基于XOR 门加密的抗控制流攻击方法*
2020-09-12余云飞张跃军汪鹏君
余云飞, 张跃军,3, 汪鹏君, 李 刚
1. 宁波大学 信息科学与工程学院, 宁波315211
2. 温州大学 电气与电子工程学院, 温州325035
3. 密码科学技术国家重点实验室, 北京100878
1 引言
随着物联网、云计算和移动支付等技术的快速发展, 嵌入式系统在军事、汽车、医疗、通讯等领域得到广泛应用, 尤其是众多嵌入式系统之间网络通讯、协同处理能力也得到进一步加强. 这同时也给攻击者找到可趁之机. 攻击者可以利用软件漏洞实施控制流攻击进而对整个系统进行控制. 控制流攻击是指利用程序漏洞, 通过篡改程序控制流的存储地址或控制流数据等方式, 将程序导向并执行预先设定的恶意代码, 达到破坏系统或盗取关键信息的目的. 根据恶意代码注入与否, 控制流攻击可分为代码注入攻击和代码复用攻击. 代码注入攻击指攻击者利用软件的某些漏洞将恶意代码注入到应用程序. 堆栈溢出攻击是代码注入攻击的一种典型方式, 堆栈中写入的数据量超过堆栈本身的容量, 溢出的数据可以覆盖合法的数据, 但由于原始程序并没有做边界检查, 这就为攻击者实施溢出攻击埋下隐患. 攻击者可以利用溢出攻击覆盖原始返回地址, 将返回地址篡改为指向预先注入恶意代码的地址, 进行控制流劫持. 堆栈溢出攻击如图1 所示, 攻击者用起始地址A 覆盖堆栈中的返回地址, 进行控制流的劫持. 随着数据执行保护(Data Execution Prevention, DEP) 技术[1]的提出, 代码注入攻击被有效地阻止.
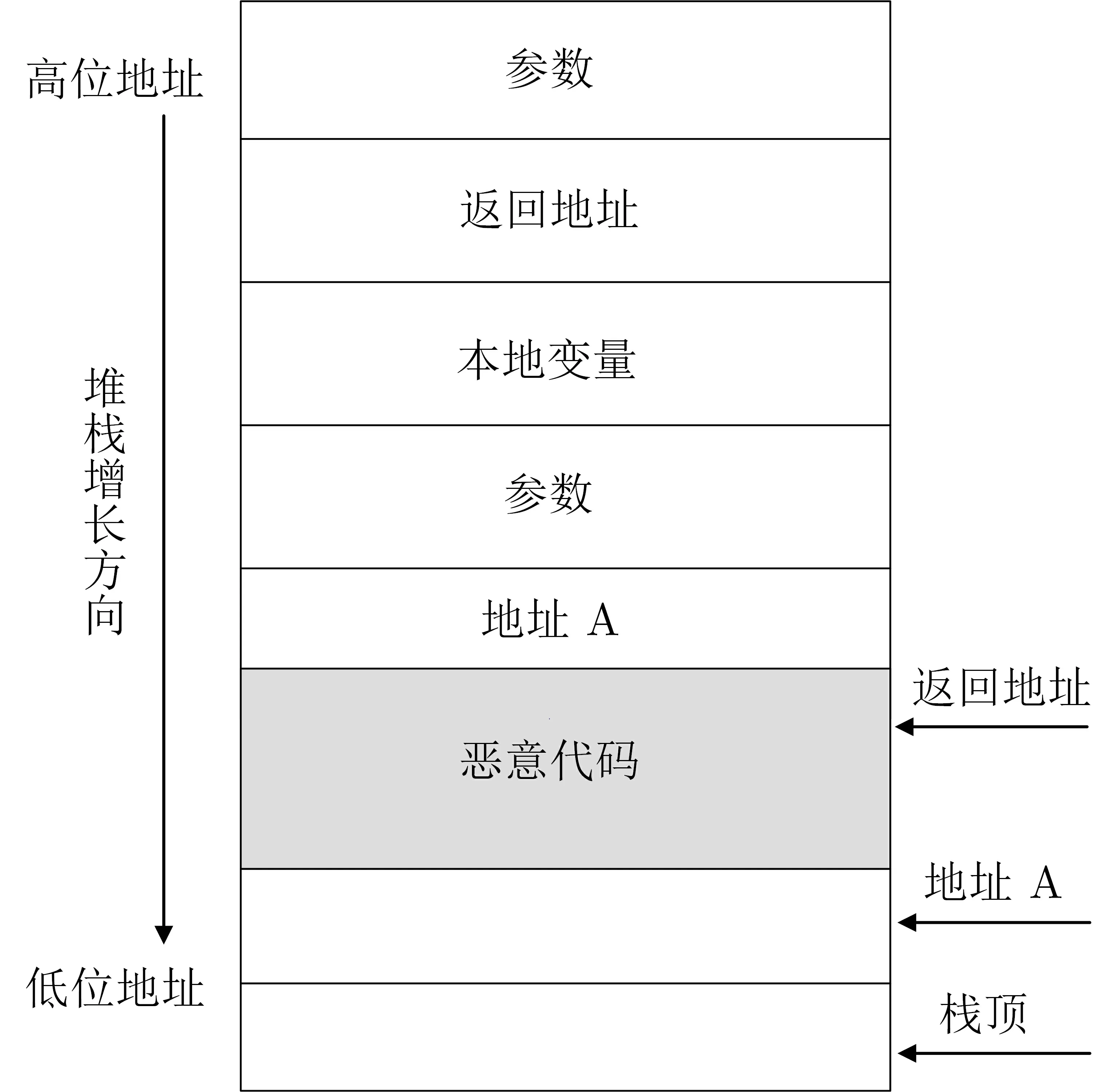
图1 堆栈溢出攻击Figure 1 Stack overflow attack
代码复用攻击则利用程序本身的代码片段去组成想要实施的恶意代码, 研究表明这种方法能够成功绕过DEP 机制, 进而实施控制流攻击——面向返回的编程攻击(Return Oriented Programming, ROP)[2].攻击者实施ROP 攻击, 不需要向内存中注入恶意代码, 仅利用程序中大量以ret 结尾的指令作为配件gadget 即可组成图灵完备的恶意代码实施攻击. 针对控制流攻击, 许多防御方法被相继提出, 本文主要考虑与硬件特性相关的方法. 