融合本体和改进禁忌搜索策略的气象灾害主题爬虫方法
2020-09-04刘景发顾瑶平刘文杰
刘景发 ,顾瑶平 ,刘文杰
(1. 南京信息工程大学计算机与软件学院,南京210044; 2. 广东外语外贸大学信息科学与技术学院,广州510006)
0 引言
气象灾害频繁多发且对人类造成的损失不可估量,因此需要做好灾前预警和灾后应急处理。相比其他气象灾害,暴雨灾害和台风灾害发生频率较高且造成影响较大。互联网网页中存在许多与气象灾害相关的文本信息,这些信息复杂多样且更新频率快。为了在众多网页中高效、准确地获取互联网上的暴雨灾害和台风灾害信息,许多学者开始关注研究网络主题爬虫[1-2]。
主题爬虫研究的两个关键问题为主题描述和爬虫方法。Du 等[3]使用概念背景图描述主题,但是背景图的大多数构造方法依赖于早期训练结果或用户的历史爬虫信息,若用户知识储备不够会影响背景图的质量。费晨杰等[4]通过隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型训练主题文档扩充主题词。LDA能有效识别大规模文档集或语料库潜藏的主题信息,但是对于描述单个主题效果不好且工作量大。
主题爬虫方法主要包括:1)传统启发式爬虫方法。这类爬虫方法一般遵循两种搜索策略,即基于网页内容的搜索策略和基于链接结构的分析策略。Shark-Search 算法[5]、基于Bayes算法[6]的概率模型和基于语义相似性的向量空间模型[7]都是基于网页文本分析的评价方法。此类方法考虑了网页的文本内容与主题的相关性,但缺乏评估链接结构对相关性的影响。目前PageRank 算法[8]、基于超链接分析的主题搜索(Hyperlink-Induced Topic Search,HITS)算法[9]是基于链接结构的评价方法。Yuan 等[10]在经典PageRank 算法基础上提出了一种基于作弊相似性和相关性的改进PageRank 算法。Zhang等[11]通过对Hub值和Authority值的计算方法进行优化,提出了一种HITS 算法的改进版本I-HITS 算法。基于链接结构的分析策略侧重于评价网页中链接的权威性,容易出现“主题漂移”现象[12]。2)智能优化爬虫方法。最常见的智能优化爬虫方法有广度优先搜索(Breadth First Search,BFS)算法[13]和最佳优先搜索(Optimal Priority Search,OPS)算法[14]。BFS算法将网页中的超链接提取出来,利用先进先出队列辅助搜索网页,该方法虽然保证了网络覆盖率,但却忽视了链接的优先权;OPS 算法优先抓取价值度高的链接,属于一种贪心策略,容易陷入局部最优而错过更多与主题相关的网页。此外,遗传算法[15]、蚁群算法[16]等一些全局搜索算法也被应用于爬虫中。这类方法中的一些操作算子(如交叉、变异)应用不完全,只是重复选择操作,并未产生新的链接,因此效果往往一般。最近,东熠等[17]将寻找一组Pareto 最优链接的方法融入蚁群算法,提出了一种基于多目标蚁群算法的主题爬虫策略;但是由于蚁群算法固有的基于信息素的寻优方式,以及基于多目标的爬行方法难以保证链接分布的多样性和均匀性,所以仍然容易陷入局部最优。
