面向多用户移动边缘计算轻量任务卸载优化
2020-10-21张文献杜永文张希权
张文献,杜永文,张希权
(兰州交通大学 电子与信息工程学院,兰州 730070)
1 引 言
随着移动通信技术的不断发展,移动终端服务给人们的生活带来了极大的便利.同时,新的需求相继涌现,给移动计算技术带来了许多新的挑战.其中最显著就是计算需求和计算能力不匹配的问题.同时移动设备通常存在高能耗问题,这使得它无法支撑规模较大的计算任务.根据思科的报告表明(1)http://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/mobile-whitepaper-c11-520862.html.,移动数据流量将在未来5年增长7倍,到2021年将达到每月49艾字节,同时全球IoT设备数量将从目前的80亿增加到120亿.
由于数据流量的激增,终端已经无法承载这样大规模的计算需求.利用中央云技术处理大量数据,一时被认为是一个有效的解决方案.但是,云计算在解决终端计算需求的过程中存在一些劣势:延迟性高、能量消耗大以及网络带宽占用高等.为了提高移动应用的服务质量(QoS),移动边缘计算技术(MEC)作为一种新的解决方案应运而生,同时,移动边缘计算技术可以用来解决移动设备上不断增加的移动应用程序计算需求问题.
作为MEC的一项关键技术——任务卸载,它首先通过卸载决策去确定哪些计算需要在本地处理,哪些计算需要上传到边缘服务器去处理.最后通过计算资源分配来确定最后卸载的位置.任务卸载技术可以有效解决MEC框架在资源存储、计算性能以及能耗等方面存在的不足.这不仅减轻了核心网的压力,而且降低了因传输带来的时延.
此外,在无线衰落环境中,时变无线信道条件在很大程度上影响着无线MEC系统的最佳卸载决策[1].在多用户场景中,主要问题是个体计算模式的联合优化(即,卸载或者本地计算)和无线资源分配(例如,在进行卸载时该选择哪些基站).由于场景中存在二进制卸载变量,这些问题通常被表述为混合整数规划(MIP)问题.为了解决MIP问题,大多研究采用了分支定界算法[2]和动态规划[3],但它们的计算复杂度过高,不适合应用在大规模MEC网络.为了降低计算复杂度,一些新的研究提出了启发式局部搜索和凸松弛方法.然而,它们都需要大量的迭代才能达到局部最优值.因此,不适合在快速衰落信道中进行实时卸载决策,一旦信道衰落变化的速度变快,这些方法就需要重新解决优化问题.
随着智能体数量的增加,状态空间维度的爆炸将使传统的表格方法变得不可行[4],传统的强化学习(RL)算法将无法很好的解决维数问题.最近,深度强化学习(DRL)已经被证明可以通过利用深度神经网络(DNN)有效的逼近RL的Q值[5].深度强化学习与移动边缘计算结合可以使移动设备基于任务队列状态、能量最大化长期效用、队列状态以及信道质量学习到最优任务卸载决策和能量分配方案.
在本文中,考虑了如何更有效的判别计算任务是否需要卸载到边缘节点上.提出具有多用户的MEC网络,其中每个用户都遵循二进制卸载策略.本文的目标是根据时变无线信道共同优化用户任务卸载决策.为此我们提出了基于深度强化学习的计算卸载框架,以实现最低时延与能耗的卸载.与现有基于深度强化学习的算法相比,本文的工作如下:
1)在现有的基于离散动作空间做出决策的基础上,提出了一种基于候选网络的连续动作空间的算法,以获得更好的本地执行和任务卸载的功率控制.
2)基于多用户的MEC系统,针对每个具有任务随机到达和时变无线信道的移动用户独立地学习动态卸载策略.依此策略实现ECOO(Edge Computing Optimize Offloading)算法,实现功耗和计算成本降低,并减少时延.
3)通过实验仿真,说明通过ECOO与传统的DQN和DDPG算法的分散策略中学习的性能相比,在能耗与时延方面有更好的仿真结果,并分析了每个用户的功率延迟权衡.
2 相关工作
现有的大量工作研究了移动边缘计算的优化问题.一些工作为了降低时延与能耗,将卸载决策的问题建模成MIP问题,并考虑怎样应对随机任务到达和信道快速衰落.