文献[3,4] 提出利用控制流完整性(Control Flow Integrity, CFI) 检测异常控制流, 该方案通过线下静态分析获取目标地址白名单, 每次控制流转移时, 立即询问该地址是否在白名单中, 一旦出现目标地址不在白名单的间接跳转,就会报错并终止程序, 由此检测控制流跳转异常, 但要获取完备的目标地址白名单是很难实现的; 文献[5]通过研究ROP 对地址信息的依赖性, 在探究随机化效率的基础上, 提出一种短序列随机化的抗攻击技术, 并对随机化覆盖率的特性进行剖析, 解决了如何提高随机化覆盖率问题, 但是攻击者可以利用内存泄露方式获得随机化后的数据进行攻击; 文献[6] 提出基于异常控制流识别的漏洞攻击检测方法, 能够准确检测到漏洞进行攻击, 并可作为漏洞利用攻击的实时检测方案,而由于此方案需要扩展指令集, 可能造成指令集不兼容问题; 文献[7]针对ROP 攻击提出采用指令集随机化的防御策略, 在指令末端数据中设定多寄存器并在数据范围内随机分配寄存器数据, 达到防御ROP 攻击的目的, 但由于间接跳转指令的识别, 如无法正确识别目标指令就不能保证随机化后的正确性; 文献[8]提出上下文控制流完整性检查, 利用intel CPU 中的LBR(Last Branch Record, LBR)机制, 每当程序要执行重要的系统调用时对LBR 中保存的先前的跳转指令进行CFI 判断, 若全部符合, 则继续执行, 若不符合控制流图, 跳转则停止执行并报错, 有效地检测出控制流的非法转移, 但由于检测粒度不够细, 攻击者可通过构造栈和选择函数实施攻击; 文献[9] 提出利用Intel 处理器跟踪的硬件机制, 结合虚拟技术对内核模块进行控制流完整性检查, 对防御ROP 攻击具有极强的保护精确性, 兼容性和效率, 但是生成完备的内核模块控制流图非常困难, 并且由于细粒度的控制流完整性检查, 将会引入很大的性能开销; 文献[10] 提出一种基于异常控制流识别的攻击检测方法, 该方法通过构建完整的安全执行轮廓, 并限定控制流转移的合法目标, 来识别异常控制流转移, 而构建完整的安全执行轮廓十分困难, 若不能构建完整的安全轮廓, 将会导致攻击误报问题; 文献[11] 在分析增强内容敏感和字段敏感指针的基础上, 提出细粒度的控制流完整性检测方法, 保证操作系统内核完整性, 细粒度检查要求严格控制每一个间接转移指令的转移目标, 