基于深度学习的溶剂定量构效关系建模研究进展
2020-10-27田璐瑶王梓豪粟杨文华强申威峰
田璐瑶,王梓豪,粟杨,文华强,申威峰
(重庆大学化学化工学院,化工过程强化与反应国家地方联合工程实验室,重庆401331)
引 言
准确可靠的定量构效关系模型是计算机辅助溶剂分子设计的重要基础,被广泛应用于溶剂筛选、性质预测、过程模拟、风险评估等化工产品与过程开发及设计工作中,降低了实验所需的人力和物力,加速了新型绿色溶剂设计的开发进程[1−2]。经典的定量构效关系建模主要包含两部分工作:分子结构的定量描述和目标性质的数学关联。但是,设计一种精巧的分子结构描述模型需要由具有丰富知识与经验的专业人员完成;同时,性质与分子结构数值化特征的数学关联需由人工的统计学分析完成[3]。近几十年来,随着化合物种类的指数型增长,发现将新的候选化合物作为潜在的绿色溶剂具有重要的研究价值[4]。但是,经典的定量构效关系模型难以满足溶剂分子大范围评估与筛选的需求。因此,实现自动化的定量构效关系建模,并开发智能化且描述能力更强的构效关系建模方法具有重要意义[5]。
随着计算科学与人工智能技术的快速发展,借助高性能计算平台和深度学习技术可以实现多维度的大数据分析和关键特征的自动提取,这使得深度学习技术在计算机视觉和自然语言处理领域得到了广泛应用。受此启发,化学研究者们近期提出了基于深度学习技术描述分子结构的图像、拓扑和文本的方法,并成功应用于化合物的基础物性、环境、健康和安全等重要性质的预测[6−8]。相对于经典的性质预测模型而言,基于深度学习技术的定量构效关系模型可实现分子结构特征的自动提取以及分子描述符和性质的关联,并且具备了更强的非线性关联能力。因此,深度学习模型可以描述更加广阔的化学空间和更复杂的函数关系,使得采用计算机在较大的潜在化学空间中自动化地筛选候选溶剂成为了可能,从而实现智能化的溶剂设计[9−11]。并且,该模型可以为复杂体系特殊精馏过程涉及的功能性溶剂(如萃取剂、共沸剂等)提供高效便捷的智能化设计工具,降低特殊精馏过程的潜在环境、健康与安全风险[12−13]。
1 定量构效关系建模基本原理
定量构效关系模型的构建基于化合物性质与分子结构间存在的强相关性。其建模策略是将分子结构特征数值化并与目标性质进行数学关联,实现定量构效关系的建模[14],解决化合物性质值缺失或实验测量难以实现等难题,实现化合物性质的较高精度预测并加速新型化学品的开发进程[15−17]。
1.1 分子结构识别与特征提取
在构效关系建模过程中,首先需选取分子结构特征的描述及编码模型,将分子结构信息(如元素类型、原子空间位置、电荷分布、官能团等)具象化为定量的数值型描述符[18]。经典的定量构效关系建模常用的分子结构特征描述及编码方法有基团贡献法、拓扑指数法、签名描述符等[10]。
1.1.1 基团贡献法 在基团贡献法中,基团是由原子与化学键构成的子结构片段,且分子结构被视为基团的组合,如图1 所示。该方法假设每种基团对目标性质具有确定的贡献值,分子的性质值则可以通过各基团的贡献值与其出现频次乘积的加和得到[19],其函数表达如式(1)所示。

图1 基团贡献法表示的乙醇分子Fig.1 Ethanol molecule represented using the group contribution method

式中,P 是目标性质值;cg是基团g 的贡献值;ng是基团g 在分子中出现的频次;f 函数为(非)线性转换。
基团贡献法因具有模型简单、计算快速等优点得到了广泛的应用。例如,Gmehling 等[20]提出的UNIFAC 基团贡献法可以用于各种有机物体系的相平衡计算;Joback 等[21]提出的基团贡献法用于预测有机物临界性质,并被广泛应用于过程设计;Frutiger 等[22]提出了一种新的基团贡献法用于预测有机物的燃烧热,呈现较高的预测精度与应用便捷性。并且,基团贡献法可构建用于分子设计的线性规划模型[23−24]。尽管基团贡献法是应用较为广泛的分子结构表达方法,但其未考虑各基团的排列顺序和连接方式,因此在识别与区分异构体时存在一定的局限性[23]。值得注意的是,Gani 等[25]提出的多层次基团贡献法具备一定的异构体分辨能力,扩展了基团贡献法的应用范围。
