基于Spark的路网交通运行分析系统*
2020-08-26许宏科
杨 孟 许宏科 钱 超 朱 熹
(长安大学电子与控制工程学院1) 西安 710064) (深圳市城市交通规划设计研究中心有限公司2) 深圳 518021)
0 引 言
随着智能交通系统(intelligent transportation system, ITS)研究的深入展开,道路交通数据规模和复杂度呈爆发式增长,呈现出大数据的“6V”特征[1].采用传统的串行处理方式,其计算速度已无法满足大数据环境下实时业务需求.因此,采用并行化与分布式的数据处理技术来提高交通信息处理水平成为当前交通大数据平台研究的热点.建立综合运输服务大数据平台,促进交通运输大数据产业化应用成为迫切的行业需求[2].
目前,国内外在交通大数据应用领域积极展开相关研究.由于传统的数据存储方法无法解决海量交通数据的高效存储和快速增长问题,Zhu等[3-4]采用Hadoop的分布式文件系统进行交通数据并行存储,并应用MapReduce分布式计算框架实现对交通数据的统计分析,提高了海量交通数据的存储和计算效率;Rathore等[5]根据城市交通监控数据,利用Hadoop的MapReduce机制,在并行环境下将视频进行分块处理,提高城市道路违规检测的效率.为提高交通数据处理能力,孙卫真等[6]改进了分布式调度算法模型,优化了Hadoop的处理能力,从而弥补了传统调度算法实时性的不足;Park等[7]采用数据挖掘算法对交通流数据进行聚类与分类分析,提出了一种改进的交通事故预测模型;Fan等[8]以ETC收费数据为基础,采用随机森林算法与Hadoop构建大数据机器学习分析平台,实现公路旅行时间的预测;Chen等[9]利用历史的交通速度,在Hadoop平台上集成了KNN算法和高斯过程对道路速度进行预测.以上研究主要利用历史数据对交通数据进行处理,为了实现交通数据的实时处理,Tsai等[10]利用Spark平台实时处理数据的能力,构建了一种可以实时提供路网交通量的系统;黄廷辉等[11]利用道路检测数据,提出了一种分布式城市交通流预测模型,实现了实时、准确的交通流预测;段宗涛等[12]在Hadoop平台上设计并实现了一种多路径的实时交通流分配方法,解决了传统交通分配方法的难以保证交通流均衡性问题;陈钊正等[13]结合实际的交通流数据,利用聚类算法对交通流量和速度进行聚类分析,给定了交通状态划分方法,结果反映了实时、准确交通运行状态.
综上所述,应用分布式系统进行交通大数据研究集中在对传统交通模型的改进以及对交通信息预测,缺少利用实时的交通数据对路网交通运行状态进行更加合理、准确的分析研究,从而进行多指标综合评价.因此,本文设计了一种基于Spark的路网交通运行状态分析系统,以实时的交通流指标为基础,实现对路网运行状态的判别.结合真实路网交通数据,对系统分析结果进行综合评价,验证了系统的准确性与高效性.
1 路网大数据机器学习平台
Spark是Apache项目的一个开源集群运算框架[14],具有分布式存储和并行计算的能力,同时还提供了机器学习算法编程的接口,以及利于迭代运算的并行化执行机制,保证平台在可接受的时间内完成大规模数据的学习和训练.本文采用Spark技术搭建的路网大数据机器学习平台总体框架,见图1.在Linux操作系统上搭建Hadoop与Spark平台,利用Hadoop平台的分布式文件系统(hadoop distributed file system, HDFS)作为路网大数据机器学习平台的数据存储层,负责底层交通数据存储管理.数据处理层利用Spark SQL对交通数据进行读取与查询,并将读取的结果作为SparkR的输入,利用Spark调用的k-means算法和随机森林算法实现路网交通运行状态的判别;并在数据应用层对数据判别结果进行研究分析.在数据的存储、处理与应用过程中,由于Spark平台的独立调度器(standalone)模式较为简单方便,无需依赖其他任何的资源管理系统,利用Standalone模式实现底层资源调度;同时,利用弹性分布式数据集(resilient distributed datasets, RDD)进行交通数据处理任务的并行执行;相较于MapReduce方法,RDD利用高速内存代替了低速磁盘I/O操作,提高了整体的运算效率.
