面向长答案的机器问答研究
2021-01-08朱运昌庞亮兰艳艳程学旗
朱运昌,庞亮*,兰艳艳,程学旗
(1.中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190;2.中国科学院大学, 北京 100049)
0 引言
随着互联网的快速发展,基于关键词的传统搜索引擎由于准确率低、存在冗余信息等缺陷,而机器开放域问答系统允许用户使用自然语言问句进行信息查询,能够对用户输入的问句进行理解给出更精确的答案。因此开放域问答系统已成为自然语言处理中的重要研究课题。特别是自新冠肺炎疫情暴发以来,国家各级部门相继出台了一系列惠民惠企政策,为了更好地帮助各行业从众多繁杂的政策中准确找到与自己相关的信息,政策型机器开放域问答受到了极大关注。
作为机器开放域问答中的重要技术,抽取式阅读理解的形式为给定一篇文档和一个问题,模型从文本中找出一个片段去回答此问题。得益于深度学习的快速发展,Match-LSTM[1]、BiDAF[2]和QANet[3]等模型纷纷涌现,抽取式阅读理解已经取得了长足进步。特别是BERT[4]出现之后,机器在SQuAD[5]等数据集上的表现甚至超过了人类。然而,现有的抽取式阅读理解模型和数据集大多只关注如命名实体之类的短答案抽取,但政策型问答中的答案却通常是长度很长的政策内容,这些长答案往往也对应着更长的输入文档。面对长文档长答案的场景,现有模型往往会遇到输入长度超越极限和长答案抽取不完整的挑战。
首先,任何模型实际中都存在一个输入文本长度的极限,当输入文本长度超过这个极限后,模型就无法正常的工作。对于当下最流行的BERT来说,其基于的Transformer[6]结构是通过位置嵌入(position embedding)来体现不同词语的位置信息的,有限的位置嵌入的数量就限制了输入序列的最大长度;对于基于循环神经网络(recurrent neural network, RNN)[7]的阅读理解模型来说,虽然其理论上不存在输入长度的极限,但因输入序列过长而出现的长距离依赖等问题也会使模型的性能出现剧烈下滑。
此外,虽然可以利用图1所示的预处理方法通过滑动窗口的方式将长文档切分成多个文档块来保证长文档以多次输入的形式输入到抽取式阅读理解模型之中,进而解决输入长度超越极限的问题,但是文档中的潜在答案(尤其是长答案)仍会不可避免地被切分到不同文档块,即使在最理想情况下模型精准地抽取出了每个文档块中存在的部分答案,但这些部分答案与真实答案在召回率上仍却存在着巨大差距。

● 问题:疫情期间,如何安排经费预算?● 答案长度:446● 文档块:1) [1, 501]:关于进一步做好新型冠状病毒感染肺炎疫情防控经费保障工作的通知……全力支持疫情防控工作,坚决打赢疫情防控阻击战。2) [502, 986]:现就进一步做好疫情防控经费保障工作通知如下:一、明确经费保障目标……二、统筹安排经费预算近期,按照党中央、国务院统一部署……切实履行好经费保障职能。3) [987, 1483]:年初卫生防疫经费预算安排不足的 ……对基层财政“三保”经费的保障力度也要切实加强。三、加快调度拨付资金……垫付等措施,优先保障疫情防控资金拨付。……6) [2346, 2581]:七、切实做好信息上报和新闻宣传工作……坚决打赢疫情防控阻击战。 财政部 2020年1月31日
为了克服这些挑战,本文注意到抽取式问答的目标只是为了找到更精准的答案边界位置,其对与问题无关的片段和答案内部冗长的内容其实并不特别关心。因此,在经过对整个文档进行过分块阅读之后,问答系统对整个上下文及与问题相关的候选答案区域已经有了初步了解,这时问答系统可以就放心地排除与问题无关的片段,甚至可以跳过候选片段中间的冗长内容,只考虑候选答案的边界并对它们进行整合就可以得到一个更完整精确的答案。