1.1.2 拓扑指数法 分子图是分子结构的拓扑表达,其顶点和边分别对应分子结构中的原子和化学键[26]。基于图论的理论,通过计算分子拓扑指数可以描述原子的顶点度、连通性、原子类型等分子图属性[27]。例如,Wiener 指数[28]作为最经典且研究最早的拓扑指数之一,描述了图中所有原子之间的总距离。Randic[29]提出分子连通性指数用于量化烷烃分子结构的分支程度,并基于此构建了烷烃类化合物的熔化焓和蒸气压预测模型。此外,Gani 等[25]使用连通性指数预测新基团的贡献值,改善了基团贡献法的适用范围。
该方法计算较为简便,对分子骨架有较强的描述能力。但是,拓扑指数所描述的分子图属性是基于二维空间的分子结构的近似表达,顶点之间的距离并非三维空间中原子之间的真实距离,且拓扑指数未考虑图中的化学信息,因此,拓扑指数在区分类似的分子结构时存在一定的局限性[30−31]。
1.1.3 签名描述符法 签名描述符既可以表示为类似基团贡献法的子结构形式,也可以转换为描述整个分子结构的拓扑指数形式[32]。从指定的某原子出发,遍历一定高度内的所有原子产生有向非环图得到原子签名[3]。因此,一个分子的性质P,可以由某一固定高度下基于每个原子得到的原子签名进行关联,如式(2)所示。

式中,d 是当前原子签名描述符集合的起点原子;Di是高度为i的签名描述符集合;cd为回归系数;iαG(d)表示原子描述符d出现的次数[26]。
Weis 等[33]将签名描述符成功应用于溶剂筛选,并从环境、健康与安全角度进行溶剂分子的设计。Chen 等[34]使用签名描述符实现药物分子的高通量筛选,并应用于新型药物的研发。签名描述符不仅可以记录各原子的化学信息,而且可以捕获分子中各原子间连接信息的全貌,因此具有良好的异构体鉴别能力。
1.2 分子结构与目标性质的关联
在分子结构信息得到量化之后,需要运用建模方法将其与目标性质进行关联,从而实现性质预测模型的构建[10]。用于性质关联的数学工具主要有多元(非)线性回归、人工神经网络、支持向量机等。其中,人工神经网络和支持向量机是较为流行的机器学习算法,在处理高维分子特征与复杂非线性关系时更为有效[18]。本节将介绍这几种最常见的经典定量构效关系建模方法。
1.2.1 多元线性回归 多元线性回归基于多个独立变量拟合目标值并建立线性回归模型[35],具有结构简单和计算快速等优点。多元线性回归方程的广义数学表达如式(3)所示。

式中,Y 是因变量,即构效关系模型的目标性质值的期望值;X1,X2,…,Xn是自变量,即构效关系模型中使用的分子描述符;a1,a2,…,an是各自变量的回归系数;a0是常数项。该模型可以通过核函数,转换为非线性模型。
该模型常应用于基于基团贡献法的定量构效关系建模。Pan 等[36]采用结合遗传算法的多元线性回归构建模型预测有机化合物的燃烧极限,结果表明所得多元线性模型足以对大多数有机化合物快速地做出较为准确的预测。通过多元线性回归所建立的模型,在分析多因素的影响时表现更便捷且更具可解释性[24,37−38],也便于进行模型的不确定性分析。然而,在实际应用中,此方法的性能对于分子描述符的选择较为敏感,并且由于模型结构的限制难以拟合复杂的非线性关系,在大规模的数据集上无法取得很好的精度[39]。
