一种面向FAST PB量级脉冲星数据处理加速方法及系统*
2021-01-19谢晓尧刘志杰于徐红游善平许余云姜家涛
张 辉,谢晓尧,李 菂,刘志杰,王 培,于徐红,游善平,许余云,姜家涛
(1. 贵州师范大学贵州省信息与计算科学重点实验室,贵州 贵阳 550001;2. 中国科学院国家天文台,北京 100101;3. 贵州师范大学数学科学学院,贵州 贵阳 550001;4. FAST早期科学数据中心,贵州 贵阳 550001;5. 中国科学院大学,北京 100049;6. 贵州水利水电职业技术学院管理工程分院,贵州 贵阳 551416)
1967年,剑桥大学在读博士乔瑟琳·贝尔(Jocelyn Bell)和导师休伊什(Hewish)等人首次在狐狸星座发现了射电脉冲星PSR B1919 + 21[1],这项20世纪重大的天文学发现于1974年12月获得了诺贝尔物理学奖,以表彰休伊什教授等人在射电天体物理学领域的开创性研究。人类至今已探测发现脉冲星约3 000颗,它们的自行速度可达每秒数百千米[2]。脉冲星强磁场、高密度、高能辐射、超强引力场、伴随恒星演化和超新星爆发过程等极端物理性质是地面人工实验室无法实现的。脉冲星的发现为核物理、粒子物理、天体物理、爱因斯坦相对论和宇宙学的检验提供了天然理想的实验室。对脉冲星进行深入研究,有希望获得许多重大物理学问题的答案。脉冲星的自转周期极其稳定,具有精准的时钟信号,可为引力波探测、航天器导航等重大科学技术应用提供理想工具。
脉冲星独特的物理性质和科学价值使其很快成为天体物理学最活跃的研究领域之一。为了更深入研究这类天体,望远镜的大量时间用于开展巡天项目,以期发现更多的样本数据。过去,受望远镜设备、数据采集系统、计算搜索理论和技术等因素限制,单个巡天项目采集的观测数据总量通常介于GB和TB之间。1997~2003年澳大利亚帕克斯望远镜采用13波束接收机巡天(Parkes Multi-beam Pulsar Survey, PMPS)[3],采集到49 700余个PSRFITS格式的数据文件,数据总量约5 TB,探测发现新脉冲星超过1 122颗。2012年南赛(Nançay)望远镜开展的SPAN512项目,采集的数据总量约50 TB。2010~2012年开展的高时间分辨宇宙(The High Time Resolution Universe, HTRU)系列巡天项目,因同时提高了时间分辨率和频率分辨率,每个波束(Beam)文件达16 GB,采集数据总量约1 PB。