场景文字识别技术研究综述
2020-09-15王德青吾守尔斯拉木许苗苗
王德青,吾守尔·斯拉木,许苗苗
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.新疆大学 新疆多语种信息技术重点实验室,乌鲁木齐 830046
1 引言
文字作为人类文明的标志,是记录思想、文化和历史的载体,是信息交流的途径,也是人类感知世界的重要手段。文字是不同于普通视觉元素的信息来源,可以和其他视觉元素信息形成互补。文字中包含的高层语义,使得场景信息可以被高效地利用,这对理解图像具有非凡的学术意义。自然场景中的图像通常包含丰富的文字信息,对分析和理解场景图像的内容有着重要作用。当前,随着互联网的快速发展,越来越多的领域需要利用图像中的文字信息[1]。
光学字符识别(Optical Character Recognition,OCR)[2]技术是指运用电子设备对图像中的文字进行检测,然后识别出图像中的文字内容。场景文字识别(Scene Text Recognition,STR)[3]是在自然场景中图像分辨率低、背景复杂、字体多样等情况下,将图像信息转化为文字序列的过程。当前,很多人定义OCR 技术不仅包括传统意义上对简单二值图像中的的文字识别,还包括复杂的自然场景图像中的文字检测和识别。近年来,OCR 技术的应用使得人们工作与生活的效率大幅提升,OCR技术也是当前计算机视觉领域的热点研究方向。近年来,图像里的文本检测与识别技术发展迅速,但是由于受到识别文本的语种、数据集的大小及公开时间等限制,场景图像文字检测识别技术目前尚不能满足实际应用中的需求,为此该技术的应用前景非常广阔。
目前,随着人工智能的飞速发展以及英文和中文的广泛使用,研究图像里的中英文文字识别在机器翻译、图像视频文本识别、文档识别等领域具有极其重要的意义。同样,维吾尔文在一带一路的沿线省份新疆,使用非常广泛,研究图像中的维吾尔语检测及识别对于智慧城市建设、文化遗产保护、网络舆情监控等意义重大。目前,OCR 技术主要应用于卡证识别、票据表单识别、图像文字识别、遥感图像识别、无人驾驶、图像检索等。
传统的光学字符识别与场景文字识别不同,传统光学字符识别主要用于文档中的图像识别,文档的背景颜色比较单一[4]、分辨率高。然而在自然场景中,图像里的文字会受到光照、复杂背景、对比度低、遮挡等因素的影响,因此会存在图像中的文字大小、角度、位置变化、分辨率不同等问题。为了提高文字的识别效果需要对图像进行预处理,预处理过程包括:彩色图像灰度化、二值化处理、噪声去除、图像变化角度检测、文字几何矫正[5]等。
2 场景文字识别预处理技术及流程
场景文字识别预处理技术包括图像分割、图像二值化、图像去噪、检测技术、矫正技术等。
(1)检测技术
由于自然场景中的图像背景复杂使得图像存在几何变形,图像的畸变对文字识别的效果影响较大,因此对图像的检测是十分重要的。直线检测常用的方法[6]可分为两类[7]:全局Hough 变换法和局部感知组合法。文本图像的倾斜检测方法有[8]:投影图倾斜检测方法、基于Hough 变换的倾斜检测方法、交叉相关性倾斜检测方法、基于Fourier变换的倾斜检测方法和K-最近邻簇倾斜检测方法等。
(2)矫正技术
在图像中的字体可能会变形,以维吾尔文为例,维吾尔文共有32 个字母,其中元音有8 个,辅音有24 个,每个字母有2至8种写法,共有126种形式[9]。维吾尔语的结构属粘连语类型[10],为了更好地矫正要先确定其基线,矫正是为了得到标准化的数据,常用的数据矫正方法包括[11]:(1)基线提取和弯曲矫正。由于一些字符存在弯曲且另一些字符在识别时是通过其相对于基线的位置来确定的,所以要确定基线的位置。基线提取的主要方法有:行间互相关[12]、最近邻域聚类等。(2)倾斜矫正比较常用的算法有[13-14]:竖直笔画、投影图方法。(3)字号矫正。将字体大小处理为一致的大小,而且能够将字号进行估计[15]。(4)图像轮廓平滑处理。图像的平滑(滤波)是为了抑制图像的噪声,减少文字表示的采样点数量,提高有效性。
