基于三维深度卷积神经网络的车间生产行为识别
2020-09-10刘庭煜孙毅锋何必秒
刘庭煜,陆 增,孙毅锋,刘 芳,何必秒,钟 杰
(1.南京理工大学 机械工程学院,江苏 南京 210094;2.北京航天新风机械设备有限责任公司,北京 100854)
0 引言
随着信息技术和制造技术的发展,智能制造已经成为制造模式转型与升级的必然趋势。在智能制造模式下,生产车间的工人数量不断减少,然而即使在自动化程度极高的汽车生产制造领域,仍然有20%的工作由工人参与完成[1]。工业机器人或者其他生产要素通常在安装完毕后便具有相对独立的活动空间和工作区域,但现场工人的活动范围往往遍布整个生产区域,并不局限于其所在的工位。鉴于此,作为生产管理的重要元素,人员具有极强的不可替代性和不确定性,是生产过程的重点监管对象之一。因此产品生产制造过程中的人员行为管理将成为长期研究的热点[2-3]。然而由于工人活动的多样性和不确定性,生产车间人员行为管理已经成为整个生产管理中的重要内容。
使用科学有效的方法对工人的行为进行记录、理解和分析,一直是生产管理的重要研究方向。科学管理之父和工业工程之父泰勒(Taylor.F.w,1856-1915)通过使用相机记录并量化计算工人的劳动行为和劳动时间,制定了标准操作方法和时间定额,开创了分析生产动作的先河。随后,吉尔布雷思夫妇改进了泰勒的工作研究并发明了“动素”的概念,他们将人的生产动作归纳成17个动素,通过分析每一个作业需要的时间对动作进行分解和定量研究[4]。时至今日,人员行为管理已历经百年发展,但由于人员行为的高度时效性和不确定性,有效的管理手段仍然是用摄像机记录人员行为,并指定专人目视监控。然而,生产车间通常范围较广,某些复杂机电产品的关键生产工位较多,同时对大量监控图像进行实时观察令监控人员应接不暇,难以全局全时高效管控。以项目合作单位为例,为防止在某火工品装配过程中发生暴力敲打或使用通讯设备等违规行为,避免安全事故,在多个大型装配车间部署了一百多个高清防爆摄像头,但是1个专职监控人员通常只能监控10个画面,无法处理大量摄像机产生的海量视频数据。因此,该系统难以进行全面实时监控,只可用于事后追责。
近年来,借助计算机强大的数据分析和数字图像处理技术,生产车间的人员行为观测逐渐由人员主动观测和识别向基于计算机视觉的智能人员行为识别转变[5-7]。早期研究主要通过光流法或隐马尔可夫模型选定图片中的特征点[8-10]来识别人员行为,也有研究[3]基于深度学习算法识别RGB图片来判断车间生产单元的工人行为,辅助控制工业机器人协助工人作业,提高生产效率。然而上述方法主要是基于常规的二维RGB图像识别算法,计算机在处理平面图像中人员的关节或躯干时极易出错,识别效率和效果较差。
随着Kinect等低成本深度视觉传感器的商用化,可以大量布置深度传感器来获取生产现场三维点云数据,并通过实时高效分割人体躯干和关节获取人员骨架姿态的结构化数据,使得人员行为识别领域取得了长足进步[11-16]。Rude等[1]基于Kinect采集自然状态下的车间工人行为,利用半监督学习算法对工人行为进行分类,可以较为准确地识别工人行为,将该方法应用于生产线节拍平衡可以使生产高效稳定。
基于深度视觉的人体行为识别的本质是对不定长的人员姿态序列进行识别和分类,目前多采用基于隐马尔可夫模型(Hidden Markov Model, HMM)或循环神经网络(Recurrent Neural Networks, RNN)的算法[5,11,13,15]构建基于时间序列的动态模型。在RNN模型中,由于前层梯度来自于后层梯度的乘积,随着模型深度的增加会产生梯度消失或者梯度爆炸,导致模型不稳定。为避免此类问题,国内外一些学者提出将时序的人员行为转换为行为特征图像的方法[6-7],从容将基于时序的人员行为识别问题转换为图像识别问题,利用图像识别算法对时序行为特征图像进行特征提取,进而实现基于时序特征的人员行为识别。Ke等[6]利用人体主要关节点之间的距离构造灰度图片,通过迁移学习的方式微调VGG19图像识别网络对构造的灰度图片进行识别,得到了良好的效果;Du等[7]将每个关节点x,y,z3个坐标轴的坐标值分别置于彩色图片的RGB 3个通道中,通过建立卷积神经网络对图片进行识别来识别人员行为。
针对车间生产行为识别问题,本文基于三维骨架的行为特征和基于卷积神经网络的RGB图像识别方法结合,提出一种基于三维深度卷积神经网络(3D-Deep Convolutional Neural Network, 3D-DCNN)的人体行为识别方法,对人员行为进行时间序列像素化并构造人员行为时空特征RGB图像,在此基础上训练深度卷积神经网络,通过对构造的人员行为特征图像进行识别和分类来有效识别人员行为。
1 车间人员行为识别系统总体方案
在生产作业车间尤其是一些易燃易爆危险产品的生产装配车间中,为了保证安全生产,需要对生产过程中的人员行为进行管控。在这些危险品的生产装配过程中,虽然工人的行为都有一套严格的生产行为规范,但是仍有部分员工无法按照制定的工艺流程标准操作规范进行操作,其中不乏一些具有多年生产经验的老员工。为了减少乃至杜绝由此造成的生产安全事故,本文根据生产现场情况设计了一套能够对危险火工品车间中的人员行为进行识别的方案,以此对车间人员的生产行为进行智能监控。图1所示为该系统的总体设计方案。