如今,500 m口径球面射电望远镜已投入使用,可探测频率覆盖70 MHz至3 GHz,它的灵敏度更高,综合探测能力更强,具备19波束同时扫描巡天能力,配备更高时间分辨率和频率分辨率的超宽带接收机,单波束数据采样频率由原来的1 024 Hz拓展至4 096 Hz。若19个波束同时工作,以100 μs为时间采样分辨率,频率带宽400 MHz,采用8 bit记录数据,日采集数据量可达100 TB。2017年7月~2018年5月,500 m口径球面射电望远镜多科学目标同时扫描巡天(The Commensal Radio Astronomy FAST Survey, CRAFTS)[4]记录0~1 GHz、1~2 GHz两个频段的数据,系统性脉冲星巡天观测数据已达数PB,其中,超宽带脉冲星漂移扫描数据约0.8 PB,19波束巡天数据约2 PB,加上数据处理分析过程产生的中间数据,总计已经超过3 PB。数据存于FAST早期科学数据中心集群磁盘阵列和磁带库中。预计500 m口径球面射电望远镜在射电脉冲星领域采集的数据总量在10~100 PB,巡天数据已迈入PB时代[5]。
500 m口径球面射电望远镜面临大规模数据异地传输、存储、快速处理和结果数据管理等实际问题。针对PB量级数据分析处理加速问题,本文提出了一种基于PRESTO的分布式并行计算方法,并据此研发了一套并行计算加速系统,系统命名为Craber,以纪念中国科学家发现Crab脉冲星和科学工作者的开拓创新精神。
1 搜索流程、软件及加速分析
1.1 搜索流程和软件
从观测数据中搜索脉冲星涉及多个必要步骤,包括去干扰、消色散、时频信号转换、周期信号搜索、数据折叠和候选体筛选识别等。从计算机处理数据的角度看,搜索流程可概括为(1)获取数据文件,计算节点读取一个观测原文件;(2)分析处理数据,按照预先设定的参数空间和搜索策略,执行分析指令;(3)生成结果,生成可供识别的候选体集合;(4)读取下一个待处理文件,并重复执行(1)、(2)、(3)步,详细的搜索流程和理论见文[6]。文[7]在脉冲星搜索加速方面做过尝试,取得了一定的加速效果。目前,较成熟的脉冲星搜索数据处理软件有PRESTO[8],SIGPROC[9]和基于图形处理器技术的Peasoup等,但存在如下几方面不足:
(1)软件并行程度不够。在一般的搜索中,消色散方法主要有两大类:相干消色散和非相干消色散[10]。这些方法需尝试数百个甚至上千个色散值,计算量成百上千倍增加。现有软件因开发历史较早,基于当时较小的数据规模,搜索流程中大多采用分步串行、单机计算方式。
(2)计算结果整理、统计和归档能力弱。计算参数、中间数据、结果数据、日志数据等缺乏科学化管理,数据归档同步不及时,数据分享和统计分析困难。