(3)传统光学字符识别流程
传统的光学字符识别过程为[16]:图像预处理(彩色图像灰度化、二值化处理、图像变化角度检测、矫正处理等)、版面划分(直线检测、倾斜检测)、字符定位切分、字符识别、版面恢复、后处理、校对等。流程图如图1所示。
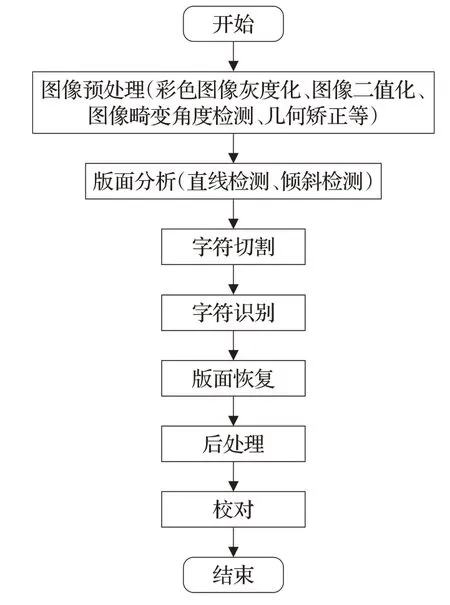
图1 传统字符识别流程图
(4)深度学习场景文字检测与识别流程
深度学习场景图像文字检测与识别流程包括:输入图像、深度学习文字区域检测、预处理、特征提取、深度学习识别器、深度学习后处理等。流程图如图2所示。
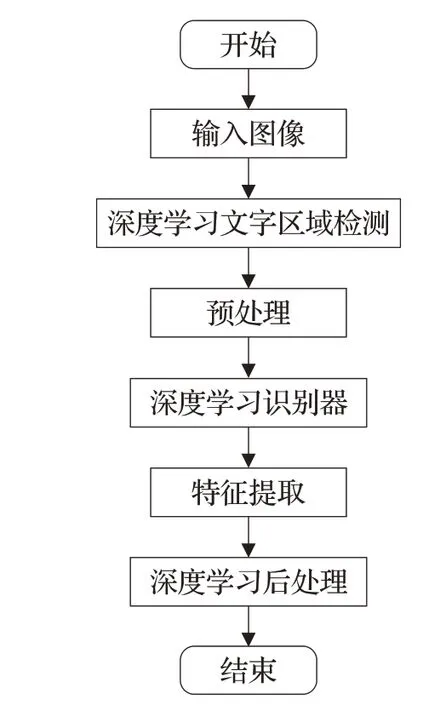
图2 基于深度学习的OCR流程图
3 基于深度学习的自然场景文字检测与识别技术
3.1 基于深度学习的通用检测网络
场景文字检测与识别算法的特征提取模块的网络通常来源于通用检测网络,部分目标检测算法可直接用于场景文字检测。本节介绍几种常用的通用检测网络。
(1)RCNN网络
RCNN[17]网络是首次将卷积神经网络应用于目标检测领域的算法。该网络利用CNN[18]进行特征提取,通过候选区域方法实现目标检测问题的转化。但是RCNN网络提取候选框是通过速度较慢的selective search[17]算法且重复卷积网络计算,所以该算法存在内存占用量大、运行速度慢、训练需要多阶段、不能实时更新等缺点。其结构如图3所示。

图3 RCNN网络图
(2)Faster R-CNN网络
Faster R-CNN[19]网络将获取特征图、候选区域选取、回归和分类等操作全部融合在一个深层网络当中,实现了端到端检测。该网络引入RPN[19]网络,利用CNN卷积操作后的特征图生成候选区域,训练时RPN 与检测网络Fast R-CNN[20]共享卷积层,大幅提高网络的检测速度和精度。但是该算法因为主干网络较为复杂所以产生目标候选框时需要较多时间,运行速度慢不能满足实时性要求。其结构如图4所示。
(3)YOLO网络
YOLO[21]网络是一个端到端网络,可以从原始图像的输入直接得到物体位置和类别。该网络将物体检测看为回归问题,输入图像经过一次推理,就能得到图像中所有物体的位置和其所属类别及相应的置信概率。但是该网络的局限性在于:(1)位置的准确性差,对小目标和密集物体的检测效果不好。(2)输入尺寸固定,输出层为全连接层,在检测时,只支持与训练图像相同的分辨率输入。(3)没有region proposal 阶段,召回率较低。其结构如图5所示。
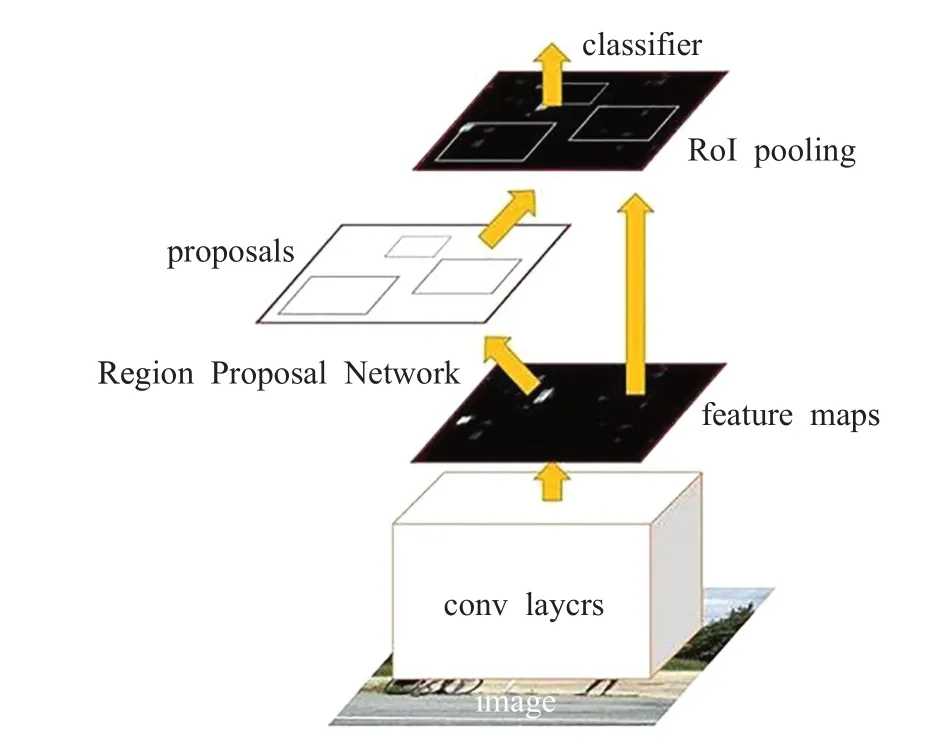
图4 Faster R-CNN网络图

图5 YOLO网络图
(4)RetinaNet网络
RetinaNet[22]网络使用新的损失函数focal loss,有效解决了one stage目标检测过程中正负样本比例不平衡问题。该网络实现目标检测的过程为:首先用残差网络ResNet[23]进行特征提取,其次用特征金字塔网络FPN[24]生成多尺度特征图,然后用全卷积分类子网络进行目标分类,最后用回归网络对目标进行定位。由于该网络是基于anchor-based的检测方法所以存在两个问题:(1)启发式引导特征选择。(2)基于重叠的anchor 采样。其结构如图6所示。
(5)FSAF网络
FSAF[25]网络使用无anchor 特征选择模块,有效解决了启发式引导特征选择和基于重叠的anchor 采样问题,提升了检测的准确率和速度。实验结果表明FSAF网络可以更好地发现具有挑战性的目标;具有较好的鲁棒性和高效性。但是该网络是基于anchor-point 的方法,所以存在注意力偏差(attention bias)和特征选择(feature selection)等问题。其网络结构图如图7所示。
