基于自监督表征学习的海面目标检测方法
2021-01-16张友梅李晓磊
张 倩, 张友梅, 李晓磊, 宋 然, 张 伟
基于自监督表征学习的海面目标检测方法
张 倩1, 张友梅2, 李晓磊1, 宋 然1, 张 伟1
(1. 山东大学 控制科学与工程学院, 山东 济南, 250061; 2. 齐鲁工业大学(山东省科学院) 数学与统计学院, 山东 济南, 250353)
为提升海上无人装备对海洋的感知与监测能力, 海面目标检测准确度的提升至关重要。但受复杂海况影响和传感器限制, 采集高质量海面目标样本困难, 导致大规模海面目标数据集缺乏, 使得基于深度学习的海面目标检测发展缓慢。为此, 文中将自监督表征学习引入海面目标检测领域, 利用动量对比自监督表征学习算法进行船舶特征学习, 从大规模无标签海面目标数据中挖掘船舶目标特征, 为后续进行基于更快的区域卷积神经网络的海面目标检测提供先验知识。实验结果表明, 借助于大规模无标签数据集, 文中提出的基于自监督表征学习的海面目标检测方法能够取得与有监督预训练方法相当的检测效果, 突破了有标注海面目标样本不足的限制。文中工作可为进一步研究基于深度学习的海洋智能感知问题提供参考。
海上无人装备; 目标检测; 自监督表征学习; 深度学习
0 引言
作为海域辽阔的海洋大国, 提升海洋科技实力对建设海洋强国意义重大。借助于无人艇等海上无人装备对海域进行实时监测可以有效加强海域管控, 维护我国海洋安全, 因而如何提高海上无人装备的智能感知能力便成为海洋科技领域的关键问题之一。在此背景下, 海面目标检测成为海洋环境感知领域的热点研究方向之一。
目标检测作为计算机视觉领域最具挑战性的任务之一, 包括定位和分类2个子任务, 即确定所需检测图片中所包含目标的位置并对其进行准确分类。近年来, 随着深度学习理论的快速发展, 基于深度学习的目标检测算法成为主流, 在通用场景下取得了较好的检测效果。但深度学习模型往往依赖于大规模数据集进行训练, 应用较为广泛的MS COCO(microsoft common objects in cont- ext)[1]、PASCAL(pattern analysis, statical modeling and computational learning)、VOC (visual object classes)[2]等标准数据集中海面目标较少, 因而将在这些数据集上训练的目标检测模型直接应用于海面目标检测任务效果不佳。同时, 由于长期以来海面目标专用数据集较少, 且大多没有模型训练所需的边界框标注, 基于深度学习的海面目标检测相关研究相对较少。
由于海洋环境不同于陆地和天空, 其环境更加复杂多变, 浪、涌、涡和流等海面波动均会对海面目标检测造成影响, 相比于通用场景下的目标检测任务, 海面目标检测难度更大, 传统海面目标检测方法具有诸多局限性。为在海面目标检测过程中充分利用深度学习模型对视觉信息的感知能力, 并针对现有海面目标检测数据集样本量较小、难以满足模型有监督预训练需求的问题, 文中首次将自监督表征学习引入海面目标检测领域,提出了一种基于自监督表征学习的海面目标检测模型。
1 相关方法介绍
1.1 基于深度学习的目标检测
