最大化AUC 的正例未标注分类及其增量算法*
2020-11-15马毓敏王士同
马毓敏,王士同
江南大学 人工智能与计算机学院,江苏 无锡 214122
1 引言
对于PU(positive-unlabeled)分类[1-2]问题,训练样例集中的正例样本相对比较容易获得,而反例样本的获得比较困难,例如医疗诊断、地震监测、生物信息学,在这些领域仅能观测到一些标记为正例的样本以及大量可能包含正例样本和负例样本的未标注样本。为了使分类器的分类精度较高,反例样本集合应该是无偏的,即反例样本集合应该包含非正例的其他所有类别。因此,人们转而研究基于正例和未标注样本的学习,其中未标注样例集合数量通常远远大于标记的正例样本数目。
解决PU 分类问题的传统方法是简单地将这些既包含正例样本又包含负例样本的数据视为负例样本,这可能导致解决方案有偏差。为了减轻这种偏差,提出了几种方法。Wang 等[3]称PU 学习为部分监督学习,提出使用间谍(spy)技术选择可靠负例,利用期望最大化(expectation maximum,EM)和朴素贝叶斯(naive Bayes,NB)分类器的S-EM(spy-expectation maximum)实现分类;Liu 等[4]提出基于聚类的方法进行分类,通过对正例进行聚类,选择不属于任何簇的未标注样本作为可靠负例样本,迭代训练SVM(support vector machine);Xu 等[5]分别从正例和未标注样本中随机抽取相同数量的样本作为初始训练集,用于构造SVM,将距离分割平面最远的未标注样本作为负例,通过自训练得到分类器。实验表明,未标注样本的利用能提高预测效果,但选择初始训练集的方法会影响训练效果。Park 等[6]提出基于K-means 和投票机制的可靠负例选择方法(reliable negative selection method based onK-means voting mechanism,SemiPU-clus)及关系预测框架,解决异质信息网络中的关系预测问题,性能优于将无链接节点对完全视作负例的方法,但预测效果易受聚类结果影响;Sakai等[7]从理论上推导了PU 和半监督AUC(area under receiver operating characteristic curve)优化方法的泛化误差范围,提出了不依赖于数据分布的强大分布假设,仅基于正例和未标注数据的AUC 优化方法,然后将其与有监督的AUC 优化方法相结合扩展到半监督学习,再次证明了无标签数据有助于在没有限制性分布假设的情况下以最佳参数收敛率来降低泛化误差的上限,但对于新数据层出不穷的时代,其算法不适用于增量学习[8-9];Ren 等[10]提出最大化AUC 框架揭露了PU 问题下将所有未标注样本视为负例样本最大化AUC 与已知正负例分类情况下最大化AUC 线性相关,彻底摆脱了对未标注样本的负例选择,但是其算法需要多次迭代增加了复杂度且算法不适用于增量学习。
