数据驱动的车削和钻削加工能耗预测
2020-09-10吕景祥唐任仲
吕景祥,唐任仲,郑 军
(1.长安大学 道路施工技术与装备教育部重点实验室,陕西 西安 710064;2.浙江大学 工业与系统工程系,浙江 杭州 310027;3.浙江科技学院 机械与汽车工程学院,浙江 杭州 310023)
0 引言
制造业在给我国创造巨大财富的同时,消耗了大量的资源和能量,环境污染和能源短缺已经成为当前社会面临的重要问题。2015年5月8日,国务院印发的《中国制造2025》将“绿色制造”列入五大工程之一,指出到2025年,主要产品单耗要达到世界先进水平[1]。机械加工是零件成形的重要方法之一,在制造业中广泛应用,在创造大量的就业机会和财富的同时消耗了巨大的能量,而且能效低下,平均不足30%[2],例如GUTOWSKI测试了丰田汽车生产线的机械加工能耗,发现其能效最高仅为14.8%[3]。因此,减少机械加工能耗,实现机床高效低碳运行的需求十分迫切。
降低零件机械加工能耗的前提是准确预测该过程的能耗,近年来学者们围绕机械加工尤其是数控加工能耗建模开展了大量研究。国内He等[4]提出通过解析数控程序预测机械加工能耗的流程和方法;Jia等[5]通过分析机床运动,提出一种基于动素的机械加工工艺过程能量需求建模方法;刘飞等[6]建立了机床机电主传动系统启动、空载、加工和间停各时段的简化能量模型,将各时段能耗相加得到机床服役过程的主轴能耗。国际上,Kara等[7]通过开展大量实验验证了材料单位体积切削能与材料去除速率成反比;Mori等[8]认为机械加工过程的能耗等于基本能耗、空运行能耗和主轴定位能耗之和,在此基础上,Balogun等[9]进一步考虑了机床喷冷却液和去除材料的能耗,建立了基本状态、准备状态和加工状态能耗的数学模型。然而,上述方法需要解析工艺过程并已知机床能耗模型,其中工艺过程解析包括数控代码翻译、参数匹配和提取等,而且由于机床能耗特性各不相同,其能耗模型需要通过大量实验测试获得,导致该方法在实际生产中应用时过程复杂且费时费力。另外,文献中的理论公式没有考虑能耗部件状态不同时(如冷却泵和主轴开停)空运行功率的变化,因此难以准确计算实际加工能耗。
近年来,传感器、工业互联网、大数据等新兴技术不断融合,且在制造业中的应用越来越广泛。黄少华等[10]综述了制造物联网应用于离散车间的关键技术和应用模式;任明仑等[11]从大数据驱动的视角引入数据生命周期理论,提出一种质量控制持续演进框架;张洁等[12]提出大数据驱动下“关联+预测+调控”的智能车间运行分析与决策方法体系;朱雪初等[13]研究了基于工业大数据预测晶圆加工周期的方法;万祥等[14]结合粗糙集和关联规则算法,挖掘汽轮机组运行典型负荷下的历史数据,得到机组热耗率最佳时对应的运行参数范围;Bhinge等[15]采用高斯回归方法预测零件铣削加工过程的机床能耗,但仅建立了以工艺参数为自变量的能耗模型。本文采用数据驱动的方法对车削和钻削加工能耗进行预测,该方法无需分析机床具体工作过程,只是利用零件设计、工艺、制造、能耗等数据,通过机器学习的方法预测加工能耗,就能便捷地得到更加准确的车削和钻削能耗。