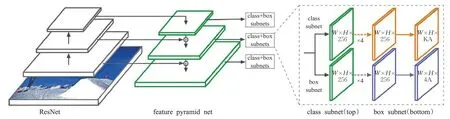
图6 RetinaNet网络图
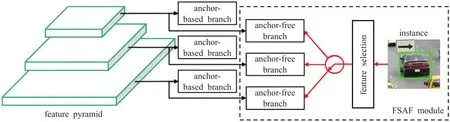
图7 FSAF网络图
由表1可以看出:RCNN网络将CNN方法应用到目标检测问题上,检测精度较传统方法大幅提升;Faster R-CNN 网络用RPN 网络提取候选区域,有效解决了利用SelectiveSearch算法选取候选框时运行速度慢的问题但是该网络的速度不能满足实时性要求;YOLOV1网络采用单独的CNN 模型实现端到端的目标检测,相比于基于候选区域的Two-stage 类算法速度有较大提升,但没有解决Two-stage 类算法的准确率不高的问题;RetinaNet 网络提出了新的损失函数Focal Loss 解决了正负样本的比例不平衡问题,但是网络存在启发式引导特征选择和基于重叠的anchor 采样问题;FSAF 网络使用无anchor 特征选择模块,虽然解决了上述问题,但是引入了注意力偏差和特征选择问题。
3.2 基于深度学习的场景文字检测技术
文本检测与目标检测不同,文本是序列,目标检测是一个目标。在目标检测中,每个目标都有定义好的边界框,检测到的边界框与目标的实际边界框的重叠率大于某个值则说明检测结果正确。文本行是由一些独立的字符组成,检测时需要更准确的定位。所以目标检测算法不适用于场景文本检测。
自然场景图像背景复杂,文字的位置、颜色、大小等没有规律地变化,有时是多语言的,这些因素使得自然场景图片中的文字检测非常麻烦,而机器学习算法在解决自然场景图片的文字检测常常有不错的结果。本节主要介绍基于维吾尔文和中英文的图像文字检测技术。
传统的方法如李凯等[27]提出的基于边缘和基线的检测方法、依再提古丽等[28]提出基于角点密集度的定位方法、姜志威等[29]提出共享维吾尔语之间的字符结构信息等方法对于维吾尔文的检测效果并不理想,随着人工智能的快速发展,基于深度学习的方法在自然场景下维吾尔文的检测中应用较多,实验证明其检测效率高、检测的准确率较好。常用的基于深度学习的维吾尔文场景文字检测技术有:基于深度学习的自然场景中维吾尔文检测[30]、基于改进YOLOV3的维吾尔文检测[31]等。
(1)基于深度学习的自然场景中维吾尔文检测
彭勇[30]提出基于深度学习的维吾尔文检测网络。该网络利用改进的单深层神经网络进行特征提取,然后将提取的特征输入文本检测组件,最后进行定位。该算法仍然存在一些问题有待解决:(1)由于文字多方向,使用矩形边框检测时准确率较差。(2)本网络只对深度学习网络进行了改进,未将传统维语特征加入。(3)可将图像分割技术应用于自然场景维文检测。其网络结构如图8所示。
(2)自然场景中维吾尔文检测系统的设计与实现
李路晶一[31]提出改进YOLOV3[32]网络的维吾尔文检测方法。该网络对YOLO V3进行改进,将Darknet-53中的Res block替换为密集型的Dense block[33]。并且在该网络中引进dilated卷积,利用Trident Net[34]结构替换FPN。同时将深度可分离卷积(Depthwise Separable Convolution[35])和 MobileNet V2[36]进行结合,构造了一个轻量级的网络。BN 层与Depthwise Separable Convolution 进行融合,提高了运行速度。但是该网络仍存在以下问题:(1)针对维吾尔语的默认框的生成较为粗糙。(2)缺乏语义分割使得检测精度不高。其流程图如图9所示。
