基于自适应动态规划的HEV 能量管理研究综述*
2020-12-08张子豪
金 辉,张子豪
(北京理工大学机械与车辆学院,北京 100081)
前言
随着能源短缺和环境污染问题的加剧,汽车行业的发展迎来重大挑战。 据国际能源机构(IEA)调查,2017 年我国燃料燃烧产生的 CO2占全世界28.3%,其中交通领域 CO2排放量全世界占比11%[1]。 燃油车辆因存在高油耗和高排放问题,从2016 年开始,陆续有8 个国家提出了燃油车禁售声明[2],因此须发展更为清洁的新能源汽车。 纯电动汽车相比燃油汽车能量利用率更高,排放更少,但是现阶段电池技术和充电设备等基础设施的发展阻碍了电动汽车的应用[3],短时间内其无法完全取代燃油汽车。 氢燃料电池汽车也是新能源汽车的一种,但现阶段由于氢燃料电池成本高、安全性差、氢气制取困难等问题,短时间内无法大规模投入使用[4]。混合动力汽车(HEV)是一种比较折衷的办法,其具有发动机和电动机双系统结构,有串联、并联和混联[5]3 种动力传输连接形式,拥有燃油汽车和电动车两者的优势,是一种很好的过渡方法。 HEV 结构比较复杂,需要能量管理策略(EMS)来实现较好的功率分配,以使发动机和电动机处于性能最优的工作区间,在满足动力性需求的同时提高车辆的燃油经济性。 现有的能量管理策略可分为3 类:基于规则、基于优化和基于人工智能的控制算法[6-9]。
基于规则的控制算法是根据专家经验进行设计,无须提前了解行驶路线,具体包含确定规则和模糊规则算法,这种方法系统响应速度快、控制简单,还具有高鲁棒性和可靠性。 Lin 等[10]按照发动机的稳态效率图来划分并联式混合动力货车的动力分配,该策略将发动机工作区间分为3 个区域,当驱动转矩数值处于某一区间时即以对应的模型工作。 基于规则的控制算法计算量小,实时性好,但对多种行驶工况的适应性较差,无法进行在线调整,而且没有最优理论支撑,在应用中难以实现最优的节油效果。
基于优化的控制策略中,一般将燃油经济性、动力性等作为成本函数,通过最小化成本函数来获得最优转矩、传动比和功率分配,优化方法包含全局优化和实时优化方法[5,11]。 全局优化需要行驶周期和周围环境的先验知识,以此来获得全局最优解。 随着高精度电子地图和车联网技术的发展,行驶时的道路和环境信息均可提前获得,主要问题是如何提高该方法的实时性。 全局最优解可通过线性规划、最优控制、遗传算法和动态规划(DP)等算法求解[12]。 以动态规划算法为例,动态规划算法由Bellman[13]在20 世纪50 年代提出,用于求解多阶段过程的优化决策问题,是一种全局优化算法,能较好地处理非线性问题,现已在能量管理研究中获得广泛应用。 基于DP 算法,徐萍萍等[14]进行插电式混合动力电动汽车(PHEV)的全程能量管理策略研究,与传统能量管理策略相比,其大大提高了车辆燃油经济性,减少了油量消耗。 动态规划虽然在多阶段全局最优化问题上能获得不错的效果,但是存在着“维的诅咒”,求解时间会随着状态变量和控制变量的增加而呈现指数型增长,运算效率较低,实时性不好。
实时优化算法的核心思想就是将全局最优标准降为瞬时最优,设计一个只与当前系统状态有关的成本函数,具体包括瞬时等效燃油最小消耗策略(ECMS)、鲁棒控制和模型预测控制(MPC)等方法。张静等[15]针对某款混合动力卡车,建立基于ECMS算法的门限值控制策略,保证算法实时性的同时也提高了燃油经济性。 实时优化的方法在一定程度上提高了实时性,但基于瞬时最优化的方法最终并不一定实现全局最优。