卸载决策作为MIP问题,有许多相关的工作将MEC网络中的计算模式决策问题和资源分配问题联合建模.例如,文献[6]提出了一种坐标下降(CD)方法,它每次沿着一个变量维度搜索.文献[7]研究了一种类似于多服务器MEC网络的启发式搜索方法,它可以动态地调整二进制卸载决策.另一种广泛采用的启发式方法是凸松弛法,例如,通过将整数变量放宽到0到1之间的连续变化[8],或者通过用二次约束逼近优化[9].尽管如此,一方面,降低复杂性的启发式算法解决方案质量无法保证.另一方面,基于搜索和凸松弛方法都需要相当多的迭代才能达到令人满意的局部最优值,并且不适用于快速衰落信道.
为了应对随机任务到达和信道快速衰落,MEC系统中无线电和计算资源的动态联合控制策略变得更具挑战性[10-13].文献[10],作者考虑了多用户的部分计算卸载,并研究了基于时分多址和正交频分多址的资源分配,目的是最大限度地减少用户能耗的加权总和.在文献[11]中,作者设计了多输入多输出系统,通过形成的多输入多输出波束和计算资源分配的联合优化,解决任务卸载的能耗问题.文献[12]研究了用于能量获取的绿色MEC系统,其中利用延迟成本解决了执行延迟和任务失败的问题.对于多用户场景,作者主要讨论功率延迟权衡[13].
最近,许多工作在无线网络的资源管理研究上已经取得进展,在文献[14]中,作者提出了一种深度强化学习算法,用于研究在时变的实际无线环境中的最佳缓存和干扰抗性.在文献[15]中,Chen等人在具有多个基站的超密集切片无线接入网络中,为移动用户判断哪些MEC可用于任务卸载.作者提出了一种基于深度Q网络(DQN)的计算卸载算法策略,以获得最佳策略,进而最大化长期效用性能.在现有的工作中,只有基于集中式DRL算法来解决MEC系统中的最优计算卸载,而用于多用户MEC系统动态任务卸载控制的DRL算法设计研究数量仍然是欠缺的.
3 问题模型
如图1所示为一个多用户MEC系统,它由一个MEC服务器,一个基站(BS)和一组移动用户组成N={1,2,…,N}.其中每个用户都需要完成计算密集型任务.由于需要解决每个移动设备计算能力有限的问题,将MEC服务器部署在BS的附近,这样可以通过不同的用户需求来改善用户的QoS.此外,随着移动用户的增加,联合用户共同处理问题使每个用户的分散任务卸载问题解决起来更加便利,因为这可以减少用户与MEC服务器之间的系统开销,提高MEC系统的扩展性.在下文中将详细介绍建模过程.
3.1 网络模型
考虑到一个5G MBS或BS作为一个MEC系统,并通过采用线性检测算法来管理多个移动用户上行链路传输(ZF).对于每个时隙t∈T,BS的接收信号可以写为[16]:
(1)
其中p0,n(t)是用户n卸载任务数据位的传输功率,sm(t)是具有单位方差的复数数据符号,n(t)∈(0,σ2)是加性高斯(AWGN)的矢量,方差为σ2.为了表征每个移动用户时隙的相关性,本文采用以下的高斯马尔可夫块衰落自回归模型[17]:
(2)
其中ρm是时隙t和t-1之间的归一化信道相关系数,e(t)是误差矢量.
(3)
从公式(3)中可以验证每个用户的信噪比SINR随着用户数N的增加而变差,为了解决这一问题,需要为每个用户分配更多的卸载功率.
3.2 计算模型
在这一部分中,我们将讨论每个移动用户是如何利用本地执行或者计算卸载来满足其运行应用程序.假设所有的应用程序是细粒度的[18],d1,m(t)表示计算任务在本地移动设备上,d0,n(t)表示将计算任务卸载到边缘服务器上执行.在时隙t开始时,用户n的任务缓冲区的队列长度为:
Bn(t+1)=[Bn(t)-(d1,n(t)+d0,n(t))]++an(t),∀t∈T
(4)
其中an(t)表示时隙t期间任务到达的数量.
1)本地计算:p1,n(t)∈[0,p1,n]为本地执行分配功率.首先,假设用户n处理一个任务所需要的CPU周期数为Ln,周期数可以通过离线测量来估算[19].使用DVFS技术调整芯片电压[20],κ为在时隙t时写入有效开关电容的CPU频率.因此,在t时隙的本地处理可以通过以下方式导出:
(5)
(6)
2)边缘计算:为了利用边缘计算解决问题,MEC服务器通常配备有足够的计算资源,通过BS卸载到MEC服务器的所有任务都将被处理.因此,根据公式(3)可以得出用户n的卸载数据的比特量.
d0,n=τ0Wlog2(1+γn(t))
(7)
其中W是系统带宽.