(3)计算资源整合能力差。观测数据以FITS格式存储,搜索中伴随产生众多临时文件,且多为小文件,带来频繁读写磁盘,计算任务具有数据密集型和计算密集型双重特点。现有搜索软件缺乏整合计算资源的能力,特别是不具备整合异地异构计算资源的方法。
1.2 并行计算分析
针对现有搜索软件存在的问题,结合数据搜索特点和实际应用,对计算可行性分析如下:
(1)任务可并行。从搜索流程分析,不同观测文件间不存在数据耦合关系,且处理过程中也保持数据相互独立。因此,全体待处理观测文件构成一个任务集合,单个观测文件为其中一个子计算任务。
(2)计算节点间可并行。通过网络技术将单个计算节点特别是异地计算节点整合起来,形成一定计算力的集群系统,各单节点上并行处理任务。
(3)软件程序可并行。根据PRESTO模块化程序设计和分步串行计算特点,经分析发现它具备改为并行运算的可能,可通过在各节点上部署优化过的PRESTO,并行调度子程序进行计算。
(4)搜索数据库协同计算和数据管理。异地计算资源协同计算和多任务并行处理面临数据一致性和归档问题,可通过建立搜索数据库系统协同管理和结果回收。
1.3 FAST早期科学数据中心计算资源
FAST早期科学数据中心由贵州师范大学与国家天文台联合建设,目标是解决500 m口径球面射电望远镜数据存储、分析处理和开展前沿科学研究。早期科学数据中心至台址两地数据中心通过2 GB专网连接,横跨州、县、镇20多个中转节点,传输距离300多千米,采用波分复用和双路通信容错技术保障数据传输的可用性。数据中心致力于改善软件可用性的同时,也设计、定制和组装满足望远镜未来一段时期计算需求的计算资源。
如表1,数据中心已分步建成A, B, C, D 4类不同子网计算集群,配备1.5 PB磁盘存储系统和1 PB磁带库,部署在数据中心宝山、花溪两地机房。计算集群采用中央处理器 + 图形处理器异构并行计算体系架构,包含154个中央处理器,288块图形处理器显卡,共计1 384个中央处理器核心和955 392个图形处理器核心,并对台式计算机进行改造,扩展显卡插槽,加装图形处理器显卡、大容量磁盘和内存资源等,强化单节点计算能力,共同组成分布式并行化计算集群,由任务管理节点统一调度,极大地解决了500 m口径球面射电望远镜当前一段时期的数据分析问题。
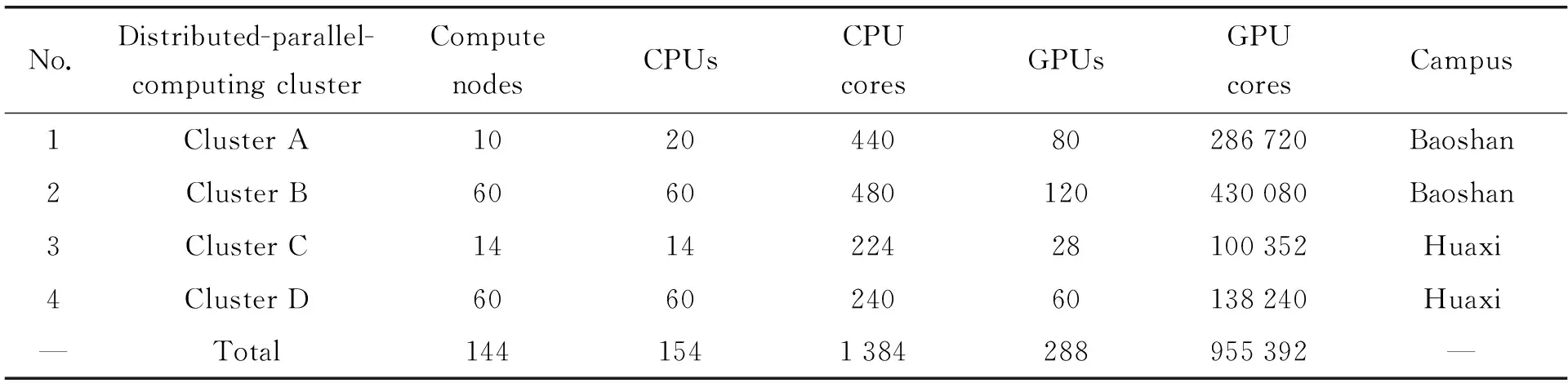
表1 FAST早期科学数据中心中央处理器 + 图形处理器异构系统计算集群算力统计Table 1 Statistics for computational power of computing cluster in FAST Early Science Data Center
