结合主题词嵌入和注意力机制的主题模型
2020-11-14覃婷婷陈可佳
覃婷婷,刘 峥,陈可佳
(南京邮电大学 计算机学院,南京 210023)
0 概述
随着互联网行业的快速发展,文档数据急剧增加,从文本数据中发现潜在的主题信息也变得更加困难。经典主题模型如LDA[1]和sentenceLDA[2]通常利用文档或者句子级别的单词共现来构成主题,根据简单的词袋模型捕获单词之间的语义信息,但是,该方法忽略了有价值的单词序列信息[3]。目前,研究人员提出了引入单词嵌入和主题嵌入的主题模型LTE(Latent Topic Enbedding)[3],其将单词嵌入和主题模型集成到一个框架中。单词嵌入模型[4]将单词映射到分布式表示中,其主要关注小滑动窗口内的单词共现,这使得单词嵌入可以捕获单词子序列的信息。但是,现有的单词嵌入模型通常只关注单词上下文的语义信息,并未充分了解文本的主题。
目前,学者们关于主题建模和单词嵌入进行了较多研究。LDA是用离散数据集合(如文本语料库)建立的生成概率模型[1],LDA及其变体已广泛应用于内容推荐[5-6]、趋势检测[7-8]以及用户概况分析[9-10]等应用中。Bigram主题模型[11-12]为了减轻LDA主题模型词袋假设的负面影响,为每一对主题的单词创建多项式分布,这导致其计算成本大幅增加。主题联合词向量模型[13]通过对单词和主题向量进行线性变换得到最终的词向量。文献[14]将主题模型应用于文档检索,在一定程度上提高了文档检索的效果。文献[4]提出了Skip-gram模型的几个扩展模型,提高了向量的质量和训练速度。文献[15]将主题建模的结果输入单词嵌入模型以学习主题词嵌入,但是其并非整合主题建模和单词嵌入。文献[16]基于LDA主题模型引入深度神经网络模型LSTM(Long Short-Term Memory),建立了LLA(Latent LSTM Allocation)模型。LLA模型通过LSTM预测每个单词主题的生成概率,使得LDA模型的超参数减少,同时利用了上下文的文本信息。但是,LLA模型用LSTM对主题和单词进行嵌入,并且忽略了单词与主题之间的相互关系。在本文模型中,将通过引入注意力机制的方法来解决这一问题。
