基于VMD多尺度散布熵的柴油机故障诊断方法*
2020-09-03乔新勇韩立军
乔新勇,顾 程,韩立军
(1.陆军装甲兵学院车辆工程系,北京 100072; 2.武警工程大学乌鲁木齐校区,乌鲁木齐 830049)
前言
失火故障是柴油机较为常见的故障状态,因导致柴油机的动力性和经济性严重下降而受到高度重视。柴油机缸盖振动信号蕴含着丰富的信息[1],由于柴油机结构复杂、运动部件多,其缸盖表面振动信号混合了不同频率激励源的信号和强背景噪声,呈现非平稳、非线性的特点。如何从成分复杂的振动信号中提取故障特征,是实现柴油机故障诊断的关键。
自适应分解方法常用于分析非平稳非线性的多分量耦合信号,常用的方法有经验模态分解(EMD)、集合经验模态分解(EEMD)、局部均值分解(LMD)、本征时间尺度分解(ITD)等[2-5]。其中EMD虽然能够无监督地进行信号自适应分解,但存在端点效应和模态混叠的问题;EEMD将白噪声添加到原信号中进行EMD分解,一定程度上抑制了模态混叠问题,但由于噪声的加入使计算效率大大下降,且分离出虚假分量;LMD克服了EMD欠分解、过分解等问题,但自身也存在端点效应和模态混叠;ITD能够分解相互独立的合理旋转分量,其分量的瞬时频率具有物理意义,但由于自身缺陷分解存在失真。变分模态分解(variational mode decomposition,VMD)在2014年由Dragomiretskiy等[6]首次提出,不同于递归式模式分解,其本质上是多个自适应维纳滤波器组,分解精度较高,能够较好地解决信号分解过程中模态混叠的问题,且具有较高的运算效率,克服了EMD等方法中的不足。