2 系统设计
2.1 设计思路和方法
根据数据中心已有的软硬件资源,整合结构化数据库、搜索软件和网络资源,解决如何调度、如何管理、如何抗错等问题,系统设计思路和方法如下:
(1)优化PRESTO程序套件,开发一套并行计算任务调度系统,调度部署在各节点上的PRESTO程序分步搜索指令,并行地分析处理子任务;
(2)整合利用FAST早期科学数据中心位于贵州师范大学宝山、花溪两校区两校区子网计算集群,构建一个对外透明的分布式并行计算集群;
(3)以单个观测数据文件划分计算任务单元,建立任务队列,经任务调度分发程序和数据库协同具体搜索工作;
(4)建立面向搜索过程和数据管理的专门数据库,进行任务分发、计算协同、日志数据和结果数据回收管理,解决异地计算资源参与计算时的数据一致性和归档问题,供后续应用程序开展候选体识别和筛选。
2.2 功能节点划分
如图1,Craber并行加速计算系统按照功能不同,逻辑上划分为:(1)1个数据源节点,用于存放观测数据文件;(2)1个任务控制节点,用于计算任务的协调控制;(3)N个并行计算节点,负责具体计算搜索任务;(4)1个数据库节点,承担数据管理和协同计算;(5)1个非结构化结果数据节点,负责存放过程数据;(6)1个网络应用节点,提供配置交互。各节点间通过高速网络进行通信和数据交换,调度系统采用客户端/服务端(C/S)体系架构实现。
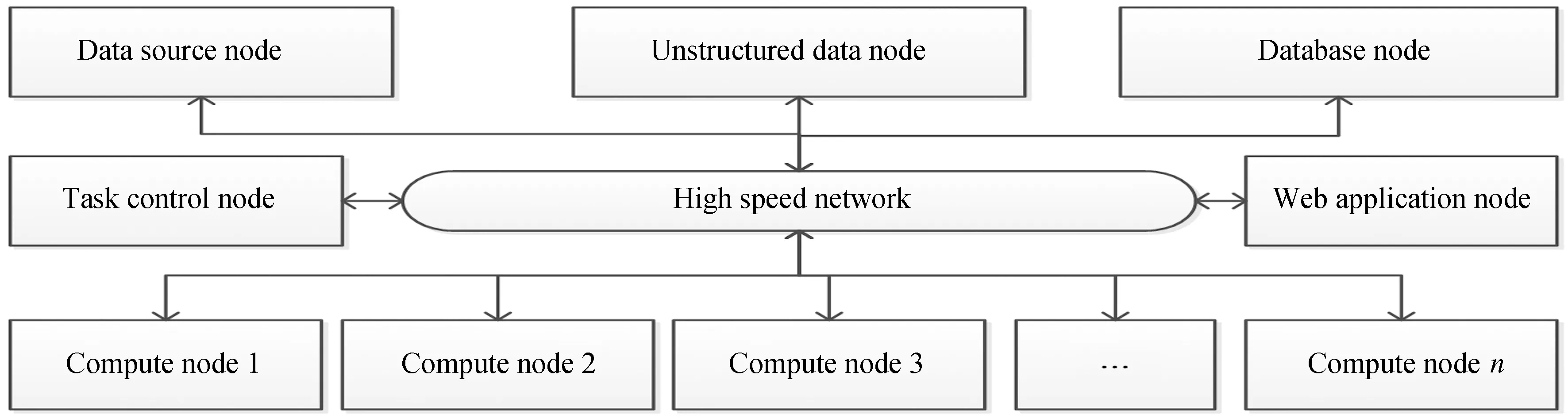
图1 Craber加速计算系统功能结构图Fig.1 Structure diagram of the Craber parallel accelerated computing system
2.3 计算节点与其他节点间指令和数据传递过程
计算节点主动与数据库和任务控制节点通信和获取计算任务。任务节点负责从数据库任务队列中获取参数,分发给计算节点,如数据文件地址、计算参数、处理指令集。计算节点作为客户端,通过配置文件获取参数信息,与服务器通信后进入计算状态,执行PRESTO套件程序指令,进行脉冲星数据的计算工作,并将计算结果提交任务控制服务器和计算结果文件服务器。如表2,节点上配置文件规定了此节点用于去干扰、消色散、周期搜索、数据折叠等步骤的线程分配方案、各步等待时间以及数据同步情况。

表2 配置文件参数列表说明Table 2 Configuration file parameter list and description