主题模型可以了解文本的主题信息从而捕获文本的主题分布,使得用户可以较容易地获取文本的主要内容,而单词嵌入可以在一个小的滑动窗口内捕获单词的语义信息,并将单词表示成一个较低维度的分布,这使得衡量单词间距离的难度降低。鉴于主题模型和单词嵌入的优点和缺点,本文使用LDA模型作为主要框架,通过注意力机制将主题嵌入和单词嵌入融合到LDA模型中,在此基础上,构建一种JEA-LDA(Joint Embedding and Attention for Latent Dirichlet Allocation)模型。在文本的生成过程中,本文假设文档中观察到的单词的主题可以通过2个通道生成,一个是多项式分布,另一个是基于主题嵌入和单词嵌入。此外,在JEA-LDA模型中,针对主题和单词建立注意力机制,获取主题与单词间的相互关系。在训练单词嵌入和主题嵌入的过程中,学习注意力分数,以确保在给定文本中与文本主题相关的单词的权重高于不相关单词的权重,从而使得主题嵌入和单词嵌入的信息将影响主题建模的结果,而主题分布又将影响单词嵌入和主题嵌入的训练。
1 JEA-LDA主题模型
经典主题模型LDA利用单词实例的共现来提取文本主题,但是其忽略了单词间的位置关系。在本文中,通过将主题词嵌入融入到LDA主题模型中来预测文本中每个单词的主题,同时本文在主题词嵌入模型中引入注意力机制,计算每个单词的重要性分数,利用单词的重要性分数和主题词嵌入来预测下一个单词的主题。
1.1 模型框架
本文JEA-LDA主题模型的贝叶斯网络示意图如图1所示。
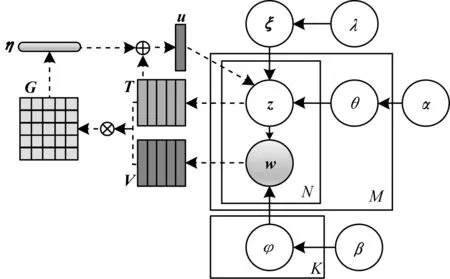
图1 JEA-LDA主题模型的贝叶斯网络示意图Fig.1 Bayesian network schematic diagram of JEA-LDA topic model
JEA-LDA主题模型以LDA模型为主题框架,融合单词嵌入和主题嵌入并引入注意力机制。由图1可以看出,JEA-LDA主题模型与LDA主题模型结构相似,不同之处在于,JEA-LDA主题模型添加了一个决定参数λ,表示主题生成的来源,JEA-LDA还结合了单词嵌入和主题嵌入结构,并在单词和主题之间添加注意力机制,用来捕获主题与单词之间的相互作用关系。在图1中,V表示短文本单词序列所组成的单词嵌入矩阵,为被预测单词的前导单词序列,T表示连续单词的主题嵌入矩阵,为被预测单词的前导单词的主题序列。嵌入矩阵的每一列表示一个单词嵌入或主题嵌入,主题嵌入和单词嵌入的长度保持一致。

(1)
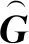
为了捕获连续单词序列(如短语)的相对空间位置信息,本文在注意力的计算过程中引入一个非线性函数ReLU。特别地,本文考虑一个长度为2r+1、中心词为第n个单词的单词序列,用注意力矩阵G的局部矩阵Gn-r:n+r来计算主题-短语的注意力分数。本文通过式(2)在第n个短语与主题间学习更高级的注意力分数:
sn=ReLU(Gn-r:n+rW1+b1)
(2)
η=softmax(m)
(3)
(4)
本文用交叉熵来衡量主题表示的概率,即式(4)中u为待预测单词w的概率,如式(5)所示:
p(zw|V,T)=CE(Zw,f(u))
(5)
在JEA-LDA主题模型中,本文首先根据狄利克雷分布先验参数α和β获取参数文档-主题分布θ和主题-词分布φ;然后根据多项式分布Multi(θ)和主题词嵌入模型为每一篇文档的每一个单词选定主题;最后根据多项式分布Multi(φ)为每一篇文档逐步生成单词。JEA-LDA模型的生成过程如算法1所示。
算法1JEA-LDA模型生成算法
输入文本数据集D={d1,d2,…,dM}
输出文档-主题分布θ,主题-词分布φ
1.for k=1 to K do
2.根据狄利克雷先验分布抽样主题-词分布φk~Dir(β);
3.end for
4.for each 文档d∈D do
5.根据狄利克雷先验分布抽样文档-主题分布θd~Dir(α);
6.for each 单词w∈d do
7.根据伯努利分布抽样一个决定参数ξw~Ber(λ);
8.根据文档-主题分布和主题词嵌入模型的预测概率为单词w抽样一个主题zw~(1-ξw)Multi(θd)+ξwp(zw|V,T);
9.根据主题-词分布抽样一个单词w~Multi(φzw);
10.end for
11.end for
12.return 文档-主题分布θ,主题-词分布φ
1.2 模型参数推导
在JEA-LDA模型中,单词w的概率可描述为p(w|α,β,λ,σ),其目标是最大化单词w的概率。在理想情况下,可以通过最大化p(w|α,β,λ,σ)来计算σ的最优值。但是,直接计算p(w|α,β,λ,σ)非常困难,因此,本文计算后验概率p(w,ξ,z|α,β,λ,σ),如式(6)所示:
p(w,ξ,z|α,β,λ,σ)=
p(ξ|λ)p(z|α,ξ,σ)p(w|z,β)=
(6)
其中,Ed,k表示文档d中属于主题k的单词个数,Fk,v表示文档数据集中属于主题k的单词v的个数,Γ(·)表示Gamma函数,A表示通过伯努利分布生成的0的数量,B表示通过伯努利分布生成的1的数量。根据贝叶斯规则,为文档d的单词w指定主题k的概率如式(7)所示:
p(zd,w=k,ξd,w|w,z,α,β,λ,σ)=
p(ξd,w|λ,ξ)p(zd,w=k|w,z,ξd,w,α,β,σ)=
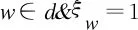