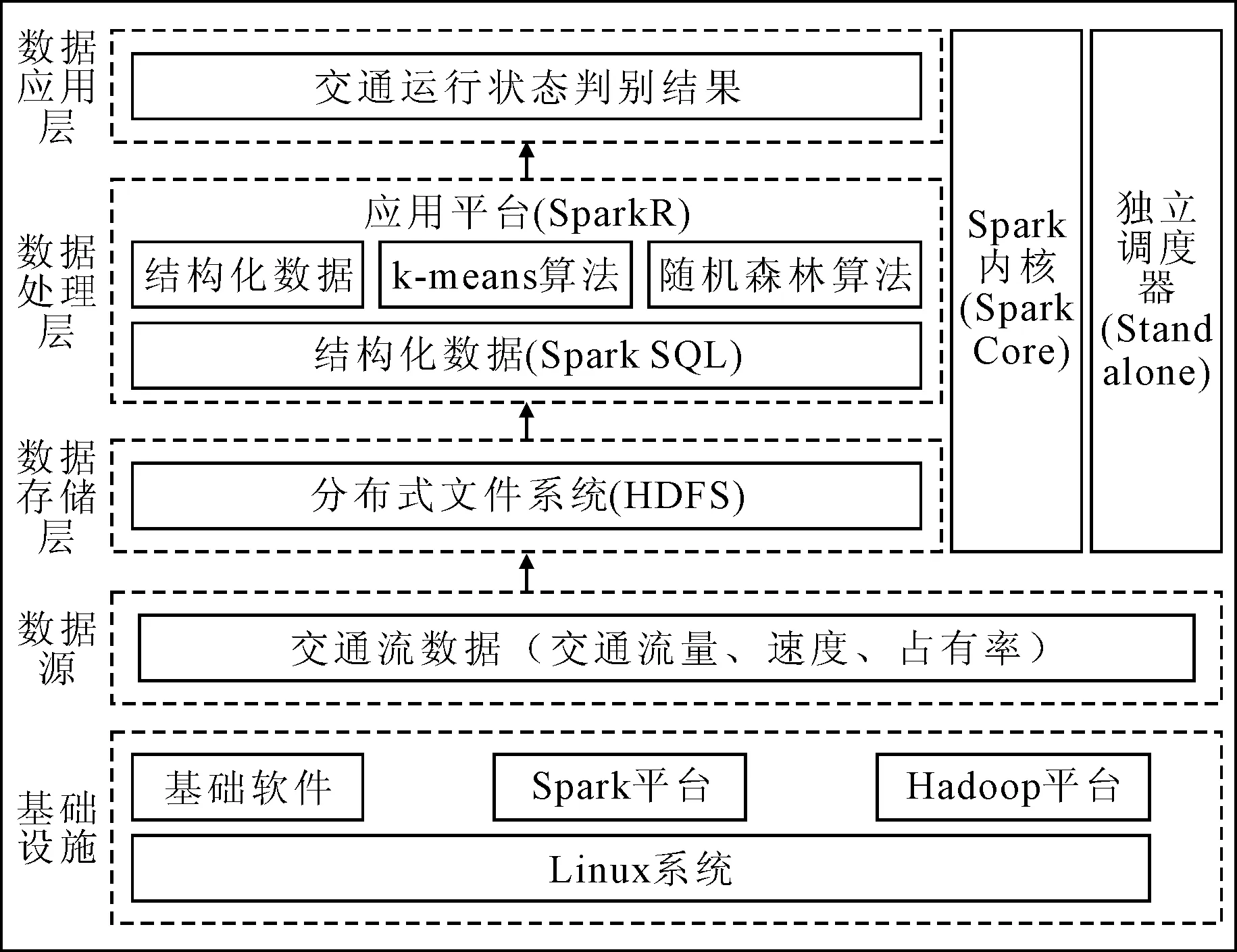
图1 路网大数据机器学习平台
2 路网交通运行状态研判
2.1 路网交通运行状态聚类
路网畅通程度是描述道路运行状态的重要指标.2012年,交通运输部在《公路网运行监测与服务暂行技术要求》中以路段平均车速为标准,将道路交通运行状态划分为“畅通”“基本畅通”“轻度拥堵”“中度拥堵”“严重拥堵”五级.但不同的道路速度可能会有多种不同的道路状况,仅用平均车速来度量交通运行状态缺乏科学性和可靠性.因此,本文以道路交通流量、速度和占有率作为评价交通运行状态的指标,采用聚类算法将道路拥堵程度划分为五种状态.传统的k-means算法由于其原理简单而被广泛使用,当数据量较大时,算法的时间开销非常大.本文采用分布式k-means算法进行聚类分析,将大量交通流数据划分为多块子数据,采用多个处理器并行计算,从而减少算法的运算时间.分布式k-means算法的基本思想基本过程如下.
1) 从高速公路交通流数据集D={x1,x2,…,xn}中,随机选择k个中心点mj,并将其存入文件clusterList中.
2) 在路网大数据机器学习平台的分布式文件系统中,每个节点都包含部分数据集Di,将文件clusterList分发给分布式文件系统的每个节点中.
3) 在每个子数据集Di中,计算非中心数据xi到k个中心点数据mj的距离d(xi,mj),如果d(xi,mj)=min{d(xi,mj),i=1,2,…,n′;j=1,2,…,k},则将xi划分到中心数据mj的类中.
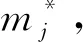
5) 计算k-means算法的误差平方和准则函数J,若聚类准则函数收敛或聚类迭代达到最大,则得到最终聚类结果;否则重复步骤2)、3)、4)继续迭代,直到满足聚类停止条件.
6) 迭代结束,得到交通流运行状态聚类结果.
