基于神经结构搜索的多种植物叶片病害识别
2020-10-21黄建平陈镜旭李克新李君禹
黄建平,陈镜旭,李克新,李君禹,刘 航
(东北林业大学机电工程学院,哈尔滨 150040)
0 引 言
目前全球粮食产量的增长速度远低于人口增长速度,粮食产量和安全对保障人民生活水平和国民经济发展具有重要的意义[1-2]。植物病虫害是影响农林业生产、生态安全和农林作物产量的生物灾害[3],及时准确掌握植物病虫害的类型、严重程度及病害发展状况,能够有效减少病害对农林业生产造成的经济损失,同时减少滥用农药造成的环境污染,为科学制定病害防治策略提供依据[4]。传统的植物病害监测方法主要依赖于专家通过可见特征来进行评估[5],这不仅需要专家具有丰富的经验,同时评估过程较为繁琐、耗时,具有一定的主观性[6],难以满足实际生产中大面积、快速病虫害监测的应用需求。早期基于计算机视觉识别植物病害的方法首先需要提取植物特定特征,再使用传统分类方法识别病害。然而提取特征的过程复杂,且特征提取器的选择及设计对病害的识别结果有较大的影响[7-9]。近年来,迅速发展的深度学习是机器学习的一个分支,被广泛应用于多个领域,如图像分类、目标检测、视觉跟踪等[10-11],并取得了很好的效果。基于深度学习的植物叶片病害图像分析方法具有精度高、速度快等优点,为植物病害准确快速检测提供了有效的技术手段。Srdjan 等[12]将深度卷积神经网络用于植物病害识别,该方法能够区分植物叶片与其周围环境,并能够区分健康叶片与13 种不同的植物病害,模型识别的平均准确率达 96.3%。Mohanty 等[3]使用GoogleNet 和 AlexNet 两种深度学习网络结构对PlantVillage 数据集进行了植物病害图像分类试验,结果表明采用迁移学习效果更好,GoogLeNet 的性能优于AlexNet。Alvaro 等[13]提出一种基于深度学习的番茄植株病虫害检测方法,采用Faster R-CNN 检测框架和VGG16特征提取网络,成功检测并识别9 种不同类别的病虫害。Wang 等[14]使用PlantVillage 中的苹果病害数据集进行试验,分析了VGG16、VGG19、 Inception-v3、和ResNet50共 4 种网络结构在全新学习和迁移学习下的分类性能。结果表明,对训练好的VGG16 经过迁移学习得到的模型识别效果最佳,其在测试集上的总体准确率为90.4%。孙俊等[15]对卷积神经网络模型 AlexNet 进行了改进,采用批归一化与全局池化相结合的卷积神经网络模型对多种植物叶片病害进行分类,改进后模型的平均准确率达99.56%,结果表明改进后的模型具有较高的识别准确率和较强的鲁棒性。Ferentinos 等[11]使用含 58 类植物病害的公开数据集对AlexNet、AlexNetOWTBn、GoogLeNet、Overfeat、VGG 共5 种不同的模型架构进行训练并测试模型识别准确率,结果表明采用VGG 架构训练的模型识别植物病害的准确率最高,达到99.53%。马浚诚等[16]构建了一个基于卷积神经网络的温室黄瓜病害识别系统,实现了对温室黄瓜病斑图像的准确分割及病害识别,分割准确率为 97.29%,识别准确率为 95.70%。Esgario 等[4]使用 AlexNet、GoogLeNet、VGG16、ResNet50 共 4 种不同的深度神经网络结构对咖啡病虫害进行分类及严重程度估计,结果表明训练后的ResNet50 对咖啡病虫害识别准确率最高,为 97.07%。Singh 等[17]提出一种能够识别芒果炭疽病的多层卷积神经网络结构,与现有的分类方法相比,该方法具有更高的分类精度,达到97.13%。采用深度卷积神经网络识别植物病害时,训练数据较少会导致模型性能下降。Barbedo 等[18]通过将每幅图像划分成小的图像块作为训练数据,一定程度上提高了病害分类的准确性。