本文研究基于数据驱动的零件车削和钻削加工能耗预测方法。首先介绍零件机械加工能耗的构成,然后分别研究零件机械加工能耗数据采集和预处理、特征属性预处理、特征选择和能耗预测算法,最后进行案例研究,分别采用神经网络、支持向量回归、随机森林3种算法预测车削和钻削加工能耗,并与已有模型进行对比,验证了所提方法的有效性,以及相比于文献现有方法的优越性。
1 零件机械加工能耗的构成
零件加工能耗定义为加工开始直至结束的机床能量消耗,以一个轴类零件粗车加工为例,机床的功率曲线如图1所示[16],能量消耗等于零件加工过程机床各类运动能耗之和,即
E=Eba+Ecl+Esr+Efd+Ec+Etc+Erf+Ecp。
(1)
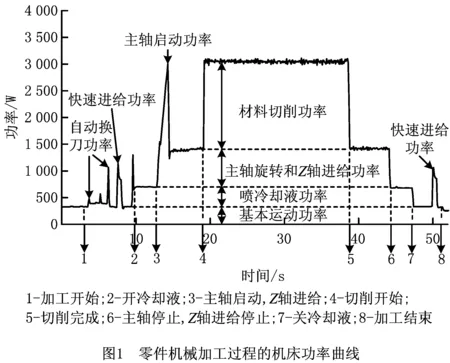
式中Eba,Ecl,Esr,Efd,Ec,Etc,Erf,Ecp分别为基本运动、喷冷却液、主轴旋转、进给运动、材料切削、自动换刀、快速进给和自动排屑的能耗。其中:Eba等于机床待机功率乘以机床开机运行时间;Ecl等于冷却泵电机的额定功率乘以喷冷却液的时间;Esr,Efd分别等于主轴旋转、进给运动功率和相应时间的乘积,其中主轴旋转、进给运动功率受电机、机械结构和运动参数(主轴转速、进给速度)的影响;Ec等于切削功率乘以切削时间,其中切削功率的影响因素最为复杂,包括毛坯材料、毛坯形状、毛坯尺寸、零件形状、零件尺寸、刀具材料、刀具直径、刀具几何角、冷却条件、切削参数(如主轴转速、进给量、切削深度)等;Etc等于换刀电机功率和换刀时间的乘积;Erf等于进给电机功率和快速进给时间的乘积,后者取决于快速进给速度和进给距离;Ecp等于排屑电机运行的功率乘以运行时间。
由上述分析可知,零件机械加工能量消耗的影响因素包括零件设计相关的毛坯材料、毛坯形状、毛坯尺寸、零件形状、零件尺寸数据,零件加工工艺相关的主轴转速、进给量、切削深度、切削宽度、冷却条件数据,机床相关的机床型号、主轴额定功率、进给轴额定功率、冷却泵额定功率等数据,以及刀具相关的刀具材料、刀具直径、刀具几何角度等数据。可见,通过理论分析准确预测零件加工能耗十分困难,因此本文尝试采用数据驱动的方法预测零件加工能耗。
2 数据驱动的车削和钻削加工能耗预测方法
2.1 能耗数据采集和预处理
数据驱动方法应用的基础是对能耗数据进行采集和预处理,研究框架如图2所示。能量消耗根据电流、电压传感器采集的机床电流、电压数据计算得到:
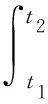
(2)
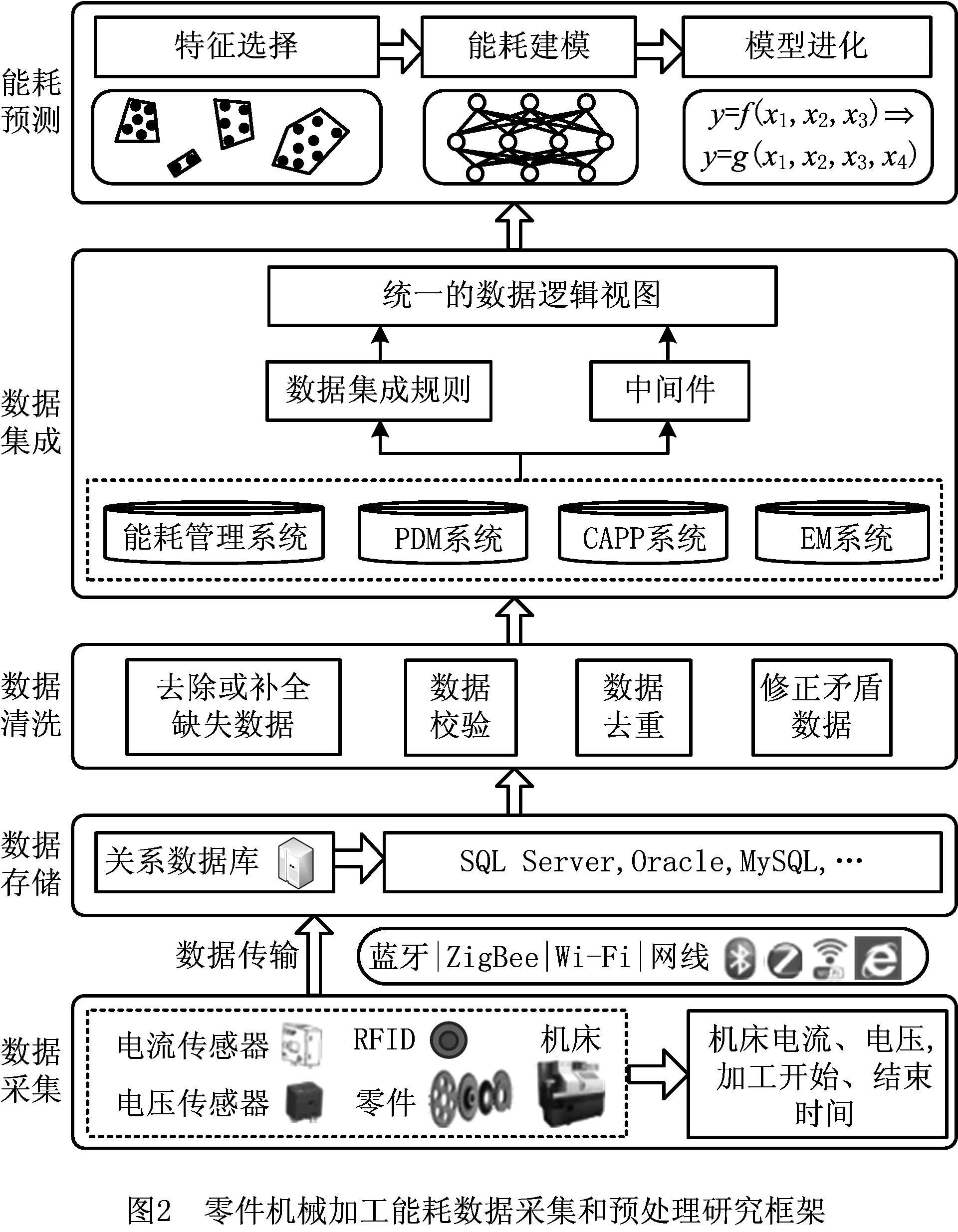
式中:U1,U2,U3分别为机床3根相线的瞬时电压;I1,I2,I3分别为机床3根相线的瞬时电流;t1和t2分别为零件加工的开始和结束时间,采用射频识别(Radio Frequency IDentification, RFID)技术自动采集,即在零件加工开始和结束时,控制机床对应的读写器读取与零件绑定的RFID标签,得到t1和t2。将采集的能耗和加工时间数据采用蓝牙、ZigBee、Wi-Fi、有线网络等技术传输至服务器,并用关系数据库存储,常用的数据库包括SQL Server,Oracle,MySQL等。
