基于策略改进遗传算法的双星星族光谱拟合*
2021-01-19迟焕斌李忠木
迟焕斌,李忠木,王 锋,3
(1. 昆明理工大学管理与经济学院,云南 昆明 650093;2. 大理大学天文研究所,云南 大理 671000;3. 广州大学天体物理中心,广东 广州 510006)
双星星族是包含一些共同演化的双星和单星、具有相同初始金属丰度和演化年龄的恒星组合,是对单星星族的扩展和丰富。基于双星星族模型得到的星团和星系参数结果通常更合理[1],因此,基于双星星族的研究得到越来越多的关注。
光谱拟合是获得星系物理信息的重要方法[2]。随着各种巡天项目的开展和天文信息技术的发展,人们获得了越来越多的高质量光谱数据,为天体光谱拟合创造了条件,有效推动了光谱拟合的发展。光谱拟合近年来取得了一系列成果,如文[2]利用贝叶斯方法对单星星族光谱进行拟合来估计星系参数信息;文[3]用贝叶斯模型选择的方法分析了双星星族和单星星族模型,发现双星星族模型比其它没有考虑双星相互作用的模型的光谱拟合效果好很多;文[4-5]对早期星系紫外到可见波段的光谱进行拟合,发现双星星族模型可以很好地解释球状星团蓝离散星的观测结果;文[6]首次通过双星星族光谱拟合解释早型星系的紫外反转现象。
由于双星星族演化比传统的单星星族复杂,考虑的物理量多,对应的理论光谱库大,一定拟合精度要求下的光谱采样率更高,所以双星星族光谱拟合需要进行海量的计算。能否快速高效地进行双星星族光谱拟合直接影响星族演化合成方法的应用。因此,探索基于双星星族模型的快速有效的光谱拟合方法十分重要。
为了解决双星星族光谱拟合速度不能满足星系演化等研究需求的问题,加快星族演化合成方法在天文研究中的推广和应用,本文基于管理策略进行了一次尝试,将光谱拟合转化为一类最优化问题,以最小化理论光谱和观测光谱之间的均方误差为优化目标,建立最优模型,提出策略改进的遗传算法对模型求解,并与双星拟合算法[1]和传统遗传算法对比,验证算法的有效性。
1 双星星族模型介绍
双星星族模型的一个主要目标是构建高精度且完备的双星星族理论光谱库。双星星族的理论光谱构建包括两部分:模型输入参数的假设和理论光谱的计算。
