基于二维主成分分析与卷积神经网络的手写体汉字识别
2020-09-04郑延斌韩梦云樊文鑫
郑延斌 ,韩梦云 ,樊文鑫
(1. 河南师范大学计算机与信息工程学院,河南新乡453007;
2. 智慧商务与物联网技术河南省工程实验室(河南师范大学),河南新乡453007)
0 引言
脱机手写体汉字识别是模式识别领域的研究热点之一,也是文字识别领域最为困难的问题之一[1]。它广泛应用于银行票据识别、邮件分拣、办公室自动化等领域,可以带来巨大的经济效益和社会价值[2-3]。由于汉字种类繁多、相似汉字之间易混淆以及书写风格多样等问题,过去几十年,研究者提出了许多传统的方法来提高脱机手写体汉字的识别性能,但识别精度仍然远远落后于人类的表现[4]。
受深度卷积神经网络(Convolutional Neural Network,CNN)在计算机视觉领域成功应用的启发[5-6],研究者将该方法应用于手写体汉字识别问题中,并取得了很好的结果。Ciresan[7-8]等提出了一种端对端的多列深度CNN 模型,在脱机手写体汉字识别中取得了93.5%的识别率,为当时最好的识别结果;Zhong 等[9]提出了一种改进的 CNN 模型,通过手工提取的特征与CNN 相结合的方式将识别率提高到了96.74%;Zhang 等[10]将传统的归一化-协同方向分解特征图与CNN 相结合,取得了96.95%的识别率。这些基于CNN 的识别方法虽然取得了较好的识别结果,但由于构建神经网络需要很高的计算成本,因而无法部署在便携设备上。
为了解决CNN 运行速度和存储容量的问题,涌出了许多优化CNN 模型的方法。Li 等[11]提出了一种新的加权平均池技术,可以在不损失精度的前提下减少全连接层的参数,并通过添加中间输出,在单个CNN 中实现了级联模型,显著降低了识别时间;Xiao 等[4]提出了一种基于CNN 的快速和紧凑的手写体汉字识别方法,通过全局监督低秩扩展(Global Supervised Low-Rank Expansion,GSLRE)方法和自适应降权(Adaptive Drop-Weight,ADW)技术来解决CNN 识别中速度和存储容量的问题。
CNN 识别手写体汉字需要的特征数量相当大(图像的特征维度可能达到几百甚至几千),因此,直接存储和处理图像时效率比较低。在实际的应用中,大量的数据特征并不能刻画数据的本质特征,数据的冗余还可能会影响到后续的数据处理[12]。因此,在使用CNN 分类之前,对汉字图像进行特征提取,可以减少无关的数据特征,提升CNN 的运算速度。然而,在手写体汉字识别方面还未发现相关研究。
