基于YOLO v3算法改进的交通标志识别算法
2020-09-04江金洪鲍胜利史文旭韦振坤
江金洪 ,鲍胜利 ,史文旭 ,韦振坤
(1. 中国科学院成都计算机应用研究所,成都610041; 2. 中国科学院大学,北京100049)
0 引言
目前,交通标志在现实生活中随处可见,道路上的减速限行、安全警示、车辆引流等交通标志为人们安全便捷出行提供了强有力的保障。针对理想情况下的交通标志识别算法研究已取得较高的成就,但由于车辆在实际道路上获取的图片容易受到光照强度、天气状况等因素的影响,且交通标志目标往往只占整张图片的极小部分,这使得交通标志识别在车辆真实行驶过程中的应用存在诸多挑战[1]。因此,真实自然条件下交通标志识别的研究具有重要价值。
传统交通标志识别算法主要利用图像处理技术对图像的颜色、形状、边缘等进行提取特征和分类。文献[2]中提出了在 HSV(Hue,Saturation,Value)空 间 训 练 自 适 应 增 强(Adaptive boosting,Adaboost)分类器的检测算法,该方法具有较好的鲁棒性和较高的准确率,但检测速度较低;文献[3]中基于CIELab 和YCbCr 空间的方向梯度直方图(Histogram of Oriented Gradient,HOG)特征训练支持向量机(Support Vector Machine,SVM)分类器,但该方法泛化能力较弱;文献[4]中根据交通限速标志的颜色和形状特征,提出了一种基于车载视频的交通限速标志的检测和识别算法;文献[5]中则提出了基于深度森林的交通标志识别算法。上述算法虽然在准确率上不断提高,但它们在实时性和准确率的平衡性上依然难以达到卷积神经网络(Convolutional Neural Network,CNN)所能达到的效果。
自 2012 年 AlexNet[6]在 ImageNet[7]图像分类比赛中获得巨大成功后,CNN 便广泛应用于计算机视觉领域。近几年由于各种新型CNN 结构不断地被提出,使得目标检测算法得以迅猛发展。当前,深度学习目标检测算法可以分为两类,以Faster R-CNN(Faster Region-CNN)[8]为代表的双阶段目标检测算法和以 YOLO(You Only Look Once)[9]、单次多框检测(Single Shot multiBox Detector,SSD)算法[10]为代表的单阶段目标检测算法。由于CNN 在计算机视觉领域存在速度快、准确度高的优势,使得它在交通标志识别任务中得到广泛应用。