由图1可知,本文对人员生产行为的识别过程由行为数据获取、行为数据预处理、识别模型构建和行为识别与评估4部分组成。
(1)行为数据获取 鉴于骨架序列模型能够简洁明了地表达人体的运动和行为,本文将基于骨架序列模型获取人体行为数据,并对其进行预处理和行为识别。文中涉及的行为数据有两个来源:①MSR-Action3D公开行为数据集,该数据集使用KinectV1采集20种人体基本行为,其中骨架序列由人体20个关节点的坐标信息构成;②自建生产行为数据集NJUST3D,该数据集基于火工品生产过程常见行为构建的行为数据集,该数据集使用KinectV2采集18种生产行为,其中骨架序列由人体的25个关节点的坐标信息构成。
(2)行为数据预处理 采集到的人体骨架序列原始数据与理想行为数据之间存在较大偏差,这些偏差主要由KinectV2对人体关节的识别精准度和数据采集过程中实验人员的体态、距离等多方面原因造成。为此,本文设计一套人体行为数据预处理方法,对人体的骨架序列进行标准化预处理,将各个状态下的人员行为数据统一到相同标准中,消除了由个体差异导致的识别误差。
(3)识别模型构建 基于标准化后的人体骨架姿态数据构建人员行为时空特征RGB图像,藉此构建深度卷积神经网络,对人员行为特征进行识别和分类。
(4)行为识别与评估 本文分别使用MSR-Action3D行为数据集和NJUST3D数据集对上述方法进行实验验证,并基于实验结果进一步分析行为数据模型,提出目前存在的问题和需要改进的方向。
2 基于三维骨架信息的行为数据预处理
本文以KinectV2深度传感器作为数据采集设备,配合Kinect for Windows SDK提供的应用程序接口(Application Programming Interface, API),实时获取检测区域的人员骨架关节位置信息。然而,由于Kinectv2设备的识别准确率和工人个体差异等原因,导致这些未经处理的行为数据存在异常,包括将环境中的物品(机床、工作台等)识别成车间工人,或者因工人的体态差异而产生不同的行为识别结果,因此需要对采集到的行为数据进行标准化预处理。鉴于人体骨架为一刚性的铰链结构,其骨架长度不变,本文通过骨架关节向量重构的方式对人体骨架信息进行标准化处理,剔除行为数据中的异常值,消除因个体之间差异导致识别异常,保证最终模型的输入为相对标准的行为数据。
KinectV2获取的数据为人体骨架关节数据,共包括25个关节位置坐标,如图2所示。每个关节及其对应关系如表1所示。


