CStock:一种结合新闻与股价的股票走势预测模型
2020-11-16陈可心
陈可心,黄 刚
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
股票预测研究是金融大数据的一个应用研究方向,随着中国经济的快速增长和金融市场的不断扩大,越来越多的投资者开始关注提高投资回报率并能有效地避免一定风险的方法,其中对股票走势预测在商业和金融领域具有重要的意义。面对股票价格的涨跌,投资者会获得难以预测的收益甚至亏损,因此预测股票的走势,选取值得投资的股票成为投资者关心的问题。鉴于股票市场的复杂性、不稳定性,预测股票走势所需要考虑的变量和信息来源的数量巨大,预测股票走势是一个非常艰难的任务,如今依旧是各领域重点关注与讨论的对象。传统的分析方法主要是利用既有的股票数据和相关技术图表,结合投资者自身经验对股票走势进行预测。但是这种方法在当今日益庞大且复杂的股票市场中并不适用。除了效率低、过于依靠人工经验以外,还存在股票内容信息完整性差、特征数据冗余等一系列问题,对股票数据的利用率低,效果不佳,难以满足市场发展的需要。
随着机器学习技术的不断发展,越来越多的投资者开始使用机器学习技术对股票数据进行分析,从价格历史数据中学习以预测未来价格,搭建股票市场预测模型。常见的机器学习算法有Logistic回归、遗传算法、支持向量机等,并取得了不错的结果。而随着神经网络技术的兴起,通过搭建深度的神经网络来刻画股票价格并预测股票的走势,受到了人们的广泛关注,一些学者对这方面也展开了深入的研究[1-2]。NairBB等人[3]基于决策树构建去噪混合股价预测模型。该模型首先对股票数据的相关特征进行特征提取,然后使用决策树算法对提取过的特征进行特征选择并使用PCA算法进行降维处理,降维后的数据输入到模糊模型中预测股价。Ticknor等人[4]构建了一个贝叶斯神经网络模型,不需要对数据进行预处理操作和周期分析,仅把市场价格和技术指标作为预测模型的输入,来预测未来股票的收盘价格。苏治等人[5]构建了一种通过遗传算法对数据进行降维优化的SVM模型,采用量化选股方法分别从短期和中长期对其选股性能和预测精度进行了实证分析。程昌品等人[6]采用了先对股票价格序列使用小波分解,分离出非平稳时间序列中的低频信息和高频信息,然后对高频信息构建ARIMA模型,对低频信息使用SVM模型进行拟合的方法,得到了较好的结果。郝知远等人[7]基于舆论情报数据并进行自然语言处理及挖掘的建模预测分析的研究工作.其主要方法是依据最大化收益思想,提出了根据ROC曲线下的面积AUC值进行遗传参数寻优的支持向量机,解决传统方法在预测中可用性不高的问题。韩山杰等人[8]基于谷歌人工智能学习系统TensorFlow,构建多感知器MLP(multi-layer perceptron)神经网络模型,用于预测每日收盘股价。并就股价预测问题将TensorFlow与传统BP(back propagation)神经网络进行性能对比。Chen K等人[1]分析在加入不同数量的特征及不同的数据预处理状况下,使用长短期记忆网络LSTM对预测结果的影响;与随机预测方法相比LSTM模型提高了股票收益预测的准确率。王子玥等人[9]使用LSTM进行股票价格的预测,提出变步长集成方法及改进的MSE损失函数,预测上能取得较为可观的提升,但未得出通用的最优步长范围。Minh DL等人[10]提出了一种利用财经新闻和情感词典预测股票价格走向的框架,将股票价格趋势预测的双流门控循环单元(TGRU)和在股票新闻和情绪词典上训练出Stock2Vec嵌入模型相结合。
不同于现有方法的是,文中提出了一种CStock量化选股模型,利用contextual long short-term memory (CLSTM)以及bi-directional long short-term memory(BiLSTM)结合股票相关的新闻信息和已知股价走势信息,从而有效地对股票走势进行预测。