2011 年,Sermanet 等[11]在德国交通标志(German Traffic Sign Recognition Benchmark,GTSRB)数据集[12]上实现了神经网络识别交通标志首次超过人工的效果,仅有0.56%的错误率;2016 年,腾讯公司联合清华大学创建了一个接近真实驾驶环境的数据集TT100K(Tsinghua-Tencent 100K)[13],并训练了两个卷积网络用于识别与分类,其准确率能达到88%,召回率能达91%;2018 年,Wang 等[14]提出了一个级联掩码生成框架来解决分辨率与小目标检测之间的矛盾,通过多次对感兴趣区域(Region Of Interest,ROI)的回归,得到了定位更准确的目标框及更高的精度。
深度CNN 虽然能提升识别算法的准确率和实时性,但其计算量和参数量都相对比较大,对硬件需求较高,且目标框交并比(Intersection over Union,IoU)计算与边框回归损失函数的优化方向并不完全等价,会使得目标框定位存在误差。为减少算法的计算量和提高目标框的定位精度,本文提出了一种深度可分离的YOLO v3改进算法IYOLO(Improved YOLO v3),主要工作如下:
1)在YOLO v3[15]的网络结构基础上引入深度可分离卷积(Depthwise Separable Convolution,DSC)[16],使其在不损失准确率的基础上,减少了模型参数数量和计算量;
2)为提高算法的准确率和目标框定位精度,在原YOLO v3损失函数的基础上引入了广义IoU(Generalized IoU,GIoU)损失[17]和 Focal 损失(Focal Loss)[18],使设计的损失函数优化方向与目标框最大IoU 计算方向一致,同时在一定程度上解决了类别之间的不均衡问题,提高了检测准确率。
1 IYOLO网络结构
1.1 YOLO v3
YOLO v3 算法是基于 YOLO、YOLOv2[19]算法的改进算法,它在检测速度和精度上均有很大的提高。YOLO 算法最早是由 Redmon 等[9,15,19]提出,其思想是将整张图片作为神经网络的输入,并在最后输出层直接输出回归的目标框位置和类别信息。不同于Faster R-CNN 算法需要在中间层生成候选区域,YOLO 算法采用直接回归的思路,实现了端到端的结构,这使得算法在输入图片大小为448× 448 时每秒帧数(Frames Per Second,FPS)能达到45,其精简版本Fast YOLO的FPS 甚至可达到155,检测速度远远快于Faster R-CNN。针对YOLO 算法存在对小目标和密集目标检测效果差以及泛化能力较弱的问题,作者在之后又逐渐提出了YOLO v2 和YOLO v3 两种升级版本算法,其中YOLO v3 算法由于其速度快、准确率高,现已广泛应用于工业检测。