1.2.2 人工神经网络 人工神经网络是一种模拟人类大脑及神经系统工作的机器学习方法。在由神经元组成的多层计算网络中,变量由输入层传入,再通过隐藏层的转换后,最终在输出层得到计算结果。在神经网络的训练过程中,常利用反向传播算法对人工神经网络模型中神经元的权值和偏差进行更新,以建立一个能够更好地描述输入变量与目标值之间关系的模型[40−42]。为使模型具备更强的拟合能力,通过在人工神经网络的隐藏层之间引入激活函数以提高模型的复杂性。与多元线性回归不同的是,人工神经网络可以用于处理复杂任务中的非线性数学建模,以针对分子结构和相关的理化性质建立数学模型。图2展示了基于人工神经网络预测化合物性质值的实现途径。
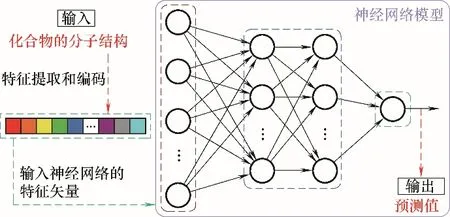
图2 基于人工神经网络的化合物性质预测Fig.2 Property prediction of compounds using the artificial neural network
人工神经网络具有较强的学习和自适应能力,在捕获数据过程中处理非线性关系时也是非常有效的[43−44],因此人工神经网络可以实现分子结构和相关的性质之间复杂的非线性建模。例如,Eslamimanesh 等[45−46]使用人工神经网络估算了常见的24 种离子液体和21 种常用固态化合物在超临界二氧化碳中的溶解度,预测值与实验值的平均绝对偏差表明该模型具有良好的预测效果。
1.2.3 支持向量机 支持向量机是一种可以用于实现分类、回归与离群值检测的机器学习方法。对于性质预测常涉及的回归问题,支持向量机基于样本的特征空间构造超平面,使数据点尽可能接近超平面,以获取预测性能更好的模型[47]。同时,核函数的引入使得支持向量机算法可以执行更为复杂的非线性任务,通过对比不同核函数在特定任务下表现的性能,从中选择合适的核函数可以有效地提高模型的预测性能。
支持向量机的建模过程可以视为凸优化问题,借助优化算法可得到目标函数的全局最优解,以此获取全局最优模型。在大多数情况下,基于支持向量机算法的预测模型通常会优于基于人工神经网络的预测模型,被应用于理化性质预测建模的构建[47]。例如,Pan 等[48]基于支持向量机拟合了官能团与闪点之间可能存在的定量关系,对数据集采用交叉验证的方法得到支持向量机的最优参数。使用最终优化得到的支持向量机模型进行模拟,结果表明,预测的闪点值与实验数据吻合较好。He 等[49]提出了基于支持向量机的有机过氧化物自加速分解温度预测模型,通过对比多元线性回归和支持向量机预测模型对训练集和测试集的平均绝对误差,验证得到后者的预测性能明显优于前者。
2 基于深度学习的定量构效关系模型概述
随着人工智能技术和计算机运算能力的迅速发展,深度学习技术在计算机视觉和自然语言处理等领域取得突破性进展与成功应用,成为了当下的研究热点[50]。深度学习隶属于机器学习领域,但深度学习区别于经典机器学习的最明显特征是深度学习不包含显式的特征工程。图3展示了经典的机器学习技术与深度学习技术在化合物性质预测建模中的区别。

图3 经典机器学习与深度学习在预测建模中的区别Fig.3 Difference between classic machine learning methods and deep learning techniques in predictive modeling
在已有的深度学习定量构效关系建模研究中,其中一类研究是使用深度学习替代人工的统计学分析以提高计算效率,采用大量的分子描述符(数千种或数万种描述符)表征分子结构信息,并基于深度学习来关联目标性质或对化合物进行分类[51−52]。另一类研究使用深度学习直接对以图或文字形式表示的分子结构进行学习,并基于矢量化的分子信息关联目标性质。研究者基于不同的深度学习方法构建了多种构效关系模型,如表1所示。

表1 基于深度学习的定量构效关系研究Table 1 Studies of deep learning based quantitative structure-property relationship
