面向视频监控基于联邦学习的智能边缘计算技术
2020-11-03赵羽杨洁刘淼孙金龙桂冠
赵羽,杨洁,刘淼,孙金龙,桂冠
(南京邮电大学通信与信息工程学院,江苏 南京 210003)
1 引言
由于物联网技术[1]、云计算技术[2]以及第五代移动通信技术[3-4]的推动,全球数据量呈指数级增长。由中国信息通信研究院发表的《大数据白皮书》指出,全球数据量将于2020 年年底达到50 ZB(1 ZB=240GB)。面对如此庞大的数据量,传统的以云计算技术为核心的集中式数据处理方式逐渐显现出瓶颈。与此同时,随着边缘端硬件设备数据处理能力不断增强,以边缘计算技术[5-6]为核心的分布式数据处理方式应运而生。
视频监控作为物联网技术中的一环越来越受到人们的重视,它广泛应用于交通[7]、安防[8]等各个领域。早年间,人们通过建立专门的监控室来观测监控视频,这样做不但人力成本昂贵,而且不能及时捕捉关键信息。近些年,深度学习在目标检测领域快速发展,使智能视频监控系统在各个领域得以落地。但是面对海量的视频数据,传统的集中式云计算处理方式能力有限,主要体现在以下3 个方面。
1) 实时问题。随着边缘摄像头数量的不断增加,将在网络边缘产生大量的实时数据。把数据从边缘设备传输至云计算中心占用大量的网络带宽,造成网络时延。
2) 效率问题。在海量视频数据中,只有少部分数据具有信息价值,直接传送视频数据占用大量网络资源。基于深度学习的视频分析方法需要强大的计算能力支持,不经过处理的视频数据会给云计算中心带来计算负担。
3) 隐私问题。视频数据中携带有大量的个人隐私,将这些视频数据直接上传云计算中心增加了泄露用户隐私的风险。