为了更好地进行能耗建模,对采集的原始能耗数据进行预处理,包括数据清洗和数据集成。针对数据缺失、格式不一致、逻辑错误等问题,进行数据清洗,包括去除或补全缺失数据、数据校验、数据去重、修正矛盾数据等内容。零件设计、工艺以及机床、刀具数据是能耗预测模型的自变量,而且设计、工艺、机床等各类数据分散在多个信息系统,如产品数据管理(Product Data Management, PDM)系统、计算机辅助工艺规划(Computer Aided Process Planning, CAPP)系统、设备管理(Equipment Management, EM)系统等,对此建立数据集成规则,设计中间件,得到全局数据模型来访问不同信息系统的数据库,从而提供统一完整的数据逻辑视图,在此基础上进行后续能耗预测。
2.2 特征属性预处理
能耗建模是建立能量消耗和输入变量之间的关联关系。零件材料、几何尺寸、切削参数、冷却条件、机床和刀具类型等输入变量影响零件加工能耗,然而不同变量对能耗的影响大小有差异。由于存在和能量消耗这一目标值冗余、关联或不相关的特征,需要进行特征选择,剔除对能耗影响小或与能耗无关的特征,选择影响显著的特征作为模型输入变量,以提高能耗模型的训练效率和预测精度。应用特征选择算法前,要对特征进行预处理,包括:
(1)非数字特征数字化 零件材料、冷却条件、机床和刀具类型等属性均为非数字特征,需要将其数字化。零件材料的强度和硬度不同,切削力、切削功率和能耗的影响不同,其中硬度的影响最大,因此用硬度值表示相应的材料;冷却条件用喷冷却液功率表示,干切削时该特征取值为0,湿切削时该特征取值为机床冷却泵电机的额定功率;机床通过待机功率和主轴电机功率影响基本运动和主轴旋转能耗,因此分解为待机功率和主轴电机额定功率两个数字特征;刀具通过刀具直径、齿数、前角、主偏角等几何属性影响切削能耗,因此分解为刀具直径、角度等多个数字特征。
(2)冗余特征筛选 本文采用的Relief系列算法不能处理冗余特征,需要其他方法辅助筛选冗余特征。当某特征能够被另一特征的取值决定,或者某特征在数据集中在所有样本上的取值几乎一致时,该特征属于冗余特征,可以从数据集中删除。
(3)特征属性归一化 由于特征取值范围差异很大,采用最小最大值法将特征属性取值统一映射到[-1,1]区间,计算公式为
x=(x-xmin)/(xmax-xmin)。
(3)
式中:x为特征的取值;xmin和xmax分别为特征的最小和最大取值。
通过特征属性预处理得到零件机械加工能耗的数据集。由于不同零件类型、工艺过程的能耗原理差异很大,根据零件类型(轴套类、盘盖类、盒体类、叉架类、箱体类等)和加工工艺过程分别进行特征选择和能耗建模。典型工艺包括外圆车削、平面铣削、复杂曲面铣削、平面磨削、钻削等,各类工艺共有的属性包括工件材料、主轴转速、进给量、切削深度、空行程距离、机床待机功率、主轴电机额定功率、喷冷却液功率、刀具前角和主偏角,各类工艺特有属性总结如表1所示。