爬虫作为一种常用的互联网数据获取工具,尽管近年来已经积累了大量可用的开源爬虫框架系统,如Scrapy、Pyspider、WebCollector 等,但是普遍存在爬准率不高的缺陷。为克服传统主题爬虫方法中主题描述的不足和开源爬虫系统爬准率不高的缺陷,本文采用领域本体描述暴雨灾害和台风灾害主题,并提出一种基于页面主题相关度、锚文本主题相关度以及链接指向网页PR(PageRank)值的链接综合优先度的评估方法;针对目前智能爬虫方法容易迂回搜索、陷入局部最优的缺陷,本文将禁忌搜索策略引入主题爬虫,并对其关键搜索机制(禁忌对象和接受原则)进行改进,通过将改进的禁忌搜索策略(Improved Tabu Search,ITS)与本体(Ontology)技术相结合,提出了一种融合本体和改进禁忌搜索策略的主题爬虫方法On-ITS。On-ITS 爬虫方法利用ITS 能尽量避免爬虫迂回搜索,从而尽可能拓宽有效搜索途径,是一种较理想的具有全局搜索能力的智能爬虫方法。实验结果表明,本文的On-ITS网络主题爬虫方法能爬取更多与主题相关的网页。
1 主题相关度计算
主题爬虫首先要解决主题描述问题,然后构建主题词权重向量和网页文本特征词权重向量,并应用向量空间模型(Vector Space Model,VSM)分别计算页面主题相关度和锚文本主题相关度以及链接指向网页的PR值,最后综合分析等待队列中链接的综合优先度来评价链接。
1.1 构建主题词权重向量和网页文本特征词权重向量
1.1.1 主题语义权重向量获取
Gruber 在1993 年将本体(Ontology)引入计算机科学与信息科学领域,本体能够实现特定领域中某些概念及其相互之间关系的形式化表达,不仅可以解决传统主题描述存在的未考虑语义的问题[4],且相比目前常用的主题描述方法(根据领域专家经验给出主题词)[18]能更准确地描述主题。本文在没有结构化主题词表的情况下,在CNKI数据库中分别以暴雨灾害和台风灾害为主题检索核心论文,抽取最能反映文章内容的标题、关键词和摘要作为领域术语候选集合,并利用ICTCLAS2016分词系统进行分词处理,接着利用形式概念分析(Formal Concept Analysis,FCA)[19]和 本 体 Web 语 言(Ontology Web Language,OWL)形成本体结构,最后使用Protégé 将本体进行可视化。图1为暴雨灾害本体关系图,图2为台风灾害本体关系图,图中均包含多个概念和多种语义关系。