YOLO v3 算法使用一种残差神经网络(Darknet-53)作为特征提取层,在花费更少浮点运算和时间的情况下达到与ResNet-152[20]相似的效果。在预测输出模块,YOLO v3 借鉴FPN(Feature Pyramid Network)[21]算法思想,对多尺度的特征图进行预测,即在三种不同尺度上,每个尺度上的每个单元格都会预测出三个边界框,其结构示意图如图1所示。
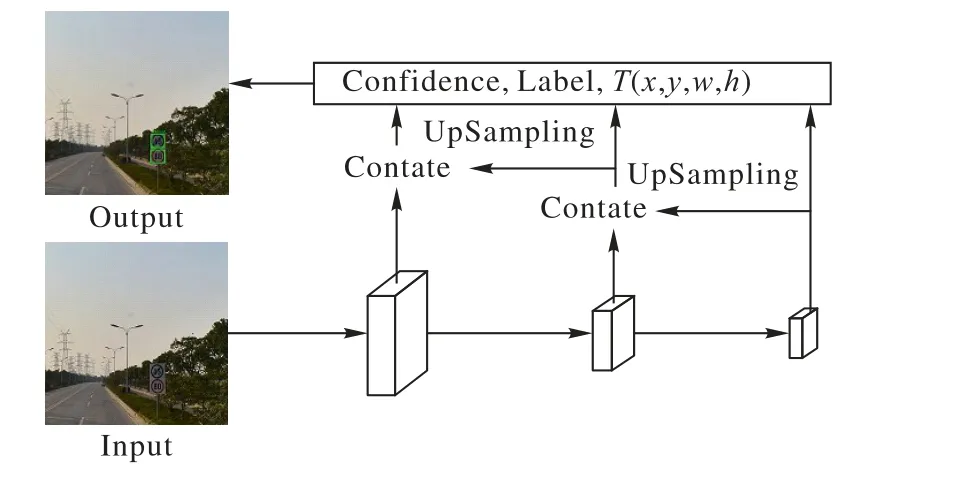
图1 YOLO v3结构示意图Fig. 1 Schematic diagram of YOLO v3 structure
自 YOLO v2 算法起,YOLO 算法引入 anchor box,初始 9 个anchor box 的大小由K-Means 算法对所有真实目标框的长宽聚类得到,网络预测输出相对于anchor box 偏移量分别为tx,ty,tw,th,则边界框真实位置如式(1)所示:

其中:(cx,cy)为当前单元格相对于图像左上角的偏移值,为对应尺度anchor box的长和宽。
1.2 深度可分离卷积
在使用传统卷积计算时,每一步计算都会考虑到所有通道的对应区域的计算,这使得卷积过程需要大量的参数和计算。深度可分离卷积则是将分组卷积思路做到极致(每一通道作为一组),先对每一通道的区域进行卷积计算,然后进行通道间的信息交互,实现了将通道内卷积和通道间卷积完全分离。
在传统卷积算法中,输入为H×W×N特征图与C个尺度为k×k×N的卷积核进行卷积计算时,会得到输出特征图大小为,在不考虑偏置情况下,参数量为N×k×k×C,计算量为H×W×k×k×N×C,其卷积过程如图2所示。
在深度可分离卷积中,将卷积过程分为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两部分。深度卷积是对输入的同一通道类进行尺寸为k×k的卷积,通道间并没有信息交互,提取到的是一个通道内的特征信息,其参数量为N×k×k,计算量为H×W×k×k×N。逐点卷积则是利用C个尺寸大小为1× 1×N的卷积对通道间的信息进行融合,在实现通道间通信的同时可调控通道数量,其参数量为N× 1 × 1 ×C,计算量为H×W× 1 × 1 ×N×C,其卷积过程如图3所示。
