基于Att-iBi-LSTM 的新闻主题词提取方法研究
2020-10-30赵彤洲江逸琪高佩东
柴 悦,赵彤洲,江逸琪,高佩东
武汉工程大学计算机科学与工程学院,湖北 武汉 430205
新闻主题词提取是将核心词和短语从新闻文本中挖掘出来的过程。主题词包含有助于人们理解文本内容的主要信息,通过查看主题词,用户可以更轻松地找到他们需要的新闻。由于主题词是对文本主题信息的高度凝练,人们还可以使用它们以较低的复杂度来计算文本相关性,因此为许多自然语言处理应用带来了便利[1-3]。
传统的主题词提取方法主要有两种:一种是根据词的统计信息对关键词进行排序,如词频-逆文档频率方法[4]和TextRank[5]等;另一种是应用机器学习算法,提取各种特征来训练模型,如隐马尔可夫模型[6]、支持向量机(support vector machine,SVM)[7]、朴素贝叶斯模型[8]等。词频-逆文档频率方法在进行文档主题词提取时,由于文档主题结构特征缺少的原因,导致该方法主题词提取效果差。TextRank 考虑了部分文档主题结构特征,如文档中词与词之间的关系,但仍然倾向于选取文档中的高频词作为主题词。应用机器学习算法进行主题词提取,通过提取各种特征来训练其模型已被证明可以获得出色的性能,但这种方法依赖人工定义的规则,没有充分考虑词的上下文信息且对特定的数据集敏感[9]。
近年来,长短期记忆(long short-term memory,LSTM)模型在多种NLP 问题中被广泛使用,如情感分析[10]、词性标注[11]、命名实体识别[12]、关键词抽取[13]等问题。但是LSTM 模型在进行主题提取时从句子开头到中心词建模,没有考虑句子下文对该词的影响。
为了更好地解决这些问题,文中提出了一种双向的LSTM 网络模型,用于主题词提取任务。文中将主题词提取任务视为一个二分类问题,对于句子中给定的词,训练一个分类器来确定它是否为主题词。具体而言,需要从两个方面考虑信息,即中心词的内容及其上下文信息。通过双向的LSTM 以从句子开头到中心词和从结尾到中心词两个方向对给定单词及其上下文建模。通过这种方式,模型可以捕获中心词的句子级信息。通过利用中心词的上下文的文本信息,模型则可以判断其是否为主题词。
此外,当给定一句话时,某些词在主题中比其他词更具有代表性。例如,在“目前,跳伞比赛一切正常……”一句中,如果想确定“跳伞”一词是否为主题词,“比赛”一词的信息比其他词对“跳伞”的判决有更大的影响。即,应该明确每个单词的重要性,然后生成给定词的向量表示。因此,在双向的LSTM 的基础上引入了一种自注意力机制[14-15],通过自注意力机制考虑不同单词的重要性来生成给定单词的表示向量,从而更好地从文本中提取主题词。