(7)
本文根据式(7)整合ξw,如式(8)所示:
p(zd,w=k|w,z,ξ,α,β,λ,σ)=
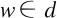
(8)
本文利用式(8)采样每篇文档中每个单词的主题,重复执行,直至收敛。接下来则考虑单词嵌入和主题嵌入的优化过程。在主题词嵌入的过程中,对于每个短文本d的单词w的主题,本文用单词w前面的单词序列预测w的主题。因此,目标函数可以建立如下:
(9)
根据上述分析,可以用蒙特卡罗EM算法来推导JEA-LDA模型的参数,如算法2所示。应用该算法可以获得本文模型的参数,如文档-主题分布θ和主题-词分布φ。
算法2蒙特卡罗EM算法
输入文本数据集D
输出文档-主题分布θ,主题-词分布φ
1.初始化单词嵌入矩阵V和主题嵌入矩阵T;
2.为每篇文档的每个单词随机指派一个主题;
3.repeat
4.E-Step:
5.for each 文档d∈D do
6.for each 单词w∈d do
7.根据主题词嵌入模型计算p(zd,w|σ);
8.根据式(8)获取主题zd,w;
9.end for
10.end for
11.M-Step:
12.用随机梯度下降法优化主题词嵌入模型参数σ;
13.until收敛
在算法2中,第1行首先对主题词嵌入模型进行初始化,本文用预测训练的单词嵌入初始化单词嵌入矩阵,对于不在词汇表中的单词和主题,本文采用均匀分布进行初始化。第2行对每一篇文档随机指派一个主题。第7行根据主题词嵌入模型的前向过程预测单词w主题为zd,w的概率。第8行根据式(8)指定单词w的主题zd,w。第12行用随机梯度下降法求解主题词嵌入模型的参数。
假设算法2的最大迭代次数为H,语料库中文本数量为M,每篇文档的平均单词数量为N,则JEA-LDA模型的时间复杂度为O(HMN)。
2 实验结果与分析
2.1 实验数据集
本次实验采用搜狗实验室(http://www.sogou.com/labs/)的新闻数据集来预训练单词嵌入,使用爬取自新浪微博的文本数据集来评估文本主题质量,该数据集包括679 823条文本数据,每条文本数据包含100个~200个单词。
2.2 对比模型
本次实验的对比模型具体如下:
1)LDA[1],经典主题模型,直接用LDA对文本数据集提取主题。
2)DMM[17],Dirichlet多项式混合模型,其主要思想是假设每篇文本仅有一个主题。
3)LF-DMM[18],DMM的改进模型,其在DMM模型中引入了外部词向量来补充单词间的关系。