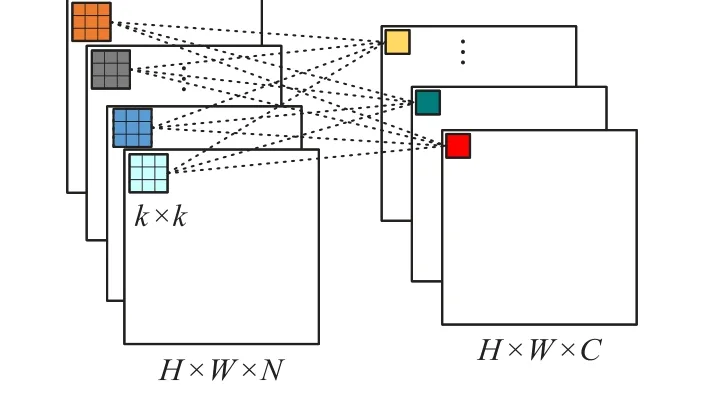
图2 标准卷积过程Fig. 2 Standard convolution process
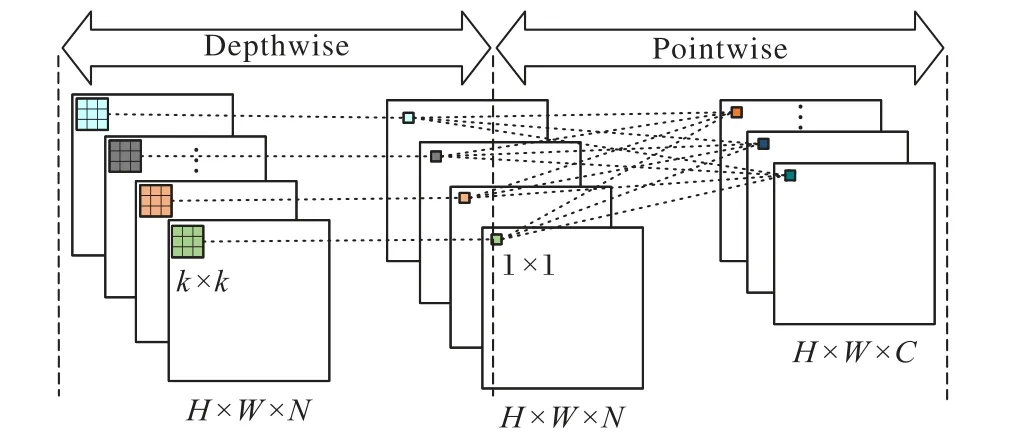
图3 深度可分离卷积过程Fig. 3 Depthwise separable convolution process
1.3 IYOLO网络结构
IYOLO整个网络结构如图4所示。
为解决YOLO v3算法在高分辨率交通标志图片上参数量较大、实时性较差的问题,提出利用深度可分离卷积重新构建网络结构。相对于标准卷积模块,深度可分离卷积模块(Depthwise Separable Convolution Module,DSC Module)如图5所示。
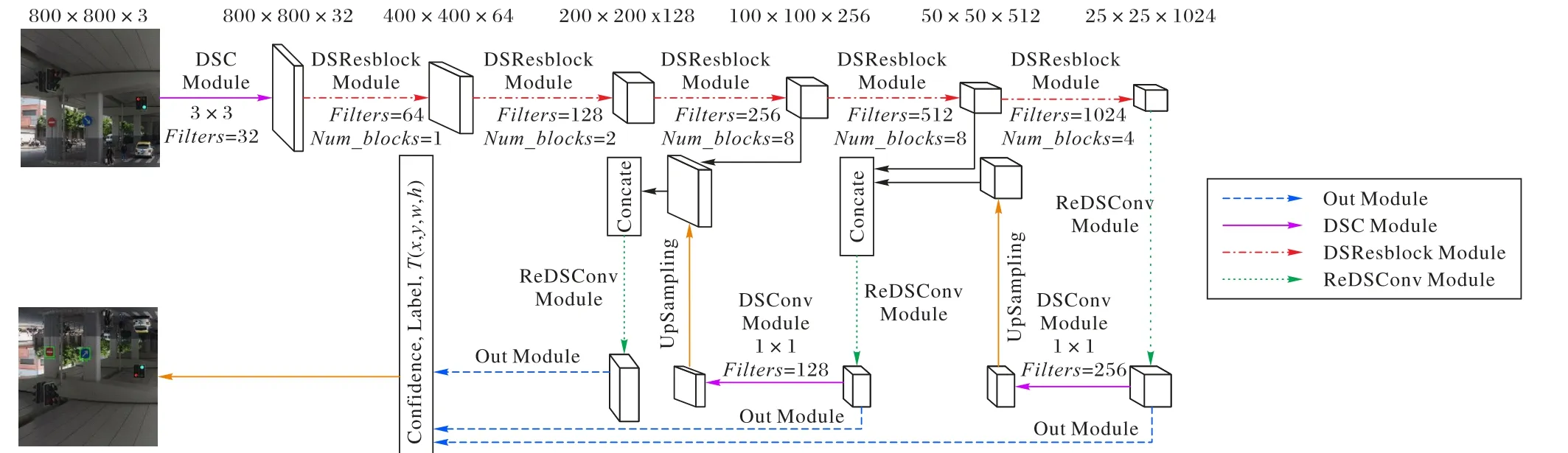
图4 IYOLO结构示意图Fig. 4 Schematic diagram of IYOLO structure
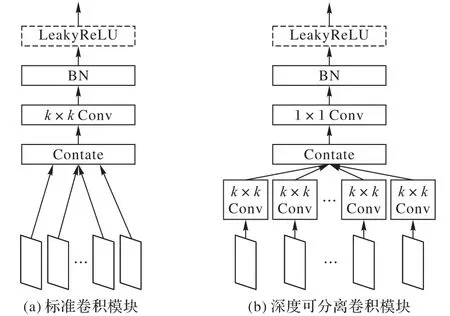
图5 标准卷积模块和深度可分离卷积模块Fig. 5 Standard convolution module and depthwise separable convolution module
网络结构的设计上依然借鉴了ResNet 网络残差的思想,主体网络由多个DSResblock 模块组成。DSResblock 模块结构如图6 所示,其中虚线框内的结构会被重复Num_blocks-1次。
IYOLO 的最后三层输出部分主要由ReDSConv 模块和Out模块两部分组成,其结构如图7所示。
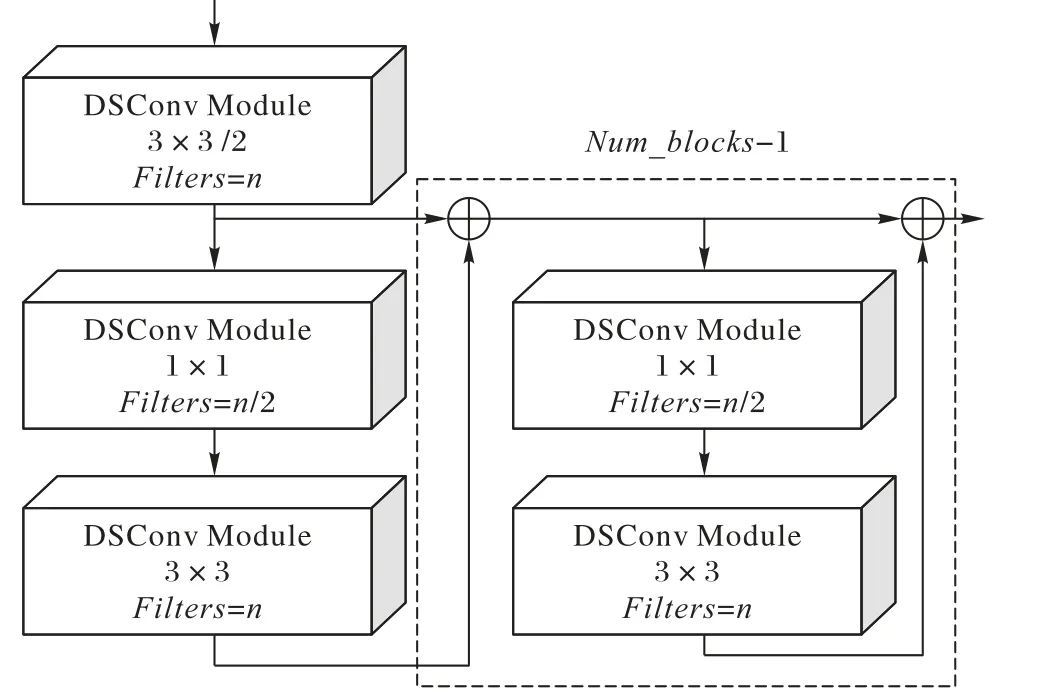
图6 深度可分离残差模块Fig. 6 Depthwise separable residual module
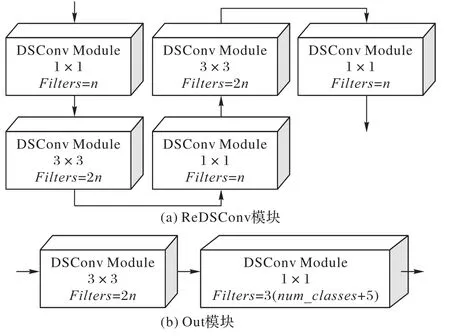
图7 输出部分示意图Fig. 7 Schematic diagram of output section
2 IYOLO损失函数
YOLO v3算法在目标框坐标回归过程中采用的是均方误差(Mean Square Error,MSE)损失函数,在类别和置信度上使用了交叉熵作为损失函数,其损失函数如式(2)所示。
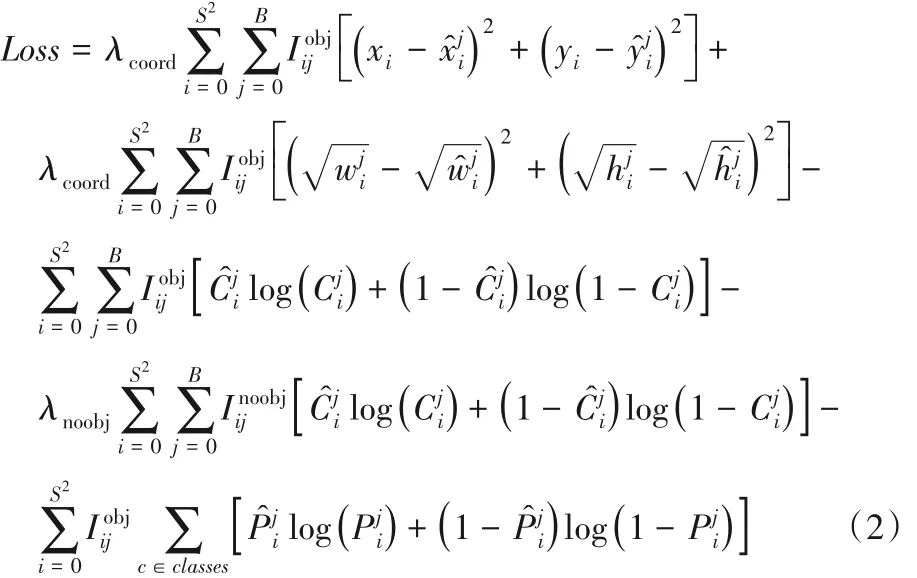