为提取故障信号的特征向量,信息熵被引入机械设备故障诊断中,并得到了广泛应用。常用的信息熵主要有近似熵、样本熵、排列熵等[7-9],但这些信息熵只从单一尺度衡量信号的复杂度,对于柴油机等复杂机械系统难以完全反映全部状态信息,多尺度样本熵[10]、多尺度排列熵[11]被引入到故障诊断中,由于样本熵计算量大、计算速度慢,排列熵没有考虑振动幅度之间的差异,Rostaghi和Azami[12]提出一种新的衡量时间序列复杂度的方法——散布熵(dispersion entropy,DE),一定程度上解决了样本熵和排列熵的不足。
本文中提出利用VMD和多尺度散布熵相结合的方法提取故障特征向量,首先利用VMD对柴油机缸盖信号进行分解,选取散布熵最小模态分量作为分析信号;然后计算该信号的多尺度散布熵,选取合适尺度熵值作为故障特征向量;最后利用粒子群算法优化支持向量机识别和诊断故障状态,与其他4种方法对比显示了该方法的优越性。
1 变分模态分解

式中:Ak(t)为信号的瞬时幅值;φk(t)为信号的瞬时相位,ωk(t)=φ′k(t)为信号的瞬时频率。相对于相位而言,信号的瞬时幅值和瞬时频率为缓变量。
假定各模态分量聚集在其中心频率的有限带宽上,那么变分模态分解可以看作为求取估计带宽之和最小的K个模态分量uk(t),约束条件为所有模态分量和等于原始信号f(t)。具体构造步骤如下。
(1)通过利用Hilbert变换求取各模态分量的解析信号,获得单边频谱。

(2)估计各模态分量解析信号的中心频率,将各分量频率调制到各自的基频带。

(3)利用H高斯平滑计算借条信号梯度L2范数的平方,对各模态分量带宽进行估计。最终得到约束变分模型,如式(4)所示。
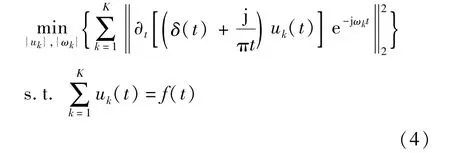
通过引入惩罚因子和拉格朗日乘法算子得到增广拉格朗日表达式求取上述模型的最优解,即