将会引入过大的性能开销; 文献[12] 提出控制流完整性监视保护, 它是一种粗粒度控制流完整性检查方法, 关键思想是以可变大小的块指令动态地限制间接分支仅定位程序块的第一条指令, 而粗粒度CFI 则是将一组类似或相近类型的目标归到一起进行检查, 由于检查粒度不够细, 攻击者依然可以利用精心设计的指令配件绕过防御机制实施攻击; 文献[13] 提出一种新的硬件辅助CFI 框架, 该框架使用功能标签方法和有效标签的状态模型来实施细粒度CFI 策略, 然而细粒度的检查将会引入过大的开销; 文献[14] 提出一种基于加密消息认证码, 保护控制流元素并通过动态检查阻止所有已知的攻击, 实质上此方案也属于粗粒度CFI 检查, 攻击者依然可以利用配件绕过此防御机制; 文献[15] 提出利用影子栈和片内安全存储区等硬件实现功能齐全的CFI 指令集架构, 进而防御控制流攻击, 而由于此方案需要对指令集修改, 将会导致指令集不兼容等问题.
综上, 针对以上硬件防御手段或存在开销大或安全性低, 亦或指令集不兼容等问题[16,17], 本文采用硬件开销较小的XOR 门加密电路和内置安全寄存器组对返回地址加密及存储. 如此, 既不会带来过大的开销, 也不会引入新的指令集.
2 XOR 门加密抗控制流攻击
鉴于现有抗控制流技术存在的问题, 提出一种基于XOR 门加密的抗控制流攻击方法, 电路结构框图如图2 所示. 攻击者实施控制流攻击必须篡改堆栈中的返回地址, 为了防止攻击者修改堆栈中的返回地址且不带来过大的硬件开销, 引入XOR 加密电路对返回地址进行加密处理, 当指令译码结果为程序调用指令call 时, 返回地址不会被直接压入到堆栈中, 而是经过XOR 加密电路加密. 为了检测加密后的返回地址是否被攻击者修改, 需要对加密后的返回地址进行存储, 因此引入内置安全寄存器组(Build-in Security Register Bank, BSRB) 存储加密后的返回地址. 加密的返回地址被同时压入堆栈和内置安全寄存器组中,当指令译码结果为程序返回指令ret 时, 堆栈和内置安全寄存器组中的加密返回地址则要经过XOR 解密电路后送入地址比较器, 通过返回地址比较结果检测系统是否受到控制流攻击, 若受到攻击, 立即触发reset 信号翻转为有效电平使系统重新初始化, 停止程序继续执行.