近些年,为了解决深度学习过度依赖硬件资源的问题,研究者提出了多种轻量级神经网络模型。Zhang 等[9]提出分组卷积和通道随机组合操作对神经网络进行压缩,Howard 等[10]提出深度可分离卷积来减少标准卷积的运算量,Tan 等[11]提出自动神经网络结构体系搜索方法来构建轻量级神经网络。这些方法使神经网络可以在移动终端或者嵌入式设备中运行。吕华章等[12]介绍了近些年边缘计算标准化进展情况,张佳乐等[13]探究了边缘计算数据安全与隐私保护现状。大量参考文献表明,边缘计算可以有效突破云计算当前瓶颈,是大势所趋。
基于上述考虑,本文提出一种基于联邦学习(FL,federated learning)的分布式边缘计算模型,并将其应用于视频监控系统,该方法仅传输神经网络模型权重,免于视频数据的传输。经实验发现,本文提出的分布式边缘计算模型可以针对不同场景实现单独训练,以提高目标检测的准确性。联邦学习的引入不仅可以保证边缘端用户隐私不会泄露,还可以减少神经网络模型的训练时间。
2 系统模型
2.1 基于联邦学习的边缘计算视频监控模型
图1 是传统的集中式云计算模型。在当前行情下,不同企业拥有不同数据格式的视频数据库,集中式云计算模型需要将这些数据统一上传至云端服务器,经过数据清洗和数据格式统一后训练出一个通用的神经网络检测模型。在完成神经网络模型的建立后,各企业需将待检测的视频上传至云端服务器统一检测,服务器再将检测结果逐一下发。这样会占用大量的网络资源,且难以满足一些对实时性要求较高的应用场景。各个企业之间存在数据壁垒,将数据上传至云端服务器存在数据泄露的风险。除此之外,由于各企业数据量不同,通用的神经网络模型对于数据量较少的企业不友好,检测效果较差。
针对以上问题,微众银行[14]提出如图2 所示的联邦学习模型。在联邦学习模型中,各企业只需将神经网络模型下载到本地,利用本地的数据进行训练,最后将训练完成的权重参数上传。云端服务器根据各企业上传的权重参数联合优化神经网络模型。视频的检测与分析都在数据库本地进行,既保证了数据的安全性,也保证了数据处理的实时性。
