计算机化分类测验的特点与发展述评
2020-11-17简小珠陈平
简小珠 陈平
一、计算机化自适应测验的应用与分类
(一)计算机化自适应测验的发展应用
计算机化自适应测验 (computerized adaptive testing,CAT)是一种以项目反应理论(item response theory,IRT)为指导的新兴测验形式。它在测试过程中根据考生作答情况来匹配考生能力水平的试题,实现因人施测。相对于传统的纸笔测验,CAT使用较少的试题就能获得相同的测量精度,而且根据被试能力水平选择试题,可以降低被试测试焦虑。CAT的其他优点还包括采用标准化的测试、即时的报告测验成绩与反馈作答结果信息等[1]。
CAT国际协会于2010年成立[2],创办了专业期刊Journal of Computerized Adaptive Testing[3],每 两年举行一次研讨会议。研讨会议促进CAT研究的发展应用。根据协会的统计,目前至少有二十多项CAT项目正在施测应用中[4],CAT已被广泛应用于多个测量领域:(1)心理与教育测量领域,例如美国大学入学考试(SAT)、学业进展测评(MAP)、中国台湾地区初中升高中的基础知识测试等;(2)职业资格考试领域,包括美国医生护士资格考试、微软软件程序员认证考试、美国军队职业能力倾向成套测验(ASVABCAT)等都采用了CAT版本的测验;(3)人格测量领域,CAT应用于人格问卷的典型例子是明尼苏达多项人格量表(MMPI)采用CAT测试的实践与研究,Forbey和Ben-Porath(2007)回顾了MMPI-2使用CAT的测试应用[5];(4)认知诊断测量领域,认知诊断CAT(CD-CAT)是目前研究热点之一,唐小娟、丁树良和俞宗火(2012)概述了近年来CD-CAT的理论与实践研究情况[6];(5)在多维能力测量方面,发展出多维能力 CAT (Multidimensional Adaptive Testing),多维能力CAT可以提高自适应测验的内容覆盖面,测量多个能力维度,从而获得更多的测验信息和更高的测验效率,例如 Yao、Pommerich 和 Segall(2014)及刘发明和丁树良(2006)等人的研究[7-9]。
(二)计算机化自适应测验的分类
对于目前出现的众多CAT研究,已有研究者对它们进行了分类,Chang(2012)以及唐小娟等(2012)将CAT分为两类[10]:以IRT为基础的传统CAT和以认知诊断理论为基础的认知诊断CAT。这里对CAT进行了更为细致的分类,从四个角度进行阐述:
第一,从CAT所使用数学模型的角度,可分为单维CAT、多维CAT和认知诊断CAT。单维CAT是最早的、也最为常见的CAT形式,使用单维能力IRT模型,如单、两、三、四参数Logistic模型,等级反应模型等。多维CAT是以多维能力IRT模型为基础的CAT形式,以及多维能力IRT模型(Reckase,2009)[11],包括多维Rasch模型、三参数多维Logistic模型、多维等级反应模型等。认知诊断CAT是以认知诊断模型作为基础模型的CAT形式,认知诊断CAT使用的认知诊断模型又可以分为两类,一类是以IRT为理论基础的认知诊断模型,如线性Logistic模型、多成分潜在特质模型等等;另外一类是不属于IRT范畴的认知诊断模型,如规则空间模型、属性层次模型、DINA模型、融合模型等。
第二,从CAT测验长度是否固定的角度,可以分为定长CAT(Fixed-length computerized adaptive testing,FL-CAT)和变长 CAT(Variable-length computerized adaptive testing,VL-CAT)。 定长 CAT 规定所有被试作答相同数量的题目,只要CAT达到指定的测验长度,测验则终止。变长CAT是不固定测验长度的CAT,需要以其他终止规则来判断是否要终止测验。
第三,从CAT能力评价绝对参照点的角度,CAT发展出计算机化分类测验(Variable-length Computerized Classification Testing,VL-CCT),有些文献也称为 mastery adaptive test, 或者 computerized mastery adaptive test,或者 Pass-Fail CAT。VL-CCT 本质上是单维CAT的一种特殊形式。VL-CCT测验在CAT形式下按照某一绝对标准(即能力估计值分界点)对被试进行分类,看其是否达到某一绝对标准来对分数进行解释并将被试分为通过或不通过两类,或两类以上。测验过程中只要确定了对被试的分类并达到其他测验目标,则测验终止。VL-CCT能用较少的试题实现对被试的准确分类,而且在对被试能力分类方面要优于一般的单维CAT(Eggen&Straetmans,2000)[12]。VL-CCT测验类似于传统纸笔测验形式下的标准参照测验(或掌握性测验)。VL-CCT适合应用于心理与教育测量中的掌握性评价或等级评价,以及职业资格考试评价,可以有效地对被试进行分类。VL-CCT也可以看成是变长CAT(VL-CAT)的一种特殊形式。但与一般的变长CAT相比,VL-CCT需要有一个或多个划界分数线,必须要对被试进行分类才能终止测验,并兼顾其他测验目标;而变长CAT可以在达到标准误准则、贝叶斯最小方差变异准则等要求时就终止测验,不需要划界分数线。
