面向多维度逻辑场景的自动驾驶安全性聚类评价方法*
2020-12-08张培兴
朱 冰, 张培兴, 赵 健
(吉林大学,汽车仿真与控制国家重点实验室,长春 130022)
前言
自动驾驶汽车是全球汽车产业发展的战略方向,而准确可靠的安全性测试评价是自动驾驶汽车推广应用的基础[1-2]。
目前,自动驾驶汽车大多基于公开道路或封闭试验场地进行安全性测试,评价指标主要为平均人工接管次数或单一场景的测试通过性[3-4]。 其中,平均人工接管次数指自动驾驶汽车每行驶1 000英里过程中人工接管的平均次数,可反映自动驾驶系统在多维度场景下的表现,但其测试过程存在风险且测试效率低下[5];测试通过性是指自动驾驶系统通过一系列具体测试用例的安全性测试,其逻辑场景只能针对离散的单一维度,评价结果不够全面[6]。
自动驾驶汽车行驶环境复杂多变,因此,其安全性测试评价必须是面向多维度逻辑场景的综合性能评价,传统方法无法满足其安全性评价需求[7-8]。本文中面向多维度逻辑场景,提出一种基于统计规律的自动驾驶安全性聚类评价方法,可通过聚类给定多维度逻辑场景中的危险参数,对被测算法的整体性能进行量化评价。
首先基于高斯模型对多维度逻辑场景下的遍历测试危险参数结果进行聚类,得到连续分布的危险域;在此基础上,分析不同危险场景的搜索难度和参数覆盖范围,提出危险域离散度、危险域范围两个基本评价指标,并将其耦合形成自动驾驶安全性聚类评价参数即场景危险率;最后,应用提出的方法对一种黑盒自动驾驶算法进行测试评价。
1 多维度逻辑场景危险参数聚类
基于场景的测试是自动驾驶汽车测试的必由之路,按照测试流程,测试场景可分为功能场景、逻辑场景和具体测试用例[9]。 其中,逻辑场景通过参数空间描述场景中要素的变化范围、体现要素间的耦合效应,是承上启下的测试主体,例如自动驾驶避撞测试时本车速度、相对速度和相对距离就是构成该逻辑场景的3 个典型测试维度。
本文中首先对多维度逻辑场景进行遍历测试获取危险参数,进而通过高斯模型对危险参数进行聚类,形成连续分布的危险域,算法流程如图1 所示。
首先,进行危险参数预处理:(1)将多维度逻辑场景参数离散化形成具体测试用例;(2)对具体测试用例进行遍历测试获取危险场景参数集;(3)对危险参数进行对称处理;(4)将对称处理后的危险参数进行标准化。
然后,对处理后的危险参数进行聚类:(1)利用组内残差平方和计算聚类中心数量;(2)当聚类中心为1 时,直接对危险参数进行单高斯模型聚类;(3)当聚类中心大于1 时,应用最大期望值(expectation maximization, EM)算法对危险参数进行高斯混合模型聚类;(4)获取均值、标准差等高斯模型参数;(5)删除因对称化处理所产生的多余聚类结果。
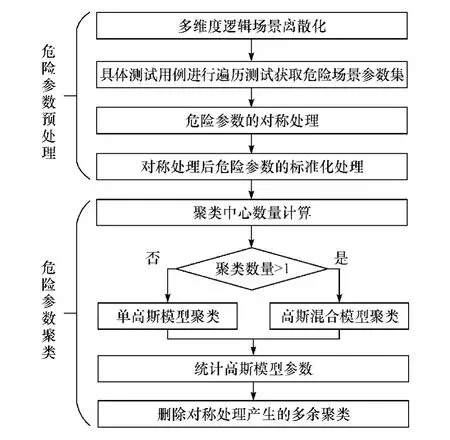
图1 多维度逻辑场景危险参数聚类流程
1.1 危险参数预处理
首先将多维度逻辑场景参数离散化形成具体测试用例,离散过程需要考虑的要素包括传感器精度、被测算法模型、系统运算频率等,当多种要素共同影响时,应该选择最宽松的限制条件作为离散步长。以相对距离为例,毫米波雷达长距离测距精度为±0.5 m, 中距离测距精度为±0.25 m,因此可以将相对距离以1 m 的步长进行离散。
对具体测试用例进行遍历测试,在足够大的参数空间范围内,必然存在导致危险发生的参数空间,将导致测试结果发生碰撞危险的场景参数定义为危险参数。 遍历测试后可获取危险参数集。
由于给定多维度逻辑场景边界的限制,危险参数集可能不会是一个完整的高斯分布范围。 因此需要将危险参数集在给定参数空间的危险边界按照不同的参数维度坐标轴进行对称。 这样既可以将危险参数集构建成一个完整的高斯分布,还可以保证后续标准化处理后的数据均值落在最危险参数点位置。
由于多维度逻辑场景参数类型不同,参数数值范围差异较大,因此需要对参数进行标准化处理。采用Z-score Normalization 方法对危险参数进行标准化处理[10],如式(1)所示。
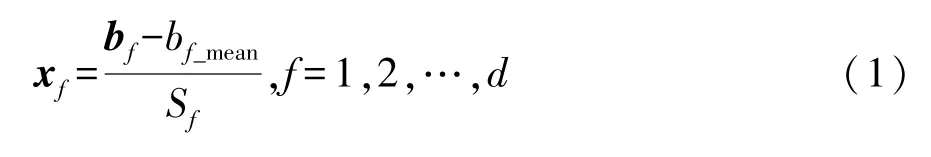
式中:xf为危险参数集X的第f维危险参数列向量;bf为对称处理后的第f维危险参数列向量;bf_mean为对称处理后第f维危险参数的均值;sf为对称处理后第f维危险参数的标准差;下角标f代表多维度逻辑场景的第f个维度;d为多维度逻辑场景的变量维度总数。
由此,可得预处理之后的多维度逻辑场景危险参数集X,如式(2)所示。X中的每一行向量xj(j=1,2…,m)为每个危险测试用例所对应的参数向量。
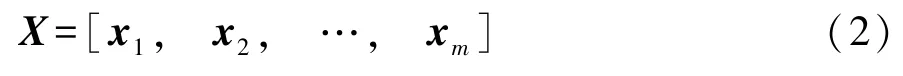
1.2 危险参数聚类
参数聚类首先需要确定聚类中心数量,本文中采用组内残差平方和计算危险参数聚类中心数量[11]。 组内残差平方和是指所有聚类中每个类内的要素距离其聚类中心的误差平方的总和,如式(3)所示。