本文结合云计算模型与联邦学习模型,提出基于联邦学习的边缘计算视频监控模型,如图3 所示。该模型由4 个部分组成,分别是云端服务器、企业服务器、边缘开发板和摄像头。云端服务器负责存储公共数据集和训练通用神经网络模型,并将网络模型分发给企业服务器;企业服务器针对不同场景根据本地数据库训练与更新神经网络模型,并将算法部署于边缘开发板NVIDIA TX2 上;边缘开发板NVIDIA TX2 负责实时分析视频数据,并将处理后的视频数据上传至企业服务器统一管理;摄像头负责实时采集视频。企业服务器完成神经网络模型训练后,将网络权重上传至云端服务器,云端服务器联合处理各企业的网络权重,用于更新通用神经网络模型。
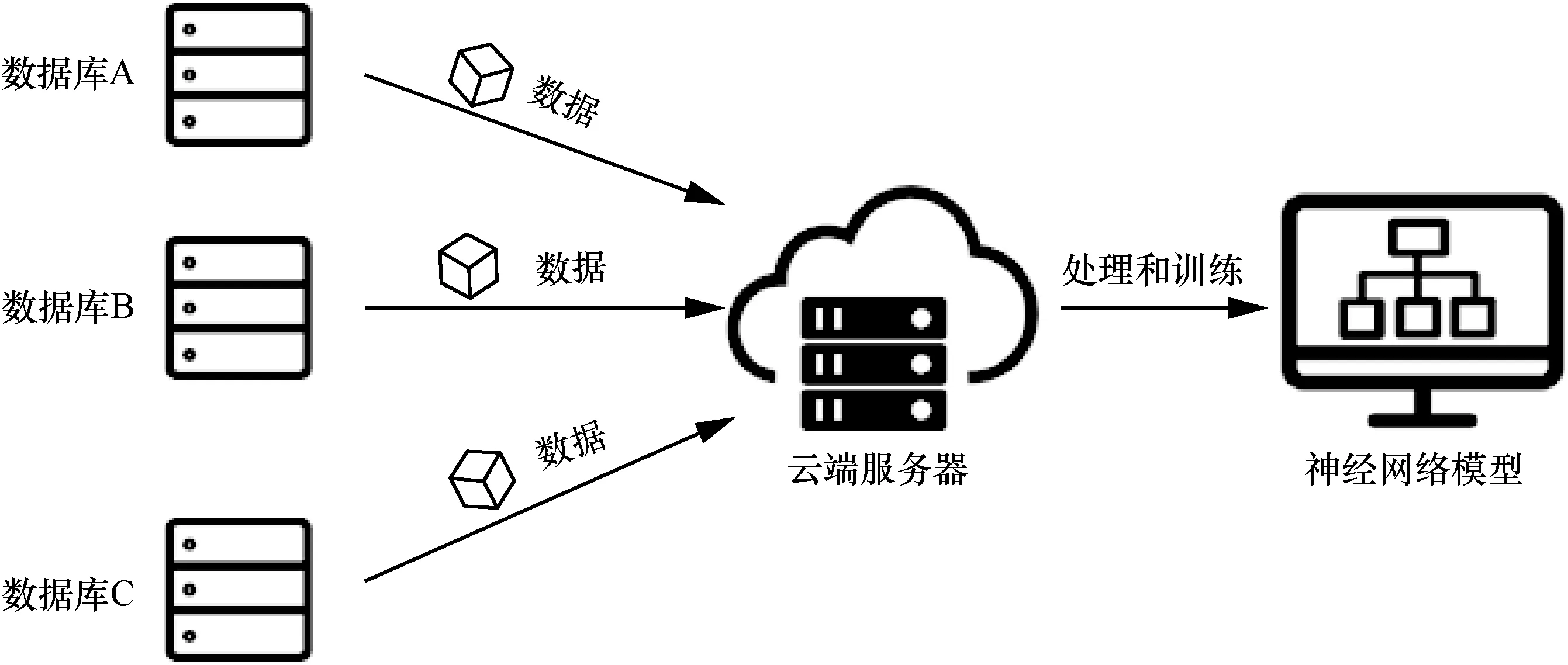
图1 传统的集中式云计算模型
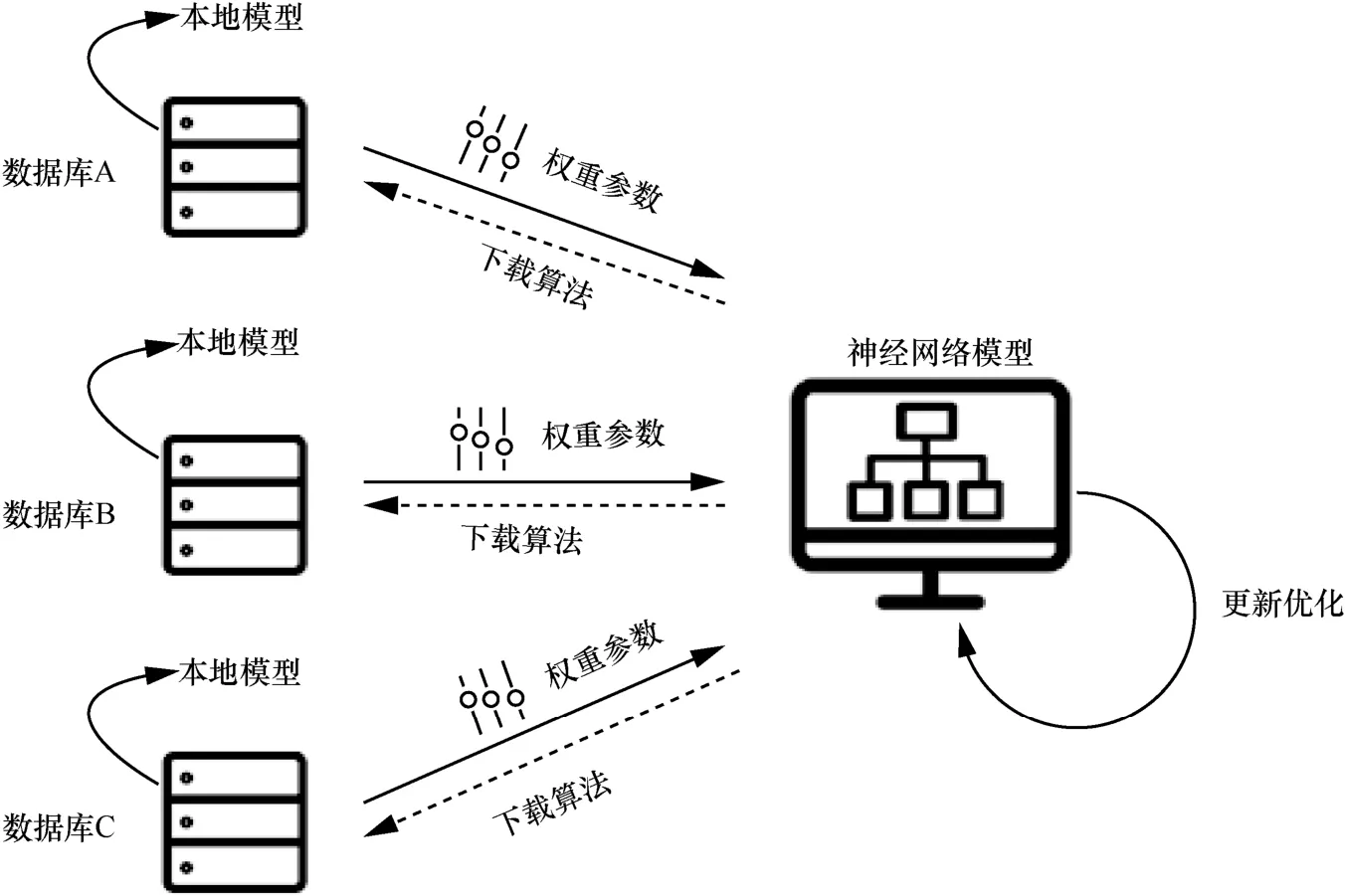
图2 联邦学习模型
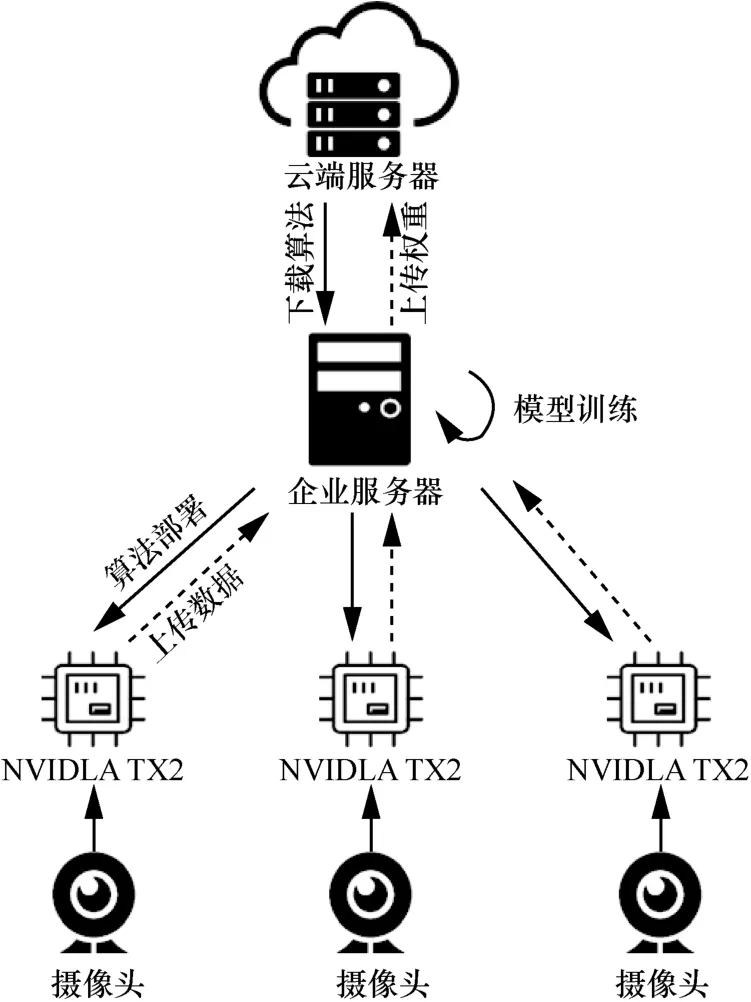
图3 基于联邦学习的边缘计算视频监控模型
本文以智能安全帽检测系统为例来验证基于联邦学习的边缘计算视频监控模型。为了提高神经网络在边缘开发板上的检测速度,本文采用改进YOLOv3[15]神经网络检测模型。
2.2 改进YOLOv3 神经网络模型
在基于深度学习的目标检测领域,根据检测方式的不同,检测方法大体可以分为两类:基于候选区域的两步目标检测算法和基于端到端的一步目标检测算法。其中,基于端到端的一步目标检测算法以其检测速度快著称。本文选取基于端到端的目标检测算法YOLOv3,并在其基础上进行改进,使其能够在计算能力受限的边缘设备NVIDAI TX2 上快速运行。