为解决分类效果,本文提出了核最大化AUC 算法(kernel max AUC,KMAUC),一个基于AUC 的利用核函数实现高维映射的PU 学习框架,其中AUC 度量[11-12]用于指导学习过程。相比于传统PU 分类算法需要经过多次迭代才能求出局部最优解,本文提出的KMAUC 算法具有可解析解,可以实现快速计算最大化AUC 评估值,在追求分类效果的同时兼顾了算法的复杂度,增强了算法的实用性。
针对传统PU 分类问题对于增加数据集时,往往需要把新数据集和已有的数据集合并成更大规模的数据集,通过重新学习来发现整个数据集的分类,不具有增量学习的能力,仅适用于整批处理的方式,不能有效地处理不断增加的数据集序列的问题,现有的方法提出了基于K邻近域的增量算法[13],但无法保证邻域矩阵的连续性,还提出了基于K邻近域的最小生成树算法[14],通过节点的更新来适应新增点的加入,虽然保证了邻域矩阵的连续,但节点的更新仍然需要大量的计算。针对此问题,本文进一步提出了增量核最大化AUC 算法(increment kernel max AUC,IKMAUC),把新来的观测数据融合到以前所获得的信息中去,快速计算隐藏在高维空间样本,不必重复计算原有的数据,实现快速增量学习。
综上所述,本文提出的IKMAUC 算法具有两大优点:(1)避免了多重迭代的麻烦,从而实现快速计算;(2)增加训练样本时还可以进行增量计算,通过直接计算新增样本的高维特征空间分布,避免对原始样本的高维特征空间分布重新求解,利用Sherman-Morrison 公式对新增样本数据的模型进行迭代更新达到快速训练的效果。
2 最大化AUC
2.1 AUC 指标
AUC 是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。其他评价指标有精确度、准确率、召回率,而AUC 比这三者更为常用。因为一般在分类模型中,预测结果都是以概率的形式表现,如果要计算准确率,通常都会手动设置一个阈值来将对应的概率转化成类别,这个阈值也就很大程度上影响了模型准确率的计算。不妨举一个极端的例子:一个二类分类问题一共100 个样本,其中99 个样本为负例,1 个样本为正例,在全部判负的情况下准确率将高达99%,而这并不是希望的结果,在医疗检测、地震监测等情况中,往往就是这极少数的数据起着至关重要的作用。从准确率上看模型的性能反应极差,而AUC 能很好描述模型整体性能的高低。这种情况下,模型的AUC 值将等于0。AUC 越大代表模型的性能越好。AUC度量标准被定义为[15]:
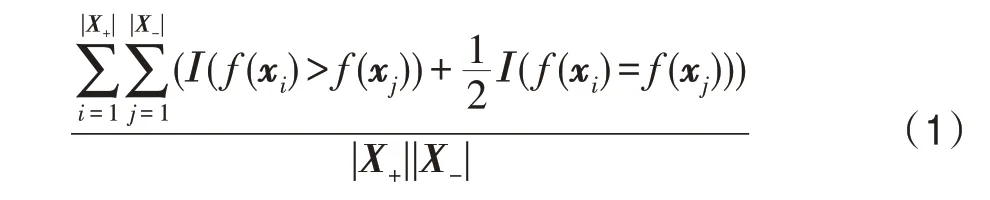
其中,f(x)=wTx是评分函数,向量w参数化评分函数,xi与xj分别表示正例样本、未标注样本特征向量。X+和X-分别表示正例样品和负例样品的分布,|X+|与|X-|分别表示正例和负例的样本数。Ι(·)为指示函数,参数为真时其值为1,否则为0。AUC 反映了随机抽取一个正例样本的评分值大于随机抽取一个负样本的评分值的概率。
2.2 最大化PU 分类的AUC 公式
PU 问题无法直接将AUC 作为目标函数,因为PU 问题中没有负标签,解决这个问题可以盲目地将所有未标注的样品视为负例样品,称为Blind AUC(BAUC),且BAUC 与AUC 之间的关系为(证明详见参考文献[10]):
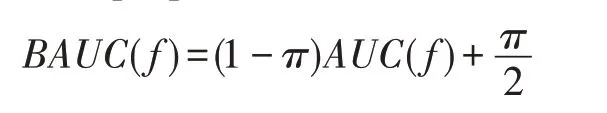
其中,π是正例样本的百分比。
这个公式表明BAUC 线性地取决于AUC,最大化BAUC 就是最大化AUC。由于AUC 为不连续且非凸函数,因此在实际应用时常常使用代理函数作为近似。典型的代理函数包括平方损失函数l(f)=(1-f)2(如OPAUC(one-pass AUC)[16])、对数损失函数l(f)=ln(1+e-f)(如RankNet[17])和指数损失函数l(f)=e-f(如RankBoost[18])等。现有的研究表明:平方损失函数、指数损失函数和对数损失函数等对AUC 优化具有一致性。本文将使用平方损失函数,将评分函数f(x)=wTx带入损失函数得:
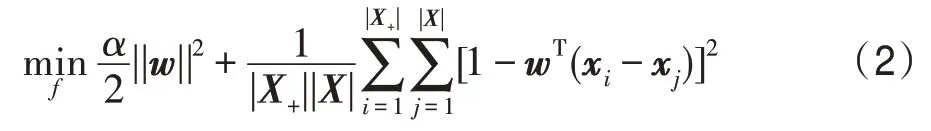
其中,α>0 是L2 正则化参数,是正则项,避免造成过拟合。式(2)具有两个优点:(1)最小二乘损失函数对AUC 优化具有一致性;(2)由于其一阶导数连续可以得到解析解。
2.3 最大化AUC 算法
本节介绍2.2 节提出的式(2)的优化求解方式,一个很自然的想法是应用最小二乘法,避免了多次迭代的繁杂,直接得到具有优良特性的估计量且计算比较方便。为方便书写,令式(2)为目标函数L,把w看作是L的函数,通过最小化L确定这个函数就变成了一个求极值的问题。最大化AUC 公式的优化过程如下:
L对w这个待估参数的偏导数:

由以上推导可以看出,通过直接对目标函数求偏导可以直接得到w的解析解,带入评分函数从而应用于PU 分类中。
2.4 核最大化AUC 算法(KMAUC)
由于现实中数据集往往存在于低维空间不是线性可分的,最大化AUC 算法的分类效果并不理想,为了方便将不能用线性分割的数据转化成可以线性分割的数据,只需将低维空间上的点映射到高维空间上就可以实现线性可分,在特征空间的线性运算即为对应原输入空间的非线性算法。低维空间转化为高维空间如图1 所示。