第四,从CAT自适应过程设计的角度,CAT发展出计算机化自适应序列测验 (computer-adaptive sequential testing,CAST)[13]。 计算机化自适应序列测验,有些文献也称为计算机化多步自适应测验或多阶段自适应测验 (Multistage Testing,或multistage adaptive testing,MST)。CAST在测试过程中将测试分为3至5个阶段,在每个阶段测试的内容模块需要根据被试上一阶段的作答情况来估计被试能力值,并根据被试能力值情况选择下一阶段的测试内容模块。
此外,还有一些其他分类角度,包括是否属于速度测验、是否是由被试自己选择测试起点等等,但这些分类角度较少被研究者关注。
二、VL-CCT的组成部分及特点
VL-CCT本质上是单维CAT的一种特殊形式,组成部分与单维CAT的组成部分基本上是一样的。为叙述方便,下文中CAT均表示单维CAT。Thompson(2007)认为VL-CCT测验包括五个组成部分:测量模型、量尺化的题库、测试起点、选题策略和终止规则[14]。笔者认为,在Thompson观点的基础上应增加能力估计方法、研究结果的评价分析这两个部分。由于VL-CCT测验的主要目标是将被试进行分类,因而VL-CCT在选题策略、终止规则、评价分析等部分有其独特性,以下分别论述VL-CCT各个组成部分的特点。
(一)测量模型
VL-CCT以IRT为基础理论,常用的IRT模型都可作为VL-CCT的测量模型。研究者已经将常用的IRT模型应用到了VL-CCT中,例如:Eggen(2011)在VL-CCT的终止规则研究中使用了Rasch模型[15],文剑冰和王文昊(2008)在比较VL-CCT的终止规则研究中使用了三参数Logistic模型[16],Smits&Finkelman(2013)在人格测量情境下CAT与VL-CCT的比较研究中使用了等级反应模型[17]。
(二)量尺化的题库
在CAT研究中,题库的试题b参数往往模拟服从标准正态分布N(0,1)。也有一些研究让b参数服从 U[-3,+3]或 U[-4,+4],如 Wouda 和 Eggen(2009)以及程小扬、丁树良、严深海和朱隆尹(2011)等人的研究[18,19]。在VL-CCT测验中,在能力分数划界点的试题需要更多的题量,那么试题b参数分布就需要在能力分数划界点模拟成尖峰分布形态。例如Huebner和 Li (2012)、Thompson (2009) 的研究中[20,21],一部分研究情境的试题参数分布设计为在能力分数划界点-0.75上服从宽分布的正态形态 N(-0.75,2.0),另一部分研究情境的试题参数分布设计为在能力分数划界点-0.75上服从窄分布的正态形态 N(-0.75,0.4)。有些VL-CCT研究中也使用实测题库的试题参数,例如:Chen、Lei、Chen 和 Liu(2014),Lin (2011),van Groen、Eggen 和 Veldkamp(2014),Yang、Poggio 和 Glasnapp(2006)等,都使用了实测题库的试题参数[22-25]。
(三)测试起点
在CAT模拟研究中,能力起点一般从能力中点θ=0.0 开始,例如 Lin(2011);Bock 和 Mislevy(1982);Passos,Berger 和 Tan (2008);Van Der Linden 和Veldkamp(2004)等人的研究[26-29]。 在VL-CCT 测验研究中,除了上述两种测试起点方法外,还可以选择以下两种方法作为起点[30]:一是以实际参加测试的被试能力分布的中点作为测试起点,二是以被试通过与未通过的概率似然比等于1.0时作为测试起点。
(四)选题策略
选题策略 (包括试题曝光率控制和测验交叠率控制)是计算机化自适应测验的关键环节,许多CAT研究都是围绕选题策略和测验安全控制进行的。毛秀珍和辛涛(2011)以及简小珠、戴海崎、张敏强和彭春妹(2014)等人的研究中都已经将CAT形式的选题策略及其变式进行了概括分类[31,32],包括Robbins-Monro选题策略 (b匹配选题策略)、Fisher信息函数策略 (FI)及其变式、KLI函数策略 (Kullback-Leibler information,KLI)及其变式、α分层策略及其变式、贝叶斯策略及其变式等等,并认为应根据CAT测验情境要求来选择相对应的选题策略。