表1 典型工艺零件加工能耗的相关属性及说明
2.3 特征选择算法
常见的特征选择方法分为过滤式、包裹式和嵌入式3类[17]。过滤式方法直接对数据集进行选择,然后再训练学习器,运行效率较高,代表方法是处理两分类问题的Relief算法,其核心思想是根据最近邻样本估计每个属性的特征权重[18]。为了处理多分类问题,Knonenko基于Relief算法,改进得到了鲁棒性更强的ReliefF算法,该算法能够分析不完整和有噪音的数据。针对应变量连续的情况,Kononenko进一步提出带有回归功能的RReliefF算法[18]:从数据集中随机选择一个样本R,并选择k个最近邻样本,基于概率模型计算样本的相对距离,然后基于贝叶斯概率模型计算特征权重。然而上述算法在应用时,存在以下不足:当k值较小时,最近邻样本大多是应变量取值和样本R接近的样本,缺乏应变量取值和R差异大的样本,导致特征权重计算结果失真,而k取值过大又会增加计算复杂度。因此,本文结合样本分类思想对现有RReliefF算法进行改进。首先根据应变量取值将样本分为两类,然后随机选择样本Ri,分别从Ri的同类和异类样本中寻找k个最近邻样本H和M,随机抽样重复m次,计算特征A的权重。近邻选择的方法是遍历数据集,计算各样本与样本R的距离:
(4)
式中:d(R1,R2)为样本R1和R2的距离;N为样本特征的个数;diff(A,R1,R2)为样本R1和R2在特征A上的距离。特征A为离散值变量时,
diff(A,R1,R2)=
(5)
A为连续变量时,
diff(A,R1,R2)=
(6)
式中:value(A,R1)和value(A,R2)分别为样本R1和R2的特征A的取值,max(A)和min(A)分别为样本数据中特征A的最大值和最小值。特征A的权重[18]
(7)
(8)
(9)
(10)
式中f(R)为样本R的应变量取值。
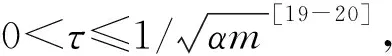
运行上述算法时,需要设置随机抽样次数m和近邻个数k两个关键参数值。因为算法采用随机方式抽取样本,所以通过提高抽样次数m可以减少由于随机选择样本Ri带来的不确定性,m取值应大于20[18]。近邻个数k的合理取值由问题复杂性、噪音多少、样本数量综合决定,为避免错失重要特征属性,推荐采用多个k值计算特征权重,选择所有计算结果的最大值作为特征的最终权重[18]。
2.4 能耗预测算法
神经网络、支持向量回归(Support Vector Regression, SVR)和随机森林是3种常用的机器学习算法,能够处理大量数据并拟合非线性关系,已被广泛用于机械加工领域,例如预测零件加工质量、刀具磨损等,因此本文选择上述3种算法预测车削和钻削加工能耗。
神经网络是一种由多个神经元按照一定层次结构连接起来的网络。在神经网络中,神经元接收到来自前一层神经元传递的输入信号,这些输入信号通过自带权重的连接进行传递,输出由神经元的总输入减去神经元的阈值得到。其中,神经元之间的连接权重以及每个神经元的阈值通过数据集不断训练学习得到。误差反向传播(Back Propagation, BP)神经网络是广泛应用的一类神经网络,其将输出层的误差反向传播至隐层神经元,根据隐层神经元误差调整连接权重和阈值。BP算法的目标是最小化训练集上的误差,为了提高传统BP算法的收敛速度,采用LM(Levenberg-Marquardt)算法改进BP神经网络,该算法具有二阶收敛速度,能够在迅速得到神经网络模型的同时保证较高的模型精度。