3.3 能耗模型
智能手机,传感器和远程服务器在内的所有计算设备在一定执行时间内的总能耗主要由两部分组成:计算能耗Energycomp以及用于卸载的移动设备能耗Energyoff.首先,能耗模型i计算如下:
(8)
(9)
其中alltaski表示任务数为i的计算设备,Mj表示所需的CPU资源,DRi表示CPU总资源.
3.4 成本模型
移动用户需要为远程服务器提供的计算资源支付相应的费用.基于剩余资源量的动态价格模型.剩余资源量越少,资源价格越高.此时,用户更愿意选择单价较低的服务节点作为卸载目标,以降低用户成本,提高资源利用率.单位时间t中剩余资源量的动态价格模型[21]:
(10)
CC表示当前设备的成本,UT表示计算费用的间隔时间,RPM表示计算资源的单价,TM表示当前设备的总计算资源,LU(t)表示当前设备每单位时间使用的计算资源比率.同时,由于本地设备的计算资源属于用户自身,不需要计算成本,因此,远程设备的总成本:
(11)
4 基于DRL的动态计算卸载
强化学习可以通过特定场景中的自学能力来做出最佳决策,它通过将所有问题抽象为智能体与环境之间的交互过程来进行建模.在交互过程的每个时间步骤,智能体接收环境的状态并选择相应的响应动作.然后在下一个时间步骤中,智能体根据环境的反馈获得奖励值和新的状态.基于不断的学习,强化学习能够适应环境.虽然强化学习具有很多优势,但是它缺乏可扩展性,并且仅限于相当低的维度问题.为了解决强化学习中决策困难的问题,深度强化学习将深度学习的感知能力与强化学习的决策能力相结合.依靠强大的函数逼近和深度神经网络的表达学习特性来解决高维状态空间和动作空间的环境问题[22].
在本节中,采用改进的DDPG算法[23],在每个用户处能独立地学习分散的动态计算卸载策略,为本地执行和任务卸载分配功率.特别的,每个用户都没有MEC系统的先验知识,所以每个用户都不知道用户N的数量.下面引入分散动态计算卸载的DRL框架,定义状态空间,动作空间和奖励函数.最后介绍ECOO算法.
4.1 DRL框架
状态空间:为了全面研究MEC中子任务和服务器资源之间的关系,对系统的全面观察包括所有用户的信道向量和任务缓冲区的队列长度.但是,现实中在BS上收集这些信息后将它们分发给每个用户的系统开销是巨大的.为了减少开销并使MEC系统更具可扩展性,假设每个用户根据其独立的状态来选择动作.
在时隙t开始时,每个用户n的数据缓冲区Bn(t)的队列长度将根据式(4)更新.同时,其将接收一个来自BS的反馈,该反馈在BS处传给用户n最后接收到的SINR.此外,还可以通过信道互异性来估计用于即将到来的上行链路传输的信道矢量hn(t),定义的状态为:
Sn,t=[Bn(t),φn(t-1),hn(t)]
(12)
(13)
为了确保卸载决策能在本地移动设备或者远程服务器上执行子任务,子任务的卸载决策只需要考虑数量为N+M+1的计算设备,其中包括一个云数据中心,N个本地移动设备,M个边缘服务器.
动作空间:根据每个用户智能体观察到的系统的当前状态Sn,t,为每个时隙t选择本地执行或是任务卸载的分配功率动作an,t:
an,t=[P1,n(t),P0,n(t)]
(14)
不同于其他传统DRL算法,从若干预定义的离散功率电平中进行选择,本文通过应用改进的DDPG算法可以从连续动作空间中优化分配功率,并且显著减少离散动作空间的高维度缺陷.