在CAT下,FI函数方法及其变式、KLI函数方法及其变式、PG 方法(progressive method,PG)及其变式、贝叶斯选题策略等选题策略同样都可以适用计算机化分类测验。例如,路鹏、周东岱、钟绍春、丛晓(2013)在VL-CCT下使用贝叶斯选题策略,发现被试分类准确性较高[33];Veldkamp(1999)、van Groen、Eggen和Veldkamp(2014)在VL-CCT下为实现多个测验目标[34,35],在FI函数的基础上进行改进,提出了六个FI函数选题策略的变式,包括:加权方法(Weighting Methods,WM)、 等级优先方法(Ranking or Prioritizing Methods)、目标程序方法 (Goal Programming,GP)、 全局信息方法 (Global-Criterion,GC)、极大值方法(Maximin Methods,MA)、约束控制方法(Constraint-Based Methods,CBM)。van Groen 等(2014)的研究结果表明[36],WM、GP、GC、MA、以即时能力估计值为基础的FI、以一组划界分数线中数为基础的FI(MC)、以最近的划界分数线为基础的FI(NC)等这七种选题策略方法,其模拟结果发现,这七种选题策略方法下的被试分类准确性相差不大,然而以一组划界分数线中数为基础的FI(MC)、以最近的划界分数线为基础的FI(NC)这两种方法下的测验长度较短,测验效率相对较高。
近年来研究者还提出了专门适合VL-CCT测验的两种选题策略,即加权似然比函数方法(Weighted Log-odds ratio,WLOR)和交互信息函数方法(Mutual Information,MI)。
加权似然比函数(WLOR))方法最早是由Lin和Spray(2000)提出的[37]。 Eggen(1999)、Eggen 和Straetmans(2000)认为,KLI函数方法能适合VL-CCT的终止规则 SPRT(sequential probability ratio test)[38,39],选择具有最大KLI函数值的试题,可以在分类测验中使用较少的试题对被试能力进行较为准确的分类,但KLI函数方法只能适合分为两类的情况(即一个分界点),而有多个分界点时就很困难。Lin和Spray(2000)在KLI函数方法的思想基础上发展出加权似然比函数方法(WLOR),在备选的试题集中,选择在加权似然比函数上具有最大值的试题作为测试的下一道试题,加权似然比函数方法公式为:

其中,θ1和θ2应该分别在分数界限的以上和以下,R函数值的性质与作用与KLI函数值很相似。
交互信息函数方法(MI)由 Weissman(2007)提出[40]。为了克服KLI函数方法只能适合分为两类的情况,Weissman(2007)提出MI方法可以适合被试分为三类及三类以上的情况。MI函数方法也是在KLI函数的思想上发展起来的,其函数公式为:

其中,Xi表示在试题i上f(θ)的作答反应,f(xi,θ)是Xi,θ上的联合分布函数,而f(xi)、f(θ)分别是被试作答反应、被试能力分布的边际分布。在此方法下,选择具有最大MI信息量的试题作为下一道试题的测试。MI信息函数方法是对称的,而KLI函数则不是对称,MI信息函数方法可以适合多个分数界线的测验,如果只有一个分数界线时,MI信息函数方法也就简化成了KLI函数方法了[41]。在MI函数的基础上结合多重分类方法,进一步提出了交互信息函数多重分类方法 (Mutual Information and Multiple Imputations,MIMI),该方法是MI方法的一种变式。Weissman(2007)通过CAT模拟比较发现,在被试分为四类的情况下,MI方法分类准确性略高于FIP方法(后验加权的FI方法)和FI方法,而测验使用的试题数量也略少于FIP方法和FI方法。
从选题策略方法公式中使用能力值参照模式的角度,Thompson(2009)将 VL-CCT下选题策略的应用分为两种模式[42]:第一种模式是选题策略使用划界分数线 θ0为参照模式(Cutscore-based methods,CB),即选题策略方法公式中使用划界分数线的能力值θ0来计算,并据此来选择试题进行测试;第二种模式是选题策略以测试过程中被试能力估计值θˆ为参照模式(Estimate-based methods,EB),即选题策略方法公式中使用即时动态更新的被试能力估计值θˆ来计算,并据此来选择试题进行测试。本文在Thompson(2009)归纳的选题策略应用模式的基础上进一步总结如表1。
在以往研究中发现,同一种选题策略下CB模式和EB模式的测验长度、分类准确性有差异,因此研究者将选题策略分为CB模式、EB模式两大类。Thompson(2009)将选题策略与终止规则结合分析,以寻找选题策略与终止规则的最佳组合模式,在VL-CCT下将FI选题策略的CB模式、EB模式,分别与序列概率比检验 (SPRT)、能力置信区间方法(ACI)这两种终止规则进行组合,分别在这四种情境下进行模拟分析。当终止规则为ACI时,FI选题策略的EB模式比CB模式所需测验题量平均少2.8题;而在终止规则为SPRT时,FI选题策略的EB模式比CB模式所需测验题量平均多20.46题。综合其研究结果,在FI选题策略为CB模式、终止规则为SPRT的组合情境下,被试分类准确性略高,而测验长度最短。当然在总体上,CB模式下的题库利用率低于EB模式。以上是FI选题策略CB模式、EB模式与不同终止规则进行组合设计,其他的选题策略、终止规则进行组合对被试分类准确性、测验效率的影响将是怎样的?如何寻找选题策略、终止规则最佳的组合?这将是VL-CCT未来研究拓展方向之一。