基于深度学习的目标检测模型通常分为单阶段检测模型和两阶段检测模型。前者根据输入的图像特征直接预测物体的边界框坐标和类别, 代表算法包括YOLO (you only look once)[3]系列、单阶段多框检测器(signle shot multibox detector, SSD)[4]等, 此类算法由于只进行一次边界框回归, 因而检测速度更快, 但检测精度有待提升。而两阶段算法将目标检测分为两步进行:
1) 由候选区域生成网络(region proposal net- work, RPN)生成一系列候选框, 该过程基于预设的锚点完成了第1次边界框回归;
2) 对候选框坐标进行调整, 即进行第2次边界框回归, 同时识别框内物体, 检测精度更高。虽然目前RetinaNet[5]等单阶段算法在检测精度方面已取得很大提升, 但基于两阶段式框架的更快的区域卷积神经网络(faster regions with convolutional neural network features, Faster R-CNN)[6]、包含掩膜分支的区域卷积神经网络(mask regions with convolutional neural network features, Mask R-CNN)[7]等依然是目标检测领域表现优异的主流方法。
1.2 海面目标检测
海面目标检测任务是指定位海洋场景图片中的目标(主要是船舶), 并对其类别(如轮船、帆船及渔船等)进行细分。传统的海面目标检测通常包括海天线检测、背景建模和背景去除3个步骤, 所得的前景区域被认为是包含目标的区域。虽然海天线检测对提高海面目标检测效果有所帮助, 但其对恶劣天气、复杂海况等适应性较差。
近年来, 基于深度学习的海面目标检测研究不断出现。Shin等[8]将YOLO v2模型分别在通用场景数据集和海洋场景数据集上训练, 证明利用海洋数据进行模型训练是非常有必要的。Moosbauer等[9]发现使用预训练的Mask R-CNN参数对模型进行初始化检测效果更佳。但基于深度学习的海面目标检测研究尚处于起步阶段, 文中针对大规模海面目标数据集缺乏所导致的深度学习算法在海面目标检测领域应用受限的问题, 以充分利用无标签海洋数据为出发点, 将自监督表征学习引入海面目标检测领域, 可实现在无需大规模有标注海面目标数据的情况下取得较好的检测效果。
1.3 自监督学习
自监督学习作为无监督学习范式的一种, 通常从数据本身获取监督信息, 以此作为人工标注的替代, 模型借助于所获取的监督信息来学习数据的底层结构特征。目前自监督学习已广泛应用于自然语言处理领域[10-11], 而对于目标检测[3-6]、目标跟踪[12-14]等视觉感知任务, 有监督训练仍是主流方法。但对缺乏大规模数据标注的海洋感知任务而言, 模型通过采用自监督的方式初步学习如何进行更具普适性的特征提取, 然后在有限的标注数据上结合任务需求对模型进行微调也不失为一种合适的选择。现有的自监督学习主要包括以自编码器及其变体[15-17]为代表的生成式方法和以动量对比(momentum contrast, MoCo)[18]、简易式对比学习(simple framework for contrastive learning of visual representation, SimCLR)[19]为代表的对比式方法, 相比于前者, 对比式方法侧重于从原始数据中获取抽象化的语义信息, 因而更适合于视觉感知与理解任务。
2 海面目标数据集
受复杂海况影响和传感器限制, 采集大规模、高质量海洋环境及目标数据样本比较困难, 导致可用于海洋感知研究的开源数据集较少, 且样本量远不及ImageNet[20]、MS COCO[1]等通用数据集。