VMD算法流程图如图1所示。
VMD算法在使用过程中首先需要设定分解层数K和惩罚因子α,不同的参数对分解效果影响较大。在实际应用过程中通常需要根据经验设定参数值,本文中利用文献[13]中提出的中心频率观察法,根据信号自身特性对其进行VMD分解。
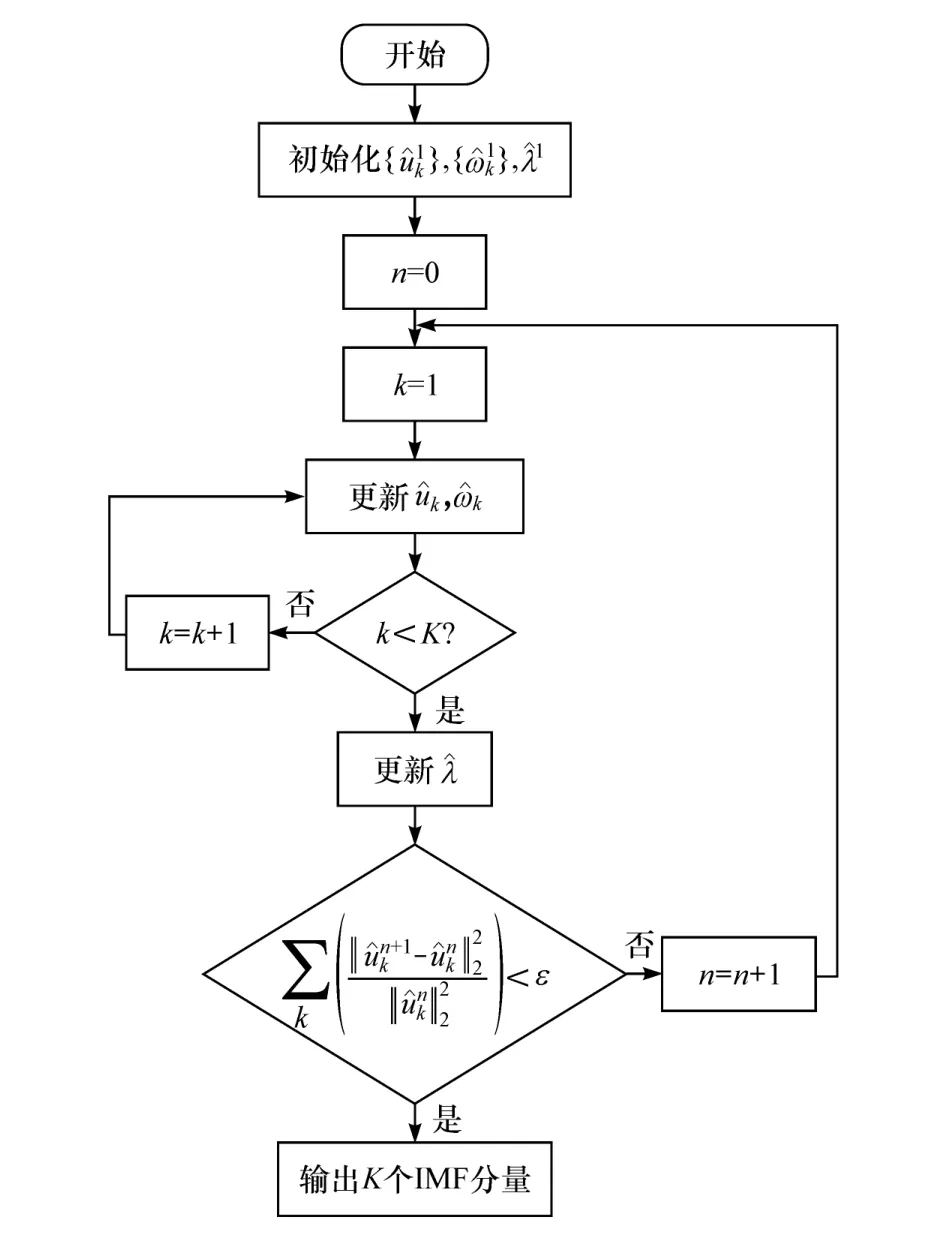
图1 VMD算法流程图
2 多尺度散布熵
2.1 散布熵
散布熵是2016年由Mostafa Rostaghi提出的一种新的衡量时间序列复杂度的算法,克服了排列熵没有考虑幅值大小的缺陷,稳定性好,计算速度快。其具体计算方法[14]如下。


从散布熵计算方法可以看出,当全部散布模式概率相等时,散布熵具有最大值ln(cm)。散布熵值越大,时间序列复杂程度越高,反之越低。文献[12]中给出计算散布熵的参数建议:嵌入维数m取2或3较为适宜,类别个数c取4~8中的整数,时间延迟d一般取1,时间序列样本长度应大于2 000。
2.2 多尺度散布熵
在散布熵基础上提出的多尺度散布熵(multiscale dispersion entropy,MDE)能够在不同尺度反映时间序列的复杂程度。多尺度散布熵的计算方法如下。
(1)对长度为L的原始信号进行粗理化处理,得到N个长度为τ的序列,计算每段序列的平均值得到粗粒化信号。

3 算法流程
由于柴油机结构复杂、行驶工况多变,缸盖振动信号耦合了不同程度的噪声[15],直接计算原信号的散布熵容易因噪声信号的干扰产生误差,且单一尺度的散布熵不能很好地表征柴油机的故障,本文中提出基于VMD多尺度散布熵的柴油机故障诊断方法,具体步骤如下。