神经网络建模的关键之一是确定隐层神经元的数量,数量太少容易导致模型欠拟合,太多会导致模型过拟合并增加训练时间[21]。隐层神经元的节点个数J可用经验公式计算[22]:
(11)
式中:ni和no分别为输入层和输出层的节点数;c为模型的常数,c∈[1,10],本文设计循环算法确定c的最佳取值,即令c从1~10取值,分别训练神经网络,并比较各网络预测的均方根误差,选择使神经网路误差最小的c值。网络训练时,将数据随机分成3部分:70%的训练集数据用于根据误差训练网络;15%的验证集数据用于验证网络的适应性,进一步确定模型的参数;15%的测试集数据用于评估网络的预测精度。
SVR算法由支持向量机发展而来,通过在高维空间中构造线性决策函数实现线性回归,通常采用ε-SVR算法和径向基核函数,其中径向基核函数
(12)
式中:xi和xj为样本的自变量;γ为核的宽度系数。应用模型时,需要设置惩罚系数C和宽度系数γ,通过循环算法遍历可能的C和γ参数组合,选择使模型训练误差最小的C和γ。
随机森林算法是以决策树为基学习器的一种集成学习方法,该算法在决策树的训练过程中引入随机属性选择构建多个决策树,其用于回归问题时将各个决策树的预测结果求平均作为最终的输出结果。应用模型时需要设置决策树的数量N,采用不同的N值训练随机森林模型并计算模型训练误差,选择误差最小时对应的N值为决策树的数量。
3 案例分析
本文在金工车间开展零件外圆车削和钻削加工实验,采集和预处理能耗数据,应用机器学习算法预测加工过程能耗来说明上述数据驱动的能耗预测方法的应用过程,并验证其有效性。
3.1 能耗数据采集和预处理
外圆车削加工的工件材料包括45号钢、6061铝合金和QT500-7球磨铸铁3种,机床包括CK6153i和CK6136i两台数控车床,其中钢和铸铁切削采用住友VNMG160408硬质合金刀具,铝合金切削采用克洛伊CCGT09T304刀具,冷却条件分为干切削和湿切削两种。钻削加工的工件材料为45号钢,刀具采用日本NACHI公司的直柄麻花钻(钻尖角118°),钻头直径分为Φ=8 mm,Φ=10 mm,Φ=12 mm三个系列,机床为XHK-714F立式加工中心和JTVM6540数控铣床,冷却条件均为湿切削,切削液为普通水基乳化液。零件加工的其余变量包括零件几何参数(如零件直径和切削长度)和切削参数(如主轴转速、进给量和切深),采用自变量随机组合的方式设置。应用课题组自行搭建的功率装置采集能耗数据,该装置由电流传感器、电压传感器、数据采集卡、计算机、NI Labview数据采集软件、SQL Server数据存储软件构成,采集机床工作的电压和电流数据计算得到机床功率,实验所用工件、刀具、机床和能耗测试装置如图3所示。