目前,在手写体汉字识别中常用的特征提取方法分为两类[13]:一类是基于结构的特征提取,但因为结构提取特征困难,且对噪声敏感,故很少使用;另一类是基于统计的特征提取。主成分分析(Principal Component Analysis,PCA)[14]是一种通过降低数据维度从而有效提取特征数据的方法,它的中心思想是将数据降维,以排除信息共存中相互重叠的部分[15]。在基于PCA 的图像特征提取中,二维图像必须先转换为一维图像向量,再求协方差矩阵的特征向量[16]。由此得到的图像通常是一个高维的图像向量空间(比如图像的分辨率为64×64,转化为一维向量的维数则高达为4 096)。由于利用PCA方法得到的协方差矩阵的维数较大,因此很难准确地对特征向量进行估计。
二维主成分分析(Two Dimensional Principal Component Analysis ,2DPCA)是 Yang 等[17]在 PCA 基础上提出的一种基于二维矩阵的特征提取方法,在提取特征之前不需要预先将图像矩阵转换成一维向量,可以直接使用原始图像矩阵构造协方差矩阵。与PCA 的图像协方差矩阵相比,使用2DPCA 的协方差矩阵要小得多。因此,与PCA 相比,2DPCA 有两个重要的优点。首先,它更容易准确地评估协方差矩阵;其次,确定相应的特征向量所需的时间更少。
针对CNN 识别手写体汉字速度慢的问题,本文采用2DPCA 与CNN 相结合的方法识别手写体汉字。该方法在保持手写体汉字识别率的情况下,极大地提升了手写体汉字的识别速度。该方法主要分为两个阶段:第一阶段为图像特征提取,即利用2DPCA 提取手写体汉字的二维图像特征;第二个阶段为图像分类,即将第一阶段提取的二维图像特征矩阵放入CNN 的输入层中进行分类。实验结果表明该方法能著降低CNN的运行时间,验证了方法的合理性和有效性。
1 相关基础
1.1 卷积神经网络
CNN 是一种分层神经网络,它通过将输入与一组核滤波器进行卷积来提取局部特征。然后对得到的卷积特征图进行子采样(表示为池化),并过滤到下一层。下面是对CNN 算法[9]的简单介绍。


对于采样层来说,就是将卷积的特征图降维,公式如式(3)所示。其中:down()是求和采样函数,计算映射中的每个n × n区域的最大值。

Softmax 主要用于多分类问题,它可以将多个神经元的输出映射到(0,1)区间内,从而将多分类的结果以概率的方式展现。假设有T 类标签,每个类别的训练数据用(xi,yi)表示,其中 i={1,2,…,N},xi和 yi分别为特征向量和标签。CNN 的目标是最小化交叉熵损失函数,如式(4)所示:
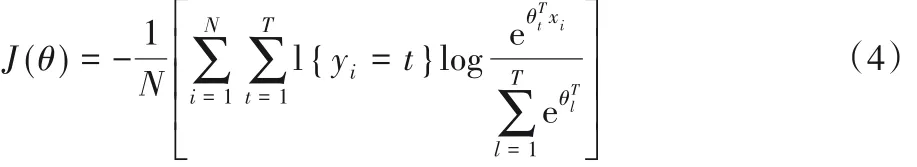
在CNN 的训练过程中,使用随机梯度下降(Stochastic Gradient Descent,SGD)算法可以使J(θ)的损失函数最小化。
1.2 二维主成分分析
1.2.1 2DPCA算法思想
设X 表示一个n 维的单位列向量,2DPCA 的思想是通过式(5)将图像A(一个m×n的图像矩阵)投影到X上[18-20]:

从而得到一个m 维的投影向量Y,Y 为图像A的投影特征向量。需要考虑如何计算X。实际上,投影样本的总体散布矩阵可以用来测量X 的判别能力,而投影样本的总体散布矩阵可以利用投影特征向量的协方差矩阵的迹来表示[21]。从这一点来看,可采用以下准则:

其中,训练样本投影特征向量的协方差矩阵由Sx表示,且Sx的迹用tr(Sx)表示。式(6)中准则最大化的物理意义是求出一个X,所有的样本都投射到它上面,使产生的投射样本的总体散射是最大的。协方差矩阵Sx[22]可以表示为:
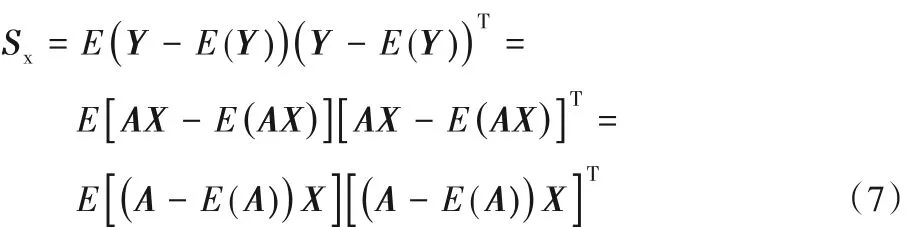
因此:
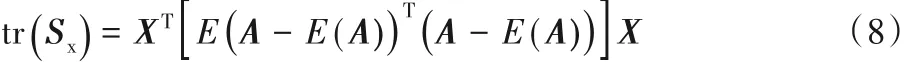
定义总体散布矩阵Gt如式(9)所示:
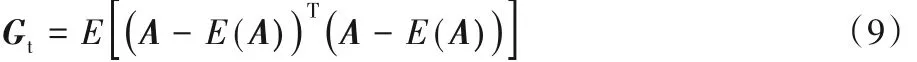
由定义可知,Gt是一个n × n 的非负定矩阵,可以直接使用训练图像样本来评估Gt。假设训练图像样本的总数为L,第j 个训练图像用一个 m × n 的矩阵 Aj(j = 1,2,…,M)表示,所有训练样本的均值图像用表示,则Gt可以利用式(10)评估。
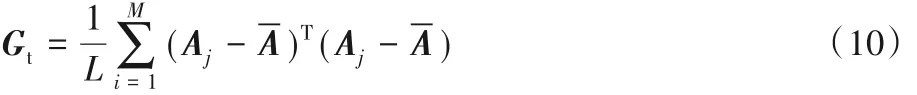
则式(6)中的准则可以表示为:

其中:X 是一个单位列向量。这个准则称为广义总体散射准则。使准则最大化的单位向量X称为最优投影轴。当将图像矩阵投影到X上之后,投影样本的总散射将达到最大化。
若 X 的最优投影轴用 Xopt表示,则 Xopt是最大化 J(X)的单位向量,即Gt的特征向量对应于最大的特征值。一般来说,只有一个最优投影轴是不够的。通常需要选择一组投影轴X1;X2;…;Xd,X1;X2;…;Xd受正交约束和最大化准则J(X)的管制,如式(12)和式(13)[23]所示:
事实上,最优投影轴X1;X2;…;Xd是Gt的标准正交特征向量对应的前d个最大的特征值。
1.2.2 特征提取
2DPCA 的最优投影向量X1;X2;…;Xd被用作特征提取。对于给定的图像样本A,令

然后,得到一组投影特征向量 Y1;Y2;…;Yd,Y1;Y2;…;Yd为样本图像A 的主成分。需要注意的是,2DPCA的每个主成分都是一个向量。所有的主成分构成一个m × d的矩阵B =[Y1;Y2;…;Yd],B 称为图像样本A 的特征矩阵或特征图。
2 基于2DPCA与CNN的手写体汉字识别
为了提升CNN 模型的识别性能,人们提出了许多方法来提高手写体汉字的识别率,主要包括数据增加和采用更深的CNN 网络。数据增加是一种非常重要的提升CNN 鲁棒性及推广能力的技术,通常采用平移、尺度缩放、旋转、仿射变换和弹性形变等方法对手写体汉字图像数据进行扩充。然而,数据增加和更深的CNN 网络模型都会导致计算成本增加、训练和识别时间过长。为了提高CNN 的识别速度,采用了一种基于2DPCA 与CNN 的手写体汉字识别方法,该方法可以保持手写体汉字的识别精度并提高识别效率。