2.2 路网交通运行状态判别
利用k-means算法实现路网交通运行状态聚类后,每条交通流数据被赋予一个特定的分类标签,其聚类结果为T={(xi,mj);i=1,2,…,n;j=1,2,…,5}.其中:xi为交通流运行数据,包括交通流量、速度和占有率,n为数据集记录数,mj表示交通流运行数据聚类后的标记即五种交通运行状态.随机森林算法(random forest, RF)是以聚类产生的类别标签为规则,判别数据与分类规则之间的关系.将带标签的交通流数据作为随机森林算法的输入数据,实现路网运行状态判别,其具体判别过程如下.
1) 以高速公路交通流运行数据集D={x1,x2,…,xn}与各样本对应的客户类别为基础,采用Bootstrap重采样技术从数据集D中有放回地随机抽取numTrees个子数据集,并将numTrees个子数据集Di基本均匀的分配到路网大数据机器学习平台的所有节点中.
2) 分别从平台所有节点的数据集Di中随机选取M(M≤3)个特征属性,将M个特征属性作为数据集Di的特征属性.
3) 并行训练所有节点的数据集Di,以计算信息增益的方式确定最优的属性划分点,构建numTrees棵交通流运行状态判别决策树.
4) 利用numTrees棵决策树形成交通流运行状态判别随机森林,并综合numTrees棵决策树的判别结果,按numTrees棵树分类器投票决定最终分类结果.
2.3 路网交通运行状态判别结果评价
综合评价路网判别结果,本文引入交通运行状态混淆矩阵见表1,其中,每一列代表了交通运行状态的类别,每一行代表了交通数据真正的归属类别.混淆矩阵可以直观反应实际交通运行状态与判别结果的分布情况,根据混淆矩阵提取出精确度、召回率和F度量等指标来评判判别结果的准确性.
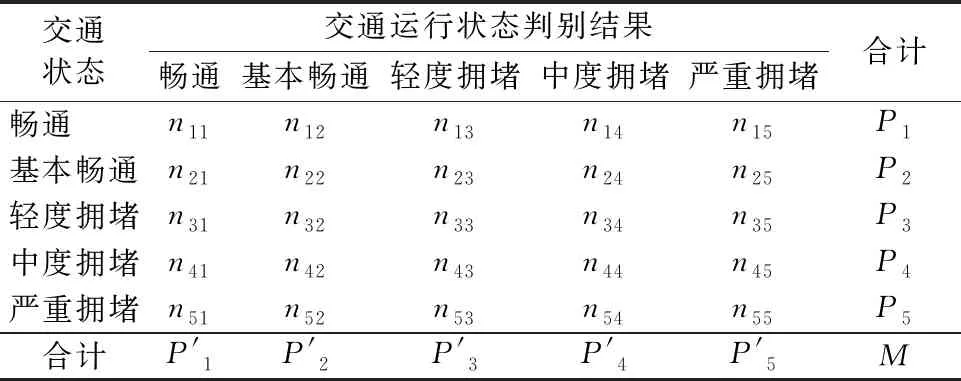
表1 交通运行状态混淆矩阵
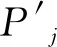
(1)
2) 召回率Rec描述交通运行状态判别模型中正确结果占实际交通运行状态的百分比,其中Pj为实际交通运行状态为j的测试数据记录数.
(2)
3)F度量 精确度Prec与召回率Rec的调和均值,体现了判别模型的稳定性.
(3)
3 实例分析
3.1 实验平台搭建
PeMS(performance measurement system)是美国加州运输局运行监测系统,包含近40 000个检测器的实时路网交通数据.本文选取西奥克兰(West Oakland)地区高速公路作为实验路网,包括I880号、I580号、I980号、I80号和SR24号高速公路,共布设57个车辆检测器,实验路网见图2.以2016年5月29日—9月3日的交通流运行数据作为基础数据,具体数据量为1 608 768条,采样间隔为5 min.实验路网交通流运行参数见表2.

图2 实验路网
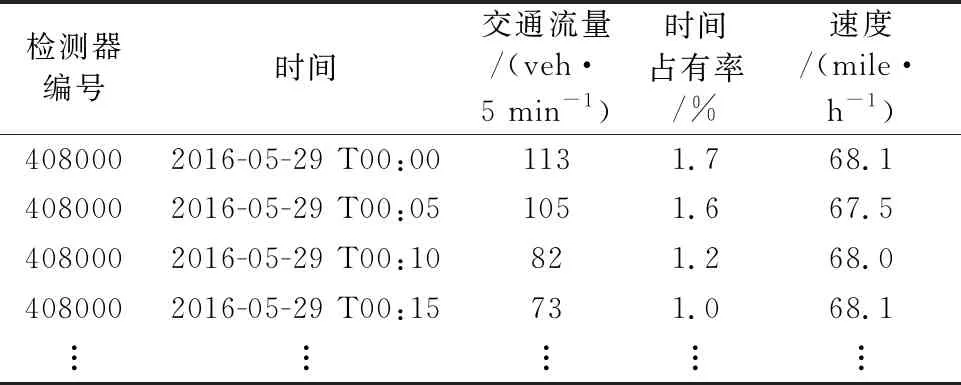
表2 交通流运行原始数据表
本文利用5台PC机搭建包含一个控制节点和四个计算节点的路网大数据机器学习平台,处理器Intel(R) Core(TM)2 i5-6500@3.20 GHz,4 G内存.在路网大数据机器学习平台中的所有节点上均安装有Linux(ubuntu 12.04)操作系统,并配置Spark所需的软件,包括:Java,Hadoop,Scala,Spark和R.