2.1 海上船舶数据集
Gundogdu等[21]于2017年公开了大规模海上船舶数据集(maritime vessels, MARVEL), 该数据集图片均来自Shipspotting网站, 根据任务需求可分别下载14万/40万图片用于相关研究, 其中的样本如图1所示。

图1 MARVEL数据集样本示例
MARVEL数据集是目前已知样本量最大的海洋船舶数据集, 但由于缺乏目标检测所需的边界框标注, 无法直接将其用于海面目标检测任务。文中利用该数据集对自监督海洋船舶特征学习进行研究。
2.2 新加坡海上数据集
2017年Prasad等[22]开源的新加坡海上数据集(Singpore maritime dataset, SMD), 共包括81段视频, 其中63段有标记, 共包含10类目标。该数据集包含可见光数据(visual, VIS)和红外数据(near infrared, NIR)两部分, 文中使用该数据集中的VIS部分(见图2)进行海面目标检测研究。

图2 SMD数据集样本示例
虽然SMD数据集样本量不大, 但63段有标记视频中的目标均有边界框标注, 可直接用于海面目标检测任务。文中将该数据集中的视频数据转换为图片数据(每2帧取1帧), 然后进行基于图像的海面目标检测研究。
3 基于自监督表征学习的海面目标检测
针对现有海面目标数据集样本量不足的问题, 文中尝试利用无标注的大规模海面目标数据集, 通过引入自监督表征学习相关方法, 挖掘海面目标样本的底层特征, 为海面目标检测任务提供先验知识, 提高基于深度学习的目标检测模型在海面目标检测任务上的表现。换言之, 即将海面目标检测模型训练分为自监督船舶特征学习和有监督海面目标检测2个阶段进行, 以降低海洋数据样本不足对检测效果的影响。
3.1 基于MoCo的船舶特征学习
海面目标以各类船、艇为主, 其间相似性较高, 在无类别标签的情况下学习样本特征难度较大, 而对比式学习方法能够更好地挖掘相似样本间的差异, 从而学习到更具样本区分度的特征, 更有利于海面目标检测、分类等下游任务。因此在自监督船舶特征学习阶段, 文中采用He等[18]提出的MoCo方法在无标注海面目标数据上训练特征提取模型(见图3)。
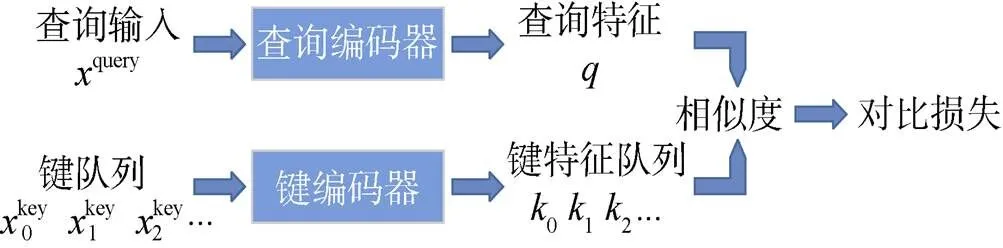
图3 MoCo自监督表征学习方式
MoCo将对比学习看作字典查找过程, 并提供了一种构建大且连续的动态字典的方式, 其核心思想为: 通过将字典作为一个样本队列进行维护来保证字典足够大; 同时通过采用动量更新的方法更新键编码器来避免其变化过快, 以提高队列中键的表征一致性。
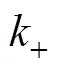
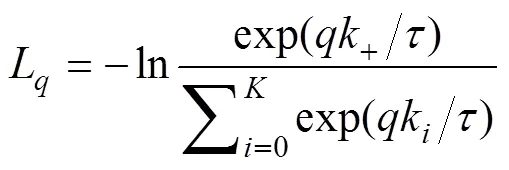
所谓动量更新即在训练过程中不通过反向传播更新键编码器参数, 而是采用如下更新方式
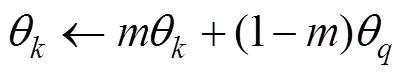
为了验证基于MoCo的船舶特征学习的有效性, 文中将学得的特征直接用于船舶分类任务, 在MARVEL数据集上进行了实验研究。
3.2 基于Faster R-CNN的海面目标检测
