基于聚类和相似度计算的陆空通话词向量评估
2020-11-16向倩
向 倩
(中国民航大学 空中交通管理学院,天津 300300)
0 引 言
陆空通话用于管制员与飞行员交互空中交通动态信息,是保障航空安全和效率的最基础手段,是一种全球通用的管制员和飞行员英文对话标准。为加强管制员培训效果,满足非英语国家陆空通话用语规范和发音标准的需求,提出管制员飞行员人机对话系统,利用计算机响应管制指令替代机长席位。对话系统分为语音识别模块和语言理解模块。语音识别与语音合成技术[1-2]已广泛应用于陆空通话领域,而直到最近几年,自然语言理解研究才得到了初步发展。2017年,卢薇冰[3]和路玉君[4]基于改进CNN和RNN模型利用词向量对陆空通话语义相似度进行比较,辅助计算机判断复诵过程中的失误。
2013年,词向量被证明能捕获更复杂的语言属性,最大限度保留单词语义、结构信息[5]。人机对话系统语言理解模块基于神经网络,以对话文本为网络实际输入,文本向量为本质输入,高质量的词向量能赋予神经网络更多学习信息,因此除优化系统网络模型外,需要对词向量进行评价以保证源头输入向量的质量。
早期词向量内部评估通过直接测量语义相关性和几何相关性来测量词向量的质量,包括相似性计算、类比、分类等方法[6]。后来的学者更加关注词向量在下游任务的表现,使用词向量作为下游任务的输入特性,并度量特定于该任务的性能指标的变化称为外部评估方法。Schnabel[7]、Anna[8]等人结合了传统内部评估方法和诸如名词短语分块、命名实体识别、情绪分类、推理任务等外部评估方法。Tulkens[9]提出了利用词向量将荷兰语方言文本映射到文本原始分类区域,借此衡量词向量的相似分类特性。
对于低资源语言如陆空通话用语,由于缺乏前人标注文件和工具材料,需要制定自身的评估方法和标准。词向量的首要功能是表征语义,对词向量质量评估即对词向量表征语义的能力进行评估。考虑到下游管制员飞行员人机对话系统的任务,制定了一个基于K-Means的概念分类和基于Siamese网络句子相似度计算的陆空通话词向量评估方法。首先建立陆空通话数据集,借助word2vec模型生成词向量;其次利用概念分类的方法,通过比较词向量分类和人工分类词典的差异来证明词向量表征语义区分单词的功能;最后建立陆空通话指令比较集,通过词向量来比较指令相似度,利用判断准确率来进一步证明词向量表征语义的功能。
1 语义表示方法
自然语言理解的发展得益于语义表达技术的发展,早期人类知识被表示为知识库的形式;随着计算机技术的更新,以自然文本为输入,高维稀疏向量为输出的传统语义表达方法开始盛行[10];然而高维稀疏的语义表达方法无法有效地表达出词语之间的相似度信息,1986年Hinton[11]提出了词的分布式表示,能通过刻画词的多重属性更高效表示词义和语言结构等信息,在形式上表示为低维连续的向量。以管制员指挥国航1421航班调整航向的指令为例,展示了两种语义表示方法的具体形式,如表1所示。

表1 语义表示方式示例
每个单词以几十上百维的向量形式表示,涵盖了语义、语法、上下文关系等多种特征。词向量将单词映射到向量空间里,通过计算单词的“距离”信息来捕捉它们之间存在的句法(结构)和语义(语义)等相关关系。
2 陆空通话词向量训练
2.1 陆空通话语言结构分析
陆空通话语料数据集来源于飞行进离场阶段真实通话录音文件。进场阶段是指航路飞行航空器下降对准跑道的过程,离场阶段是指离场航空器加入航路飞行的阶段。该阶段涉及到的空管指令主要包括:高度、速度、航向、进离场程序。其对话结构如下:
对方呼号+通话内容
复述通话内容+己方呼号
示例:
C:CCA1421,Dongfang Approach,radar contact.
P:Dongfang Approach,CCA1421.
C:CCA1421,turn right heading 110 for spacing.
P:Right heading 110,CCA1421.
管制员用语分为许可类、指令类、限制类、报告类、证实类和信息类,飞行员用语分为请求类、状态报告类、复讼类。
陆空通话标准用语具有以下几个特点:语法结构单一,指令长度适中,指令重复率高,词汇量有限,属于小型语料库。分析陆空通话语言结构及词向量评估方法可得出:
(1)对话多为祈使句和陈述句,不具有主观情绪色彩,因此不能用情感分类来评估陆空通话词向量。
(2)语料库词汇较少,指令之间存在较弱的上下文语境关系,单词之间缺乏有效的类比关系,故不能用类比(关系识别)来评估。
(3)指令主语一般为航空器呼号,选择偏好用于判断句子语义和动宾等逻辑信息,同样也不适合该方法。
多个传统词向量内部评估标准均不适用于陆空通话词向量的评估。结合管制员飞行员人机对话系统需求和词向量内部、外部评估标准,利用概念分类和句子相似度计算来评价陆空通话词向量。
2.2 词向量生成训练
根据上述陆空通话呼叫结构形式和终端区信息,建立指令类-复讼类常规陆空通话数据集,共计360个单词,3 167 641条指令-回答语句对,涉及5架航空器、1家管制单位。
目前应用最为广泛的词向量训练方法有word2vec、Glove,经过众多研究显示word2vec在大部分测评指标优于Glove。word2vec可利用CBOW和Skip-gram两种方法产生词向量,CBOW是输入已知上下文,输出对当前单词预测的模型,Skip-Gram是推测当前单词上下文单词的模型,模型网络结构见图1。