Nazki 等[19]提出一种生成对抗网络AR-GAN,并用AR-GAN 对9 种高度不平衡的番茄病害数据进行扩充,将深度卷积神经网络识别番茄病害的准确率由80.9%提高至 86.1%。郭小清等[20]根据番茄病害叶片图像的特点,对AlexNet 进行了去除局部归一化层、修改全连接层等改进设计,并开发了基于Android 平台的番茄叶部病害识别系统。该模型对番茄叶部病害及每种病害早中晚期的平均识别准确率达到 92.7%,基于此模型的 Andriod端识别系统在田间的识别率达到 89.2%。刘洋等[21]对MobileNet 和Inception-v3 两种轻量级卷积神经网络进行迁移学习,在 PlantVillage 数据集上平均识别率分别达到95.02%和95.62%,在自建葡萄病害叶片图像集上平均识别率分别为87.50%、88.06%。将得到的2 种较优分类模型移植到 Android 手机端进行对比,结果表明MobileNet 分类模型占用内存更小,运算时间更快,更适合用于手机端。
目前多数的网络结构都需要专家根据不同应用场景进行合理的设计,并且需要不断调整网络结构及参数以获得最优的识别模型,这个过程不仅耗时,同时需要具备专业的知识及经验[22]。Zoph 等[23]提出了神经结构搜索(Neural Architecture Search,NAS),无需人为手动设计网络结构。Zoph 等[24]证明了使用神经结构搜索得到的网络模型优于大多数人工设计的网络结构,并根据该神经结构搜索方法提出了NASNet。Adedoja 等[25]采用已经训练好的网络模型 NASNet,并在 Plantvillage 数据集上进行了迁移学习,测试的准确率为93.82%,该方法并未针对植物病害数据设计合适的网络结构。本文提出一种基于神经结构搜索的植物叶片病害识别方法,该方法能依据数据集学习合适的网络结构。采用PlantVillage 公共数据集进行神经结构搜索,对搜索到的最优网络模型进行测试和分析,以期能够实现植物叶片病害的准确识别,为科学制定病害防治策略提供有效的技术手段。
1 植物病害识别方法
1.1 神经结构搜索
随着深度学习的广泛应用,神经网络的结构变得越来越复杂,对于不同场景需要人工经过不断的试验来寻找合适的网络结构。神经结构搜索能够根据特定应用领域学习到最优的网络结构模型。神经结构搜索的主要过程如图 1 所示。首先预先定义一个搜索空间F,即定义通过NAS 算法可以搜索到的神经结构;然后利用搜索策略在搜索空间中搜索到一个合适的网络结构f,其中f∈F;使用性能评估的方法对该结构进行评估,将评估结果反馈给搜索策略从而对已搜索到的网络结构进行调整;循环该过程直到搜索到符合要求的最优网络结构[22]。
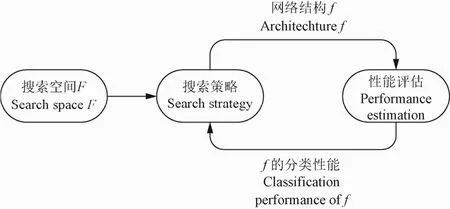
图1 神经结构搜索框图Fig 1 The block diagram of neural architecture search
1.2 病害识别方法
现有的许多神经结构搜索方法需要较高的计算成本才能有较好的效果,且搜索速度非常慢。针对该问题,Wei 等[26]提出了网络态射(Network Morphism)的方法,该方法能在保持神经网络功能不变的基础上将一个训练好的神经网络修改成一个新的神经网络。但基于网络态射的神经结构搜索[27-28]不够高效,Jin 等[29]提出一种使用贝叶斯优化指导网络态射的方法,实现了更高效的神经结构搜索。本文使用该方法自动搜索适合于植物叶片图像病害识别的神经网络结构,提出的植物病害识别方法如图2 所示,该方法分为以下4 个步骤:1)将数据集按照 4∶1 的比例随机划分为训练数据和测试数据;2)将训练数据作为神经结构搜索的输入,采用神经结构搜索方法获得最优的神经网络结构;3)将搜索到的最优网络结构在训练数据集下训练,得到病害分类模型;4)采用测试数据集评估网络模型的性能。