人工智能算法是未来的一个发展方向,神经网络模拟人脑神经元的活动,能以任意精度逼近非线性的复杂函数,申彩英[16]和席利贺等[17]利用DP 算法获得的最优化结果训练BP 神经网络,得到了具有实时控制能力的神经网络模型,该方法既能较好地实现全局最优效果也提高了算法实时性。 强化学习[18]基于智能体(Agent)与环境的交互,通过预先设定的奖励/惩罚机制来选择可选策略内的最佳动作。 自适应动态规划算法(ADP)有效融合了神经网络、最优控制和强化学习的特性,利用神经网络的函数泛化能力,来近似求解系统的成本函数,从理论上解决了传统动态规划在高复杂度非线性系统中的“维数灾”问题,在HEV 的能量管理策略研究中获得了广泛应用。
因为应用领域不同,ADP 算法有很多同义名称,如近似动态规划、神经动态规划和强化学习等[19],在2006 年美国科学基金会组织的“2006 NSF Workshop and Outreach Tutorials on Approximate Dynamic Programming”研讨会上,建议将该方法统一称为 “Adaptive/Approximate dynamic programming”。ADP 算法目前在多领域内实现了应用,如微电网的动态能量管理机制[20-23]、车辆的自适应巡航控制[24]和微分对策问题研究[25-27],一些研究者对ADP 算法在导弹制导律[28]、航空航天飞行器鲁棒控制[29]、城市交通信号优化控制方法[30]等方面的应用进行了总结,在这些研究中,ADP 算法均取得了不错的效果。
为更好地促进ADP 算法在混合动力汽车能量管理研究的应用,本文中介绍了ADP 的结构发展和算法实现方式,分析了ADP 算法在能量管理策略研究中的应用,最后针对现状总结ADP 算法在该领域应用的不足以及未来的发展趋势。
1 ADP 算法的发展
1.1 ADP 算法的结构发展
ADP 算法由Werbos[31]率先提出,他提出了两种结构:启发式动态规划(HDP)和二次启发式动态规划(DHP)。 HDP 的算法结构如图1 所示。

图1 HDP 的结构图
HDP 的结构包含3 层网络:执行网、模型网和评价网。 执行网用来映射状态输入与控制输出的关系,模型网根据前一阶段的状态和输入来估计出下一阶段的状态,评价网用来近似系统的成本函数J(x(k))。 图中实线和虚线分别代表信号和误差传递的方向。 DHP 结构的评价网的输出为成本函数的梯度∂J(x(k))/∂x(k),其余部分与 HDP 相同。若评价网用来估计成本函数及其梯度,则这种方法称为全局二次启发式动态规划(GDHP)。 这些方法都需要被控对象的模型网,如果省略模型网,对评价网的输入不仅仅为系统状态x(k),还包括执行网络的输出u(k),则这3 种方法分别称为控制依赖启发式动态规划(ADHDP)和控制依赖二次启发式动态规划(ADDHP)、控制依赖全局二次启发式动态规划(ADGDHP)。 综合以上ADP 结构的发展方向,其区别主要在于评价网的输入、输出信息和有无模型网。评价网的输入信息和输出信息代表了对系统信息的获取情况,信息越丰富,成本函数的近似精度越高。但是过多的信息会导致计算量的大幅增加,而且无效数据的使用也会阻碍学习进程。 因此根据具体问题合理选择ADP 结构,是该方法有效应用的重要举措。
He 等[32]提出了一种新型的3 层网络结构ADP算法,包含执行网、评价网和参考网,将参考网整合入执行-评价体系中可自适应地构建一个内部强化信号来促进学习和优化过程。 Padhi 等[33-34]提出了一种单网络自适应评价(SNAC)方法,该方法取消了执行网,只保留了评价网。 因此该方法可实现一个更简单的结构,只拥有双模结构一半的计算负担,可大大提升计算效率,另外由于取消了执行网,可消除执行网的近似误差。 这种方法的实现前提是最优控制方程可通过状态变量和协状态变量明确表示,拥有二次型成本函数的仿射非线性控制系统满足此要求,在航空航天、汽车和机器人等领域[35]的部分问题中均可以使用此方法。
1.2 策略迭代与值迭代
