基于深度学习的实时人脸表情识别研究
2020-11-05周章辉谭功全
周章辉, 谭功全
(四川轻化工大学自动化与信息工程学院, 四川 自贡 643000)
引 言
面部表情识别长期以来一直是计算机视觉领域的一项艰巨任务。随着智能化的加快,各种服务机器人层出不穷,而服务机器人的成功无否,很大程度取决于一个机器人能否与用户进行顺畅的交流[1]。因此,机器人需要识别从用户的脸上提取信息,比如识别感情、状态或者性别。面部表情识别在其他领域也是比较热门研究热点,比如在网络教育、智能家居、疲劳检测、工作状态检测、百姓娱乐上,都有很大的应用前景,受到了广大学者的关注[2]。而使用机器学习技术来正确解释这些因素被广泛地证明是复杂的,因为每个任务中的样本具有可变性。传统的机器学习是要先设计出特征提取的方法,对输入的原始图像进行特征提取,如从中提取眼睛周围的纹理特征、嘴巴周围的纹理特征、或者提取颜色特征和形状特征,然后再设计出分类器,对提取的特征进行分类处理[3]。目前,传统的面部表情特征提取方法有局部二元模式[4](Local Binary Pattern,LBP),gabor小波变换[5]和方向梯度直方图(Histogram of Oriented Gradient,HOG)等。奥卢大学的Ojala等人提出LBP算法用来描述灰度图像的局部纹理信息[6],2004年,Ahonen[7]等将LBP算法用于人脸识别领域以得到更高效的提取特征。在分类识别上,一般采用迭代算法(Adaboost)、支持向量机(SVM)等[8]。这些都是人为设计的一些特征提取方法,大都损失了原有图像中的一些特征信息,实际检测的精度受到了很大影响。而卷积神经网络的提出,对于解决面部表情识别问题来说,提供了很大的帮助。卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习的算法,其最早于1998年由Yann Lecun[9]提出,其本质为一个多层感知机,用来处理手写数字识别问题。2012年提出的AlexNet[10],其层次更深,参数规模更大,并且引入了修正线性单元(Relu)作为激活函数,在图像识别中取得了较大的成功。2014年由牛津大学视觉组设计的VGGNet[11],采用小卷积堆叠的方式来搭建整个网络,其深度达到了16层以上。同一年,Google研究设计的GoogleNet Inception V1[12],将多个不同尺度的卷积核、池化层进行整合,利用全局池化层代替全连接层,使得网络参数量和模型大小大大减小,之后分别提出了Inception V2、Inception V3。本文基于GoogleNet Inception V3模型进行CNN改进,改进后的模型分为两个通道,先用3×3的卷积核对输入进行卷积操作,再进行通道的1×1卷积。同时采用L2正则化函数,在每个卷积模块后面都加入了Relu激活函数。基于改进模型,本文设计了一种可视化的人脸识别表情系统,完成了人脸表情实时检测和图片输入检测的功能。并且在FER2013数据集上与主流的人脸表情识别算法进行对比,验证了本文改进的网络模型具有更好的性能。
1 改进的卷积神经网络
CNN在本质上是一种从输入到输出的映射,能够学习较多的输入到输出的关系,但是不需要任何精确的数学表达式来表达输入和输出之间的关系,只需要用已知的模式对卷积网络加以训练,网络就具有输入输出之间的映射关系[13]。并且CNN执行的有监督训练模式,在训练开始之前,用不同的随机数对网络的所有权值进行初始化。本文设计了一种用于人脸识别的深度卷积神经网络结构,如图1所示,包括:(1)在卷积神经网络中加入了新的通道,成为双通道卷积网络,并且在新的通道中加入了卷积层;(2)在每个卷积模块后面都加了一个Relu激活函数;(3)采用与原网络模型不同的L2正则化函数。
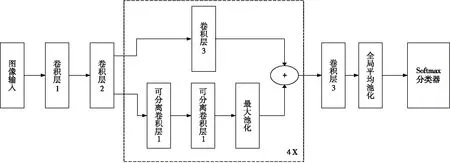
图1 表情识别模型
图1所示的模型含有15个卷积层,以此来形成网络的特征提取,除了最后一个卷积层不进行批归一化操作,其余卷积层都进行批归一化操作。此结构中包含4个残差深度可分离卷积,每个卷积后面是一个批归一化操作和Relu激活函数。最后一层加入了全局平均池化层和Softmax分类器来生成预测值。这个模型训练总参数有58 423个,可训练的参数有56 951个,不可训练参数有1472个。输入层输入的48×48的图像,卷积层1、卷积层2和最后一个卷积层7分别使用8个3×3的卷积核、8个3×3的卷积核和7个3×3的卷积核进行卷积操作。深度可分离卷积层1和深度可分离卷积2均分别使用16个、32个、64个、128个3×3卷积核进行卷积操作。卷积层3分别使用16个、32个、64个、128个1×1的卷积核进行卷积操作。最大池化层采样窗口大小为3×3;Softmax层对全局平均池化层输出的特征进行分类,将人脸分成愤怒、沮丧、恐惧、高兴、悲伤、惊讶、中性。
1.1卷积层
CNN是一个前馈式神经网络,能从图像中提取出拓扑结构,挖掘出数据在空间上的相关性,以减少训练参数的数量,从而改进反向传播算法来优化网络结构的效率。其中的卷积层采用不同的卷积核分别与输入到卷积层的特征图进行卷积求和,将其正则化,再加上偏置,然后再经过该层加入的激活函数最终输出形成神经元,也就是该层不同特征的特征图[14]。通常来讲,卷积层的计算公式为:
j= 1,2,…,N
(1)
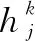
θ(x)=max(0,x)
(2)