每个零件绑定一个RFID标签,在零件加工开始和结束时,控制RFID读写器读取标签并记录时间,根据零件加工开始和结束之间的功率计算能耗。实验测试的零件加工功率曲线实例如图4所示。去除开始或结束时间缺失无法计算能耗的数据,分别得到168条和62条有效的车削和钻削能耗数据。应用RFID识别码信息将零件能耗数据和零件设计、工艺、机床信息进行关联,得到零件加工能耗及其对应的特征信息。采用2.2节方法对特征进行预处理。本案例中,45号钢、6061铝合金和QT500-7球磨铸铁的硬度分别为262 HB,97 HB,200 HB;CK6153i,CK6136i,XHK-714F,JTVM6540的待机功率分别为332 W,336 W,371 W,361W;主轴电机额定功率分别为7.5 kW,5.5 kW,7.5 kW,4 kW;冷却泵电机的额定功率分别为370 W,132 W,233 W,216 W。两台数控车床的待机功率取值接近,刀具由工件材料唯一确定,为冗余特征,从数据集中删除。最终的特征及取值范围如表2和表3所示。
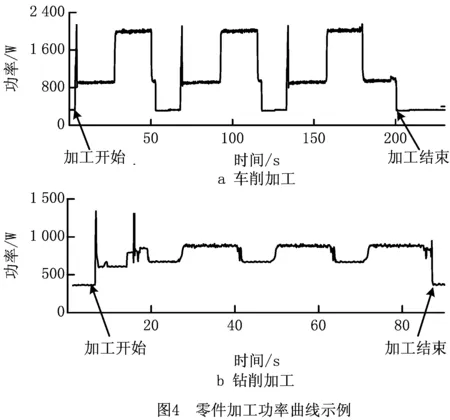
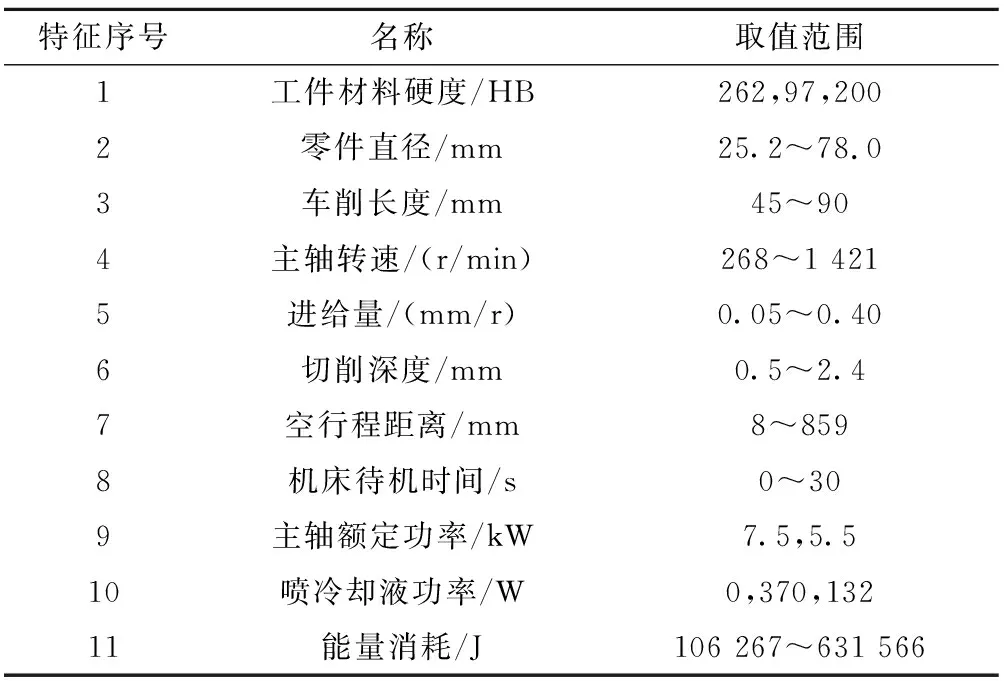
表2 零件车削加工实验数据集的特征及取值范围

表3 零件钻削加工实验数据集的特征及取值范围
3.2 零件机械加工能耗的相关特征选择
得到零件加工数据集后,根据式(3)将所有特征属性归一化,映射到区间[-1,1]内。采用MATLAB软件运行2.3节的RReliefF算法,结合实验的样本数量,分别选择近邻个数k=5,10,15,20,25和k=3,4,5,6,7计算车削、钻削能耗相关的特征权重,取5次计算的最大值为各特征的最终权重,抽样次数m均为100,计算结果如图5所示。
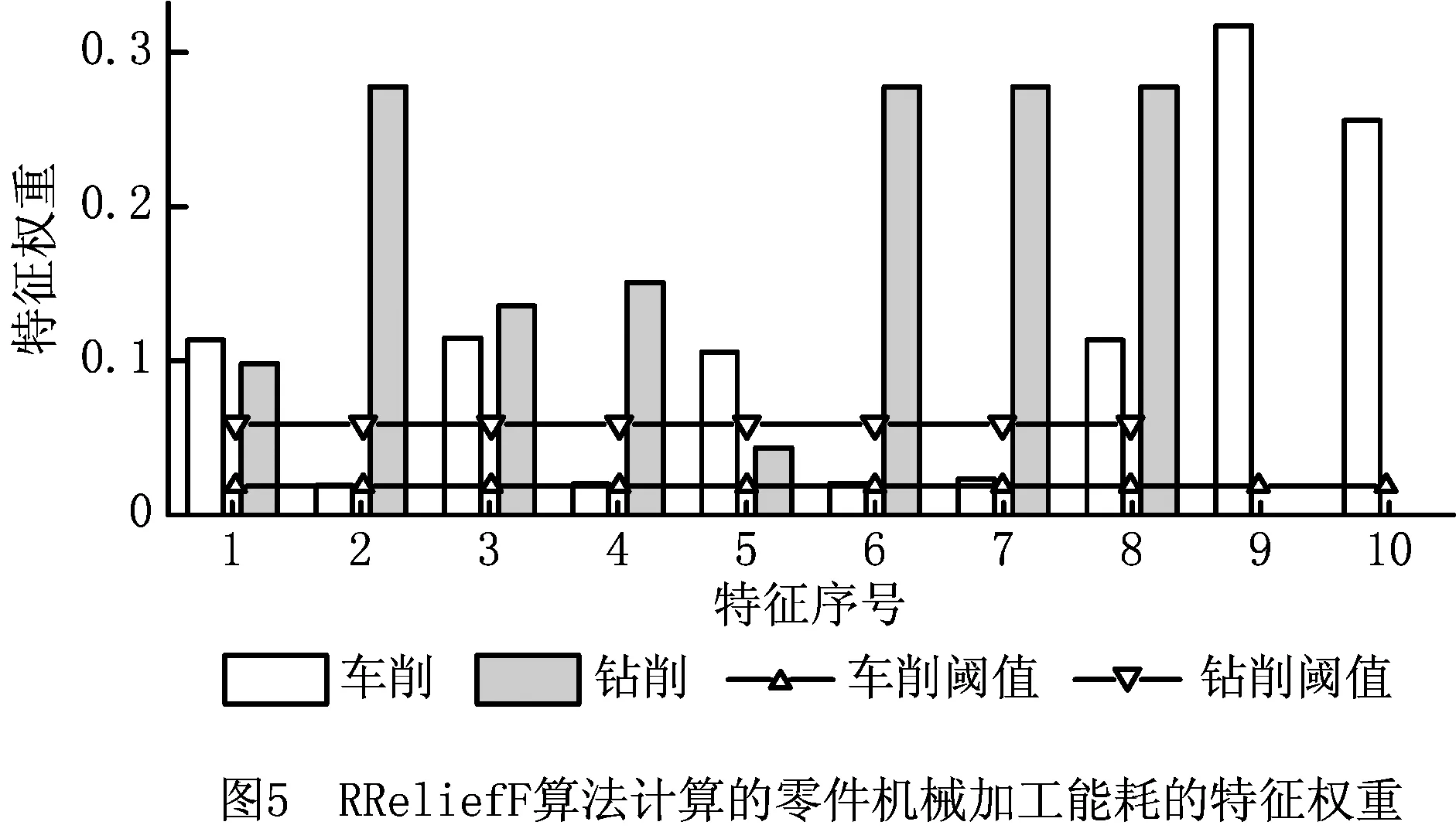
由图5可知,机床相关特征的权重最大,如机床待机功率、主轴电机额定功率、喷冷却液功率,这是由于机床自身的功率特性直接决定了零件加工功率的大小。其次是零件设计相关的特征,如车削长度、工件材料硬度、钻孔深度,零件的设计信息决定了切削时间的长短,进而影响加工能耗。工艺参数相关的特征权重较小,如进给量、主轴转速和切削深度,因为工艺参数主要影响材料去除能耗,而这部分能耗在零件加工总能耗中所占的比例较小。
本案例中,α=0.05,车削和钻削加工数据条数m=168,62,计算得车削和钻削加工权重阈值取值范围分别为0<τ≤0.34,0<τ≤0.570<τ≤0.34。结合特征计算结果,为了尽可能不遗漏相关特征,同时考虑到模型的特征较少(少于11个特征),设置特征权重取较小值。分别设置车削、钻削的特征权重阈值为0.02,0.06,将车削、钻削加工权重较大的9个和7个特征作为后续能耗建模的输入变量。
3.3 零件机械加工能耗预测
根据上述数据集,分别采用神经网络、SVR和随机森林算法预测零件的机械加工能耗,算法在配置有Intel i5-7200双核CPU、8 G内存、Win10操作系统计算机的MATLAB平台上运行。首先对数据进行归一化处理,然后将所采集的数据按照3∶1的比例分为训练样本和测试样本两组,以选择后的特征为自变量,能量消耗为应变量,分别调用神经网络工具箱、LIBSVM工具箱和机器学习工具箱,基于训练样本应用神经网络、SVR和随机森林算法训练能耗模型。采用平均误差评价模型训练的效果,平均误差