图1 CBOW网络结构、Skip-gram网络结构
简而言之,word2vec模型其实是一个由输入层、隐藏层、输出层组成的简单神经网络,隐藏层为线性的单元。该模型以One-Hot向量为输入,经过训练之后,使用输入层和隐藏层之间的连接权重矩阵表示单词之间的关系,输出层与输入层具有相同维度。
(1)CBOW模型。
CBOW模型又称连续词袋模型,以某中心词临近的上下文单词所对应的词向量为输入,输出该特定中心词的词向量。

(2)Skip-gram模型。
Skip-gram颠倒了CBOW的输入输出关系,即已知当前单词,预测其上下文单词。不根据上下文单词来猜测目标单词,而是推测当前单词可能的前后单词。该模型输入为某一中心词的词向量,而输出则是该中心词对应的上下文词向量。
建立一个可以沿文本滑动的时间窗,窗口大小N表示窗里含特定词在内的单词数目,利用该滑动窗就能统计出每个单词可能出现的上下文单词;为加快训练速度,将预测相邻单词这一任务改变为提取输入与输出单词的模型,并输出一个表明它们是否是邻居的分数(0表示“不是邻居”,1表示“邻居”)。这个简单的变换将需要的模型从神经网络改为逻辑回归模型,因此更简单,计算速度更快。同时为避免所有例子都是邻居即准确率为100%时而产生低质量词向量,可在数据集中引入不是邻居单词样本作为负样本,为这些样本返回0,并随机填充输出单词;最后训练神经网络模型,减小损失值,不断更新模型参数用以表示单词之间的关系。
CBOW在小型数据库中表现更佳,而Skip-gram多用于大型语料库,陆空通话语料库为小型语料库,更适用前者。词向量生成训练选择gensim库中的word2vec模块,在陆空通话数据集上进行训练产生词向量,窗口大小设置为5,维度设置为300。
3 陆空通话词向量评估
传统词向量评估基于更高得分向量必然会改善下游任务结果的假设,往往根据得分来比选不同方法产生的词向量。然而该假设有时并不成立,不同的自然语言处理任务可能依赖于词向量的不同语言特征,不能将这些评估分数用作向量质量的绝对评估标准。词向量作为无监督技术的产物缺乏目标值比较,如果不参考下游任务的性能,不能较客观地对其质量进行评估,因此针对特殊任务需要一套绝对的指标来评估词向量。
陆空通话指令分类明显,内部评估任务设定为概念分类实验,根据词向量将具有相同相似属性的单词聚类,浅层分析词向量词义和词性的表征效果[12]。外部评估任务设定为指令相似度计算实验,通过对比基于词向量的句子相似度计算方法和基于wordnet、基于编辑距离的方法来佐证词向量表征语义的功能。
3.1 概念分类
手工制作陆空通话词典并标注分类,利用词向量将其所对应文本映射到文本的手工分类区域,通过计算映射准确率,判断是否可以在没有任何监督的情况下创建与手工制作资源等价的资源。
手工词典按指令类别分为4大类和19小类。大类:速度、高度、航向、其他进离场指令。小类:航向动作、航向数据、高度动作、高度数据、速度动作、速度数据、动作原因、方位、跑道、航路点、航空器呼号、进离场程序、管制单位、管制单位频率、距离数据、气压数据、应答机编码、介词、其他单词。
利用K-means将词向量聚类为10类。聚类数据i映射到原始分类中的数据个数和所占比例见公式1。各类别映射准确率见表2。