奖励函数:每个智能体的行为都是通过奖励驱动的.为了学习能量感知动态计算卸载策略的MEC模型,研究在可接受的缓冲延迟内花费最少的能耗完成任务.根据Little定理[24],任务缓冲区的平均队列长度与缓冲延迟成比例.我们认为奖励值最低的值是最佳的,因此定义每个用户n在时隙t之后接收的奖励函数rn,t:
rn,t=-ωn,1P1,n(t)-ωn,2P0,n(t)-ωn,3Bn(t)
(15)
其中ωn,1,ωn,2和ωn,3都是非负加权因子,通过设置不同的值,可以动态权衡在任务卸载时的能量消耗和缓冲延迟.改进的DDPG在策略on下从初始状态开始最大化用户n的值函数:
(16)
当γ→1时,它可用于近似每个用户在无线范围内未损失奖励[25],平均计算成本为:

(17)
4.2 基于候选网络的优化
ECOO算法的伪代码描述如下:
输入:批次大小δ,当前神经网络MainNet,候选网络集Net
输出:训练完成的神经网络
1.随机选择大小为δ的数据样本miniBatch
2.初始化状态列表stateList和奖励列表rewardList
3.初始化数组NetTotalArray来存储的所有奖励值Net2,Net2∈Net
4.totalValue=0
5.N=Net的大小
6.for i=0, δ-1 do
7. targetValue=0
8. 根据miniBatch中的第i个样本获取当前状态St,动作at,奖励rt和下一个状态St+1
9. 根据状态St计算网络MainNet的奖励列表Q1
10. 根据状态St+1计算网络MainNet的奖励列表Q2
11. 在Q2中选择与最大奖励值相对应的动作at+1
12. 初始化奖励值列表NetValueList以存储候选人计算的奖励值
13. for j=0,N-1 do
14. 基于状态St+1和动作at+1计算第j个网络的奖励值Qj
15. NetValueList[j]=Qj
16. end for
17. targetValue=Max(NetValueList)
18.Q1[at]=targetValue
19. totalValue=totalValue+rt
20. stateList[i]=st
21. rewardList[i]=Qj
22. 通过主网络中的每步替换Net中最早的目标网络
23.end for
24.if totalValue>Min(NetTotalArray) do
25.用NetTotalArray中总奖励值最小的网络替换主网络,并将对应的总奖励值更新为totalValue
26.end if
27.根据stateList和rewardList训练主网络
28.Return MainNet
图2表示了基于DRL的移动边缘计算卸载的模型,其包括:高维状态空间表示、神经网络结构设计和长期奖励的最大化.如图2所示,智能体观察环境并获得原始服务信号,例如信噪比和无线信道信息.这些信号可以组合成高维状态输入,然后进入到深度神经网络中.需要特定结构的深度神经网络,例如卷积神经网络或递归神经网络,它们能够挖掘有用的信息并输出值函数或策略.根据输出,智能体可以选择出一个动作,该动作代表下一个卸载动作.然后观察所得的卸载性能,并将其作为奖励返回给控制器,来决定是否卸载.卸载智能体使用奖励来训练和改进深度神经网络模型,以最大化累积奖励.

图2 深度强化学习计算卸载过程Fig.2 Deep reinforcement learning computing offloading process
假设所有的计算任务具有等大的规模,并且假定边缘节点的计算能力足以进行任务的计算.目标是找到最佳的缓存策略,以最大程度地减少卸载时造成的时延和能耗.DQN算法通过延迟更新,以保证当前网络与目标网络之间的参数差异,从而提高训练过程的稳定性.但是当噪声或误差而过估训练过程的动作值时,在后面的参数更新过程中,相应动作的值也将不可避免地被高估.综合考虑多个候选网络的结果,将行动选择网络与行动价值网络分离,以确保最优学习策略[26].这些网络的详细功能如图3所示,具体将在下文介绍这些网络.
输入:每次请求T,智能体接收的状态输入到它的神经网络.仅从索引为0的当前请求任务到索引为1的请求任务中提取特征.实际上,除了此处所述的请求信息外,状态输入中还可以包含有关上下文和边缘网络的更多原始观察结果.
策略:收到状态后,智能体需要判断边缘节点是否有该任务的计算资源,如果有,则智能体将进行计算卸载动作.智能体根据策略选择操作,由评论者网络表示.应用每个动作后,移动边缘卸载环境为智能体返回了奖励,它定义了每个请求中的卸载流量.执行者网络参数的每次更新θ遵循策略梯度[27]:

(18)
评论者网络参数遵循时差法[28]:
θv←θv-α′∑tθ(rt+γV(∣st+1;θv)-V(st;θv))2
(19)
这里α和α′是学习率.为了权衡与环境之间的交互,将熵正则化(其定义为每个时间步长下策略的熵的加权梯度)添加到公式(18).训练过程可以离线或在线进行.通过脱机的方式,卸载策略是先验生成的(在训练阶段),然后在部署后保持不变.通过在线方式,缓存策略直接在边缘节点上进行训练,并在新数据到达时定期进行更新.