YOLOv3 的检测原理为将输入的图像人为地划分为T2个方格,每小方格产生A个边界框,若待检测物体的中心位置位于某个小方格中,则由该小方格负责预测该物体。改进YOLOv3 神经网络结构如图4 所示。
改进YOLOv3 神经网络结构主要分为4 个部分:输入层、主网络框架、多尺度检测模块和非极大值抑制模块。主网络框架由卷积层组合而成,用于提取图像特征。与YOLOv3 不同的是,本文采用文献[10]提出的深度可分离卷积层代替标准卷积层,通过将标准卷积分解为深度卷积和逐点卷积,从而降低了神经网络的浮点数运算量,其结构对比如图5 所示。多尺度检测模块从3 个不同尺度的特征图上检测物体,其中大尺度的特征图含有更多特征信息,负责检测小物体;小尺度的特征图含有更多全局信息,负责检测大物体。非极大值抑制模块用于获取局部最大值,从而抑制神经网络产生多余的候选框。
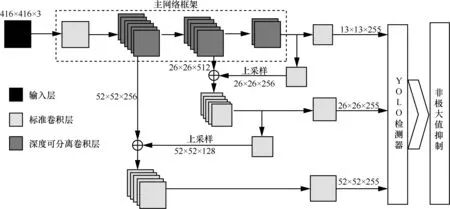
图4 改进YOLOV3 神经网络结构
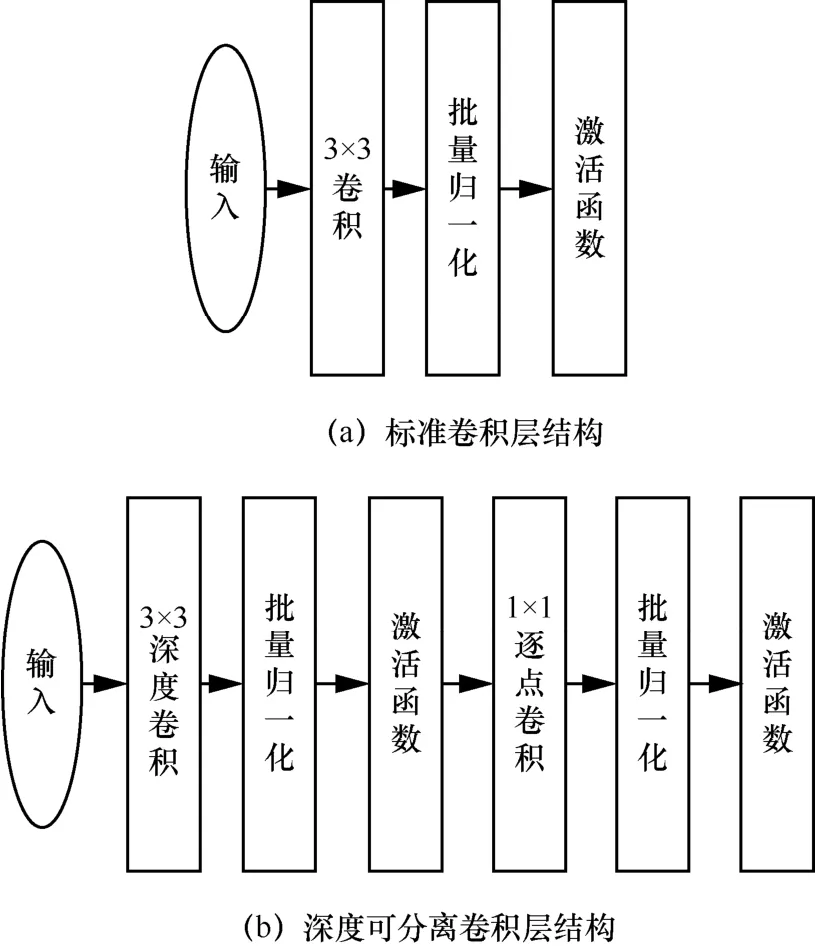
图5 标准卷积与深度可分离卷积结构对比
改进YOLOv3 的损失函数如式(1)所示,主要由中心坐标损失losscenter、边界框大小损失lossscale、置信度损失lossconf以及分类损失lossclass这4 个部分组成。losscenter和lossscale采用和方差的计算方式,如式(2)和式(3)所示;lossconf和lossclass采用交叉熵的计算方式,如式(4)和式(5)所示。
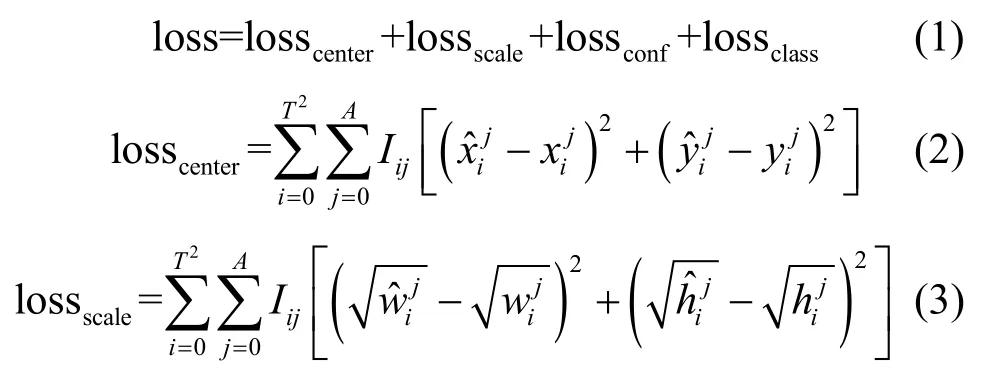

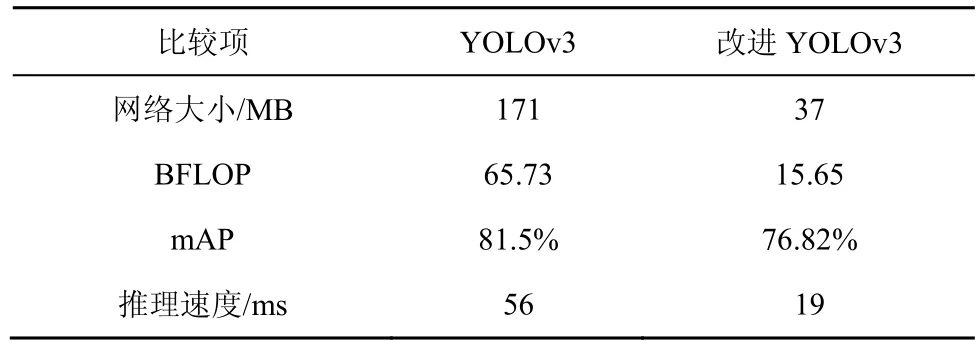