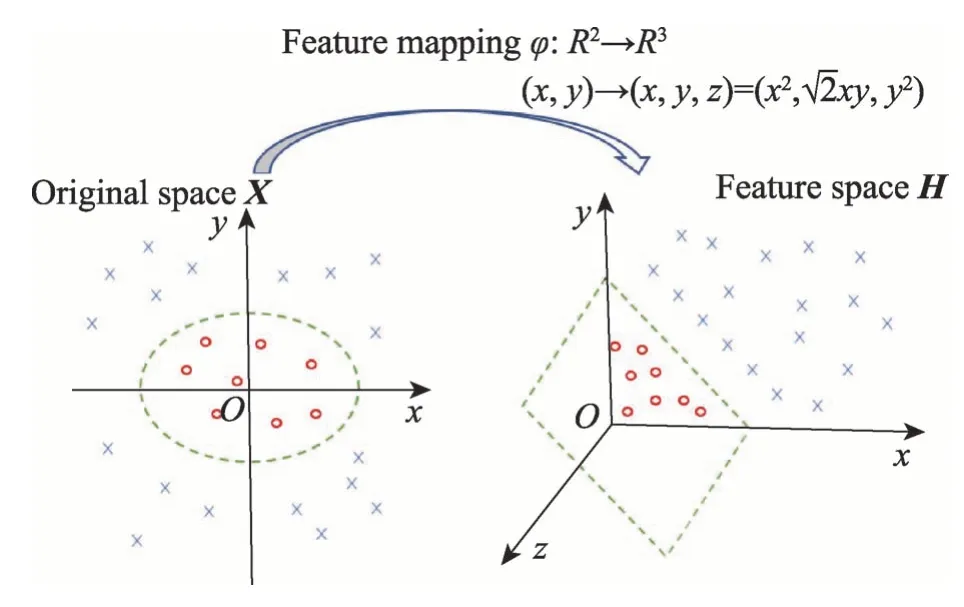
Fig.1 Feature mapping图1 特征映射
左面的图为原空间,右面的图为映射后的空间,从图中也可以看出来,左面图要用一个椭圆才能将两个类别分割开来,而右面的图用一个超平面就可以分割开,也如图上的共识所示,原空间点左边为(x1,x2),经过某个函数或者某种计算方法,转化为特征空间上点坐标为(z1,z2,z3),因此将低维空间转化到高维空间大概率可以对其中的点进行线性分割。对于生活中观察到的数据也是类似,若原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本线性可分。
本文提出了KMAUC 算法,利用核映射[19]φ将数据集从原始空间映射到高维空间,使得这个样本在这个特征空间内线性可分,解决数据集不是线性可分的情况。
由于高维特征空间样本可能是无限维的,为了显示地表示高维特征空间的样本,可以借助核矩阵把高维特征空间的内积运算转换为原始输入空间中的核函数的计算求解,这种核函数技术不仅可以产生新的非线性算法,而且可以改进一些传统线性处理算法。核矩阵表示为:

其中,k(xi,xj)=<φ(xi),φ(xj)>,m为样本数。
对核矩阵K做特征值分解(eigenvalue decomposition),K=VΛVT,其中Λ=diag(λ1,λ2,…,λm)为特征值构成的对角矩阵,V为特征向量矩阵,可以得到高维特征空间的内积,高维特征空间φ(X)可表示为:

高维特征空间中w的解析解为:
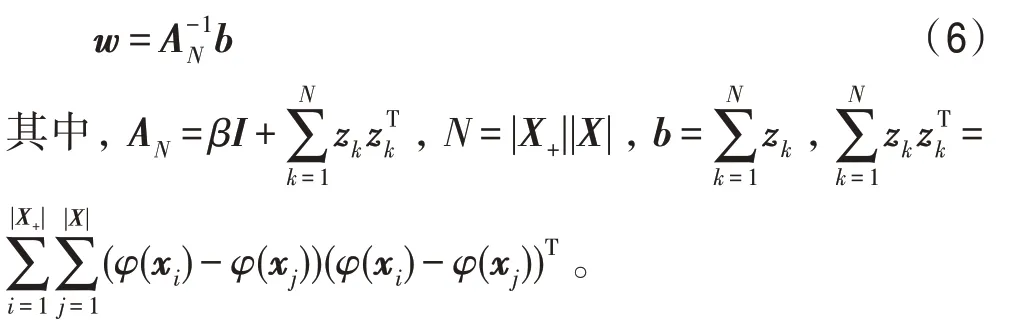
最后,KMAUC 算法的输出函数为:
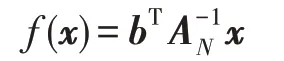
以上推导将最大化AUC 应用到非线性数据集,在真实数据集上可以取得更好的效果。
2.4.1 算法过程
KMAUC 算法过程如下:

2.4.2 时间复杂度
KMAUC 算法的时间复杂度[20]主要分为两步,分别对应于算法过程的步骤1(计算高维特征空间样本坐标)与步骤2(计算权重w)。
步骤1计算高维特征空间样本坐标的时间复杂度主要分为两步,分别对应算法过程的步骤1.2、步骤1.3。在步骤1.2 中,若l为输入样本点维数,m为输入样本数,计算核矩阵需要进行m2次的迭代,每次迭代的时间复杂度为O(l),则总的时间复杂度为O(lm2);在步骤1.3 中,通常情况下对于m×m维核矩阵特征值分解的时间复杂度为O(m3)。