(1)利用中心频率观察法选取VMD的分解层数K,对柴油机缸盖振动信号进行分解,得到K个模态分量IMF1、IMF2、…、IMFK。
(2)计算K个模态分量的散布熵值,选取散布熵最小的模态分量作为代表故障特征的信号进行分析。
(3)计算被选模态分量的多尺度散布熵,选取合适尺度的散布熵值作为故障特征向量。
(4)利用粒子群算法(PSO)对支持向量机(SVM)核函数的参数进行优化,并将优化后的支持向量机模型对信号特征向量进行训练和测试,识别柴油机的状态。
4 实例分析
4.1 台架试验
对某12缸四冲程柴油机进行了台架试验,试验设置4种柴油机状态,如表1所示。柴油机运行工况为1 500 r/min、50%负荷,对左1缸缸盖振动信号进行采集,采样频率为20 kHz,采样时间为1 s。振动加速度传感器安装位置如图2所示。
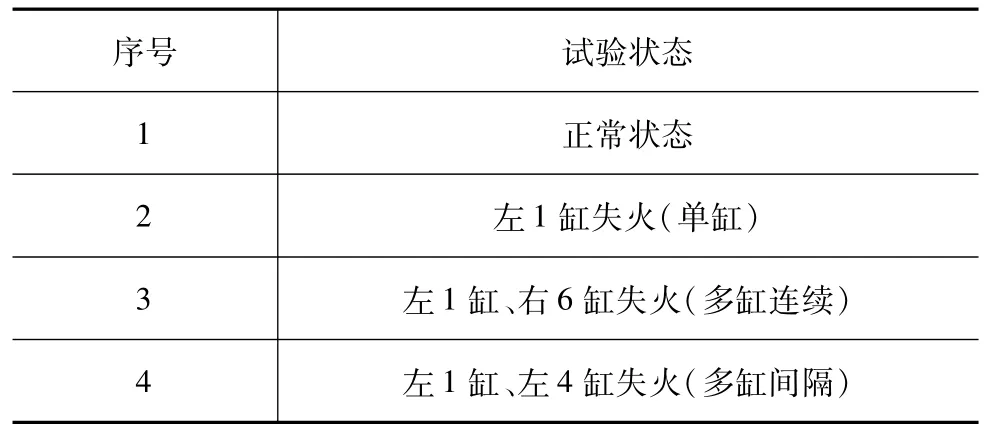
表1 柴油机试验状态

图2 左1缸缸盖振动测点
4.2 信号分析
采集得到4种试验状态下的振动信号如图3所示,时域图中4种状态的波形比较杂乱,没有明显的故障特征,需要对时域振动信号进行处理。
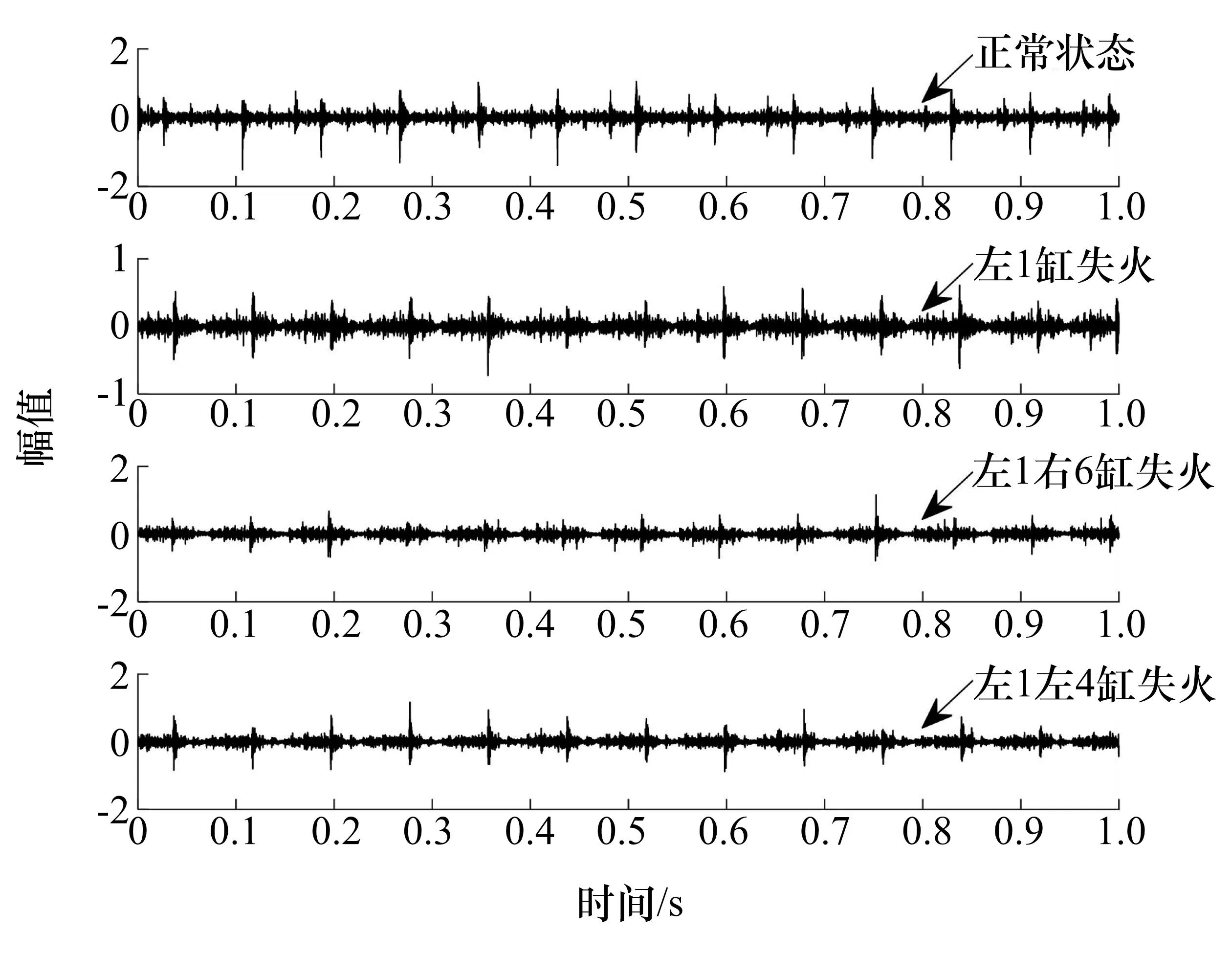
图3 4种试验状态下的振动信号
以左1缸失火故障为例,对振动信号进行变分模态分解。利用中心频率观察法对分解层数K进行选取,惩罚因子采用默认值2 000。表2为左1缸失火故障时,不同分解层数对应的中心频率,可以看出,当分解层数K为3时,出现欠分解现象,当分解层数K为5和6时,出现过分解现象,因此确定左1缸故障时分解层数K=4。对振动信号进行VMD分解,得到4个模态分量如图4所示。
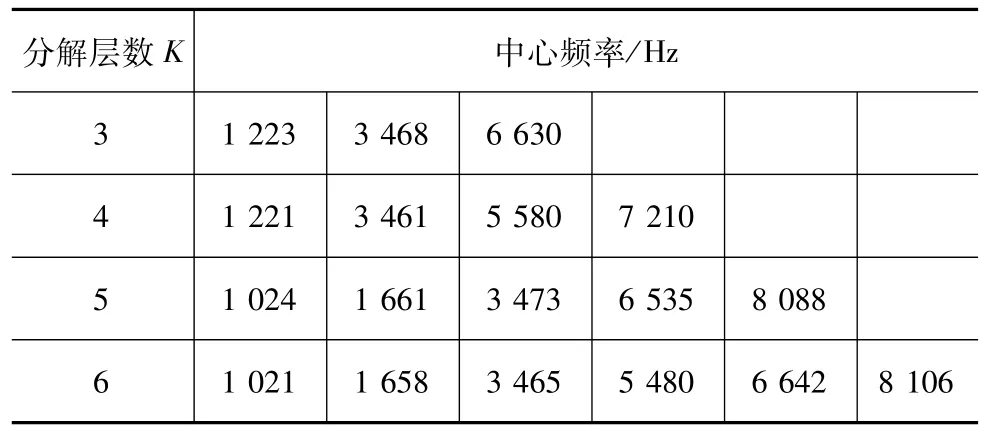
