一种基于用户兴趣概念格的推荐评分预测方法
2020-10-21朵琳,杨丙
朵 琳,杨 丙
(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 概 述
近年来,随着互联网和信息技术的飞速发展,推荐系统[1-3]被广泛应用于电子商务网站中.推荐系统支持消费者从过载的信息中选择所需的产品或服务.协同过滤(collaborative filtering,CF)[4]是最常用的推荐算法,被广泛应用于文学和工业领域,它利用用户的评分来构建用户-用户或项目-项目的相似度指标,并识别用户或项目的邻域来生成推荐.
然而,CF推荐算法存在这样的问题:当用户-项目评分矩阵非常稀疏,用户只对少数项目进行评分时,CF推荐算法的推荐质量极大地受到影响[5].Luo等人[6]提出将用户相似度分为局部用户相似度和全局用户相似度两部分来解决数据稀疏问题.此外,Patra等人[7]使用全局相似度和一个新的局部相似度来解决稀疏性的问题.他们使用Bhattacharya系数作为全局相似度的度量,利用数据库中所有可用的评分来计算用户-用户或项目-项目之间的相似度.张俊等人[8]根据兴趣向量来计算用户的兴趣相似性度,并引入专家信任度来进行评分预测填充,以此降低数据稀疏性.林建辉等人[9]针对传统的相似性度量只考虑用户对项目评分的问题,提出通过用户之间的相似性与信任关系来查找“最近邻”,有效地缓解了稀疏性问题.Guo等人[10]提出通过多类型辅助反馈信息来解决稀疏性问题.Xu等人[11]通过嵌入在用户评论中的形容词特征来解决数据稀疏性问题.
本文提出了一种基于用户兴趣概念格的推荐评分预测(Recommendation Rating Prediction Based on User Interest Concept Lattice,简称RRP-UICL)方法.该方法通过用户兴趣概念格将“最近邻”分为直接“最近邻”和间接“最近邻”两类.然后计算目标用户与直接“最近邻”和间接“最近邻”的相似度,最后,将计算所得的相似度值用于预测目标用户的不可见项目评分值,解决了传统CF推荐算法的稀疏性问题.
2 相关介绍
2.1 基于邻域的协同过滤
基于邻域的协同过滤推荐算法[12]的主要目标是基于目标用户的邻居用户向其推荐项目,根据计算相似度对象的不同而划分为基于用户和基于项目两类算法.本文的研究基础为基于用户的算法,主要包括查找“最近邻”和预测推荐两个步骤.
2.1.1 查找“最近邻”
相似度度量可以找到目标用户的“最近邻”用户,相似度度量考虑已评分项目的评分,来计算目标用户和其他用户之间的相似度.

1)修正的余弦相似性
修正的余弦相似性(Adjusted Cosine,ACos)采用式(1)计算用户u与用户v之间的相似度.
(1)
2) 皮尔逊相关
皮尔逊相关(Pearson Correlation,PC)采用式(2)计算用户u与用户v之间的相似度.
(2)
3) 受约束的皮尔逊相关
受约束的皮尔逊相关(Constrained PC,CPC)采用式(3)计算用户u与用户v之间的相似度.
(3)
式中,rmed为评分等级的中位数.
4) Jaccard
采用式(4)计算用户u与用户v之间的Jaccard相似度.
(4)
式中,|Iu∩Iv|为用户u和用户v共同评价过的项目个数.
2.1.2 预测推荐
向目标用户推荐项目,首先需要预测未评分项目的评分,然后推荐前N个高评分项目[13].使用式(5)预测目标用户u对项目i的评分.
(5)
式中,Sim(u,v)为用户u与用户v的相似度,Nu为用户u的“最近邻”集合.
2.2 概念格
形式概念分析(FCA,formal concept analysis)理论[14-16]是由R Wille提出的,它是一种数据分析和知识表示的方法.形式概念分析的两大基本内容是形式背景和形式概念,其基本的数据结构是概念格[17].
对于一个形式背景K=(G,M,I),其中,G是对象集合,M是属性集合,I是G和M之间的一个关系,I⊆G×M.在形式背景的对象集A⊆G和属性集B⊆M之间定义如下两个映射:
f(A)={b∈M|∀a∈A,aIb}
g(B)={a∈G|∀b∈B,aIb}
其中,f(A)是A中所有对象所共有的属性,g(B)是B中所有属性所共有的对象.
由形式背景K生成的概念格中的每个节点Z=(A,B)是一个二元组,满足:A⊆G,B⊆M,f(A)=B,g(B)=A,则二元组Z称为形式概念,其中,A是形式概念Z的外延,记作Ext(Z),B是它的内涵,记作Int(Z).
若Z1=(A1,B1)和Z2=(A2,B2)是概念格中两个形式概念,满足A1⊆A2(B1⊇B2),则称Z1为Z2的亚概念,Z2为Z1的超概念,记为Z1≤Z2,其中“≤”为一个偏序关系.
3 RRP-UICL方法
RRP-UICL方法的主要步骤如图1所示.从图1可以看出,RRP-UICL方法主要分为两个模块:一是“最近邻”模块,二是推荐模块.下面将介绍这两个模块的细节部分.