如文[1]所述,双星星族模型采用文[7]的快速恒星演化程序代替恒星演化轨迹,采用BaSeL 3.1恒星光谱库[8]和Chapbrier初始质量函数[9],并假设每个双星的主星和次星质量比服从0~1的均匀分布[9]。恒星形成率假设为ψ(t)=ψ(0)e-t/τ[8]的形式,t和τ分别表示星系的年龄和恒星形成的持续时标。
利用演化星族合成方法,在初始质量函数和恒星形成率已知的情况下,可以计算星系中不同时刻形成的恒星数。借助文[7]的快速恒星演化程序进行恒星演化计算,通过BaSeL 3.1恒星样本库将恒星的演化参数转换为光谱能量分布。在完成恒星演化计算后将所包含的单颗恒星的光谱合成,可以计算年龄为t的星族在波长λ的光谱流量fλ0。每个星族光谱流量由3个参数决定:金属丰度z、年老星族年龄t1和年轻星族年龄t2。考虑恒星速度弥散σ*、尘埃消光(采用文[8]的消光理论)、红移、银河系消光等因素,双星星族合成中在波长λ处观测的光谱流量可表示为
fλ=[fλ0(z,t1,t2)⊗G(v*,σ*)]p(τλ)r(Aλ) ,
(1)
其中,fλ0为由z,t1,t2决定的星族的光谱流量;G(v*,σ*)为平均值和标准偏差分别是v*和σ*的一个高斯分布;p(τλ)为通过尘埃消光是τλ的尘埃的能量百分比;r(Aλ)为通过银河系消光Aλ后的能量比;⊗为卷积算子。
为了简化双星星族的理论光谱库,本文将v*,σ*,τλ,Aλ的取值均设为0,仅考虑z,t1,t2。这并不影响实验目的,同样可以对比分析改进遗传算法在光谱拟合中的表现,因为对比实验也是基于同样的简化双星星族理论光谱库。
2 基于策略改进遗传算法的双星星族光谱拟合
2.1 双星星族光谱拟合模型
光谱拟合的目的是获得星系星团的物理参数信息。在双星星族模型中,光谱是由z,t1,t2,v*,σ*,τλ,Aλ和星族恒星质量8个参数共同决定的。星系的恒星质量可由文[10]的拟合公式
log(M*/M⊙)=0.63+4.52log[σ0/(km·s-1)]
(2)