利用2DPCA 与CNN 相结合方法识别手写体汉字,首先输入样本图像并对其进行预处理。预处理的第一步是统一图像的尺寸大小,即将所有样本转为大小相同的图像。第二步是将相同大小的图像作归一化处理,归一化之后所有图像的像素值都在[0,1]区间内。预处理之后,利用2DPCA 提取总体散布矩阵的特征向量对应的前d 个最大特征值,即最优投影向量,将图像投影到最优投影向量即可得到图像的特征矩阵。最后,将特征矩阵放入CNN 的输入层,通过卷积、池化、全连接等一系列操作,求取识别结果。识别的算法描述过程如下:
输入 样本集R,低维空间维数d;
过程
对样本集R中的图像A进行预处理;
根据式(5)求A的投影向量Y;
利用式(7)求协方差矩阵Sx;
根据Sx求出协方差矩阵的迹;
求广义总体散射准则函数:J(X) = XTGtX;
求最优投影向量 Xk(k = 1,2,…,d),最优投影轴 X1,X2,…,Xd是Gt的标准正交特征向量对应的前d个最大的特征值X1,X2,…,Xd;
将图像A投影到Xk,求投影特征向量Y1,Y2,…,Yd;
特征矩阵B =[Y1,Y2,…,Yd];
令 训 练 集 Al={(Bk,Fk)}(l,k = 1),测 试 集 Am={(Bl+1,Fl+1)}(m,k = l);
用Al训练一个CNN模型;
输出 用CNN 对Am中的样本进行预测,预测结果与其标签作比较,得到一个预测精度。
通过2DPCA 与CNN相结合的方法识别手写体汉字,首先求汉字图像的二维特征,每个汉字图像对应一个特征矩阵,利用此矩阵,卷积神经网络可以实现图像的分类。整个识别过程在2.1~2.3节中详细介绍。
2.1 预处理
1)尺寸统一化。
设整个手写体汉字的数据集为R,由于其中的汉字图像A的尺寸大小各不相同,为了便于处理,通过尺寸统一化将所有汉字图像设置成相同的大小。统一尺寸后的图像高为m,宽为n。
Resize(A) =[m,n]
2)图像归一化。
图像归一化就是通过一系列变换,将待处理的原始图像转换成相应的唯一标准形式。在提取特征之前,对汉字图像进行归一化处理,归一化之后所有的像素值都在[0,1]区间内。
2.2 基于2DPCA的汉字特征提取
预处理之后,汉字图像为m × n 的归一化图像。2DPCA算法的目的是将每一张m × n 的汉字图像降维成m × d 的特征矩阵(d 远远小于n),且将m × d 的特征矩阵放入CNN 中训练,手写体汉字的识别率不会明显降低。