根据本体的结构特征,综合语义距离IFDis、概念密度IFDen、概念深度IFDep、概念重合度IFCoi和概念语义关系IFRel五项影响因子来衡量概念间的语义相似度值[20-21]。IFDis、IFDen、IFDep以及IFCoi的计算方法参见文献[21],与文献[21]中定义的概念语义关系不同的是,本文除了考虑到同义(Synonym)关系和继承(Is-a)关系外,还考虑引发(Includes)关系。计算概念C1和C2语义关系影响因子IFRel的公式如下:

其中:L 表示概念C1和C2之间最短路径上的边数;Ci表示路径上第i个概念;V(Ci,FCi)表示概念Ci与其祖先概念FCi之间的有向边权重。
综合考虑以上所有影响因子,定义概念C1和C2的语义相似度值为:
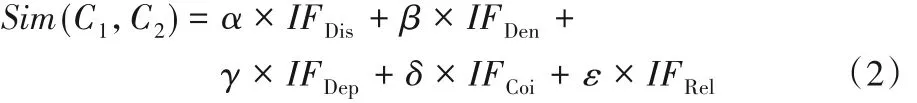
其中:α、β、γ、δ、ε的总和为1。
假设主题关键词集合为t =(t1,t2,…,tn),n 表示描述主题的主题词数量。根据式(3),主题语义权重向量为:
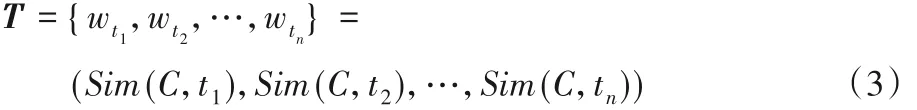
其中,wti(i = 1,2,…,n)表示主题关键词集合中第i 个主题词的权重,即对应的主题关键词概念ti与主题概念C之间的语义相似度值Sim(C,ti)。
1.1.2 网页文本特征词权重向量获取
传统的网页文本特征词权重向量获取方法通常只考虑词频,很多学者采用的方法为词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)[22]计算模型。若某个概念(特征词)在文档中的权重大小wdi使用式(4)计算,那么网页P的特征词权重向量为
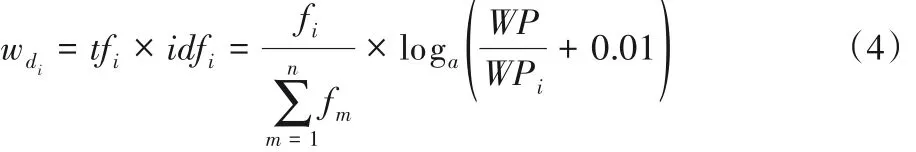
其中:fi表示第i个主题词在网页文本中出现的词频;WP 表示已爬取到的总网页数;WPi表示爬取网页中包含的第i 个主题词的网页数;a >1。
网页是一个包含HTML 标签的文本,网页的所有内容均写在标签内部,主题词出现在不同标签中的权重是不一样的。因此,本文采用文献[18]中的方法设置标签位置权重系数,将HTML标签分为5组,并给予主题词在不同标签组中的权重系数为Wk(k = 1,2,…,K,K = 5)。概念di在网页文本中的权重大小wdi可以使用式(5)表示。
其中:wfi,k表示第i 个主题词在网页文本的第k 组标签的词频;WFi,k表示第i个主题词在第k组标签上的词频。
1.2 文本主题相关度计算
本文采用VSM 计算主题语义权重向量T与网页P的文本特征词权重向量D的主题相关度值,如式(6)所示。
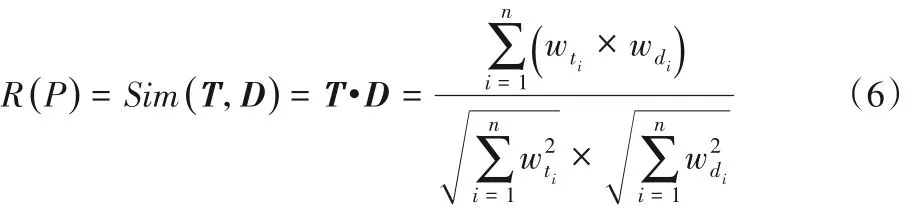
设网页的文本主题相关度的阈值为φ,如果R(P)>φ,则认为网页P与主题相关。
1.3 网页PR值及链接综合优先度计算
