基于抽象汇编指令的恶意软件家族分类方法
2022-03-08李玉罗森林郝靖伟潘丽敏
李玉,罗森林,郝靖伟,潘丽敏
(北京理工大学 信息与电子学院,北京 100081)
恶意软件是指在未经用户许可的情况下收集敏感信息、控制用户设备、严重侵犯用户个人权益的软件[1]。目前,恶意软件检测方法根据检测时是否执行目标代码,分为静态分析[2-3]和动态分析[4-5]。随着深度学习在图像识别领域展现出强大的特征提取能力,并且归属于同一家族的恶意软件变体,其特征图像的纹理特征也十分相似,因此可视化技术开始应用在恶意软件任务中。根据可视化的目标,恶意软件可视化检测方法分为二进制文件可视化和动态行为可视化。二进制文件可视化将文件按字节排序,生成特征图像并识别所属家族[6-8],并未提取深层行为特征,仍依赖于待检测软件的二进制代码,易受到代码混淆的影响。
为了将恶意行为信息融入特征图像中,汇编指令逐渐成为可视化研究的重心。鉴于二进制文件存在加壳现象,难以自主生成反汇编文件,因此对于加壳文件需通过动态调试进行脱壳,再进行反汇编。获得汇编代码后,Zhang等[9]提出了基于图像识别恶意的软件检测方法(IRMD),从反汇编文件中提取操作码序列,构建2-gram操作码特征组,采用卷积神经网络(CNN)进行识别和分类,证明了操作码序列具有较强的行为特征表达能力,且同一家族的恶意软件变体在汇编指令层面具有相似的行为模式。受IRMD启发,Ni等[10]开发了基于局部敏感哈希的恶意软件分类方法(MSCS)。MSCS将每个操作码视为一个序列,以关注软件的整体行为特征,并引入局部敏感哈希算法生成特征图像,利用CNN进行软件的恶意性检测。与MSCS类似,Sun和Qian[11]通过循环神经网络(RNN)捕获指令序列内的时序特征,并对指令序列进行预测,一定程度上减小了变体技术对指令序列的影响。
上述可视化检测方法将软件行为融入特征图像中,但仅从操作码层面提取行为特征,并未结合操作数,导致指令语义缺失。同时,恶意软件变体通常在软件中插入无关的正常指令以隐藏恶意指令和恶意行为,且正常指令与恶意指令仅通过操作码难以区分,导致基于操作码序列的检测方法难以区分出无关指令,受代码混淆和花指令干扰较大,影响变体分类结果。
