基于视觉特征提取的强化学习自动驾驶系统
2020-12-22郑振华刘其朋
郑振华,刘其朋
(青岛大学复杂性科学研究所,山东 青岛 266071)
0 引言
随着人工智能技术的突破性发展,曾经只存在于科幻电影中的自动驾驶汽车也逐渐进入现实世界。自动驾驶汽车不仅可以把人类从枯燥的驾驶中解放出来,将精力投入到更有价值的活动中,还可以减少人为失误造成的交通事故。自动驾驶汽车不再是交通工具,而是移动的生活场所,它必将带来人类出行方式的根本性改变,进而导致人类社会的巨大变革。鉴于自动驾驶汽车可预见的影响力,各国政府陆续出台各种规章制度,推动这一技术的发展,同时提供了指导性的发展规划。尤其是2020年2月10日,中国科技部、工信部等11个部门联合印发《智能汽车创新发展战略》,提出到2025年,实现有条件自动驾驶的智能汽车达到规模化生产,实现高度自动驾驶的智能汽车在特定环境下市场化应用。面对巨大的商机,各国企业也在自动驾驶系统研发和推广中投入巨大的人力、财力。百度、华为等明星科技企业均发布了自动驾驶系统解决方案或智能芯片。在政府和企业的大力推动下,我们有理由相信,自动驾驶汽车在不远的将来必将进入我们的日常生活中。
从技术层面来讲,自动驾驶系统包含3个主要模块:感知、决策和控制。感知模块中,车辆通过传感器(包括摄像头、激光雷达、GPS、惯性导航单元等)感知周围环境和自身状态;决策模块中,车辆基于感知信息确定行驶路线和驾驶行为,例如是否变道、是否减速让行;控制模块中,进一步考虑车辆的物理限制,例如速度上限、车轮转角范围,安全可靠的执行决策命令。现有已公开的自动驾驶系统均采用了上述模块化的解决方案,分别设计实现上述相对独立的模块,最后整合起来完成自动驾驶任务[1-2]。模块化的系统架构的优点是可解释性比较强,因为大部分子任务(除了目标识别相关的任务)都是基于明确规则的。缺点是系统非常复杂,开发、维护成本较高。
目前基于神经网络的端到端自动驾驶系统逐渐引起学术界和工业界的关注。这类系统不再明确区分感知、决策和控制模块,而是将自动驾驶系统作为整体考虑,用神经网络完成从传感器信息到控制命令的映射。例如,Bojarski等人采用监督学习(Supervised Learning)的方式实现了端到端自动驾驶系统[3]。训练好的系统仅需要前置摄像头图像信息便可以得到最终的车辆转角控制命令,保证车辆沿给定车道行驶。为了训练车辆适应各种车道形状,监督学习方式需要人工采集大量训练数据,包括摄像头信息和对应的人类驾驶员的正确操作。可见,为了训练具有鲁棒性的自动驾驶系统,训练数据需要覆盖尽量多的驾驶场景。高质量训练数据的收集是监督学习中最重要也是最困难的部分之一。在监督学习中,自动驾驶系统学习的是给定环境中人类驾驶员的操作,它的学习效果上限就是人类驾驶员的操作水平,不会搜索更优的驾驶操作。
强化学习,尤其是基于神经网络的深度强化学习,由于在棋类、游戏类场景中超越人类的表现而获得巨大关注[4]。通过设定恰当的奖励机制,系统可以自动探索给定环境下对应的最佳动作,这种寻优的结果很可能超越人类的水平[5-6]。例如,在AlphaGo的训练中,研究人员首先基于人类棋谱采用监督学习的方式训练系统,使其对围棋游戏规则有初步理解,然后采用深度强化学习的方式让系统继续搜索可以获得更大收益的策略[5]。