由于深度学习网络模型需要大规模的训练数据,并且人工标注的训练数据的大小非常有限,无法满足模型的训练要求。文中提出一种生成此任务的训练语料库的方法,通过该方法获得了大量粗数据集。为了充分利用这些训练数据,文中提出了一种两阶段训练方法来训练模型。首先,使用粗数据集对模型进行预训练,然后使用人工标注的数据重新训练模型。这样,与仅使用人工标注的数据相比,模型获得了更好的性能。
1 相关工作
1.1 LSTM 模型
LSTM 网络模型属于一种循环神经网络(recurrent neural network,RNN),通过在模型中引入控制门解决了一般的RNN 存在的长期依赖问题[16]。所有循环神经网络都具有神经网络的重复模块链的形式,LSTM 也具有这种链式结构,LSTM模型如图1 所示。

图1 LSTM 模型Fig.1 LSTM model
LSTM 模型的单个重复模块是由t 时刻的输入词向量wt,细胞状态Ct,临时细胞状态,隐层状态ht,遗忘门ft,记忆门it,输出门ot组成。LSTM 的信息更新过程是一个遗忘无用信息并记忆新信息的过程,并在这个过程中的任意时刻t 均会输出一个隐层状态ht,其中遗忘ft,记忆it和输出ot均与上个时刻的隐层状态ht-1和当前输入wt有关。于是t时刻的LSTM 的状态更新为[16]:式(1)~(6)中,Wf、Wi、Wc和Wo分别表示其下标所对应单元的权重矩阵,bf、bi、bc和bo为偏移向量。σ和tanh 为两种激活函数,如式(7)、式(8)所示。
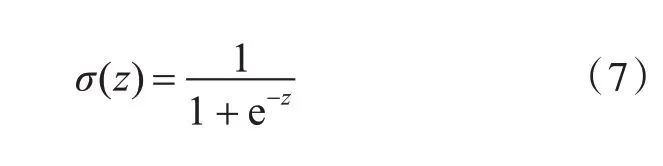
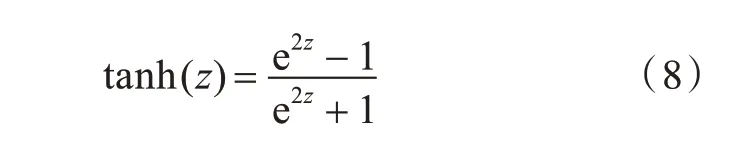
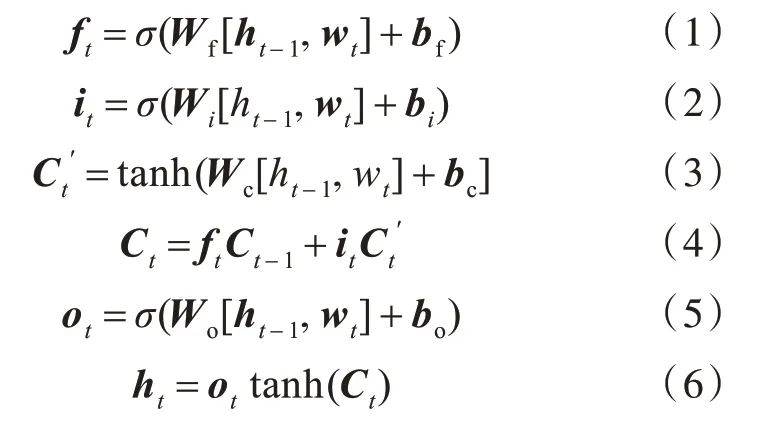
则,t时刻隐含层状态可以表示为:
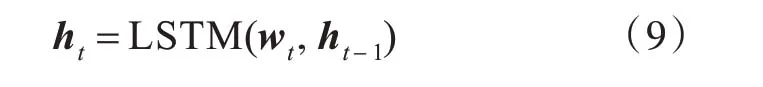
1.2 Attention 机制
Attention 模型结构如图2(a)所示。
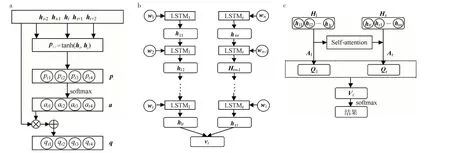
图2 模型结构:(a)Attention 模型,(b)iBi-LSTM 模型,(c)Att-iBi-LSTM 模型Fig.2 Structures of models:(a)Attention model,(b)iBi-LSTM model,(c)Att-iBi-LSTM model