步骤2计算权重w的时间复杂度主要分两步:(1)计算AN需要N次向量乘积的迭代,每次迭代的时间复杂度为O(m2),总的时间复杂度为O(m2N) ;(2)计算的时间复杂度为O(m3)。
综上所述,KMAUC算法的时间复杂度为O(m2N+m3+lm2),通常情况下,N>>m>>l,因此KMAUC 算法的时间复杂度为O(m2N)。
3 增量学习
KMAUC 算法对模型更新时需要重新代入所有数据,不能很好地应用在实际场景中。针对这一问题,增量学习方式应运而生。增量学习是指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识,减少计算量加速学习过程。
3.1 计算高维特征空间的增量样本
随着样本个数的增加,核矩阵有所改变,新增核矩阵区域数据的出现会破坏原有核矩阵特征值分解结构,若是直接对高维特征空间样本特征值分解,其时间复杂度会随着样本个数的增加呈指数增加。为解决这一问题,本文利用新来的观测数据子集包含的几何信息融合到以前所获得的信息中去,快速发现隐藏在高维空间的分布,保留原先计算出的特征空间样本情况下,巧妙计算出新增数据,大大缩减计算时间,增量样本计算方式如下:
第一次新增样本时,样本总数达到(m+1)个,核函数矩阵Km+1是(m+1)×(m+1)的方阵,它比初始核函数矩阵Km多一行一列,比较Km+1和Km的元素,可以看到Km+1能写为如下分块矩阵的形式:


往后再增加样本时,都通过Schur Complement公式用相同的方法简便运算。
3.2 计算增量后权重w′
增量后权重w′可以保留增量前计算w所计算的数值AN与b,对于新增样本部分发生的变化用ΔA与Δb表示,带入计算表示为:
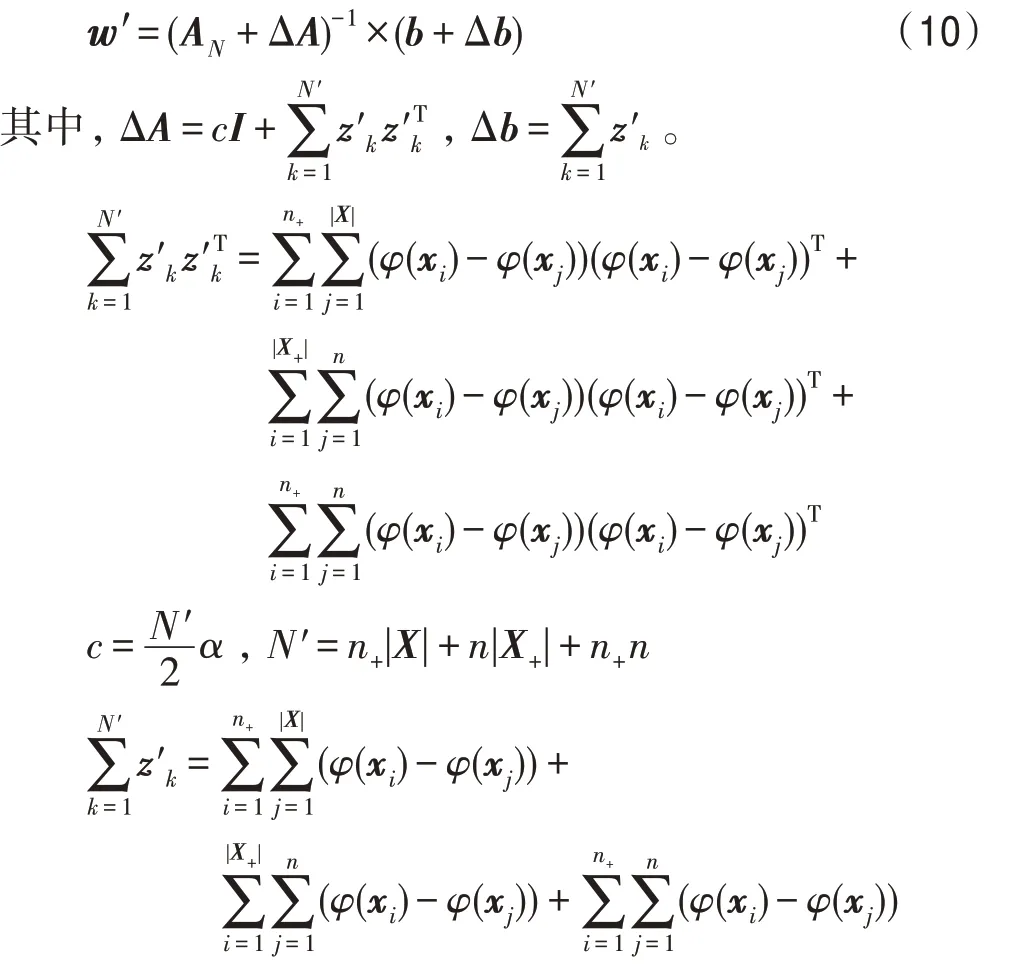
|X+|与|X|表示每次增量前训练样本正例与未标注样本数,n+与n表示每次增量的正例与未标注样本数。
由于(AN+ΔA)-1的时间复杂度会随着样本个数的增加,计算所需的时间呈指数增加,本文利用Sherman-Morrison 公式迭代求解,快速计算矩阵的逆。具体求解过程如下:
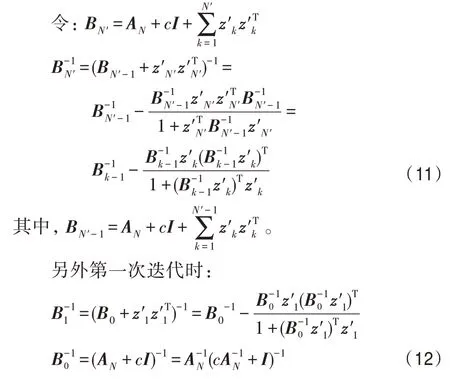
3.3 核最大化AUC 公式算法(IKMAUC)
3.3.1 算法过程
IKMAUC 算法过程如下:

3.3.2 时间复杂度
IKMAUC 算法的时间复杂度主要分为两步,分别对应于算法过程的步骤1(计算增量样本在高维特征空间的分布)与步骤2(计算增量后权重w′)。