近年来,强化学习在自动驾驶系统中的应用也越来越受到学界的关注。各类先进的强化学习算法被用于训练具有鲁棒性的自动驾驶系统。中国国内在这方面已有不少研究。例如,刘偲将DDPG(Deep Deterministic Policy Gradient)强化学习算法用于训练自动驾驶系统,在仿真平台上,训练好的车辆可以沿给定车道线行驶,验证了该方案的有效性[7]。张斌等人改进了DDPG算法,在训练过程中重点关注过往失败的训练数据,训练效果得到明显提升[8]。王丙琛等人采用人类驾驶数据对系统进行预训练,并加入LSTM(Long Short Term Memory)机制,提升了车辆对未来状况的预判,仿真测试表明,训练时间大大缩短,系统稳定性得到提升[9]。夏伟等人将强化学习算法DQN(Deep Q-Networks)用于自动驾驶系统,基于实际驾驶员数据对系统进行预训练,并加入了经验数据聚类采样过程,使用更少的训练数据,更高效的训练自动驾驶系统[10]。李志航采用Double DQN结合LSTM,在仿真平台获得了相比于传统DDPG更好的训练效果[11]。
上述研究中,强化学习的输入数据,即智能体观测到的环境状态均是低维传感器数据,包括车辆行驶方向与车道夹角、车辆与车道边缘距离、车身方向速度等,并不包括来自前置摄像头的视觉图像信息。这是由于图像本身维度过高,例如一个600×800像素的RGB彩色图像,维度为1 440 000。强化学习算法很难直接从这么高维度的数据中学习出与驾驶操作相关的信息。为了解决这一问题,Raffin等人提出了一种将图像特征提取与强化学习解耦的方案,首先对高维图像数据进行特征提取,在降低数据维度的同时保留原始数据中的关键信息[12]。Kendall将这一思想应用于自动驾驶中,设计了变分自编码器(VAE, Variational AutoEncoder)提取图像信息,然后将降维之后的特征送入DDPG算法进行强化学习训练。实车测试结果表明,只需要经过约30分钟的训练,车辆即可沿给定车道线自动行驶[13]。
Kendall等人的工作虽然实现了基于纯视觉感知的强化学习自动驾驶系统,但是没有考虑系统的泛化能力。所谓的泛化能力是指在一种环境中训练的系统可以应用到其他明显不同的环境中。如果自动驾驶系统泛化能力比较差,那么每次环境稍微变化都需要重新训练,这显然是不合适的。Bojarski等人的工作表明,车道保持任务中关键的信息就是车道线的位置[14]。受这一工作启发,本文对Kendall等人的工作做了两方面的改进:1)加入了车道线提取环节,将原始图像转化为只保留车道线信息的灰度图;2)采用训练效率更高、效果更好的SAC(Soft Actor-Critic)强化学习算法。
本文内容安排如下:首先给出系统的整体架构,然后依次介绍车道线提取环节、变分自编码器特征降维环节和基于降维特征的SAC强化学习环节,最后在仿真实验平台上测试系统的有效性和泛化能力。
1 自动驾驶系统设计
1.1 系统整体架构
本文设计的自动驾驶系统架构如图1所示,车辆首先通过前置摄像头获取道路图像数据。图像为RGB彩图,包含丰富的环境信息,但也包含与自动驾驶任务不相关的干扰信息,如天空、车道外侧地面等。为了提取关键的车道线信息,将彩色图转化成灰度图后,使用高斯滤波对灰度图进行平滑处理,去除高频噪声,再利用Canny算法[15]进行轮廓检测,只包含图像中物体的轮廓线条。之后利用掩膜提取图片中的感兴趣区域(ROI),即图片中的车道线。完成车道线提取工作之后,得到仅包含车道线信息的黑白二值图像,大小与原图相同。为了降低训练数据维度,用变分自编码器对图像进行特征提取,在极大降低特征维度的同时,保留图中的关键信息。此时,原图像变换为低维向量。随后,将低维特征作为观测状态放入SAC强化学习算法中进行训练。最终,训练好的系统将会根据输入决定相应的车辆操控策略,输出车辆的速度与转角命令,使得车辆保持在给定车道线内行驶。