通过Attention 机制获得注意力权重αij,αij表示i 时刻词wi的上文或下文中第j 个词wj对wi的影响。为了使获得的注意力权重发挥作用,将隐含层状态hi通过配置注意力权重得到qi,如式(10)所示:
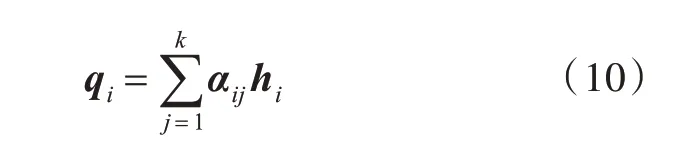
其中,αij的计算过程如式(11)所示:
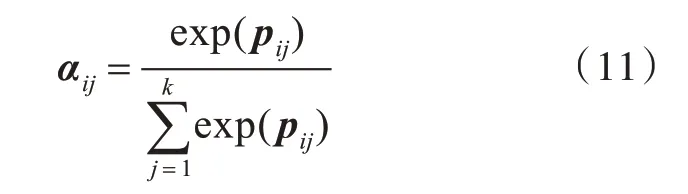
k 为wi上文或下文中词的数量,pij为目标注意力权重,pij=tanh(hi'hj),tanh 是一种注意力学习函数,ht是LSTM 网络输出的特征向量。
2 双向LSTM 引入Attention机制模型
2.1 双向的LSTM 模型
文中将主题词提取看作一个二分类问题,采用LSTM 构建分类器。设当前词为中心词,本文视中心词及其上文具有相同重要性。但是,在传统的LSTM 模型中,只能使用从句子开头到中心词,从而忽略了中心词的后续文本信息的影响,这样有可能丢失重要信息。因此,为了充分利用中心词的上下文信息,提出改进的双向LSTM 模型(iBi-LSTM)进行词分类,将中心词的上下文本信息都输入到模型中,并在两个方向上将中心词与其上下文信息一起建模,以便计算中心词的概率并判断其是否为主题词,如图2(b)所示。
在图2(b)中,采用了两个LSTM 对中心词及其上下文信息进行建模,一个以从左到右的方式对从句子开头到中心词的词进行建模(LSTMl),另一个从句子结尾到中心词的信息进行建模(LSTMr)。wt表示文档中的第t 个词的词向量,hlt为t 时刻LSTMl的隐藏层的输出,hrt表示t 时刻LSTMr的隐藏层的输出,则:
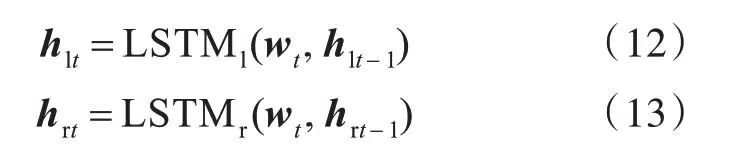
2.2 Att-iBi-LSTM 模型
Attention 机制可以通过获取的注意力权重来区分词向量中各语义编码的重要性,增强模型提取特征的能力,因此该方法可以提高模型分类的准确率。本文通过引入Self-Attention 来获取句子中词之间的语义或句法特征,如图2(c)所示。
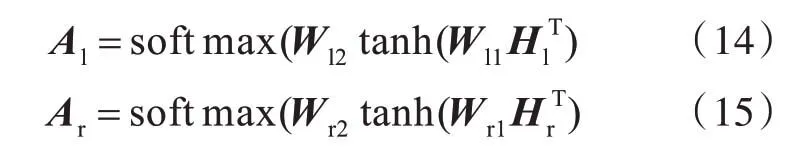
其中,W1是一个维度为da×u的参数矩阵,W2是一个维度为r×da的参数矩阵,u 为隐藏状态向量hi的维度,r 是所采用的multi-hop 注意力机制的hop 数量,da为设置的权重矩阵的维度。注意力权重矩阵A是multi-hop 注意力矩阵,它有助于在对当前单词进行建模时显式捕获语义信息。与传统的single-hop 注意力机制相比,multi-hop 注意力机制使模型能够专注于上下文的不同部分,从而可从多方面捕获句子信息。