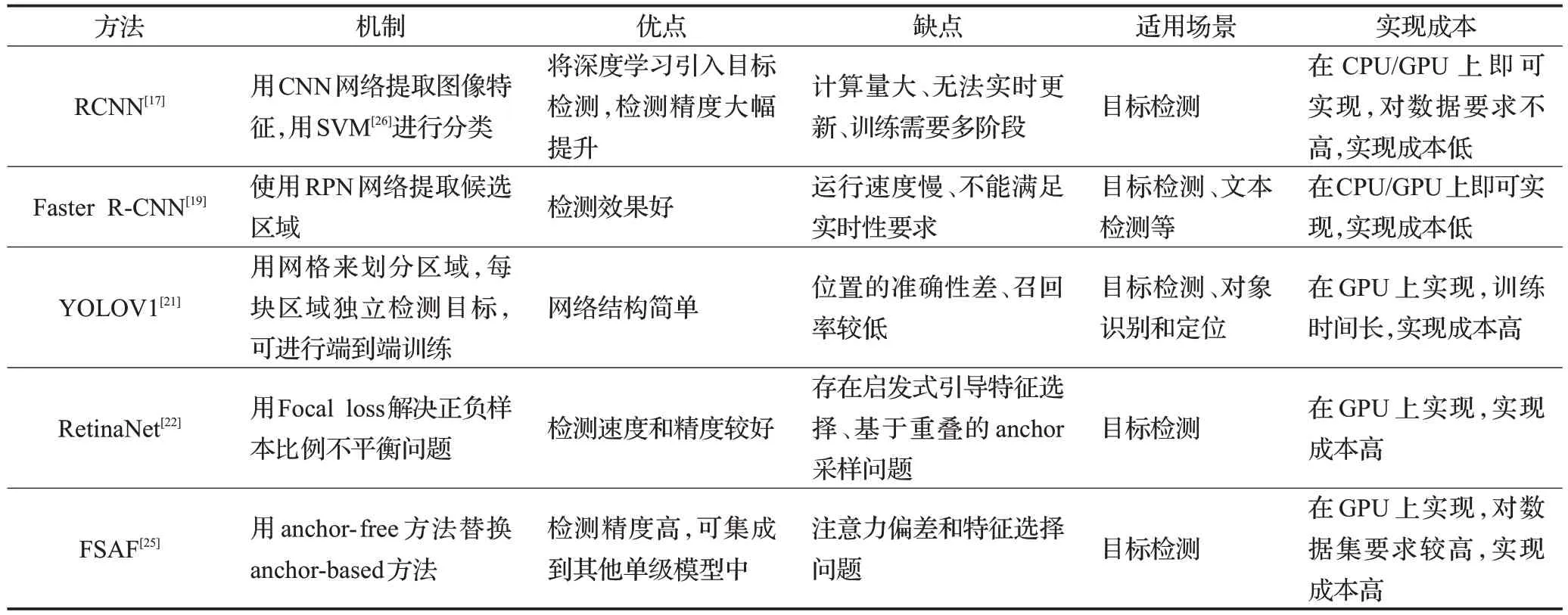
表1 通用检测网络对比
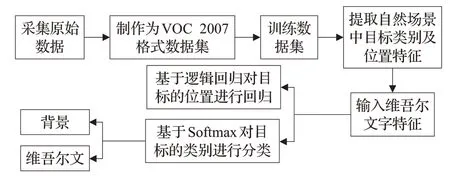
图9 维吾尔文检测流程图
常用的基于深度学习的中英文的场景文字检测方法有:CTPN[37]网络、EAST[38]网络、WordSup[39]网络、基于自适应文本区域表示的任意形状场景文本检测[40]网络、可微二值化实时场景文本检测[41]等。
(3)CTPN网络
CTPN[37]网络本质是全卷积网络FCN[42],可以输入任意大小的图像。该网络提出了垂直锚点机制,联合预测每个固定宽度proposal 的位置和文本、非文本的分数,引入RNN连接文本proposal;将CNN[18]与LSTM[43]结合,能够应用于复杂场景中的文字检测。但是该算法只能检测水平方向的文本,对多方向的文本行处理有待改善;由于涉及到anchor 合并,合并与断开的时间有待确定。其结构如图10所示。
(4)EAST网络
EAST[38]网络是一个端到端的文本检测网络。该网络利用全卷积网络(FCN[42])和非极大值抑制(NMS[44])消除中间过程冗余,有效减少了检测时间,可以检测单词级别或文本行级别的文本,检测的形状可以为任意形状的四边形。但是该网络也有很大的局限性:(1)由于该网络处理的文本实例的大小与网络的感受野成正比所以导致该网络预测长文本区域受到限制。(2)由于该算法的训练集中只有少量的垂直文本的图片,所以在对于垂直文本实例的预测会遗漏。(3)样本的权重设置不合理。其结构如图11所示。
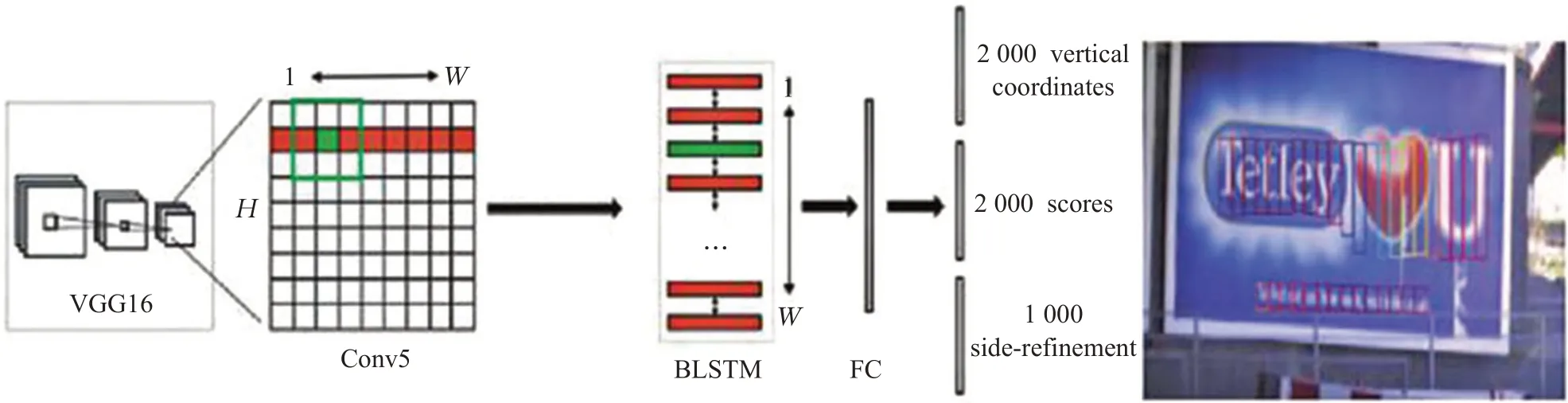
图10 CTPN网络图
(5)WordSup网络
WordSup[39]网络主要应用于不规则形变文本行识别、数学公式图文识别等。该网络通过弱监督的训练框架,在文本行和单词级标注的数据集上训练出字符级的检测模型。网络可分为两大部分,字符检测(character detector)部分,得到的是字符对应的坐标;文本结构分析(Text structure analysis)部分,得到的是词的坐标(如果为词)。该算法的缺点在于它的字符级标注是矩形的anchor,当图像存在透视畸变时,矩形框不能较好地描述该字符。同时用了合成数据集(有准确的字符级标注)以及从单词级标注的数据集评估得到的字符级标注数据集(字符级标注不一定准确)。其结构如图12所示。
(6)基于自适应文本区域表示的任意形状场景文本检测
为了解决检测弯曲文本的问题,王小兵等人[40]提出了基于自适应文本区域表示的循环神经网络。该网络使用不同的点的数量的自适应文本区域来表示不同形状的文本;同时用RNN[45]来学习每个文本区域的自适应表示,有效地避免了逐像素分割,大幅提升了运行速度。该网络可以检测水平场景文本、定向场景文本、任意形状的场景文本。但是该算法仍然可以改善:(1)该算法的训练样本为单词级别或句子级别标注,可以通过使用角点检测来改善任意形状场景文本检测。(2)该网络为非端到端网络,可以优化网络结构实现任意形状场景文本的端到端识别。结构如图13所示。
(7)可微二值化实时场景文本检测
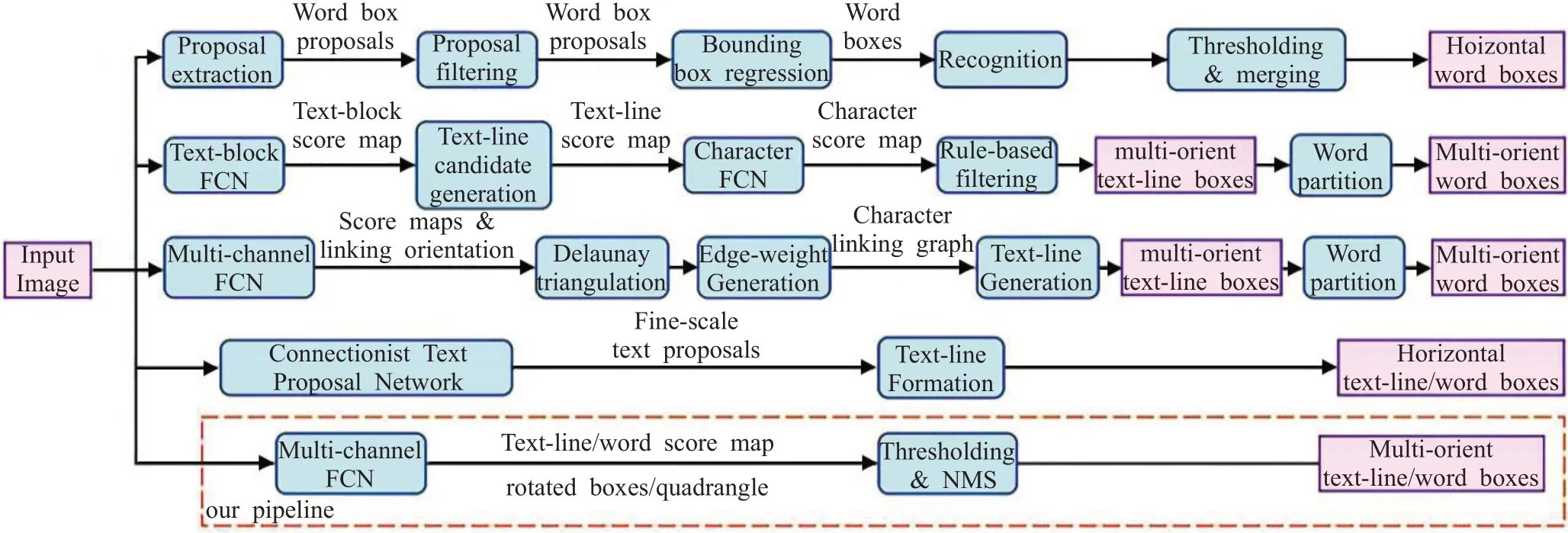
图11 EAST网络图
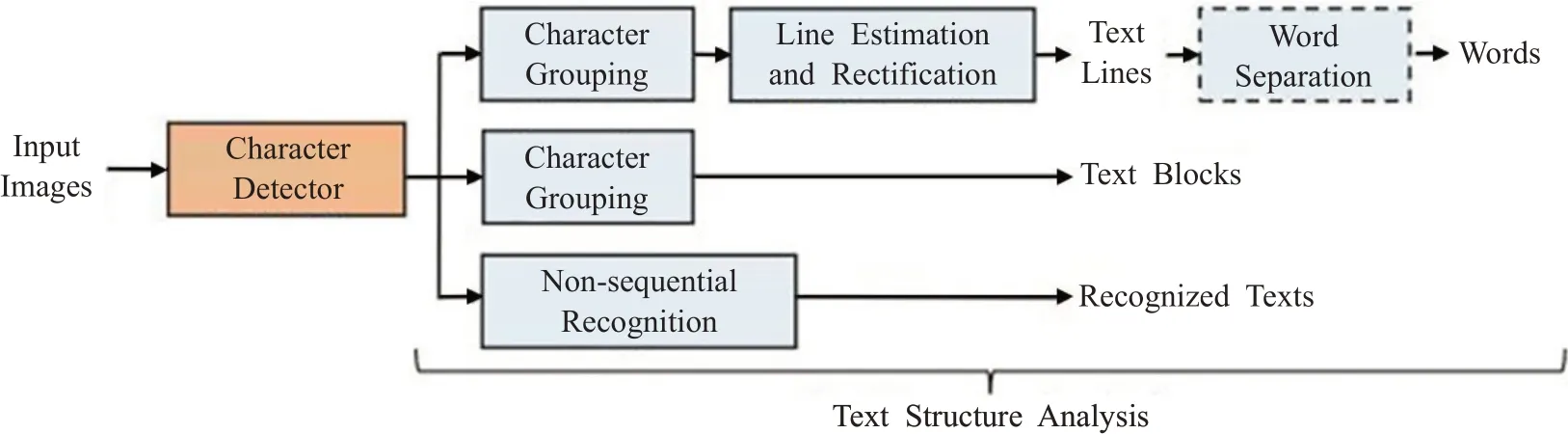
图12 WordSup网络图
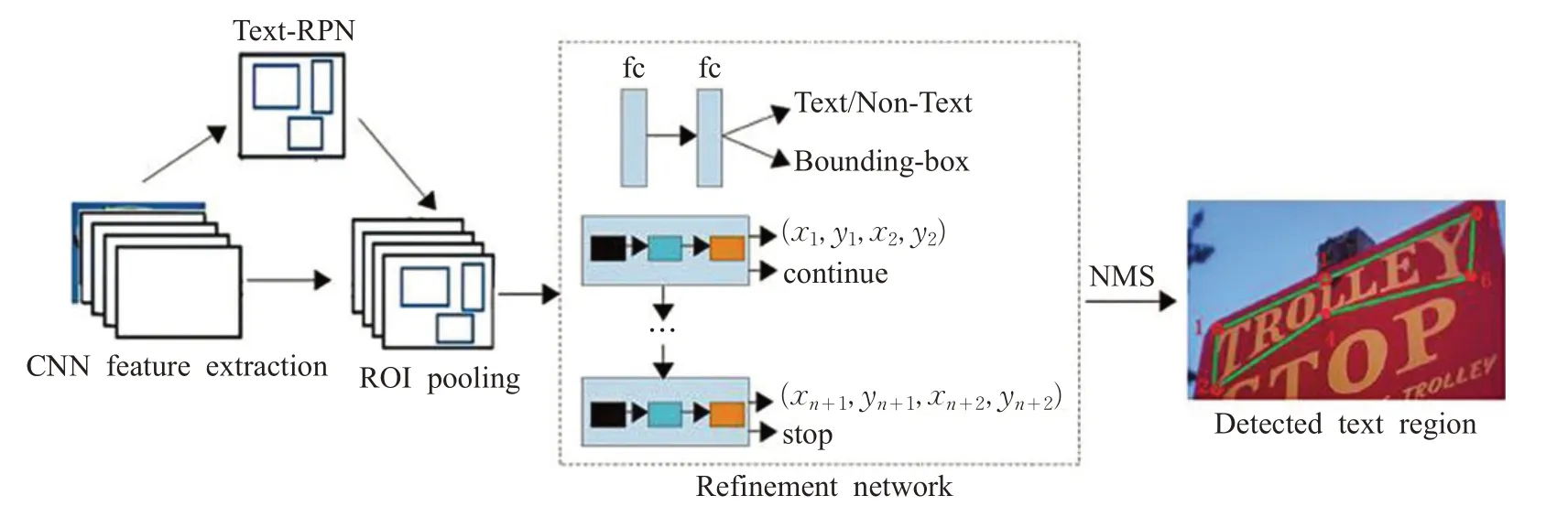
图13 自适应文本区域表示的任意形状场景文本检测网络图
廖明辉等人[41]提出可微分模块DB。该网络将分割算法与DB模块结合形成了一个快速且鲁棒的文本检测器。该网络中的DB模块产生适应的阈值使得网络运算速度加快,该模块能够生成更加鲁棒的分割二值图;在推理阶段可将该模块去除,有效减少了运行时间与资源消耗,该模块在轻量级的主干网络(ResNet-18[23])也具有很好的性能。但是该网络不是端到端检测框架。其结构如图14所示。