图2 Relu激活函数图像
卷积层作为特征提取层,其每个神经元的输入与前一层的局部感受相连接,提取出该局部的特征。卷积层1采用8个3×3的卷积核对48×48的图像进行卷积操作,其特征图的大小为(48-3+1)×(48-3+1)=46×46,得到8个46×46的特征图。同理,卷积层2得到8个44×44的特征图。深度可分离卷积层1与深度可分离卷积层2均分别得到16个44×44、32个22×22、64个11×11、128个6×6的特征图。卷积层3分别得到16个22×22、32个11×11、64个6×6、128个3×3的特征图。卷积层7等得到7个3×3的特征图。
1.2池化层
本文应用了两个池化层,一个最大池化层(Max-Pooling)和一个平均池化层[15](Mean-Pooling)。为了避免将学习到的特征直接去训练Softmax而带来的维数过高的问题,在模型中加入了最大池化层,其目的是将特征图的大小变小,使得特征图的输出具有平移不变性。全局平均池化层不改变输入特征图的大小,将每个特征图转化为一个值。比起使用全连接层减少了参数,加快了训练时间,且可以减少过拟合。
1.3Softmax层
本次CNN设计的最后一层采用的是Softmax分类器。Softmax分类器实质是一种逻辑回归二分类器泛化到多类的情形,从新的角度做了与传统的SVM不一样的处理,即需要将输入分量映射到概率域上做一个归一化,保证其和为1,映射即是概率。其公式为:
(3)
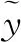
(4)
其中:fj表示当前层的第j个特征图;总体损失是Li遍历训练集之后的均值,再加上正则化项。
2 实验结果及分析
实验使用Pycharm编辑器,在基于python3.65解释器版本下的keras深度学习框架下进行编程。硬件平台为组装台式机:AMD ryzen 2600 cpu、主频3.4 GHz、内存16 GB、Nvidia GeForce GTX1060 3 GB。
实验使用的数据集为Kaggle比赛提供的一个数据集。该数据集包含28 709张训练样本,38 59张验证数据集和3859张测试样本,一共有35 887张包含生气、讨厌、恐惧、惊讶、悲伤、高兴、正常这7种类别的图像,图像分辨率为48×48,如图3所示。为了防止网络过快地过拟合,本文对输入图像做了一些预处理:将采用Imagegenerator生成器对图像进行旋转,变形和归一化操作,同时扩充数据量,避免因数据量太少而导致过拟合。模型的优化器采用Adam算法,为随机梯度下降算法的变种,学习率最大值最小值设置为0.1,学习衰减率为0.1,随着迭代次数的增长,其学习率也相应做改变。通过多次的调参实验,经过5000次的迭代训练,本文设计的网络模型在FER2013数据集上的识别效率达到66.7%,见表1。网络训练的过程中,网络损失值逐步减少,整体过程趋于平稳,收敛情况不错。图4和图5分别描述了本文设计的卷积神经网络的训练准确率(train_acc)和验证准确率(val_acc)。图6和图7分别描述了训练损失值(train_loss)和验证损失值(val_loss)。