PageRank 算法是反映未访问链接价值的重要算法,本文为了克服传统PageRank 算法存在的“主题漂移”现象,将锚文本主题相关度融入到PageRank 算法中,提出一种改进的网页P的PR值计算公式:
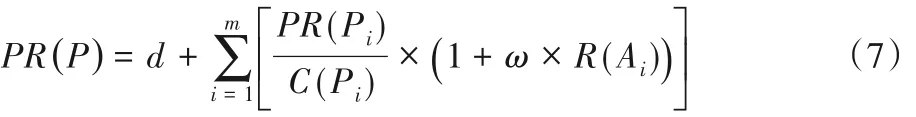
其中:ω 为调节因子;d 为阻尼系数(本文设置为0.2);Pi表示指向网页P 的第i 个入链网页,PR(Pi)表示网页Pi的PR 值,C(Pi)表示网页 Pi出链的总数;R(Ai)表示 Pi对应的链接锚文本Ai的主题相关度,由于锚文本与网页文本不同,其没有位置权重信息,因此本文中锚文本特征词权重采用式(4)计算,锚文本的主题相关度采用式(6)计算。
综合分析链接l 指向网页P 的PR(P)值、链接l 的网页文本主题相关度以及链接的锚文本主题相关度,得到该链接的综合优先度p(l):
p(l)= μ1× PR(P)+
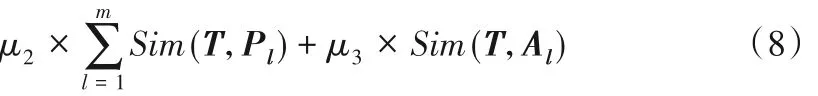
其中:m 表示链接l 入链网页的数量;Pl为链接l 指向的网页文本特征词权重向量;Al为链接l对应的锚文本特征词权重向量;μ1+ μ2+ μ3= 1。
对于每一个未访问的链接,若其综合优先度大于预先设定的阈值η,则被认为是合格链接,将其加入等待队列;否则舍弃该链接。
2 基于On-ITS策略的主题爬虫方法
2.1 禁忌搜索算法
TS 算法[23]是一种超启发式算法,由美国科罗拉多大学教授Fred Glover 在1986 年提出。TS 算法是一种局部邻域搜索算法,其基本流程是:给定一个初始解X,从X 的邻域中确定若干候选解N,若最优候选解N 优于X,则忽略N 的禁忌属性,将N 替换成为新的当前解和当前最优解,且将其对应的对象放入禁忌表中,更新禁忌表中各对象的任期;否则在N中选出未加入禁忌表的最优解作为新的当前解X,将其对象加入禁忌表中并更新禁忌表;如此进行上述过程的迭代搜索,直到满足算法终止条件。
2.2 链接的邻域集和扩展邻域集
定义1 邻域集。对于当前链接Curl,称Curl指向网页上所有链接的集合为Curl的邻域集,记为N(Curl)。
定义2 候选邻域集。对于当前链接Curl,若其指向网页上的链接的综合优先度大于设定的阈值η,则这样的链接组成的集合为Curl 的候选邻域集,记为C(Curl)。显然,C(Curl) ⊆ N(Curl)。
定义3 扩展邻域集。对于当前链接Curl,若其所在网页上的链接的综合优先度大于阈值η,则这样的链接组成的集合为Curl的扩展邻域集,记为E(Curl)。
在整个爬虫过程中,常规的邻域搜索通常只考虑链接所指向网页上的链接。但是,为了利用On-ITS 方法扩大爬虫的搜索范围,在访问当前链接Curl 的候选邻域集的迭代次数达到设定的次数后,则从Curl 的扩展邻域集中重新选择一个链接作为新的当前链接。
2.3 禁忌对象