2.1 XOR 加/解密返回地址

图2 抗控制流攻击结构框图Figure 2 Diagram of defending control flow attack
为保护返回地址不被篡改, 引入XOR 门加/解密电路对返回地址进行加/解密. 正常情况下, 当系统执行程序调用指令call 时, 下一条指令的地址会被压入到堆栈中, 当执行程序返回指令ret 时, 系统会从堆栈中取出返回地址, 继续执行下一条指令. 为防止攻击者利用软件漏洞去篡改堆栈中的返回地址, 进而实施控制流劫持, 引入XOR 门加密电路. 当执行调用指令call 时, 返回地址A 不会被直接压入到堆栈中, 而是经过XOR 加密电路与密钥K 异或加密. 密钥K 则是由伪随机数发生器生成的16 位随机数并存储在专门的密钥寄存器中, 并经过DesignCompiler 综合, 在TSMC 65 nm CMOS 工艺下平均功耗为0.187 mW, 关键路径延时为2.0 ns, 产生的随机数可以通过NIST 测试. 如图3(a) 所示, 堆栈中压入的是经过XOR 加密电路加密的返回地址(K ⊕A); 当执行程序返回指令ret 时, 堆栈中的返回地址则要经过XOR 解密单元, 如图3(b) 所示, 出栈的返回地址为K ⊕A ⊕K). 攻击者如果篡改堆栈中加密过的返回地址, 当其从堆栈中取出时, 须经过XOR 解密单元, 由于攻击者篡改的返回地址没有经过XOR 加密单元,攻击者想要执行指令的地址A 将被解密电路导向地址(K ⊕a) 由于K 未知继而攻击失败.
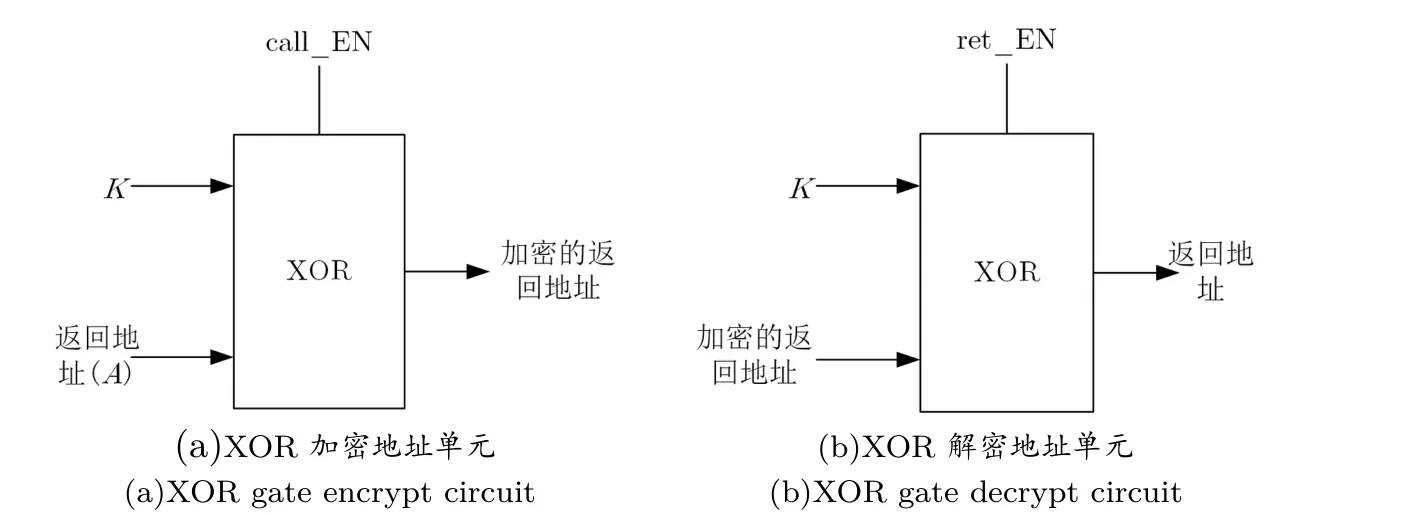
图3 XOR 门加/解密电路Figure 3 XOR gate encrypt/decrypt circuit
2.2 存储加密返回地址
图4 为提出的内置安全寄存器组, 用于存储加密后的返回地址. 攻击者实施控制流攻击的基础就是在系统执行调用指令call, 返回地址被压入到堆栈后, 对堆栈中的返回地址通过缓冲区溢出的方法进行篡改.为了检测堆栈中加密后的返回地址是否被篡改, 引入内置安全寄存器组备份加密返回地址. 内置安全寄存器组实质上是一个特殊的堆栈, 用于专门存储加密的返回地址和保护其不被攻击者覆盖. 该寄存器组中的加密返回地址只能通过调用指令call 和程序返回指令ret 写入和读取, 而其他指令禁止访问.