经分析,无关指令和恶意指令的区别仅在操作数上有所体现,但操作数的语义与运行环境密切相关,即同一个操作数在不同运行环境下的含义不同,因此难以提取。
针对基于汇编指令的恶意软件可视化家族分类方法中,操作数语义与运行环境密切相关而难以提取,导致指令语义缺失,难以正确分类恶意软件变体的问题,本文提出了一种融合抽象汇编指令和家族共性指令序列的恶意软件家族分类方法(malware family classification method based on abstract assembly instructions,MCAI),利用操作数抽象类型提取进行指令重构,使操作数语义脱离运行环境的约束而易于提取,并结合词注意力机制和双向门循环单元(Bi-GRU)构建双向结构指令嵌入网络,学习指令的行为语义,并利用深度层次网络捕获恶意软件家族共性指令序列,以减小恶意软件变体技术对指令序列的干扰,融合原始指令和家族共性指令序列构建特征图像,并通过CNN实现恶意软件家族分类。
1 MCAI原理
1.1 MCAI原理框架
MCAI原理如图1所示,包含指令重构模块、指令嵌入模块、家族共性指令序列提取模块、特征图像生成模块和特征图像分类模块。指令重构模块通过操作数抽象类型提取重构指令,使操作数语义脱离运行环境的约束,丰富指令的行为语义,并对重构后的指令进行词法分析,识别指令内部的各个元素,以便后续特征提取;指令嵌入模块利用词注意力机制和Bi-GRU构建指令嵌入网络,学习指令的行为语义,获得指令的向量表示,并通过深度层次网络学习家族共性行为模式,对指令进行预测;特征图像生成模块将预测结果和嵌入结果组合成双通道恶意软件特征图像;特征图像分类模块利用CNN捕获图像的局部特征,并给出家族分类结果。
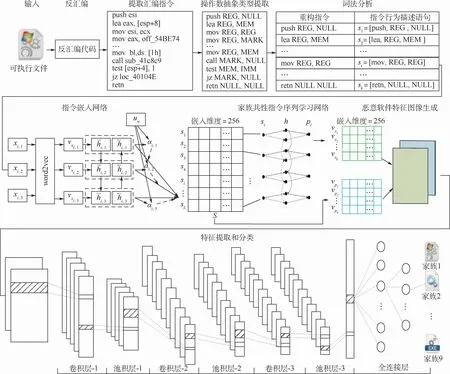
图1 MCAI原理框图Fig.1 Functional block diagram of MCAI
1.2 指令重构模块