在海面目标检测阶段, 采用在通用场景的目标检测任务上表现优异的Faster R-CNN[6]模型, 如图4所示, 该模型由用于特征提取的backbone (基础网络)、用于生成感兴趣区域(region of interest, ROI)的RPN、生成最终检测结果的ROI -Head三部分组成, 其中ROI-Head包括分类和定位2个分支。
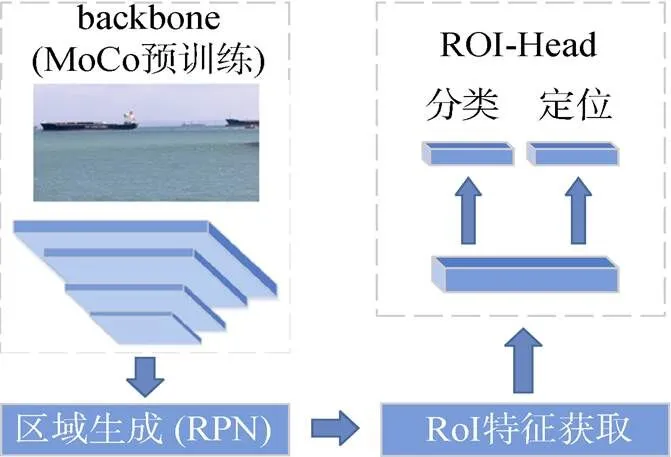
图4 基于Faster R-CNN的海面目标检测框架
backbone由深度卷积神经网络构成, 将输入图像映射为深层特征图, 该部分通常在Image- Net[17]数据集上进行预训练, 但由于其中的海洋样本较少, 直接用于海面目标检测效果不佳。文中模型中的backbone部分采用第1阶段自监督船舶特征学习训练所得的特征提取网络参数进行初始化, 为目标检测模型尽可能多地提供海洋环境及船舶相关的先验知识, 然后在训练模型其他部分的同时对backbone进行参数微调。
RPN网络作用于特征图之上, 以预设的锚点为基准, 输出预测框相对于锚点的偏移量, 从而生成一系列候选框。通过整合特征图与候选框信息, 即可获取每个感兴趣区域的特征, 文中采用ROI-Align(ROI对齐)方法代替ROI-Pooling(ROI池化)方法来实现该过程。此外, 在模型训练过程中, 对分类任务和定位任务分别采用交叉熵损失函数和Smooth L1损失函数。
此外, 考虑到SMD数据集中各类目标样本分布严重不平衡, 为更好地验证文中所提出的自监督预训练方法的有效性, 进行了不区分类别的海面目标检测, 即将图片中的所有目标均归类为“目标”。
4 实验验证与结果分析
为验证提出的基于自监督表征学习的海面目标检测模型(MoCo+Faster R-CNN)的有效性, 文中借助于现有的海洋数据集MARVEL和SMD进行了大量实验。
4.1 实验设置
在自监督船舶特征学习阶段, 模型中的编码器均采用ResNet-50网络, 利用MARVEL数据集中的图片数据(不使用其对应的标签)进行模型训练。为明确样本量对自监督船舶特征学习效果的影响, 分别使用14万样本和40万样本进行实验。为量化自监督船舶特征学习效果, 在MARVEL数据集用于分类任务的14万样本上进行了船舶分类实验, 将学习到的特征直接用于船舶分类, 即在固定特征提取网络的情况下以有监督的方式训练了一个线性分类层。
在海面目标检测阶段, 模型的backbone部分使用上一阶段训练的ResNet-50进行模型初始化, 即采用ResNet-50+Faster R-CNN框架。在SMD数据集上进行目标检测模型的训练与测试, 采用和Moosbauer等[9]相同的数据集划分, 将数据集train和val部分视为训练集, 而后在test数据集上进行模型测试。在测试阶段选择平均准确率(average precision, AP)、平均召回率(average recall, AR)和f-分数(f-score)作为评分标准, 分别在交并比(intersection over union, IOU)阈值为0.3和0.5的条件下进行测试。
文中所有实验均在Ubuntu 16.04.10系统中进行, 其中船舶特征学习和海面目标检测部分均使用8块Nvidia Tesla V100显卡, 16个CPU; 船舶分类实验部分使用4块Nvidia GTX 1080Ti显卡, 8个CPU。虽然在模型训练阶段所需的计算资源较多, 但在模型测试阶段, 在单块Nvidia GTX 1080Ti 显卡上仅需约10 ms即可完成单张图片船舶分类, 200 ms内可完成单张图片海面目标检测, 所需计算资源较少且耗时较短。