3 方案实施
为验证所提方案的有效性, 使用硬件编程语言verilog 分别在oc_8051 处理器与ARM6 处理器的取指、译指及执行阶段加入XOR 加解密电路和内置安全寄存器组及地址比较器, 实现具有防御控制流攻击功能的处理器.
3.1 抗控制流攻击的处理器硬件架构
图5 为本方案在处理器取指、译指、执行阶段加入XOR 地址加解密单元和内置安全寄存器组及地址比较器架构框图, 检测处理器是否受到控制流攻击步骤如下.
步骤1: 指令译码结果为程序调用指令call 时, 触发伪随机数发生器产生密钥K 存储到密钥寄存器中;
步骤2: 将返回地址送入XOR 加密单元进行加密处理;
步骤3: 将加密后的返回地址同时送入压入堆栈和内置安全寄存器组;
步骤4: 指令译码结果为程序返回指令ret 时, 同时弹出堆栈和内置安全寄存器组中的加密返回地址,并送入到XOR 解密单元, 将加密的返回地址进行解密处理;
步骤5: 在执行阶段, 将从堆栈和内置安全寄存器组中弹出的解密后返回地址送入到地址比较器;
步骤6: 若地址比较器结果相同, 则继续执行程序, 反之则停止执行程序.

图5 抗控制流攻击处理器的架构Figure 5 Architecture of defending control flow attack processor
3.2 抗控制流攻击的处理器工作过程
抗控制流攻击处理器具体工作流程如图6 所示. 处理器工作过程分为五个阶段: 取指、译指、执行、访存、写回. 当处理器处于译指阶段时, 指令译码结果为call 指令时, 即子程序开始调用. 处理器将触发随机数发生器产生密钥K 存储到密钥寄存器并将返回地址送入XOR 加密单元进行加密, 加密过后的返回地址被送入到堆栈和BSRB; 指令译码结果为ret 指令时, 即子程序调用结束. 处理器将同时弹出BSRB和堆栈中的加密返回地址并送入到解密单元, 并将解密的返回地址送入地址比较器进行比较. 若比较结果相同则程序继续正常执行, 反之则停止执行. 若攻击者篡改堆栈中加密后的返回地址进行劫持控制流, 则篡改后的返回地址出栈后必须强制经过解密电路, 由于篡改后的地址未经过加密, 最终出栈的返回地址并非攻击者想要执行指令的地址, 控制流攻击则失败. 在攻击者无法获取密钥K 时此方案是安全的, 但若攻击者同时覆盖堆栈和BSRB 中的返回地址, 由于XOR 解密单元的存在, 攻击者想要执行的指令地址依然会被强制解密, 攻击依旧失败, 只是系统不会做出异常处理, 而是继续执行其它地址处的指令.
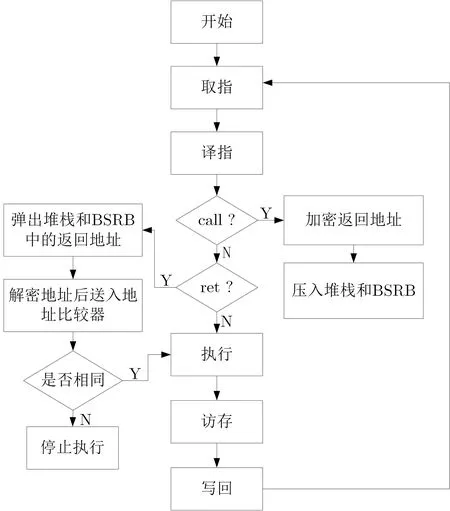
图6 抗控制流攻击的流程图Figure 6 Process of defending control flow
4 实验结果与安全性分析
为验证方案的有效性, 进行gadget 消除与逻辑综合以及波形仿真等实验, 实验环境包括: Intel Xeon(R) Dual-Core CPU 2.0 GHz、6 G RAM 服务器, 涉及的工具软件包括: ROPGadget-master5.4、Pin2.14、NClaunch 以及DesignCompiler.
