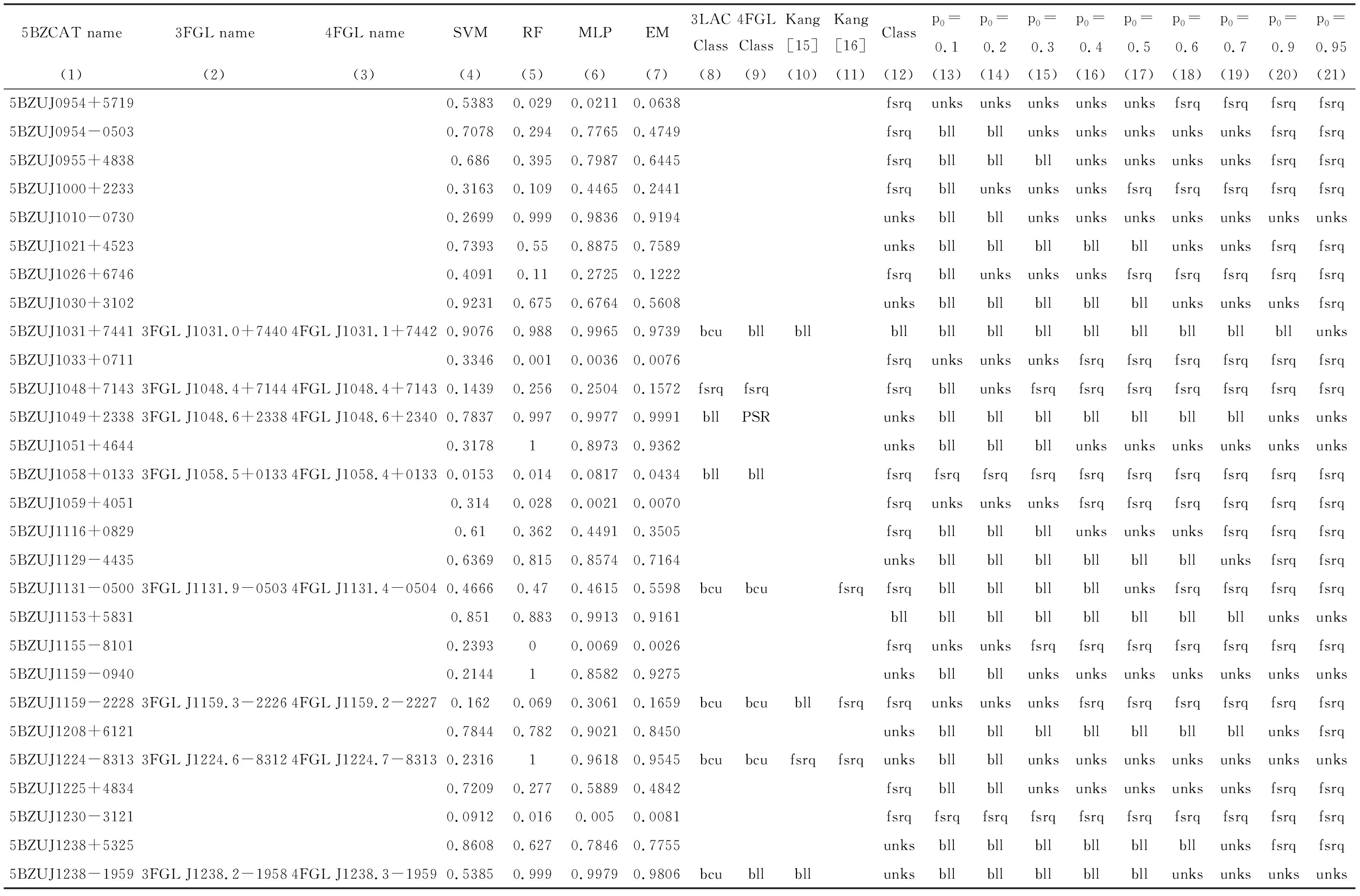
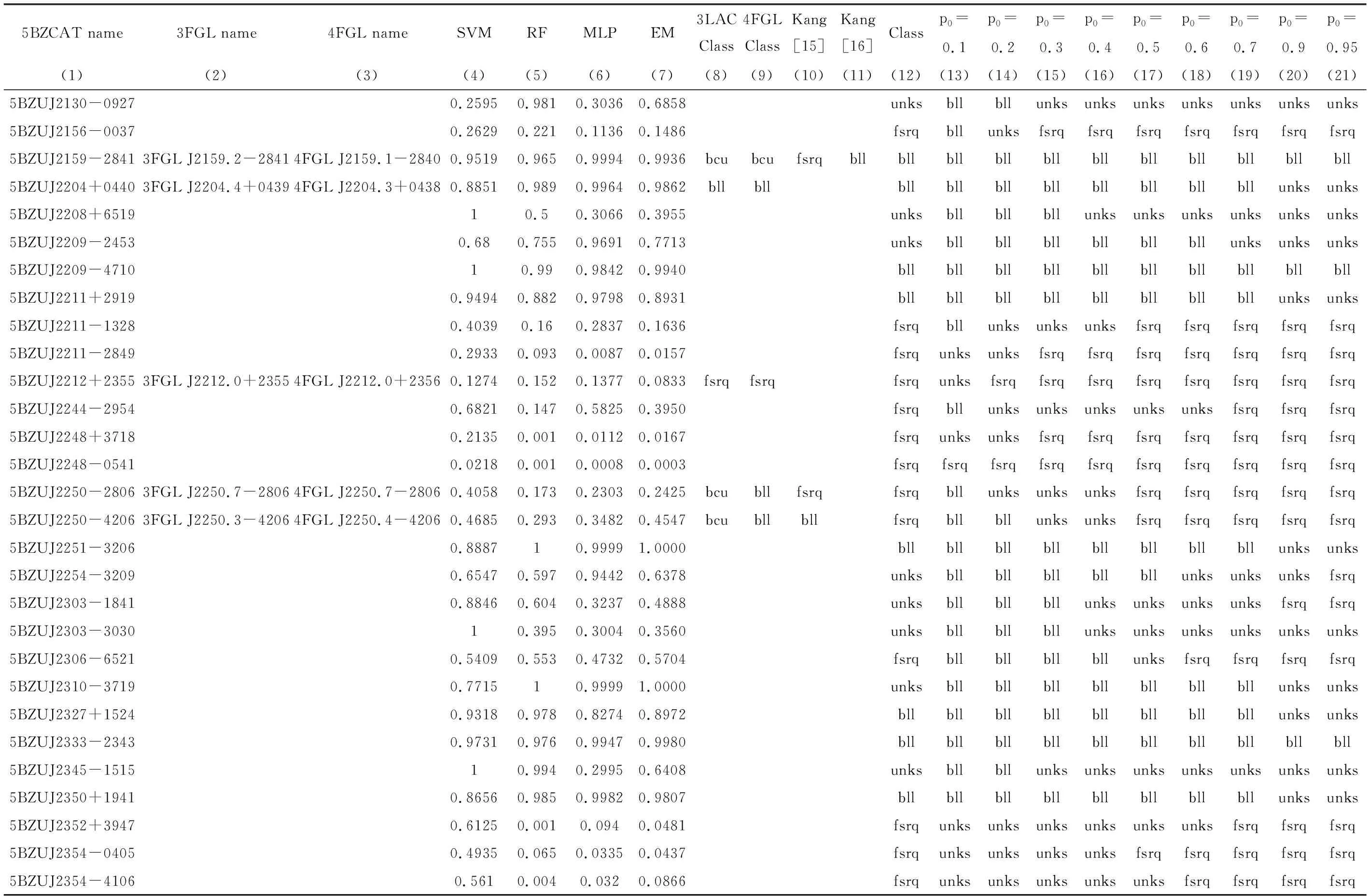
4个分类器的不匹配源的数量如表3和表4,p0取0.8时,227个不确定类型的耀变体由4个分类器共同决定的类别,以及和其他文献共同源的类别均展示在表5中。表3第1列为进行分类比较的文献;第2列为不同文献中蝎虎天体和平谱射电类星体的总数;第3列为分类器名称;第4~9列为p0取不同值时,4种分类器不匹配源的数量。表4第1列为进行分类比较的文献和不确定源;第2列为不同文献中蝎虎天体和平谱射电类星体的总数;第3~8列为4个分类器共同决定未知类型的耀变体类别时,不同的p0对应的不匹配源和不确定源的数量。表5第1~3列为未知类型的耀变体在5BZCAT,3FGL和4FGL中的名称;第4~7列为4种分类器预测的pBL Lacs;第8~11列为5BZCAT,3FGL,4FGL和文[15-16]对不确定类型的耀变体的分类;第12列为p0=0.8时,4个分类器共同决定的不确定类型的耀变体类别。