图1 系统整体架构
1.2 车道线提取
不同道路环境中,路面颜色和质地、车道线形状、环境背景纹理可能差别很大。但是为了方便驾驶员辨认,车道线与路面在外观上一般有明显差异,例如采用比较醒目的颜色进行区分。基于这一观察,车道线可以通过计算机视觉算法提取出来。本文中采用Canny算法[15]进行车道线轮廓提取。
在处理图片时,先将RGB彩色图片转换成灰度图,虽然转换过程会损失颜色信息,但一般并不会妨碍车道线与路面的区分,依然可以保留原图中颜色变化的信息(此时变为灰度的变化),而且从三通道的RGB彩图变换到单通道的灰度图,维度的降低会加速后续图像的处理。本文采用OpenCV中的颜色转换函数,具体的灰度值与RGB值的变换公式为
GRAY=0.30R+0.59G+0.11B
其中,GRAY为灰度图中任意一点的灰度值,R、G、B分别为彩色图片中对应位置红、绿、蓝三通道的像素值,对三个颜色通道进行加权计算,得到相应的灰度值。
车道线提取的基本思想是通过灰度变化的幅度识别车道线轮廓。原图像中可能存在噪声点,而噪声点与周围灰度值有明显区别,可能影响对车道线轮廓的判断。因此,首先要对图像做平滑处理,降低噪声点的干扰。这里采用高斯平滑方法,也称为高斯模糊。在高斯平滑中,用一个权重矩阵w与图像中每一个像素点及其邻居做卷积,实际上就是令原图中每一个像素点取附近像素值的加权平均。
假如权重矩阵的行、列均为5,其中元素的坐标设定为
(1)
即原点在矩阵的中心位置。权重矩阵中(x,y)位置上的元素值为
(2)
为了保证权重矩阵和为1,还需要对其进行归一化。
结合式(1)、(2),并令σ=1,可以得到最终的权重矩阵为
(3)
将得到的高斯权重矩阵与要处理的图像进行卷积操作,即可实现高斯平滑处理,减轻噪声点的影响。
本文中车道线轮廓检测采用Canny算法,基本思想是通过Sobel算子计算出图像中每个像素点灰度变化的大小,并通过阈值截取保留恰当的像素点进行轮廓拟合。常用的Sobel算子:
(4)
(5)
其中,Sobelx为沿x方向的Sobel算子矩阵,Sobely为沿y轴方向的Sobel算子矩阵。与高斯平滑操作类似,将Sobel算子矩阵与图像每个像素进行对应元素相乘并累加的操作,分别计算图像沿x轴方向的和沿y轴方向的灰度变化。从Sobel算子矩阵可以看出,灰度(左右或者上下)变化较大的像素点Sobel算子计算结果较大,而灰度比较平缓的区域Sobel算子计算结果接近于0。
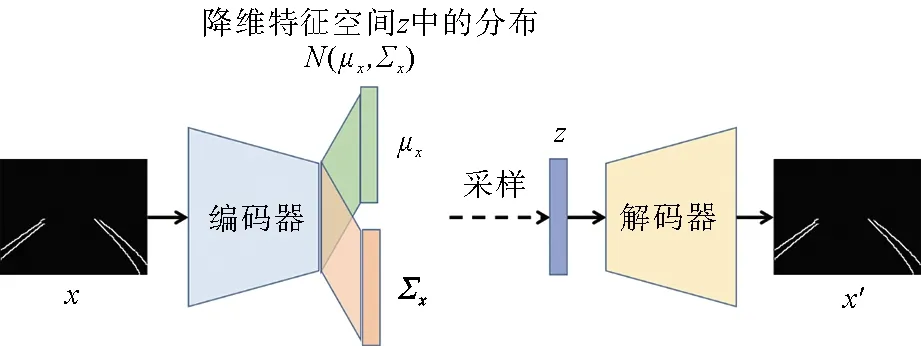
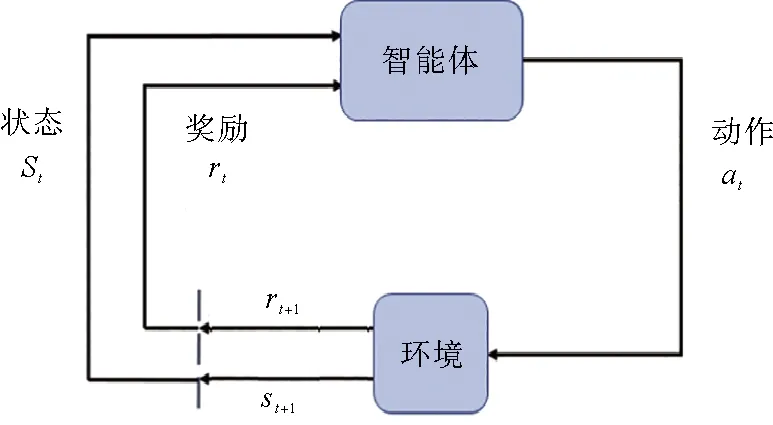
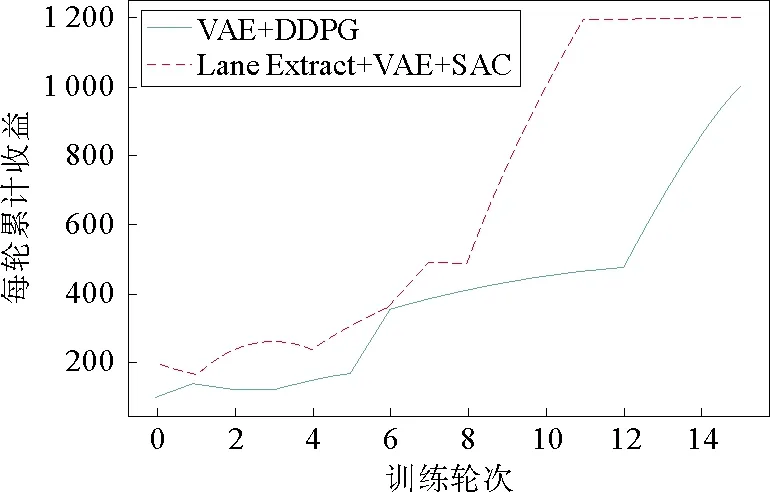
获得图像的灰度变化之后,设定Th1,Th2两个阈值,并且Th1 最后一步是提取图片中感兴趣的区域(ROI,Region of Interest)。在前置摄像头的整幅图像中,影响车辆行驶的仅仅是车辆前方的部分区域,而较高的天空以及远处的事物都可以看作是背景噪声,应该剔除掉。这里可以通过掩膜的方式,仅保留图像中特定区域的像素点。 经过以上车道线提取操作,可以得到如图2所示的图像。 图2 车道线提取示意图 提取车道线之后,图像中只包含关键的车道线信息(灰度值为255)以及大量的黑色背景(灰度值为0),而图像大小(即长×宽)并没有变化,依然与原图相同。此时图片中包含冗余信息,可以进一步地进行特征提取和降维。本文采用变分自编码器完成这一工作。