(13)
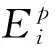
参数设置对算法预测效果的影响很大,本文设计循环算法对模型进行调参。神经网络隐层神经元节点个数J的确定过程如下:①令J的取值范围为1~11,分别训练神经网络;②比较各网络预测的均方根误差,存储误差最小的神经网络;③选择训练误差最小网络对应的节点数为所选的神经网络节点数。SVR算法需要设置的参数包括惩罚系数C和宽度系数γ,其他参数均采用默认取值,参数C和γ的确定过程如下:①根据经验确定C和γ的取值范围,C=0.5×i(i∈{1,2,…,20}∈[1,20]),γ=0.01×j(j∈{1,2,…,20}∈[1,20];②设计循环算法,遍历每一个可能的C和γ参数组合,比较选择使模型训练误差最小的C和γ取值。随机森林决策树的数量确定过程为:①根据经验,设置决策树的数量N的取值范围为N=50×i(i∈{1,2,…,20}∈[1,20]);②设计循环算法,采用不同N值构建随机森林,比较选择使模型训练误差最小的N值。上述方法可以根据不同的工艺类型、机床、零件特征等动态调整参数,从而得到精度较高的预测模型。本案例3种算法的参数取值汇总如表4所示。
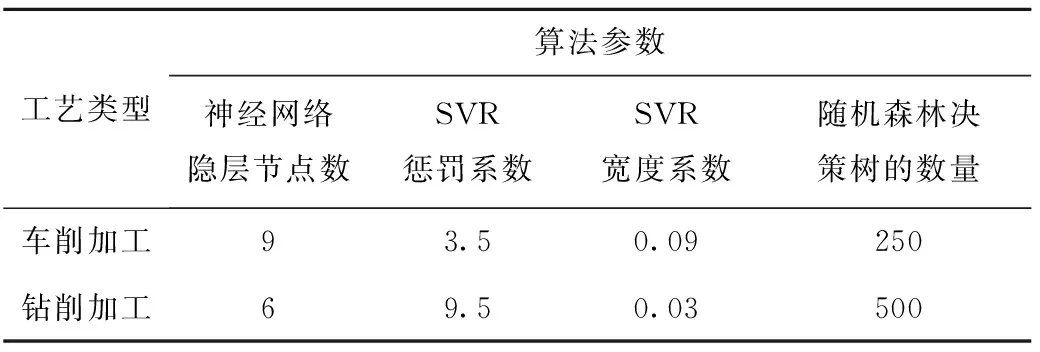
表4 零件车削和钻削加工能量消耗预测算法参数
下面采用上述3种算法预测能耗。以车削为例,结果如图6所示,图中前128个数据为训练样本,后40个数据为测试样本。为了分析特征选择算法对预测结果的影响,选择所有特征作为自变量,重新应用上述算法预测能耗,预测误差如表5所示。由表5可知,测试样本预测平均误差大于训练样本误差,其原因是数据样本量小,模型容易过拟合,泛化性能不足。使用特征选择算法后,测试样本预测平均误差在4.17%~9.94%之间,而采用全部特征建模的平均误差有所增加,可见特征选择算法既能简化模型,提高模型的训练效率,又有助于提高模型预测精度。3种算法均达到了较好的预测效果,其中神经网络的预测误差最小,其次是SVR,随机森林的预测误差最大。
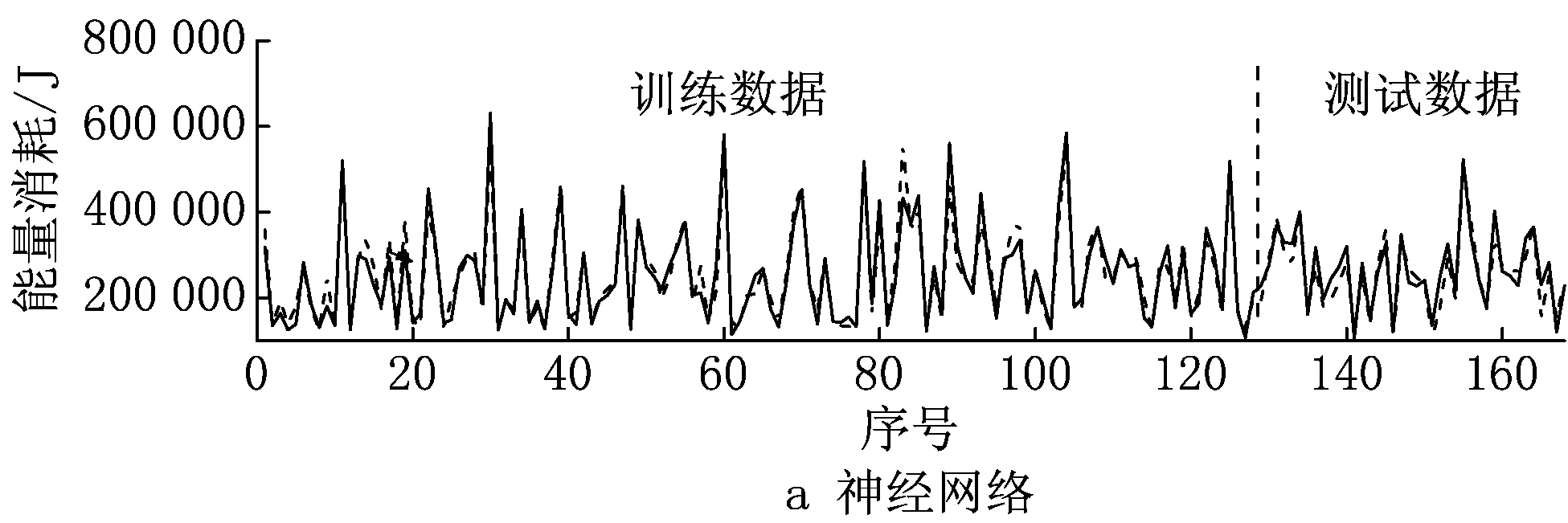
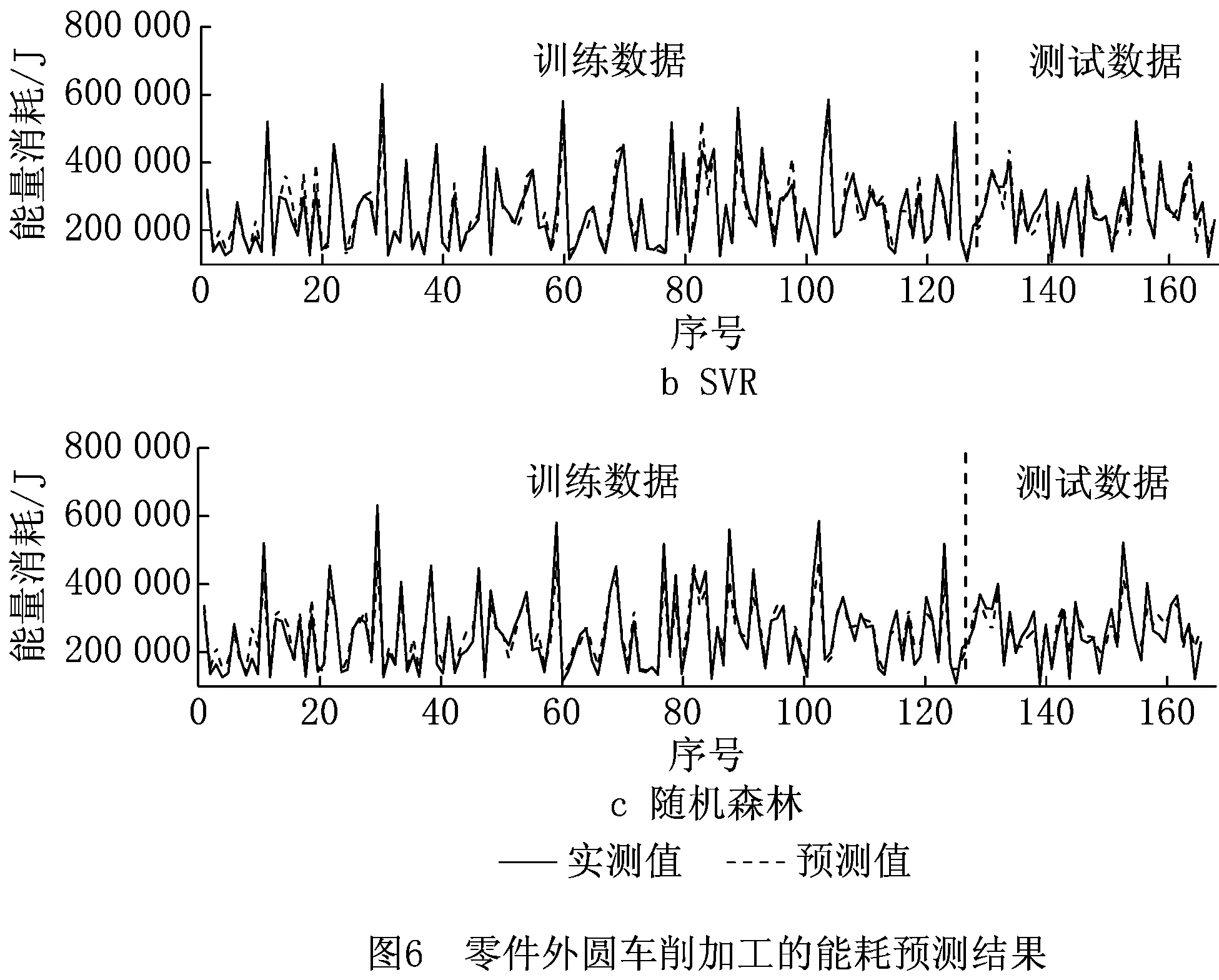

表5 零件机械加工能耗预测的平均误差 %
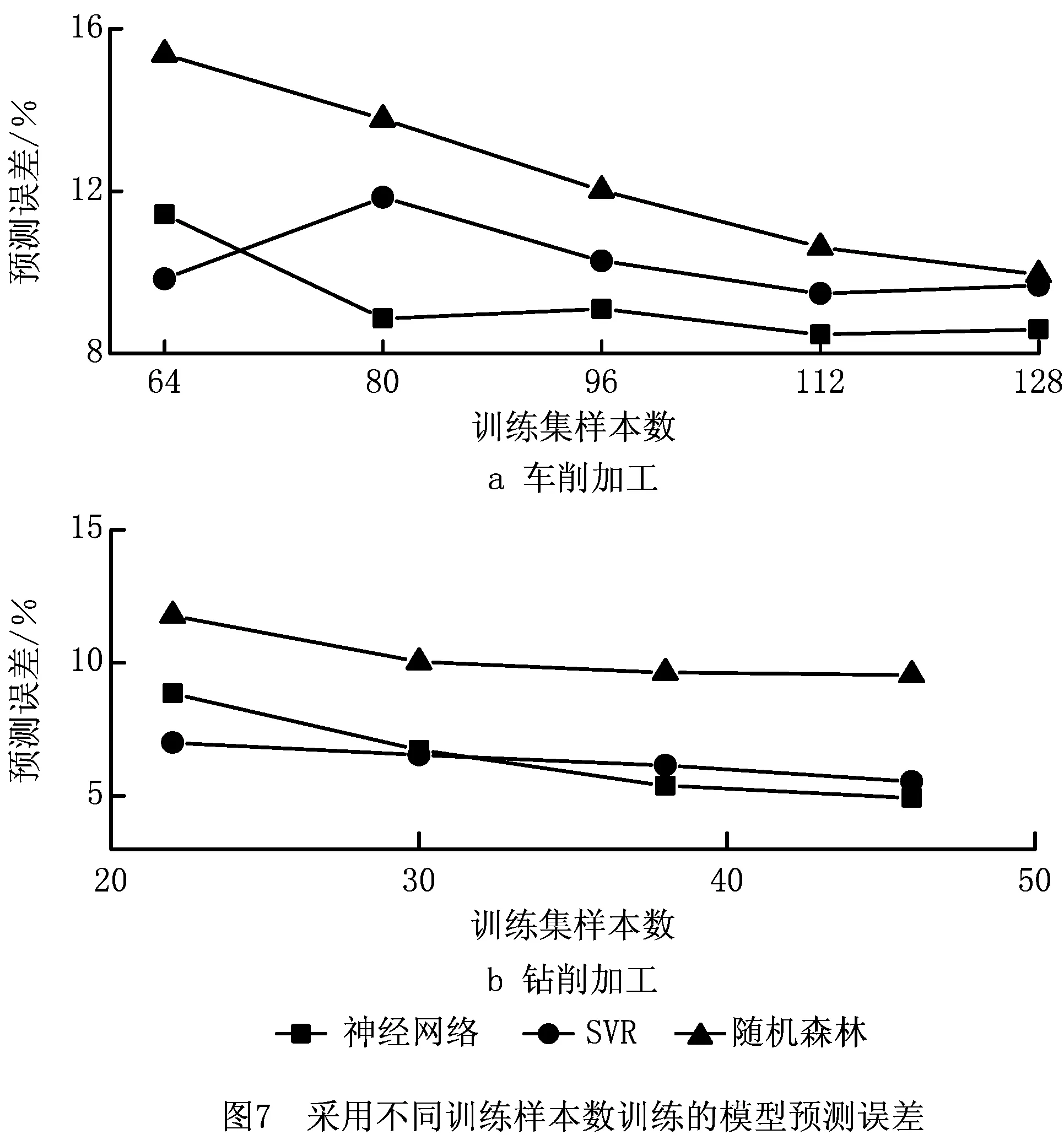