基于这个思想,本文提出了一个答案边界整合(BoundaryQA)框架,该框架提供了三种答案边界整合策略:局部片段合并策略是利用启发式规则来局部地合并那些因文档块切分而被分开的两个邻近候选答案片段,从而得到更完整的答案;全局边界重选策略是额外训练一个答案边界重选模型,让此模型自己学习出如何从所有候选答案边界中全局地重新选择出一对最好的答案开始边界和结束边界;跳跃式重阅读策略则是首先基于基础抽取式阅读理解模型预测出的多个候选答案生成一段仅包含候选答案边界附近上下文的摘要,最后训练一个精读模型让其重读这个包含全局候选答案和边界局部上下文信息的简短摘要并从中抽取出更准确的答案。
为了验证BoundaryQA框架的有效性,本文在具有明显的长答案长文档特点的疫情政策问答数据上进行了实验。实验结果表明框架中的三种策略均能够在整体ROUGE-L[8]指标提升的基础上,明显提升长答案抽取的ROUGE-L。此外,实验结果还表明ROUGE-L的提升主要源自召回率的提升,这说明BoundaryQA框架有效缓解了长答案抽取不完整的问题。
作为机器开放域问答的重要组成部分,抽取式阅读理解技术直接决定了最终答案的准确程度。
0.1 基于注意力机制的抽取式阅读理解模型
注意力机制[9]很早就被提出,在处理机器阅读理解任务时,基于神经网络的模型几乎都直接或间接地使用了注意力机制[10]。简单来说注意力机制就是在编码或者解码的阶段为序列的每个位置生成一个权重。权重大小代表了当前位置对最终预测结果的重要性。
在抽取式阅读理解任务中,根据注意力机制的结构可以将这些模型分为单路注意力模型、双路注意力模型和自匹配注意力模型。
单路注意力模型被用来模拟人做阅读理解时带着问题去阅读的过程,先看问题再去文本中有目标地阅读以寻找答案。通过结合问题和文档二者的信息生成一个关于文档各部分的注意力权重,进而对文档信息进行加权,该注意力机制可以更好地捕捉文本段落中与问题相关的信息。Hermann等[11]最先将基于注意力机制的深度神经网络模型用于机器阅读理解任务,即以问题为上下文计算出文档中每个单词的权重并生成文档的最终表示。在此基础上,Chen等[12]分别对注意力函数做了一些改进,但它们在本质上并没有摆脱单路注意力的框架。
不同于单路注意力模型只在文档上使用注意力机制,双路注意力模型同时在文档和问题上使用了注意力机制。Cui等[13]按列进行注意力计算,获得“文档-问题”注意力矩阵,然后采用启发式规则,按行进行合并,得到文档的注意力。Seo等[2]则是首先对相似度矩阵按列使用注意力机制,得到问题的注意力表示,再按行使用注意力机制,得到文档的注意力表示,然后将二者进行融合,得到文档的最终表示。双路注意力模型由于对文档和问题之间的相似度进行了更加细粒度的建模,因此包含更加丰富的细节信息,其性能往往比单路注意力模型好。
上述两种注意力机制可以被认为是带着问题去阅读文档或是带着文档去阅读问题。这些注意力机制过于依赖先验信息,导致只重视文档中与问题相关度较高的局部信息,丢失了文档本身强调的重点信息。自匹配注意力模型则会反复阅读文档并找出重点。基于这一点,Wang等[1]提出了单路注意力模型和自匹配注意力模型结合的网络结构,Clark等[14]则是通过在双路注意力模型之后加入自匹配注意力模块从而使模型性能获得了进一步提升。
0.2 基于预训练模型的抽取式阅读理解
随着预训练模型近年来在自然语言处理中的应用与发展,抽取式阅读理解不再单纯地依靠网络结构与注意力机制的方法。预训练语言模型的发展推动了机器阅读理解的进步,在某些数据集上已经超越了人类的表现。
预训练模型前期通过语言模型在大量自然语言上进行自监督训练,如掩码预测、句子关系的预测、以及自然语言的多任务训练等。通过在大量文本上进行预训练,得到强健的语言模型,可以捕获句子间更深层次的关联关系。在做机器阅读理解任务时,只需要设计适合具体任务的网络拼接到预训练模型网络后进行微调即可。