汇编指令是程序在操作系统层面的基本执行单元,因此能够反映程序的操作和意图。通过反汇编器,可以获得样本的反汇编代码p。其中,p由多条指令Ii组成,i∈[1,k]。若恶意软件已被加壳,需先经过脱壳处理,再进行上述反汇编过程。
x86指令语法规定,汇编指令Ii由一个操作码和多个操作数组成。操作码表示指令的行为类型,操作数体现了指令的操作目标。因此,汇编指令中的每一个组成元素都是指令行为的一部分,仅通过操作码或操作数无法完整描述指令行为。然而,操作数的语义存在不确定性,同一个地址在不同的软件中可能表示不同的函数,因此在过去的检测和分类方法中,如基于RNN的恶意软件可视化分类方法(RMVC)、MCSC等,仅保留了操作码序列作为特征,导致无法区分出恶意软件变体内的正常指令,影响分类效果。为了充分利用操作数信息,使操作数的语义脱离运行环境的限制,方法对操作数类型进行抽象,定义了内存地址(MEM)、寄存器(REG)、立即数(IMM)、标号(MARK,包括函数名、跳转地址等)和无操作数占位符(NULL)5类操作数类型,用操作数类型代替操作数完成指令重构。
由于每条汇编指令内操作码数量不一致,对操作数数量进行规范化处理,即通过NULL实现指令对齐,使每条指令的操作数数量均为2个,补齐后的指令集如图2所示。

图2 操作数类型抽象Fig.2 Operand type abstracting
对规范化的指令I′i进行词法分析,识别指令内部的各个元素,并构造指令行为描述序列si。其中,si由3部分组成,分别为操作码和2个抽象操作数类型。
1.3 指令嵌入模块
指令嵌入网络将每个指令行为描述序列嵌入至其向量表示中,并学习指令的行为语义,以便特征提取网络可以提取行为特征。指令嵌入网络由word2vec[12]、Bi-GRU[13]和词注意力模块[14]构建,如图3所示。
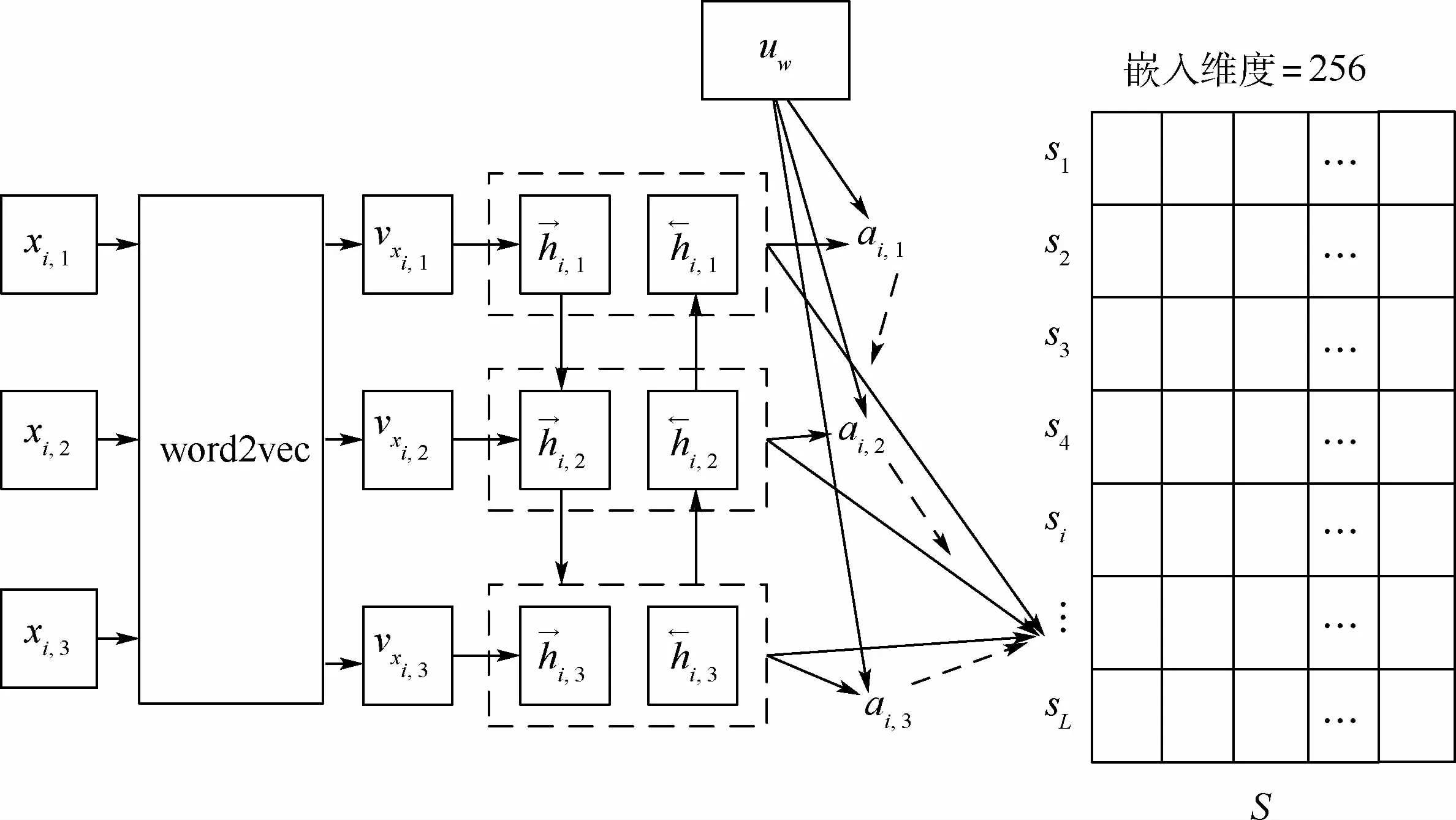
图3 指令嵌入网络Fig.3 Instruction embedding network
利用word2vec构建词嵌入网络,训练si中每一个单词xi,j的向量表示。