计算,其中,M*为星系的恒星质量;M⊙为太阳质量;σ0为恒星的速度弥散。其它参数可通过光谱拟合,即将星族的理论光谱与观测光谱进行比对,从而给出星族组成的定量信息。具体任务是从理论光谱库中找到最接近观测光谱的理论光谱。在光谱拟合过程中,通过将观测光谱与理论光谱进行比对,并最小化理论光谱与观测光谱数据之间的差异,以确定拟合最优的理论光谱,进而推断恒星组成的主要参数。
双星星族理论光谱库有稠密的参数网格:恒星金属丰度取值为0.000 3~0.03,金属丰度较低时(z< 0.001)参数间隔为0.000 1,金属丰度较高时(z> 0.001)参数间隔为0.001;星族群的年老星族年龄(t1)在0~15 gigayear范围内,间隔为0.1 gigayear,年轻星族年龄(t2)从t1递减到0 gigayear,间隔为0.1 gigayear;恒星速度弥散σ*以步长为10 km·s-1从0到350 km·s-1增加;尘埃消光(τλ)取值是时间隔为0.01的0至0.5区间。因此,双星星族理论光谱库包含巨大的参数空间,光谱拟合包含海量的计算,为此建立拟合模型如下。
记观测光谱为fobλ,双星星族合成理论光谱为fthλ,则光谱拟合契合度可由
χ2=∑[(fobλ-fthλ)2ωλ]
(3)
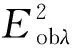
(4)
ωλ也可以根据特殊要求赋予某个阈值。星族光谱拟合的实质是在理论光谱库对应的参数空间进行搜索,找到与被拟合的观测光谱χ2最小值所对应的理论光谱。当χ2最小时,双星星族合成光谱拟合模型满足物理约束0 <ωi< 1,其本质是一个最优化问题,可表示为
(5)
2.2 双星星族光谱拟合算法
遗传算法[11](Genetic Algorithm, GA)是模拟自然界生物遗传进化行为,提出选择、交叉和变异算子,通过对求解问题空间的多点并行迭代搜索能快速有效地收敛至全局最优解的一类仿生启发式算法。遗传算法是一种基于种群的搜索算法,其个体代表了可能解的一个样本。随着搜索迭代的进行,个体通过分享和交换信息产生更好的后代。传统遗传算法(Conventional Genetic Algorithm, CGA)包含选择、交叉和突变等至关重要的操作,可以选择获胜的个体,维持种群的多样性,并在种群内的个体之间交换信息。