表2 左1缸失火故障时不同分解层数下的中心频率
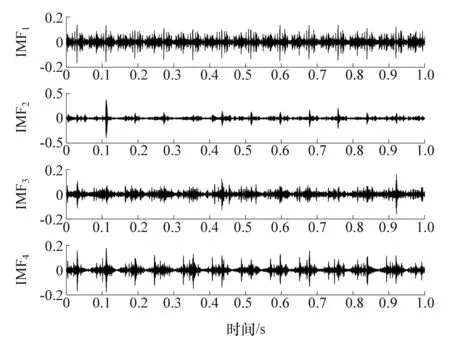
图4 左1缸失火状态下VMD分解各模态分量
通过分析4种状态的分解层数均为4,利用VMD分解得到4个模态分量并计算各分量散布熵值,如表3所示。可以看出,每种状态模态分量IMF1的散布熵值均为最小,且正常状态较其他3种故障相差较大,因此选用IMF1作为多尺度散布熵分析对象。
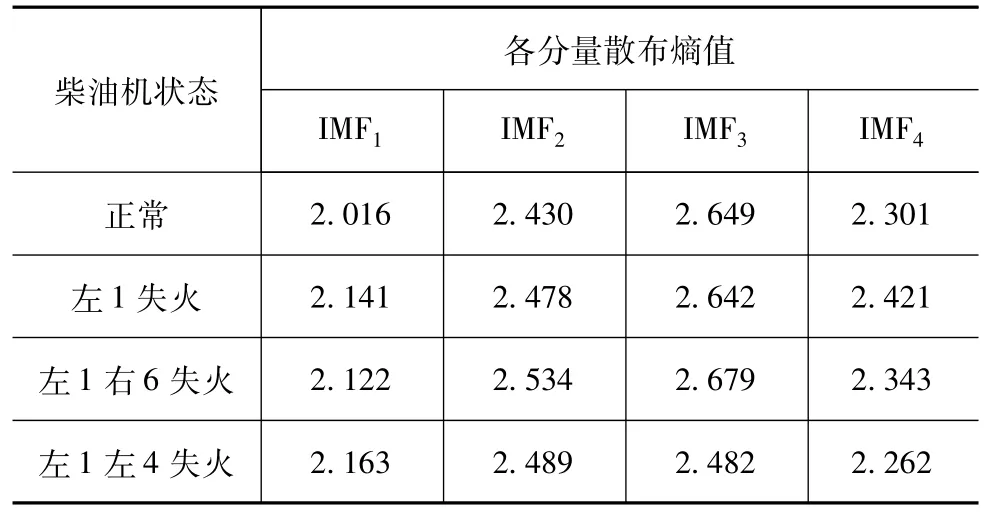
表3 4种状态各分量散布熵
计算4种状态下分量IMF1的多尺度散布熵,其中嵌入维数m=2,类别c=4,时间延迟d=1,最大尺度因子τmax=20,每种状态的MDE均值标准差图如图5所示。从图中可以看出,在尺度因子τ∈[1,4]时,4种状态的多尺度散布熵值随尺度的增加而增大,且3种故障状态的MDE值相近,明显高于正常状态。故障状态由于气缸失火没有燃烧,导致振动信号复杂程度上升,散布熵值增大。当尺度因子τ>5时,多尺度散布熵值随尺度增大呈下降趋势,且出现曲线交叉情况,在尺度因子达到16时多尺度散布熵值趋于平稳。在选择故障特征向量时,特征量太多会产生信息冗余,特征量太少又不能完全反映故障信息,综合考虑,本文中选取前6个尺度的MDE值作为故障特征向量。
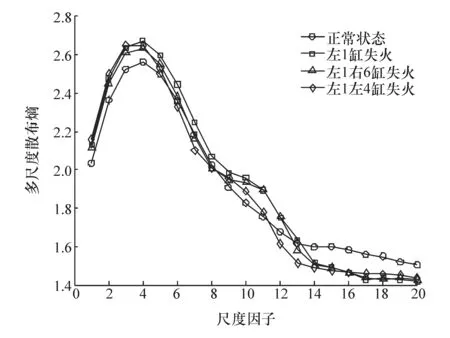
图5 4种状态的多尺度散布熵熵值图
4.3 失火故障识别