其中,ELMO[15]将通过预训练得到的字词表征以及网络结构信息保存,在处理阅读理解任务时,其学到的字词动态嵌入信息就会被应用到下游网络中。BERT[4]引入Transformer编码模型,通过掩码语言模型和下一句预测任务来进行预训练,获得了更多的语言表征。此外,ENRIE[16]引入了外部知识到预训练过程,MTDNN[17]在预训练阶段进行多任务学习。XLNet[18]使用排列语言模型,加入双注意力流机制。RoBERTa[19]使用动态的掩码替换静态掩码,去除下一句预测任务,并使用了更大的批大小和更多的训练语料。BERT-WWM[20]引入整词掩码策略,将BERT对字的掩码改为对整词的掩码。ALBERT[21]和DistilBERT[22]通过对模型进行蒸馏获取小型化模型,方便模型的部署。
1 机器开放域问答
机器开放域问答的形式化定义为:给定一个文档集P={P1,P2,…,P|P|},对于一个问题Q=[q1,q2,…,qm],系统需要从P中找到能够回答Q的文档P=[p1,p2,…,pn],并从P中预测出答案片段A=Pstart:end,1≤start≤end≤n,其中start和end分别为答案A在文档P中的开始和结束边界位置。
机器开放域问答通常包括相关文档检索、候选答案抽取和最终答案决策三个步骤。由于本文主要期望通过候选答案边界整合的方式预测出更完整的长答案,即第三个步骤,并且信息检索和抽取式阅读理解技术已经较为成熟,本章将只简要介绍前两个步骤所采用的现成的技术方案。
相关文档检索的目标是根据问题Q从文档集P中检索出能够回答问题的最佳文档P*。为了简单起见,本文采用经典的BM25算法作为文档检索器,并假设排名最靠前的文档P即为最佳文档。
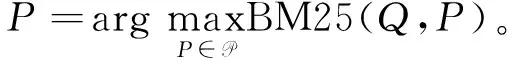
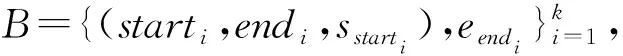
2 最终答案决策:BoundaryQA
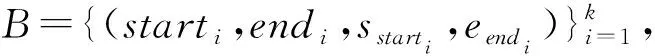
由于抽取式问答的目标只是为了找到更精准的答案边界位置,其对与问题无关的片段和答案内部冗长的内容其实并不特别关心。尤其是在分块阅读文档并得到k个候选答案后,问答系统对整个上下文及与问题相关的候选答案区域已经有了初步了解,因此这时问答系统可以就放心地跳过与问题无关的片段甚至候选片段中间的冗长内容,只对候选答案边界进行整合,这样,文档和答案的长度就不再可以影响最终答案的决策,问答系统也就可以决策出一个更完整精确的答案。接下来,本章将介绍基于这个思想的BoundaryQA框架中所提供的三种不同答案边界整合策略。
2.1 局部片段合并
由于模型在训练阶段学习过从文档块中抽取部分答案,因此,如果模型学得好的话,模型就应该能把潜在答案散布在各个文档块中的部分答案抽取出来作为候选答案,并且这些候选答案片段应该是邻近的。基于这个见解,本文首先提供了一种朴素的局部片段合并策略。
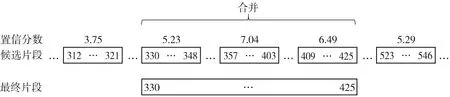
如算法1及图2所示,此策略先找到置信分数最高的候选答案作为最终答案的基础,接着以基础部分为中心分别局部地向前、向后扩展最终答案。具体地,如果基础部分最邻近的候选片段与基础部分的距离小于邻近距离阈值dist,并且该片段的置信分数与最高置信分数的差值小于分数差距阈值diff,此策略就将最终答案向前或向后扩展到该片段的开始位置或结束位置,如此循环直到无法继续与邻近片段合并为止。得到算法1输出的start和end后,最终答案为Pstart:end。

算法1:局部片段合并输入:候选答案集B邻近距离阈值dist分数差距阈值diff输出:最终答案区间[start,end]1. mid←argmaxiBi,3+Bi,42. score←Bmid,3+Bmid,43. 以结束、开始边界对B1:mid-1升序排序4. 以开始、结束边界对Bmid+1:k升序排序5. l←mid6. start←B_(l,1)7. while |start-Bl-1,2| 作为一种启发式策略,邻近片段合并策略的性能与两个阈值的设置密切相关,这严重依赖人类的经验。此外,邻近片段合并策略只能作用在置信度最高的候选答案周围的局部区域,如果上一步的阅读理解模型抽取的片段偏差较大或者对片段的打分方差较大,那么邻近片段合并法就很难奏效。