相比于传统的线性主成分分析法(PCA,Principal Component Analysis),变分自编码器是一种非线性的编码器,借助神经网络强大的函数映射能力,可以获得更好的特征提取和降维效果[16]。 训练好的变分自编码器可以将输入的图像数据转换成低维数据,并且保留关键特征信息,保证从低维数据几乎可以重建原始数据。变分自编码器包括编码器和解码器两部分,如果用于数据降维,则只需要编码器部分。 变分自编码器本质上是一种无监督深度学习模型,其结构如图3所示。 图3 变分自编码器结构 变分自编码器的具体训练过程如下: 1)输入车道线提取图像,记作x; 2)编码器部分通过卷积层将图像映射到低维特征空间Z中,一般为低维向量空间。但是输入图像并不是直接对应到某个向量,而是对应到Z空间中的一个正态分布N(μx,Σx),其中μx为分布的均值,Σx为协方差矩阵,这两个参数由x确定。假设向量空间维度为n,则当前的输入图像可以与一个2n维的参数向量[μx,Σx]对应; 3)依照正态分布N(μx,Σx)采样得到向量z; 4)采样向量z通过解码器(主要包括转置卷积上采样网络)重构输入图像x′。 5)利用误差反向传播,调节编码器和解码器网络参数,最小化图像重构误差,同时要求分布N(μx,Σx)尽量接近标准正态分布。 从上述训练过程可以看出,对于给定的输入图像,变分自编码器并不是寻找特定的编码向量,而是寻找一个满足优化指标的概率分布函数,这也是其名称中“变分”的由来。相比于主成分分析和普通的自编码器,变分自编码器的一个重要优势是编码之后的低维特征空间具有很好的编码分布结构:当输入图像外观稍微变化时,对应的低维特征分布也会有微小改变,即编码具有连续性。这样可以保证,当编码器遇到新的图像时,可以将其规则地纳入降维特征空间中。 在实际应用中,为了训练变分自编码器,需要采集若干车道线图像信息,其中车道线的形状应该尽量丰富。通过上述无监督过程训练变分自编码器,直到重构图像外观比较接近原图像。由于图像能够重构,这表明降维特征保留了原图中的关键信息。因此,后续基于降维特征的强化学习从理论上来说可以达到与基于原图的强化学习类似的效果,并且由于去除了原图中大量的冗余或者干扰信息,数据维数降低,但质量提高,学习速度更快。 通过车道线提取和特征降维环节获得的图像降维特征作为环境观测状态用于强化学习训练过程。本文采用了SAC(Soft Actor-Critic)强化学习算法[17]。强化学习算法的基本框架如图4所示。 图4 强化学习基本框架 在本文工作中,智能体为自动驾驶策略,动作包括车辆速度和转向角,环境为车辆所处的道路交通环境,状态原本为前置摄像头的图像,但是经过前两个环节的车道线提取和特征降维,实际中用到的状态为当前时刻车道线图像x对应的降维特征[μx,Σx]。 各类强化学习算法的根本目的是搜索最优策略,即给定状态下的相应动作,使得累计收益最大化,其中累计收益为一次完整训练过程中所有时刻单步奖励的累加,本文构造的累计收益函数详见2.2节。与PPO(Proximal Policy Optimization)[18]和TRPO(Trust Region Policy Optimization)[19]相比,SAC是off-policy的算法,即可以使用旧策略下产生的数据进行训练,提高了采样数据的利用效率。这对于与环境互动成本较高的应用场景(例如实体机器人、自动驾驶系统等)是至关重要的。而与其他off-policy的算法如DDPG(Deep Deterministic Policy Gradient)[20]和DQN(Deep Q-Network)[4]相比,SAC搜索的是策略分布,而不是唯一的最优策略,搜索范围更广,不易过早陷入局部最优。 