在词向量基础上,利用Bi-GRU构建句子嵌入网络以训练每条指令的向量表示。鉴于指令内部的序列信息为双向关联,因此采用Bi-GRU分别从前向和后向捕获指令内部的序列信息,并通过词注意力机制为指令内的各个元素自动化分配权重,以进一步突出指令的关键信息,增强指令的行为语义。
指令嵌入网络从3个方面学习指令的行为语义信息。word2vec提取每个单词的基本上下文信息,Bi-GRU分别从前向和后向学习了输入指令内部各元素的顺序信息,词注意力模块从指令内元素的上下文中学习元素的权重,并加权得到指令最终的嵌入结果。
1.4 家族共性指令序列提取模块
属于同一家族的恶意软件具有相同的行为特征,在汇编代码中体现为具有相似的指令序列,并且指令序列中具有较强的时序性。双向循环神经网络(Bi-RNN)[15]具有较强的时序特征提取能力,通过Bi-RNN可以学习恶意软件家族的通用行为特征。
为了更好地说明Bi-RNN的学习过程,图4中用标号代替指令,每一个标号对应一条指令。
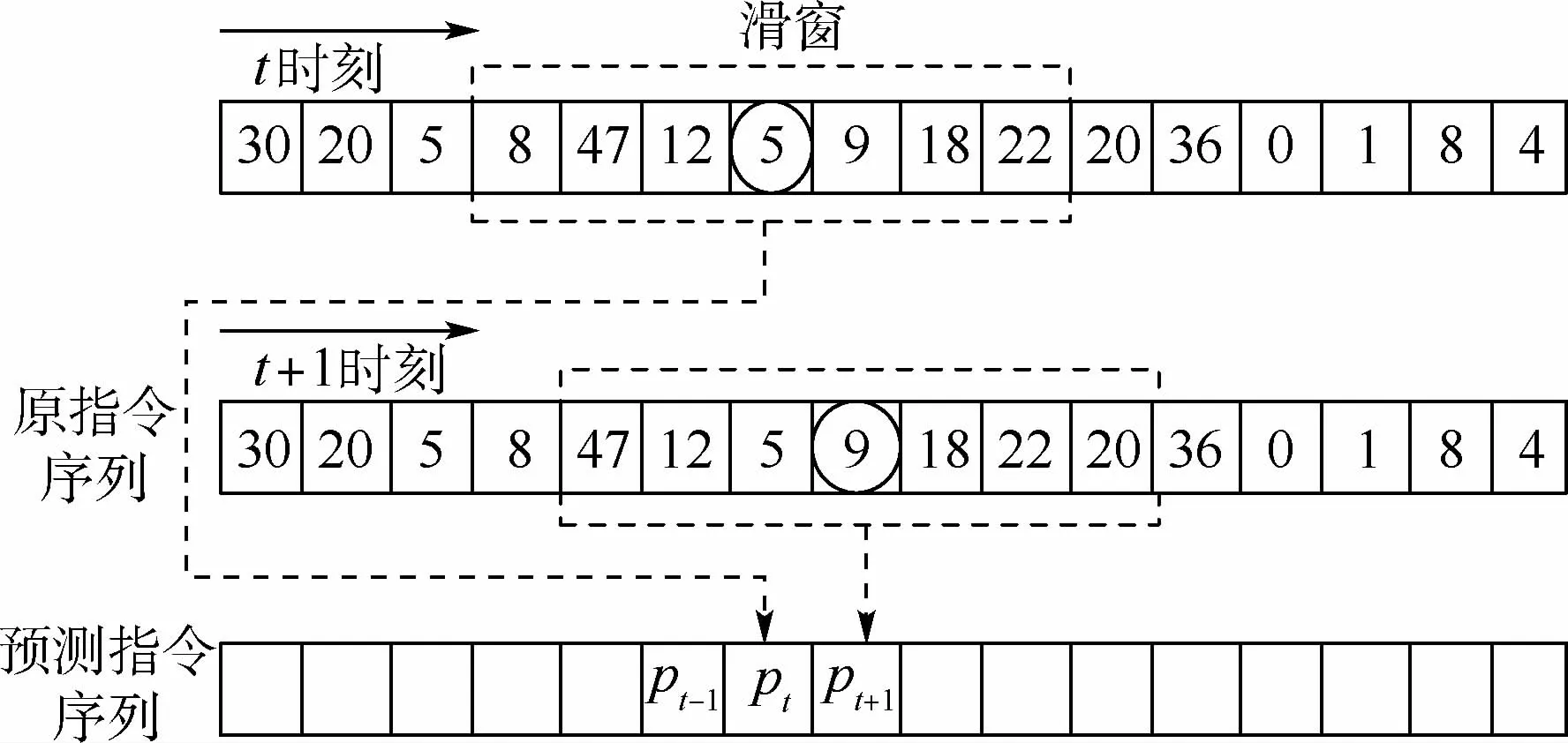
图4 家族共性指令序列学习Fig.4 Family common instruction sequence learning
Bi-RNN采用滑动窗口的方式学习指令的时序特征。在t时刻,Bi-RNN学习虚线框内的指令序列并预测圆圈内的指令内容,得到pt。在t+1时刻,滑窗右移一个指令,再次学习窗口内的指令序列并预测圆圈的指令内容,得到pt+1。随着滑窗的移动,指令的预测值组成一个新的指令序列,即为原指令序列的预测结果,损失函数即为指令的预测值和指令的真实值之间的差异。在反向传播阶段,为了快速降低损失函数值,滑动窗口的预测结果将会是窗口中最常见的指令,从而使Bi-RNN学习到该家族通用的指令序列。因此,即使恶意软件通过变体技术调整的部分指令,Bi-RNN也可以根据指令序列的上下文信息还原指令序列,有效减小了恶意软件变体技术对指令序列的影响,如图5所示。

图5 家族共性指令序列预测Fig.5 Family common instruction sequence prediction
预测指令通过查询嵌入表可得到嵌入结果vpi。
