无人车行驶环境图像的几何测距*
2020-09-03代金坤罗玉涛梁伟强
代金坤,罗玉涛,梁伟强
(1.华南理工大学机械与汽车工程学院,广州 510640; 2.广汽集团汽车工程研究院,广州 510640)
前言
视觉传感器具有提取信息量大、信息完整、价格便宜等优点,故成为获取周围环境信息的重要手段之一。由于图像存在深度缺失以及背景环境干扰等问题,通过单目摄像头对物体进行准确测距的方法一直是视觉研究的难点之一,目前主流的检测方法有:使用运动图像中的多个匹配点对物体深度进行估测[1-5];通过寻找稳定参照物的方法获得距离信息[6-7];通过固定摄像头位姿状态下的物体距离检测方法[8-10];通过卷积神经网络检测物体在图片中的大概尺寸,结合先验信息进行估测[11-13]。这些方法都有一定的可行性,但都存在精度低、适用性窄、容易受环境干扰以及步骤繁琐等问题。利用卷积神经网络预先提取所测物体位置,再经过图像分割得到所测物体信息的方法,减少了由于外界环境的影响而带来的误差,具有更好的适用性、可靠性和抗干扰能力。
针对单目物体测距中深度缺失、背景干扰与前景分割困难等问题,提出了一种基于几何测距模型的物体测距方法。首先,使用卷积神经网络对物体进行标记并定位物体在图片中的位置,为了提高训练效率与准确率,在此利用迁移学习的方法,使用Tiny-YOLOv2网络模型加载已训练完成的权重,对需识别的物体进行训练与检测,之后根据训练结果对网络模型进行改进,并对其参数进行调整,获得更为适合于当前环境下的物体检测卷积模型。然后,提出了一种通过物体分类、边缘检测和边缘拟合技术获得物体数值信息的方法,该方法能精确提取物体的图像信息,并转化为数值信息。最后,建立了一种基于空间几何理论的测距模型,结合在图像中提取的物体数据信息和物体尺寸的先验信息实现了物体的距离测量。
1 物体检测与识别
1.1 模型训练
直接在原始图像上进行物体的分割与数值化,存在物体提取困难以及计算量过大等问题,故先使用卷积神经网络模型在压缩尺寸后的图像上对物体进行检测与定位,得到物体的位置后再从原始图像中将物体裁剪出来进一步处理。本文中使用迁移学习的方法,在已有的模型和通用数据库训练得到的权重下,加入自己的数据集,可快速得到理想权重,极大地节约了时间与成本。
目前基于深度学习的主流目标检测算法主要有以R-CNN[14-16]系列(R-CNN、Fast R-CNN、Faster RCNN)为代表的算法,和以SSD[17]、YOLO[18-20]系列(YOLOv1,YOLOv2,YOLOv3,Tiny-YOLO)为代表的算法。一般情况下,R-CNN系列算法精度比SSD、YOLO系列算法高,但SSD、YOLO系列算法速度更快。SSD、YOLO系列算法在经过改进后精度已有很大的提升,已接近甚至超越了R-CNN系列算法。本文中基于YOLOv2模型的简化版本Tiny-YOLOv2进行目标检测,提高了训练速度与处理效率。
1.2 Tiny-YOLOv2网络改进
本文中的数据集数据较少、物体种类不多,且识别目标较小,基于通用物体识别的Tiny-YOLOv2网络并不能表现出最优的检测效果,故在此对原网络模型进行改进。由于Tiny-YOLOv2本身即为简化版本,网络结构已达到效率最高,故在此保留原网络层数,而将第13层的卷积层由Conv3*1024改为Conv3*512,将最后一层卷积层由Conv1*425改为Conv1*50,具体情况如表1所示,以此来进一步提高物体的检测准确率与检测效率。

表1 改进前后网格对比
利用265张训练集图片数据进行训练,60张测试集图片进行测试,共检测识别了5种不同的物体,分别为门牌、逃生通道灯、车牌和两种常见提示牌,在同一电脑配置下,通过原网络和改进网络进行训练,在其余参数设置相同的情况下,原网络在迭代次数为400次时损失函数不再下降,改进网络在迭代次数为1 100次时损失函数不再下降,改进网络训练情况部分识别结果如图1所示,原网络训练情况在这里不做描述,训练集损失函数对比如图2所示。
基于迁移学习优势,原网络和改进网络的训练效率都有较大幅度提升,改进网络由于网络模型发生改变导致部分权重需重组,所以训练时间更长,但是改进网络最终的平均损失率要低于原网络。
由表2可知,由于样本总量较小,导致两种网络在测试集的识别率都较低,但相对来说改进网络的识别率仍有显著的提升。同时,在训练集的识别率与检测速度上改进网络皆优于原网络。