2.4 计算节点内部数据处理和交互过程
单个节点的计算能力体现为可用的线程数量。任务服务器给计算节点分配数个任务,广播计算参数。如图2,计算节点根据任务参数,从数据节点中读取对应观测数据文件并处理。计算节点依据线程分配方案和数据库中任务ID值,并行执行图中1~6步流程,由数据库和任务控制节点完成数据同步。
如图3,单个计算节点图形处理器/中央处理器异构系统开展单个任务计算数据处理流程。在每个计算节点上通过指定图形处理器核心分配方案,分别用于PRESTO子程序并行地进行消除干扰(RFIFIND)、消除色散(PRESUBBAND)、周期搜索、数据折叠等步骤。因消色散耗时相对较长,系统指定较多核心数专门用于消色散,较少核心数用于周期搜索、数据折叠等步骤进行流水化作业。
2.5 搜索数据库
Craber系统的任务状态和任务数据的维护通过数据库实现。搜索数据库解决的问题包括:(1)在分布式计算任务中,保证调度的任务数据一致性,提高容错能力;(2)为原始数据、处理日志、结果整理和统计提供基础平台;(3)为后续利用人工智能(Artificial Intelligence, AI)开展候选体筛选识别提供数据支持和辅助工具。作为Craber系统重要组成部分之一,我们专门设计了面向搜索过程的搜索数据库(详细内容另文发表),它主要包含FITS观测数据文件信息表、任务执行时间状态信息表、任务指令参数表等10余个不同用途的数据库表,其中,文件信息表记录FITS文件的编号、文件名、文件路径、格式、观测设备和处理状态等。通过调用PRESTO中readfile指令获取数据集中全体待计算FITS头文件信息,并写入数据库任务指令参数表,记录一个任务ID对应的计算参数,以及PRESTO子程序指令rfifind,prepsubband,realfft,accelsearch,prepfold步骤编号,用来表示 prepsubband 的子步骤。

图2 单个计算节点内的计算流程Fig.2 Search process of one single compute node in the cluster
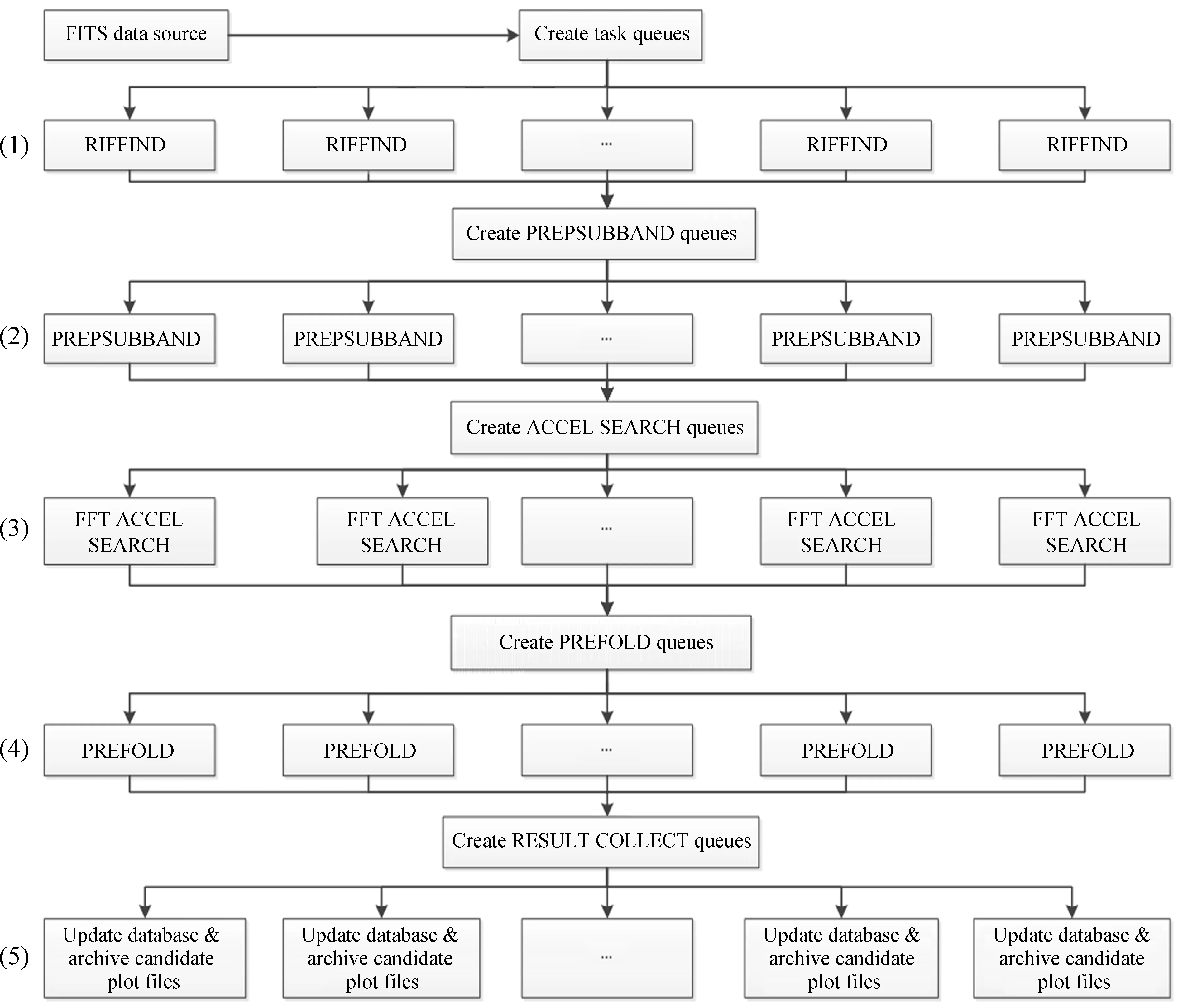
图3 基于图形处理器/中央处理器的异构系统并行计算加速流程Fig.3 GPU + CPU-based parallel computing acceleration process for heterogeneous systems
3 系统实施与结果分析
3.1 计算实验环境