表1 关节标号对照表
2.1 人体行为的向量表达
使用三维骨架数据对人体行为进行数字化表示,其本质是提取图片中人员骨架关节点的位置信息来描述人员行为。通过Kinectv2深度传感器及其开发工具包能够自动捕获人体25个关节点的三维坐标,本文用这25个关节点的三维坐标构造75维向量,作为单帧图片中行为的特征向量。用frameData表示该特征向量,
frameData={x1,y1,z1,…,x25,y25,z25}。
式中x1,y1,z1,…,x25,y25,z25分别为人体25个关节的位置坐标,遵循笛卡尔直角坐标系,坐标轴以Kinect为坐标原点,X轴为水平坐标轴,Y轴垂直向上,Z轴为深度摄像头的红外光轴方向。
通常仅依靠单帧图片对人体行为进行描述会遗漏许多重要的信息,而使用由多帧图片构成的连续动作来描述人体行为则会更加可靠。因此,本文将多个单帧的行为特征向量frameData按照时间先后进行组合,构造了用来表示连续动作的人体行为特征向量actionData:
式中m为一组行为包含的图片帧数。
2.2 骨架异常值的剔除
使用Kinect获取到人员骨架的关节原始数据后,需要剔除行为数据中的异常值。本文采用Kinect设备内置的人体关节识别算法提取骨架关节位置数据,使用过程中发现该算法的准确性不够,经分析,所采集的人员骨架关节位置信息主要存在以下两个问题:
(1)人员识别准确率不高,在采用Kinect进行人员行为检测时,可能会将周边的物体(如桌子、椅子等)错误识别成工人。鉴于周边物体相对静止不动的特征,若发现识别后的行为数据始终保持不变,则将其当作误检数据进行剔除。
(2)由于检测距离、方向等原因导致Kinect设备对人员骨架关节位置进行检测时出现错乱,主要表现为局部错乱和整体错乱。局部错乱(如图3a)指身体的某些部位突然变长或变短,导致身体比例不协调,会对人员特征提取产生较大影响;整体错乱(如图3b)指整体骨架关节位置整体识别错乱,导致无法识别出人员各个关节的位置。对于人员的局部错乱,采用骨骼位置向量重构的方法,在对骨骼关节位置进行标准化的同时重构所有重要关节点的位置,得到一个统一的方向向量;对于整体错乱的骨骼关节,则通过计算重要的关节长度来设置检测阈值(例如膝盖到脚踝的正常距离为40 cm,设置阈值上限为60 cm,若超过该长度则将其作为异常值剔除)来排除明显的异常值。

人体骨架可以看作为一个刚性的铰链结构,其骨架长度在人员活动过程中保持不变,可以用两点之间的欧式距离lenthi_j表示人员两个关节点之间的长度,
i,j∈[1,25]。
(1)
式中i和j表示关节点的标号,若标号为某一骨骼的两端,则表示骨骼的长度(lenth18_19表示左边小腿的长度),否则表示两关节点的距离(lenth2_10表示右肘到脊柱的距离)。
在正常行为中,人员左右半肢的臂长和腿长信息均为对称,若深度摄像头误将机床等信息识别为人员,则异常骨架关节信息的骨架长度大多不对称。此处将计算人员的左、右半肢长度的比例,通过设定正常值阈值剔除错误的人员骨架信息。
(2)
D值是衡量左右长度比例的一组指标,若D值大于所设定的阈值,则该帧骨架关节信息为异常信息,可以剔除该帧信息。
2.3 骨架数据标准化及向量重构
2.3.1 提取标准骨架数据
深度摄像头采集到的每一帧工人的行为数据均由25个关节点的位置数据组成。由于个体之间存在差异(高矮、胖瘦等),骨架关节数据可能不统一,这种差异在识别过程中被看做为噪音。此处对骨架关节位置数据进行标准化处理,将不同身高体态的人员数据转化为统一的标准下的数据,进而保证行为识别过程中的数据稳定可靠。
本文数据标准化参考的标准是国标中的中国成年人人体尺寸(GB 10000-88),该标准分区统计我国不同地域人体主要尺寸,这里采用18~60岁50分位人体尺寸作为衡量标准,如表2所示。

表2 人体部分关节长度标准尺寸 mm
通过该标准尺寸长度对采集到的人员关节长度数据进行标准化,从而将所有人员尺寸化归到统一长度,消除不同身高体态对人员行为识别产生的影响。鉴于Kinect深度传感器在数据采集过程中对人员手指等身体细微部分的API较少,而且这些部位的识别准确率较差,会存在较大误差,为了保证算法对人员整体行为识别的准确性,本文不对人员手指等细微关节进行标准化。
2.3.2 提取骨架方向向量
在25个骨架关节位置中,每两个关节点构成一个方向向量,用sta_di_j表示该方向的单位向量,
i,j∈[1,25]。
(3)
通过长度和方向向量计算对应关节点的方向向量
(4)
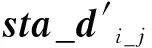
2.3.3 坐标变换
人体骨架信息的初始坐标系建立在以Kinect为坐标原点的摄像机坐标系,在数据采集过程中,人员并非始终正对传感器,因此采集的行为数据与深度传感器之间存在一定的角度偏差。为了消除此类偏差对人员行为数据采集造成的影响,以便后期图像数据处理,需要对该原始坐标系进行坐标变换,构成以人的臀中部(关节1的位置)为坐标原点,以人体正面为Z轴、Y轴垂直向上、X轴遵循笛卡尔坐标系的人体三维坐标。坐标变换如下:
(1)坐标系平移
(5)
(2)坐标旋转
(6)
式中x5,x9和z5,z9分别为左肩和右肩关节的坐标值。以人体右肩到左肩的方向向量作为新坐标系的X轴,求得坐标变换后的X轴和Z轴坐标值,进而得到坐标变换后的坐标值
(7)