设汉字图像的最优投影向量为X1,X2,…,Xd,通过Yk=AXk(k = 1,2,…,d)对 m × n 的汉字图像A 作线性变换,投影特征向量Y1,Y2,…,Yd即可构成特征矩阵B,特征矩阵B =[Y1,Y2…,Yd]。
通过2DPCA算法求特征矩阵的具体步骤如下:
步骤1 根据式(7)求得协方差矩阵Sx,由1.2.1 节知Sx= E[(A - E(A))X][(A - E(A))X]T。
步骤2 根据迹的定义求出协方差矩阵Sx的迹,tr(Sx)=XT[E(A - E(A))T(A - E(A))]X。
步骤3 求广义总体散射准则函数。定义总体散布矩阵Gt= E(A - E(A))T(A - E(A)),由1.2.1 节式(5)的准则函数可得J(X) = XTGtX。
步骤4 求最优投影向量Xk(k = 1,2,…,d)。最优投影轴 X1,X2,…,Xd是 Gt的标准正交特征向量对应的前 d 个最大的特征值。
步骤5 将图像A 投影到Xk上,由式(5)可知投影特征向量为Y1,Y2,…,Yd。
步骤6 特征矩阵B =[Y1,Y2,…,Yd]。
2.3 基于特征矩阵的CNN模型
特征矩阵作为CNN 的输入在手写体汉字识别方面展现了很好的性能,它不仅没有降低手写体汉字的识别率,还明显提高了CNN 的识别速度。本文采用三种CNN 模型验证该方法的有效性。它包括AlexNet(Alex Krizhevsky)模型与文献[3]和文献[8]提出的两种深度卷积神经网络模型。文献[3]和文献[8]的模型分别命名为ACNN模型和DCNN模型。
文献[3]的卷积神经网络结构包含8 个卷积层、4 个池化层、1个全连接层和1个输出层。全连接层连接上一层的所有激活,输出层用Softmax 函数生成分类。如图1 所示,图中每一部分包含两个卷积层和一个池化层。
AlexNet 采用与文献[6]相同的体系结构,模型如图2 所示。它由8 个加权层组成;前五层包括三组卷积层和最大池化层,以及两个单独的卷积层;其余三层是完全连接的层。在该模型中,所有滤波器的大小均为3×3,卷积步长为1,池化层的大小为2,步长也为2。
文献[8]提出的 CNN 架构如图 3 所示,主要由 3 个卷积层、2 个池化层、1 个全连接层和一个Softmax 回归层组成。其中,网络的前6层用于特征提取,最后一层用于分类。

图1 ACNN的模型架构Fig. 1 Model architecture of ACNN
图2 AlexNet的模型架构Fig. 2 Model architecture of AlexNet
图3 DCNN的模型架构Fig. 3 Model architecture of DCNN
3 实验与分析
3.1 数据集