将注意力矩阵A和隐藏状态向量H相乘,以生成中心词wt的加权向量表示:

最后,通过对Cl和Cr中的行向量求平均,得到两个方向上中心词的向量表示,然后将这两个向量连接起来以生成中心词的最终向量表示Vt。然后将Vt输入softmax 层以生成中心词是否为主题词的概率分布,如式(16)所示:
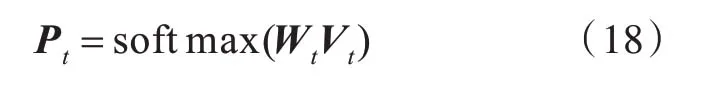
2.3 模型训练
主题词提取实质是一个二分类问题,即是主题词或者不是关键词。采用Adam 作为模型的优化器,该模型将AdaGrad 和RMSProp 算法融合,可基于训练数据迭代更新网络权重实现自适应学习[17]。
分类函数为softmax 函数。模型训练目标就是最小化损失函数,本文使用式(17)的交叉熵作为损失函数:
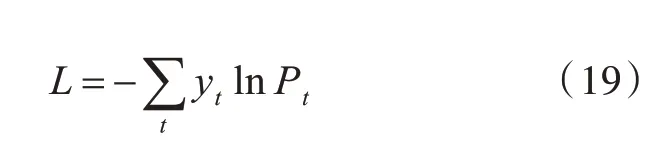
其中,yt表示样本t 的标签,正类为1,负类为0,Pt表示样本t预测为正的概率。
为了更好地训练模型,本文提出一种两阶段训练方法:首先,使用粗数据集对模型进行第一阶段的训练,然后,使用人工标注的数据进行第二阶段的模型训练。
训练深度神经网络模型需要大规模的训练数据。然而,对于主题词提取的任务,需要人工来标注训练所需的语料。由于人工标注的数据集的数量有限,所以本文提出了一种自动标注新闻文本中的主题词并可生成大规模带标签的数据集,用加权词频-逆文档频度值[Tidf,如式(22)所示]作为数据集中主题词的判断依据。但是,这种自动标注的主题词不一定准确,因此将生成的数据集作为第一阶段(预训练阶段)训练的数据集,即粗数据集。
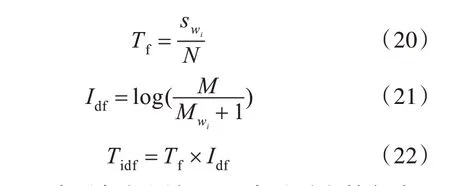
式(20)中,Tf表示加权词频,Idf表示逆文档频度,是某个词在标题中出现的次数,s2是这个词在文章正文中出现的次数,通常1 ≥s1≥0,因此在实验中词wi在标题中出现则swi=2(s2+1)。式(21)中,M 是语料库的总文档数,Mwi是包含该词的文档数。
3 实验部分
3.1 数据集
本实验自建了一个小规模数据集,数据来源于新浪新闻的体育、娱乐和科技新闻共12 000 篇文章,其中体育新闻、娱乐新闻和科技类新闻各4 000 篇。分别从体育、娱乐和科技新闻中随机抽取1 000 篇新闻文本进行人工标注,然后根据2.3节的方法自动标注剩余的9 000 篇新闻文本,数据集如表1 所示。
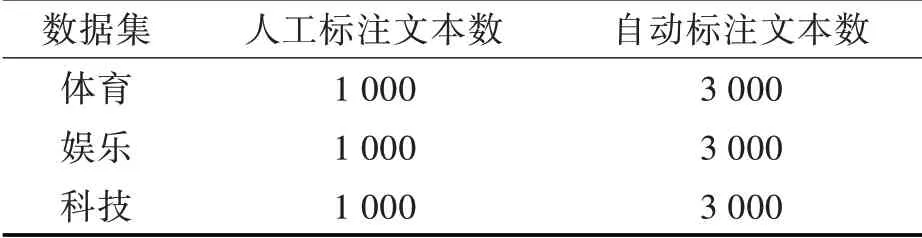
表1 数据集Tab.1 Data sets
3.2 实验参数设置