SAC是基于最大熵的强化学习算法,在训练过程中不仅希望累计收益最大,还希望策略分布函数的熵最大,具体的优化目标如下: 其中,π*为最优策略分布,st,at分别为状态和动作,R(st,at)为在状态st下采取动作at时获得的奖励,H(π(·|st))为策略π对应的熵,α为权重参数,用来调节优化目标中奖励项与最大熵项的相对重要程度,从而控制策略的随机性。关于SAC更详细的理论分析可以参考文献[17]。 强化学习过程中策略优化需要不断与环境实时互动,而自动驾驶测试中常用的数据集(例如KITTI[21],Cityscape[22]等)没有闭环互动,因此均不适用于强化学习算法的测试。现有工作大多在仿真平台上编程实现多种算法并对比分析它们之间的优劣。本文采用了Donkey Car仿真平台[23],并在其中实现了本文设计的自动驾驶系统以及比较相近的Kendall等人的工作,通过对比累计奖励、训练时间和不同环境中的泛化能力来说明本文系统的有效性。 Donkey Car仿真平台是专门针对智能车与自动驾驶设计的测试工具,如图5所示。它的优点是具有简单易用的程序接口,用户可以将自己设计的算法对接到该平台上。Donkey Car是一个轻量级的测试平台,对硬件性能要求较低。本文中运行Donkey Car仿真环境的软硬件平台配置为:Ubuntu 16.04操作系统,Intel Core i7-7820@2.9GHz处理器,32 GB内存,Nvidia GTX 1080 GPU,编程环境python 2.7,深度学习框架Tensorflow,深度强化学习框架Stable Baselines。 图5 Donkey Car仿真平台 仿真实验的目的是证明本文设计的基于特征提取的自动驾驶系统训练时间更短,在不同测试环境中的泛化能力更强。这里选择Donkey Car中的沙漠场景作为训练场景,而草地场景用于测试泛化能力,如图6所示。对比这两个场景,除了路侧的地面颜色不同,草地场景中还包含了一些路锥,这些环境的变化都有可能使训练好的自动驾驶系统失效。 图6 Donkey Car中的训练和测试场景 1)数据采集:这里采集的数据是为了训练变分自编码器。人工操控小车沿车道行驶一段距离,收集5000幅前置摄像头图像。Donkey Car提供了简单易用的操控指令,可以通过键盘上的方向键改变小车的速度和方向。收集的数据应该尽量涵盖多种车道线形状。 2)车道线提取:由于OpenCV中已经实现了高斯平滑和Canny算法,因此直接调用OpenCV中的相关函数即可,将上述5000幅图像转化为仅包含车道线的黑白二值图像。 经过Canny算法轮廓提取之后,图像中除了车道线可能还包括其他轮廓,例如远处的地平线、临近车道的外侧边沿等。此时,可以进一步地利用掩膜提取感兴趣区域。 3)训练变分自编码器:将车道线提取之后的图像输入变分自编码器模型中进行无监督训练。编码器部分包括4个卷积层和1个全连接层,随后将输出的值分别传入两个相互独立的全连接层,得到32维的均值向量和32维的协方差矩阵向量(这里限制协方差矩阵为对角阵,因此只需要对角元素)。之后采样得到降维特征变量送入解码器。解码器部分包括1个全连接层和4个转置卷积上采样层,最终生成重构的图像。训练直到重构图像和输入图像几乎相同为止。将训练好的变分自编码器中的编码器部分提取出来独立使用。 4)SAC强化学习训练:车辆前置摄像头的原始图像经过车道线提取和特征降维之后得到64维向量,作为观测状态送入SAC强化学习算法进行训练。由于近年来强化学习的流行,目前已有不少强化学习的框架和函数库。