本研究采用中国科学院自动化研究所提供的手写体汉字数据集CASIA-HWDB1.1 进行实验。CASIA-HWDB1.1 数据集包含了3 755 个常用的GB2312 一级汉字,由300 个不同的编写者书写,每个汉字的样本库包含240 个训练样本和60 个测试样本。为了验证本文提出的方法,随机选取CASIAHWDB1.1 中的15 组相似手写体汉字进行验证[24],每组包含10个相似样本。部分相似手写体汉字样本如图4所示。
3.2 实验配置及实验平台
在预处理中,将所有的汉字图像统一为64 × 64 的大小,并对64 × 64的汉字图像进行归一化处理。提取特征矩阵时,选择d的个数为10,即每张图像的特征矩阵大小为64 × 10。提取特征矩阵之后,对每个特征矩阵进行标准化处理,保证每个维度的特征数据方差为1,均值为0。
特征矩阵输入CNN 之前,首先打乱整个训练样本,以减少训练时的过拟合。为了得到更好的手写体汉字识别率,对三个CNN 模型通过多次重复实验进行调参。选取部分参数作对比,不同CNN 模型的识别率如表1所示,对3个CNN 模型的平均识别率作比较,可知第三组数据的识别率最高,效果最好。因此,CNN 模型的参数配置如下:批大小设置为48,正则化大小为0.8,学习率为0.000 2,每循环200 次学习率降低10%。

图4 CASIA-HWDB1.1的相似数据样本Fig. 4 Similar data samples in CASIA-HWDB1.1 dataset
实验采用的平台是基于Python 语言的深度学习框架tensorflow,硬件环境为Intel i5 CPU,8 GB 内存,操作系统为Windows 10 64位。

表1 不同参数的手写体汉字识别率对比Tab. 1 Comparison of handwritten Chinese character recognition rates under different parameters
3.3 结果与分析
将2DPCA 与CNN 相结合的方法用于手写体汉字识别,并分别与2.3 节中的三种CNN 模型进行对比。2DPCA 与三个CNN 模型相结合的方法分别命名为2DPCA-ACNN、2DPCAAlexNet 和2DPCA-DCNN,三种方法统称为2DPCA-CNN。通过对比三种模型与2DPCA 结合前后的识别率和识别时间,验证本文方法的合理性和有效性。
3.3.1 比较2DPCA-ACNN与ACNN
将 2DPCA-ACNN 与文献[3]中的 ACNN 方法作对比,ACNN 的架构如2.3 节的图1 所示。在识别过程中,任选一组相似手写体汉字分别采用本文方法与文献[3]中的方法进行训练和识别,随着迭代次数的增加,相似手写体汉字中测试集的识别率变化曲线如图5 所示。其中横坐标为迭代次数,纵坐标为测试集的识别率,迭代次数设置为5 000。从图5 中可以看出,随着迭代次数的增加,测试集的识别率逐渐上升并趋于稳定,且2DPCA-ACNN 与ACNN 识别率分别为94.88%和95.12%,2DPCA-ACNN 与ACNN 的识别方法在本次实验中识别率相差不大。