其中:λcoord、λnoobj分别表示坐标损失权重和不包含object 的置信度损失权重表示第i个单元格的第j个box 是否负责该objec(t1 或0)表示预测目标框坐标、置信度和类别表示真实目标框坐标、置信度和类别。
但以MSE为目标框坐标的损失函数会存在两个缺点:
1)L2损失(即MSE 损失)值越低并不等价于IoU 值越高,如图8 所示,三对目标框具有相同的L2损失值,但IoU 值却不一样;
2)L2损失值对目标框尺度比较敏感,不具有尺度不变性,如在式(2)中,对w、h值开方处理就是为缓解目标框尺度对L2损失值的影响。
IoU是在目标检测算法常用的距离测量标准,其值的计算如式(3)所示,其中A、B分别为两目标框面积。

针对于MSE损失函数存在的缺陷,提出利用GIoU损失作为目标框坐标回归的损失。与IoU 相似,GIoU 也是一种距离度量标准,其值的计算如式(4)所示,其中Ac为两目标框的最小闭包区域面积,U为两目标框的相交面积。

GIoU损失的计算如下所示:

GIoU 作为距离度量标准,满足非负性、不可分的同一性、对称性和三角不等性;GIoU 值是比值,因此对目标框尺度并不敏感,具有尺度不变性;由式(4)所知,GIoU 的上限是IoU,当两目标框越接近且形状相似时,GIoU 越接近IoU;即有当GIoU值越高时,IoU值越高。
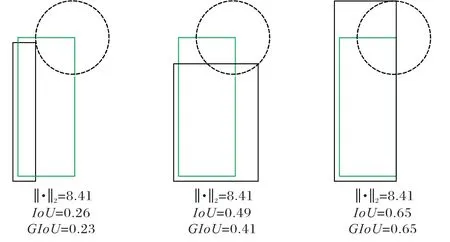
图8 三种指标关系示意图Fig. 8 Schematic diagram of relationship among three indicators
为进一步提高识别的准确率,在对置信度设计损失函数时采用了Focal 损失替换交叉熵损失。Focal 损失是基于交叉熵损失的改进,主要是解决了one-stage 目标检测算法中前景类与背景类比例严重不均衡的问题。Focal 损失通过降低大量简单背景类在训练过程中所占的权重使得训练的算法模型更专注于前景类的检测。Focal损失如式(6)所示:
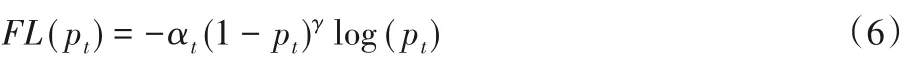
类别损失仍使用交叉熵损失如式(7)所示,其中c^是真实类别,c是预测类别。
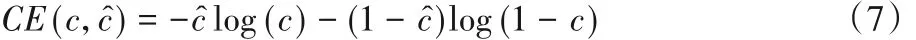
改进后的算法损失函数GFLoss如式(8)所示:
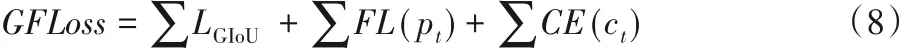
IYOLO 损失函数将GIoU 损失作为目标框坐标回归的损失,量化评测指标GIoU 为损失,这解决了原MSE 损失存在的损失优化与最大IoU 值计算方向不一致和对尺度敏感的问题。同时引入Focal损失,缓解了数据类别不均衡对检测算法的影响,并提高了算法的检测准确率。