基于这些框架,研究人员不必“重复造轮子”,只需要调用框架内的函数即可实现特定的强化学习算法。本次实验调用Stable Baseline来实现SAC强化学习算法。在训练时,当小车偏离当前车道时完成一轮训练(Episode),记录本轮累计收益,然后令小车复位到车道线内,继续下一轮的训练。这里的重点是设置恰当的累计收益函数,从而激励小车保持在当前车道线内行驶,且速度尽可能的快。本文实验中采用Donkey Car仿真平台,并调用其内部变量构造奖励函数。具体设置如下: (1)车辆保持在车道线内正常行驶时,每一步的基本奖励项:αt=1。这意味着,只要车辆保持在车道线内,每行驶一步都会有1个单位的奖励。 (2)车辆保持在车道线内正常行驶时,每一步还会获得与当前速度成正比的奖励项:βt=0.1×vt/vmax,其中vt为车辆当前速度,vmax为车辆最大速度。在车道保持的同时,车辆速度越快,奖励越高。 (3)当车辆驶出车道线时,奖励项γt=-10。负值意味着这一行为实际上是被惩罚的。 (4)当车辆驶出车道线时,与当前速度成正比的奖励项:δt=-5×(vt-vmin)(vmax-vmin),其中vmin为车辆最小速度。同样地,负值意味着惩罚。驶出车道线时,速度越快,惩罚越重。 综合以上奖励项,时刻t的单步奖励为: (1)在车道线内行驶时:rt=αt+βt。 (2)车辆驶出车道线时:rt=γt+δt。 作为对比,在Donkey Car仿真平台上测试了Kendall等人设计的自动驾驶系统,即变分自编码器加DDPG强化学习算法[13]。图7中显示了两个自动驾驶系统中训练轮次(episode)与累计收益的曲线对比。本文设计的自动驾驶系统在每一轮训练中累计收益均较大,并且仅需要11轮训练即可令小车绕给定车道一周(虚线),而文献[13]中变分自编码器加DDPG的设计方案至少要增加50%的训练轮次(实线)。图7中累计收益上限为1 200,此时小车可以沿给定车道行驶一周。 图7 训练轮次与累计收益函数曲线 在训练完成之后,为了验证自动驾驶系统的泛化能力,在草地场景中进一步测试。由于加入了车道线提取环节,场景中草地颜色、路旁杂物的放置并不会影响后续的特征提取和SAC策略选择,本文设计的系统依旧可以正常工作,小车可以完整行驶一周。而Kendall等人的工作对环境变化比较敏感,在沙漠环境中训练的模型无法直接在草地场景中使用,小车会很快偏离给定车道。该实验证实本文设计的系统具有更好的泛化能力。 针对现有自动驾驶系统泛化能力不足的问题,本文设计了一种基于视觉特征提取的强化学习自动驾驶系统,通过提取车道线信息,剔除了环境噪声干扰,经过变分自编码器特征降维,只保留原图像中的关键信息,提高了强化学习的训练速度。基于Donkey Car仿真平台的测试表明,本文设计的系统不仅可以很好的完成车道保持任务,训练速度也得到了提升,并且具有良好的泛化能力,更换不同场景后依然可以正常行驶。 后续研究将在实体智能小车平台上进一步测试本文设计的自动驾驶系统的有效性。另外,考虑加入长短期记忆(LSTM)神经网络,更好的捕捉连续图像特征,使车辆操控更平稳。 本文工作针对的交通环境是封闭道路,基本假设为没有障碍物、交通灯、车辆、行人等交通元素,是一种非常简化的交通场景设定。本文的研究目的是验证所提出的算法在封闭道路环境下的泛化能力。后续工作会进一步考虑更复杂、更真实的交通环境,例如加入交通灯、静态障碍物等。相应的自动驾驶系统也将添加更多功能,如避障、信号灯辨识等。
1.3 基于变分自编码器的图像特征降维
1.4 SAC强化学习算法
2 实验分析
2.1 实验平台


2.2 训练步骤
2.3 训练效果分析
3 结论