图1 RRP-UICL方法模型Fig.1 RRP-UICL method model
3.1 “最近邻”模块
3.1.1 构造用户兴趣概念格
在这一阶段,首先将用户对系统中已有项目的所有评分组成的评分矩阵R转化为二进制矩阵.在二进制矩阵中,评分较高的项目被认为是用户感兴趣的项目.本研究是在1~5的评分等级上面进行的,则将评分4和5视为最高评分,其值在二进制矩阵中设置为<1>,其他值均设置为<0>.该二进制矩阵可以看作是一个用户兴趣形式背K=(U,I,R),其中U是所有用户集合,I是所有项目集合,R是U和I之间的一个关系.然后通过用户兴趣形式背景K可以构造用户兴趣概念格[18],用Lc表示K的概念格,图2给出了实例分析.
为了加快推荐过程,需要删除用户兴趣概念格Lc中一些多余的形式概念,本文定义了两个条件对形式概念进行删除:
常爱兰爱上驮子的事其实我们岭北周村的人是不大看好的。村上的周老相公就奚落过几次,说常爱兰爱驮子,肯定是爱驮子的钱。驮子有钱么?周老相公就说,你们看,驮子到岭北周村来几年了,从来没有回过家,那么他的钱用到哪里去,咱们村,噢,不用说村了,就是整个岭北镇就那么屁股点大的地方,他去哪里用钱,他一年弹棉花弹到头了,钱肯定是有不少的。而常爱兰呢,她有什么?她就是一个寡妇,今年寡这个,明年寡那个,寡上谁谁倒霉。
对于一个形式概念Z:
1)若∃Z∈Lc,使得|Ext(Z)|=1,即可删除Z.
2)若∃Z,Z′∈Lc,使得Int(Z)∈Int(Z′),即可删除Z.
图3显示了图2(c)删除多余形式概念后的结果,为最终的用户兴趣概念格Lc.
3.1.2 划分直接“最近邻”和间接“最近邻”
在这一阶段,首先,需要查找目标用户的“最近邻”.然后,通过用户兴趣概念格来确定与目标用户最相似的用户.最后,将“最近邻”与最相似用户进行比较,以此来划分直接“最近邻”和间接“最近邻”.下面将详细介绍该过程:
在基于邻域的协同过滤方法中,对相同项目具有相似偏好的用户被视为“最近邻”用户.本文也采用了协同过滤方法来查找目标用户的“最近邻”,选择与目标用户u兴趣相近的若干用户作为“最近邻”Nu.以图2(a)的评分矩阵为例,若向目标用户1推荐项目5,从评分矩阵中可以看出,用户U2、U3和U6均参与了对项目5的评分,这些用户都有可能向目标用户1推荐项目5,则目标用户1的Nu为{U2,U3,U6}.
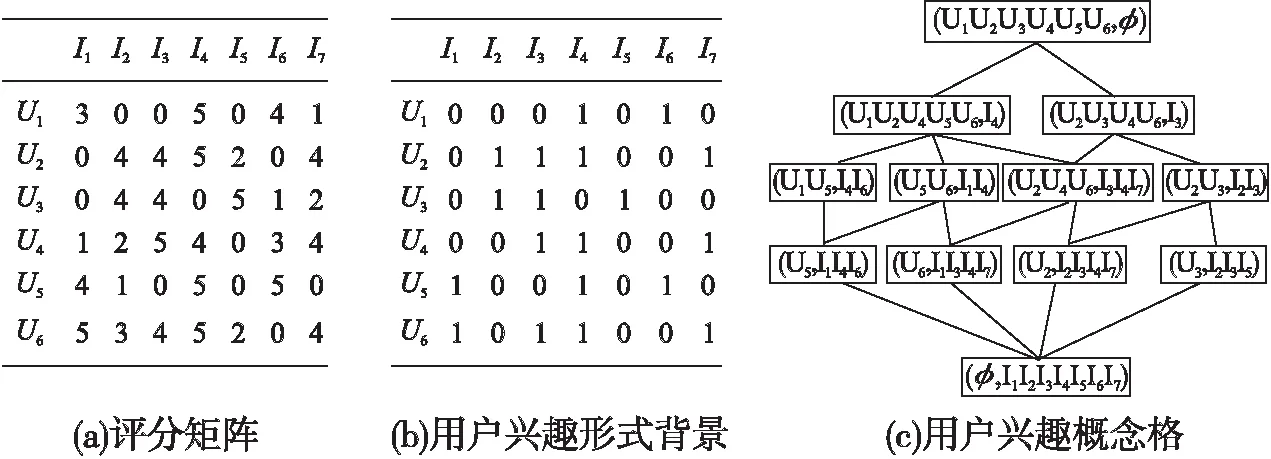
图2 构造用户兴趣概念格实例分析Fig.2 Example analysis of constructing user interest concept lattice
然后,查找与目标用户u最相似的用户MNu,在用户兴趣概念格Lc中,采用由底部到顶部的搜索方法来查找MNu,MNu的定义如下:
MNu={Ext(Z)|max(|Int(Z)∩I′u|),Z∈Lc}

