电子商务环境下ST公司财务危机分类预测
2020-09-22黄丽霞
摘要:在过去的几十年中,人们一直在深入研究企业危机预测问题。从传统的统计模型到智能的机器学习模型,已经构建各种预测模型应用于不同数据集,尤其是人工智能技术的发展为该类问题提供了更多方法,因此本文首先以电子商务环境下的ST公司为研究样本,构建基于卷积神经网络的财务危机预测模型,对电子商务企业财务状态分类进行实证研究。研究结果表明,相比于传统类预测方法,基于CNN的分类模型对ST公司的预测准确率明显高于其他几种模型,具有较好的预测性能。
关键词:卷积神经网络;财务危机;电子商务;ST公司
引言
风险水平是银行和投资者进行投资决策的主要关注点,它可以衡量公司经营状况的潜在不确定性并评价日常的经营活动。因此,非常需要能够预测投资者愿意投资的公司破产的可能性。电子商务企业财务危机是指企业运营管理失效,致使企业无法适应经营环境的变化和做出管理策略的改变,出现到期不能清偿债务的情况,最终使得企业生存发展陷入困境。根据中国证券市场的规定,一般将财务报表中连续两年出现负盈利的的企业做出警示,在企业名称前添加“ST”标记,从企业的角度来看对未来经营、投融资活动会产生不利的影响,为了避免这种情况需要提前识别财务风险,积极采取措施解决问题。
1、文献综述
通过国内外财务危机研究的梳理,主要的关注点是预测变量选择和预测模型构建。徐安(2016)认为应该减少变量的个数,一是太多变量会导致数据不完整。二是如果有很多变量,很难解释变量与分类结果之间的关系。Tadaaki Hosaka(2018)认为从模型性能角度看减少变量个数会使得信息丢失,降低预测的准确性。因此结合主成分分析对数据预处理提高效率,既可以减少输入变量个数,又最大限度保证了数据量。危机预测问题关键是衡量公司偿债能力,初始模型主要是基于统计学,Fitzpatrick最早构建单变量模型,Altman引入多变量产生经典Z分数模型,Meyer等(1970)在前者的研究基础上引入逻辑回归预测财务危机发生的概率,包括logistic和probit模型。
虽然这些模型已广泛应用于学术界和工业界,但统计模型在提高预测能力方面受到限制,为了克服统计模型的局限性,在机器学习领域积极开发了使用模式识别方法的研究,如支持向量机(SVM),遗传算法、神经网络(NN)和Adboost模型之类的机器学习技术方法,研究表明确实比传统的统计方法有更高的准确率。赵冠华(2009)的研究结论表明,遗传算法能自动寻优到最佳参数,显著提高了模型预测的正确率。Bredart(2014)研究神经网络与Logistic的预测效率表明前者有更高的准确性。Flavio Barboza等(2017)使用新的变量,例如以经营利润率、股本回报率、销售收入、资产、员工数量相关的增长指标作为预测变量。结果表明与传统模型相比,机器学习模型平均显示出超过10%的准确度。将所提出模型与所有预测变量进行比较,与随机森林相关的机器学习技术贡献87%的准确度,而逻辑回归和线性判别分析在测试样本中分别产生69%和50%的准确率。Marcantonio M等(2014)基于遗传算法和Gregorio(2016)基于案例推理而建立的财务危机预测模型,已被应用于获得决策破产规则。A.Chaudhuri,K.DeFuzzy (2012)应用模糊SVM来解决破产分类问题。这种增强的方法结合了机器学习和模糊集的优点,在聚类能力方面优于概率神经网络。