在实验过程中,使用预训练的词向量,并在训练过程中使其保持不变。这些词向量是通过在搜狗新闻数据集上使用Word2Vec的Skip-gram模型[18]进行训练得到的,每个词向量的维度设置为100。每个隐藏状态的维度也设置为100,用于计算自注意力的参数da设置为128,batch_size 设置为128,Adam 的学习率设置为0.001。
3.3 评价指标
采用精确度(precision,P)、召回率(recall,R)和F1值作为模型性能的评价指标。将主题词提取看作是一个二分类问题,主题词为一类A,非主题词为一类B。对于类别A,预测结果与真实结果相同的样本数为Nptrue,预测结果为A 但实际结果不是A 的样本数为Npfalse,实际结果为A 但预测结果不为A 的样本数为Nfalse,则:
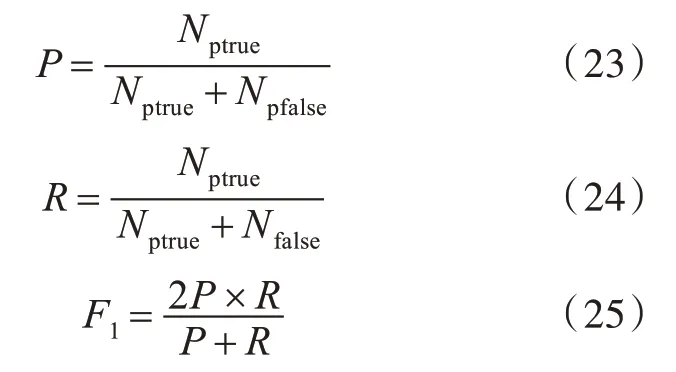
3.4 实验结果与分析
将本文的iBi-LSTM 和Att-iBi-LSTM 方法与现有的SVM、TextRank 和LSTM 模型方法对比,其中数据集相同。
实验1:仅使用人工标注的数据集作为模型训练的语料,在体育、娱乐和科技新闻上分别验证各种主题词提取方法,各新闻语料的80%作为训练集,20%作为测试集,从训练语料中随机抽取10%作为验证集。在测试集上计算出P、R 和F1值,实验结果如表2 所示。每个评价指标中的最优值用粗体标出。
从表2 可以看出,在体育和科技新闻数据集上iBi-LSTM 的精确度明显高于其他对比方法,Att-iBi-LSTM 的召回率和F1值在所有方法中获得了最优值,在科技新闻数据集上Att-iBi-LSTM 的精确度、召回率和F1值都是最高的。
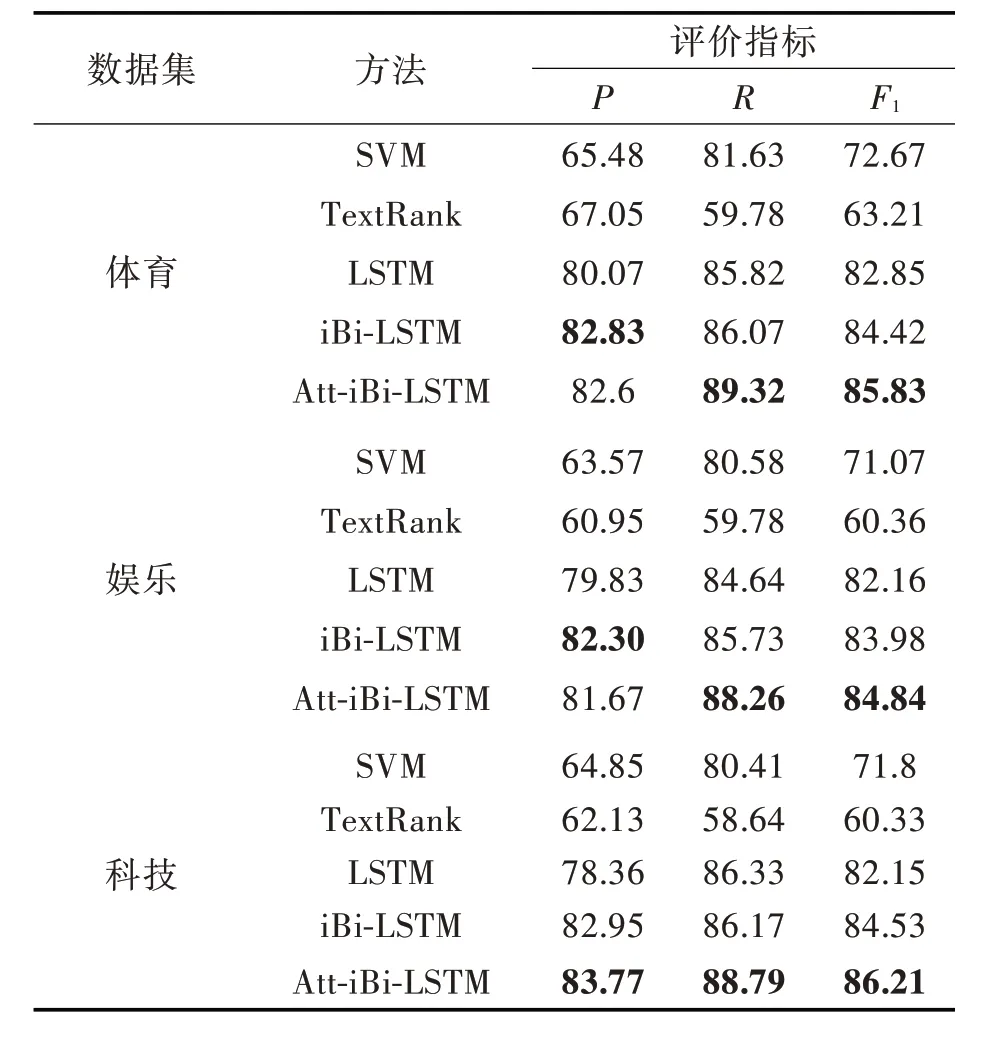
表2 主题词提取结果Tab.2 Results of topic words extraction %
各方法在3 个数据上的平均结果如表3 所示,每个评价指标中的最优值用粗体标出。
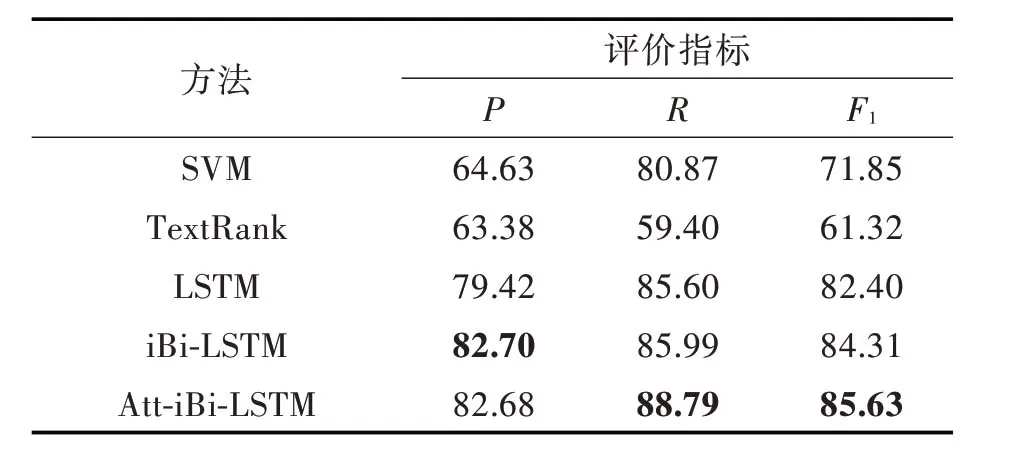
表3 各数据集上的平均实验结果Tab.3 Mean experimental results on datasets %