表2 各分类器的最优超参数Table 2 Optimal hyper parameters for ML classifiers

表3 4种分类器与其他文献的不匹配源Table 3 Mismatched sources of 4 classifiers

表4 联合4种分类器后与其他文献的不匹配源Table 4 Mismatched sources of combining 4 classifiers
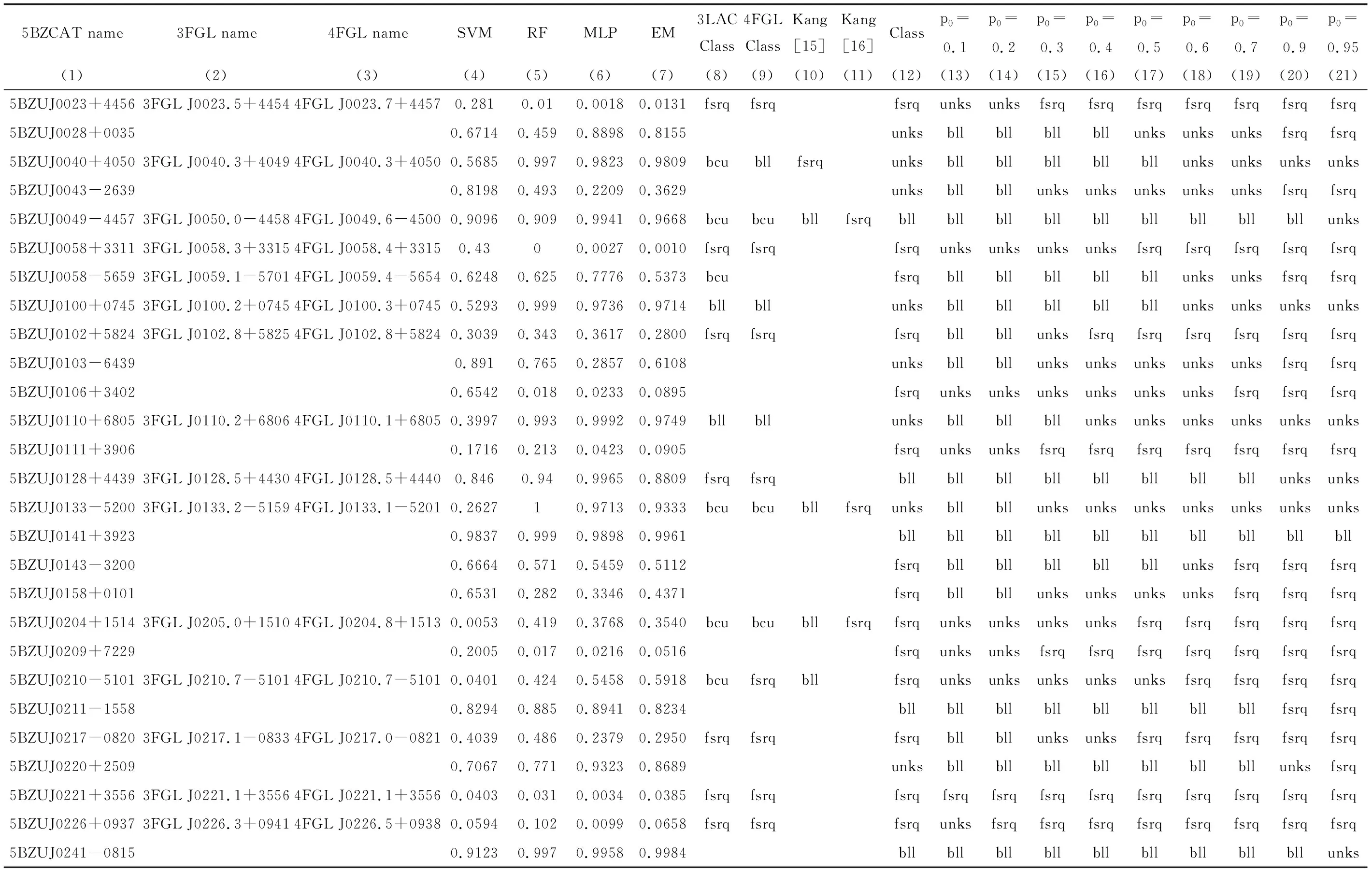
表5 227个未知类型的耀变体的分类结果与其他文献的分类结果Table 5 Classification results of 227 bzus and other literatures
(续表5)
(续表5)
(续表5)

(续表5)

(续表5)

(续表5)
(续表5)
4 总 结
本文以罗马5期耀变体多波段目录为主要样本,结合河外星系数据库的数据,选取红移、多波段有效谱指数、多波段流量/流量密度等8个参数,用支持向量机、随机森林、集成学习和多层感知机对罗马5期耀变体多波段目录中的227个不确定类型的耀变体进行分类,用特征工程和网格搜索分别筛选最优的特征和超参数,提升分类准确率。与其他文献的分类结果进行比较,通过将判别概率阈值p0设为0.8,并同时考虑4种分类器的预测类别,进一步减少了与其他文献不匹配的源。本文的分类结果表明,蝎虎天体和平谱射电类星体在8参数空间是可区分的,最终得到33个蝎虎天体候选体和119个平谱射电类星体候选体。