为了克服这些缺点,本文继而提供了一种可训练的全局边界重选策略。 为了避免调节阈值超参的麻烦,该策略额外训练一个答案边界重选模型,让模型自己学习出如何从所有候选答案边界中全局地重新选择出一对最好的答案开始和结束边界。 图3展示了答案边界重选模型的结构,该模型以候选边界的特征矩阵F=[f1,f2,…,f2k]∈6×2k为输入,其中fi=[posi,n-posi,posi-posi-1,posi+1-posi,sposi,eposi]表示按位置排序后的第i个候选边界的特征向量,该特征向量的前两维分别表示这个边界在文档P中的正向位置和反向位置,中间两维分别表示此边界与相邻的前一个边界和后一个边界的相对距离,最后两维分别表示此边界作为答案开始边界和结束边界的分数。为了更好地建模边界顺序,特征矩阵先被送入了一层序列建模常用的双向GRU[23],接着双向GRU输出的隐层表示又被送入了一层Transformer[6]以通过自注意力机制来让所有候选边界更好地全局交互,至此就可以得到所有候选边界最终的嵌入表示b×2k。 H′=Transformer(BiGRU(F))。 虽然全局边界重选策略克服了局部片段合并策略只能局部交互的缺点,但是这两种方法都只利用了候选边界这些点的信息,并没有利用边界周围的上下文信息。另外,如果想对上一步预测出的存在偏差的候选边界进行修正,前两种方法都无法做到,因为前两种方法本质上都是从已有的候选边界中选择,并不能预测出新的修正后的边界。 为了克服这个缺陷,本文进一步提出了采用重新阅读的策略来修正最终答案的边界。然而,如果只是简单重阅读,不免又会陷入长答案长文档的境地。不过,经过第一遍阅读之后,阅读理解模型已经抽取出了多个候选答案片段,也就是说,只有这些候选片段及其附近上下文是与问题最相关的内容,因此,我们可以放心地跳过其他不相关内容,只针对性地精读由候选片段及其附近上下文构成的摘要就可以了。但是,对于候选片段很长的情况,这个摘要还是会太长从而导致精度模型无法一次性读完。考虑到抽取式阅理解只关注寻找答案的边界,长答案中间冗长的内容除了能提供一些上下文信息,在最后答案边界选择时并不会受到关注,因此我们完全可以舍弃掉这些不太重要的上下文信息来换取更精简的摘要。 具体地,为了得到精读模型,我们利用算法2根据上一步阅读理解模型抽取的候选答案生成出训练集中所有相关文档的摘要,图4展示了这种摘要的一个示例,然后以此构造出新的精读训练样本,微调上一步中的阅读理解模型。在预测时,我们首先找到摘要中的置信分数最高片段的开始和结束边界1≤start′≤end′≤|S|,然后根据映射关系找到其在原始文档中的位置1≤start≤end≤n,得到最终答案为Pstart:end。 图2 局部片段合并示意图Fig.2 Schematic diagram of local span merging 图3 全局重选模型的网络结构Fig.3 Global reselection neural network 问题:疫情期间,如何安排经费预算?摘要:...:一、明确经费保障目标 各级财政部门要按照习近 … 好疫情防控经费保障工作。确保人民群众不因担心费… 统筹安排经费预算 近期,按照党中央、国务院统一部署… 时,切实履行好经费保障职能。年初卫生防疫经费预算安排不 … 经费的保障力度也要切实加强。三、加快调度拨付资金... 本章通过实验对我们提出的BoundaryQA框架进行验证,并通过与基线方法对比来验证本文提出的三种答案边界整合策略,最后还分析了上下文窗口大小对跳跃式重阅读的影响。 