1.5 特征图像生成模块
为充分利用CNN的特征提取能力,将Bi-RNN的预测结果分别转换为单通道图像,并组成双通道的恶意软件特征图像。特征图像生成过程如下:
1)将嵌入结果和预测结果的数值归一化至0~255,对应灰度图像像素值。
2)顺序排列,分别生成单通道图像M∈R1×k×w。其中,k为样本内指令个数,w为指令嵌入的输出维度,实验中的嵌入维度为256。
3)鉴于样本内的指令数量不同,因此生成的图像长度不一致,需要对2个单通道图像各自放缩。通过双线性差值法,将2个单通道图像均放缩大小为3 000×256。其中,256为指令嵌入的输出维度,3 000为数据集内指令数量的中位数。
4)2个放缩后的单通道图像组成双通道恶意软件特征图像M∈R2×3000×256。
1.6 特征图像分类模块
通过CNN可以捕获图像内的局部特征。鉴于图像中的每一行对应一个指令,为确保一条指令的信息可以被完整的处理,在第一个卷积层中,使用宽卷积核f∈R2×h×256,其中h为卷积核高度,代表一次处理指令的个数,实验中取h=2,即经过第一个卷积层后,每个通道的卷积结果为列向量。随后,该卷积结果依次经过其他卷积层和池化层,完成图像的局部特征提取,并由全连接层和softmax层进行分类。
2 实验分析
2.1 实验数据
实验数据来源于2015 Kaggle微软恶意软件分类挑战赛[16],数据集中包含来自9个家族的10 868个有标记样本,包含样本的二进制文件和反汇编文件,是目前恶意软件研究领域广泛使用的数据集。数据集家族标签及样本数量如表1所示。鉴于本文方法是基于汇编代码实现的,因此仅使用反汇编文件。训练集占40%,验证集占10%,测试集占50%。

表1 数据集家族标签及样本数量Table 1 Family label and number of the sample in the dataset
2.2 实验环境
实验硬件环境为:Intel(R)Core(TM)i7-6700 CPU@3.40 GHz,RAM 8 GB,Windows10系统。主要软件和开发工具包为:Python 3.7、TensorFlow v1.14.0、scikit-learn0.22。