(五)终止规则
CAT测验终止规则主要有固定测验长度和不固定测验长度两类。以固定测验长度为终止标准时,当作答试题数量达到规定的测验长度便终止测验。在许多研究中,固定测验长度范围一般在25题至70题之间。当CAT终止标准为不固定测验长度时,需要使用终止规则作为测验终止的依据。Babcock和Weiss(2012)归纳了变长CAT下的几种终止规则,包括标准误准则、最小信息量准则、最小能力估计值变化准则[63]。(1)标准误准则,在当前能力估计值的测验标准误差达到指定的标准便终止测验,标准误准则是以往CAT研究常用的终止准则。(2)最小信息量准则,当前题库中被选择用来测试当前被试的试题所提供的信息量小于指定的标准时则可以终止测验。(3)最小能力估计值变化准则,是指CAT测试过程中在测试一道试题后,被试能力估计值的前后变化值小于指定的精度时就终止测验。此外,还有贝叶斯最小方差变异准则。以贝叶斯估计法作为CAT选题策略标准时,测验终止规则是估计能力之变异数小到某个预定的标准时终止施测。标准误准则、最小能力估计值变化准则、最小信息量准则、贝叶斯最小方差变异准则这四种终止规则也可以在VL-CCT中使用。VL-CCT下为了达到对被试的分类,还发展出专门适用的四种基本终止规则及其发展变式,包括序列概率比检验方法、能力置信区间方法、拓展似然比方法、贝叶斯决策理论方法,这些终止规则实质上都是对被试进行分类的规则,是VL-CCT的关键组成部分,以下分别论述这四种终止规则。

表1 VL-CCT选题策略的应用模式分类
第一种终止规则:序列概率比检验方法(Sequentialprobability ratio test,SPRT;Eggen,1999;Eggen&Straetmans,2000)[64,65],其测验虚无假设与备择假设是,H0:θ=θ1,H1:θ=θ2; 其中,θ1,θ2分别是划界分数的下界和上界,θ0为划界分数线的能力值,且θ1=θ0-δ,θ2=θ0+δ。 θ1,θ2之间的宽度 θ2-θ1=2δ被称为“indifference region”,即无差异区间。2δ是被试分类判定在划界分数线附近所允许的误差区间,δ一般为0.1 至 0.3 之间(Lin,2011)[66],δ越大则被试分类准确性下降,而测验长度缩短。SPRT方法下似然比率LR的计算公式:

其中xi是某被试在试题i上的得分,为1或0分;P(θ1)、P(θ2)分别为被试在能力 θ1、θ2上正确作答概率的期望值;h是测验目前已经测试了的最大题量。 同时设定A=(1-β)/α,B=β/(1-α),α、β 为 I型错误和II型错误的概率,α、β需要预先设定,在一些研究中设定 α=β=0.05[67-69]。
如果似然比率LR≤A,那么将接受虚无假设,即被试判定为未通过,测验终止;如果LR≥B,那么将接受备择假设,即被试判定为通过,测验终止;如果A≤LR≤B,那么继续测下一道试题。如果测验的测试题量已经达到最大允许题量,而且A≤LR≤B,那么此时就属于对被试强制分类:如果LR≤1,那么被试判定为未通过;如果LR>1,则被试判定为通过。
以上是SPRT终止规则对被试能力分类的统计算法。当VL-CCT采用以划界分数线为参照模式的选题策略时,同时配合SPRT作为测验终止规则更为有效,测验长度较短,而且有更好的分类准确性(Lin,2011)。
SPRT方法后来被许多研究者加以发展,Wouda和 Eggen(2009)、Finkelman(2008)等人的研究中论述了删节SPRT方法(Truncated sequential probability ratio test,TSPRT)和随机截尾 TSPRT 方法(stochastically curtailed SPRT,SCTSPRT)[70,71]。 TSPRT 方法是SPRT的改进形式,当被试作答试题题量小于最大测验长度N时,TSPRT方法的判定方法与SPRT一致。当被试作答试题题量等于最大测验长度N时,那么测验终止。如果公式(3)中的
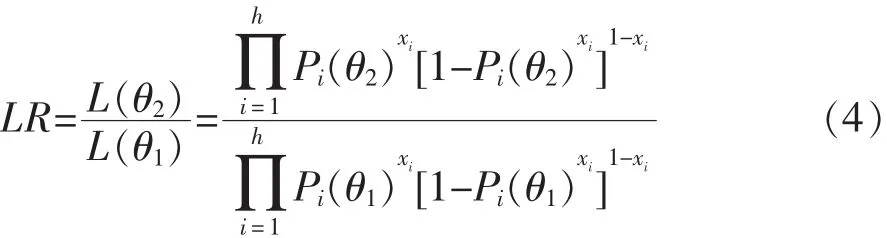
假定C为一个常量,且logC=(logA+logB)/2。此时判定方法为:如果公式(4)中的LR≥C,则被试判定为通过;否则,则评定为未通过。并且其中A≤C≤B。
Finkelman(2008)在TSPRT的基础上进一步提出了随机截尾TSPRT方法 (stochastically curtailed TSPRT,SCTSPRT)[72],该方法是当被试已作答题量k等于最大测验长度N时,与TSPRT方法的判定方法一致;在当被试已作答题量k小于最大测验长度N时(即k<N),在TSPRT方法的基础上进一步增加终止规则。SCTSPRT增加终止规则时,需要预先设定能力分界点 θ0的概率值 γ',γ, 并且 0.5<γ',γ≤1,γ'、γ设置一般为0.8至0.95之间,而不接近或等于1。γ',γ 也可以设置为同一个概率值。 同时令Pθ1,θ2(LR)为被试作答情况在(θ1,θ2)区间积分分布的期望概率。SCTSPRT增加终止规则以下两条:当k<N时,(1)如果似然比率LR≤A,或者LR<C且Pθ1,θ2(LR)≥γ,那么被试判定为未通过,测验终止;(2)如果似然比率LR≥B,或者LR>C且Pθ1,θ2(LR)≥γ',那么被试判定为通过,测验终止。