4.2 实验结果与分析
文中采用MoCo自监督学习算法在MARVEL数据集上进行船舶特征学习, 并在此基础上训练线性分类器完成了对26类船舶的分类任务。表1为MARVEL数据集上船舶分类准确率(acc), 可以看出:
1) Res50_MoCo_14代表利用MARVEL数据集中14万样本进行自监督特征学习, 并将学到的特征用于船舶分类;
2) Res50_MoCo_40代表利用MARVEL数据集中40万样本进行自监督特征学习, 并将学到的特征用于船舶分类;
3) Res50_Sup代表利用MARVEL数据集中14万样本以有监督的方式训练船舶分类模型。
实验过程中自监督船舶特征学习和有监督船舶分类模型均训练50个epoch, 前者额外训练一个线性分类层。
表1中第2列数据表明, 利用自监督特征学习学到的特征进行船舶分类, 可以达到60%左右的分类准确率, 虽然相比于有监督船舶分类还有一定差距, 但足以说明借助于基于MoCo的自监督学习算法可以实现对船舶目标的有效表征。表2是采用Res50_MoCo_40时MARVEL数据集船舶分类具体实验结果。
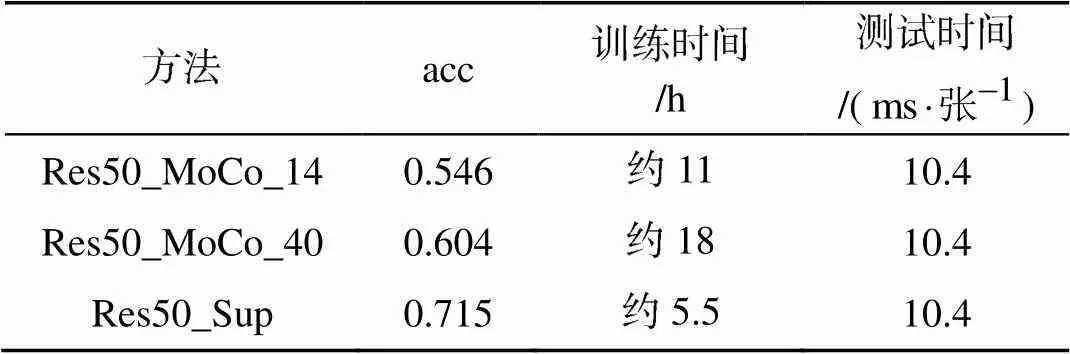
表1 MARVEL数据集船舶分类结果
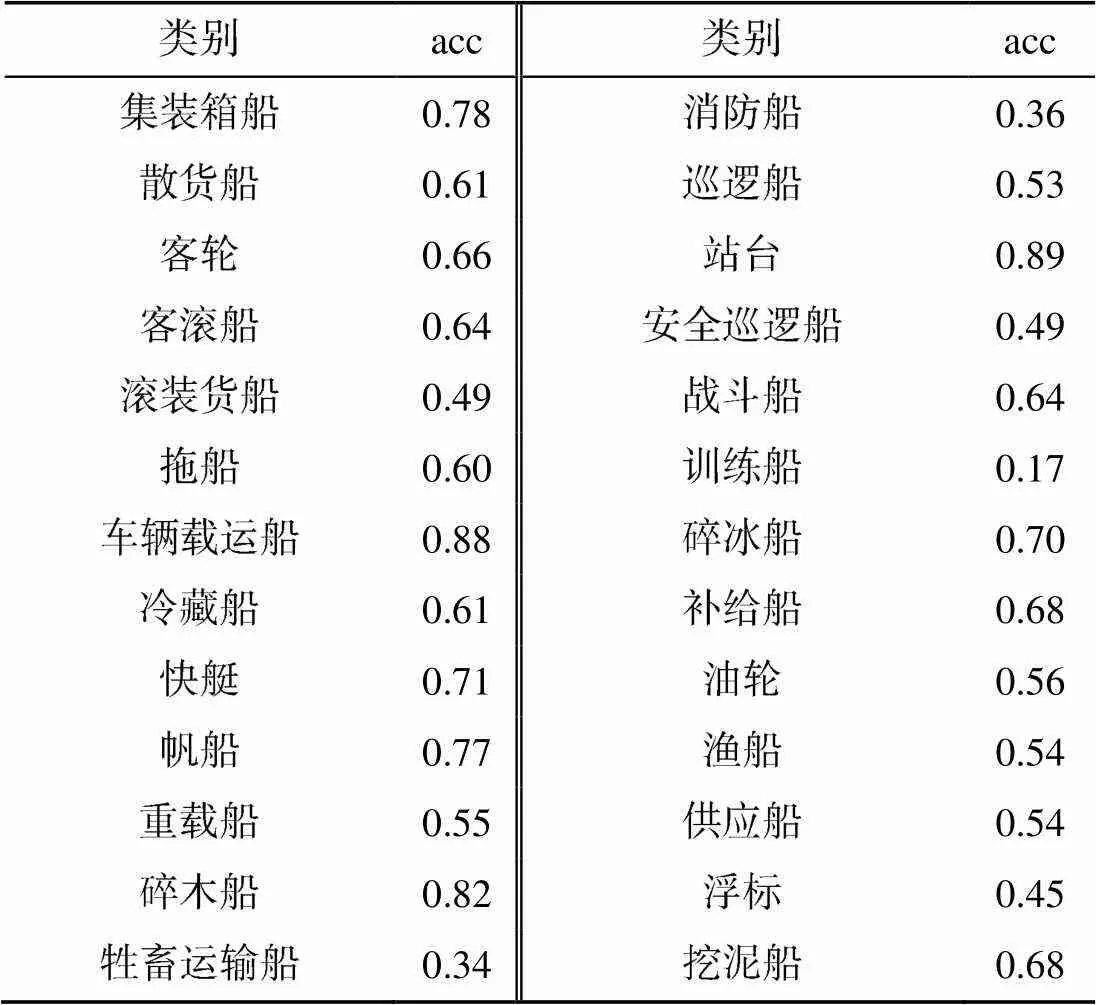
表2 MARVEL数据集船舶分类准确率
由表1数据可以看出, 在模型训练阶段, 相比于有监督方法, 在基于MoCo的船舶特征学习基础上进行船舶分类需要更长的训练时间, 但远低于人工标注大规模数据集所需的时间消耗; 而在测试阶段, 由于二者采用相同的模型结构, 因而时间消耗基本一致, 因此在无标签大规模数据集上进行船舶特征学习来服务于船舶分类、海面目标检测等下游任务是可行的。
文中利用Faster R-CNN框架, 在SMD数据集上进行了不区分类别的目标检测, backbone均采用ResNet-50, 但对其采取不同的预训练方式。
1) Res50_Sup_14_FRCNN: 利用MARVEL数据集中14万样本及其标签对ResNet-50进行有监督预训练。
2) Res50_MoCo_14_FRCNN: 采用MoCo特征学习方法, 利用MARVEL数据集中14万样本对ResNet-50进行自监督预训练。
3) Res50_MoCo_40_FRCNN: 采用MoCo特征学习方法, 利用MARVEL数据集中40万样本对ResNet-50进行自监督预训练。
表3和表4分别为IOU阈值设置为0.3和0.5时的实验结果, 其中Res101_MRCNN和Res101_ FRCNN为Moosbauer等[9]采用有监督backbone预训练方法进行海面目标检测的实验结果, DCT (discrete cosine transform)-based GMM(Gaussian mixture model)为Zhang等[23]采用传统的海天线检测-背景建模-背景去除方法的实验结果。