然而,传统策略改进遗传算法在局部搜索能力上表现较差,且对初值非常敏感。对遗传算法运行机制分析后,受粒子群算法惯性自适应的启发,同时为克服不足,本文在传统遗传算法策略改进的基础上,设计了一种自适应遗传算法(Self-adaptive Genetic Algorithm, SGA)用来求解双星星族光谱拟合问题。传统遗传算法采用固定交叉概率(Probability of Cross, PC)和固定突变概率(Probability of Mutation, PM),这使得算法按照既定的规则进行,从而导致遗传变异不够灵活。基于特定的进化遗传使得算法的性能如收敛速度和全局优化能力等对进化参数的选择很敏感。如果个体的适应度值大于总体的平均适应度值,则分配的交叉概率和变异概率较小。此外,适应度值越大的个体越接近目标解,因此,应赋予较小的交叉和变异概率,以保护信息不被遗传给下一代。与之相反,对适应度值较小的个体则伺机引入扰动因子(Disruption Operator, DO),增强变异能力,个体被赋予较大的交叉和突变概率,以增加变异概率,于是,适应度值越小的个体变异的机会越大。为了减小进化参数选择的依赖性,提高算法的收敛速度和全局优化能力,自适应遗传算法改进如下:
(1)自适应交叉概率更新:
(6)
(2)自适应突变概率更新:
(7)
其中,i为当前迭代次数;favg为种群的平均适应值;fc为选择交叉操作的个体适应值;fm为选择变异操作的个体适应值;fmax为最大适应值;γGA为随机参数,根据经验取γGA=0.5。
(3)为了增强算法对搜索空间的探索能力,引入扰动因子:
(8)
其中,δ为(-2, 2)之间的随机数;Disi, j为第i个染色体和邻域第j个染色体的汉明距离;Disi,best为当前最优染色体和第i个染色体的汉明距离。
自适应遗传算法具体流程如图1,主要包括:
(1)光谱数据预处理,包括剔除发射线、归一化和红移处理;
(2)问题编码与种群初始化;
(3)按目标函数计算适应值并保留当前最优种群,决定种群的大小包括染色体长度和个数等,依策略初始化种群,设定进化终止条件;