3.2 聚类可靠性分析
聚类结果的可靠性决定了路网运行分析系统准确性.因此,本文通过对比并行化聚类算法和传统的聚类算法结果、并行化聚类算法结果和实际交通特性,对聚类结果进行评价.
3.2.1并行化聚类和传统的聚类结果分析
相较于传统的聚类算法,路网大数据机器学习平台对预处理后的交通流数据进行并行计算,大幅度提高了聚类效率,聚类结果统计见表3.由表3可知,两种聚类方式的聚类结果占比基本一致,其平均相对误差约为7.3%,说明并行化聚类和传统聚类算法结果具有一致性.

表3 并行化聚类与传统聚类结果
3.2.2并行化聚类结果时间特性分析
图3为401416号检测器6月7日并行聚类结果时间分布特性图,采用“1”“2”“3”“4”“5”表示交通运行状态的“畅通”“基本畅通”“轻度拥堵”“中度拥堵”“严重拥堵”.由于I980号高速公路具有早晚高峰特点,而401416号检测器处于I980号高速公路下行线上.由图可知:401416号检测器并行聚类结果时间分布特性具有早高峰特点,在早晨08:00前后道路交通量和占有率达到最高,同时道路上车辆的速度下降到最低值,与交通流运行特性是一致的,说明交通流运行数据并行聚类结果是可靠的.
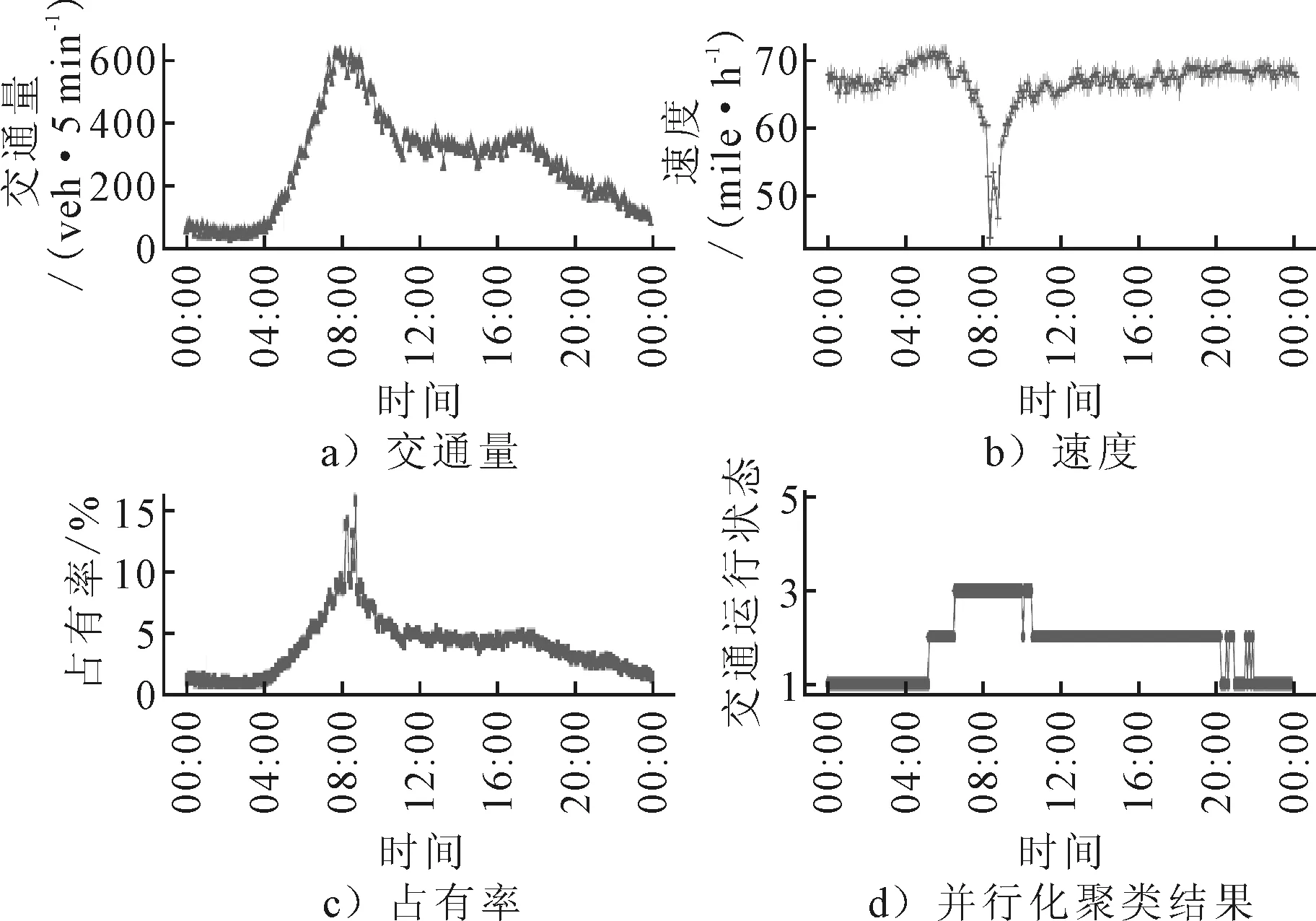
图3 401416号检测器样本与并行化聚类结果时间分布
3.3 判别准确性分析
3.3.1传统判别与并行化判别结果评价
在单机和路网大数据机器学习平台上分别构建路网交通运行状态判别模型,其中85%的路网数据作为训练集,15%的路网数据作为测试集,构建传统判别与并行化判别结果的交通运行状态混淆矩阵,并从混淆矩阵中提取出两种判别结果平均精确度、召回率和F度量见图4.由图4可知,在路网大数据机器学习平台上并行化判别路网运行状态会影响其判别结果,并行化判别的精确度、召回率和F度量略低于传统判别,但均达到98.5%以上,说明并行化判别结果的准确性依然可靠.