如图4,Craber集成一个大容量数据文件服务器,存放经预处理后的FITS文件,为了方便计算节点快速读取观测文件,数据源利用网络文件系统(Network File System, NFS)实现管理,节点内使用临时文件系统(Temporary File System)提高输入输出能力,部署一个任务控制服务器,用于计算的协调控制、任务分发和参数广播,数据中心4个计算子网分布式部署,负责具体的计算搜索业务。搜索数据库采用大型关系型数据库ORACLE进行结果数据管理和计算参数设定。一个文件服务器存放中间数据文件及候选体判别图,一个前端网络应用程序进行作业期间的实时监控。

图4 当前FAST早期科学数据中心Craber计算加速系统网络部署拓扑示意图Fig.4 Network deployment topology of Craber acceleration system of FAST Early Science Data Center
3.2 测试数据
如表3,帕克斯多波束巡天项目采用96个频率通道,子带宽3 MHz,积分时间2 100 s,单个文件100 MB。500 m口径球面射电望远镜CRAFTS数据集经过频域分割数据预处理,频率范围269.125~396.875 MHz,频道数512,带宽128 MHz,单波束扫描时间26.214 4 s,单个文件128 MB。

表3 来自帕克斯多波束巡天和500 m口径球面射电望远镜CRAFTS巡天项目的测试数据文件样例Table 3 Two sample test files from PMPS and CRAFTS
3.3 实验结果
如图5,随机选取400个帕克斯多波束巡天数据文件,消色散的色散量步数设为768。以单线程单机处理,单个文件耗时约6 000 s,采用8线程OMP(OpenMP)处理,单个文件平均耗时3 530 s。启用Craber子网计算集群D中55个计算节点,每个节点配置Intel酷睿i7处理器、32 GB内存和1 TB硬盘,总耗时约14 550 s,平均36 s处理一个数据文件,即集群整体吞吐速度是36 s。
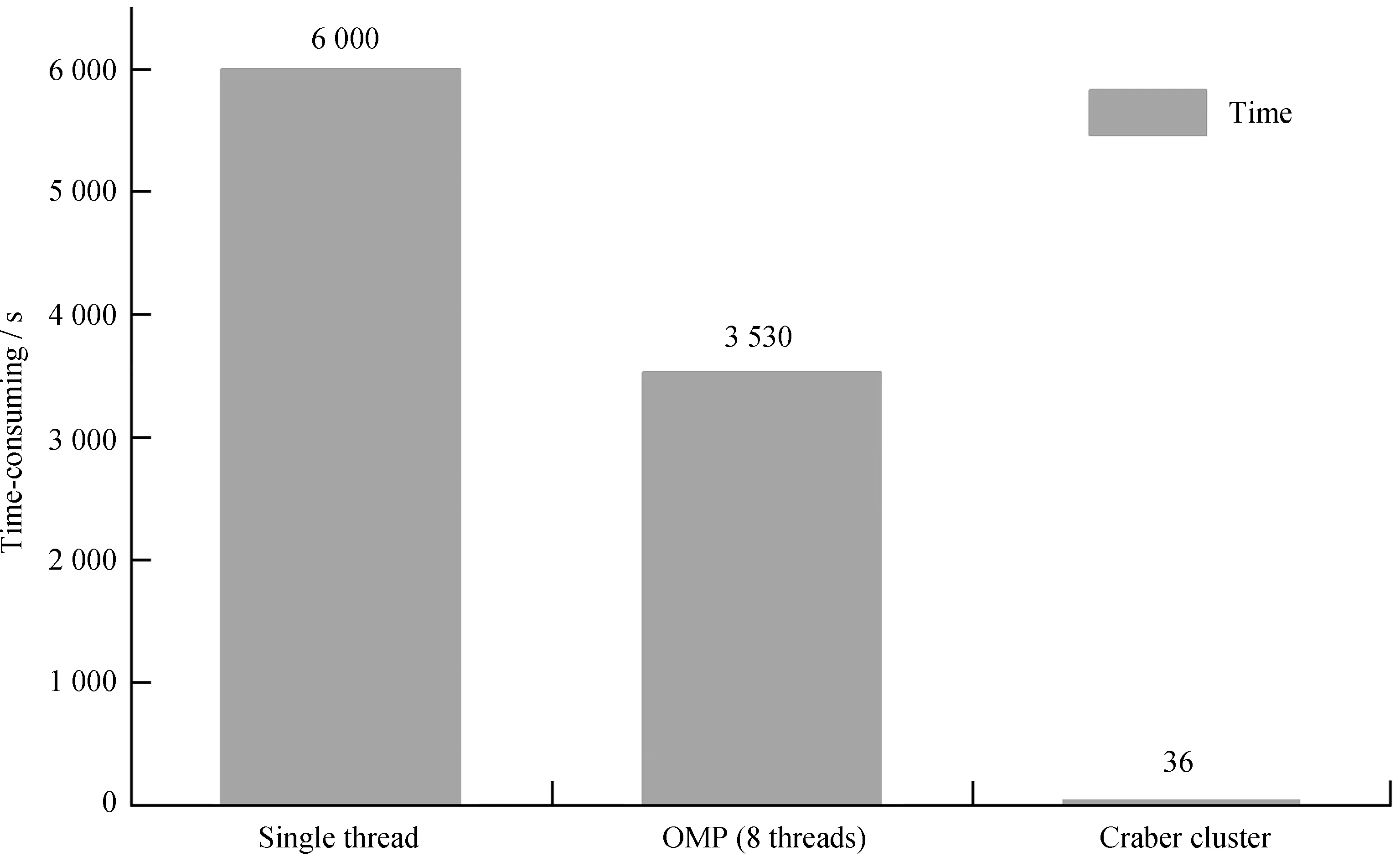
图5 分别使用单机单线程、OPM 8线程、Craber加速集群系统对400个PMPS数据文件处理耗时测试