(4)判断是否达到收敛或停止条件,如果满足则输出搜索结果,否则进行迭代进化;
(5)选择算子,根据适应度值随机选择一组较好的个体;
(6)按(5)式更新交叉概率;
(7)交叉算子:从集合中随机选择两个染色体交换一个或多个位,根据交叉概率产生两个新的个体,按(8)式添加扰动因子;
(8)按(7)式更新变异算子:从集合中随机选择一个染色体,并根据突变概率改变一个或多个位以产生一个新的染色体;
(9)返回步骤(4)进行终止判断,循环以上步骤,直到终止条件。
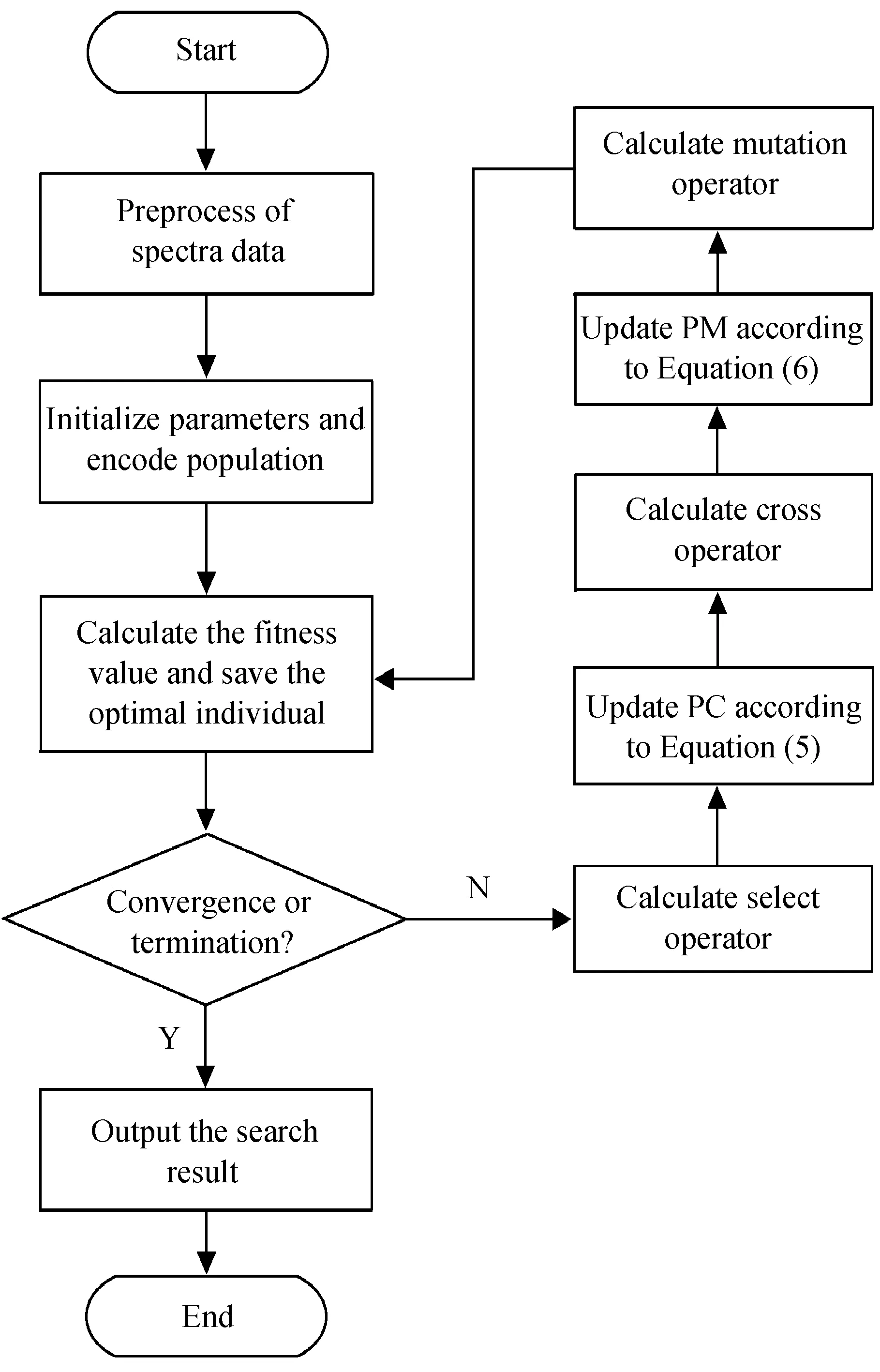
图1 自适应遗传算法流程图Fig.1 SGA flow chart
3 实验与分析
3.1 策略改进的遗传算法实验
为了验证自适应遗传算法在双星星族光谱拟合中的寻优效率,本文选取传统遗传算法和文[1]的双星拟合算法作为对比。实验代码采用Python3.6开发,操作系统为ubuntu18.04 64 bit,内存容量为8 GB,中央处理器型号为i7-4790,主频3.60 GHz。实验的理论光谱数据(详情参考文[1])使用基于Chapbrier初始函数的双星星族理论光谱库进行拟合, 观测光谱数据选自99个本地星系的紫外-可见波段的光谱数据,可以从互联网上下载,具体可参见文[4]。这些数据的特点是覆盖从紫外到可见光波段的波长,范围很广。此外,由于双星对紫外光谱有明显的影响,这些数据也是探索双星演化对光谱拟合影响的理想数据。每条观测光谱采样点数为Nλ=3 871,以550 nm为归一化因子对光谱进行预处理。自适应遗传算法参数设置为交叉概率上限C2=1,变异概率上限M2=1,随机参数γGA=0.5,个体编码长度n=20,种群规模Pop=100,耗时指标取每个算法重复20次的平均值。
首先,从观测光谱数据中随机选取一条(NGC 1399星系)作为实验数据,参考文[12]进行数据预处理;然后,将观测光谱进行坏点、发射线、天光线等屏蔽,得到编号为spec-0266-51630-0010的光谱数据;接着,借鉴文[13]的方法,采用χ2/Nλ作为评价标准,当χ2/Nλ< 1时,认为理论光谱与观测光谱拟合良好, 星族合成参数估计准确,拟合结果可以接受,拟合迭代过程如图2(a)。