4)LF-LDA[18],LDA的改进模型,其在LDA模型中引入了外部词向量来补充单词间的关系。
2.3 主题一致性评估

(10)
PMI得分越高,模型学习的主题一致性越好,即模型性能越高。
图2所示为微博文本数据在每个对比模型上的主题一致性PMI分数,其中,使用每个主题的前20个单词分别计算PMI分数。从图2可以看出,本文JEA-LDA模型相较于其他模型能够取得更好的一致性效果。
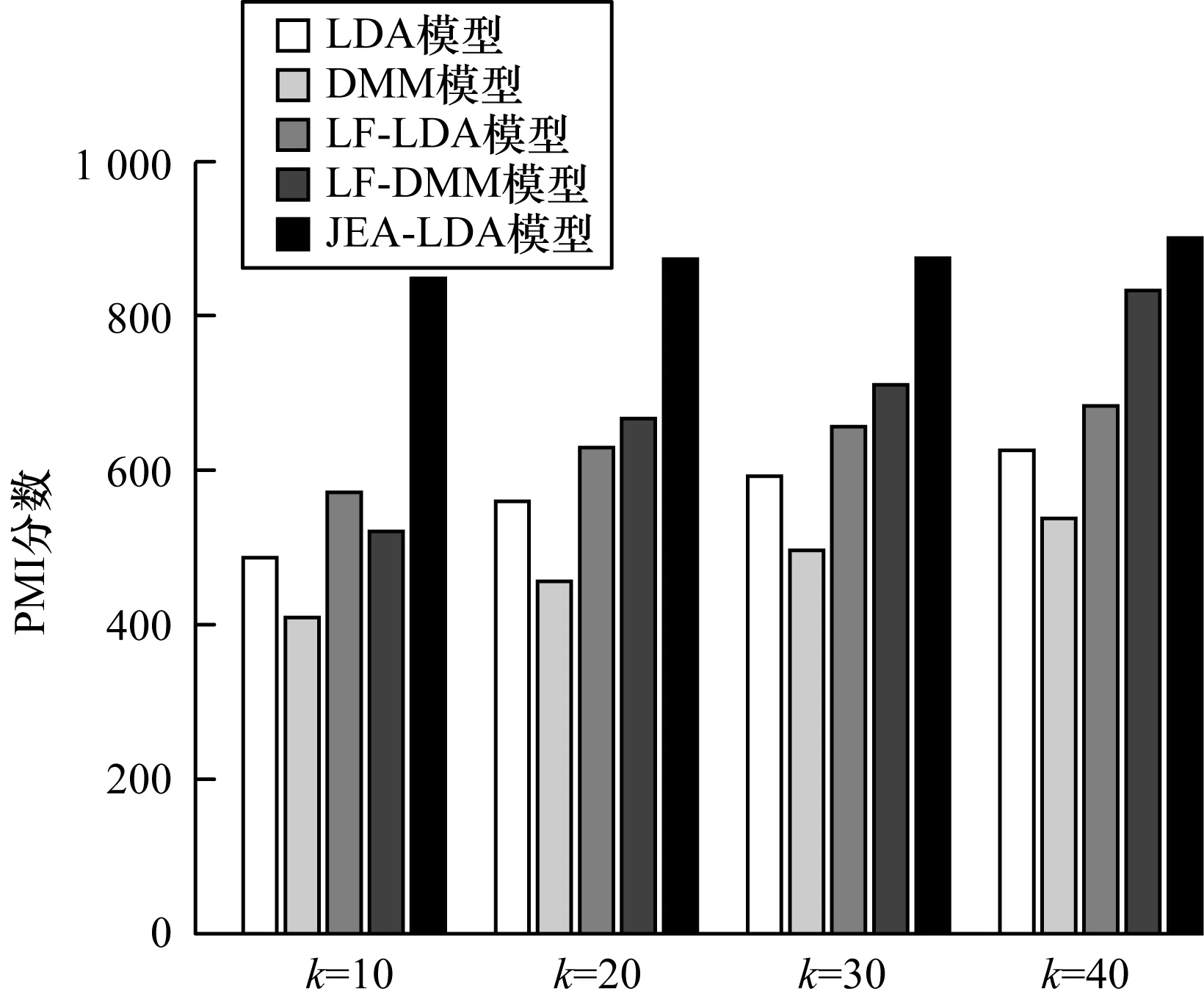
图2 5种模型的PMI分数对比结果Fig.2 Comparison results of PMI score of five models
2.4 分类实验
在本文的对比主题模型中,可以获得模型的文档-主题分布θ,因此,可以用通用分类器对文本进行分类,以测试文本主题分布的效果,本次实验采用SVM分类器。主题之间的区分度越高,文本主题的分布越合理,分类效果越好,模型的学习能力越高。
本文采用精度(P)、召回率(R)和F1值作为每种模型的分类评价指标,5种模型的分类结果对比如表1~表3所示,其中最优结果加粗表示。
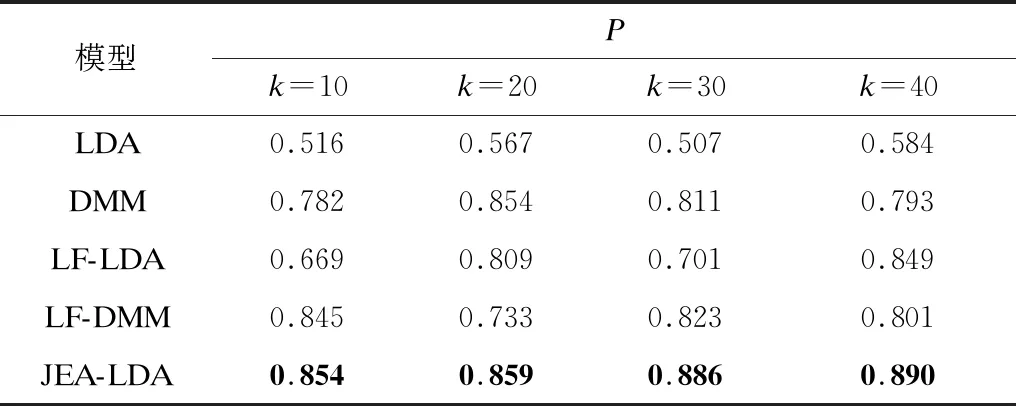
表1 5种模型的分类精度对比Table 1 Comparison of classification precision of five models
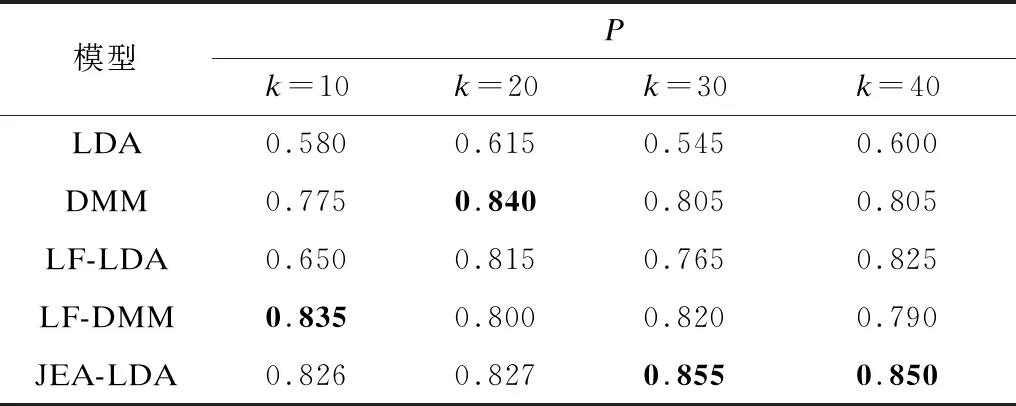
表2 5种模型的分类召回率对比Table 2 Comparison of classification recall of five models
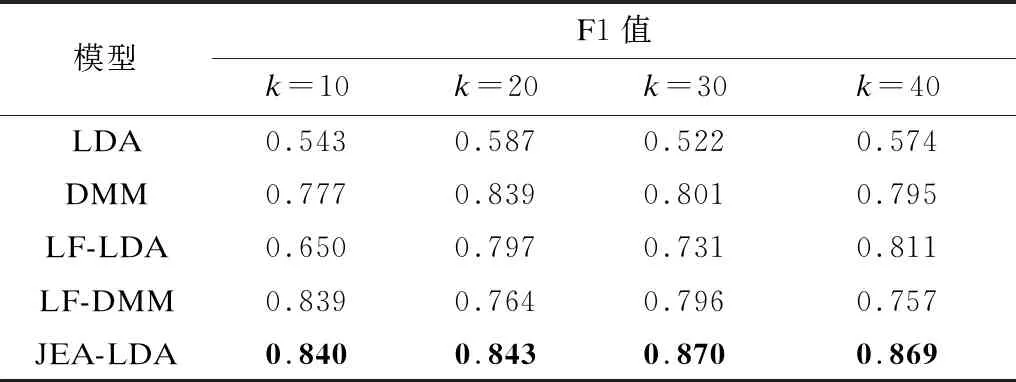
表3 5种模型的分类F1值对比Table 3 Comparison of classification F1 value of five models
从表1~表3可以看出,本文模型通过引入单词嵌入和主题嵌入,在一定程度上改善了主题模型的分类性能。
3 结束语
本文将主题嵌入和单词嵌入融合到LDA主题模型中,在主题和单词之间建立注意力机制,获取主题与单词间的相互关系。在训练单词嵌入和主题嵌入的过程中学习注意力分数,以确保在给定文本中与文本主题相关的单词的权重高于不相关单词的权重。实验结果表明,主题嵌入和单词嵌入相结合能够改善主题提取的效果。下一步将在本文研究的基础上,考虑短文本数据稀疏问题,针对短文本的主题提取和注意力机制进行分析和研究。