深度信念网络中的受限玻尔兹曼机可基于输入矢量以无监督学习的方式生成特征向量,并在监督学习下实现目标特性的关联。递归神经网络则是通过遍历分子结构的无向图,自动提取用于表征分子结构的特征实现目标特性的关联,可以避免依赖于化学知识的人工特征提取过程。卷积神经网络可直接处理二维的分子结构图片并提取特征,与基于分子图的递归神经网络类似,两者均不依赖于数值化的分子描述符或分子指纹。上述的深度学习方法均要依赖于大量的样本数据减轻模型训练的过拟合问题以提高模型泛化能力。相较于此,长短期记忆−卷积神经网络可在有限的数据上呈现较强的模型泛化能力,同样地,该神经网络框架也是通过对二维的分子结构图片进行处理并提取特征,实现目标特性的关联。
尽管深度学习技术在分子结构的精准识别上呈现了较大的潜力,但是由于深度神经网络结构复杂,预测模型的构建及应用过程中均会消耗大量的计算资源,因此基于深度学习的预测模型构建对计算机硬件性能和运算加速平台均有较高的要求。
3 基于深度学习的溶剂定量构效关系建模相关应用
3.1 应用于热力学性质
在溶剂设计中评估候选化合物的溶解能力、循环利用价值,需要溶剂的热力学性质,涉及临界性质、熔沸点及相平衡计算等。在以往的构效关系研究中,这类性质通常由基团贡献法预测,但是,基团贡献法具有忽略基团间连接方式、异构体识别能力有限等局限性[57−59]。Su 等[6]开发了一种基于非环有向图的分子结构编码算法,通过嵌入算法和树形长短期记忆网络对分子结构进行矢量化,并基于此提出了用于构建基础物性预测模型的新型深度学习框架,如图4 所示。此深度学习框架耦合了用于映射分子树形结构和输出特征向量的树形神经网络,以及实现化合物结构与性质关联的前馈神经网络。
Lim 等[60]提出了一种新颖的计算有机溶剂中溶剂化自由能的深度学习模型Delfos,可预测各种有机溶质和溶剂系统的溶剂化自由能。该模型的特别之处在于运用两个单独的溶剂和溶质编码器网络,使用词嵌入和递归层来量化给定化合物的结构特征,并增加了从递归神经网络输出中提取重要子结构的注意力机制。研究者对2495个溶质−溶剂组合进行大量计算,同时也分析了各种分子子结构对溶剂化过程的影响,结果表明Delfos 模型拥有与最先进的计算化学方法相媲美的潜力。
这些研究表明了分子识别描述符与神经网络的耦合作用在表征分子拓扑结构和捕获分子结构特征的优越性,进一步验证了基于深度学习和数据驱动建模的优势,并为符合特定使用场景的可持续过程设计及产品开发提供基础数据及重要的理论支撑[61−63]。
3.2 应用于环境性质

图4 基于深度学习的构效关系预测模型开发Fig.4 Development of predictive models for structure−property relationships based on the deep learning
由于环境影响在分子设计、化学合成与产品开发等领域中是必须考虑的因素[64−65]。其中,化学需氧量(COD)作为评价环境中水体污染物相对含量的重要指标,能较快测定有机物在工业废水中的污染程度。但是,污水流量常处于不稳定状态,这使得污水的COD 难以准确预测。因此,如何建立高精度的COD 预测模型是解决城市污水处理厂高能耗问题的关键。传统的模型开发过程中分子特征选择存在人为干预、拓扑特征或分子描述符过多等问题,限制了预测模型的广泛应用。Wang 等[66]基于长短期记忆−卷积神经网络(LSTM−CNN)深度学习算法,提出了一种城市污水COD 动态预测模型,收集城市污水处理厂的实时数据并进行训练。预测结果表明,与单独的CNN 或LSTM 模型相比,LSTM−CNN 模型具有更高的预测精度和更好的预测性能。高精度的COD 含量预测模型为制定污水处理厂曝气系统的先进控制策略提供了依据。