当采用N(Curl)更新爬取队列时,为了避免算法迂回搜索,防止在N(Curl)中反复挑选而找不到合适的链接,则将Curl 放入禁忌表中,暂时禁止操作,设置为禁忌对象。然而,通常的禁忌搜索算法设置禁忌对象是从邻域集中选择综合优先度最高的链接,若其优先度高于“best so far”链接的优先度,则无视该链接的禁忌属性,将该链接作为禁忌对象存放至禁忌表中;否则从邻域集中选择非禁忌的具有最高综合优先度的链接作为新的当前链接,并将该链接放入禁忌表中。与该策略不同,本文忽略链接Curl 原来是否是禁忌对象,只要从Curl 的候选邻域集中随机选择出不同的5 个(或所有)链接的综合优先度都没有Curl 的优先度高,则将Curl 设置为禁忌对象,并从Curl 的扩展邻域集中随机挑选一个非禁忌的链接作为新的当前链接。显然,当再次从扩展邻域集中选择链接时,就不会再选择Curl,从而能有效地搜索不同的路径,给当前局部搜索更多的寻优机会。本文中,禁忌长度设置为5。
2.4 藐视准则与改进的接受原则
藐视准则是指在某禁忌链接的综合优先度大于已访问所有链接的最大综合优先度时,则无视其禁忌属性,接受该链接为当前链接。在通常的禁忌搜索方法中,当不存在某禁忌链接的综合优先度优于已访问过的所有链接的最大综合优先度时,就从当前链接Curl的N(Curl)中选择非禁忌的综合优先度p 最高的链接为当前链接。这种策略没有给接近最高优先度的链接足够机会从它出发爬取它的子链接,容易陷入局部最优。本文在留藐视准则的情况下,对这种Curl 的接受原则作了如下改进:
1)若从当前链接 Curl 的 C(Curl)中选择的链接 Surl 是禁忌对象,且它的p 大于已访问过的所有链接的最大综合优先度时,则解禁Surl,并将Surl设置成当前链接。
2)若链接Surl是禁忌对象,且它的p小于已访问过的所有链接的最大优先度时,则从Curl的N(Curl)中重新随机选择一个链接作为当前链接。
3)若链接Surl 不是禁忌对象,且Surl 综合优先度大于当前链接的优先度,将设置Surl为当前链接Curl。
4)若链接Surl 不是禁忌对象,且Surl 综合优先度小于当前链接的优先度,则从Curl的N(Curl)中随机选择一个链接作为当前链接。
2.5 主题爬虫设计
融合本体和改进禁忌搜索策略(On-ITS)的主题爬虫具体步骤如下:
1)选择30 个初始种子链接作为种子链接群,将之放入等待队列WaitQueue中,令Hurl为种子链接群中综合优先度最高的链接,初始化阈值φ,设置禁忌表为空。
2)在WaitQueue中随机选取一个URL作为当前链接Curl,令该链接访问次数T = 1。
3)从Curl 的候选邻域集C(Curl)中随机挑选一个链接Surl,令 C(Curl) = C(Curl) -{Surl}。
4)如果Surl是禁忌对象,则:
如果p(Surl) >p(Hurl),则从禁忌表中释放Surl,令Hurl =Surl,Curl = Surl,同时将禁忌表中各禁忌对象的任期减1,释放任期为0的对象,转6);否则令T = T + 1,转5)。