利用4.2节中的方法构建特征向量集,每种状态各提取33组样本,其中15组样本为训练集,18组样本为测试集,正常状态、左1缸失火故障、左1右6失火故障和左1左4失火故障的类别标签分别为1、2、3、4,利用粒子群优化支持向量机方法(PSO-SVM)进行故障分类识别。设置种群规模为20,迭代次数为200,初始参数c1=1.5、c2=1.7,适应度曲线如图6所示,得到最佳参数惩罚因子c=0.1,核函数参数g=6.6682。将测试集输入到该模型进行识别,识别结果如图7所示。可以看出,以多尺度散布熵为输入的PSO-SVM模型能够准确识别4种状态,对故障的识别率为100%。
图6 粒子群优化SVM适应度曲线
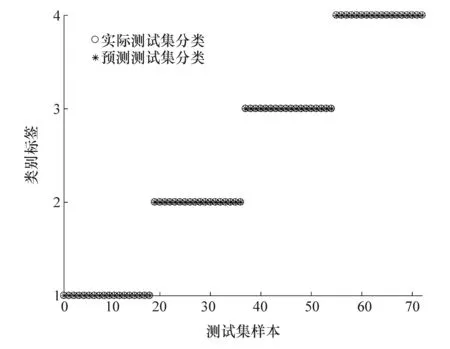
图7 4种样本测试集识别结果
为验证本文方法的优越性,对相同数据样本分别利用直接计算原信号的多尺度散布熵与支持向量机相结合的方法(MDE-SVM),经验模态分解、多尺度散布熵与支持向量机相结合的方法(EMD-MDESVM),变分模态分解、多尺度排列熵与支持向量机相结合的方法(VMD-MPE-SVM),变分模态分解、多尺度散布熵与支持向量机相结合的方法(VMDMDE-SVM)对失火故障进行诊断识别,结果如表4所示。比较5种方法的诊断准确性可以看出,VMDMDE-PSO-SVM方法能够准确识别出正常状态和3种不同失火故障,准确率最高,对失火故障识别效果最好。

表4 5种方法失火故障识别结果
5 结论
本文中提出一种基于VMD和多尺度散布熵的柴油机失火故障诊断方法,得到以下结论。
(1)VMD能够分离出不同频带的模态分量,有效地抑制了噪声干扰;多尺度散布熵克服了排列熵未考虑幅值大小的缺陷,从多个尺度全面反映了时间序列的复杂度,提高了算法的准确性。
(2)利用VMD-MDE实现柴油机故障特征提取,并利用PSO-SVM对故障进行识别判断。与其他4种方法相比,该方法能够准确识别出4种状态,识别率为100%。