500 m口径球面射电望远镜超宽带漂移扫描巡天数据分析的结果显示,单个128 MB数据文件平均处理时间22 s。2017年10月至今参与处理数据文件66 000多个,相关结果数据统一存储于系统集成的搜索数据库和文件服务器中。500 m口径球面射电望远镜通过多套独立的脉冲星搜索流程,已探测到超过100颗优质脉冲星候选体,该系统辅助探测到其中数十个候选体,经后随观测认证,首批认证两颗脉冲星[11],其中,第1颗脉冲星J1859-01(FP1),自转周期1.83 s,距离地球约1.6万光年[12],第2颗脉冲星编号J1931-01(FP2),自转周期0.59 s,距离地球约4 100光年,两颗脉冲星由500 m口径球面射电望远镜在南天银道面通过漂移扫描发现,更详细的参数结果见文[13]。另有部分候选体处于国际射电天文台认证阶段,具体参数结果还在进一步分析中。
4 总结与展望
Craber计算加速系统是针对处理500 m口径球面射电望远镜海量数据、完成脉冲星搜索主要科学目标而开发的专用计算系统,包含154个中央处理器,288块图形处理器显卡,为500 m口径球面射电望远镜脉冲星搜索项目的数据处理提供了有力保障,集成的面向搜索过程的数据库系统在协同计算任务中,保证调度的任务数据一致性,提高容错能力,并为原始数据、处理日志、结果整理和统计提供基础平台,同时,也为下一步人工智能程序开展学习训练、候选体识别提供数据支持,大幅减少结果数据整理统计和管理工作量。系统应用于帕克斯巡天数据处理,单个100 MB文件平均耗时36 s,应用于500 m口径球面射电望远镜脉冲星漂移扫描巡天数据处理,单个文件平均耗时22 s。500 m口径球面射电望远镜使用多套独立的脉冲星搜索流程,确认发现114颗脉冲星,其中,该系统已辅助发现数十颗新脉冲星,包括一些具有特殊辐射特征的脉冲星[14]。系统可经适当计算参数调整后用于FAST单脉冲(RRATs, FRBs)搜索,以及搜寻模式、跟踪模式和漂移扫描模式下的大规模脉冲星数据分析处理加速。随着5 G技术的成熟和硬件成本进一步降低,大规模数据的异地协同计算将变得更易操作。下一步计划持续向Craber集群系统增加更多计算节点,在黔西南州新增计算子网,并入此计算集群系统。优化搜索数据库功能结构和计算节点中的中央处理器/图形处理器调度方案,以应对500 m口径球面射电望远镜今后PB量级数据集的快速处理,改善数据中心存储压力,辅助探索发现更多新脉冲星样本。
致谢:感谢Scott Ransom博士提供的PRESTO程序套件,以及来自帕克斯望远镜的数据支持。同时,特别感谢贵阳学院张正东博士、澳大利亚联邦科学与工业研究组织(Commonwealth Scientific and Industrial Research Organization, CSIRO)George Hobbs教授、王晨教授、代实博士以及网易的张翔工程师对本文的建设性建议和帮助。