其中d表示两个神经网络间的编辑距离(Edit-distance),取值范围为(0, +∞),ρ是将距离从原始度量空间映射到相应新空间的映射函数。采用基于A*搜索和模拟退火的方法优化树形结构空间中的采集函数,选择Upper-confidence bound(UCB)作为采集函数,定义为



图2 基于神经结构搜索的植物叶片病害识别方法框图Fig 2 The block diagram of plant leaf disease recognition using neural architecture search
病害识别过程如下:定义一个层数为L的卷积神经网络作为神经结构搜索的初始架构,其中每一层是一个由ReLU 层、一个批量归一化层、卷积层和一个池化层构成的卷积块。在所有的卷积层之后,输出张量先经过一个全局平均池化层和一个Dropout 层,其中Dropout 的比率为rd,然后经过一个由nc个神经元组成的全连接层和一个ReLU 层,最后经过另一个全连接层和一个Softmax层。将训练数据作为神经结构搜索的输入,在搜索过程中将所有生成的网络结构、网络结构学习到的参数和模型损失值作为搜索历史H。通过优化采集函数算法生成下一个要观测的网络结构,该算法以模拟退火算法的最低温度Tmin、降温速率r和搜索历史H作为输入,输出新的网络结构和所需的网络态射操作,将现有的架构fi变形为一个新的架构fi+1(i表示搜索算法在执行过程中搜索到的第i个网络结构)。采用批量训练的方法将数据划分为多个批次,并通过随机梯度下降(Stochastic Gradient Descent,SGD)的模型优化方法对生成的架构fi+1进行初步的训练,采用交叉熵计算分类损失,训练过程中设置模型损失值在n1个 e poch 后不再下降时停止训练,通过评价度量函数对fi+1进行性能评估并获得其分类性能,根据所有搜索到的网络结构及它们的性能训练底层的高斯过程模型。在确定的搜索时间内不断重复上述过程,最终自动标示出搜索历史H中最优的网络结构f*(f*∈F)。采用相同的训练方法对该网络结构进行最终的训练,训练过程中设置模型损失值在n2个 e poch 后不再下降时停止训练,得到病害分类模型。将测试数据作为模型的输入,得到病害识别结果。
2 试验数据
2.1 数据描述
采用 PlantVillage 公开数据集[30]进行试验。该数据集有54 306 张植物叶片图像,包含14 种作物和26 种病害。通过植物病害专家现场鉴别,将该数据集按照疾病种类分为 38 个不同的类别,图 3 为数据集每一类病害图像示例。

图3 PlantVillage 数据集的叶片图像及病害示例[30]Fig 3 Leaf images and disease examples of PlantVillage data sets[30]
2.2 数据处理
PlantVillage 公开数据集中每一类所包含的图像数量各不相等,其数据分布如图 4 所示。为了分析数据平衡是否对神经结构搜索产生影响,将训练数据进行过采样与亚采样处理,使训练数据的每个类别数目在 1 500 左右,处理前后的训练数据数量统计如图 4 所示。同时,为研究神经结构搜索方法在训练数据缺乏颜色信息时搜索到的模型是否能学习到更高层次的病害特征,通过颜色空间转换的方法对数据进行灰度处理,示例如图 5 所示,使用灰度处理前和处理后的数据分别进行相同的试验。该研究使用PlantVillage 原始数据(54 306 张)、处理后达到平衡的数据(53 936 张)及进行灰度处理后的数据(54 306 张)分别进行试验,将训练集和测试集按照4∶1 的比例随机划分。

图4 原始训练数据与经过处理后达到平衡的训练数据对比Fig 4 Comparison between the original training data and the balanced training data after processing
3 结果与分析
3.1 试验参数设置
试验采用的软件环境为:Windows 64 位系统,开源Keras 框架[29],Python 编程语言(Python 3.6)。硬件环境:计算机内存 16 GB;处理器为 Intel(R) Core i7-9700k,3.60 GHz;GPU 为英伟达的 GeForce RTX 2080Ti,11 GB 显存。
试验中将一个层数为L的卷积神经网络作为神经结构搜索的初始架构,其中L为3。卷积层中卷积核大小都设置为3×3,数量为64,滑动步长为1,池化层大小设置为2×2,滑动步长为2。Dropout 的比率rd设置为0.25,nc为64。在贝叶斯优化算法中,采集函数中的平衡系数β设置为2.576,模拟退火算法的初始温度设置为1,降温速率r设置为0.9,最低温度Tmin设置为0.000 1。模型训练过程中学习率为 0.025,动量因子为 0 .9,权重衰减因子为0.000 3,最大迭代次数为200,每个批次训练128张图片,即train batch 设置为128。搜索过程中对每个搜索到的网络结构进行初步的训练,epoch 数量n1设置为5,在设置好的搜索时间内搜索一个最优网络结构。采用相同的设置对获得的最优神经结构网络进行最终的训练,epoch 数量n2设置为 30。
3.2 量化评价指标
准确率(accuracy,Acc,%),正确分类的样本数除以样本总数,计算方法如下