此外,环境性质如辛醇水分配系数,衡量了化学物质在脂质和水相之间的平衡与分布,可作为溶剂选择的物化标准。Wang 等[67]运用Tree−LSTM(树形长短期记忆)网络捕获分子中原子的连接性,并耦合签名描述符实现分子特征的自动提取,进一步结合前馈神经网络用于构建化合物环境性质的预测模型。研究者基于上万种化合物的结构与辛醇水分配系数,验证所提出的深度学习方法在关联大规模数据上的潜力,并实现了在无人为干预条件下分子特征的提取和构效关系的智能化建模。如图5所示,所构建的预测模型呈现了较好的预测性能和外推能力,以及良好的模型应用域。尽管这一研究专注于预测辛醇水分配系数以度量有机化合物的亲脂性,但所提出的深度学习方法可以进一步推广到其他重要环境性质如水溶性和生物富集因子的预测模型构建,并作为一种智能化的工具指导绿色溶剂的筛选与开发以及计算机辅助分子与过程设计[68]。
3.3 应用于安全性质
许多化学品的安全性质是有机物在工业过程危险评估中必须考虑的因素。因此,通过构建模型来预测化学品安全性质也是十分必要的[69−71]。例如,Mayr 等[72]构建了基于卷积神经网络的深度学习模型,通过处理和学习高信息量的化学特征,提高了对化学品毒性的预测能力,并进一步分析了各层神经元与毒理基团在性质预测时发挥的作用与联系;Xu 等[73]开发了一种改进的分子图编码卷积神经网络架构,利用深度学习的特征自动学习能力,不仅实现了急性口服毒性(AOT)的高效预测,还反向挖掘出致使化学品具有高AOT 的相关分子子结构;Fernandez 等[74]使用二维卷积神经网络,直接从二维分子图信息提取抽象的结构特征,验证了深度学习技术在毒性预测中的高精确度。
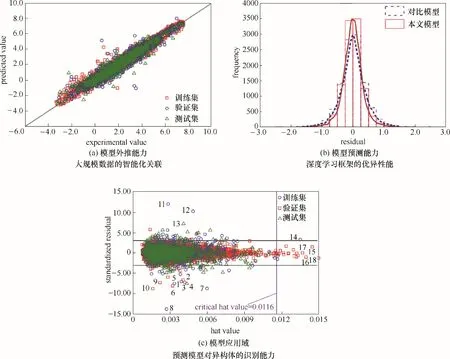
图5 基于深度学习的构效关系模型分析Fig.5 Analyses of the deep learning based predictive model of the structure−property relationship
此外,在化工产品开发及分离过程设计中,可燃性作为极为重要的安全性质之一,主要涉及自燃温度、闪点和易燃极限[42,48,75]。一些研究人员通过构效关系的关联实现了可燃性的预测,但是此类模型都是基于人工筛选的分子特征描述符建立的,未能实现分子特征的自动提取与模型的智能化构建。并且,可燃性研究中单个模型通常仅适用于单个性质,无法同时为多种相关性质展开预测。Wenzel等[8]基于深度学习技术构建了多任务学习神经网络,实现单个模型对多种可燃性质的智能化预测,其工作原理如图6所示。这一思路可以借助联合训练与交替训练提取多种相关性质之间的异同,并实现损失函数的快速收敛,构建的预测模型可以进行多种可燃性质的同步预测,有效提高多任务学习的效率。
3.4 应用于溶剂分子
在萃取精馏工艺设计与开发过程中,在有限的设计空间内首先选择的是工艺中所需萃取溶剂分子[76]。最经典的研究是从分子层面探究形成共沸的机理,研究者们应用热力学理论初步筛选出候选萃取溶剂,并进一步采用相对挥发度、溶剂选择性、无限稀释活度系数、模糊决策等理论知识作为辅助手段来选择最佳的萃取溶剂[12−13],通过减少萃取剂用量以期实现清洁生产与节能减排的目标。例如,Austin 等[77]使 用COSMO(conduct−like screening model)模型开展计算机辅助混合物的设计,该方法无须二元交互参数,只依赖于分子体积和电荷密度分布来估计溶液性质,这使得基于量化计算的高精度分子信息可以耦合至混合物设计研究中。在确定工艺中所需溶剂后,可以进一步优化工艺流程和操作条件。然而,这种连续的决策过程会限制分子设计空间,并忽视分子与工艺过程之间的内在联系,从而导致预测性能不佳。因此,在解决此类设计问题时无论是基于技术经济问题还是基于环境健康指标,分子设计中的性质预测建模都需要考虑多项指标[5]。针对计算机辅助分子和过程设计研究所涉及的多目标优化问题,Lee等[78]系统地比较了五种混合整数非线性规划的多目标优化算法,以评估它们在分子设计与分子及过程设计中的性能,此类研究为多目标分子设计问题提供了理论基础,可有效提高计算机辅助分子和过程设计问题在多目标优化中获取帕累托前沿的效率。