否则,如果 p(Surl) > p(Curl),则令 Curl = Surl,同时将禁忌表中各禁忌对象的任期减1,释放任期为0 的对象,此时若p(Surl) >p(Hurl),则 令 Hurl = Surl,转 6) ;否 则 ,令T = T + 1,转5)。
5)如果T > 5,则将Curl加入到禁忌表中,并在E(Curl)中随机挑选一个链接重新作为当前链接Curl,转3);否则当前链接Curl保持不变,转3)。
6)将Curl 指向网页保存到下载页面集合PageDown 中,Curl放入 WaitQueue。
7)计算链接Curl 指向页面的主题相关度,如果该页面主题相关度大于阈值φ,则将之保存到主题相关网页集合PageSave中。
8)如果PageDown 中下载的网页数量达到15 000,则算法结束;否则,转2)。
3 实验结果与分析
实验环境:处理器为Intel Core i5-6500;开发工具为Eclipse4.6.1+JDK1.8.0;本体编辑工具为Protégé 5.2;分词工具为ICTCLAS2016。采用Java语言编程实现爬虫系统。
爬行主题:暴雨灾害和台风灾害。
实验数据:分别以暴雨灾害和台风灾害为主题词在搜索引擎上搜索,各选取排列靠前的50 个链接构成候选链接群,再由专家进行筛选,得到能分别充分表现暴雨灾害主题和台风灾害主题特征的各30个链接作为爬虫的初始种子链接群。
实验参数:在爬虫算法中,参数的设置会直接影响实验结果。经反复实验后,确定参数设置如下:φ = 0.62,τ = 34,α =0.8,β = 0.04,γ = 0.06,δ = 0.03,ε = 0.07,η = 0.15,ω = 0.6,μ1= 0.55,μ2= 0.25,μ3= 0.20。
3.1 算法评价指标
评价爬虫算法的指标主要有爬全率(Recall)和爬准率(Accuracy),计算公式如下:

其中:LG 表示已被下载的网页中与主题相关的网页数;TG 表示互联网中与爬行主题相关的网页总数;DG表示已爬取的网页总数。由于互联网中与某一主题相关的网页总数难以统计,因此本文选择爬准率来评价算法。此外,本文还将使用下载网页的平均相关度AR 和标准差SD 测试算法的性能,计算公式见式(11)、(12)。
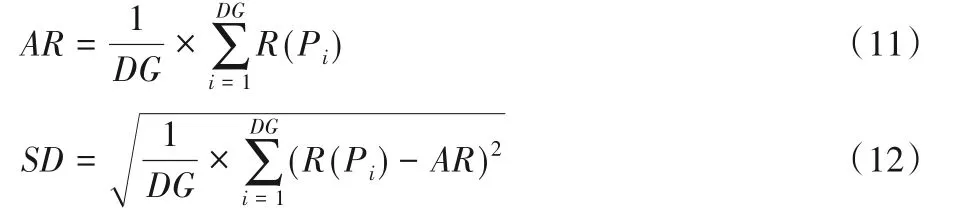
其中R(Pi)为网页Pi的主题相关度。
3.2 结果分析