最近的研究表明,卷积神经网络正被应用于各种领域的识别问题,某些领域已有的研究显示出它有比于统计模型具有更高的识别精度和更低的误差频率,这为电子商务环境下的企业财务危机预测研究开阔了新的思路,提供了新的理论和技术支持。
2、实证研究
2.1 样本选择
互联网电子商务的发展是从1999年B2C网站开通,网上在线纳税、教育、购物等应用开始,伴随互联网技术的发展和移动通信工具的普及应运而生,电子商务利用信息网络技术,在互联网、局部网和增值网上以电子交易方式进行交易行为和相关服务的活动,现如今互联网行业产值已超5000千亿,对该领域中的财务危机研究具有重要意义。因此从软件和信息技术服务业和电子商务中心2018年公布的500强电商企业中选取120家公司做为研究样本。
2.2 数据收集与预处理
电子商务ST企业样本的财务指标数据来源于深圳国泰安数据库、金融数据库以及各类财经数据网站,按照1:2的比例选取了2016-2019年电子商务行业中120家首次被ST与财务健康的A股公司。并按照时间将样本分为训练组和测试组,训练样本由2016-2018年75家财务异常和财务正常公司组成,作为训练样本用来训练模型,其中财务异常的公司有25家,由0,1编码区分两组变量类别,ST公司所属类别的变量被定义为1,财务健康的企业被定义为变量0,剩下的2019年45家以1:2对比的财务异常和财务正常公司作为测试样本用来检验模型的精确度。
2.3 财务危机预测指标
财务危机预测领域对于财务指标选取的研究还没有统一的标准,但大部分研究集中是从财务指标角度出发,因此为了使本文研究结果与一般方法具有可比性,财务危机预测领域对于财务指标选取的研究还没有统一的标准,但大部分研究集中是从财务指标角度出发,因此为了使本文研究结果与一般方法具有可比性,初步选取由盈利能力、创新成长能力、营运能力、偿债能力组成的12个财务指标,其中盈利能力包括总资产、主营业务利润率、净资产收益率,销售成长能力包括收入、凈资产增长率和研发人员占比,营运能力包括应收帐款、总资产、股东权益周转率;偿债能力包括流动、速动比率和资产负债率。运用SPSS对数据进行主成分分析。结果如表1。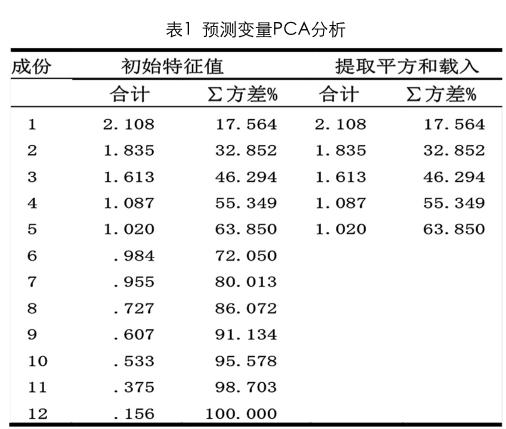
表1是利用SPSS对总体样本进行描述性统计的结果,其中营收账款周转率、存货周转率和产权比率的均值和标准差数值偏大,没有通过三倍标准差交叉检验,于是在PCA分析中,选取剩余的12个指标作为自变量,确定5个主成分因子并保存为变量,结合旋转成份矩阵将变量命名为盈利能力、偿债能力、成长能力、财务杠杆、经营能力,做为卷积神经网络的输入。
2.4 基于卷积神经网络的分类预测
卷积神经网络结构包括2个卷积层、2个池化层和一个完全连接层,主要结构如图1下。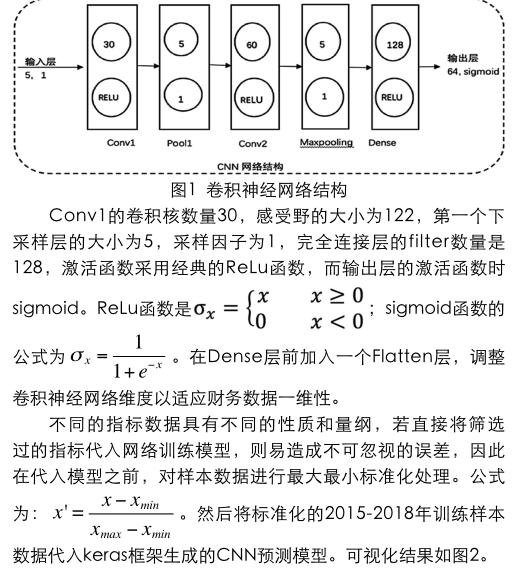