3 实验与结果分析
3.1 实验数据集
为评估本文所提的IYOLO 算法在真实自然环境下对交通标志的检测性能,采用了清华大学与腾讯公司公开发布的TT100K 数据集。TT100K 数据集数据是在腾讯街景地图上截取并进行人工标注,其图像的分辨率为2 048× 2 048,标注类别数为221,其中包含6 107张图像的训练集和3 073张图像的测试集,覆盖了不同天气条件和不同光照下的交通标志图像。由于原始图像分辨率较大,因此在本次实验中对原图像进行了裁剪处理,裁剪后的图像尺度为800 × 800。由于数据集中各个类别之间的数据量存在严重不平衡的问题,因此本次实验只选择了数据量较多的45 类交通标志进行识别,并对训练集中数据量较少的类别进行数据扩充,随机采用了加入随机高斯噪声、亮度调整、镜像三种数据增强策略,最终使得每个类别的数据量均达3 000以上。经裁剪和扩充后,训练集包含212 384 张图片,测试集包含52 413 张图片,其中45 类交通标志类别分别是:pn、pne、i5、p11、pl40、po、pl50、pl80、io、pl60、p26、i4、pl100、pl30、il60、pl5、i2、w57、p5、p10、ip、pl120、il80、p23、pr40、ph4.5、w59、p12、p3、w55、pm20、pl20、pg、pl70、pm55、il100、p27、w13、p19、ph4、ph5、wo、p6、pm30、w32。
3.2 评测指标
本文采用平均精度均值(mean Average Precision,mAP)和FPS两个指标对算法模型进行评估。
mAP 指标通过首先计算每个类别的平均精度(Average Precision,AP),再对所有类别的平均精度求取均值得到,计算如式(9)所示。其中:TP(True Positive)为真正例,FP(False Positive)为假正例,FN(False Negative)为假负例,Nc表示第c类划分精确率P(Precision)和召回率R(Recall)的数量,p(rc)表示在c类召回率为rc时的p值。
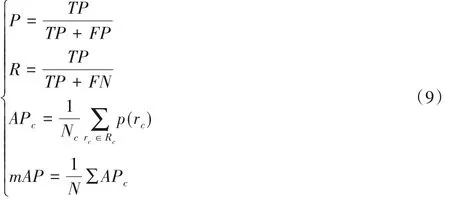
在实时检测任务中,FPS 值是极其重要的指标,是检测速度的直接体现,对任务的应用场景有直接的影响。
3.3 结果与分析