图1 部分识别结果

图2 损失函数对比
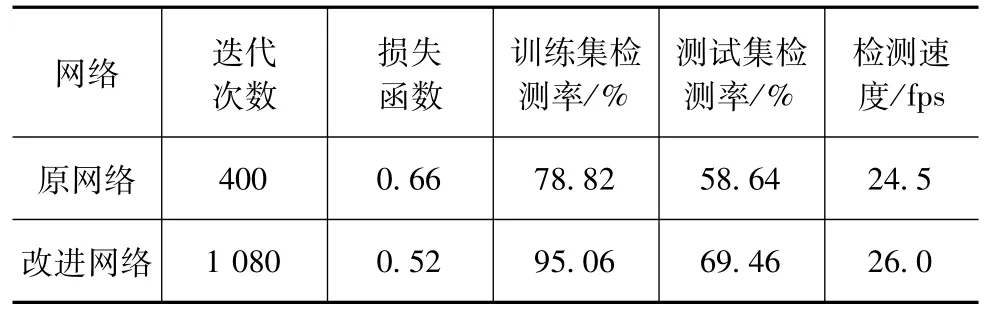
表2 网络对比
2 物体分割与数值化
此步骤的主要目的是从第1.2节中裁剪出来的图片中获取物体的数值信息,即不仅要将物体分割提取,并且要将提取到的物体边界进行数值化,物体由于射影定理,在图片上的形状为多边形,而对于多边形而言,只要得到边缘顶点坐标即确定了多边形的全部数值信息。在此提出了一种通过物体分类、边缘检测和边缘拟合获得物体数值信息的方法。
2.1 边缘检测
因为不同的物体在纹路和颜色方面有些许差异,使用通用的检测参数与检测方法并不能获得最优的效果。故该方法首先通过上文中物体检测获得的物体标签信息将物体进行分类,根据不同的物体种类设置不同的检测参数与检测流程,以此来获得最优检测效果。主要变动的参数包括:边缘检测阈值、色彩空间提取的RGB颜色范围、Hough直线检测线段阈值。主要的检测流程包括:中值滤波消去噪声、使用Canny函数进行边缘检测、使用色彩空间过滤颜色、使用OSTU算法进行图像二值化处理、使用Hough变换检测直线,以此得到物体的边缘信息,具体参数如表3所示。

表3 主要方法与主要参数
2.2 边缘拟合
通过滑动窗口的二次多项式拟合算法可有效提取与拟合多边形边缘,为提高拟合效果,在此对算法进行改进,加入了k、l1、l2、r1、r2感兴趣区域的参数,具体过程如下。
首先,统计图片某部分的每列像素之和,以左右两边的感兴趣区域为范围搜寻像素值和的最大值作为滑动窗口的起始点。

式中:Pij为图像的像素矩阵P第i行、第j列的值;m、n为图像的像素宽度与高度;hj为每列像素之和;Bl、Br为滑动窗口的左右初始点;k、l1、l2、r1、r2为感兴趣区域的参数。
根据式(1)获得初始点之后,算法根据一个矩形面积向上生长,根据矩形中像素最大值确定生长方向以及下一个初始点,以此迭代,最后通过多项式拟合方法对每一个矩形的中心点进行拟合,最终得到边界信息,设矩阵4个顶点坐标分别为(w1,h1)、(w1,h2)、(w2,h2)和(w2,h1),迭代过程如式(2)所示。

式中:N为矩形内像素之和;cj为矩形内每列像素之和;Bc为滑动窗口的迭代后的初始点。
由于多边形边界分布在图像边缘部分,以此为据对算法参数进行设置,增加了滑动窗口在图像边缘部分的搜索力度,并在宽度和高度方向上各使用一次。在已知图像尺寸m、n的情况下,通过对算法参数的反复调整,得到最优的拟合方法,参数设置如表4所示,最终效果如图3所示。