表2 聚类数据映射到原始分类中数据的比例

(1)
其中,i为聚类类别,m为大类类别(≤4),n为小类类别(≤19),count()为数据个数。
注:数据过少的分组忽略不计。
表2聚类数据的映射结果显示,当聚类数据较少时映射准确率较高,普遍能达到90%以上,分类特征明显。而当聚类数据较多时,由于单词涉及的航行动作多且复杂,映射准确率较低,不到60%。该结果从浅层证明了陆空通话词向量具有一定分类特性,符合陆空通话指令分类明显的特征。
利用t-SNE(t-distributed stochastic neighbor embedding)机器学习算法将300维词向量降至2维,图2可视化了词向量在二维空间的分布和词向量聚类结果,不同灰度代表不同单词分类。其中词向量的空间距离不代表向量的实际距离。

图2 陆空通话词向量聚类二维平面图
3.2 句子相似度计算
利用基于Siamese网络的句子相似度计算模型来判断两句陆空通话指令的相似程度,其结构如图3所示。通过比较该方法与其他计算方法的判断准确率来评价词向量。句子相似度计算的其他方法主要有基于编辑距离的方法、基于wordnet层级距离的方法,及其组合方法。
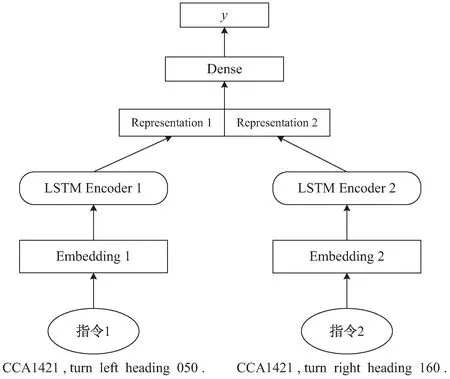
图3 句子相似度计算模型结构
基于编辑距离的方法是指计算两个句子之间,由一句话转成另一句话所需的最少编辑操作次数,次数越多,说明它们越不同,多以单词共现程度来衡量两句话相似度。这种方法从单词和语句表面结构出发,弱化了同义词的语义关系,可视为基于语言结构的度量方法[13]。
wordnet词典详细定义了每个单位的词性和词义,利用单词上下位关系构成分类树,基于wordnet层级距离的方法将分类树中的路径作为相似度计算的参数。这种方法从语句深层词义出发,可视为基于单词词义的度量方法,容易忽略掉反义词包含的可用上下文相关性[14]。对于字面不相似语义相似、语义不相似句子结构相似的场景需要更复杂的模型来捕捉语义和结构信息。
(1)网络结构。
Siamese网络是一种神经网络框架,利用2个共享权值的网络学习一对输入数据的差异,能同时考虑单词词义和语言结构[15]。具体使用LSTM来构建句子相似度计算模型,该模型由输入层、嵌入层、LSTM层、全连接层和输出层5部分组成。LSTM读取表示每个输入句子的词向量,它的最终隐藏状态即为每个句子的向量表示,这些句向量由词向量构成,它们之间的相似性被用作语义相似性的预测。该方法依赖于预先训练好的词向量作为LSTM输入,因此它将受益于词向量质量的提升。损失函数选择交叉熵损失函数binary_cross entropy,当x1和x2相等时loss=0,否则loss为一个正数,概率相差越大,loss越大。