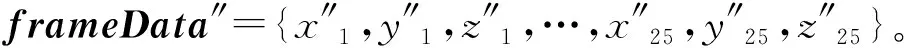
至此,经过剔除异常值、数据标准化、坐标变换和骨架关节向量重构,得到一组比较标准的行为数据。
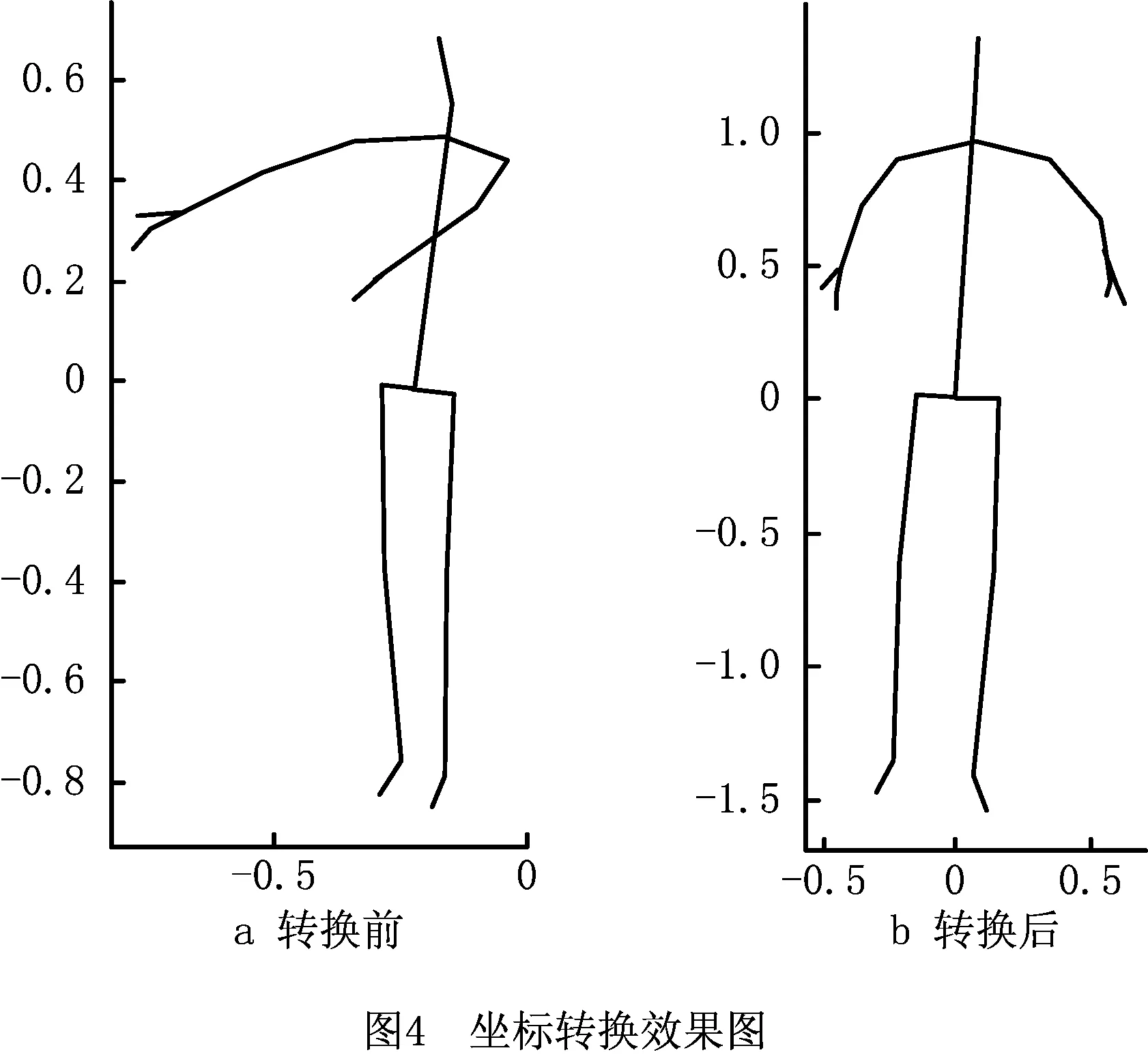
图4a所示为工人在摄像头坐标系下的骨架位置坐标,经过标准化和坐标变换后,变为图4b所示的坐标。相比可见,预处理后主要有以下变换:
(1)坐标原点图4a中坐标原点位于摄像机处,经过坐标变换后,坐标原点位于人的臀中部。
(2)人体骨骼长度对数据进行标准化后,人体骨骼的长度发生了变化。通过向量重构将人体骨骼变换为统一大小,进而将图4b变换为标准尺寸的人体骨架信息。
(3)坐标方向图4a中的人侧对着摄像机,绘制的骨架图为一个侧面。鉴于采集到的为三维骨骼信息,可以通过坐标变换绘制出图4b,X轴的方向为两肩连线的方向,并且正方向是由右肩指向左肩。
3 三维深度卷积神经网络模型的构建和算法验证
3.1 骨架序列的时空特征图形化
将人体骨架序列的行为数据转化为一张行为特征图像时,最重要的是在数据转化过程中要保留相应的数据特征不变。由2.3节可知,指定的单帧数据经过标准化预处理后,人员行为的骨架关节表示为
在实际生产过程中,对一种行为的描述需要多帧行为数据,此时用actionData″表示一组连续的骨架序列行为数据,
(1)人体骨架分组
人体的四肢和躯干在运动过程中的动作不同,分别识别各部分行为后再进行综合,能够获得更好的识别效果[11]。因此,将人体骨架按照左上肢、左下肢、右上肢、右下肢、头部和腹部分为6部分,如图5所示。

