基于MEM和HMM的中文词性标注方法*
2020-09-14莫礼平胡美琪李航程
周 潭,莫礼平,胡美琪,李航程
(吉首大学信息科学与工程学院,湖南 吉首 416000)
词性标注(Par-of-Speech Tagging,POS Tagging)就是赋予每个词语一个正确候选词性的过程,它是自然语言信息处理研究的重要内容.2015年,梁喜涛等[1]对现有词性标注方法进行了分析整理,将传统的词性标注方法归纳为3类:(1)基于规则的方法.该类方法简单,易于实现,但构造规则是一项非常艰难的任务.(2)基于统计的方法.该类方法客观性强,准确性较高,但需要处理兼类词和未登录词的问题.基于最大熵模型(Maximum Entropy Model,MEM)和隐马尔科夫模型(Hidden Markov Model,HMM)的词性标注方法是统计类方法的典型代表,因其能够获得一致性很好且覆盖率较高的标注结果而被广泛关注[2].(3)基于规则和统计的方法.该类方法有效地利用了规则类方法和统计类方法的优势,但标注效果依赖于建立的规则或人工的选取特征,且与任务领域的资源有很大的相关性,一旦领域变化,标注效果就会受较大影响.因此,笔者将对基于MEM和HMM的中文词性标注方法进行理论分析和对比实验.
1 基于MEM的中文词性标注方法
1.1 MEM理论
在热力学中,熵是大量微观粒子的位置和速度的分布概率的函数,用“热熵”表示分子状态混乱程度.1948年,Shannon[3]借鉴热力学的概念提出“信息熵”的概念.为了描述信源的不确定度,Shannon将信息中排除了冗余后的平均信息量称为“信息熵”,并给出了计算信息熵的数学表达式.通常,一种信息源的不确定性越大,其信息熵就越高;反之,其信息熵就越低.1957年,Jaynes[4]提出了基于概率统计的最大熵方法.最大熵方法通过将各种不同来源的信息知识聚集在一个框架下面,用以解决一些复杂的问题.1992年,Della 等[5]首次将最大熵方法应用于自然语言处理.经过近30年的发展,基于MEM的自然语言处理技术取得了令人瞩目的成果.
最大熵方法的本质就是从满足约束的模型中选择熵值最大的.利用MEM需要解决特征选择和模型选择这2个基本问题:特征选择就是选择一个能表达这个随机过程的统计特征的集合;模型选择就是参数估计或模型估计,为入选的特征集合估计权重.假设现有n个特征,约束的集合定义为
(1)
最大熵方法就是求解满足约束(1)的模型.这样模型可能不只1个,所以需要找到一个最均匀分布的概率模型.概率模型的均匀性可以用如下的条件熵来衡量:

(2)
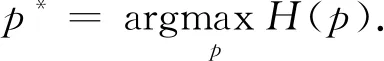
1.2 MEM在中文词性标注中的应用
最大熵方法应用于中文词性标注,需要根据上下文信息确定约束条件,从而建立MEM.基于MEM的中文词性标注方法的重点是根据中文的特殊性进行特征选取.当某一现象出现多次时,就认为该现象不是偶然的,而是表现了数据某一方面的特征.因为人工选取特征耗时耗力,所以一般是由机器自动在训练数据中寻找这种特征.特征的选取一般分为2步[6]:第1步,利用特征模板从语料中获取候选的特征;第2步,从候选特征集中选取特征.在国内的词性标注研究中,大多采用基于词的上下文特征.但汉语不同于英文,汉语的每个字一般都有其自身的意义,而英文的单个字母没有具体意义,因此在对汉语进行特征选择时考虑字的编码信息,会有助于有提高词性标注的准确率[7].
现以对文本“把这次演讲安排一下”中的“下”进行词性标注为例,说明如何将MEM应用于中文词性标注中.首先,将文本标注为“把/q-p-v-n这/t次/p演讲/v-n安排/v-n一/m-c下/f-q-v”,其中每个词后的字母代表该词所可能具有的词性.由该标注序列可知,“下”在此句子中可能有f,q,v这3种词性.用t1,t2,t3来表示这3种词性,即t1=f,t2=q,t3=v,则根据“下”的3种词性得到第1个约束条件:
P(t1)+P(t2)+P(t3)=1.
(3)
基于约束(3),即可找到词“下”的词性标注的合适模型.但满足约束(3)的模型可以有无限个,例如,M1={P(t1)=0.5,P(t2)=0,P(t3)=0.5},M2={P(t1)=1,P(t2)=0,P(t3)=0}.模型M1和M2都只做了粗略假设,没有任何的经验判断.假设当前词语的词性只有3种候选,那么最直观的合适模型就是M3={P(t1)=1/3,P(t2)=1/3,P(t3)=1/3}.在模型M3中,3种可能词性出现的概率相同,是均匀模型.同时注意到,在训练样例中90%的“一下”中的“下”的词性为t2.据此可得第2个约束条件:P(t2)=0.9.此时,还有许多的概率分布都能同时满足上述2个约束条件.在没有其他约束条件下,合理的选择仍然是概率分布最均匀的模型.即在满足上述2个约束的同时,尽可能平均分配它的概率分布:P(t1)=0.05,P(t3)=0.05,P(t2)=0.9.