式中:m为所有危险点的数量;为使用初步聚类得到的xj对应的聚类中心。
当组内残差平方和变化速率变慢时,即认为增大聚类数目也不能对聚类结果进行有效的提高,该速率变化的拐点数即为聚类中心数目。
当聚类中心为1 时,可直接对危险参数进行单高斯模型聚类,如式(4)所示。
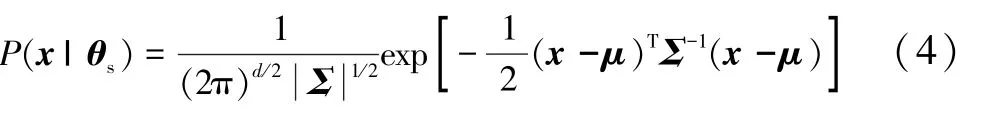
式中:P(x|θs)为单一高斯模型概率密度函数;θs为高斯模型的参数,包括均值和标准差;Σ为用来描述各维变量相关度的协方差矩阵;μ为危险参数向量的均值。 由于危险数据集经过对称和标准化处理,因此该分布的均值为0,标准差为1。
当聚类中心大于1 时,应用EM 算法对危险参数进行高斯混合模型聚类[12],即将危险参数分解为多个高斯概率密度函数组成的模型:

式中:G(x|θ)为高斯混合模型概率密度函数;θ为高斯混合模型的参数,包括第k个单高斯模型的权重αk和模型参数θk;θk包括均值μk和标准差σk;K为单个高斯模型的个数。
通过极大似然法可对θ进行估计:


应用EM 迭代算法对上式进行求解。 EM 算法的E-step 为计算Q函数,Q函数代表给定第p轮迭代的参数θp之后高斯混合模型G(x|θp)与给定数据之间的相似程度。
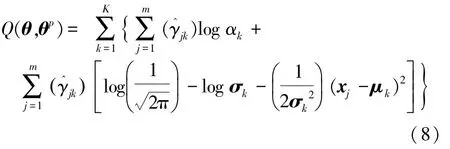
式中:称为后概率事件,即表示第j个观测数据来自第k个高斯密度函数的概率。