步骤1计算高维特征空间样本坐标的时间复杂度主要分为三步,分别对应算法过程的步骤1.2、步骤1.3 和步骤1.4。步骤1.2 计算加入新增样本核矩阵可以保留之前m×m维核矩阵计算结果,只需要进行(m+n++n)2-m2次迭代,每次迭代的时间复杂度为O(l),则总的时间复杂度化简为O(l(n++n)2-2mnn+l);步骤1.3 计算新增样本高维空间分布的时间复杂度第一次主要求[φ(Xm)T]-1为O(m3),往后每次的时间复杂度主要为(m+n+n+)×(m+n+n+)维矩阵与(m+n+n+)×1 维的向量相乘,为O(m+n+n+)2,总的时间复杂度为O((n+n+)(m+n+n+)2),由于n+n+<<m,因此计算新增样本高维空间分布的时间复杂度为O(m3)。
步骤2计算增量后权重w′的时间复杂度主要有两步,分别对应算法过程的步骤2.2 和步骤2.3。步骤2.2 计算m×m维矩阵的时间复杂度为O(m3);步骤2.3 计算求解需要经过N′次迭代,每次迭代的时间复杂度主要为(m+n+n+)×(m+n+n+)维矩阵与(m+n+n+)×1 维的向量相乘,为O(m+n+n+)2,总的时间复杂度为O(N′(m+n+n+)2)。
综上所述,IKMAUC 算法的时间复杂度为O(N′(m+n+n+)2+m3+l(n++n)2-2mnn+l),增量学习通常情况下,N>>N′>>m>>l>>n或n+,因此IKMAUC算法的时间复杂度为O(N′(m+n+n+)2)。而不做增量学习重新求解的时间复杂度为O(m2(N+N′)),可以看到具有增量学习的IKMAUC算法大大减少了训练时间。
4 实验
本章进行实验分析,通过与其他现有先进算法对比,以验证所提出的KMAUC 算法与IKMAUC 算法的有效性。在实验过程中,训练集内75%的随机选择的正例样本数据是算法已知的,剩下的25%正例样本与负例样本归为未标注样本。
验证所提出的KMAUC 算法比较涉及6种算法:选用高斯核函数的理想SVM(正负例样本的真实的标签是已知的)、单类SVM(流行的分类算法)、Biased SVM(BSVM)、文献[21]提出的先进算法ERR(error minimization formulation)、最大化AUC 算法(本文2.2 节提出的算法)、本文提出的完整最大化核AUC 算法(KMAUC)。理想情况下的SVM 作为参考进行比较,注意在理想SVM 情况下,所有样本标记全部已知,无需分为75%正例样本以及剩下未标注样本。它是评估其他算法性能的标准。
为了更好评估算法的性能,实验使用机器学习领域中具有代表性的数据集UCI 进行实验。实验所用数据集如表1 所示。
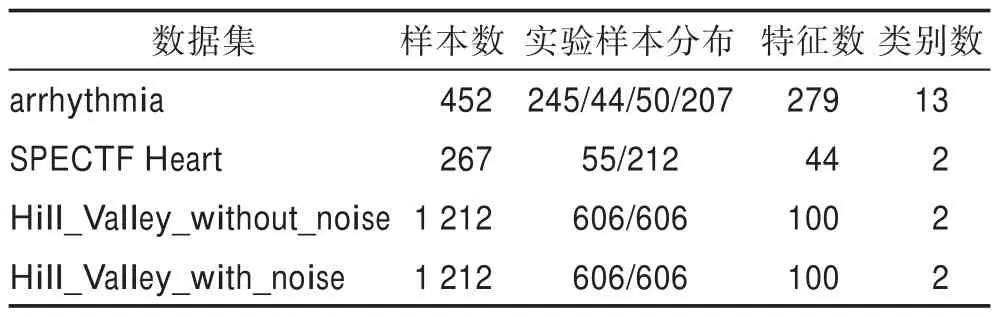
Table 1 Introduction to datasets表1 数据集介绍