图6 多任务深度学习神经网络框架Fig.6 Framework of the multitask deep learning neural network
鉴于近年来科学研究领域的快速发展,深度学习技术在溶剂分子的设计与开发应用上展现出了良好的前景。前文所述的深度学习定量构效关系模型不仅可用于溶剂的基础物性、环境性质、安全性质的预测,也可以为萃取精馏中溶剂分子的筛选与设计提供用于决策过程所需的相关性质数据。在萃取精馏或共沸精馏过程中,无法完全避免使用在安全、健康和环境(SH&E)方面存在较高风险的溶剂[79]。因此,在溶剂分子设计的初始阶段,通过开发基于深度学习的智能化的溶剂潜在SH&E风险评估模型,可以高效地获取溶剂的风险评估结果,减少对实验性质数据的依赖,加速溶剂的筛选与开发进程[80−81]。例如由欧盟制定的CHEM21 溶剂筛选规则[82],根据溶剂的沸点、闪点及危害标签对其潜在SH&E 风险进行评估,可为绿色溶剂筛选提供有价值且重要的依据。另外,基于深度学习的溶剂定量构效关系模型无法由准确的数学公式表达,故难以作为目标函数在常规的混合整数(非)线性规划问题求解器中用确定性算法快速求解,但可以作为性质约束的计算模型参与到常规分子设计模型的运算中[83]。进化算法随机地产生分子结构,并通过类似自然界生物进化优选的方式,实现目标函数的优化,其不需要计算目标函数的梯度信息,且该算法具有全局优化能力。因此,当采用深度学习模型作为分子设计问题的目标函数计算模型时,优化算法适合选用进化算法[84]。此外,使用基于深度学习的构效关系模型作为约束条件,分子设计问题也可以使用确定性算法求解寻得全局最优解,而实现此过程的关键在于如何高度近似建立的深度模型,以及如何规划分子设计问题形成混合整数(非)线性规划模型。Winter 等[85]提出了应用自动编码器对分子结构进行独立编码,以统一的方式编码化学图结构,这样就可以对整个化学空间进行预测。Gómez−Bombarelli 等[86]采用变分编码器对分子结构实现了自动化编码,并尝试了其与遗传算法结构生成特定的目标分子。但是,对于特殊精馏的溶剂设计问题,基于深度学习的定量构效关系模型尚无法完成相平衡计算,仍需耦合UNIFAC 等经典模型进行分离性能的评价。此外,基于深度学习的分子结构的自动生成过程无法实现结构约束且生成的分子结构可能违反化学规律,需进一步引入额外的分子结构开展可行性验证。
4 结论与展望
综上所述,定量构效关系建模方法的研究不限于人工设计的分子结构描述方法和线性数学模型,已经延伸至更智能化的分子结构特征提取和非线性建模。基于深度学习技术,研究者们构建了溶剂分子基础物性、环境性质和安全性质的预测模型,可进一步探究在较大的化学空间内实现溶剂的虚拟高通量筛选,结合溶剂的功能特性和可持续性,并推动绿色溶剂开发与相关化工过程的设计。
目前,为了适应数据挖掘和智能化产品设计的需求,基于深度学习技术的建模过程仍存在亟需研究与探讨的科学和技术问题。例如,将表示分子结构的线性字符串直接作为自然语言处理,导致分子结构本身具有的化学意义会有所缺失;分子结构的二维图形或三维模型在深度学习框架中的旋转与变换处理;深度学习模型与经典模型在具体设计问题中的耦合等。因此,未来的研究将会集中于解决性质预测模型中分子结构的空间拓扑关系以及模型预测精度问题,并在模型的应用阶段应选取合适的优化算法和求解策略以获得多目标优化问题的全局最优解,以实现更可靠的分子设计。这些基于数据驱动的相关研究与应用将会有更广的应用前景,以深度学习为代表的计算机科学和化学、化工的学科交叉研究将推动着化学产品开发与化工过程设计的快速发展,进一步拓展溶剂设计研究所处的化学空间,提高溶剂设计的智能化程度。