(2)行为图像构造
骨架序列图像化的本质,就是将actionData″用图片的形式表示,处理过程如图6所示。

图6中,在获得人员的RGB和深度图像信息后,通过Kinect套件内部的深度学习算法获取人体25个主要骨架关节信息和骨架位置坐标。图中Dataframe为25个关节位置坐标的向量表示。对于连续帧数为m的行为序列,分别提取Dataframe中的x,y,z分量作为转换后图形中的R,G,B 3个通道像素点的值,即:
式中Ri,Gi,Bi分别为第i帧骨架关节位置信息25个关节点位置的x,y,z轴坐标集合。不定长的连续帧行为序列像素点组合能够构造一个行为特征图片。
(3)图像数据归一化
对数据进行RGB图像合成后,由于每组行为拍摄的角度和距离不同,各图片之间存在一定差异,为了减小这种差异对图像的影响,通过归一化将与其对应的数据变换到0~1之间,同时为了更为直观地展示图像的效果,将处理后的图像进一步扩展到0~255之间,即
(8)
式中:px为单一通道单一像素点的数值;pmin,pmax分别为该通道下训练集的最小值和最大值。经过处理得到归一化后的像素值,为了便于后续模型训练,将图像调整为统一大小60×60。图7所示为图像化效果图的样例。