图3 最终的用户兴趣概念格Fig.3 Final user interest concept lattice




3.2 推荐模块
确定了目标用户的直接“最近邻”和间接“最近邻”后,就可以计算用户之间的相似度,以此来推算出目标用户对某个项目的感兴趣程度,感兴趣程度可以通过预测评分值来表示.
3.2.1 计算相似度
对于直接“最近邻”用户,由于直接“最近邻”用户的评分在评分预测过程中影响更加明显,他们与目标用户直接相关,所以,直接“最近邻”用户与目标用户之间的相似度值被设置为<1>.
对于间接“最近邻”用户,本文提出了一种新的方法来计算间接“最近邻”用户与目标用户之间的相似度.在基于用户的协同过滤推荐方法中,采用式(6)计算用户u与用户v的相似度.
(6)
式中,Iu为间接“最近邻”用户u评分过的项目集,Iv为目标用户v评分过的项目集,|Iu|为用户u评分过的项目个数.从式(6)可以看出,本文提出的相似度计算方法只需要使用用户的评分项目集,避免了用户之间的共同评分项目的影响,从而,解决数据稀疏问题.
3.2.2 预测评分值
计算了相似度后,接下来是对评分值进行预测.
首先,计算推荐项目的平均评分.对于推荐项目i,采用式(7)计算平均评分.
(7)

然后,预测推荐项目的评分,使用式(8)预测目标用户u对项目i的评分Ru.i.式中,a是评分集合的最高评分.