表1 YOLOv3 与改进YOLOv3 对比
2.3 通用模型更新方法

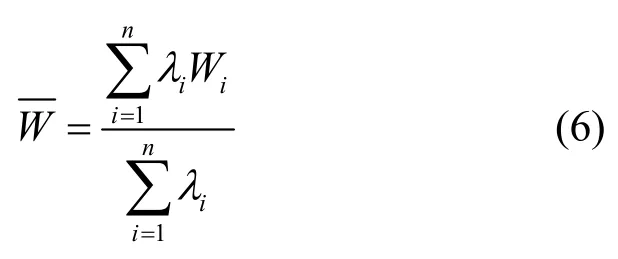
考虑到边缘端数据集数据量较小的问题,为了防止神经网络模型过拟合,采用迁移学习[16]的方式训练。企业服务器在接收到来自云端服务器的通用神经网络模型后,固定主网络框架的权重,根据本地数据集微调模型即可,这样可以极大地缩短神经网络模型的训练时间。
3 实验与结果分析
在本实验中,企业服务器采用的图形处理单元(GPU,graphics processing unit)为NVIDIA GTX 1080Ti,边缘开发板为NVIDIA TX2,操作系统为Ubuntu 16.04,编程语言为Python,深度学习框架为TensorFlow。表2 为企业服务器与NVIDIA TX2的性能、功耗、成本对比。
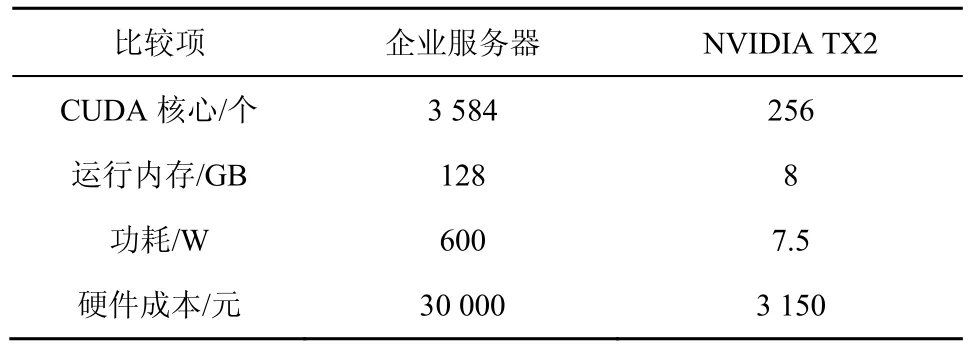
表2 企业服务器与NVIDIA TX2 的性能、功耗、成本对比
3.1 数据集的建立
在云端服务器侧,本实验通过网络爬虫以及人工标注的方式,结合通用安全帽佩戴检测数据集(SHWD,safety helmet wearing detect dataset)制作了包含15 093 幅图像的数据集,用于训练通用神经网络。在企业服务侧,根据摄像头角度以及距离远近,本实验制作了3 组不同场景的数据集,每组数据集包含2 000 多幅图像,通过迁移学习的方式验证不同场景下基于联邦学习的边缘计算视频监控系统的检测准确度。为了丰富数据集,提高检测效果,在训练神经网络模型之前,本实验采用了数据增强技术。除了常见的翻转、按比例缩放、随机裁剪、移位以及添加高斯噪声等数据增强方法,本实验还采用了Mixup[17]数据增强方法。