3.2 深度卷积神经网络识别模型的构建与训练
识别生产车间人员行为的本质在于提取人员行为特征并进行分类,上文通过图像构造的方式将基于时序的三维骨架序列行为识别问题转化为图像识别问题。
在基于三维骨架信息的行为识别过程中,所识别的主要特征为每个时间间隔中的人员行为状态。CNN图像滤波器是一个分层自适应二维滤波器体系结构,其将处理后的图片信息的时序特征和行为特征压缩在一张图片中,图片的水平方向是行为在时间轴上的特征,垂直方向是图片在不同骨架关节的动作特征,根据这两个特征建立模型。
在文献[12]的基础上建立行为识别模型,如图8所示。该模型包括4个级联卷积网络,卷积核均为3×3,卷积过程中的所有步长均设置为1,卷积过程公式为
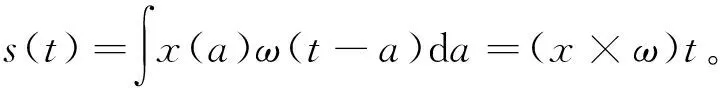
(9)
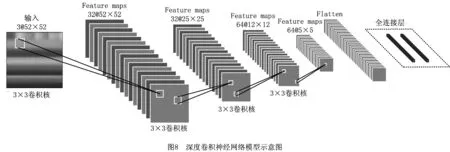
式中:x为卷积网络的输入;ω为核函数;输出s(t)为特征映射,是下一个神经网络的输入。
在前3个滤波器组中添加最大池化层,即选取相临矩形区域内的最大值作为下一个网络的输入,以减小原始动作因频率在不同尺度上发生变化而对识别结果产生的影响。
最后在识别的末端添加两个全连接层,第一个全连接层由128个神经元组成,第二个全连接层的数量由行为的识别数决定。
在训练过程中,相比于激活函数单元tanh,激活函数单元使用ReLU的模型速度更快。激活函数单元ReLU的函数表达式为
f(x)=max(0,x)。
(10)
若输入x≤0,则函数输出为0,否则函数输出为其本身。该特性大大减少了函数计算量,减少了参数间的相互依赖性,可以缓解过拟合现象。
损失函数使用的是多类对数损失函数如式(11)所示,在使用该函数时,需将标签转化为二值序列。
(11)
式中:M为训练集T中的样本数量;A为识别行为的类别数量;δ为克罗内克函数;p(Ai|xm)表示样本xm属于行为Ai的概率。该损失函数用于评估分类器的概率输出,通过对惩罚错误进行分类实现分类器对准确度的量化。
在模型训练过程中,为了提高收敛速度,采用去均值的方法去除图片的均值。在所有图片中,分别从4个角和中间提取5张图片,图像尺寸为52×52,因为骨架的时间序列通过图像的先后顺序体现,所以利用图像在水平方向的翻转来增强图像。最后通过对5张图片进投票决定图像的识别结果,如果出现5个不同的结果,则最终结果为第一张图片所代表的识别结果,若5张图片中各有两张的识别结果相同,则最终结果为第一组图片所代表的识别结果。
4 算法实例验证与分析
本文实验硬件环境为戴尔T7920工作站,配置为CPU Intel(R)Xeon E5-2640 v4(10核心),内存容量为64GBECC,操作系统为LinuxUbuntu 16.04,程序环境为Python3.6,在NVIDIAGTX1080Ti和NVIDIACUDA Toolkit GPU加速环境下开展实验验证。为了验证算法的准确性和可靠性,本文分别在微软的MSR-Action3D[14]和独立采集的车间工人行为数据集NJUST3D上进行相关测试和验证。
4.1 MSR-Action3D数据集实验验证
MSR-Action3D是最早基于深度视觉和三维骨架信息展开行为分析研究的数据集之一,其基础数据集提供了由RGBD摄像头采集到的深度图片和骨架序列图片,其中深度图像的分辨率为320×240。该数据集包括20个基本行为,由10名实验人员面对摄像机,将每组行为重复2~3次,从而采集到人员的行为数据。MSR-Action3D行为数据集样本由深度图片序列组成,同时该数据集还给出了一组基于这20个关节点的三维位置坐标。样本的行为包括挥手(抬手)、挥手(水平)、敲打、伸手抓、前冲、高抛、画叉、画勾、画圆、击掌、挥双手、侧拳、弯腰、前踢、侧踢、慢跑、网球挥杆、网球发球、高尔夫挥杆、接球/投掷共20种游戏行为,如图9所示。

为了验证算法的可靠性以及在不同数据集上的运用效果,本文使用MSR-Action3D数据集对行为识别模型进行训练。在训练过程中,为了能与前人的实验结果进行对比,本文采用文献[15]的相关参数将行为划分为3类,各分类的详细行为如表3所示。将3类行为数据分别输入神经网络模型进行训练,对测试结果取均值,获得3D-DCNN算法下该数据集的行为识别准确率。

表3 MSR-Action3D行为分类表

续表3
在模型的训练过程中,需要对数据集进行训练集和测试集分类。本文将MSR-Action3D数据集中的1/2作为训练集,1/2作为测试集,通过实验对比现有算法[14-16]和本文3D-DCNN算法。表4所示为上述几种方法的准确率在MSR-Action3D数据集上的表现。可见,本文算法明显优于文献[14,16]算法;算法[15]在处理ASR1,ASR2这类简单行为时准确率略优,但在处理相对复杂的ASR3数据集上的准确率出现大幅下降,因此综合准确率低于本文方法。如表4所示,通过模型训练得到MSR-Action3D数据集在该方法下的综合准确率为84.27%,相比现有算法[14-16],该方法的行为识别准确率有一定提升。

表4 MSR-Action3D数据集行为识别算法对比 %

续表4
从识别结果的混淆矩阵(如图10)和各行为识别的准确率(如图11)来看,在该行为识别模型下,绝大多数行为的识别准确率都能达到80%以上,部分行为的识别准确率仍然较低。行为类别1(AS1)和行为类别3(AS3)的8组行为的识别准确率分别达到86.45%和84.27%,处于较高水平;行为类别2(AS2)行为的识别准确率只有77.91%,与本次实验的平均值有一定差距。行为类别2(AS2)行为包括高处挥手、伸手抓物、画叉、画勾、画圈、挥双手、前踢和侧踢8种行为。