介绍了部分常用的场景文本检测网络。由表2 可以看出:彭勇使用改进的单深层神经网络算法进行维文检测虽然检测准确率有一定提升但是使用矩形边框检测时准确率较差;李路晶一提出改进YOLOV3 网络的维吾尔文检测方法检测速度较快但缺乏语义分割使得检测精度不高;可以看出维吾尔文检测的算法问题较多,由于缺乏公开数据集所以目前尚没有通用的维文检测网络。
CTPN网络结合CNN与LSTM深度网络,解决了复杂场景中横向分布的文字检测问题,但是该网络只能检测水平方向文本;EAST 网络利用全卷积网络(FCN)和非极大值抑制(NMS)实现端到端文本检测,但是网络的样本的权重设置不合理、感受野较小;WordSup 网络通过弱监督来训练出字符级的检测模型,解决了不规则文本识别、数学公式识别需要的字符级标注问题,但是对畸变图像的检测效果差;王小兵等提出了使用不同的点的数量的自适应文本区域来表示不同形状的文本,解决了用固定点数量的多边形来表示不同形状的文本区域不合适的问题;廖明辉等提出可微分模块DB解决了训练带来的梯度不可微问题。
3.3 基于深度学习的图像文字识别技术
文字识别是将图片中的文字序列识别的过程。文字识别时输入的是含有文字的候选框,输出是该检测框中的文字序列[46]。由于目前尚无性能较好的维吾尔文识别网络,本节主要介绍常用的基于中英文的场景文字序列识别算法:CRNN[47]网络、RARE[48]网络、FAN[49]网络、二维视角的场景文本识别[50]网络、FACLSTM[51]网络等。
(1)CRNN网络
CRNN[47]网络(Convolutional Recurrent Neural Net-work)是一个端到端的识别网络,包括特征提取、序列分析、序列解码三个部分。该网络使用双向LSTM[43]和CNN 对图像进行特征提取且将语音识别领域的CTC[52]引入图像处理不定长序列对齐问题。但是该网络仍然存在不足:(1)BLSTM和CTC使得网络结构复杂且计算难度大。(2)因为使用的是序列特征故对于角度很大的值不能识别。该网络结构如图15所示。

图14 可微二值化实时场景文本检测网络图
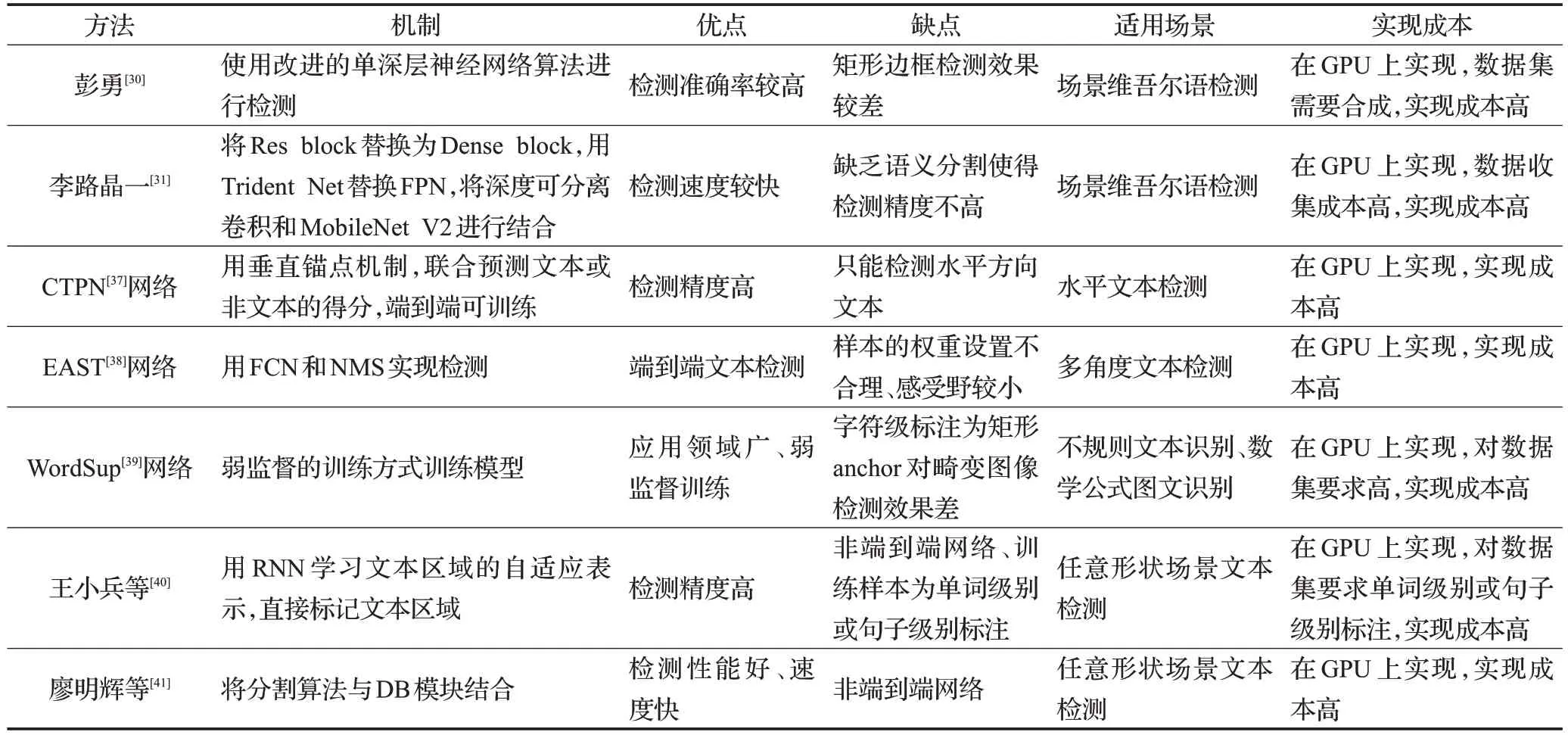
表2 文本检测网络对比
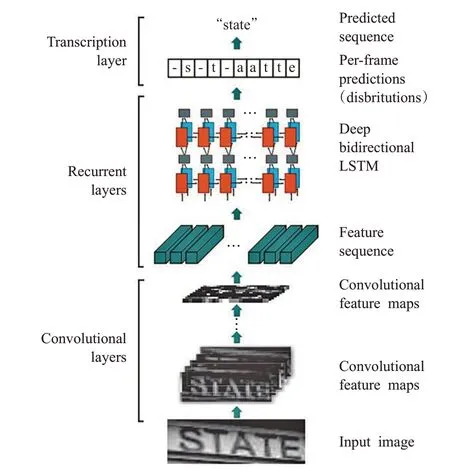
图15 CRNN网络图
(2)RARE网络
RARE[48]网络将 TPS[53]和 STN[54]结合使 STN 具有较强的矫正形变能力,可准确地识别透视变换过的文本以及弯曲的文本。该网络由空间转换网络(Spatial Transformer Network,STN)和序列识别网络(Sequence Recognition Network,SRN)两个部分组成。STN 将输入图片中的文本矫正成水平形,然后SRN 进行文本识别使得该网络在变形的图像文本识别中效果较好,可端到端训练。但是由于该网络在最后一个全连接层中使用了非线性激活函数tanh,梯度在反向传播过程中被保留,导致收敛速度较慢。结构如图16所示。
(3)FAN网络

图16 RARE网络图
FAN[49]网络解决了在复杂图像中不能得到特征区域和目标字符偏离的问题。该网络的AN(Attention Network)模块主要计算对齐因子使注意力区域与对应的真值标签对齐;FN(Focusing Network)模块首先检测注意力网络的注意力区域与目标字符位置是否对齐,然后自动调整注意力网络的注意力中心,所以该网络可以更精确地识别自然场景图像中的文本。但是该网络中注意力机制的对齐操作依赖于上一步的解码信息,如果上一步解码出错,则会导致注意力机制的对齐产生错误,且此错误会累积传播,在较长的手写文本上这个问题较为明显。其结构如图17所示。