表3和表4中的Res50_Sup_14_FRCNN和Res50_MoCo_14_FRCNN两行数据可以说明, 无论IOU阈值的取值如何, MoCo+Faster R-CNN方法在海面目标检测任务中的表现更好。具体来说, 在训练参数基本一致的情况下, 相比于有监督backbone预训练的方法, 文中将自监督表征学习用于backbone网络预训练, 在代表检测准确率的AP评分和代表检测整体效果的f-score评分上均超过了Res50_Sup_14_FRCNN。
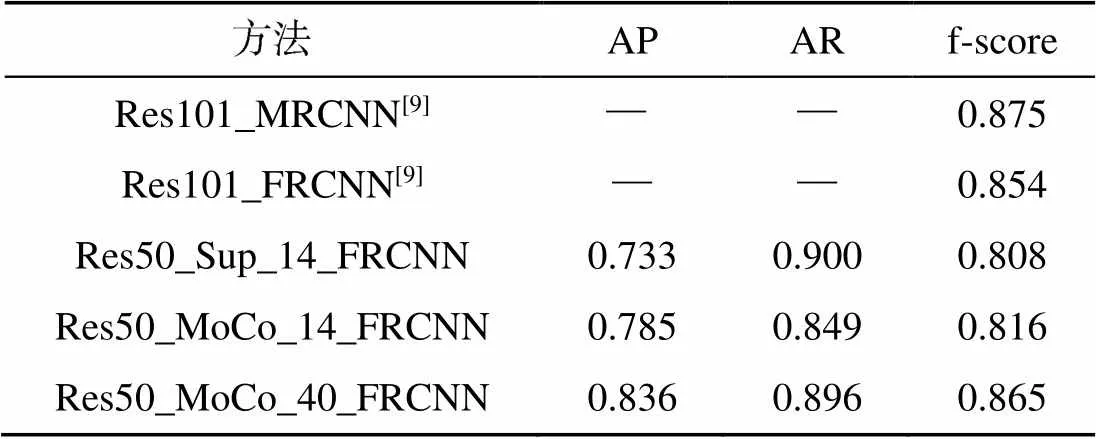
表3 SMD数据集目标检测结果(IOU_thrs = 0.3)
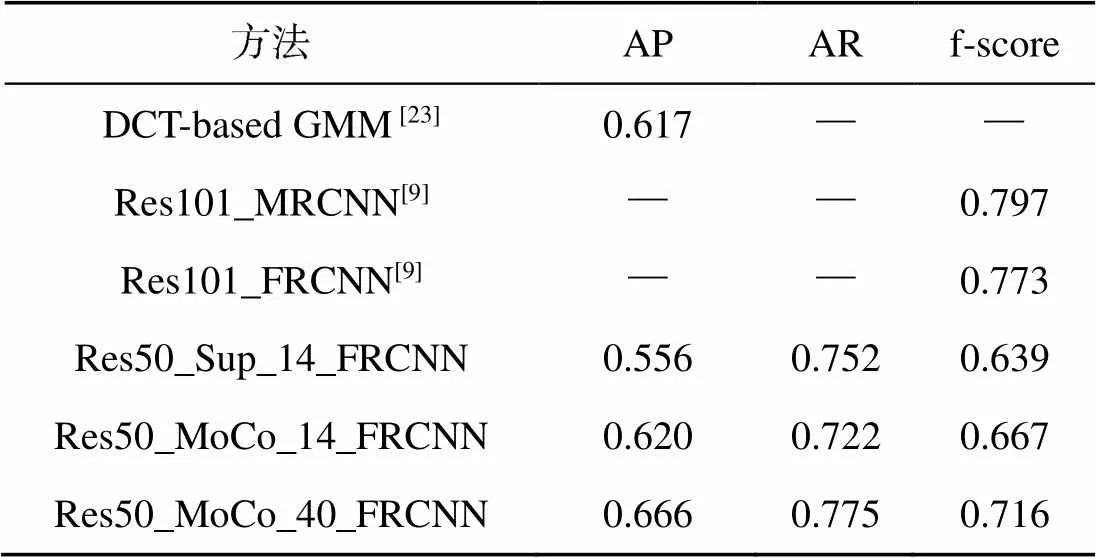
表4 SMD数据集目标检测结果(IOU_thrs = 0.5)
表3和表4中的Res50_MoCo_14_FRCNN与Res50_MoCo_40_FRCNN两行数据表明, 随着用于自监督船舶特征学习样本量的增加, 海面目标检测效果全面提升, 尤其是在IOU阈值设为0.3时, 检测效果超过了使用有监督预训练ResNet- 101网络作为backbone并引入特征金字塔(fe- ature pyramid network, FPN)[24]的Res101_ FRCNN方法(f-score分别为0.865和0.854)。由此可以说明, 当无标签海洋数据样本的样本量足够大时, MoCo+Faster R-CNN海面目标检测方法可以取得与采用有监督backbone预训练的方法相当或更好的检测效果。
此外, 表4的实验数据表明MoCo+FRCNN海面目标检测方法的检测效果优于传统的DCT- based GMM[20]方法, 也进一步证明了开展基于深度学习的海面目标检测研究的必要性。
5 结束语
文中将自监督表征学习引入海面目标检测领域, 采用MoCo方法在大规模无标签海洋数据上进行海面目标特征学习, 而后将学习到的特征用于海面目标检测任务。实验结果表明, 该方法可以取得较好的海面目标检测效果, 突破了大规模有标注海面目标数据集缺乏对开展基于深度学习的海洋智能感知研究的限制。但由于目前可用的海面目标检测数据集样本极度不平衡, 文中研究未能实现对海面目标的多分类, 如何克服样本不平衡问题, 实现多分类海面目标检测将是下一步的工作重点。
[1] Lin T Y, Maire M, Belongie S, et al. Microsoft Coco: Common Objects in Context[C]//European Conference on Computer Vision. Zurich: ETH, 2014: 740-755.
[2] Everingham M, Van G L, Williams C K I, et al. The Pascal Visual Object Classes(VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[3] Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-time Object Detection[C]//Procee- dings of The IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[4] Liu W, Anguelov D, Erhan D, et al. Ssd: Single Shot Multibox Detector[C]//European Conference on Computer Vision. Amsterdam: Springer, Cham, 2016: 21-37.
[5] Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[C]//Proceedings of The IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2980-2988.
[6] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Net- works[C]//Advances in Neural Information Processing Sy- stems. Montreal. Montreal: NIPS, 2015: 91-99.
[7] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//Proc- eedings of The IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
[8] Shin H C, Lee K I, Lee C E. Data Augmentation Method of Object Detection for Deep Learning in Maritime Image[C]//2020 IEEE International Conference on Big Data and Smart Computing(BigComp). Busan: IEEE, 2020: 463-466.
[9] Moosbauer S, Konig D, Jakel J, et al. A Benchmark for Deep Learning Based Object Detection in Maritime En- vironments[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Long Beach: IEEE, 2019: 916-925.
[10] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of Deep Bidirectional Transformers for Language Under- standing[EB/OL]. ArXiv, (2019-05-25)[2020-09-07]. https: //arxiv.org/abs/1810.04805?context=cs.
[11] Wu J, Wang X, Wang W Y. Self-supervised Dialogue Le- arning[EB/OL]. ArXiv, (2019-06-30)[2020-09-07]. https: //arxiv.org/abs/1907.00448.
[12] Song K, Zhang W, Lu W, et al. Visual Object Tracking Via Guessing and Matching[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 30(11): 4182- 4191.