表4 参数设置

图3 检测示例
根据拟合结果可得数条直线,求解相邻直线的交点,即可得到多边形的顶点坐标信息(u,v)。

如图3所示,通过该方法能准确地提取各类物体的边缘信息并进行数值拟合,得到物体的顶点坐标信息,整体上则取得了较好的效果。
3 通过几何测距模型进行测距
在此提出了一种结合物体尺寸的先验信息进行测距的几何测距模型,通过建立摄像机小孔成像模型来确定空间目标三维立体信息与图像二维成像点面之间的对应关系[21-22],并通过第2章中获得的物体数值信息与先验信息,得到物体的距离。小孔成像模型示意图如图4所示。

式中:K为相机的内参数矩阵;fx、fy分别为x、y轴方向的放大系数;cx、cy为物理成像坐标系和像素坐标系之间的位移量。
通过第2章中物体提取与数值化的方法,得到

图4 小孔成像模型
物体在像素平面内的多点坐标(ui,vi)。通过式 (4),得到含有未知数Z的物体在相机坐标系下的三维坐标。

根据立体几何学,在空间中任意不共线的3点构成一个平面,在此已知相机坐标系下4点之间的相互关系,则可构建以下关系:

观察式(11)左边第3项,在实际应用中由于物体在空间中的位姿对Z值的影响较小,可认为Zi≈Zj成立,故在此做近似处理,由基本不等式a+b≥可将式(11)化简:

由于物体始终在相机前方,故在此Zi≥0恒成立。令xi=,在此以矩形的求解过程举例,将其分割为两个三角形进行求解。

观察得知,该方程组为超定方程组,在存在测量误差的情况下,该方程组一般而言没有解,所以使用最小二乘法求其近似解,通过最小二乘原理,将式(14)转化为如下矩阵进行求解。


对矩阵方程进行求解,即可得到各个顶点的Z轴信息再通过式(16)求距离信息。将各点距离信息求均值,得到物体中心点的距离信息,至此测距完成。

4 测试结果
为验证所采用方法在实际应用中的准确度与抗干扰能力,通过采集多组实际场景信息对方法进行验证。本文中使用darkflow模块对卷积神经网络模型进行修改和调用,使用numpy库对几何模型中的矩阵运算进行优化。
摄像头使用的物理感光元件为索尼公司的IMX498传感器,传感器尺寸为1/2.8英寸,长宽比例4∶3,摄像头实际焦距为3.5 mm。分析该方法的过程发现,检测的精度主要与物体在图片中的像素尺寸和位姿有关,与物体实际距离的远近无关,即只要物体在图像中存在合理的尺寸与位姿,物体的实际距离并不会影响该方法的测量精度,故在此采集了1~4 m范围内的图像数据作方法的验证。通过该摄像头检测3类大小不同的物体,分别在1、2、3、4 m处各个不同的位置进行图片采集与检测,经过筛选后得到总计42张不同距离和角度的图像,部分图像如图5所示。
对每组图像中的物体进行距离测量,测量结果如图6所示。
测量结果表明,该测量方法的精确度较高,在4 m以内88%以上的测量值误差不超过0.2 m。测量误差并没有随着距离的增加而有较大变化,而是稳定在一个固定的区间范围内。
5 结论

图5 部分图像
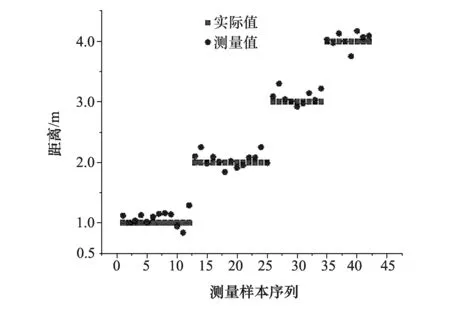
图6 测量结果
基于迁移学习的方法改进了Tiny-YOLOv2网络模型,将原网络的检测效率与测试集准确率提高了1.5帧与11%。通过该检测网络得到了被测物体的标签信息与在图像中的位置信息,将物体从原图像中进行裁剪用于下一步处理。
提出了一种检测物体边界数值信息的方法,该方法通过检测到的标签信息对物体进行分类,对不同种类的物体通过不同的阈值参数信息与不同的图像处理组合方法进行边缘检测及边缘拟合,获得准确的物体数值信息。
建立了一种检测物体距离的几何测量模型,该模型结合物体尺寸的先验信息与得到的物体在图像中的数值信息,对物体进行准确的测距。通过试验证明,该测量方法的精确度较高,在4 m以内88%以上的测量值误差不超过0.2 m,同时测量误差并没有随着距离的增加而有较大变化,而是稳定在一个固定的区间范围内。