EM 算法中的 M-step 为最大化Q函数。 当计算第(p+1)步的参数θp+1时,只需要对第p步的αk、μk、σk求偏导并使其等于 0,就可以使得Q函数极大化。
重复进行EM 算法的 E-step 和 M-step 直至模型收敛即可得到高斯混合模型G(x|θ)。
通过上述单高斯模型或高斯混合模型,可以得到模型参数,即均值和标准差。 本文中利用这些聚类参数建立自动驾驶安全性评价指标。
同时,由于危险参数预处理时进行的对称处理会导致数据扩大,因此需要对这部分多余的数据进行删除。 坐标轴处数据分布在对称处理之后不会增加高斯分布的数量,但是会造成区域扩大;其他位置的分布在对称处理之后会导致高斯分布数量增加。因此在整个聚类完成之后需要删除该类多余的分布(多余分布的特点为均值存在对称性,标准差等同),并对坐标轴处因对称造成的区域扩大进行修正。 对于那些删除数量少于(2d-1)的高斯分布类型,即位于坐标轴处的高斯分布,其标准差的修正过程为

式中:q为未因对称产生多余高斯分布的对称轴的数量;t为该类高斯分布的删除数量;σkb为修正前的高斯分布标准差;σk为修正后的高斯分布标准差。
2 自动驾驶安全性聚类评价指标
传统基于场景的自动驾驶安全性评价大多采用单一场景测试通过性作为评价指标,然而,这种指标难以反映复杂逻辑场景多维度要素的耦合关系,也无法体现不同自动驾驶策略的整体性能。 本文中综合考虑多维度逻辑场景内危险场景的分布情况和覆盖范围,根据高斯聚类结果提出危险域离散度和危险域范围两个基本评价指标,并将其耦合形成可量化的自动驾驶安全性聚类评价指标——场景危险率。
2.1 危险域离散度
针对同一多维度逻辑场景,被测算法产生的危险参数分布越分散,意味着算法的安全性越差,采用单一场景测试通过性进行测试时,发现其危险场景的难度也越大。 因此,定义危险参数的连续分布为危险域,提出危险域离散度指标对自动驾驶安全性进行评价。
显然,危险域离散度应包括两部分,一是不同危险域相对于逻辑场景中最危险边界点的距离,二是不同危险域之间的相对距离。
经过对称及标准化处理后的危险参数集,其最危险边界点即为坐标原点,因此,不同聚类中心相对于坐标原点的欧氏距离db即为不同危险域相对于最危险边界点的距离,如式(12)所示;其他不同危险域之间的相对距离可用类间距离ds表示,如式(13)所示。
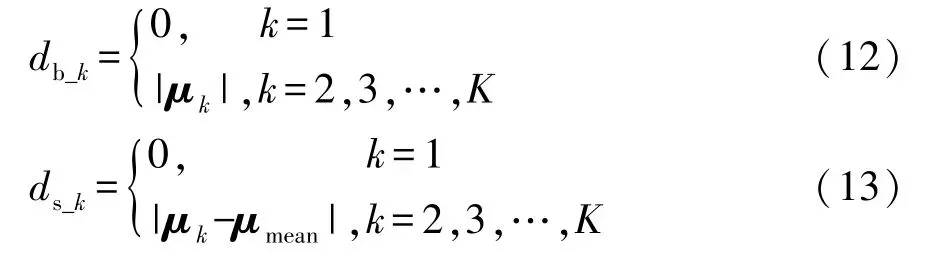
式中:μk为聚类中心的位置即高斯分布的均值,下标k表示不同的聚类;μmean为除原点外的聚类中心的均值。
第k个危险域的离散度dh_k为

式中a、c为权重系数。
2.2 危险域范围
针对同一多维度逻辑场景,被测算法产生的危险参数覆盖范围越大,意味着算法的安全性越差,因此,提出危险域范围作为自动驾驶安全性的另一个评价指标。
危险域范围Sk应该综合考虑危险参数的危险程度及其分布范围,可采用高斯分布标准差表达,第k个危险域的危险域范围Sk为

式中:ω=(ω1,ω2,…,ωd)为不同维度危险参数的重要程度系数;σk=(σ1,σ2,…,σd)为高斯分布的标准差。
ω可采用层次分析法确定。 首先建立参数判别矩阵A,如式(16)所示。

式中off为不同场景参数两两比较的相对重要程度。
通过计算可得到判别矩阵的最大特征值λmax和其对应的加权向量z。 进而,计算判别矩阵的一致性指标CI,如式(17)所示,查表获得随机一致性指标RI,计算一致性比率CR,如式(18)所示。