(4)二维视角的场景文本识别
二维视角的场景文本识别(Scene Text Recognitionfrom Two-Dimensional Perspective[50])是一种基于FCN 的文本识别算法。该网络将不规则文本识别看作图像分割问题,将文本图片编码为二维特征实现不规则文本的识别。首先用Character Attention FCN(CA-FCN)模块做像素级的分类,再通过字符形成模块(word formation module)预测整合后输出字符序列。但是该网络对于字符的Attention[55]机制需要带有字符位置的训练样本,对于没有字符级注释的训练集该算法会受到限制。其主要结构如图18所示。
(5)FACLSTM网络
FACLSTM[51]网络解决了二维特征图转换为一维特征向量时二维图像的结构信息和像素空间相关性信息被破坏的问题。FACLSTM 网络是一个典型的编码-解码结构,用嵌入Deformable Convolutional Networks[56]的VGG作为主干网络,其中有两个解码分支,一个特征检测分支,一个检测字符中心掩码分支。在序列解码时,经过ConvLSTM[57]网络提取特征图,然后用全连接层将提取的特征图映射为字符输出。该算法大幅提高了文本识别的精度。该网络的缺点是不能进行端到端识别。其结构如图19所示。
由表3 可以看出:CRNN 网络将用 BLSTM 和 CTC学习文本图像中的上下文关系解决了基于图像的序列识别问题但是由于使用序列特征,对于角度较大的值很难识别;RARE网络将STN和TPS结合实现了对不规则文本的端到端的识别但是该网络的收敛速度较慢;FAN网络提出FN 网络解决了attention drift 问题;二维视角的场景文本识别网络提出将文本图片编码为二维特征,实现了任意形状场景文本识别但是该算法的训练数据需要像素级标注成本较高;FACLSTM网络将基于CNN的特征提取(encoder)和基于ConvLSTM 的序列识别(decoder)相结合,解决了传统全连接式LSTM无法充分利用二维文本图像空间信息的问题。

图17 FAN网络图
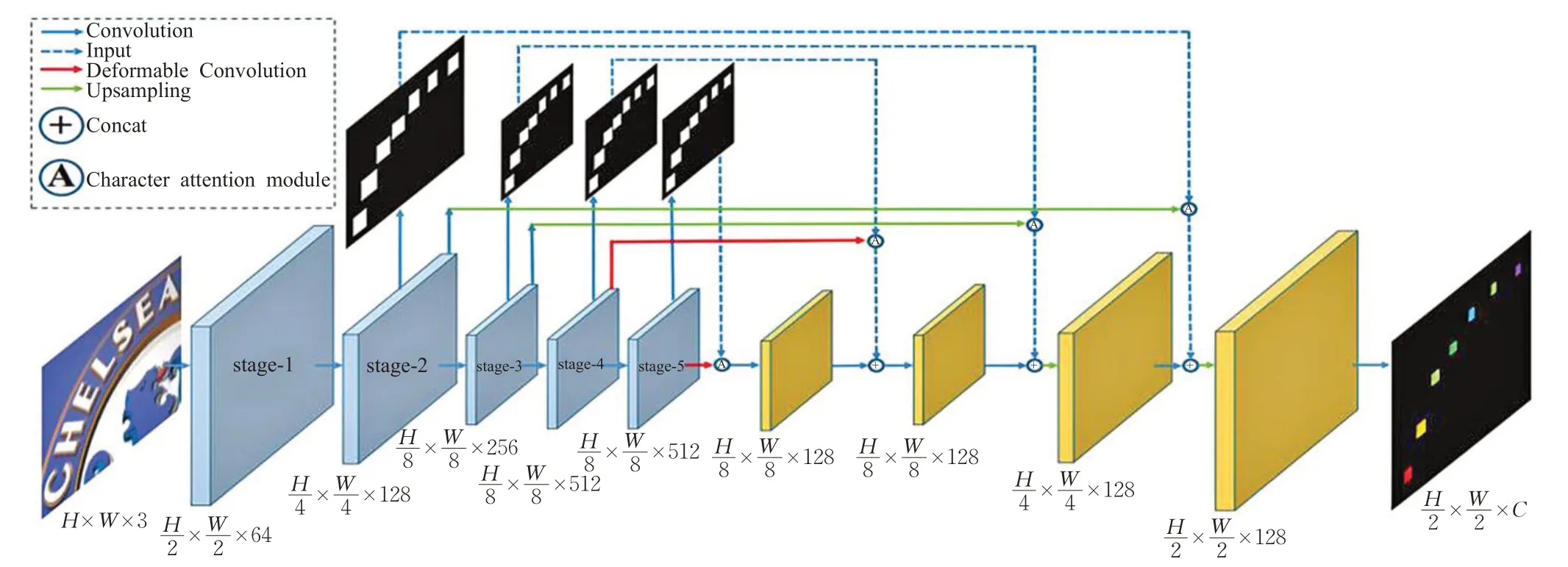
图18 CA-FCN网络图

图19 FACLSTM网络图

表3 文本识别网络对比
3.4 端到端场景文字检测与识别网络
(1)STN-OCR网络
STN-OCR[58]网络将检测和识别集成,可以进行端到端的文本识别。该网络使用半监督的方式进行训练,无需标注文本位置信息,整个系统可进行端到端训练,在检测阶段利用空间变换器对输入图像进行特征映射,并对该特征映射应用空间变换(倾斜、旋转等),产生输出特征映射及采样网格;在识别阶段,将提取的文本图像送入识别网络中获得识别结果。但是该网络不能完全检测出图像中任意位置的文本且算法难以训练。其结构如图20所示。
(2)FOTS网络
FOTS[59]网络是端到端的快速文本定位网络。FOTS网络通过CNN 学习通用特征,并将特征在文本检测和识别网络之间共享;引入了RoIRotate 将文本检测和识别统一为端到端网络。该网络的结构可分为四部分:卷积共享、文本检测分支、RoIRotate 操作、文本识别分支。但是该网络文本识别分支中使用RNN 关注模块,导致在顺序计算中效率较低,尤其是在预测长文本时,而且只能对常规文本实现检测。结构如图21所示。
(3)MORAN网络