由于在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,在数据利用核函数映射到高维空间之前需要对数据集进行预处理,所有数据都归一化到[-1,1],并将其标准化处理,消除奇异样本数据导致的不良影响。
4.1 实验环境
本文所有实验均在同一环境下完成,采用在Windows 10 环境下搭建系统,计算机处理器配置为Intel®CoreTMi3-3240 CPU@3.40 GHz 3.40 GHz,内存4 GB,算法在JetBrains PyCharm 下完成。
4.2 评估指标
为保证实验结果真实准确,每个数据集都进行10 次实验,然后取其平均值作为最终结果。
对于第一组数据集arrhythmia,通过选择不同的标签组作为正例和负例,得到了5种学习情景,如表2所示。在该数据集中,标签1 被选为健康,标签2 被选为疾病类型2,标签3 被选为疾病类型1。选择这3个标签的原因是这些类的人数足够大。5种学习情景的训练集的数据随机选择为大小分别为40、100、100、60、100,其余样本用于测试。所有训练集中的正例样本数为20,其余均为负数据。另外注意的是,数据中存在缺失值,本文对缺失值的处理方式是直接去掉有缺失值的特征。
第二组数据集是SPECTF Heart 数据集,本文选择标签0 作为正例,1 作为负例。训练集的大小为80,正例为50%,负例也是50%,其余样本用于测试。
第三组和第四组数据集是Hill_Valley_without_noise 数据集以及Hill_Valley_with_noise 数据集。对于这两个数据集,本文均是随机选择50 个标签为1的正例样本(Hill)和150 个标签为0 的负例样本(Valley)来形成训练集,其余样本用于测试。
本文选用AUC 作为衡量指标。核函数选用高斯核函数,表示为:
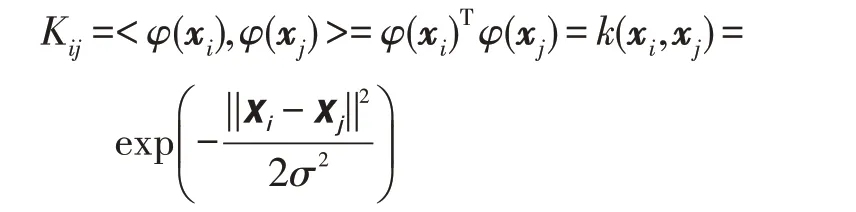
其中,σ>0 是高斯核的带宽(width)。
4.3 参数设计
算法中包含两个超参数α、σ。由于α仅用于限制w的大小,因此对这个超参数的性能不太敏感,在本文实践中被选择为小值。带宽σ对性能很重要,控制了函数的径向作用范围,带通越大高斯核函数的局部影响的范围就越大。本文用小数初始化α与σ,例如α=0.01,σ=0.01,并以贪婪的方式增加每个超参数的值,直到训练集上的性能停止改善。由于算法复杂度低且参数较少,还可以用网格搜索方式,将α从2-4~210,σ从2-4~210依次遍历,找到局部最优参数。
4.4 实验结果
KMAUC 算法与SVM(ideal)、单类SVM、Biased SVM、文献[21]提出的先进算法ERR、最大化AUC 比较,评估结果如表2 所示。