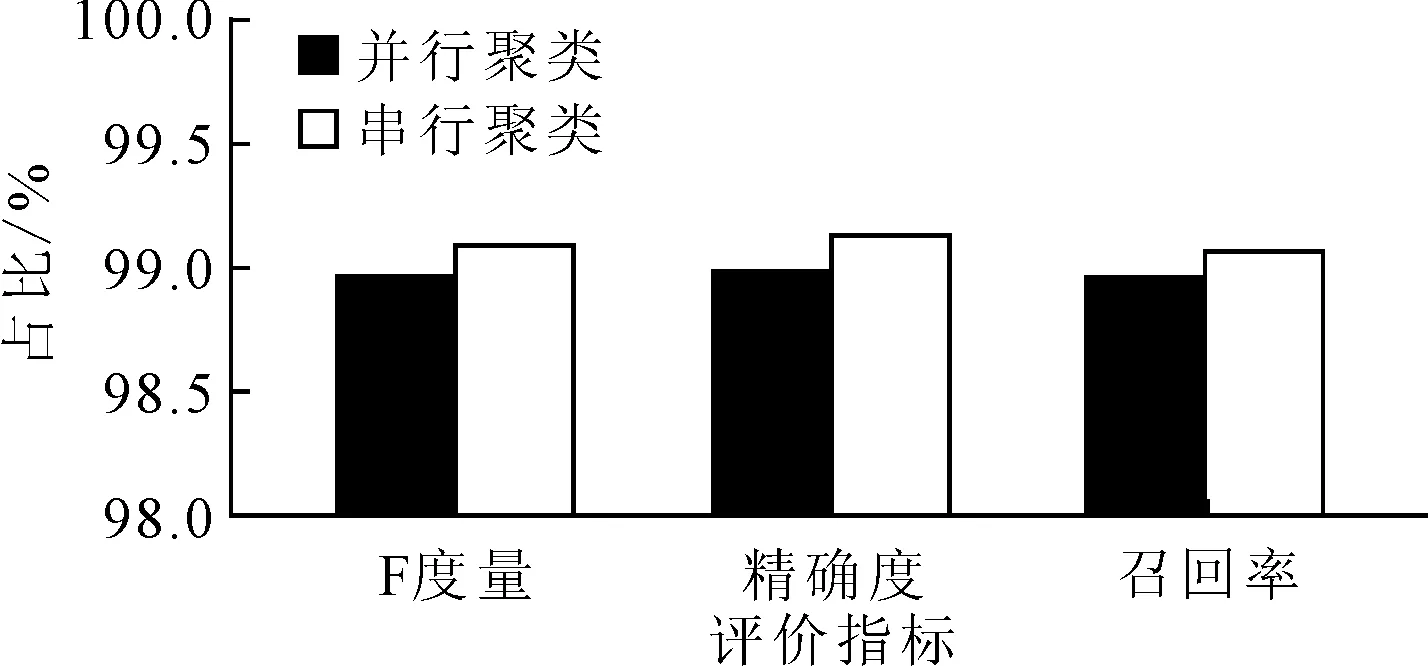
图4 传统判别与并行化判别结果评价指标平均值对比
3.3.2并行化判别模型评价
在路网大数据机器学习平台中,为评价判别模型的准确性,本文选用逻辑回归模型(Logit)、多层感知器(multi-layer perception, MLP)和随机森林算法(RF)进行对比.采用85%数据作为训练集和15%数据作为测试集进行实验,图5为在不同交通运行状态下Logit,MLP,RF分类算法的精确度、召回率和F度量对比,图6为Logit,MLP,RF分类算法的平均精确度、召回率和F度量对比.由图6可知,随机森林算法的精确度、召回率和F度量高于Logit和MLP算法,并均达到98%以上,说明在路网大数据机器学习平台中,随机森林算法的准确性相较于其他分类算法准确性较高.