[13] Li P, Chen B, Ouyang W, et al. Gradnet: Gradient-guided Network for Visual Object Tracking[C]//Proceedings of the IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 6162-6171.
[14] Lan X, Zhang W, Zhang S, et al. Robust Multi-modality Anchor Graph-based Label Prediction for RGB-infrared Tracking[J]. IEEE Transactions on Industrial Informatics, 2019. DOI: 10.1109/TII.2019.2947293.
[15] Kingma D P, Welling M. Auto-encoding Variational Ba- yes[EB/OL]. ArXiv, (2014-05-01)[2020-09-07]. https:// arxiv.org/abs/1312.6114.
[16] Burda Y, Grosse R, Salakhutdinov R. Importance Weigh- ted Autoencoders[EB/OL]. ArXiv, (2015-11-07)[2020-09- 07].https://www.arxiv-vanity.com/papers/1509.00519/.
[17] Maaløe L, Fraccaro M, Liévin V, et al. Biva: A Very Deep Hierarchy of Latent Variables for Generative Modeling [C]//Advances in Neural Information Processing Systems. Vancouver: NIPS, 2019: 6551-6562.
[18] He K, Fan H, Wu Y, et al. Momentum Contrast for UnsuperVised Visual Representation Learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual: IEEE, 2020: 9729-9738.
[19] Chen T, Kornblith S, Norouzi M, et al. A Simple Fra- mework for Contrastive Learning of Visual Representations[EB/OL]. ArXiv, (2020-07-01)[2020-09-07]. https:// arxiv.org/abs/2002.05709
[20] Deng J, Dong W, Socher R, et al. Imagenet: A Large-scale Hierarchical Image Database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248-255.
[21] Gundogdu E, Solmaz B, Yücesoy V, et al. MARVEL: A Large-scale Image Dataset for Maritime Vessels[C]//Asian Conference on Computer Vision. Taipei: AFCV, 2016: 165-180.
[22] Prasad D K, Rajan D, Rachmawati L, et al. Video Processing from Electro-optical Sensors for Object Detection and Tracking in a Maritime Environment: a Survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(8): 1993-2016.
[23] Zhang Y, Li Q Z, Zang F N. Ship Detection for Visual Maritime Surveillance from Non-stationary Platforms[J]. Ocean Engineering, 2017, 141: 53-63.
[24] Lin T Y, Dollár P, Girshick R, et al. Feature Pyramid Networks for Object Detection[C]//Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2117-2125.
Maritime Object Detection Method Based on Self-Supervised Representation Learning
ZHANG Qian1, ZHANG You-mei2, LI Xiao-lei1, SONG Ran1, ZHANG Wei1
(1. School of Control Science and Engineering, Shandong University, Jinan 250061, China; 2. School of Mathematics and Statistics, Qilu University of Technology (Shandong Academy of Sciences), Jinan 250353, China)
To improve the perception and monitoring ability of marine unmanned equipment, boosting the performance of maritime object detection is critical. However, complex sea environments and limited sensors make it difficult to collect high-quality samples for a large-scale maritime dataset. This results in a dearth of large-scale sea surface target datasets, which in turn hampers the development of maritime object detection based on deep earning. To address this problem, this study introduces self-supervised representation learning into the field of maritime object detection. Specifically, a momentum-contrast based algorithm is proposed to conduct representation learning of ships, where the characteristics of ship targets are learned from large-scale unlabeled maritime data. This provides prior knowledge for subsequent maritime object detection based on Faster R-CNN. Experimental results show that with the aid of model pre-training on a large-scale unlabeled dataset in a self-supervised manner, the proposed maritime object detection method through self-supervised representation learning has a performance comparable with those that employ supervised model pre-training. The proposed method can thus overcome the limitations caused by an inadequate number of labeled maritime samples.
marine unmanned equipment; target detection; self-supervised representation learning; deep learning
张倩, 张友梅, 李晓磊, 等. 基于自监督表征学习的海面目标检测方法[J]. 水下无人系统学报, 2020, 28(6): 597-603.
TJ630; TP391.4; TP181
A
2096-3920(2020)06-0597-07
10.11993/j.issn.2096-3920.2020.06.002
2020-09-07;
2020-11-12.
国家自然科学基金项目(61991411).
张 倩(1997-), 女, 在读硕士, 主要研究方向为模式识别、计算机视觉.
(责任编辑: 杨力军)