从表2 中可以看出,与传统的知道训练集内所有正例与负例标签的分类问题(理想SVM)相比,仅知道一部分正例标签与其他未标注标签的PU 学习算法性能更差。因此,可以得出结论,PU 学习对数据集内的不相关特征和噪声更加敏感。直观地,当各种不确定性(未知标签、不相关特征和异常值)组合并相互关联时,问题变得比这些分离问题的总和复杂得多。学习过程包含提出利用核函数映射到高维空间,性能得到明显改善。如表2 中所示,单类SVM 分类效果非常不理想,因为它完全依赖于观察到的正例样本来做出决策。对于数据集SPECTF Heart,其中特征的数量不大并且特征可能是线性分布或者特征之间距离较大,除了单类SVM 之外的所有算法倾向于实现相同的性能。对于其他数据集,加入高斯核函数处理后的数据性能明显优于未使用高斯核函数处理的数据。另外,对于文献[21]提出的ERR 算法虽然在部分数据集上得到了与KMAUC 算法相近的性能,但不能解决增量问题,面对层出不穷的数据时,具有局限性。最后可以看到,KMAUC 实现了与理想SVM(正例样本与负例样本完全已知)相近的性能,表明所提出的方法是处理现实问题的有力工具。
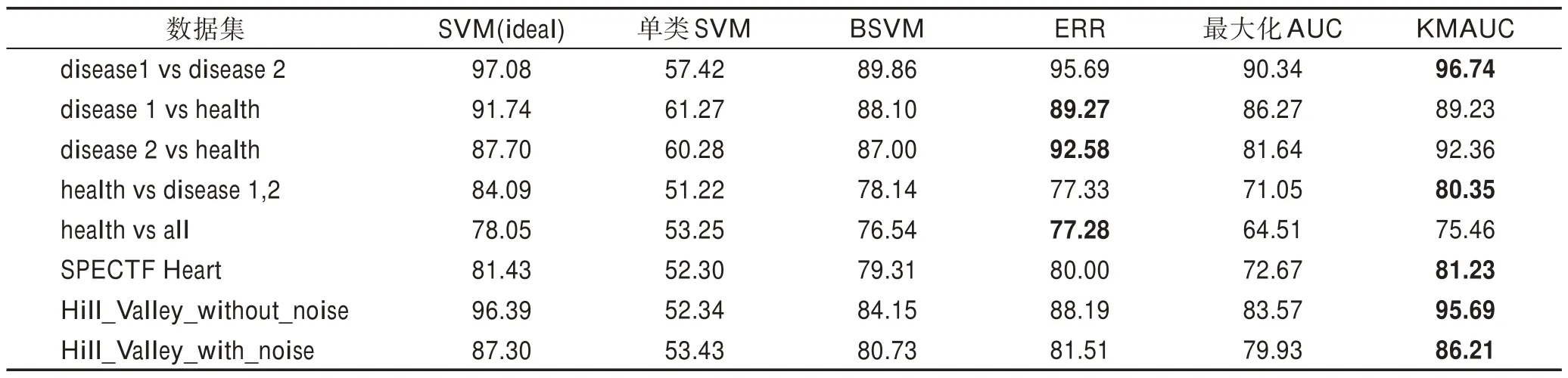
Table 2 AUC value comparison among 6 algorithms on UCI datasets表2 UCI数据集上6种算法的AUC 值比较 %
IKMAUC 算法与KMAUC 算法比较如表3 所示,本文分别从每个训练数据集选取5 个正例样本与5个负例样本组成正例未标注样本。
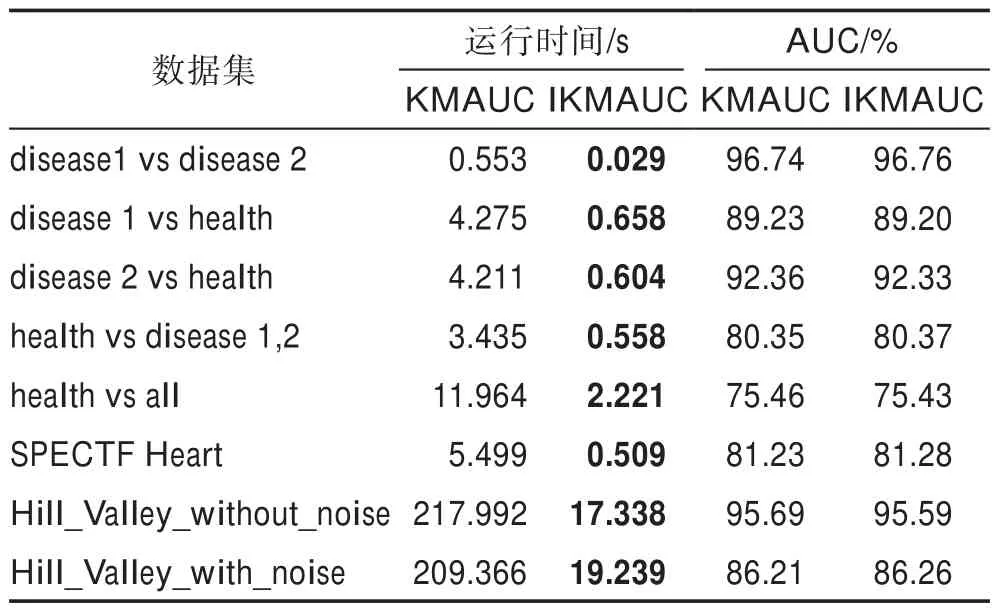
Table 3 Time and AUC value comparison among 2 algorithms on UCI datasets表3 UCI数据集上两种算法的时间与AUC 值比较
可以明显看出,IKMAUC 在保持精度的情况下大大减少了训练时间,表明应用Sherman-Morrison 公式并直接计算新增样本的高维特征空间分布,可以避免对原始样本的高维特征空间分布重新求解,并直接利用先前计算的数据继续运算,从而达到快速训练的结果。
5 结束语
从正例和未标注样本(PU 问题)学习分类问题是一个非常具有挑战性的问题。本文提出了一个强有力的算法来系统地解决PU 问题的挑战性问题。利用AUC 与PU 问题下AUC 关联,求解PU 问题下AUC 的最大化,借助核函数使得数据实现线性可分的效果。除此以外,本文提出的算法具有可解析解,能够实现快速增量,大大加快算法的学习能力。使用真实数据进行的广泛数值研究表明,与其他对比算法相比,所提方法具有有效性。在未来的进一步发展中,可以进一步优化损失函数以及算法实现,以达到更好的学习效果。