4.1 安全性分析
攻击者若要实施控制流劫持进行ROP 攻击, 必须有大量可用的以ret 为结尾的指令片段作为配件gadget 组成恶意代码, 因此减少可被利用的gadget 数目就能降低攻击者劫持控制流的可能性. 通过加解密电路, 使堆栈中的攻击者篡改后的地址经过解密指向不是以ret 为结尾的指令片段处, 进而减少可被攻击者使用的gadget. 但是由于提出的防御机制是在调用指令call 和程序返回指令ret 控制下加解密返回地址, 若加密后的gadget 地址恰好是间接跳转指令jmp 或间接调用指令call 的目标地址, 则此gadget依然可被攻击者使用, 进而实施攻击. 为了得到gadget 消除率, 首先使用ROPGadget-master5.4 工具扫描测试程序, 获得测试程序中的gadget 的总数, 然后用Pin 提取测试程序的间接跳转指令jmp 及间接调用指令call 的目的地址, 最后在二进制代码翻译工具Pin 框架下实现此方法, 并提取此方案加密后的gadget 地址. 若一个gadget 地址加密后恰好是间接跳转指令jmp 或间接调用指令call 的目的地址, 则此gadget 可以被攻击者利用, 统计此gadget 数目, 得到gadget 消除率. 基准测试程序在本方案中的gadget消除率, 如表1 所示. 其中5 个程序属于RIPE 测试程序, RIPE 里面包含了850 个缓冲区溢出攻击程序.实验结果显示gadget 平均消除率为99.52%, 结果表明此方法可以有效防御控制流攻击.

表1 Gadget 消除率Table 1 Gadget elimination rate
4.2 硬件开销
表2 与表3 是通过修改oc_8051 处理器和ARM6 处理器的源代码加入XOR 加解密电路与内置安全寄存器组以及地址比较器后的硬件开销, 使用DesignCompiler 综合获得面积、功耗和延时. 结果显示在TSMC 65nm CMOS 工艺下oc_8051 处理器面积和功耗分别增加5.10% 和6.06%, ARM6 处理器面积和功耗分别增加5.25% 和6.3%, 与文献[18] 相比, 此方案硬件开销减小了22.95%, 大大减小了硬件开销.

表2 oc_8051 处理器硬件开销情况Table 2 Overhead of oc_8051 processor

表3 ARM6 处理器硬件开销情况Table 3 Overhead of ARM6 processor
4.3 仿真波形
图7 为当堆栈中的返回地址与内置安全寄存器组中的返回地址不同时, 使用NClaunch 获得的波形图.

图7 仿真波形Figure 7 Simulation waveform
CLK 为时钟信号, INT 和INT_V 分别为中断信号和中断向量, RES 和RETI 分别为比较地址信号和中断返回信号, ROM 为指令存储地址. 当ret 指令执行时RES 为0, 返回地址比较结果不相同, 证明堆栈中返回地址遭到篡改.
5 总结
本文首先利用XOR 门加密电路对返回地址进行加密, 然后将加密后的返回地址同时压入内置安全寄存器和堆栈, 最后将解密后的返回地址送入地址比较器, 根据返回地址比较结果实现检测和防御控制流攻击的目的. 实验结果表明本方案在TSMC 65 nm CMOS 工艺下gadget 平均消除率高达99.52%, 面积和功耗最大分别仅增加了5.25% 和6.3%. 应该说明的是该方法仅局限于防御ROP 型与代码注入型控制流攻击, 无法防御面向跳转的编程攻击型(Jump Oriented Programming, JOP) 控制流攻击和拒绝服务攻击.