算法2:针对问题的摘要生成输入:候选答案集B文档P=[p1,p2,…,pn]上下文窗口大小w输出:摘要S1. I←0n2. for all(sp,ep,ssp,eep)∈B do3. Isp-w:sp+w←12w+14. Iep-w:ep+w←12w+15. S←[]6. for t←1 to n do7. ifIt=1 then8. S.append(p_t) 数据集:本文利用DataFountain疫情政务问答助手比赛提供的数据(1)https:∥www.datafountain.cn/competitions/424/datasets作为本文实验的数据集,该数据共有8 000篇文档、4 999条问答对,经过随机划分后,训练集包含2 999条问答对,验证集和测试机各包含1 000条问答对。表1展示了根据参考答案长度对整个数据集进行的统计,我们可以看到不同于以往的抽取式问答,政策型问答的答案长度普遍较长,平均长度达到了58,最大长度甚至达到了2 131。 评价指标:由于抽取式阅读理解常用的F1指标不太适用于评价答案较长的答案,本文采用ROUGE-L[8]评价答案的正确性,其考察预测答案A和参考答案A′的最长公共子序列(LCS)上的准确和召回情况,具体计算方式如下: 实验细节:基于Elasticsearch搭建文档检索器,基于谷歌发布的中文预训练BERT-BASE训练阅读理解模型。通过在验证集上调节超参,候选答案数量k设为5,算法1中的邻近距离阈值dist设为12,分数差距阈值diff设为2.3,算法2中的上下文窗口大小w设为64,全局边界重选策略中的候选边界嵌入向量维度b设为24。 本文实验的基线方法[4]除了最直接选取分数最高的候选答案作为最终答案,其他设置均与Bound-aryQA相同。表2展示了基线方法及不同答案边界整合策略在测试集上的表现,其中不同列展示了方法在不同参考答案长度的表现。我们可以发现,当参考答案长度变得比较大时,基线方法的性能下降明显,其中召回率Rlcs下降的幅度更大,这说明随着答案长度的增加,阅读理解模型越来越难抽取到完整的答案。 相比基线方法,本文提出的三种整合方法均能在整体ROUGE-L提升的基础上,对长答案抽取的ROUGE-L提升更大,另外值得注意的是,ROUGE-L的提升幅度始终与召回率Rlcs的提升幅度一致,这表明ROUGE-L的提升主要源自召回率的提升,同时也说明BoundaryQA框架有效缓解了长答案抽取不完整的问题。 三种策略对比来看,局部片段合并策略对参考答案长度稍长([4,16))的样本表现最好;全局边界重选策略对参考答案长度较长([16,256))的样本表现出众;而跳跃式重阅读法不仅带来的提升最大,其在任何答案长度区间的表现也都不俗,这充分体现了结合局部和全局信息的优势。 表3展示了采用不同上下文窗口大小的跳跃式重阅读策略在验证集上的表现,可以发现,大的上下文窗口能带来更高的召回率,但是太大的窗口会导致答案的精确率降低进而导致ROUGE-L下降,因此,一个适中的上下文窗口大小最为合适。 针对政策型问答场景中遇到的输入长度超越极限、长答案抽取不完整的挑战,本文提出了答案边界整合框架BoundaryQA,该框架提供了三种边界整合策略,其中局部片段合并策略局部地合并了那些因文档块切分而被分开的两个邻近候选答案片段;全局边界重选策略训练一个答案边界重选模型来全局地从所有候选答案边界中重新选择出一对最好的开始和结束边界;跳跃式重阅读策略则重新阅读了一段包含全局候选答案和边界局部上下文信息的简短摘要并从中抽取出更准确的答案。本文最后在真实疫情政策问答数据上进行了实验,验证了BoundaryQA框架的有效性。 表1 疫情政务数据集参考答案长度统计 表2 不同答案整合策略在测试集上的表现 表3 跳跃式重阅读策略采用不同上下文窗口大小在验证集上的表现 目前BoundaryQA框架在相关文档检索阶段中只采取了比较简单的BM25方法,未来的工作可以从检索角度切入,考虑如何根据简短的问题更好地检索到包含长答案的相关文档。2.2 全局边界重选
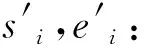
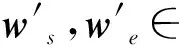
2.3 跳跃式重阅读


3 实验和分析

3.1 实验设置
3.2 实验结果
3.3 上下文窗口大小对跳跃式重阅读的影响
4 结论