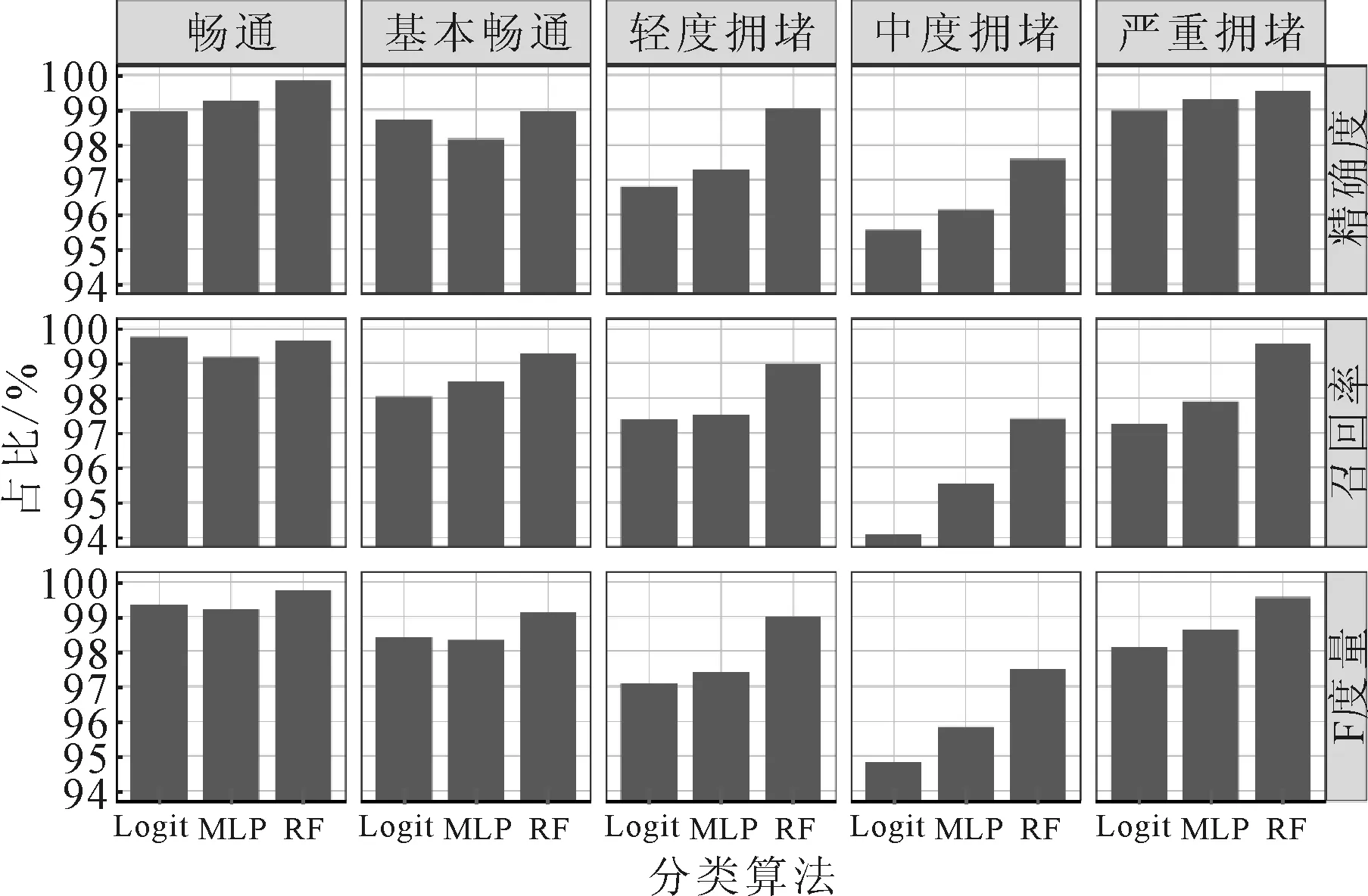
图5 不同分类算法下五种判别结果的指标对比
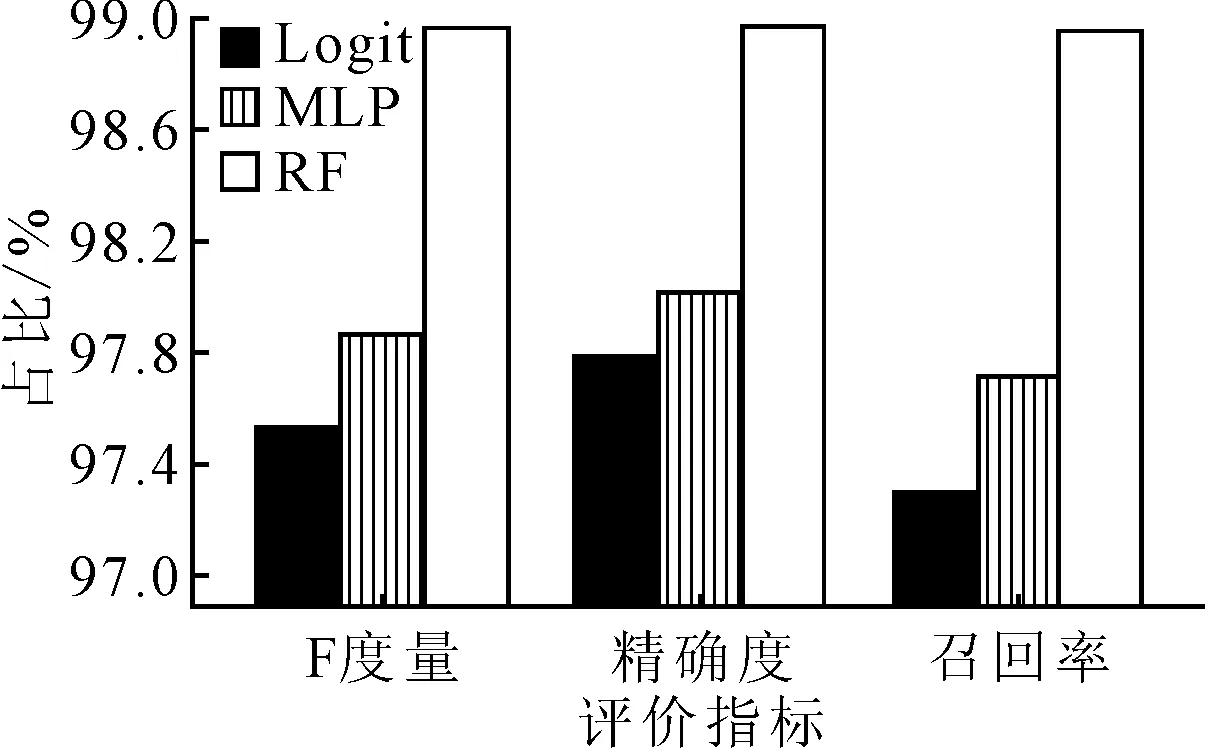
图6 不同分类算法下判别结果的指标对比
3.4 系统性能分析
3.4.1运行时间
以路网交通流数据为基础,不断增加数据规模,分析在不同计算节点数下路网交通运行分析系统的运行时间,结果见图7.