第二种终止规则:能力置信区间方法(ability confidence intervals,ACI)。该方法是在测试过程中,使用被试的即时能力估计值ˆ和条件测量标准误建立判断置信区间[73-75],其判断置信区间的计算公式为:

其中zα为(1-α)置信区间所对应的标准差,95%置信区间时zα值为1.96。CSEM则根据被试已测试题的项目信息量总和来计算,即如果此能力置信区间都高于划界分数线,则该被试判定为通过;如果此能力置信区间都低于划界分数线,则该被试判定为未通过。如果此能力置信区间包含了划界分数,则需要继续测试。当采用以被试能力估计为参照模式的选题策略时,往往需要配合ACI策略作为测验终止规则,即需要被试能力估计值达到某一能力精度(或置信区间)。
Thompson(2011)提出SEM可以分两种计算方法[76],包括理论最大值的CSEM和观察分数的CSEM。理论最大值的CSEM的计算方法为根据某一被试目前已测试题所组成的测验,在能力区间[-3,+3]每隔0.01分别计算的测验信息量并选择其中的最大值。观察分数的CSEM的计算方法是依据被试已作答试题所组成的测验,并根据牛顿迭代方法估计的能力估计值来计算测验信息量。在一般研究中,观察分数的CSEM应用较多。
第三种终止规则:拓展似然比方法(generalized likelihood ratio,GLR)。SPRT方法一般情况下是将划界分数的上界和下界 θ0、θ1设为固定值,Thompson(2011)提出拓展似然比方法方法(GLR 方法)[77],在一定的测验条件下,将似然比率计算公式中的上下界 θ1、θ2用被试的极大似然估计值来替代, 其计算公式为:

如果 θ1<θˆmax<θ2, 则LR计算方法保持不变,即除了以上LR计算方法不同之外,GLR方法的虚无假设、判定方法与SPRT终止规则一致。 Thompson(2011)在VL-CCT终止规则比较研究中得出,与SPRT、ACI方法相比,GLR方法在不损失分类准确性的前提下能缩短测验长度[78]。
第四种终止规则:贝叶斯决策理论方法(bayesian decision theory,BST)。 此方法是在贝叶斯选题策略的基础上,在测验终止时进一步对被试最终的能力估计值进行分类[79]。贝叶斯决策理论方法主要是作为选题策略使用,而作为终止规则相对较少 使 用 (Thompson,2009),Glas 和 Vos(2006)、Vos(2000)等少量研究使用了贝叶斯决策理论方法作为终止规则[80,81]。
在以上四种终止规则中,SPRT方法及其变式在VL-CCT研究中使用最多,ACI方法使用情况次之,拓展似然比方法、贝叶斯决策理论方法这两种终止规则使用较少。研究者认为,SPRT方法适合偏态分布的题库,而ACI方法更适合于均匀分布的题库(Lin&Spray,2000;Thompson,2007)[82,83]。 Spray 和Reckase(1996)的研究结果表明,在一般情况下SPRT策略要优于ACI方法[84]。
在VL-CCT下测验终止时,需要给定一个或多个被试分类的划界分数线。当划界分数线为一个时,划界分数线往往以-0.5、0.0、0.5为划界点,例如Thompson(2009)以-0.5 为分界点[85]、Huebner和 Li(2012)以 0.5 为分界点[86]、Wang 和 Huang(2011)以0.0为分界点[87],等等。当划界分数线为两个或两个以上时,被试划界分数线的划分方式可以分为两种类型。第一种类型是依据能力量尺的能力点作为划界分数线的依据,此类型往往是依据达到测验指定的能力标准进行分类。例如,Wang和Liu(2011)在两个划界分数线时设定在-1、+1,在三个划界分数线时设定在-1.5、0、+1.5[88]。 Weissman(2007)三个划界分数线设定为-0.3、+1、+2[89]。 Yang、Poggio 和 Glasnapp(2006)将四个划界分数线设定为-1.8、-0.6、+0.6、+1.8[90]。 Wouda 和 Eggen(2009)、Eggen 和 Straetmans(2000)将两个划界分数线设定在-0.13、+0.33[91,92]。第二种类型是依据被试分布的百分比作为划界分数线的依据,此类型适合将被试人数均匀分为几个等级。例如,van Groen、Eggen 和 Veldkamp(2014)将两个划界分数线设定在被试能力分布的33%和66%位置[93],在三个划界分数线时设定在被试能力分布的25%、50%、75%位置,在四个划界分数线时设定在被试能力分布 20%、40%、60%、80%位置;Gnambs和Batinic(2011)在两个划界分数线时设定在被试能力分布 25%、75%位置[94]。
(六)能力估计方法