上述案例验证了本文所提方法的有效性,为指导算法选择,进一步研究机器学习样本数据不断积累对模型预测精度和运行效率的影响。分别从车削加工的训练样本中选择64条、80条、96条、112条、128条数据训练模型,从钻削加工的训练样本中选择22条、30条、38条、46条数据训练模型,测试样本保持不变,分析模型的预测误差和运行时间,结果如图7和图8所示。随着学习样本的增加,3种算法的预测误差均逐步下降。对于车削加工,随机森林算法的预测误差下降得最为显著,由15.37%下降至9.94%,神经网络算法的预测误差由11.42%下降至8.59%,SVR算法预测误差先由9.84%上升至11.84%再下降至9.67%;对于钻削加工,神经网络算法的预测误差由8.86%下降至4.94%,SVR算法预测误差由7.00%下降至5.54%,随机森林算法的预测误差由11.77%下降至9.54%。训练样本数据较小时,SVR算法的预测误差最小。运行时间方面,SVR算法的运行时间最短,随机森林算法的运行时间最长。可见,当样本数据较少时,优先选择预测精度高且运行时间短的SVR算法,当样本数据较多时,选择神经网络有助于提高模型预测精度。当实时性要求较高时,优先选择计算速度快的SVR算法。

3.4 模型比较
现有预测机械加工工艺过程能耗的模型包括Kara等[7]提出的材料切削比能模型和Balogun等[9]提出的多阶段能耗模型:
(14)
Et=Pb(tb+tr+tc)+Prtr+Pairtair+
(15)

采用比能模型预测能耗时,首先基于训练集的数据进行回归分析,分别得到4台机床的能耗模型系数C0和C1,模型如表6所示。应用多阶段能耗模型时,需要分析加工过程,计算机床待机、准备、空切削、切削等各阶段时间值,并获取机床各个状态的功率值。
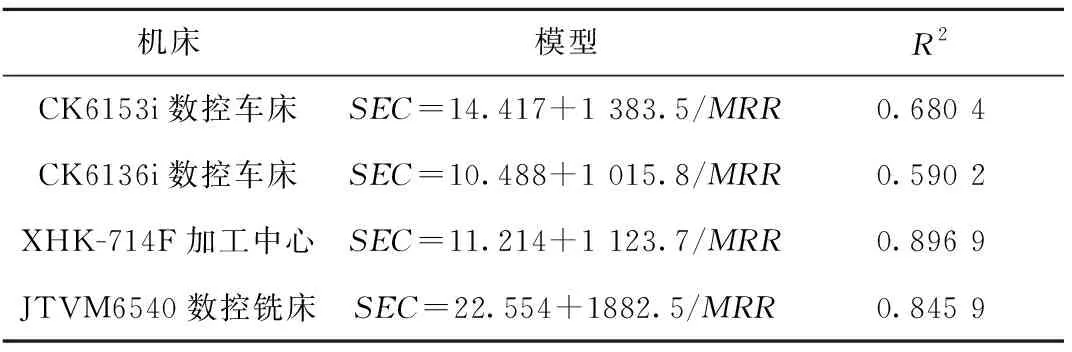
表6 车削和钻削加工工艺过程材料切削比能模型
根据式(14)的比能模型和式(15)的多阶段能耗模型,应用测试数据集预测车削和钻削工艺过程能耗,计算其预测误差,并与本文机器学习算法的预测误差进行对比,结果如图9所示。
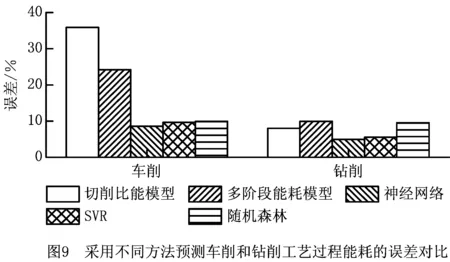
由上述结果可见,机器学习方法对车削加工能耗的预测误差显著低于现有方法;对于钻削加工,神经网络和SVR算法的预测误差低于现有方法,随机森林预测的误差同现有方法相当。因此,相比于现有方法,本文机器学习方法具有更高的车削和钻削加工能耗预测精度。
4 结束语
本文研究了一种基于数据驱动的零件车削和钻削加工能耗预测方法,包括能耗数据采集和预处理、特征属性预处理、特征选择算法和能耗预测算法4个关键技术。通过案例分析表明,RReliefF特征选择算法能够选择出对能耗影响大的属性,可以简化模型并有助于提高模型精度。在本文中,SVR算法在样本数据较小时的预测误差最小,样本数据增大后,神经网络算法的预测误差最小,随机森林的预测误差最大。相比于现有方法,采用神经网络和SVR算法能够降低车削和钻削加工能耗的预测误差。
本文方法可用于预测车削和钻削加工工艺能耗,并能根据数据集自动调整模型参数,以保持模型预测精度。随着物联网和数控系统现场总线技术的发展,更多的输入变量(空行程距离等)以及机床部件级别(主轴、X/Y/Z进给轴、冷却液电机等)的能耗将能够被自动感知和获取,可望建立更加精确的机床部件能耗模型,为机床部件级的节能奠定基础。本文研究的数据驱动方法也可以拓展应用于机械加工的其他领域,例如对零件加工精度、表面粗糙度的建模和预测。