CLSTM和BiLSTM模型起源于循环神经网络[11](recurrent neural network,RNN)。RNN是一种节点定向连接成环的人工神经网络,可以利用它内部的记忆来处理任意时序的输入序列。传统的RNN存在梯度消失和梯度爆炸问题,因此,Hochreiter等人提出了一种基于RNN的优化,即长短期记忆网络(long short-term memory,LSTM),一种时间递归神经网络,常被用于处理和预测时间序列中间隔和延迟相对较长的重要事件。
LSTM在传统RNN的基础上,通过添加门控,使其变成门控RNN,可以有效减少梯度消失(爆炸)等问题。LSTM循环网络除了外部的RNN循环外,还具有内部的“LSTM细胞”循环。其门控包括输入门、遗忘门和输出门。LSTM网络比传统RNN更适合学习长期依赖,即可以减少梯度消失(爆炸)等问题。对于股票这类带有很强时间序列特性的数据,选择循环神经网络可以更好地结合历史信息。
BiLSTM则是将两个不同方向的LSTM结合,形成双向循环神经网络,以同时提取数据的正、反向信息。而相较于LSTM,BiLSTM能同时利用两个方向上的时序信息,更容易挖掘出潜在模式。CLSTM是Shalini Ghosh等人在2016年提出的一种基于话题的LSTM。在LSTM的基础上,CLSTM考虑了不同的话题下,输入门、输出门、遗忘门的权重状态。使得LSTM关注到话题之上,给LSTM一种指导。
1 选股模型
现有预测股票市场的模型主要是利用了股票市场中的交易数据。而影响股票市场波动的因素有很多,比如与股票相关的财经新闻或政治事件等,这些股票市场数据以外的信息都会影响到市场的波动。随着文本挖掘技术[12]的出现,使得获取相关文本数据来预测股票市场走势成为现实。
文中运用了文本挖掘和深度学习的相关知识,结合嵌入式词向量技术[13],采用Bi-LSTM双向循环神经网络、CLSTM和CNN卷积神经网络对和股票有关的时序数据、文本数据进行分析,挖掘数据的深层次特征,构建选股模型。
文中对股票的数据分为数值型数据和文本型数据两部分,各部分使用不同的网络结构。其中数值型数据包括开盘价,最高价,最低价,收盘价,变化率。文本型数据包括股票名称,股票相关新闻。
1.1 模型介绍
文中使用了一种BiLSTM和CLSTM相结合的模型,对股票走势进行预测。将文本型数据作为CLSTM的Contextual信息输入。同时,将数值型数据作为BiLSTM的输入数据。
1.1.1 字符型数据
(1)新闻信息提取。
股票相关新闻信息描述了该上市公司的运营状态。因为新闻信息与股票走势存在较大相关性,人们常常根据新闻信息对股票走势进行预测。为了对股票相关新闻信息进行编码,对股票相关的新闻信息通过tf-idf[14]的方法,提取出相关关键词集合K。使用Embedding的方法,将一个大小为n的集合K中的每一个词wi映射为对应的词向量wi。对于向量集合w,使用全连接神经网络,对其信息进行提取。
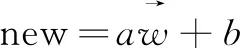
(1)
其中,a为每个词向量的权重大小,a属于Rn,b为偏置向量的权重大小,b属于Rn,new为新闻信息提取结果向量。
(2)股票信息。
对每个股票进行Embedding,将其转化成对应的股票向量S。对字符型数据通过Embedding的方法,使得其变为相应的词向量vc。将生成的词向量送入CLSTM,将股票名称(Name)作为Topic,对股票新闻关键词Keys进行处理,特别的,这里使用CLSTM的输出矩阵作为输出,得到相应的隐含层矩阵信息hc。
hc=CLSTM(Embedding(Name),Embedding(Keys))
(2)
将CLSTM的输出矩阵作为卷积层Conv1D的输入,然后使用最大池化层Maxpool1D对卷积结果进行池化操作。采用最大池化的方法提取特征值的最大特征来代替整个局部特征并大幅降低特征向量的维度。处理后得到特征向量ha。