2.3 评价方法
实验采用机器学习领域的规范统计指标:准确率、召回率、精确率及F1,来准确评估分类模型的性能,从而更加全面地体现方法的有效性和可靠性。
2.4 消融实验
2.4.1 消融实验目的
本节实验通过拆分实验过程,以确认方法中每一个环节的有效性和意义,具体包含如下3点:
1)验证操作数类型抽象和指令重构意义。
2)验证指令嵌入网络对指令行为语义捕获的贡献。
3)验证家族共性指令序列对恶意软件变体分类能力的提升。
2.4.2 消融实验过程
为验证指令重构、指令嵌入和学习通用指令行为序列的效果,对比了5种恶意软件家族分类方法:
1)以操作码序列作为样本特征,采用256位哈希编码实现操作码向量化并排列成16×16恶意软件特征图像,通过CNN识别恶意软件家族。
2)以操作码和操作数组成的原始指令作为样本特征,采用256位哈希编码实现指令向量化并排列成16×16图像,通过CNN识别恶意软件家族。
3)以操作码和抽象操作数类型组成的重构指令作为样本特征,采用256位哈希编码实现指令向量化并排列成16×16图像,通过CNN识别恶意软件家族。
4)以操作码和抽象操作数类型组成的重构指令作为样本特征,采用指令嵌入网络实现指令向量化并排列成图像,图像大小为3 000×256,通过CNN识别恶意软件家族。
5)以操作码和抽象操作数类型组成的重构指令作为样本特征,采用指令嵌入网络实现指令向量化,通过Bi-RNN学习家族共性指令序列并做出指令预测,将重构指令与预测指令合并为双通道特征图像,图像大小为2×3 000×256,通过CNN识别恶意软件家族,即MCAI。
其中,方法1~方法3网络结构相关参数见2.5.2节,方法4、方法5中CNN卷积层采用2×2卷积核,池化层采用2×2池化窗口,其余结构见2.5.2节。
2.4.3 消融实验结果
消融5种恶意软件家族分类方法1~方法5实验结果如表2所示。
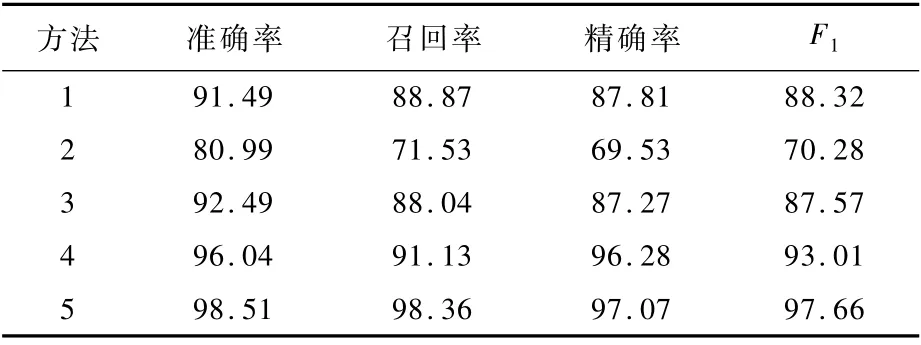
表2 消融实验结果Table 2 Results of ablation experiments %