当数据规模较小时,增加计算节点的数量对系统的运行时间影响不大;随着数据规模的增大,系统中计算节点的数量越多,其运行时间的越短.
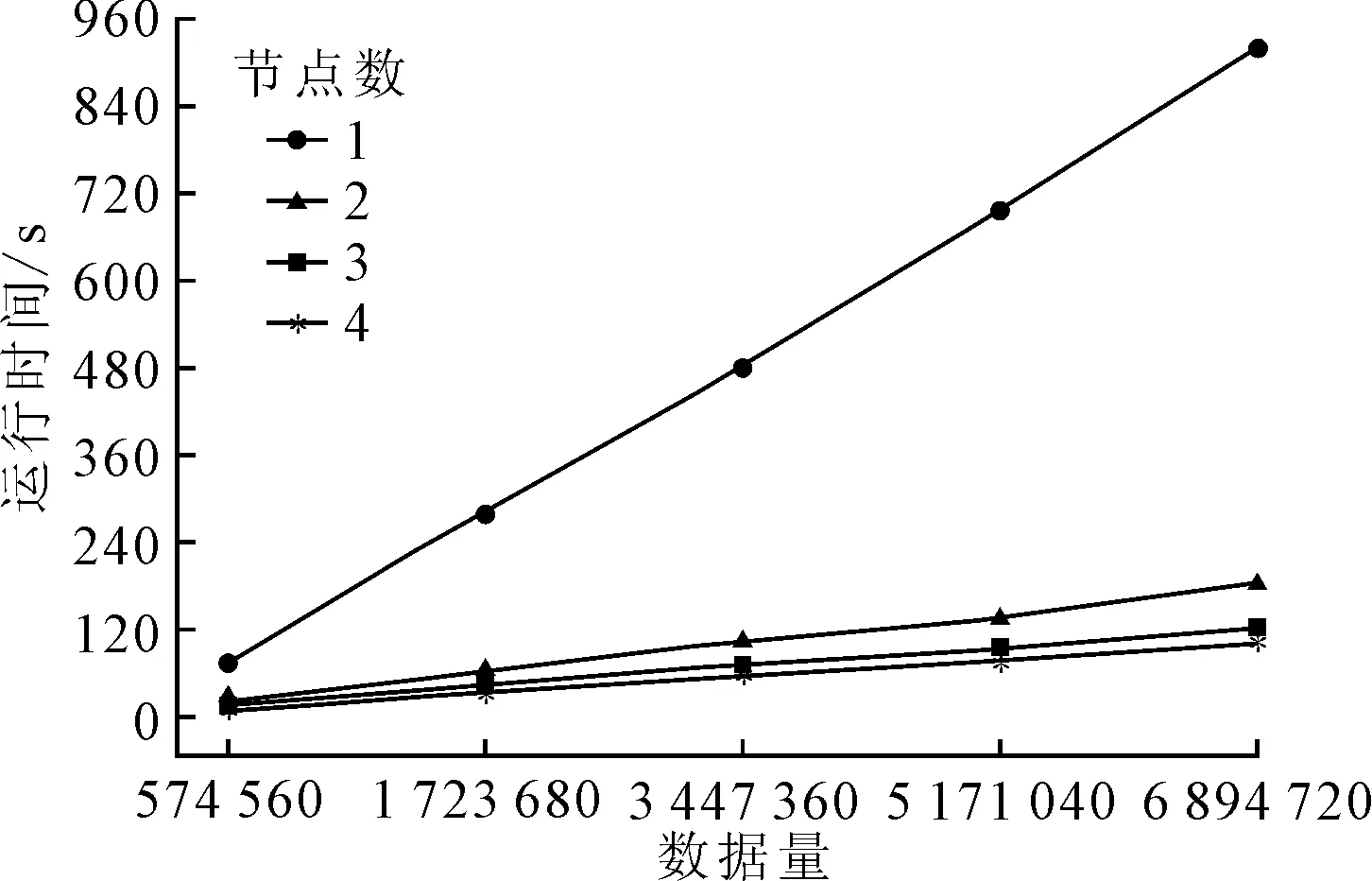
图7 不同节点运行时间对比
3.4.2加速比
在在不同数据规模下,改变系统中计算节点的数量,分析并行判别系统的加速比,结果见图8.增加计算节点的数量,加速比均会上升;当数据规模较少时,加速比随着计算节点数量的增加先增大后趋于平稳;当数据规模较大时,增加系统中计算节点,系统的加速比也不断上升.