MORAN[60]网络是为了解决任意形状的文本识别而提出的。MORAN 分为两部分:矫正网络MORN、识别网络ASRN。该网络使用了像素级弱监督学习机制,降低了不规则文本的识别难度;训练过程中无需字符位置或像素级分割的信息,显著简化了网络训练。但是该网络仍存在局限性:(1)对于字体变形角度过大的图片识别效果不好。(2)校正网络仅能对垂直方向的畸变进行变换,无法处理水平方向畸变。(3)训练难度大。其结构如图22所示。
(4)TextDragon网络
TextDragon[61]网络可以高效地识别任意形状的文本,训练时不需要字符级标注,通过可微分运算符RoISlide 将检测与识别网络融合为端到端网络。但是该网络使用单词(行级别)标注进行训练是基于分段的方法,需要维护复杂的工作流程,不适用于实时应用程序。其结构如图23所示。
(5)ABCNet网络
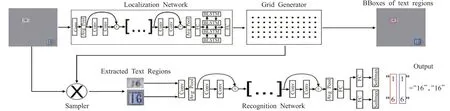
图20 STN-OCR网络图

图21 FOTS网络图

图22 MORAN网络图
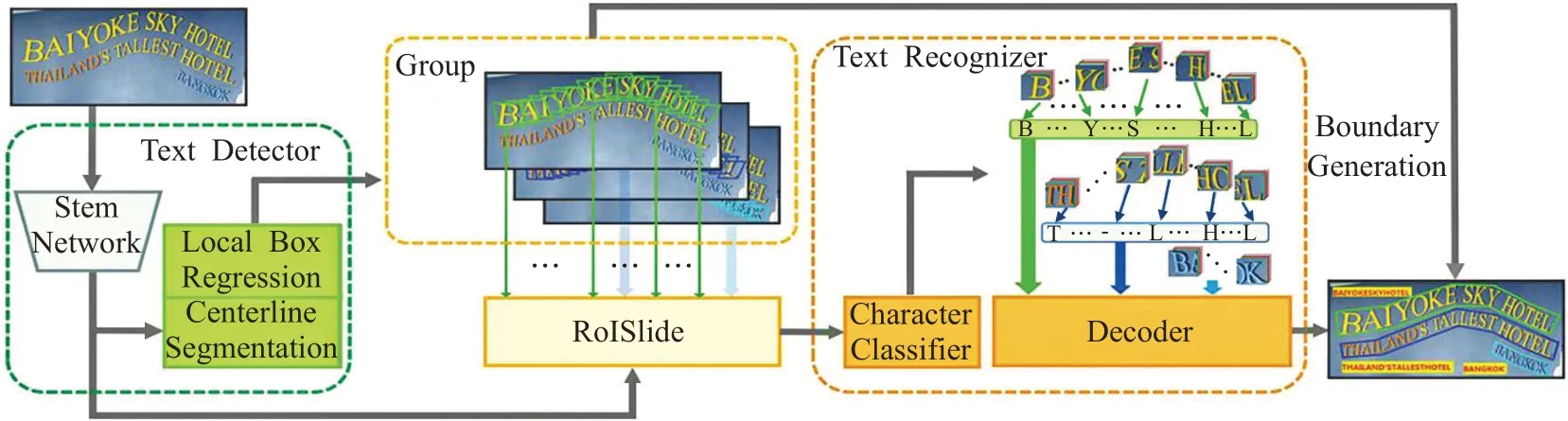
图23 TextDragon网络图
ABCNet[62]网络是一个端到端的场景文本检测识别网络。该网络首次通过参数化的贝塞尔曲线自适应拟合任意形状文本,其计算成本可忽略;其中的BezierAlign层可以准确地提取卷积特征使得识别精度显著提高。该网络由贝塞尔曲线检测分支、贝塞尔曲线Align 和识别分支两个部分组成。但是该网络用合成数据进行训练在实际较复杂场中的识别效果不好。其结构如图24所示。
端到端场景文字检测与识别网络的目标是为了从图片中定位和识别出所有文本内容。端到端网络不仅减少了计算时间和模型大小[63],而且将检测网络和识别网络融合共同训练使得模型的收敛效果更好,有效地提升了准确率。
由表4可以看出:STN-OCR网络通过集成空间变换器网络来实现端到端场景文本识别,解决了文本识别中先检测后识别的复杂步骤并且以半监督的方式训练;FOTS 网络引入了RoIRotate 将文本检测和识别结合为端到端网络,有效提高了网络的识别速度;MORAN 网络运用矫正子网络MORN对不规则文本的形状进行纠正,降低了不规则文本的识别难度但是并未彻底解决不规则文本的识别问题;TextDragon 网络运用可微运算RoISlide将文本检测和识别结合成为端到端模型,但是其在ICDAR2015[64]数据集上的效果不是最好,所以并未彻底解文本检测与识别分开的问题;ABCNet 网络通过参数化的贝塞尔曲线自适应地处理任意形状的文本,解决了基于字符的方法和基于分割的方法代价高昂、维护复杂的问题。
4 数据集
随着文本检测识别技术的不断发展,数据集的需求也越来越大。下面介绍几种公开数据集。目前的数据集分为:规则数据集、不规则数据集、多语言数据集、合成数据集等。其中不规则数据集包括ICDAR2015、SVT-P[65]、CUTE80[66]、Total-Text[67]等;规则数据集包括IIIT5K[68]、SVT[69]、ICDAR2003(IC03)[70]、ICDAR2013(IC13)[71]、COCO-Text[72]、SVHN[73]等;多语言数据集包括RCTW-17[74]、MTWI[75]、CTW[76]、SCUT-CTW1500[77]、LSVT[78]、ArT[79]、ReCTS-25k[80]、MLT[81]等;合成数据集包括Synth90k[82]、SynthText[83]等。
5 场景文字识别技术研究趋势
由于自然场景中的图片存在图像模糊、遮挡、复杂背景干扰,图片中的文字有变形文字、不规则文本、曲线文本、多种形状等问题使得场景文字识别技术面临较多挑战。近年来场景文字识别技术发展迅速,在ICDAR2015不规则数据集上识别准确率从59.2%提升到83.7%,在具有识别难度的规则数据集SVT 上识别率从80.7%提升到92.7%,但是仍然需要深入研究。
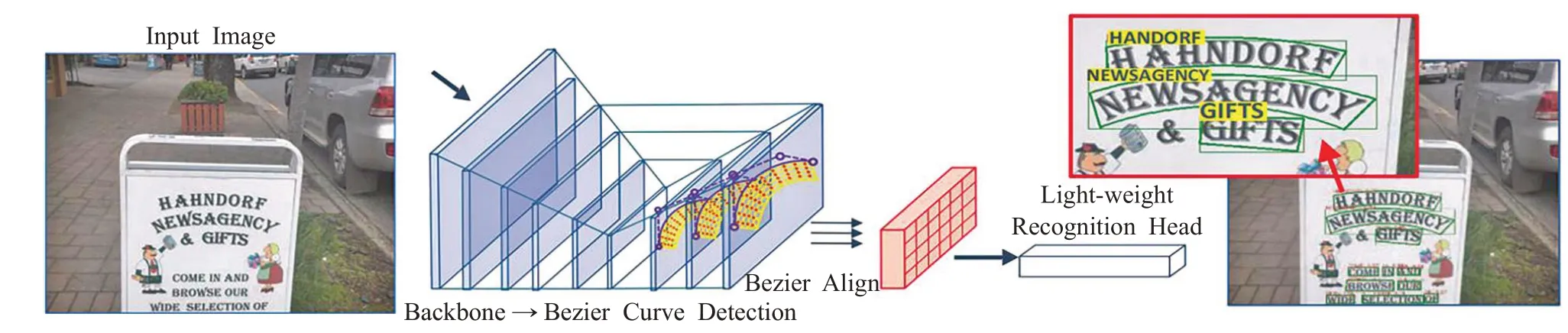