图3 神经网络架构Fig.3 Neural network architecture
鉴于MEC中资源随时间的逐渐变化以及LSTM网络长期状态的记忆能力,本文提出将LSTM与DDPG结合起来处理随时间变化的计算卸载问题.循环结构用于集成长期的历史数据,通过用LSTM层替换DDPG网络的最后一个完全连接层来更准确地估计当前状态.并且基于候选网络的优化来选择最优的学习策略.
如图4所示,假设候选网络集合Net=(net1,net2,…,neti,…,netn′)可以存储总数为n′的网络,有m′个网络集中的网络Net1,在满足固定迭代次数C后更新它们.网络设置Net2具有(n′-m′)个通过比较奖励值来选择进行更新的网络.当网络设置的数量Net2小于(n′-m′)时,每次迭代生成的当前网络都会被添加到Net2作为候选者网络.Net2等于(n′-m′),当前网络和Net2将训练当前选定的状态-动作对.如果大于,具有最小奖励值的候选网络被当前网络替换,否则继续训练.
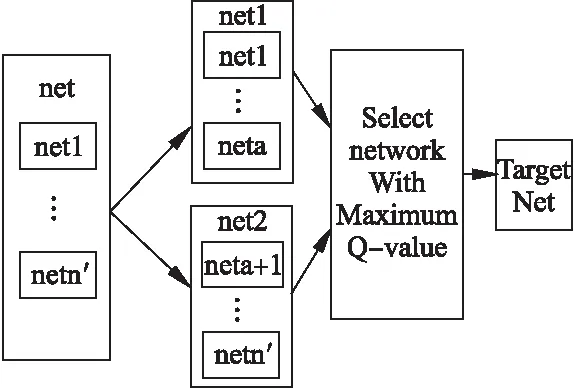
图4 候选网络更新流程图Fig.4 Candidate network update flow chart
5 实验仿真
为验证本文提出的ECOO算法在多用户移动边缘计算模型中的有效性,本文挑选出效果较好的几种算法与本文算法进行比较.实验环境在ubantu16.1,python3.6.8,tensorflow1.8下仿真.通过比较成本,能耗,服务延迟,反映出卸载决策的优缺点.在大规模异构集群中,实现的算法包括:贪婪本地执行优先(GD-Local),贪婪计算优先卸载(GF-Offload),基于DQN的动态卸载(DQN),基于DDPG的动态卸载(DDPG)以及ECOO.
5.1 模拟设置
在MEC系统中,时间间隔τ0=1ms.每一次迭代开始的时候,每个用户n的信道向量初始化为hn(0)~CN(0,h0(d0/dn)αIN),其中路径损耗常数d0=1m,路径损耗指数α=3,信道相关指数ρn=0.95,误差矢量e(t)~CN(0,h0(d0/d)αIN),fd,n=70Hz.将系统带宽设置为1MHz,最大传输功率P0,n=2W,噪声功率σ2=10-9W.对于本地执行,假设κ=10-27,每比特所需的CPU周期Ln=500,并且最大允许CPU周期频率Fm=1.26GHz.本地执行所需的最大功率P1,n=2W.
为了实现DDPG算法,对于每个用户,动作网络和评估网络都具有两个隐藏式的四层完全连接的神经网络.两个隐藏层的神经元数量分别为400和300.神经网络使用Relu激活函数.对于实现ECOO算法,在上文基础上设置了一个大小为10000的经验重播缓冲区,这样可以在查询时返回随机选择的小批量经验.将小批量设置为64,实现候选网络的优化.使用自适应矩估计(Adam)方法[29],学习率分别为0.0001和0.001.目标网络的软更新速率τ=0.001.为了初始化网络层权重,采用[23]实验中的设置.为了更好的找到更好的卸载决策,使用θ=0.15,σ=0.12的Ornstein-Uhlenbeck过程[30]来提供相关噪声.经验重放缓冲区大小|Bn|=2.5*105.
在训练阶段,对于1-5Mbps的不同任务到达率,将使用相同的网络架构.为了比较不同的策略性能,测试结果是100次训练结果的平均值.
如图5所示为用户动态计算卸载的训练过程.结果是从10次数值模拟中的得到的平均值,其中任务到达率设置为λ=3.0Mbps.可以观察到,对于DDPG和ECOO两个学习策略,迭代的平均奖励随着用户代理和MEC环境之间的交互的增加而增加,这表明ECOO算法可以在没有任何先验知识的情况下成功学习有效的计算策略.另外,从ECOO学到策略的性能总是优于不同场景的DDPG,这表明对于连续控制问题,基于ECOO的策略可以比基于DDPG的策略更有效地探索动作空间.