Mixup 原理如图6 所示。将2 幅图像缩放至同一大小后逐像素相加并按比例融合,2 幅图像的标签组合成新的标签。在计算损失函数时,需按照融合时的比例分别计算损失函数再相加。此种方式通过人为地引入遮挡来提高目标检测的准确性,尤其适用于安全帽检测这种含有目标遮挡的场景。
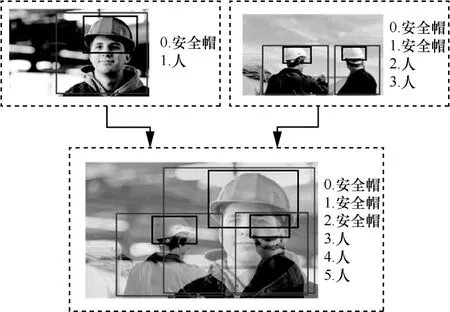
图6 Mixup 原理
3.2 评价指标
在多分类目标检测任务中,神经网络检测模型的好坏并不能单纯由精准率来衡量,需要综合评定模型的分类和定位性能。在目标检测领域,定位性能依靠交并比(IoU,intersection over union)来衡量,即预测边界框与真实边界框的交集和并集的比值。在本实验中,当IoU≥0.5 时判定为正确检测。对于某一特定类别,根据IoU 以及置信度阈值可以计算出精准率与召回率,并进一步计算平均精度(AP,average precision),最后计算各类别AP 的平均值即为mAP。
3.3 结果分析
图7 为3 个不同场景数据集训练改进YOLOv3与MobileNet-SSD[10]时的损失值与mAP 对比,其中mAP 每遍历一次数据集计算一次,损失值取值为遍历数据集时每次神经网络权重更新时的平均值。由于改进YOLOv3 与MobileNet-SSD 两者的损失函数定义不同,无法从损失值直接观察出模型的检测准确度,但可以得出,两者均需要遍历160 次左右数据集来完成模型训练,它们的mAP 对比如表3 所示。
实验发现,若采用集中式云计算模型,仅训练一个云端通用神经网络,测得3 个数据集的mAP分别为71.98%、68.32%和73.05%。除此之外,在实际应用中,企业服务器处理每帧图像的时间为19 ms,若采用集中式云计算模型,系统无法同时处理多路摄像头的视频数据,大量的待检测视频数据会导致系统内存崩溃。