ADP 算法利用神经网络的函数泛化能力,通过迭代的方式来近似求解系统的成本函数或成本函数梯度,避免了直接求解哈密尔顿-雅克比-贝尔曼(HJB)方程,以此来解决动态规划中的“维数灾”问题。
ADP 的迭代算法主要为策略迭代与值迭代算法,策略迭代包含策略评估和策略提高两个过程,它需要从一个初始稳定的控制策略开始,利用值函数对现阶段的控制动作进行价值评估,直至迭代到值函数收敛,再利用值函数更新控制策略,依据更新后的控制策略进行下一阶段的策略评估,当值函数和控制策略都收敛时,完成策略迭代过程。 值迭代算法不要求初始稳定的控制策略,给定一个初始值函数之后,其选择不同控制动作下最大的期望值函数来进行动作更新,一直迭代直到值函数收敛,进而得到最优控制策略,刘毅等[36]对值迭代的收敛条件进行了研究,指出成本函数初始化为半正定函数即可保证值迭代收敛到最优,并给出了证明。
策略迭代的一个缺点是它的每次迭代都涉及策略评估,而策略评估本身可能是一个冗长的迭代计算,需要多次遍历状态集。 实际上,可以采用多种方法截断策略迭代的策略评估步骤,而不丧失策略迭代的收敛性保证,比如设定策略评估迭代次数,一个重要的特殊情况是,仅在一次计算之后停止策略评估,即为值迭代算法。 值迭代在其每次迭代过程中有效地结合了一次策略评估迭代和一次策略提高迭代。 策略迭代基于初始稳定控制策略,收敛性更好,但计算量较大,收敛速度慢。 当系统状态空间较大时,值迭代往往不能收敛到最优的值函数和控制策略。 因此,迭代方式的选择还要根据具体问题进行确定。
1.3 离线迭代与在线自适应算法
ADP 算法按应用方式可分为离线迭代算法和在线自适应算法。 离线迭代算法需要预先训练神经网络进行权值更新,训练好后直接应用于被控对象。由于应用时不可再对神经网络进行调整,所以当系统模型状态发生较大变化时,离线迭代算法的控制效果降低,须对神经网络重新进行训练,所以离线迭代算法适用于系统状态和工作环境比较稳定的控制对象。 在线自适应算法通过在线训练神经网络,可根据系统模型的变化,在线调整相应的控制策略。但该方法需要占用系统较多的计算资源,为实现较好的实时性,需要合理设计ADP 算法并且硬件系统具有强大的计算能力。 在线算法的抗干扰能力较弱,若干扰过多可能导致神经网络无法收敛,权值会处于持续更新状态。 尽管如此,在线自适应算法在未来多领域中有着十分广阔的应用前景。
2 ADP 算法在HEV 能量管理中的应用
ADP 算法由于其有效融合了神经网络、最优控制和强化学习的特性,利用神经网络的函数泛化能力和强化学习能力,能解决动态规划算法在HEV 能量管理优化问题中所面临的“维数灾”问题,相比基于规则的算法能对多种行驶工况有较好的适应性,相比基于优化的算法计算简单,有较好的实时性。
2.1 ADP 算法的应用
功率需求信息在能量管理策略设计中有着很重要的作用,在实际驾驶过程中,由于周围环境的不确定性和驾驶员个人驾驶风格的差异,未来的功率需求信息不可精确表达,只能以近似或概率的方式进行估计。 根据是否需要估计下一阶段的功率需求信息将ADP 算法在能量管理策略中的应用分为两类。
2.1.1 需要估计下一阶段功率需求信息
依据评价网的误差函数方程:
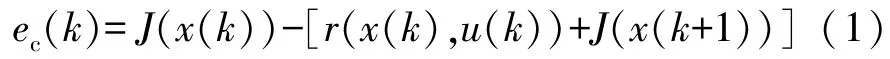
式中:ec(k)为k阶段的误差值;J(x(k))和J(x(k+1))分别为k阶段和k+1 阶段的成本函数;r(x(k),u(k))为系统在k阶段采取动作u(k)后获得的瞬时成本。
可知要计算在k阶段的误差值ec(k),须获知系统在k+1 阶段的状态x(k+1)和成本函数J(x(k+1)),有以下两种方式可用于获取这些信息。
一是利用模型网根据前一阶段的状态和输入来估计出下一阶段的状态。 刘洋[12]研究了基于HDP三网络结构的自适应动态规划算法,通过模型网来获得下一时刻的状态,使用反向传播神经网络对评价网进行预训练处理,最后的仿真结果表明该算法能够维持SOC 的平稳变化,并使其工作在高效区域的同时提高HEV 的燃油经济性。