1.1.2 数值型数据
文中对数值型数据x使用BiLSTM进行处理,使用BiLSTM输出矩阵的最后一维作为其输出,得到相应的隐含层信息hi。
1.1.3 全连接层
通过对数值型数据得到的输出hi和字符型数据得到的输出ha进行连接,通过全连接层进行计算,得到输出fc。
fc=Concat(hi,fc)*Wfc+bfc
(3)
其中,Wfc为全连接层的权重矩阵,bfc为偏置向量。
1.1.4 Softmax分类器
通过对全连接层的数据进行分析,得到分类为股票上升的概率和股票下降的概率P:
P=Softmax(fc)
(4)
即,完成分类。
1.2 模型设计
网络模型如图1所示。该模型的输入层包括数据信息和新闻信息两大部分,模型的主体部分首先使用BiLSTM对数据信息方面的特征分别进行处理,将文本型数据作为CLSTM的Contextual信息输入,而后将输出矩阵结合CNN再次处理。最后使用多层全连接神经网络对所有数据进行处理。

图1 网络模型
1.3 选股策略
通过神经网络预测模型的输出,可以得到每个股票上升的概率P。通过对P进行排序,选出最高概率的10只股票S1,S2,…,S10,通过对其概率进行求和。
(5)
然后按照如下公式进行选股,对每股的投入Inv(Si)如下:
Inv(Si)=P(Si)/Sum
(6)
则每次投资的收益率为:
(7)
其中,G(Si)表示Si股当天的实际价格变化率。
1.4 原型系统
文中设计的原型系统主要包括四层,首先是实时数据获取层,接着是数据存储层,接着是数据分析层,最后是输出层。原型系统结构如图2所示。
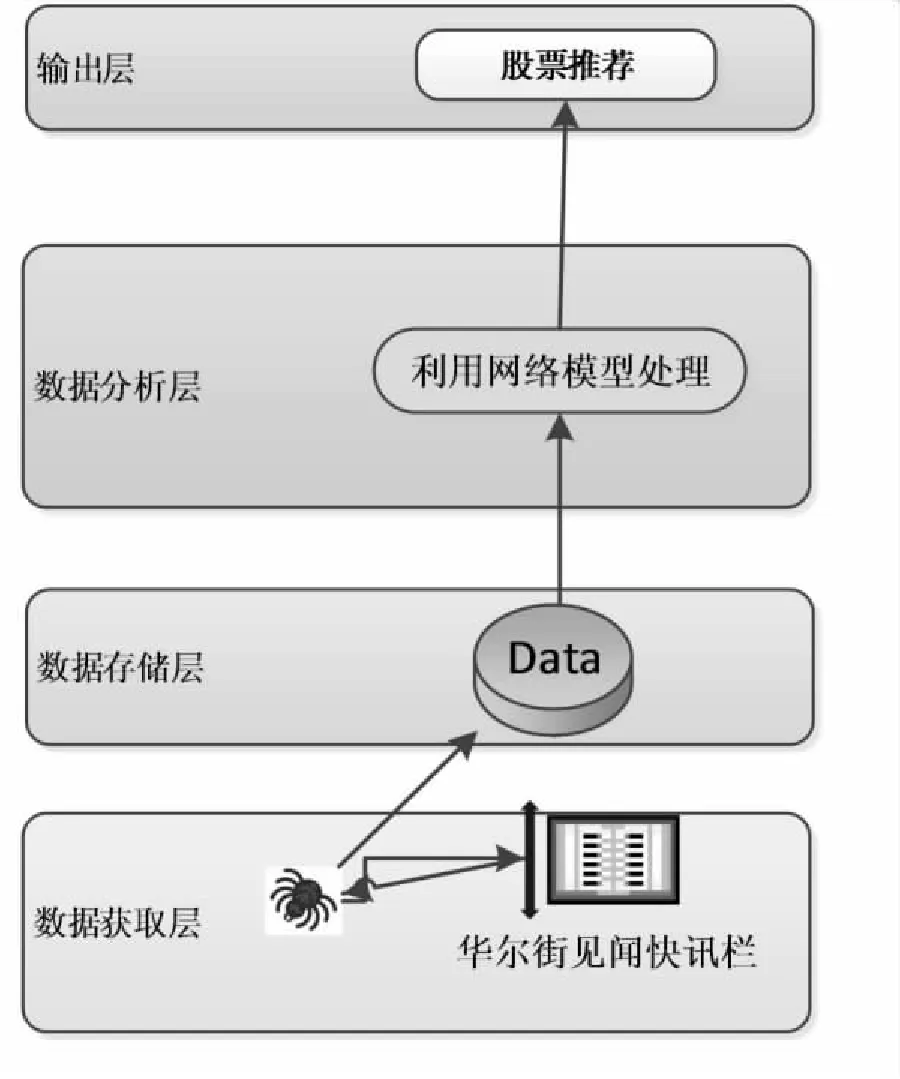
图2 原型系统结构
1.4.1 数据获取层
网络爬虫(web crawler),又称为网络蜘蛛(web spider)或web信息采集器,是一种按照一定规则,自动抓取或下载网络信息的计算机程序或自动化脚本,是目前搜索引擎的重要组成部分。狭义上理解:利用标准的HTTP协议,根据网络超链接(如https://www.baidu.com/)和web文档检索的方法(如深度优先)遍历万维网信息空间的软件程序。功能上理解:确定待爬的URL队列,获取每个URL对应的网页内容(如HTML/JSON),解析网页内容,并存储对应的数据。
网络爬虫按照系统架构和实现技术,大致可以分为以下几种类型:通用网络爬虫(general purpose web crawler)、聚焦网络爬虫(focused web crawler)、增量式网络爬虫(incremental web crawler)、深层网络爬虫(deep web crawler)。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
通用网络爬虫:爬行对象从一些种子URL扩充到整个web,主要为门户站点搜索引擎和大型web服务提供商采集数据。通用网络爬虫的爬取范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求较低,通常采用并行工作方式,有较强的应用价值。
聚焦网络爬虫,又称为主题网络爬虫:是指选择性地爬行那些与预先定义好的主题相关的页面。和通用爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,可以很好地满足一些特定人群对特定领域信息的需求。
文中设计的原型系统为聚焦网络爬虫,对华尔街见闻快讯栏介绍的数据进行爬取。
1.4.2 数据存储层
系统实时地通过网络爬虫将数据存储到数据库中,以便于模型对于数据的分析。同时经过一段时间对数据进行清理,防止数据库出现内存不够的情况。
1.4.3 数据分析层