实验结果表明,消融方法1~方法5在准确率方面分别达到了91.49%、80.99%、92.49%、96.04%和98.51%。方法1仅使用操作码序列作为样本特征,准确率达到91.49%,表明操作码序列可以在很大程度上反映恶意软件行为。但是在方法2中,结合了原始操作数后,实验效果显著下降,表明操作数的含义是每个恶意软件样本的特有信息,结合过多的特有信息将导致过拟合。方法3以操作数类型替换原始操作数实现指令重构,准确率有了较为明显的提升,表明操作数类型有助于指令行为的描述和提取。方法4采用指令嵌入网络实现指令向量化,相比于方法3中的哈希编码有较大的提升。经分析,哈希编码仅关注指令的整体信息,无法提取指令内部各元素之间的关系,而指令嵌入网络分别从词、句2个层面提取指令内、外的上下文信息,因此可以更好地学习指令特征,保留指令的行为语义。方法5通过Bi-RNN学习指令通用行为模式,对每条指令进行预测,并将预测结果和原始指令合并为双通道特征图像,实现效果优于方法1~方法4,表明Bi-RNN能够有效学习到指令的序列信息,捕获指令通用的序列模式。通过合并预测结果和原始指令,加强了属于同一家族的变体的相似性,可以在一定程度上减小变体技术的影响。
2.5 对比实验
2.5.1 对比实验目的
为了验证MCAI在恶意软件家族分类任务上的有效性,将MCAI与可视化检测领域内的优秀算法RMVC[11]、MCSC[10]进行比较。
2.5.2 对比实验过程
实验过程如图6所示。实验中,设置batch size为128,学习率为0.000 8,设置迭代次数为10 000,L2正则化系数为0.01,词嵌入维度为256。CNN中,卷积层1采用32个3×256大小卷积核,卷积层2、3均采用64个3×1大小卷积核,所有池化层均采用4×1大小池化窗口,全连接层神经元个数分别为512、256、9。

图6 对比实验流程Fig.6 Flowchart of comparative experiments
2.5.3 对比实验结果