从表3 可以看出综合3 种新闻数据集的主题词提取结果,iBi-LSTM 模型的精确度值最高,Att-iBi-LSTM 的召回率和F1值高于其他对比方法。iBi-LSTM 模型与SVM 模型相比P、R 和F1值分别提高了17.77%、5.12%和12.46%,与TextRank 相比P、R 和F1值 分 别 提 高 了19.32%、26.59%和22.99%,与LSTM 模型相比P、R 和F1值分别提高了3.28%、0.39%和1.91%。引入Attention 机制的双向LSTM 模型与iBi-LSTM 模型相比主题词提取的召回率和F1值分别提高了2.80%和1.32%,与SVM、TextRank 和LSTM 相比F1值分别提高了13.78%、24.31%和3.32%。虽然在主题词提取任务中,Att-iBi-LSTM 模型比iBi-LSTM 模型相比P 值没有提升,但是F1值作为P 和R 的调和平均数更能说明分类效果,因此Attention 机制的引入对模型进行该任务是有效的。
实验2:先使用自动标注的数据进行模型的预训练,然后使用人工标注数据集作为模型第二阶段训练的语料,训练集、测试集和验证集的比例与实验1 相同,在所有新闻数据集上的总体实验结果如表4 所示,iBi-LSTM(2)和Att-iBi-LSTM(2)中的(2)表示模型使用两阶段训练方法。

表4 两阶段训练方法对主题词提取的影响Tab.4 Influence of two-stage training methods on topic words extraction %
从表4 中可以看出,使用两阶段训练方法的iBi-LSTM(2)与iBi-LSTM 相比主题词提取的P、R和F1值分别提高了3.31%、0.86%和2.12%,使用两阶段训练方法的Att-iBi-LSTM(2)与Att-iBi-LSTM相比P、R 和F1值分别提高了2.48%、0.53%和1.56%。表4 中的实验结果证明了两阶段训练方法对模型进行主题词提取的有效性。
4 结 论
本文采用双向LSTM 引入Attention 的方法实现了新闻主题词的提取,并且在不同领域新闻主题词提取任务中均得到了较好的提取效果,说明了该方法的泛化性。本方法构建了一个双向的LSTM 深度神经网络模型,对中心词所在的句子建模,从两个方向提取这个词的上文和下文的信息,并在该网络模型中引入注意力机制,与单独的LSTM 模型相比可以获取更多的文本信息。因此,该方法有利于文本分类、文本聚类等其他自然语言处理工作的进行。此外,文中还提出了一种利用自动标注的粗数据集的两阶段模型训练方法,从实验结果可以发现这种模型训练方法对主题词提取的任务有效,所以在其他类似的工作中也可以利用这种方法。Att-iBi-LSTM 结合了LSTM 模型和Attention 机制的优点,从而获得了更好的主题词提取效果,但是这种混合模型的网络结构与单一模型相比更复杂、计算量更大,所以模型训练的时间更长。因此,需要在以后的工作中对模型进行优化以缩短模型的训练时间。