算法在种群迭代20次后收敛,对应的适应值χ2=1 308,拟合精确度为χ2/Nλ=0.343 3,理论光谱与观测光谱拟合良好,如图2(b),其中灰色曲线代表实际观测的光谱,红色曲线代表拟合得到的最优理论光谱。
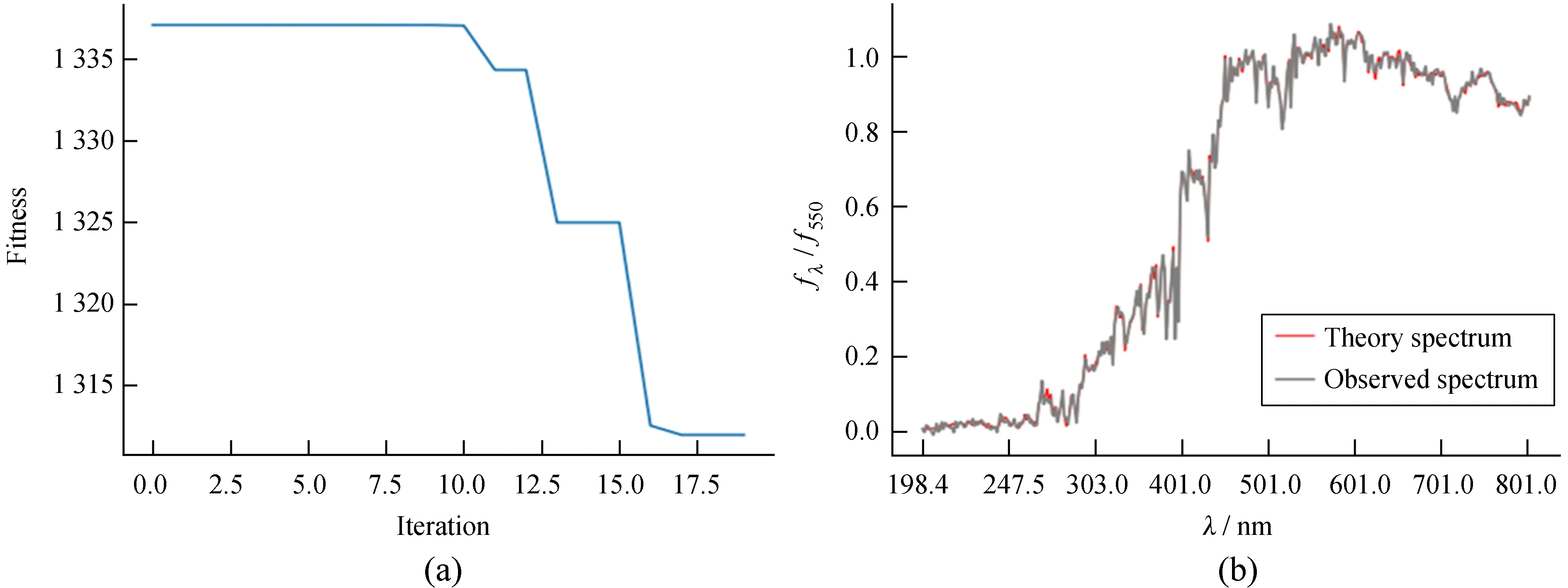
图2 自适应遗传算法拟合迭代过程Fig.2 SGA fit
3.2 与传统遗传算法的比较
传统遗传算法的交叉概率为0.8,变异概率为0.1,染色体长度为20,Pop=100。对测试光谱用传统遗传算法在双星星族理论光谱库上进行拟合结果如图3。传统遗传算法中,种群迭代16次后陷入局部最优,迭代15次后开始收敛,找到拟合度最优的理论光谱。实验迭代20次平均耗时3 201.3 s,比双星拟合算法略优,速度提高了19.2%。与传统遗传算法相比,自适应遗传算法在迭代20次后收敛,能有效跳出局部最优陷阱,收敛速度显著改善,实验20次平均耗时1 304.4 s,速度提高了19.1%。
3.3 与双星拟合算法的比较
用Python实现文[1]所述的双星拟合算法,拟合遍历过程如图4,横轴表示遍历计算的次数,纵轴表示每次计算得到的卡方统计量。由于是全网格搜索,双星星族模型的理论库覆盖波段长,演化参数网格稠密(模型光谱库覆盖金属丰度从0.000 3到0.03,精度为0.000 1;t1,t2范围从0到15 gigayear,精度为0.1 gigayear),导致样本参数空间巨大。虽然将模型参数做了简化处理,但是要完成一条观测光谱的拟合需要逐一进行海量对比才能找到拟合度最优的理论光谱,实验20次平均耗时3 954.2 s。与双星拟合算法相比,自适应遗传算法具有更强的全局搜索能力,对理论光谱搜索效率更高,收敛速度显著改善,20次平均耗时减少了67.2%。
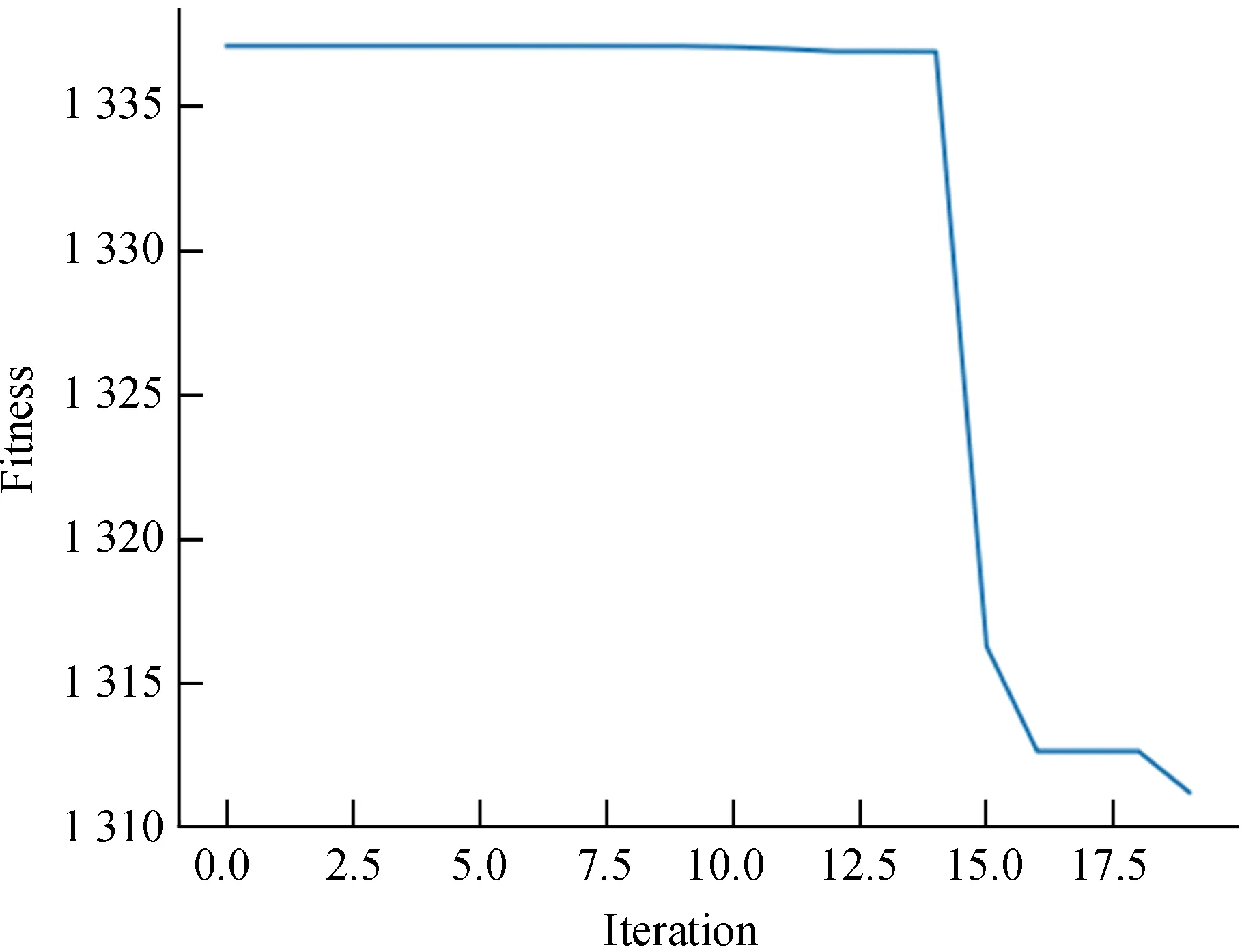
图3 传统遗传算法拟合迭代过程Fig.3 CGA fit
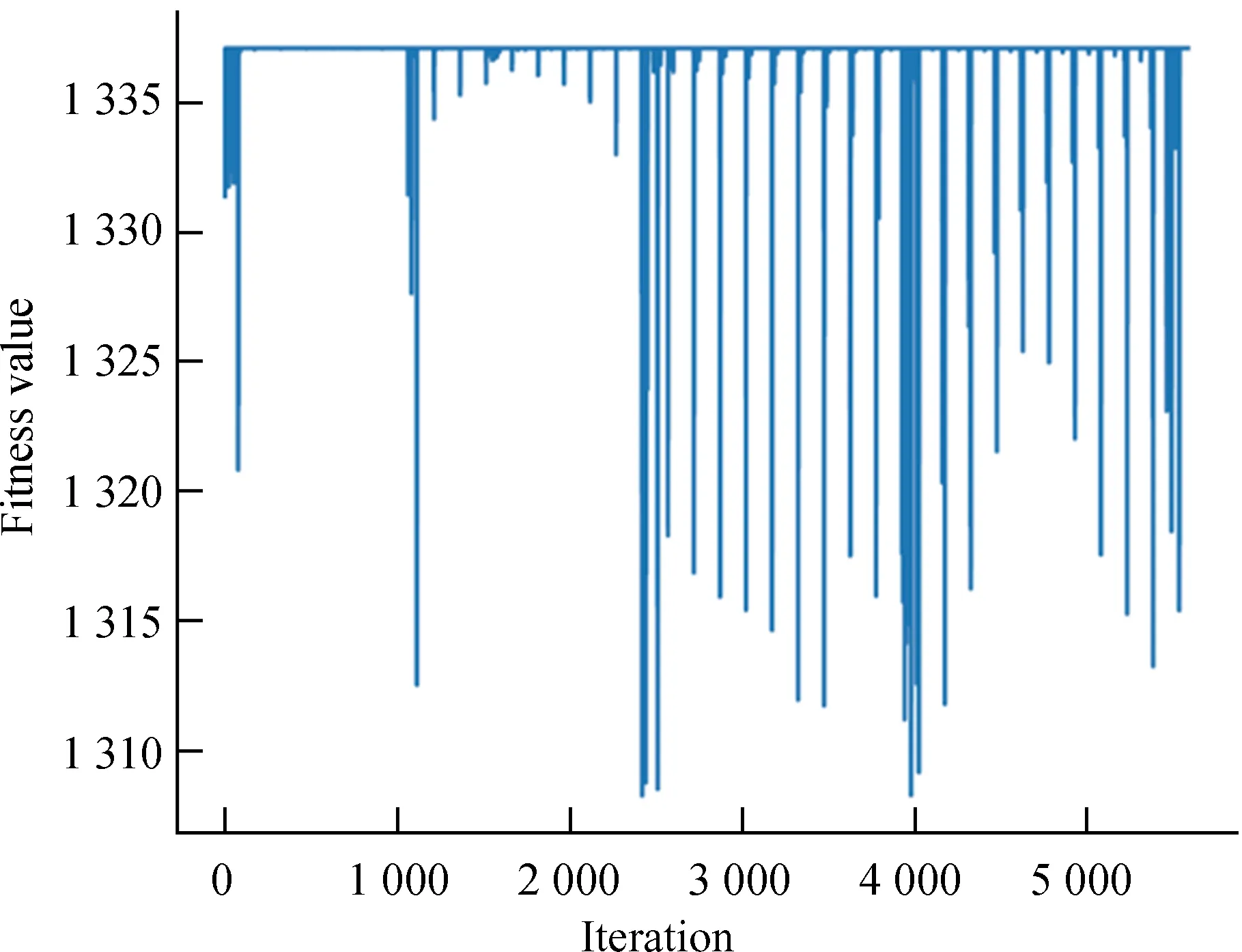