如果CR<0.1,则矩阵通过一致性检验,加权向量z即可作为不同维度危险参数的重要程度系数ω。 如果CR≥0.1,则矩阵未通过一致性检验,需要重新建立判别矩阵并进行层次分析法的后续步骤。
2.3 场景危险率
为综合评价被测自动驾驶算法在某一多维度逻辑场景下的安全性,将危险域离散度和危险域范围两个指标进行耦合,建立可量化的聚类评价指标——场景危险率。
场景危险率Rd如式(19)所示。

式中:S1为坐标原点处的危险域范围;Smin为理论最小危险域范围,即在给定场景下,假设自动驾驶汽车以理想状态进行操作计算得到的危险域范围。 值得注意的是,为保证数据的可比性,计算该值时,参数标准化过程应将理想危险参数映射到测试危险参数域进行标准化。
由式(19)可知,场景危险率值越小,则表示所测试的自动驾驶算法在给定的多维度逻辑场景下安全性越好,其下限值为1。 如果Rd值超过1.5,算法的安全性就比较差,需要进一步优化。
3 评价方法应用
为验证所提出的聚类评价方法的可行性,以Prescan 软件基础包自带的一种黑盒自动驾驶算法为例,进行测试应用。 算法的输入包括本车速度、雷达探测范围、探测角度相对速度等,输出包括发动机转矩、制动踏板行程。
选择前车紧急制动多维度逻辑场景进行测试,如图2 所示。 场景参数为本车初速度v1、前车与本车之间的初始距离e和前车初速度v2,它们的参数空间分别为[15 m/s,30 m/s]、[30 m,50 m]、[25 m/s,35 m/s]。 测试时,被测车辆以初速度v1在中间车道向前行驶;前车在本车前距离e处以初速度v2向前行驶,并以8 m/s2的减速度进行减速,持续1.5 s;之后,前车以3 m/s2的加速度加速,持续3 s;最后前车以1 m/s2的加速度缓慢加速直至30 m/s。
首先根据传感器模型性能和软件平台的仿真频率,对多维度逻辑场景参数进行离散化以形成具体测试用例,选择速度的离散步长为1 m/s,距离的离散步长为1 m。
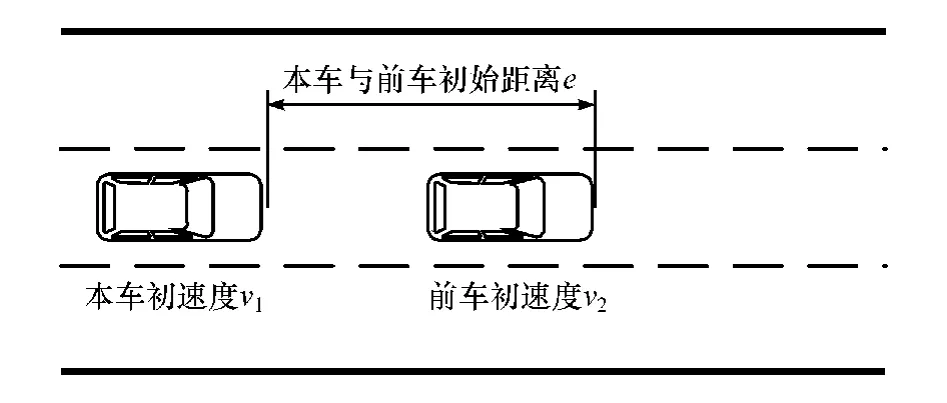
图2 测试场景示意图
对具体测试用例进行遍历测试,共测试3 696次,选择碰撞时间(time to collision,TTC)的倒数TTC-1作为危险参数选择条件,获取危险场景参数原始数据集,共获得危险参数82 个,如图3 所示。
图3 危险参数原始数据集
对危险参数进行对称处理后,计算得到:危险参数的均值为(30,30,25),标准差为(5.236 6,1.298 7, 1.222 3)。将数据带入 Z-score Normalization 标准化处理公式,得到预处理后的危险参数集,如图4 所示。
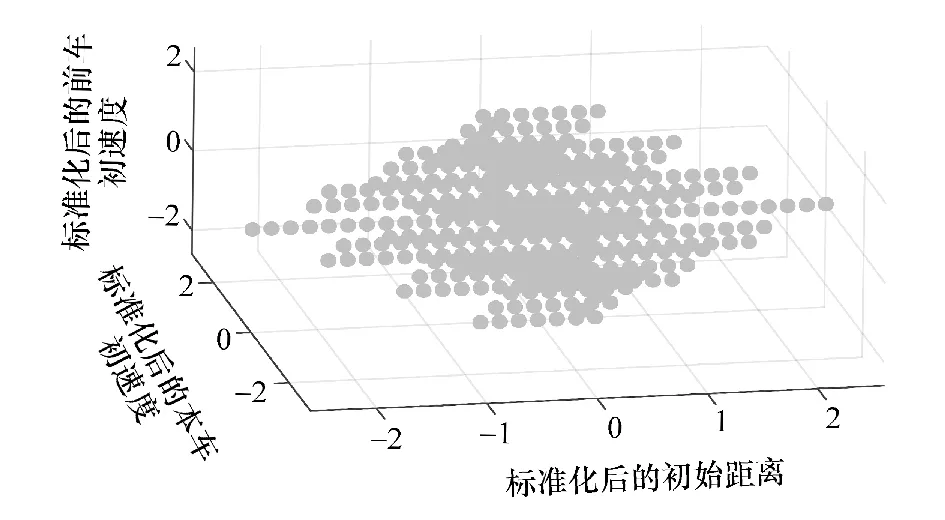
图4 预处理后的危险参数集
经过组内残差平方和计算可得该危险参数集的聚类中心为1,可直接对预处理后的危险参数进行单高斯模型聚类,该三维高斯模型在所有维度的标准差都为1,均值都为0,修正后的高斯分布标准差都为0.577 4。
将高斯聚类模型参数带入安全性评价指标进行计算。
首先需要计算不同维度危险参数的重要程度系数。 根据该逻辑场景3 个参数的危险性影响,定义参数的判别矩阵如式(20)所示。