本文实验是在Ubuntu16.04 系统下进行,深度学习框架为Keras 2.1.5,所使用的显卡配置为:4 块Nvidia GeForce RTX 2080 Ti,显存为44 GB。
仅引入了深度可分离卷积后,改进的YOLO v3 算法明显优于原始YOLO v3 算法,其对比结果如表1 所示。由表1 可知,引入深度可分离卷积后的YOLO v3 算法相较于原始YOLO v3 算法在参数量和模型大小上有了较明显的优势,只占原始算法的1/5 左右,同时在mAP 指标上,改进的算法也有0.3个百分点的提升。对比实验表明,YOLO v3算法结构中大部分参数是冗余的,且将深度可分离卷积引入到YOLO v3 算法中以减少参数量的方法是可行的。

表1 引入DSC前后YOLO v3算法性能对比Tab. 1 Performance comparison of YOLO v3 algorithm before and after introducing DSC
将 IYOLO 算法与YOLO v3、SSD300、Faster R-CNN 三种典型的多尺度目标检测算法对每个类别的AP值进行对比,结果如表2 所示。同时,四种算法的检测精度、检测速度和模型大小整体性能对比结果如表3 所示。对表2 和表3 数据进行分析可知,IYOLO 算法 mAP 能达到 89%,相较于 YOLO v3[15]、SSD300[10]、Faster R-CNN[8]算法分别提升了 6.6 个百分点、25.29 个百分点、2.1 个百分点,且它在每个类别上的检测效果均优于YOLO v3、SSD300 两种算法。从检测速度上看,IYOLO 算法远远优于Faster R-CNN 算法,且相较于YOLO v3算法FPS 提升了60%,但与SSD300 算法之间还有一定的差距。而在模型大小方面,IYOLO 算法仅有原始YOLO v3 算法模型大小的1/5 左右,其参数量亦远小于SSD300 和Faster RCNN,得到极大的压缩。
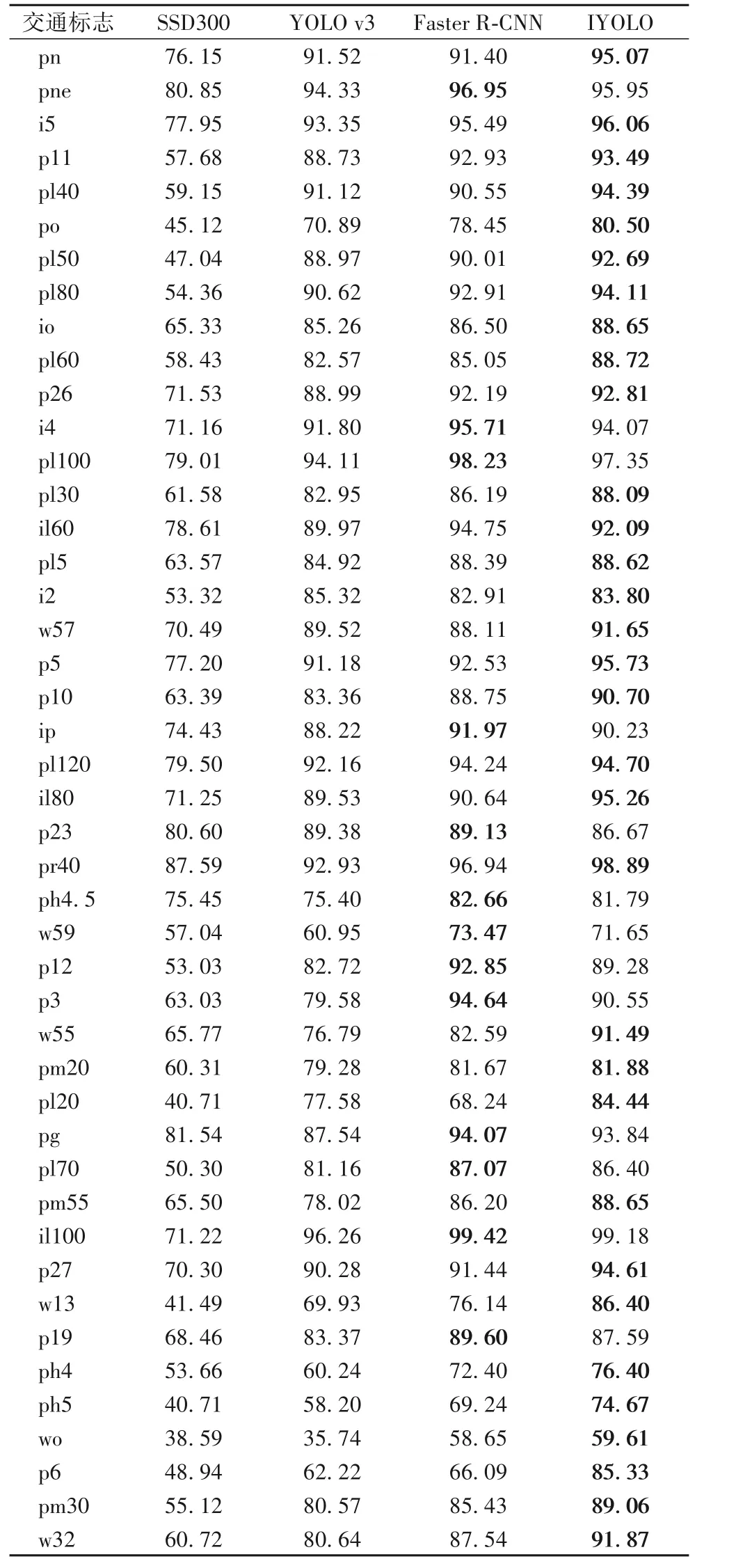
表2 四种算法的AP值对比 单位:%Tab. 2 Comparison of AP values of four algorithms unit:%
此外,本文设置了在 IoU 分别为 0.5、0.6、0.7、0.75 时,IYOLO 算法与 SSD300、YOLO v3、Faster R-CNN 三种算法在检测精度上的对比,其对比结果如表4所示。
IYOLO 算法与其他三种算法检测目标框对比效果如图9所示。