实时地将数据输入到已经训练好的模型当中,本原型系统采用的是离线模型,将已经训练好的模型直接用来分析数据。
1.4.4 输出层
输出模型最终分析的结果,对用户进行展示,引导用户选择模型分析得出的最优股票。
2 实 验
2.1 数据集
文中利用网络爬虫来获取数据。爬取了华尔街见闻快讯栏目中2017年1月1日至2018年12月31日的新闻标题及相应的发布时间作为财经新闻的初始样本数据,同时从Wind数据库中获取了2017年1月4日至2018年12月29日中交易日的交易数据,包括开盘价、最高价、最低价、交易量、涨跌幅。
实验使用美股数据作为数据集合,取100,100,*分别作为测试集,验证集,训练集的大小,使用train-development-test模型进行训练。
2.2 设 置
实验运行在Ubuntu 16.04操作系统上,使用Tensorflow,Python3等工具,设定网络BiLSTM和CLSTM的层数为2,隐含层大小为64(双向128),使用交叉熵作为损失函数。
2.3 数据表示
文中使用了数值型数据和文本型数据,下面将分开讨论:
2.3.1 数值型数据
文中使用的数值型数据包括每股每日的开盘价、最高价、最低价、收盘价和价格变动率,为了简化模型,使用了近50天内的股票数据作为基础数据,用于预测股票走势。
2.3.2 文本型数据
文中希望对股票及其相应的新闻进行提取,从新闻中获取股票可能的走势信息,如国家政策支持可能导致股票上升等。由于每条新闻过长,因而采用了Tf-idf(term frequency-inverse document frequency),一种用于信息检索与数据挖掘的常用加权技术,对每条新闻进行处理,提取出新闻相关的关键词作为输入。为了和数值型数据对齐,同样采用了近50天内的新闻数据同时结合相应的股票注册名信息作为输入,用于预测股票走势。
2.4 数据输出
通过对上述数据进行训练,预测该日股票的走势。在尝试了拟合股票走势和分类股票走势等方法之后,采用分类方法进行实验,即对股票走势进行二分类(上升/下降)来进行预测。实验表明,将问题简化为分类问题比拟合股票走势准确率更高。
2.5 评 估
准确率:实验在测试集上预测的准确率Acc(每股上升与否)为:
Acc=0.523 2
(8)
实验采用上述选股策略对测试集进行回测,选择连续的一百天,并除去回测当天数据小于100股的情况,进行测试,使用收益率作为衡量指标,其结果如图3和图4所示。
每日收益率:图3表示每次投资可获得的收益率和天数的关系,其中横坐标表示天数,纵坐标表示收益率,点为每次投资的收益率,虚线为0坐标,其中收益大于0.00的天数为 Gdays,统计可得:
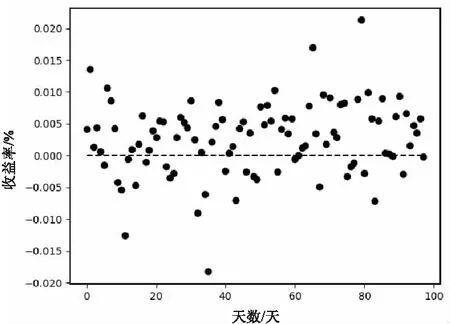
图3 每日收益率
Gdays=0.704 1
(9)
结果表明每天收益大于0的实际概率接近0.704 1。
总收益率:图4表示假设每天都采取模型给出的投资策略(这里忽略了手续费等支出),其收益和时间的关系,其中横坐标表示天数,纵坐标表示相比于第0天的收益率,其中最高点的坐标为(98,0.284 9),即如果用此模型进行选股,那么在98天时,可以累计获得相当于本金28.49%的收益。

图4 总收益率
3 结束语
文中提出了一种基于LSTM的神经网络模型,用于预测股票走势,同时给出了一种相应的选股策略。实验表明,考虑了数值型数据(开盘价,最高价,最低价,收盘价,价格变动)和字符型数据(股票名,新闻关键词)之后,可以获得较为不错的收益。虽然CStock对于股票走势预测是可行的,但是现实生活中还有很多影响股市的因素没有加入到实验的特征值中,如:股民情绪。下一步可以通过抓取投资者在Twitter上的讨论信息等的股评,利用NLP进行分析,这样可能会得到更加精准的预测结果。在投资频率方面,将本模型运用于实际中时,交易手续费问题不容忽视,需要对预测的模型进行输出大小的修改,从而减少手续费的消耗。