式中NTrue是预测正确的测试样本数,NSum是测试样本总数,模型对单个类别的识别准确率用Acci表示(i表示第i类病害)。
模型识别的平均准确率(average accuracy,AA,%)为测试所用的所有病害类型的准确率的平均值,计算方法如下
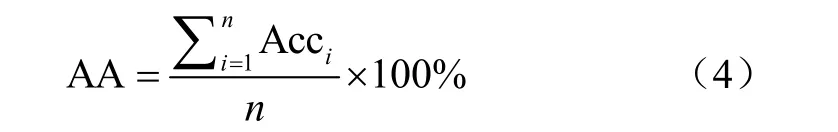
式中n为测试样本的总类别数。
3.3 试验结果
试验采用PlantVillage 原始数据,设置不同的神经结构搜索时间以研究搜索时间对搜索到网络结构的影响。将每组试验的搜索时间间隔设置为1 h,分别进行12 组试验。每组试验都是在设置好的搜索时间内不断搜索网络模型,试验设定当搜索到的网络模型损失值在5 个epoch 后不再下降时停止训练,对网络模型进行评估后继续搜索下一个网络模型,所以搜索时间越长,搜索到的模型数会越多。1 h~12 h 时段搜索到的模型数量分别为:2、4、6、8、11、12、14、16、18、19、21、25,该过程会自动存储并标示出搜索到的所有网络结构中损失值最低的模型,将其进行最终的训练并测试,每组试验搜索到的最优模型的测试结果如图6 所示。

图6 NAS 在不同搜索时间的模型测试结果Fig.6 Test results of models with different searching time for NAS
从图6 可以看出,本文的神经结构搜索方法在搜索不同时间时所得到的模型最终的识别准确率均达到了98%以上,说明该方法可以在较短时间内搜索到合适的网络结构,其中搜索时间为3 h 得到模型对于测试集的识别准确率较高。在神经结构搜索训练时间为3 h 的过程中共搜索到 6 个模型,各模型的评估值及损失值如表 1 所示。
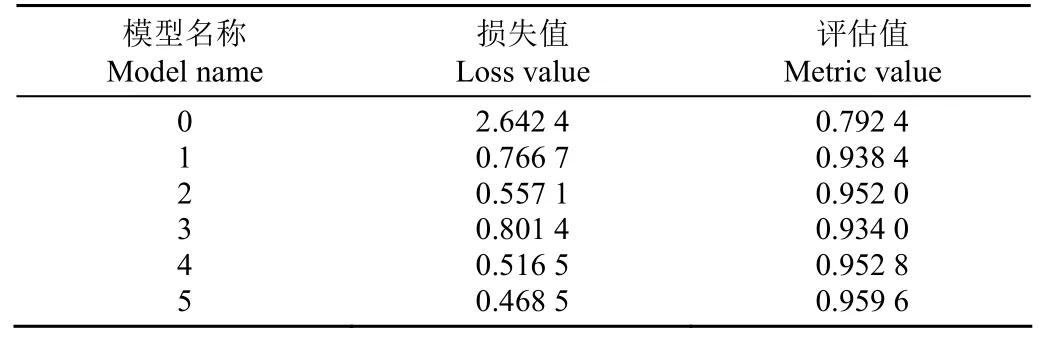
表1 使用NAS 搜索3 h 过程中对得到网络结构的评估Table 1 Evaluation of obtained network architecture during 3 h searching with NAS
从表1 可以看出,神经结构搜索对搜索到的网络结构进行了初步评估,其中最优模型为第6 个模型,对该模型的评估值为0.959 6,即模型的识别准确率为95.96%,损失值为0.468 5。将该模型作为植物叶片图像病害识别的最优网络结构并进行训练,使用测试集对训练后的模型进行测试。
使用基于神经结构搜索的方法对 PlantVillage 原始彩色数据、处理后达到平衡的数据及进行灰度处理后的数据共3 个数据集进行试验,并对相应的3 种不同的模型进行测试,研究神经结构搜索在不同情况下的有效性,以下分别称为试验一、试验二、试验三。模型对单个类别的识别准确率如表2 所示。一般来说,对于固定的神经网络结构,在训练数据不平衡时会使模型决策时对训练数据多的一类出现偏见,训练数据少的类别比训练数据多的类别更容易被错误分类[20]。从表2 可以看出,在训练数据平衡与不平衡两种状态下,试验一与试验二使用神经结构搜索得到的模型对单个类别识别准确率没有明显差异,且都达到了较好的识别结果,识别准确率分别为98.96%和99.01%。说明使用神经结构搜索的方法在训练数据平衡与不平衡时都能设计出合适的网络结构。从表2 可以看出,在试验三中模型对单个类别识别准确率有所下降,这主要是由于许多植物患病后叶片表面的颜色或出现的病斑颜色会发生变化,比如患二斑叶螨病的植物随着危害的加重,可使叶片变成灰白色至暗褐色,晚疫病在初期时病斑为墨绿色,后期变成褐色。同时,不同病害的病斑颜色也各不相同,比如土豆和番茄的早疫病病斑呈褐色或黑褐色,而苹果的疮痂病病斑呈蜡黄色。因此在训练数据缺乏颜色信息时模型更多是通过叶片的轮廓及纹理而做出识别决策。由于缺少颜色信息,训练出的模型对叶片颜色的细微变化不敏感,从而导致模型准确率稍微有所下降,最终模型的识别准确率为95.40%。由此可以看出,植物病害图像的颜色信息对于病害的识别具有积极的促进作用,同时即使在缺乏颜色信息时,本文提出的基于神经网络结构搜索的植物叶片图像病害识别算法依然可以获得较高的识别准确率。
为分析模型识别错误的原因,计算了试验一中模型对每种植物种类识别的平均准确率,其中玉米的平均准确率为 96.45%,在 14 种作物中最低,玉米病害的混淆矩阵如图 7 所示。在混淆矩阵中对角线单元格表示模型预测正确的测试样本个数,非对角单元格显示被模型预测错误的样本个数。玉米共有 4 种叶片类型,分别为玉米灰斑病、玉米锈病、玉米健康叶和玉米枯叶病。通过混淆矩阵可以发现,在 103 个玉米灰斑病测试样本中,有 1 个被错误识别为玉米健康叶,11 个被错误识别为玉米枯叶病;而在197 个玉米枯叶病测试样本中有 5 个被错误识别,都被识别为玉米灰斑病。从中可以看出,在对玉米病害进行识别时,玉米灰斑病与玉米枯叶病在识别过程中会发生混淆。图8为患灰斑病和患枯叶病的玉米病害图像,从图像中可以看出患灰斑病玉米的叶面上有长条形的浅褐色病斑,而在患枯叶病的玉米叶表面在病斑颜色、病斑形状及纹理上呈现出与患灰斑病玉米叶相似的特征,从而造成识别错误。后续研究一方面可考虑扩充训练样本的种类和数量,另一方面通过将细粒度网络与神经结构搜索相结合,提高模型的特征提取能力和分辨能力,从而提高模型的病害识别准确率。