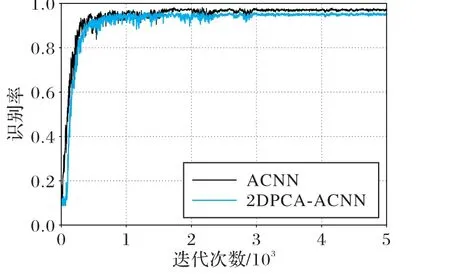
图5 2DPCA-ACNN与ACNN识别率变化Fig. 5 Recognition rate changes of 2DPCA-ACNN and ACNN
为了避免实验结果的偶然性,随机选择了5 组相似手写体汉字进行实验,并求出5 组相似手写体汉字的平均识别率和识别时间。对比2DPCA-ACNN 与ACNN,得到的测试集的识别率和识别时间如表2 所示。从表2 可以看出,ACNN 和2DPCA-ACNN中每一组手写体汉字的识别率波动不超过1%,2DPCA-ACNN 识别手写体汉字所花费的时间相较ACNN 所花费时间却减少了80%。
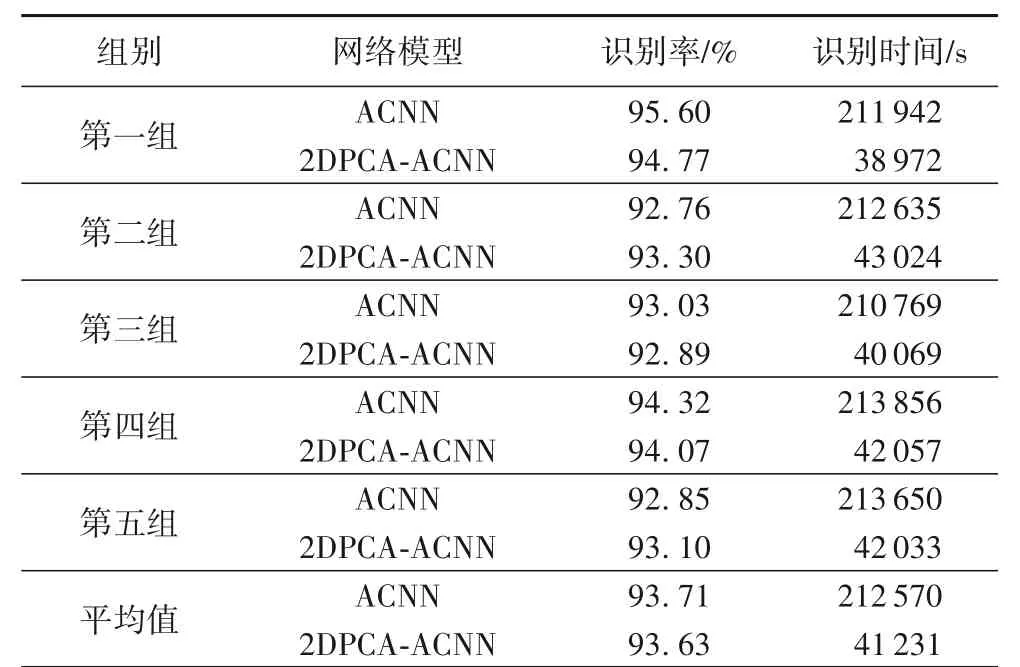
表2 2DPCA-ACNN与ACNN的识别率和识别时间对比Tab. 2 Comparison of 2DPCA-ACNN and ACNN on recognition rate and recognition time
3.3.2 比较2DPCA-AlexNet与AlexNet
该实验采用的CNN 模型是文献[6]中的AlexNet 模型,AlexNet 的模型架构如2.3 节的图2 所示。在本次识别过程中,随着迭代次数的增加,相似手写体汉字中测试集的识别率变化曲线如图6 所示。由图6 中可以看出,AlexNet 与2DPCAAlexNet 的识别率分别为92.45%和94.29%,2DPCA-AlexNet的识别率略大于AlexNet。由于每次实验初始化参数值都是随机的,样本打乱顺序也是随机的,因此一定程度的波动属于正常范围。
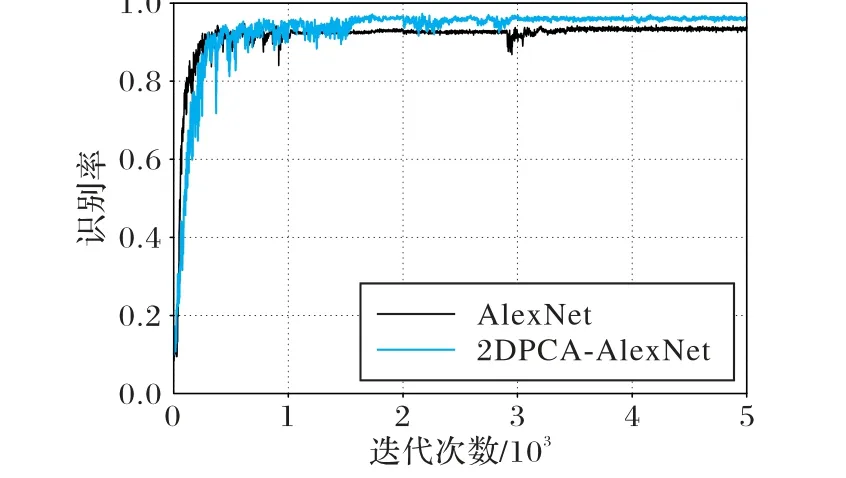
图6 2DPCA-AlexNet与AlexNet识别率变化Fig. 6 Recognition rate changes of 2DPCA-AlexNet and AlexNet
为了避免本次实验结果的偶然性,仍然选择了5 组相似手写体汉字进行实验。对比2DPCA-AlexNet 与AlexNet,得到的测试集的识别率和识别时间如表3所示。从表3可以看出,随着CNN 深度的增加,手写体的识别率也逐渐增加,且2DPCA-AlexNet 与AlexNet 中每组手写体汉字的识别率略小于2DPCA-ACNN与ACNN的识别率。此外,与AlexNet算法相比,2DPCA-AlexNet识别手写体汉字花费的时间减少了78%。
3.3.3 比较2DPCA-DCNN与DCNN