通过迁移学习的方式分场景训练,改进YOLOv3 神经网络较云端通用神经网络mAP平均提升18%,并且由于本地数据集数据量较少,神经网络的训练时间大大减少。企业服务器在完成神经网络模型的训练后将算法部署于边缘开发板NVIDIA TX2 上,从而实现视频数据的本地化实时处理。NVIDA TX2 支持统一计算设备架构(CUDA,compute unified device architecture)与TensorFlow深度学习框架,不需要模型转换即可直接运行神经网络模型,检测速度可达18 frame/s,其硬件成本仅为企业服务器的十分之一。最后,企业服务器上传神经网络权重至云端服务器用于更新通用神经网络。图8 为安全帽检测实际效果。
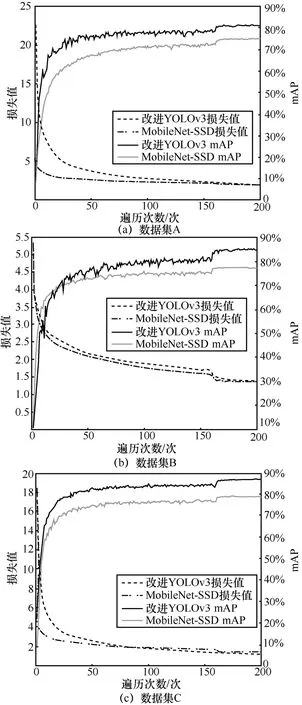
图7 改进YOLOv3 与MobileNet-SSD 的损失值与mAP

表3 改进YOLOv3 与MobileNet-SSD 的mAP 对比

图8 安全帽检测实际效果
4 结束语
现有的集中式云计算处理视频监控的方式网络数据传输量大,系统时延高且可能泄露用户隐私。针对这些问题,本文提出基于联邦学习的边缘计算视频监控系统,采用轻量级神经网络模型,将视频的分析处理分布于边缘开发板中,神经网络模型的训练分布于企业服务器中,有效地缓解云端服务器的计算与存储负担,免去视频数据的传输,并且在打破数据孤岛的同时保护用户隐私。除此之外,本文所提的基于联邦学习的边缘计算视频监控系统相较于传统系统节约了硬件成本以及运行功耗,更有利于实际项目的部署。未来工作将继续研究联邦学习算法,优化通用神经网络权重的更新方式,进一步提升检测效果,引入神经网络压缩与加速算法,使系统达到实时要求。