图24 ABCNet网络图

表4 端到端文本识别网络对比
(1)多语言结合的场景文本识别。我国是一个统一的多民族国家,文字种类丰富,目前的识别网络主要是基于中文或英文,对于多语言混合的文本的通用识别网络较少,虽然E2E-MLT[84]网络实现了多语言的识别但是其F 指数只有48%,难以满足实际需求,所以多语言混合的文本识别是一个较大的挑战,也是未来的研究重点。
(2)多行文本、曲形文本端到端识别。由于多行文本和曲形文本的弯曲分布使得很难用普通的文本框去检测,但目前出现的ABCNet网络虽然可以对曲线文本进行检测但是其F指数只有61.9%,所以多行文本、曲形文本的端到端识别仍是很有挑战性的问题。
(3)实时文字识别。随着互联网的迅速发展,网络安全问题日益突出,文字识别技术是信息过滤的基础,但是目前识别精度高的算法网络结构复杂、运行时间长、不能满足实时过滤的要求,所以如何构建轻量级模型,实现实时文字识别仍有待解决。
(4)无约束场景文字识别网络鲁棒性研究。尽管目前的场景文字识别网络已经有较好的识别效果,如Luo等[85]在SVT-Perspective数据集上的准确率达到95.5%,Qi等[86]在IIIT5K 数据集的准确率为99.6%。但是对于复杂的情况其鲁棒性较差,如小尺寸区域文字识别、噪音严重和光照不均匀的图片文字识别等。
(5)自然场景汉字识别。汉语作为中国通用语言、国际通用语言之一,研究汉字识别意义重大。目前的印刷体汉字识别率已达到98%,可以满足实际应用需求,但是自然场景中的汉字识别由于存在相似字、背景复杂等问题使得识别效果不理想,故汉字识别将是未来研究的重点。
(6)数据集及字符级标注。目前的识别网络主要是基于中英文的,主要原因在于其他语言文本公开数据集较少或没有,如目前尚无公开的维吾尔语数据集,但是可以利用GAN[87]进行数据生成,但该网络无法直接处理形变文字,所以仍可作为未来的研究重点。
另外目前的公开数据集缺乏字符级标注,但是可以运用弱监督或半监督的方式在单词级或句子级的数据集上训练出字符级模型,如WordSup[39]网络、TextDragon[61]网络、STN-OCR[58]网络、MORAN[60]网络、CharNet[88]网络、CRAFT[89]网络等。
WordSup网络在文本行、单词级标注数据集上训练出字符级检测模型;STN-OCR 网络训练时只需要提供文本标签,而不要求文本位置信息;MORAN 网络训练过程中不需要字符位置或像素级分割的监督信息;CharNet网络开发了迭代字符检测方法使用合成数据生成真实数据上的字符级标注;TextDragon网络训练时使用单词级别或行级别的标签;CRAFT 网络主要通过合成的数据集具有字符级别的标注,检测合成产生标签再进行训练并借助文本行长度确定置信度实现单个字符的标注。
由以上各种网络的弱监督训练方式对比可知,未来解决数据集缺乏字符级标注问题的研究重点为:(1)在单词级标注数据集上训练出字符级检测识别模型。(2)使用合成数据生成真实数据上的字符级标注。(3)利用数据集提供的文本内容标签,无需文本位置信息,实现网络训练。
6 结束语
首先说明了场景文字检测与识别算法的研究背景和识别难点,其次说明了场景文字识别的处理过程,然后介绍了常用的目标检测方法和文本检测方法;接着介绍了常见的场景文字识别算法和端到端检测与识别算法,并对各类算法总结了其优缺点、适用场景、实现成本等;最后介绍了常用的公开数据集,并探讨了未来发展趋势和可能的研究重点。随着人工智能的快速发展,自然场景图像中的文字检测和识别技术在自动驾驶、网络安全、地理定位、智能交通等领域将会受到越来越多人的青睐,虽然文字识别技术目前仍存在较多问题,但是随着对文字识别技术的深入研究,以及深度学习技术的进步,未来一定能解决这些问题。