本次实验比较方式同3.3.1 和3.3.2 节一致,DCNN 识别手写体汉字的架构如2.3节的图3所示。在识别过程中,随着迭代次数的增加,相似手写体汉字中测试集的识别率变化曲线如图7 所示。此时测试集在2DPCA-DCNN 与DCNN 模型上的变化曲线基本重合,证明了两种方法的识别率相差很小。
本次在2DPCA-DCNN 与DCNN 模型上进行对比,得到每组的测试集的识别率和识别时间如表4 所示。在本次实验中,两种方法的手写体汉字的识别率波动不大,且与DCNN 相比,2DPCA-DCNN 识别手写体汉字所花费的时间降低了73%。

表3 2DPCA-AlexNet与AlexNet的识别率和识别时间对比Tab. 3 Comparison of 2DPCA-AlexNet and AlexNet on recognition rate and recognition time
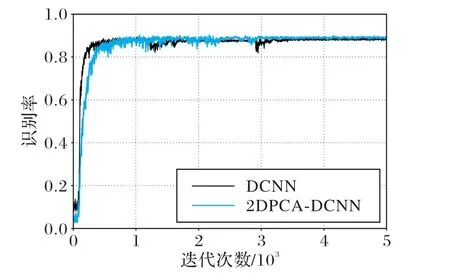
图7 2DPCA-DCNN与DCNN识别率变化Fig. 7 Recognition rate changes of 2DPCA-DCNN and DCNN
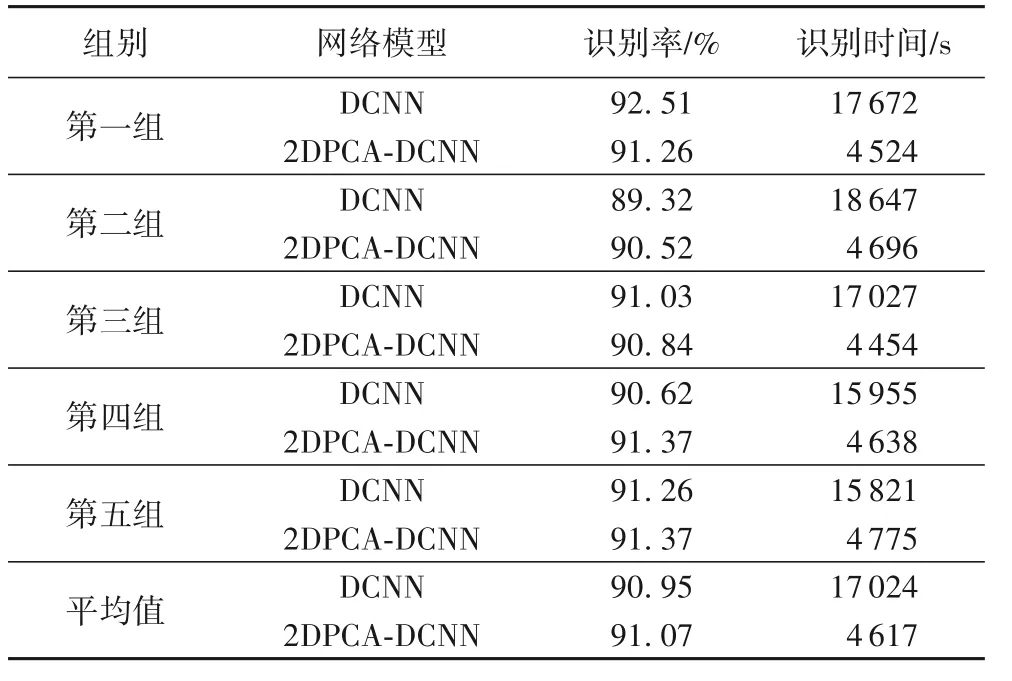
表4 2DPCA-DCNN与DCNN的识别率和识别时间对比Tab. 4 Comparison of 2DPCA-DCNN and DCNN on recognition rate and recognition time
比较3.3.1 与3.3.2 节中的实验可知,随着CNN 层数的增多,不仅手写体汉字的识别率显著提高,CNN识别手写体汉字的时间也成倍增长。比较每次实验中CNN 与2DPCA-CNN所花费的时间,可以发现CNN 层数越深,本文方法节省的时间也越多。
比较 3.3.1、3.3.2 和 3.3.3 节中的三次实验,由图 5~7 可以直观地看出,随着迭代次数的增加,2DPCA-CNN 与CNN 的识别率趋于稳定并且识别率大小没有明显的差异。比较表2~4 中的每组数据和其平均值,可以看出每次实验2DPCACNN 识别手写体汉字的时间远远小于CNN 所花费的时间,证明了2DPCA 与CNN 相结合的方法与CNN 方法相比具有明显的时间优势。
4 结语
近年来,在手写体汉字识别领域比传统方法好的深度学习模型主要是基于CNN 及其改进方法的。但是CNN 也有其缺陷,比如需要大量的训练样本、更深的CNN 模型来保持其精度。由于增加样本和采用更深的CNN 模型需要大量的参数计算,这无疑增加了CNN 的训练时间。针对CNN 训练时间长的问题,本文采用了2DPCA 与CNN 相结合的手写体汉字识别方法。该方法首先去除图像中的冗余信息,得到手写体汉字的特征矩阵;然后再将特征矩阵放入CNN 中进行识别。由于特征矩阵的参数变少,因此将特征矩阵放入CNN 模型中进行卷积、池化等运算,能明显地降低CNN的运行时间。