本文采用相同的种子链接群与评价标准,分别对比测试了本文提出的基于On-ITS 策略的主题爬虫方法、未加本体的ITS 方法与宽度优先搜索(Breadth First Search,BFS)算法[13]、最佳优先搜索(Optimal Priority Search,OPS)算法[14]和模拟退火(Simulated Annealing,SA)算法[18]。图 3(a)、(b)分别为暴雨灾害主题和台风灾害主题在五种不同爬虫方法下的爬准率。从图3可以看出,当爬取的网页数量大于7 000时,On-ITS的爬准率明显高于其他算法。当爬取的网页数量达到15 000时,在暴雨灾害主题爬虫中,BFS 算法的爬准率在20%左右,OPS算法在60%左右,SA 算法在70%左右,ITS方法在74%左右,On-ITS 方法的爬准率稳定在78%左右;在台风灾害主题爬虫中,BFS 算法的爬准率在30%左右,OPS 算法在70%左右,SA 算法在75%左右,ITS 方法在78%左右,而On-ITS 方法的爬准率稳定在82%左右。
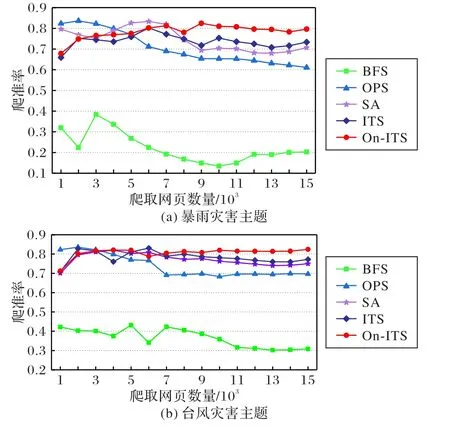
图3 BFS、OPS、SA、ITS与On-ITS主题爬虫方法爬准率比较Fig.3 Accuracy comparison of BFS,OPS,SA,ITS and On-ITS focused crawler methods
图4 (a)、(b)分别为暴雨灾害主题和台风灾害主题的五种不同主题爬虫方法爬取相关网页数量的对比。由图4 可知,在爬取相同网页数量时,On-ITS方法相较ITS方法、SA算法和OPS 算法能爬取更多与主题相关的网页,而BFS 算法爬取的相关网页数量是最少的。
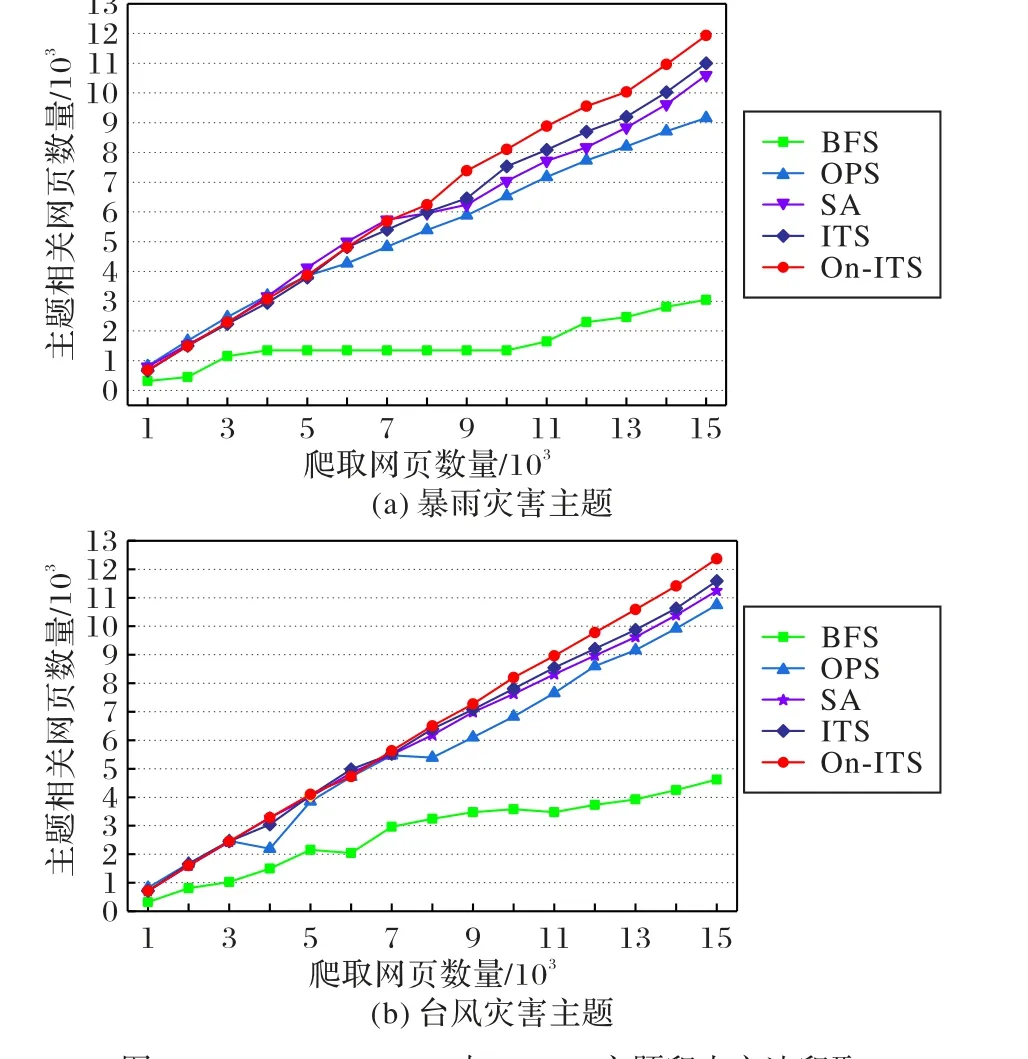
图4 BFS、OPS、SA、ITS与On-ITS主题爬虫方法爬取相关网页数量比较Fig.4 Comparison of related Web pages crawled by BFS,OPS,SA,ITS and On-ITS focused crawler methods
图5 (a)、(b)分别为暴雨灾害主题和台风灾害主题的五种主题爬虫方法爬取网页的平均相关度对比。在整个爬虫过程中,On-ITS方法爬取的网页平均相关度都比较高且比较稳定,均优于对比算法,由此看出,On-ITS方法比其他四种算法抓取网页的质量更高。
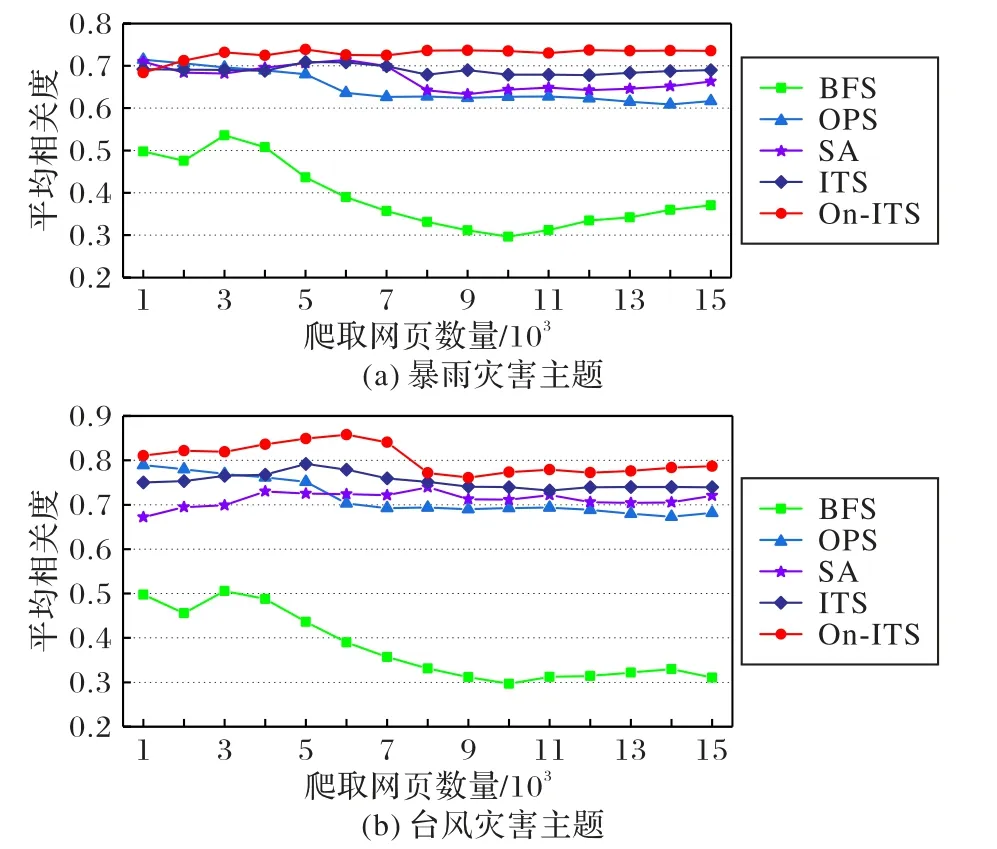
图5 BFS、OPS、SA、ITS与On-ITS主题爬虫方法爬取网页的平均相关度比较Fig.5 Comparison of average relevance of Web pages crawled by BFS,OPS,SA,ITS and On-ITS focused crawler methods
图6 (a)、(b)分别为暴雨灾害主题和台风灾害主题的五种主题爬虫方法爬取网页相关度的标准差比较。如图6 所示,随着爬取网页数量的增加,On-ITS 方法的标准差在减小。当网页数达到15 000时,在暴雨灾害主题爬虫中,On-ITS方法的标准差在 0.11 左右,而 BFS、OPS、SA、ITS 的标准差分别在0.24、0.23、0.19、0.16 左右;在台风灾害主题爬虫中,On-ITS方法的标准差在0.13 左右,而 BFS、OPS、SA、ITS 的标准差分别在0.31、0.27、0.2、0.15左右,由此可见On-ITS方法的稳定性也比较好。