由混淆矩阵可以看出,8种难以识别的行为包括伸手抓物、画勾和画叉3种行为,均为手臂运动,主要特征为大臂带动小臂。在骨架关节位置信息图像化构造过程中,这几类行为的差异仅在手腕关节,因此存在对此类行为识别的准确率较低的问题。
4.2 NJUST3D数据集实验验证
为在实际生产过程中验证本文方法,对生产行为进行模拟和数据采集。结合吉尔布雷斯动作分析方法,将生产车间中的人员行为分为前期准备行为、生产行为、违规行为和其他行为4类(如图12),每一类下还有若干小类,共模拟了18种生产车间中常见的人员行为,在实验室中模拟并采集了部分常见生产行为形成NJUST3D数据集。

如图12所示,将NJUST3D生产行为数据集行为进行如下分组:
(1)前期准备行为与普通产品的生产装配不同,火工品在受外界刺激后容易燃烧或爆炸,这类车间对进入生产区域中的人员有更严格的要求,工作人员进入生产区域后需要穿戴特定的静电服、鞋套并释放鞋底的静电。因为这3种行为比较特殊,所以将其作为进入生产车间的前期准备行为。
(2)生产行为火工品的装配过程主要是对来料进行加工,装配过程中的物料运输方式包括人工搬运、手推车搬运和吊车搬运3种,对应的人员行为为搬运物品、堆放物品、使用手推车运输和使用手持设备4项。在生产过程中可能还会涉及切割工件、拾起掉落的零件、打扫工位,因此有锯工件、捡零件和打扫工位3种行为。装配完成后需要检查异常记录,因此添加检查记录这一行为。
(3)违规行为在火工品装配车间,一切能导致火工品发生燃烧或爆炸的行为都是违规行为。生产过程中常见的违规行为有使用通讯设备(引发静电)、暴力搬运、抽烟(引发火灾)和重敲。
(4)其他行为指生产车间中常见的、不影响生产也非违规的行为,包括喝水、擦汗和坐着3种行为。
本次实验通过KinectV2深度传感器采集获取生产行为数据,NJUST3D数据集由18组(如图12)行为组成,包括重敲、搬运物料和锯工件等生产行为,以及抽烟、打扫工位和坐着休息等非生产行为。这些行为是采用两台Kinect摄像机对20位志愿者进行拍摄完成,两个摄像机的摆放位置呈60°夹角,摄像头高度分别为140 cm和160 cm(如图13)。其中志愿者被要求分别面对两个摄像机和摄像机的中间位置,将每组动作各执行3次,共采集2 160组行为数据(如图14),作为NJUST3D生产行为数据集的数据示例。