(8)
4 实验结果
4.1 数据集
本文使用的数据集为MOVIELENS 100 K,MovieLens数据集是评价推荐算法有效性最常用的数据集之一.该数据集包含了943名用户对1682部电影的所有评分,在1~5的评分等级范围内有100000个匿名评分,每个用户至少对20部电影进行了评级.如果评分为1意味着用户不喜欢这部电影,评分为2意味着用户对这部电影的喜爱程度很低,评分为3意味着用户对这部电影持中立态度,评分为4意味着用户喜欢这部电影,评分为5意味着用户非常喜欢该部电影.
原始数据集中可用评级的密度偏大,由于该模型需要在不同高度稀疏的数据集上进行测试,因此从MovieLens数据集中随机的抽取300个用户对500个随机电影的评分,生成了两个样本数据集.然后,将两个样本数据集中的可用评级随机更改为零,以形成两个稀疏度不同的数据集.数据集-1的可用评级为3026,稀疏度约为98%,数据集-2的可用评级为1656,稀疏度约为99%.
4.2 评价指标
本文采用平均绝对误差(mean absolute error,MAE)[19]和均分根误差(rooted mean squared error,RMSE)[20]来评价所提方法的准确性.
MAE表示预测评级与实际评级之间的偏差,可用于度量预测的精度.通常情况下,MAE越小,预测的精度越高,MAE的计算使用公式(9).
(9)
其中,n表示预测的所有评分的个数,ri表示项目i的实际评分值,pi表示项目i的预测评分值.
另一个与MAE相似的度量是均方根误差(RMSE),该值表示预测评级与实际评级之间的平均误差,它反映了实际值与预测值之间的偏离程度,RMSE越小,预测的精度越高,使用公式(10)计算.
(10)
4.3 结 果
为了验证RRP-UICL方法的有效性,将RRP-UICL方法与传统的基于修正的余弦相似性度量(UCF-ACos)、基于皮尔逊相关度量(UCF-PC)、基于受约束的皮尔逊相关度量(UCF-CPC)、基于Jaccard度量(UCF-Jaccard)四种方法分别在数据集-1和数据集-2上进行了实验,对五种方法进行了比较,并给出了精度指标.
当推荐项目为5、10、15、20时,对于数据集-1和数据集-2两种不同稀疏度的数据集,五种方法的MAE随推荐项目变化的实验结果分别见图4和图5.
从图4和图5中可以看出,在5种方法中,RRP-UICL方法在两个数据集中的MAE值都小于其余的4种方法.随着稀疏度的增加,UCF-ACos方法和UCF-PC方法的MAE值明显地在增大,受数据稀疏的影响较大.UCF-CPC方法和UCF-Jaccard方法的MAE值变化不是很明显.RRP-UICL方法在整个稀疏度实验范围内均取得了较小的MAE值,在数据集稀疏度较高的情况下有明显的优势.总结来说,在稀疏场景下,本文方法比传统的协同过滤方法有更好的预测精度.

图4 数据集-1不同方法的MAE值比较Fig.4 MAE value comparison of the different methods for dataset-1

图5 数据集-2不同方法的MAE值比较Fig.5 MAE value comparison of the different methods for dataset-2
同样的,在5、10、15和20这4个不同的推荐项目下,图6和图7分别展示了5种方法在数据集-1和数据集-2中的RMSE值随推荐项目变化的实验结果.
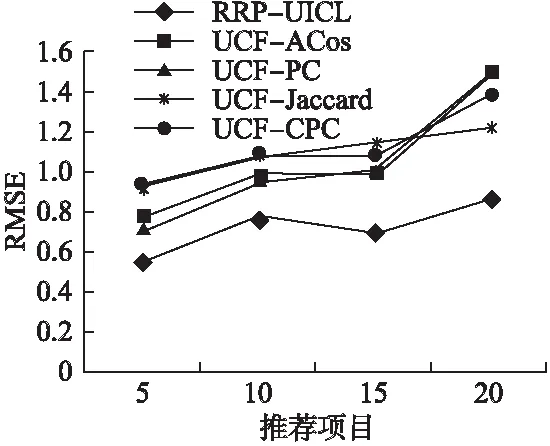
图6 数据集-1不同方法的RMSE值比较Fig.6 RMSE value comparison of the different methods for dataset-1
从图6和图7中可以看出,与MAE值相似,RRP-UICL方法在两个数据集中的RMSE值也都小于其余的4种方法.当数据集的稀疏度不断增大时,RRP-UICL方法仍然保持较低的RMSE值,而UCF-ACos方法和UCF-PC方法的RMSE值却在不断的变大,从图7中可以清楚地看到,UCF-ACos方法和UCF-PC方法的RMSE值比RRP-UICL方法大很多.UCF-CPC方法和UCF-Jaccard方法的RMSE值增加幅度不是很大,但也明显大于RRP-UICL方法的RMSE值.因此,RRP-UICL方法比传统的协同过滤方法有更好的预测精度.

图7 数据集-2不同方法的RMSE值比较Fig.7 RMSE value comparison of the different methods for dataset-2
5 结束语
本文提出的RRP-UICL方法,解决了传统的基于协同过滤推荐算法中存在的数据稀疏的问题.该方法考虑到目标用户的“最近邻”用户在评分预测过程中的影响程度不同,所以通过用户兴趣概念格将“最近邻”分为直接“最近邻”和间接“最近邻”两类.然后采用不同方法计算直接“最近邻”和间接“最近邻”与目标用户的相似度.最后,通过计算所得的相似度值来预测目标用户的不可见项目评分值.在真实的电影评分数据集上,验证了RRP-UICL方法对稀疏数据提高预测准确度的有效性.在今后的工作中,我们将研究概念格的构造算法,在本来稀疏用户-项目兴趣数据集上高效地构造概念格,从而提高算法的效率.