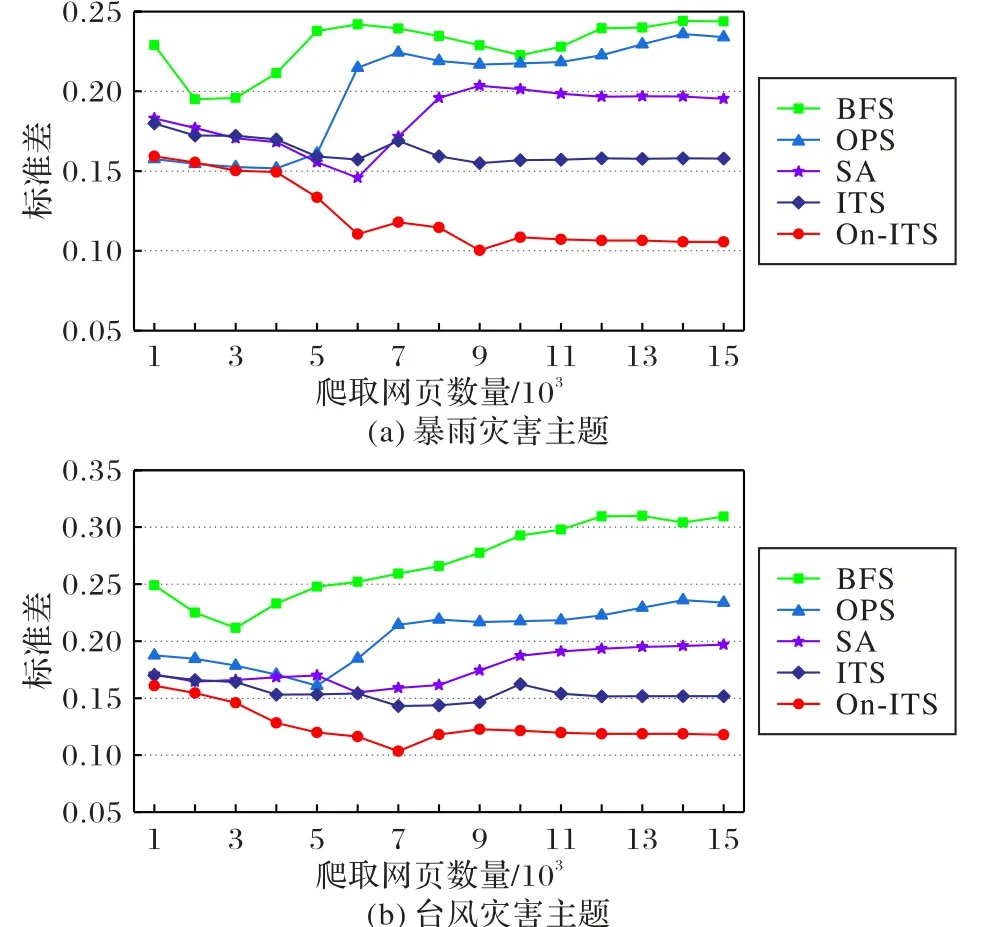
图6 BFS、OPS、SA、ITS与On-ITS主题爬虫方法爬取网页的相关度标准差比较Fig.6 Comparison of relevance standard deviation of Web pages crawled by BFS,OPS,SA,TS and On-ITS focused crawler methods
从图3~6 不难看出,当爬取网页数量达到8 000 以后,各爬虫方法的性能优劣开始显现。设定爬取网页的目标数量为15 000 是为了显示各算法性能逐渐趋于稳定的过程。事实上,随着爬取网页数量的增加,On-ITS相较其他几个算法的优势愈加明显。
实验结果表明,由于BFS 算法没有对网页的主题相关度进行预判,所以整个爬虫过程中BFS 算法的爬准率偏低。OPS 算法每次都下载相关度最高的网页,因此在前期的爬虫过程中其爬准率比较高,但随着爬取网页数量的增加,OPS算法的贪心策略导致其在后期陷入了局部最优。SA 算法采用一定的概率来选择与主题不相关的网页,具有全局搜索的优点;但该算法通过人工手动给出关键词的主题描述方式,对主题描述不够准确,且也有可能重复访问已搜索过的链接,因此会影响它的结果。本文的On-ITS 方法采用本体描述主题,构建的暴雨灾害本体(图1)和台风灾害本体(图2)分别包含46个和41 个主题词(属于小规模本体),对主题的描述相对准确;而且统计显示,采用本体计算链接文本主题相关度平均耗时5 320 169 ns,因此对算法的效率影响并不大。通过与未采用本体描述主题的ITS 算法的对比结果表明,构建本体不仅对爬虫系统的进程影响不大,而且能有效提高爬虫爬取网页的相关度。On-ITS 方法不仅能爬取更多与主题相关的网页,具有较高的爬准率,爬虫性能也比较稳定。
4 结语
本文分别以暴雨灾害和台风灾害为主题,提出了一种融合本体和改进禁忌搜索策略的主题爬虫方法On-ITS。本文利用本体语义相似度计算主题语义向量,基于HTML 网页文本特征位置加权方法计算网页文本特征向量,并结合链接的锚文本相关度和网页的PR 值计算链接的综合优先度。利用On-ITS方法进行全局搜索,能防止爬虫陷入局部最优,尽可能避免爬取已访问过的链接,从而提高爬虫系统的性能。最后对比了 BFS 算法、OPS 算法、SA 算法与本文提出的 ITS 方法和On-ITS 方法,结果表明On-ITS 方法有较高的爬准率和较好的稳定性。在下一阶段中,将在主题描述方法和主题爬虫效率方面作进一步的研究。