二是根据马尔科夫链模型从某些特定行驶工况如UDDS、ECE 和EUDC 等中获得功率需求的转移概率矩阵,以此求得下一阶段的功率需求。 Li 等[37]利用这种方法获得功率需求的转移概率矩阵,以状态向量机(SVM)作为函数逼进器对动态规划的值函数进行估计,降低计算复杂度和存储要求,能得到一个较好的次优解。 部分研究并不以自适应动态规划命名,如上文介绍的同义名称,如强化学习和神经动态规划等,这些方法的基本思想一致。 Liu 等[38]和Yin 等[39]根据马尔科夫链模型从某些特定行驶工况如UDDS、ECE 和EUDC 等中获得功率需求的转移概率矩阵,利用Q 学习或策略迭代的方法,建立基于最小累计收益的能量管理策略的数学模型来获得最优控制策略,试验结果表明这些方法可有效缩短计算时间并提高燃油经济性。 从特定行驶工况中获得的功率需求转移概率矩阵不能覆盖实际用车行驶时的全部工况, Zou 等[40]利用基于马尔科夫链的实时功率需求递归算法来在线学习和更新转移概率矩阵,并利用Kullback-Leibler (KL)发散率来确定转移概率矩阵和最优控制策略的更新时间,在线学习的方式提高了该算法对多种工况的适应性。 为提高控制策略的收敛速度, Liu 等[41]和Du 等[42]利用快速Q 学习算法来获取能量管理策略,快速Q 学习算法相比标准Q 学习算法有更快的收敛速度,可节省16%的计算时间。
2.1.2 不需要估计下一阶段功率需求信息
控制依赖的自适应动态规划方法省略了模型网,无法预测下一阶段的状态x(k+1)和成本函数J(x(k+1))。 其利用前一阶段x(k-1)的成本函数J(x(k-1)),将评价网的误差函数方程更改为
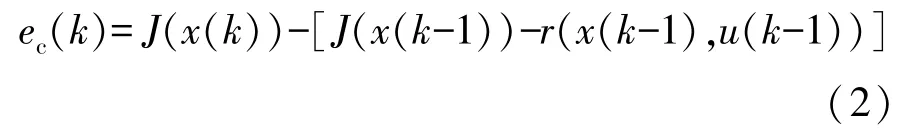
这种方法可省略模型网的计算量和近似误差,能有效提高计算效率,状态的更新通过车辆与环境交互获得。 Li 等[43]提出了一种基于神经动态规划的EMS 设计方法,选择3 层径向基函数(RBF)神经网络作为评价网和执行网的结构来近似成本函数和最优控制行为,利用时序差分(TD)方法来在线更新神经网络的权值。 为减少训练过程的计算复杂度,采取K-means 聚类算法确定RBF 中心的位置。 该方法的主要优点在于它不依赖于与未来驾驶条件相关的先验信息,并可根据运行条件的大差异进行自适应调整。 为实现较好的燃油经济性,换挡操作的优化必不可少,大部分研究者将发动机转矩/功率分配率和换挡指令组成控制集,作为评价网的输入来最小化成本函数。 换挡控制包括升挡、保持不变和降挡3 种指令,在优化时一般采用枚举法[25,38-39],而且为避免换挡操作的频繁发生,在成本函数中增设一个惩罚函数来抑制这种情况。 为了提高换挡指令的优化效率, Li 等[44]利用DP 算法对多个行驶工况的换挡操作进行全局优化,然后利用这些数据对神经网络进行训练,得到一个基于神经网络的在线换挡控制器,模拟试验表明该控制器可实现与DP 算法较为一致的优化结果。 通过将基于神经网络的换挡控制与基于ADHDP 算法的功率分配控制相结合,形成一种具有实时应用可能性的自适应能量管理策略,仿真结果表明该方法具有良好的鲁棒性、自适应性和逼近最优性。 后来该团队提出了一种新型的执行网-变速网-评价网结构来实现对功率分布和换挡操作的在线同步控制[45],并在此基础上提出了一种用于速度预测的多级神经网络结构,通过比较发现增加速度预测结构后可使发动机工作在燃油消耗更低的区域,将速度预测和能量管理策略相结合可实现更好的燃油经济性。
2.2 ADP 算法的实时性分析