CAT研究中常用的能力估计方法有极大似然估计方法(maximum likelihood estimator,MLE)、期望后验能力估计方法(expected a posteriori,EAP)、极大后验能力估计方法(maximum a posteriori,MAP)等三种基本方法及各种变式。而VL-CCT研究中也是使用这些基本能力估计方法及其变式。Yang、Poggio和Glasnapp(2006)在VL-CCT模拟研究中比较了MLE、MAP、EAP、 加权极大似然估计方法(weighted likelihood estimator,WLE)、贝叶斯估计方法(Owen’s method,OWN)五种能力估计方法,发现 MAP、OWN方法下测验测量误差较小,被试分类准确性相对较高[95]。
(七)评价分析
对于CAT研究最后得到的测验数据都需要进行统计评价分析。CAT测验数据的评价指标也都可以适合VL-CCT测验的评价,主要归纳为以下五个方面:(1)反映模拟返真性能的指标,包括偏差Bias、平均绝对值误差(MAE)、均方根误差RMSE(或均方误差MSE)等;(2)反映测验的测量准确性、测验精度方面的指标,包括标准误、测验信息量等。(3)反映题库安全性方面的评价指标,包括试题最大曝光率观测值、测验交叠率、试题使用频数的卡方统计量χ2等;(4)反映题库利用率方面的评价指标,包括题库中被调用试题所占的比例、题库中所有试题调用次数的标准差、从未调用试题的数量、曝光率低于0.02的试题量等;(5)反映测验效率方面的评价指标,如平均测验长度(average test length,ATL,也称为人均用题量,其计算方法是将m个被试重复n次模拟的测验长度累加和,再除以m*n)。平均测验长度越短、人均用题量越少,则测验效率越高。平均测验长度也是VL-CCT中被试分类效率的主要评价指标之一。
此外,近年来研究者还提出了专门适合VL-CCT对被试分类的评价指标,包括两个方面:
一是反映测验效率方面的评价指标,包括测验效率、相对测验效率评价指标。Patton、Cheng、Yuan和Diao(2013)在研究中使用测验效率、以及相对测验效率来分析测验分类效率[96]。测验效率是指所有测试试题的信息量的平均值。相对测验效率,是指用能力估计值进行计算的测验信息量与用期望估计值进行计算的测验信息量之比。
二是反映对被试分类准确性方面的评价指标,包括被试正确分类的百分比[97](percentage of correct decision,PCD,Lin,2011)、 真实能力属于掌握的测试者的正确分类百分比[98]、强制分类的百分比[99](forced classification rates)。被试正确分类的百分比主要反映对被试总体的分类正确性情况,其计算方法是PCD=(A+C)/N,被试模拟初始值归属于合格且估计值也归属于合格的被试人数A,加上被试模拟初始值归属于不合格且估计值也归属于不合格的被试人数C,这两类被试的累加和占总人数N的比例。真实能力属于掌握的测试者的正确分类百分比,此指标关注真实水平属于掌握的那部分被试的正确分类情况,特别适用于合格标准严格的资格证考试。强制分类的百分比计算方式为:当考生在既定的最大测验长度内无法被归类,此时只好强迫停止,并加以归类,此时被强迫停止测验的被试人数占测验总人数的百分比,强制分类的百分比可以间接反映测验选题策略或终止规则的分类效率。
在VL-CCT中,被试分类准确性与测验效率这两个方面往往是此消彼长,如何找到这两方面的综合评价指标呢? Finkelman(2008)、Huebner和 Fina(2014)在前人研究的基础上进行改进,进一步提出了测验效率与被试分类准确性的综合指标Loss[100,101],其计算公式为Loss=100*1w+Test Length。当被试分类错误时1w取值为1,分类准确时1w为0,公式中的100为分类不正确时的惩罚系数。当所有被试Loss平均值越小,那么测验分类效率、分类准确性的综合性能就越高。
三、VL-CCT的研究发展趋势与小结
(一)VL-CCT研究的热点与趋势评述
Groen和 Groen Van(2012)论述 VL-CCT 的重要组成部分是选题策略和被试分类策略 (终止规则),这也是多数研究者的一致观点。围绕VL-CCT的选题策略、被试分类策略是研究者关注的重点,近年来VL-CCT呈现以下几方面的研究热点与趋势:
第一,对多种选题策略进行比较,选择能同时兼顾较高的被试分类准确性和被试分类效率的选题策略是VL-CCT研究的主要热点。在VL-CCT测验情境下,被试分类效率(测验效率)、被试分类准确性存在着一定的此消彼长的关系。许多研究者试图寻找这样一种较优的选题策略:在保证被试分类准确性不降低的情况 (被试分类准确性在许多研究中都保持在90%至95%以上),适当缩短测验长度,提高被试分类效率。 近年来在VL-CCT测验情境下的选题策略比较研究有很多,包括Huebner和Li(2012)、Lin(2011)、Wang 和 Huang(2011)等等[102-104]。