实验结果如表3所示。图7~图9显示了3种方法的精确率、召回率和F1值。可以看到,本文方法在各项指标上均有所提升。此外,数据集中的Simda家族有42个样本,占样本总数的0.39%,处于严重不平衡状态。从实验结果中看出,RMVC在不平衡数据上的效果较差,受数据分布的影响较大;MCSC则表现较好,能一定程度应对数据不平衡问题;而本文方法在Simda家族上的分类结果达到了96%,对数据不平衡问题有较强的鲁棒性。
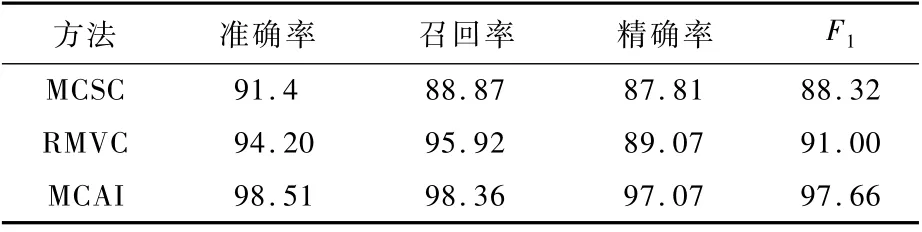
表3 对比实验结果Table 3 Comparative experimental results %
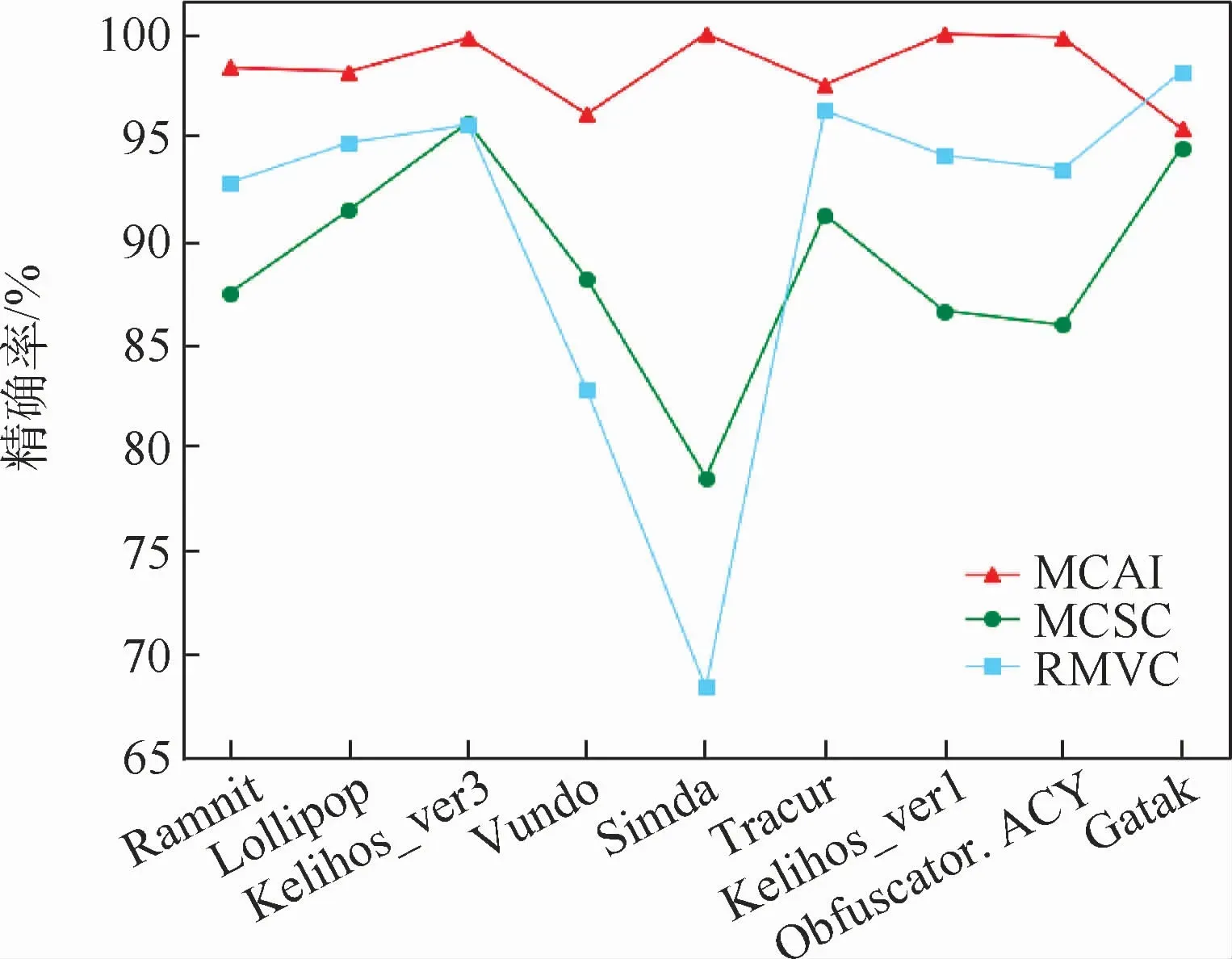
图7 对比实验精确率Fig.7 Precision of comparison experiment

图8 对比实验F1 值Fig.8 F1-score of comparison experiment
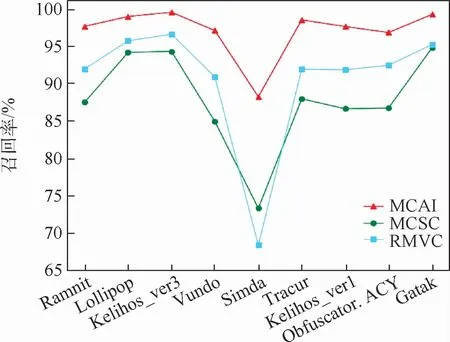
图9 对比实验召回率Fig.9 Recall of comparison experiment
3 结 论
针对基于汇编指令的恶意软件家族分类方法操作数语义与运行环境密切相关而难以提取,导致指令语义缺失,难以正确分类恶意软件变体的问题,本文提出了一种融合抽象汇编指令和家族共性指令序列的恶意软件家族分类方法。
1)通过操作数类型抽象重构汇编指令,使操作数语义脱离运行环境的约束,解决了操作数语义依赖于运行环境而难以提取的问题,进一步增强了指令行为描述的充分性和完整性。
2)通过word2vec、Bi-GRU和词注意力机制构建指令嵌入网络,实现指令向量化,并分别从指令内和指令间学习上下文信息,使指令的向量表示中包含更丰富的行为语义。
3)通过Bi-RNN学习指令的序列信息,捕获家族共性指令序列,并对每条指令给出预测指令,能够一定程度上发现并还原变体技术对指令的干扰和微调,减小代码混淆等变体技术对指令序列的影响。同时,结合预测指令和原始指令构建双通道恶意软件特征图,加强了属于同一家族的变体的相似性,进一步提升了家族分类效果。