(2)
其中,xi1表示第i个样本第1个属性的取值,xi2表示第i个样本第2个属性的取值。
(2)数据构造。
陆空通话指令比较集以{x1,x2,y}的形式构造,示例如下:x1和x2为两个句子,y为相似度标签,1表示相似,0表示不相似。比较集总计27 452对标注数据,训练集占70%,验证集和测试集各占20%和10%。其形式如下:
指令1
指令2
标签
示例:
CCA142,turn left heading 200 .
CCA142,turn left heading 200 for spacing.
1
CCA142,descend to 2100 meters.
CCA142,climb to 900 meters .
0
(3)模型训练。
随着训练轮数的增加,损失函数值呈下降趋势,准确率呈上升趋势,在训练轮数达到第34轮时,两者变化趋于平稳,准确率接近99%,损失函数值降到了0.002 8,模型基本达到收敛状态(见图4)。
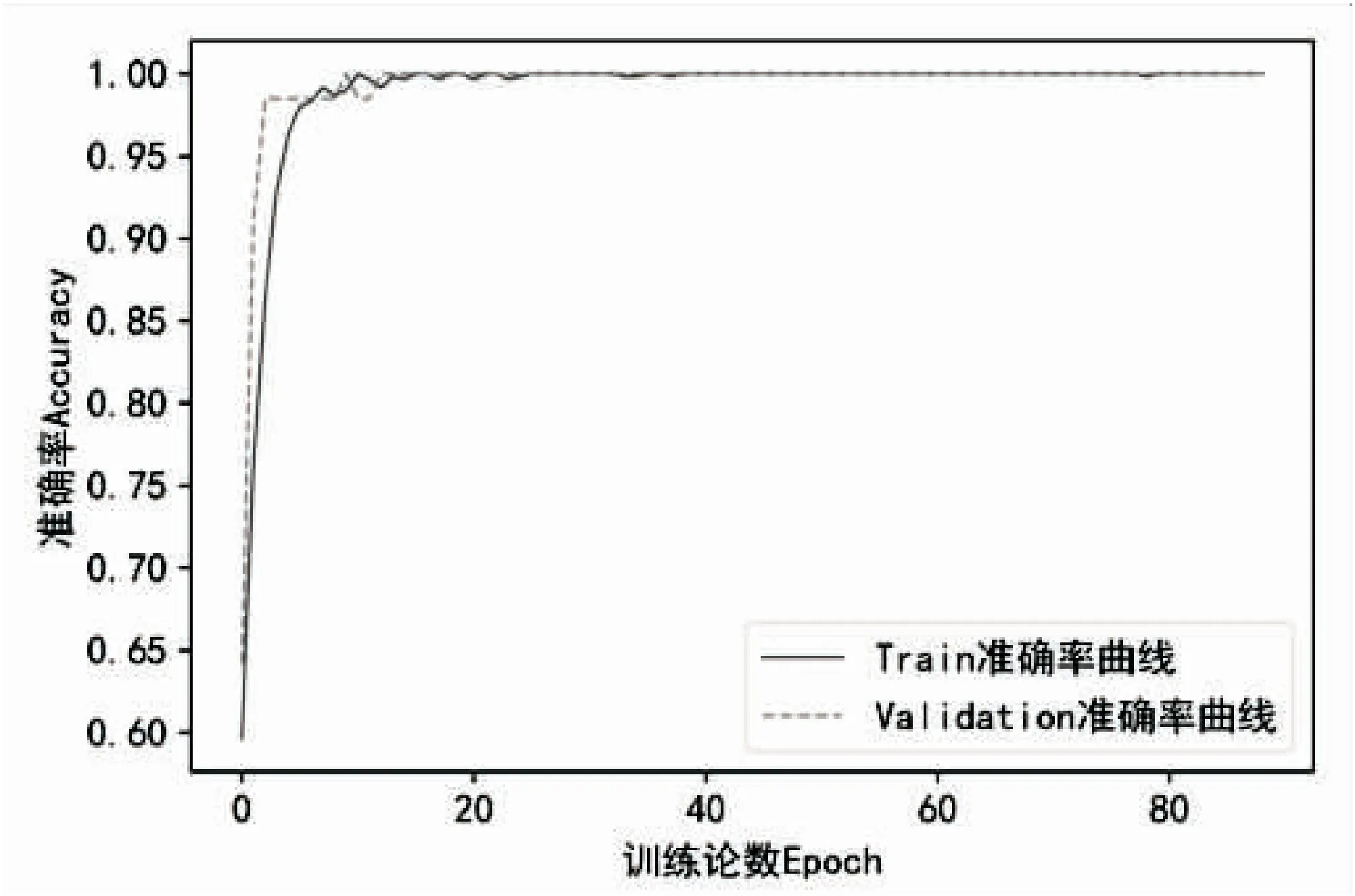
图4 模型准确率、模型损失函数值的变化情况
(4)结果分析。
以相似度0.9作为判断相似与否的分界阈值,相似度高于0.9则认为两句话相似,反之不相似。三种方法在测试集上的准确率如表3所示。基于编辑距离的方法表现最差,由于陆空通话对飞行动作和动作数据有确切要求,因此在语言结构不变的基础上变换单词为反义词时语义正好相反,而该方法无法准确度量语义,造成相似度比较准确率低的结果。基于wordnet层级距离的方法虽能够识别同义词和反义词,但语言结构变化会引起相似度计算减小,造成判断准确率下降。以神经网络和词向量来计算句子相似度的方法取得了较好的收益,准确率达到了93.6%,证明词向量是表征语义的良好手段,相对能更大限度蕴含词义和语言结构信息,作为网络输入能对下游管制员飞行员人机对话系统产生正面的影响。

表3 句子相似度算法比较
4 结束语
以近阶段常规陆空通话为知识来源,将概念分类和句子相似度计算纳入词向量评价当中。概念分类的准确率平均值达80.2%,浅层证明了词向量表征语义区分单词的特性。基于词向量的句子相似度计算准确达93.6%,远超基于词义和语言结构的其他方法,进一步证实了词向量表征语义的功能,具备作为下游人机对话系统输入的条件。
研究存在两点不足:构造比较数据集时方法不够规范,耗时长覆盖少;人为设定阈值作为相似与否的分界存在较大主观性。后续工作研究重点将围绕数据集构造、相似分界阈值设定展开。