在模型的训练过程中,生产行为数据集同样需要对数据集进行训练集和测试集分类。本文将NJUST3D数据集中每种行为的2/3作为训练集,剩余的1/3作为测试集,用于模型训练。
采用3D-DCNN方法对该数据进行训练后,NJUST3D数据集的行为识别准确率为71.36%,这在复杂生产环境中比较理想,但是对于某些极端行为,例如在火工品周围抽烟等严重危害生产的行为,该准确率仍然不足。对此,按照行为置信度由大到小排序,本文方法置信度排名前三行为的识别准确率达到92.12%,具有一定实用价值。为便于后续研究及结果分析,绘制混淆矩阵(如图15)和各行为识别准确率(如图16)。
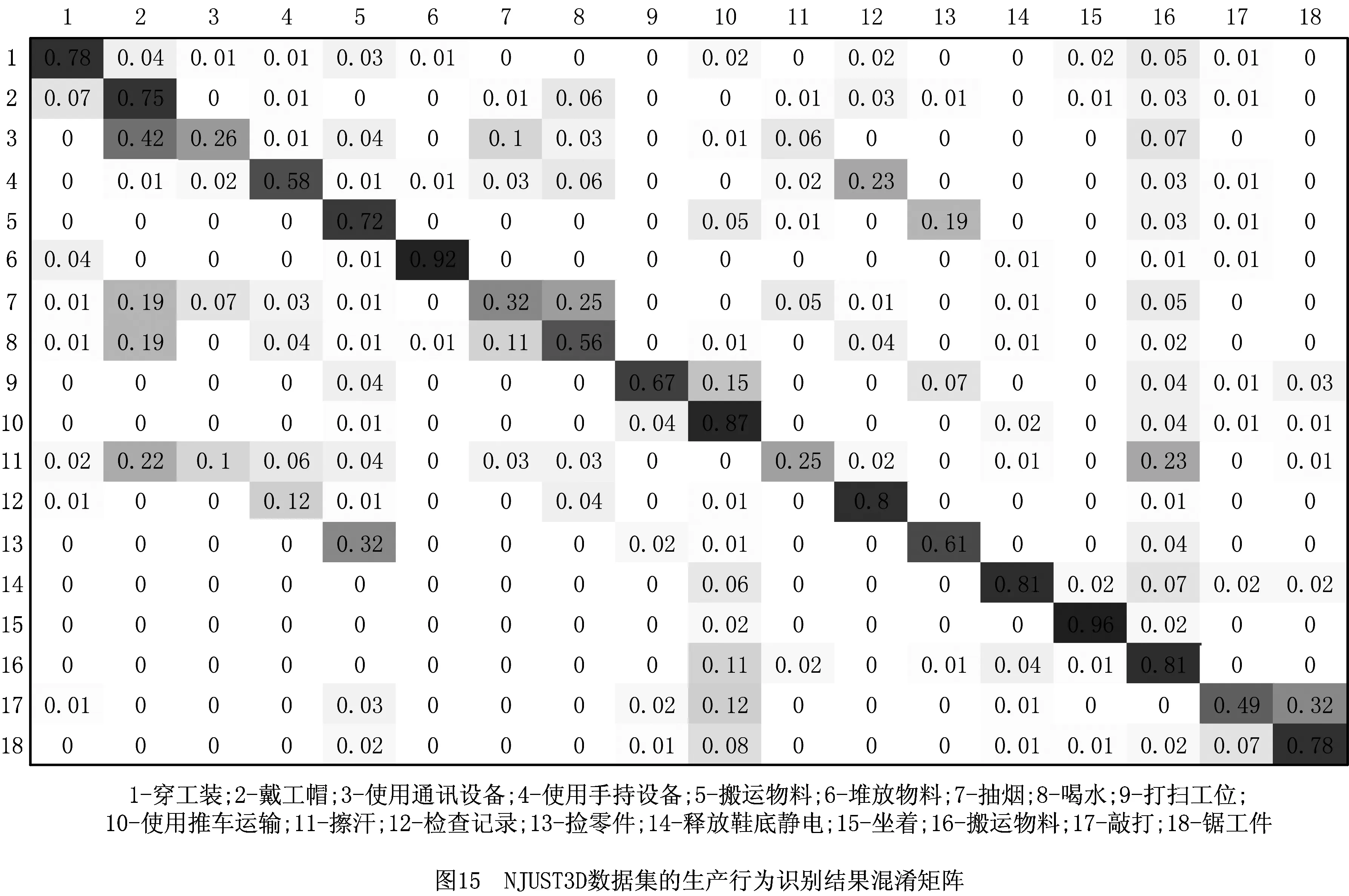

由图15和图16可知,在生产行为识别过程中,总体识别准确率较高,都能达到60%以上,但是对于部分行为,如行为3(使用通讯设备)、行为7(抽烟)、行为11(擦汗)的识别比较困难,原因是这类行为大臂和小臂的运动轨迹基本相同,行为之间的差异主要体现在手腕动作,图像中的描述并不明显(如图17),从而造成识别准确率较低。

与MSR-Action3D行为数据集84.27%的准确率相比,此处行为识别准确率有所降低,主要有以下原因:①MSR-Action3D数据集进行行为识别时将数据分为3组,其识别的本质是一个8分类问题,而本文对NJUST3D生产行为数据集进行行为识别时未分组,是一个18分类的识别问题,因识别种类更多使难度提升而造成准确率下降;②相比MSR-Action3D数据集的行为,NJUST3D生产行为数据集的行为更加复杂,多个行为之间的相似度比较高,导致识别准确度下降。
5 结束语
对生产过程人员行为进行管理是实现企业高效运行和安全生产的一个重要方式,本文提出基于3D-DCNN的生产行为智能识别方法,并在国际通用的MSR-Action3D行为数据集和实验室自建行为数据集NJUST3D上,验证了该方法的有效性。该识别结果将用于车间的安全生产监控,尤其对某些特定车间(如危险品生产车间),通过识别人员行为能够发现安全问题,从而及时消除隐患,防患于未然。
未来的工作将对人员行为识别算法进行更加深入地研究:
(1)改进微动作识别算法的准确性 本文算法对基本行为具有较好的识别效果,但在应对宏观行为相近、手部等微观行为不同的生产行为时,识别准确率明显降低,考虑从两方面进行改进:①优化数据采集方法,例如采用多个深度视觉传感器采集不同距离的行为数据等;②继续优化行为识别模型,以应对更加复杂、微观的实际应用场景。
(2)提升模型的实用性 本文所用实验设备计算能力较强,能够满足实时生产行为的识别,但车间现场硬件设施往往很难达到,需要适当降低模型的复杂程度,在更经济的硬件条件下实现生产行为的实时监控。