Lin(2011)对比分析了 FI方法、KL 方法、加权似然比方法(WLOR)、交互信息函数方法(MI)四种选题策略[105],当被试分为掌握与未掌握两类,在三种测验情境下(包括无内容平衡、有内容平衡控制、有内容平衡控制和试题曝光率控制),四种选题策略在被试分类准确性、试题曝光率、试题利用率方面都很相近,在测验长度方面WLOR方法比其他三种选题策略都要短一些。
Wang&Huang(2011)比较分析了FI选题策略、FI后验分布方法、PG方法、改进的APG方法四种选题策略[106],并使用Sympson&Hetter曝光率控制方法[107](SH,Sympson&Hetter,1985),同时结合在线试题冻结方法 (Wu&Chen,2008)[108], 此方法简写为SHOF。研究结果发现,加入试题曝光率控制方法即SHOF方法后,被试分类准确性基本没有变化,题库利用率提高,试题最大曝光率水平下降,而不足的是,被试强制分类率升高,平均测验长度增大。
Huebner&Li(2012)在 VL-CCT测验下使用 FI选题策略在划界分数线的CB模式[109],并结合随机化试题曝光率平衡算法,研究结果显示,在维持测验分类精度基本不变的情况下,随机化的试题曝光率平衡算法在减少过度曝光率的试题数量、实现试题曝光率均衡(即提供了题库利用率)方面,优于单独的Sympson和Hetter(1985)提出的SH方法。
在试题曝光率控制、测验交叠率控制的研究方面,Huebner(2012)在FI选题策略下以 SPRT为终止规则[110],比较了三种试题曝光率控制方法,包括SH方法、限制方法(RT)、项目合格方法(IE)。 Chen 等(2014)对 Chen(2010)的在线测验交叠率控制方法进行改进[111,112],并进一步比较了VL-CCT下8种测验交叠率控制方法,认为改进的测验交叠率控制方法SHG1方法能够在不损失被试分类精度的情况下,较好地控制测验交叠率。
以上研究设计中对许多选题策略 (试题曝光率控制、测验交叠率控制方法)进行了比较,同时对VL-CCT的测验分类准确性、测验效率、题库曝光率、题库利用率等进行了分析。然而,以下研究设计方向还有待于进一步探讨,例如:(1)专门适合VLCCT的选题策略,包括加权似然比方法(WLOR)、交互信息函数方法(MI)、交互信息函数多重分类方法(MIMI)这三种策略,与多种试题曝光率控制、测验交叠率控制方法之间进行交互组合设计比较;(2)专门适合VL-CCT的三种选题策略下CB模式和EB模式,与多种试题曝光率控制方法、测验交叠率控制方法之间的交互组合设计比较;(3)VL-CCT下对内容平衡、试题曝光率控制、测验交叠率等多个测验目标,使用加权离差方法、最优指数方法 (Cheng&Chang,2009;潘奕娆,丁树良,尚志勇,2011)等方法同时约束控制进行最优化组合的研究设计[113,114]。
第二,VL-CCT的终止规则及其发展变式的研究,以及终止规则之间的比较研究是VL-CCT研究的第二个热点领域。正如前文“(5)终止规则”所论述,近年来研究者在SPRT方法、ACI方法这两种基本终止规则的基础上提出了多种发展变式。此外,研究者还提出了其他改进变式,例如:(1)Finkelman(2010)在标准的SCTSPRT的基础上提出了SCTSPRT的三种变式[115],这些变式是使用新的能力估计值方法来替代SCTSPRT方法划界分数线的上下界θ1、θ2。这三种新的能力估计方法分别为极大似然估计估计算法、能力置信区间算法、贝叶斯后验估计算法。模拟研究发现,SCTSPRT的三种变式能缩短测验长度,并且在多数测验情境下,测验效率与被试分类准确性的综合指标优于标准的SCTSPRT。(2)Nydick(2014)对SPRT进行改进,使用被试能力期望值来代替SPRT的能力估计值,提出期望SPRT方法,根据期望SPRT计算的对数似然比[116]可以使得FI选题策略在选择试题时选择FI信息量在能力点(θ0+θˆ)/2上最大值的试题,从而缩短测验长度缩短,而不损失被试分类准确性。(3)Huebner和Fina(2014)在此GLR终止规则基础上提出了SCGLR方法[117],SCGLR方法是SCTSPRT和GLR的结合,研究结果发现,SCGLR方法同时具有SCTSPRT和GLR这两种方法的优点。
而且,对终止规则及其变式进行比较研究也是目前的研究热点。例如Wang和Huang(2011)的研究结果显示[118],在难度参数为正态分布的题库中,与ACI方法相比较,SPRT方法下的被试分类准确性较高,被试强制分类率较低,但平均测验长度相对较长,题库利用率相对较低,试题最大曝光率水平相对较高。在Rasch模型下,Eggen(2011)比较了TSPRT、SCSPRT、最优传统线性方法(optimal traditional linear tests,属于固定测验长度)三种终止规则[119],发现TSPRT和SCSPRT的平均测验长度较小,优于最优传统线性方法,同时SCSPRT的平均测验长度要少于TSPRT。文剑冰和王文昊(2008)通过模拟研究比较了SPRT、ACI、测验目标信息量[120]、贝叶斯决策理论(BDT)四种测验终止规则,结果显示不同的测验终止规则在不同情况下其效率和准确性表现有差异。