可计算得到该矩阵的最大特征值为3.004,对应的加权向量为[0.1220,0.6483,0.2297]。
进行一致性检验,CI、RI和CR的值分别为0.002、0.52、0.003 8,显然,CR小于 0.1,通过一致性检验,危险参数的重要程度系数即为
[0.1220,0.6483,0.2297]
代入式(15),可得S1=0.3333。
下面,计算理论最小危险域范围Smin。 在该测试场景下,被测车辆的理想制动减速度曲线如图5所示[13],其分为3 个阶段:第1 阶段为滞后阶段,车辆无制动;第2 阶段为建压阶段,制动减速度匀速增加;第3 阶段为匀减速阶段,匀减速直至停车。 将理想状况下测试车辆的位置-时间曲线与前车的位置-时间曲线做差,并将逻辑场景参数带入其中,可得到碰撞试验点如图6 所示,共发生碰撞22 次。
将该组数据进行对称处理,其均值为(30,30,25)、标准差为(2.2669,0.8660,0.9280)。Smin参数标准化过程应将理想危险参数映射到测试危险参数域进行标准化,其过程如式(21)所示,修正后Smin高斯分布的标准差σ*为(0.4329,0.6668,0.7592)。

图5 自动驾驶汽车理想制动减速度曲线
图6 理想状态的危险参数原始数据集

式中:sk_v为Smin计算标准化过程中使用的标准差参数;sk_t为被测算法试验结果在标准化过程中使用的标准差参数。
将σ*代入式(10)进行修正,并将之前得到的参数重要指数ω带入式(15),得到该逻辑场景中的Smin数值为 0.147 8。
将上述数值带入式(19),可计算得到被测算法在该多维度逻辑场景下的场景危险率为3.508 1,该算法的安全性较差。
综上,应用本文中提出的自动驾驶安全性聚类评价方法对该算法进行测试评价,结果表明,该方法可综合考虑算法在多维度逻辑场景下的统计学规律,获得量化指标,实现更为全面的科学评价。
4 结论
本文中面向多维度逻辑场景,提出了一种基于统计规律的自动驾驶安全性聚类评价方法。 首先对多维度逻辑场景危险参数进行了聚类;然后,利用聚类结果,提出危险域离散度、危险域范围两个基本评价指标,并将其耦合形成自动驾驶安全性聚类评价参数——场景危险率;最后,应用该方法对一种黑盒自动驾驶算法进行了测试评价。 本文中提出的自动驾驶安全性聚类评价方法可综合考虑算法在多维度逻辑场景下的统计学规律,获得量化指标,实现更为全面的科学评价。
多维度逻辑场景危险参数的准确获取是自动驾驶安全性聚类评价的基础,但对于不同测试场景,其定义和指标不尽相同,未来将进一步深入研究多维度逻辑场景危险参数的指标定义和筛选方法。