图3 表中设置的7类表情类别

表1本文方法在FER2013上的识别效率

图4 在FER2013上训练准确率曲线

图5 在FER2013上验证准确率曲线

图6 在FER2013上训练损失曲线

图7 在FER2013上验证损失曲线
从表1可以看出,本文模型对高兴和惊讶这两种表情的识别准确度最高,分别为88%和85,但是对于悲伤和恐惧这两种表情的识别准确度较低,为47%和53%。猜想应该需要通过细化脸部的特征提取,以此来提高分类的精准度。
与传统的算法在FER2013数据集上进行对比,结果见表2。其中,LBP是由Rivera设计的、使用了人工特征提取方法进行表情识别的算法[12],其识别精度略低于基于深度学习的算法。CNNs算法[16]使用并行卷积神经网络,且构造了3个不同的通道,最终的识别效率达到65.6%。而本文设计的双通道的卷积神经网络识别效率达到了66.7%,比LBP算法提高了1.2%,比三通道的CNNs算法提高了1.1%,说明本文设计的网络模型在人脸表情上拥有更好的识别效率。

表2FER2013数据集上识别率对比
3 基于改进模型的人脸表情识别系统
本文基于OpenCV(计算机视觉库)技术,实现了人脸表情的自动分类,同时实现了利用摄像头实时识别人脸表情和在图片中识别人脸表情的功能。并且利用python中集成的PyQt5库文件,制作了人脸表情识别的可视化界面。具体的识别过程如下:首先是载入haarcascade_frontalface_default.xml人脸检测模型、载入训练好的人脸表情识别模型,然后输入静态图片或者调用摄像头采集人脸图像信息,再对人脸进行检测、定位,而后将检测到的人脸图像转为灰度图片,再从灰度图片中提取出感兴趣区域,将其大小转换为64×64,之后用通过本文设计的卷积神经网络训练后得到的人脸表情识别模型对检测到的人脸进行表情识别,最后通过制作的可视化界面返回表情预测值。图8为本文设计的人脸表情识别的系统框架图。图9为可视化人脸表情检测界面,其中,“选择模型”功能选择的是本文训练好的精度为66.7%的人脸表情识别模型;“实时摄像”调用的是电脑上安装的联想笔记本g410自带的摄像头,以实现人脸表情实时识别;“选择图片”功能就是选择想要识别的图片来对其进行表情识别;“用时”表示的是对输入图像进行表情识别分类所产生的时间;“识别结果”输出的就是分类中最高概率的标签。图10为输入图片部分识别效果图,其中,绿色框标出来的为检测到的人脸部分,旁边绿色的字样为预测标签;图片右方为表情标签的预测概率值,概率最高的则为输出预测标签值。

图8 人脸表情识别系统框架图

图9 可视化人脸表情检测界面

图10 表情识别效果图
由图10可知,图10(a)识别的是一张表情为愤怒的图片,通过模型识别出来为愤怒的概率为65.54%,恐惧的概率为29.98,识别时间为0.451 s,选择最高概率的类别作为输出,所以该图最终识别为愤怒的表情;图10(b)识别的是一张表情为悲伤的图片,通过模型识别出来为悲伤的概率为43.80%,正常的表情为34.13%,识别时间为0.502 s,选择最高概率的类别作为输出,所以该图最终识别为悲伤的表情;图10(c)识别的是一张表情为惊讶的图片,通过模型识别出来为惊讶的概率为96.95%,害怕的概率为1.98%,识别时间为0.203 s,选择最高概率的类别作为输出,所以该图最终识别为惊讶的表情;图10(d)识别的是一张表情为高兴的图片,通过模型识别出来为高兴的概率为52.56%,正常的概率为38.55%,识别时间为0.486 s,选择最高概率的类别作为输出,所以该图最终识别为高兴的的表情。该系统的UI界面简洁、色彩舒适、交互简单、实用性强,识别时间和识别结果都清晰可见,对于一般场景的应用十分合适。由4组表情识别实验可知,识别图片表情所用时间均远远低于1 s,所耗费时间成本低,满足了人脸表情识别的实时性,且4组实验的识别都正确,识别精度高。
4 结束语
本文基于GoogleNet对深度卷积神经网络进行了优化调参,通过在Pycharm编辑器中,使用python解释器,基于keras平台构建优化后的深度卷积神经网络模型,以此来有效地对人脸表情进行识别。该卷积神经网络可以直接将图像的像素值作为输入,通过训练数据集中划分的训练集来自主学习,不明显地获得输入图像更抽象的特征,而不需要如传统人脸表情识别那样给出具体的特征提取过程。且该人脸表情实时识别系统可以采用不同模型来应对不同的人脸表情识别场景。尽管本文的卷积神经网络尽可能地减少了参数,提高了训练速度,但在数据量较为稀缺的情况下,仍需要花费较长的时间进行训练,相比较来说,此时传统的机器学习方法更具优势。下一步的研究方向是进一步考虑各个层之间特征图的关系,在超参数的选择上进一步优化,以及进一步优化卷积神经网络的结构,以提高不同应用环境下的识别率和训练速度。