2 基于HMM的中文词性标注方法
2.1 HMM理论
基于统计的方法是最常使用的一类词性标注算法.对于给定的输入词串,基于统计的方法先确定其所有可能的词性串,再对它们打分,选择得分最高的词性串作为最佳的输出结果.在所有基于统计的方法中,基于HMM的词性标注算法最常见[8].目前,HMM已应用于各种语言的词性标注并取得极高的标注准确率,基于HMM的中文词性标注方法研究也受到人们的重视.HMM是在离散马尔科夫过程的基础上改进的.它包含2个随机过程,一个是已知的观察序列,另一个是隐含的状态转移序列.状态转移序列是不可观测的,需要通过观察序列来推断[9].
为了理解HMM,先看一个实例:缸和球的实验.设有N个缸,M种不同颜色的球,每一个缸都装有很多不同颜色的球,球的颜色由一组概率分布描述.首先,根据某种随机过程选择N个缸中的某个缸,记为Z1,再根据这个缸中球的颜色概率分布,随机选择一个球,记该球的颜色为O1,并将球放回缸中;然后,根据缸的状态转移概率分布,随机选择下一个缸,记为Z2,再根据该缸中球的颜色的概率分布,随机选择一个球,记该球的颜色为O2,并将球放回缸中……如此循环,一共进行T次实验,得到缸的选取序列Z=(Z1,Z2,…,ZT)和球的颜色序列O=(O1,O2,…,OT).称可以直接观察到的球的颜色序列为观察序列,称在后台进行的缸的选取序列为隐藏状态序列.通常,HMM可用一个五元组λ=(N,M,A,B,π)来表示[9]:(1)N表示模型中隐含状态的数目.用T表示状态的集合,T={T1,T2,…,TN},t时刻的状态为Tj,1≤j≤N.(2)M表示模型中观察值的数目.用o表示观察值的集合,o={o1,o2,…,oM},t时刻的观察值为ok,1≤k≤M.(3)A表示状态转移概率矩阵.A=(aij),其中aij=P(qt=Tj|qt-1=Ti),1≤i≤N,1≤j≤N,表示状态从Ti转移到状态Tj的概率.(4)B表示符号的发射概率矩阵,它描述了HMM模型中每个状态下出现各个观察值的概率.B=(bjk),其中bjk=P(xt=ok|qt=Tj),1≤j≤N,1≤k≤M,表示在t时刻、状态Tj时观察值为ok的概率.(5)π表示初始状态概率向量.π=(πj),其中πj=P(q1=Tj),1≤j≤N,表示在初始时刻(t=1)、状态为Tj时的概率.
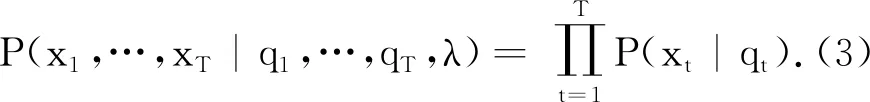
2.2 HMM在中文词性标注中的应用
HMM可以用来解决3个基本问题:第1个问题是评估问题,即根据给定的HMM求解一个观察序列的概率,可用向前算法求解此类问题;第2个问题是解码问题,即求解生成一个观察序列的最优隐藏状态序列,可用Viterbi算法求解此类问题;第3个问题是学习问题,即已知观察序列O,求解HMM的参数,可用向前向后算法求解此类问题.
词性标注问题实际上就是解码问题.将HMM应用于词性标注,那么在五元组λ=(N,M,A,B,π)中:N为词性的数目;M为词汇的数目;A为词性状态转移概率矩阵,aij表示词性从Ti转移到Tj的概率;B为词汇的发射概率矩阵,bjk表示词性标注为Tj的情况下输出词汇ok的概率;π为初始状态概率分布,πj表示初始状态词性为Tj的概率[10].HMM五元组中的参数N和M易求,故只要计算出A,B,π这3个参数值,就可利用Viterbi算法来找出最优的词性序列.
3 实验与结果
本实验采用Python语言编程实现基于MEM和HMM的中文词性标注算法,并在Inter(R) Core(TM) i5-3470 CPU @3.20 GHz、4 G内存、Win10操作系统条件下进行实验.采用北京大学加工整理的《人民日报》1998年1月份的新闻语料作为训练集和测试集.为了测试2个模型的实际标注效果,从训练的语料库中随机选取1 000行语料作为测试样本1,随机选取2 000行语料作为测试样本2.2个模型的词性标注准确率、召回率和F1这3个性能指标的比较见表1.

表1 2个模型的中文词性标注的实验结果Table 1 Experimental Results of Chinese Part-of-Speech Tagging Based on Two Models %
由表1可知,2个模型的中文词性标注都获得了一致性很好且覆盖率较高的标注效果,准确率、召回率和F1这3个指标都达到92%以上.MEM的标注效果总体上比HMM的稍佳,这与其灵活的特征机制有利于在词性标注的过程中更有效地利用上下文的信息有关.
4 结语
MEM和HMM是词性标注领域研究较多且应用较广的2个统计模型.基于MEM和HMM的中文词性标注方法具有更客观、适应性强和耗费资源少的优点,且可以通过训练更大规模的语料库来解决数据稀疏的问题.笔者分析了MEM和HMM所涉及理论、算法,并通过实验验证了2个模型用于中文词性标注的有效性,对于帮助人们更好地理解和掌握中文信息处理技术相关理论与方法具有一定的实用价值.接下来,笔者将利用MEM和HMM模型的优越性,尝试结合新型神经网络和智能优化算法对统计类中文词性标注算法进行改进.