实时性是能量管理策略应用的一个重要指标,对于ADP 算法的实时性分析,Ahmed 等[7]将其与DP 算法、基于规则算法等进行了定性比较,基于规则的算法由于结构简单,拥有最优的实时性。 ADP算法与DP 算法相比有较大提高。 蔡岗[46]对ADP算法的三模块结构与双模块结构进行了复杂度比较,假设每个网络结构相同,由于三模块结构比双模块结构多了一个模型网络,导致其比后者的数据存储要求和计算量均增加一半左右。 因此指出不依赖于模型网的双模结构——即控制依赖的AD 方法更有利于满足实时性要求。 上文提到的单网络自适应评价方法[30-31]由于仅有评价网设计,其计算负担相对更少,实时性更好,但其应用条件有相应限制。
从以上分析可以看出,ADP 算法在混合动力汽车的能量管理策略研究中有巨大的应用前景,相比基于规则的算法它可以提高对多种行驶工况的适应性,相比基于优化的算法又可有效提升实时性,可在线使用。 ADP 算法在HEV 的能量管理策略中应用时,为兼具较好的准确性和实时性,并且具有较好的收敛性和稳定性,关键须合理选择ADP 结构与车辆输入参数的数目,合理设计瞬时成本函数与误差函数方程,利用已有的先验知识来指导各个模块的设计将有助于提高收敛速度。 ADP 算法目前在能量管理策略的设计应用中仅仅处于初始阶段,还需进一步完善。
3 讨论与展望
ADP 算法有效结合了神经网络和强化学习的特性,在能量管理策略研究中表现出了极大的优良性,在未来的发展中有着重要作用。 下面对现阶段的ADP 技术在HEV 的EMS 中应用的不足与发展趋势进行总结。
(1) 选择合理的函数逼近器。 ADP 算法中的结构网通常由神经网络组成,利用神经网络的函数泛化能力对求解系统的成本函数进行近似,但神经网络目前还没有理论上的构造方法,通常利用经验和试错法来进行设计。 一方面随着神经网络的理论发展,这一现状可以得到改善。 另一方面对某些特定问题可寻找其他的函数逼近器,如支持向量机、线性基函数和分段线性函数等,根据具体问题选择合理的函数逼近方法。
(2) 多种控制方法结合使用。 将多种控制方法结合使用,可有效弥补单个方法的缺点,比如利用DP 算法的全局最优特性,利用DP 算法计算出来的结果进行神经网络的训练或模糊逻辑算法的规则设计。 或者利用遗传算法、模拟退火等算法,对ADP算法中折扣因子的取值进行自适应取值,可有效提高收敛性。 根据每个方法的特性进行优化组合,取长补短,有利于能量管理策略最优性、实时性、鲁棒性等多优化目标的实现。
(3) 多种信息融合使用。 将多种信息融合使用,如上文中介绍的将速度预测与能量管理策略相结合,可实现更好的燃油经济性。 目前高精度电子地图的研究正在广泛展开,未来可依据高精度电子地图获得全部行程的道路信息,再结合车联网技术,获得行驶环境中的动态信息,利用这些信息可有效减少一些不确定性,提高能量管理策略的优化效果和实时性应用。
(4) 缺少实车试验。 目前ADP 算法在能量管理策略中的应用采取模拟仿真的方法进行试验验证,缺少实车试验环节,对ADP 算法的实际使用效果还没有具体的体现。
(5) ADP 算法的实时性有待提高。 受限于当前阶段计算机的性能,ADP 算法在线应用的实时性有待提高。 为提高实时性需从两方面着手,一是提高硬件的计算能力,伴随5G 技术的发展,未来可通过云计算来解决车载控制器性能不足的问题,提高计算速度;二是对ADP 算法理论进行完善和发展,设计出收敛速度快、稳定性好的算法。
4 结论
针对目前的能源紧缺和环境污染问题,混合动力汽车是从燃油车辆到纯电动汽车的一种良好过渡形式,通过能量管理策略的研究可使发动机和电动机处于性能最优的工作区间。 与基于规则和优化的算法相比,ADP 算法不仅能提高燃油经济性,还具有较好的实时性。 目前ADP 算法在能量管理策略的研究仅仅处于初始阶段,还需进一步提高与完善,未来随着高性能计算机研究、车联网和5G 通信等多种技术的发展,ADP 算法的性能将会得到进一步提高,有着巨大的应用前景。