图4 双星拟合遍历过程Fig.4 Binary star to fit
3种算法均能找到最小χ2对应的理论光谱,按照理论光谱的参数网格设置,反演得到表1中的拟合参数。

表1 NGC 1399星系拟合参数Table 1 Fitted parameters of NGC 1399 galaxies
产生误差的主要原因是对实验模型进行了简化,(1)理论光谱库只考虑z,t1,t2而没有考虑v*,σ*,τλ,Aλ等参数的影响;(2)没有考虑观测光谱的误差,没有对观测光谱的不确定性进行处理,即信噪比取值很大的理想情况。文中得到的金属丰度比文[4]的拟合值小0.005,这也符合预期,原因是模型输入的不确定性通常导致金属丰度估计值偏低。星族年龄的拟合值比文[4]低50%的主要原因是简化的模型没有考虑速度弥散,从而导致星族年龄被低估。该拟合结果也体现了 “年龄-金属丰度简并效应”。
综上,增加自适应策略的改进遗传算法在拟合速度上较传统遗传算法和双星拟合算法平均提高了43.5%,拟合结果符合预期。
4 总结与讨论
采用自适应策略改进的遗传算法对双星星族光谱拟合,结果表明:(1)采用群智能算法解决双星光谱拟合问题是可行的;(2)策略改进遗传算法和传统遗传算法、双星拟合算法相比,在双星星族光谱拟合中能将计算速度分别提升19.1%和67.2%,对双星星族光谱拟合速度平均可提高43.2%,提升效果明显。策略改进的遗传算法在传统遗传算法的基础上,发挥了遗传算法全局搜索能力强、相较于传统遗传算法收敛速度快的优点。此外,策略改进的遗传算法在搜索时更智能,能有效跳出局部最优陷阱,提高算法的全局搜索能力,避免算法早熟,相对于双星拟合算法的全网格搜索,自适应遗传算法对搜索空间做了取舍,所以效率更高。虽然策略改进遗传算法在双星星族拟合上提高了速度,但是还有很大的提升空间。一方面,编码方式对算法探索能力和收敛性有影响,改进算法编码如利用量子编码等值得探索,另一方面,群智能算法发展日新月异,探索更有效的搜索策略,如探索和强化学习等融合也很有必要。考虑到遗传算法易于并行实现,下一步可探索并行策略下的策略改进遗传算法对光谱拟合速度的改善。