第三,以往VL-CCT的多数研究中被试分为两类(即只有一个划界分数线),近年来对被试分为三类及三类以上的研究逐渐成为研究者的探讨方向。在实际测验中,有时需要将被试分为三类或三类以上,例如将被试分为优秀、合格、不合格三个等级,或优、良、中、差,以及在人格测量中,分为高分组、中间组、低分组三类,或无症状组、中间组、有症状组。Gnamb 和 Batinic(2011)将被试分为三类:不合格、中等、优秀,在被试分三类的情况下将增加题库的题量压力,题库需要增加那些适合划分优秀分界点的试题。van Groen、Eggen 和 Veldkamp(2014)分别设计了两、三、四个划界分数线的测验情境[121],研究结果显示,在同一个题库以及其他测验条件下,划界分数线的个数越多,测验长度相对越长,被试分类准确就越低。Seitz和Frey(2013)在多维能力测验研究中发现,划界分数线为4个时的测验长度比划界分数线为1个时要大许多[122]。
当被试分为两类时,可以使用被试正确分类的百分比、真实能力属于掌握的测试者的正确分类百分比这两个指标来评价被试分类一致性;而当被试分为三类或三类以上时,就不适合使用以上两个指标。因此,VL-CCT下怎样对多个分类的被试分类一致性进行估计也是研究者探讨的问题。Cheng和Morgan(2012)等研究者借鉴纸笔测验中的标准参照测验对被试分类的一致性估计系数Kappa的计算[123],对VL-CCT的被试多等级分类一致性进行分析,发现最优指数方法要优于其他选题策略方法;而且被试分类的等级数量越多,被试分类的一致性则越差。Cheng、Liu 和 Behrens(2014)从公式推导与数理分析的角度探讨了被试分为三类及三类以上时[124],能力估计的标准误减小,那么被试分类准确性和一致性将提高。
第四,VL-CCT研究应用领域的拓展,包括拓展到多维能力测量、人格测量等领域。(1)在多维能力测量方面。例如,Seitz和Frey(2013)在CAT与多维能力CAT下比较了SPRT终止规则对被试的分类情况[125],发现多维能力CAT下被试分类准确性要高于CAT。(2)在人格测量中也往往需要将被试分为两类或两类以上,例如将被试分为两类(正常、不正常),或三类(正常、中间状态、不正常)。近年来VL-CCT在人格测量方面的研究,如Smits和Finkelman(2013)在等级反应模型下[126]以自陈人格问卷的试题形式进行CAT与VL-CCT模拟测试,发现测试的题量会影响被试分类准确性。Wang和Liu(2011)在展开模型下(generalized graded unfolding model,GGUM)进行VL-CCT模拟[127],发现试题的等级分点数量越多,被试分类等级数量越少,则被试分类的准确性越高。
此外,以往出现在CAT下的研究主题,目前研究者也在VL-CCT下进行深入探讨。例如:(1)关于题库参数估计对测量误差的研究。van der Linden和Glas(2000)讨论在CAT下题库项目参数估计对测量误差的影响,而在VL-CCT下探讨了题库项目参数估计的误差对被试能力分类、测验效率的影响[128]。(2)将被试作答反应时间结合到选题策略中的研究。Fan、Wang、Chang 和 Douglas(2013)在 CAT 形式下,将被试作答反应时间与α分层选题策略结合,提出结合被试作答反应时间形成半参数化的选题策略模式[129]。Sie、Finkelman、Riley 和 Smits(2015)在 VL-CCT下提出了将被试作答反应时间与FI选题策略结合形成新算法,模拟研究结果发现,此新算法可以使测验的平均时间减少,被试分类准确性略微提高[130]。
(二)小结
VL-CCT作为CAT的一种特殊形式,其主要组成部分与CAT基本一样,包括测量模型、量尺化的题库、测试起点、选题策略,终止规则、能力估计方法、评价分析共七个组成部分。VL-CCT的重要特点是发展出了专门适合被试分类情境下的选题策略、终止规则,以及在被试分类准确性、测验效率方面的评价指标。与固定测验长度的CAT测验相比,VLCCT能够用较短的测验长度实现对被试能力水平的有效分类。
在VL-CCT下寻找到能同时兼顾较高的被试分类准确性和被试分类效率的选题策略 (包括试题曝光率控制、测验交叠率控制)是主要研究趋势。提高被试分类准确性,发展新的终止规则及其变式,以及在VL-CCT下将多种选题策略、测验终止规则之间进行交叉设计,以寻找最佳的组合,这些将是今后VL-CCT研究拓展方向之一。此外,在VL-CCT下对被试分为三类及三类以上的研究,在人格测量、多维能力测量的拓展应用也是今后研究探讨的方向之一。
VL-CCT可以适合学校教育测验与评估(Groen和 Groen Van,2012),包括:(1)对学生成绩进行分等级,(2)对学习内容的掌握过程进行评估,(3)对学生群体进行分类以进行分类指导,(4)教育质量评估[131]。各能力合格水平测验、职业资格测验等也可以使用VL-CCT,因为在对被试评定分类这方面,VL-CCT要优于CAT。