表2 PlantVillage 测试集分类结果Table 2 Classification results for the testing dataset of PlantVillage

图7 玉米所包含4 种叶片状态的混淆矩阵Fig 7 Confusion matrix of four leaf states contained in maize

图8 两种易混淆的玉米病害叶部图像Fig.8 Leaf images of two confusable maize diseases
为研究本文方法在实际应用中的效果,使用一个为学术研究免费提供的植物病害症状图像数据库中的数据对模型进行测试,该数据集包含真实场景和固定背景下拍摄的玉米病害叶片[31]。由于固定背景下拍摄的图片不具有实际应用性,将固定背景下的玉米病害图像进行切割,只保留叶片部分作为测试数据,使用该数据集的 31张玉米灰斑病和 46 张玉米北方枯叶病图像用于模型测试,其中,模型正确识别了玉米的30 张灰斑病图像和37张北方枯叶病图像,识别准确率分别为96.77%和80.43%,说明该模型在实际应用中具有一定的适用性。后续研究将扩大训练数据规模或对已经训练好的模型进行迁移学习,提高模型的识别准确率。
4 结 论
该研究提出一种基于神经结构搜索的多种植物叶片病害识别方法,采用PlantVillage 植物叶片病害图像数据集进行试验。主要结论如下:
1)该神经结构搜索方法可以在较短时间内搜索到合适的网络结构,试验中设置搜索时间为1~12 h,在每个设置好的搜索时间内所得到的模型识别准确率均达到98%以上。模型对于不同种病害图像在病斑颜色、病斑形状及纹理上极为相似的情况,可能会产生识别错误。
2)神经结构搜索对训练数据类别间存在的数据量差异并不敏感,在训练数据不平衡和平衡时均可以搜索到合适的模型,并且模型对每类病害的识别准确率无明显差异,最终识别准确率分别达到98.96%和99.01%。
3)在训练数据仅含叶片的轮廓、纹理等特征但缺乏颜色特征时,该方法对一些患病后叶片表面颜色或病斑颜色会发生变化的病害的识别准确率有所降低,为95.40%。
该研究提出的方法能够根据数据集自动学习到合适的神经网络结构,简化植物病害识别网络模型设计的工作量,所得模型的病害识别准确率较高且具有一定的适用性,为实现植物病害自动准确识别提供一种技术手段。