如图2所示,它是由PCA确定的5个变量在卷积神经网络上的实验结果。图中training acc表示训练准确率,train loss表示训练损失函数,val acc为测试准确率,val loss为测试损失函数。在实验中,输入数据的大小为9000×1,样本个数为45个。
通过不断训练和调整参数可知,当epoch为100时,准确率和损失值的震荡幅度最小。由图3观察可知,测试样本上的损失值普遍要比训练样本中小,而准确率普遍要高,其中测试准确率和损失值曲线的波动度要比训练样本强烈,这代表训练样本的学习率和拟合度比较高。测试准确率曲线中准确率主要在0.7~0.9之间,其中最高值为89.31%,最小值为74.24%,平均准确率大概为85%。损失值函数曲线是红色曲线,变动范围在0.3至0.5之间,平均值为45%。统计结果如表2。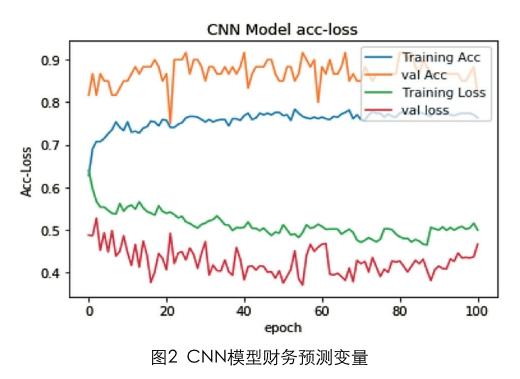
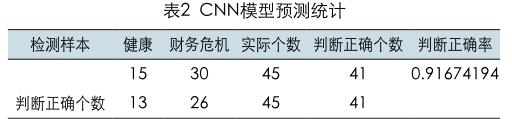
卷积网络财务危机预测模型的实证研究统计结果如表4所示,在对财务指标的研究中可知,判断正确率达到91.67%。其中,在对检测样本的统计结果中,财务危机公司误判成健康公司的个数为4;而将健康公司误判成财务危机公司的个数是2。这显示了卷积神经网络在分类预警中的优势,降低了将危机公司判断成健康公司的概率。
3、结论
以电子商务环境下上市公司的财务危机具有持续性和累积性为出发点,综合运用卷积神经、财务危机预测理论以及SPSS和Python编程技术,构建了以盈利能力、偿债能力、成长能力、财务杠杆、经营能力为主的指标体系,提出了基于卷积神经网络的财务危机预测模型,通过对120家样本公司的实证研究表明该方法在误差率和识别正确率上显示了优越的性能,研究显示预测准确率达到91%,相比于统计类预测模型有很大的改善。这对于财务危机预测模型是一个巨大的进步,具有广阔的应用前景。
参考文献:
[1] Tadaaki Hosaka.Bankruptcy prediction using imaged financial ratios and convolutional neural networks[J]. Expert Systems with Applications ,2019.117(1):287-299.
[2] A.Chaudhuri,K.DeFuzzy.support vector machine for bankruptcy prediction[J].Appl.Soft Comput,2012(2): 2472-2486.
[3] Marcantonio M D,Dellepiane U,Laghi E. Bankruptcy Prediction Using Support Vector Machines and Feature Selection During the Recent Financial Crisis[J]. International Journal of Economics and Finance,2015, 7(8):182-195.
作者簡介:黄丽霞,研究生,上海工程技术大学会计学专业。