表3 四种算法整体检测性能对比Tab. 3 Comparison of overall detection performance of four algorithms
从表4 中可以看出,随着IoU 阈值的提高,IYOLO 算法较其他三种算法在检测精度上的优势越发明显,其在高IoU 阈值的情况下仍能保持高mAP 值,而其他三种算法随着IoU 阈值的增大mAP 急剧下降。在IoU 阈值为0.5 时,IYOLO 算法较SSD300、YOLO v3、Faster R-CNN算法的mAP值提升分别为25.29个百分点、6.6个百分点、2.1个百分点,而其在IoU阈值为 0.75 时的 mAP 值提升分别为 30.84 个百分点、13.52 个百分点、11.39个百分点,即在高IoU 阈值下提升越明显,这说明了IYOLO 算法得到的预测框与真实目标框重合度更高,目标框定位更准确,这使得其应用场景更广阔。且从图9 中可以看出,IYOLO 算法比其他三种算法对目标框的定位更精确,并且解决了SSD300、YOLO v3 算法中存在漏检、误检的问题。
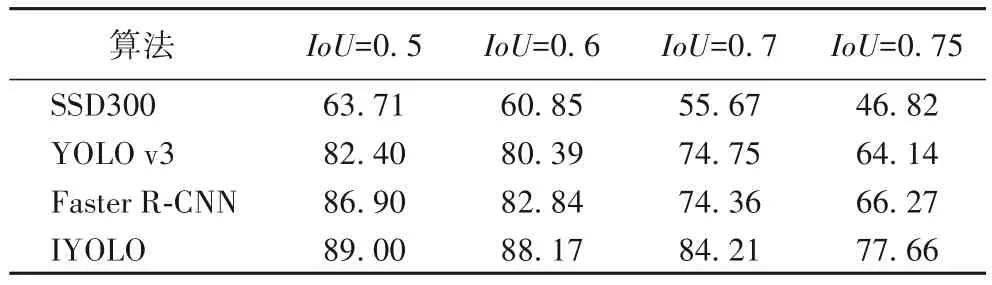
表4 不同IoU阈值下检测精度的对比 单位:%Tab. 4 Comparison of detection accuracy under different IoU thresholds unit:%

图9 不同算法检测交通标志效果对比图Fig. 9 Comparison of different algorithms for detecting traffic signs
4 结语
本文提出了一种基于YOLO v3 的改进算法,旨在解决交通标志识别任务中存在检测精度较低、算法模型参数量巨大以及实时性较差的问题。其中:引入深度可分离卷积实现了在不降低检测准确率的条件下极大地降低算法模型参数量的目标;在对目标框坐标回归损失的设计上采用了GIoU 损失,这使得算法的检测精度大幅提升,且定位的目标框也更加精准;同时将Focal 损失加入到置信度损失中,缓解了数据类别之间不均衡问题对算法模型的影响。通过对实验数据的分析可知,IYOLO 算法在其参数只有YOLO v3 算法的1/5 时,mAP指标提高了6.6 个百分点,FPS 也提高了4.5。因此,该算法在模型大小、检测精度、检测速度上均优于YOLO v3算法。为提高检测精度,IYOLO 算法采用的输入图片尺度为800 × 800,这使得其检测速度FPS 只能达到12,与达到实时检测还存在一定距离,未来可以在检测速度上做进一步的提升以达到实时检测的效果。