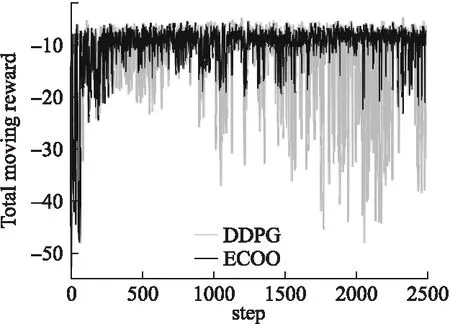
图5 训练图Fig.5 Training
5.2 多用户卸载仿真结果
在MEC系统中,有N=5个移动用户,每个移动用户随机位于距离BS的100m距离之内,任务到达率为λn=n*1.0Mbps,n∈{1,2,3,4,5}.
如图6所示,随着任务到达率的增加,平均奖励不断增加,这表明对于更大的计算需求,计算成本也会更高.基于全部在本地执行计算任务的卸载策略(GD-Local)可以在延迟上具有良好的效果,但是成本和能耗方面的性能一般.这主要是因为GD-Local算法更喜欢将子任务卸载到本地设备以供执行.当本地设备的资源不足时,子任务逐渐卸载到上层设备.由于某些子任务可以在本地执行而无需网络传输,因此该算法具有较低的网络延迟.此外,如图6所示,基于全部在边缘服务器执行计算任务的卸载策略(GD-offload)与GD-Local算法相仿,都花费了很大的能耗.主要原因是GD-offload算法倾向于将子任务卸载到边缘服务器集群,这使得在传输的过程中耗费了许多能量.同时,边缘服务器的性能可以满足更多子任务的处理需求,提高了整个集群的网络使用率.

图6 实验结果Fig.6 Experimental result
DQN算法,DDPG算法和ECOO算法都使用深度强化学习从值中不断迭代生成相应的卸载策略.从图6中结果可以看出,随着任务到达率的不断增加,ECOO算法无论在成本,能耗还是时延上都优于前面两者.这是因为ECOO算法全面考虑了目标网络的历史参数,并通过不断迭代实时的更新网络参数,用最小的奖励值替换网络,以此保持结果始终最佳,但在获得最低的能耗的同时,总会不断提高缓冲延迟.
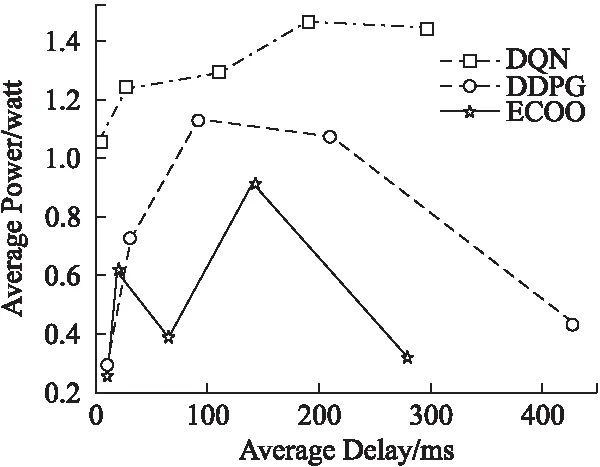
图7 平衡能耗与时延Fig.7 Power-delay tradeoff
通过设置图7中 在0.3-0.7的不同值来研究功耗延迟之间平衡的训练结果.从曲线可以推断出,平均功耗与平均缓冲延迟之间存在权衡.具体而言,随着w1的增大,功耗将通过牺牲延迟性能而降低,这表明实际上可以调整 为具有给定延迟约束的最小功耗.还值得注意的是,对于每个值,从ECOO学习的策略在功耗和缓冲延迟方面始终具有更好的性能,这证明了基于ECOO候选网络策略的优越性.
6 结 论
在本文中,针对一个多用户MEC系统,这其中设置了任务随机到达,无线信道在每个用户中随时间变化的条件.为了最小化功耗和缓冲延迟,本文设计了基于DRL的分散动态计算卸载算法.并且应用ECOO算法成功让每个移动用户学习卸载策略,该策略能够根据从MEC系统本地的观察得到的结果自适应地本地执行或任务卸载.通过模拟实验证明该策略优于传统的基于DQN的离散网络策略DDPG以及一些其他贪婪策略.在进一步工作中,我们希望基于慢衰落参数和信道统计信息来进行资源管理,以解决因无法跟踪快速变化的无线信道而带来的问题.