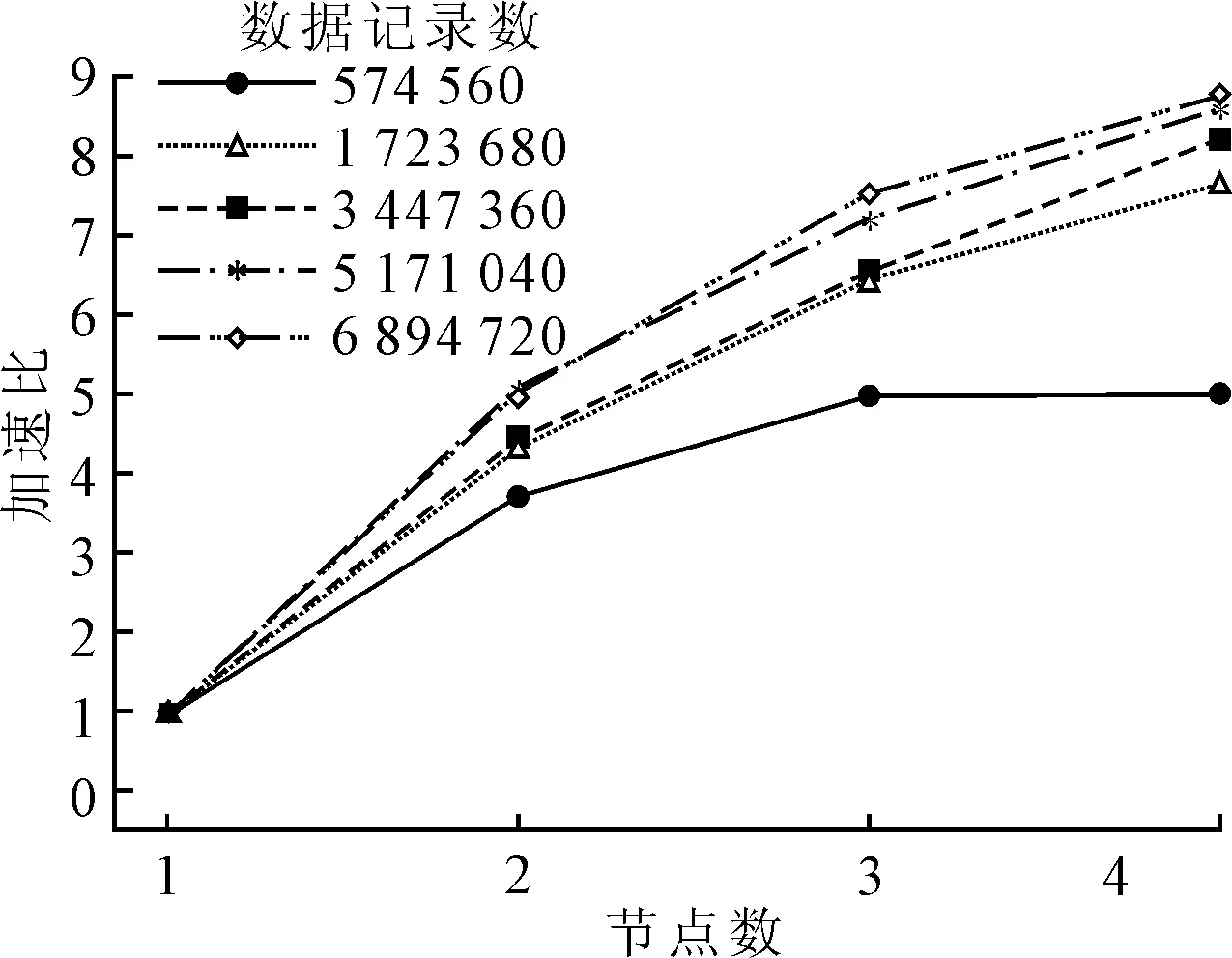
图8 路网交通运行分析系统加速比
3.4.3可扩展性
以不同规模数据为基础,通过改变系统节点数量分析路网交通运行分析系统的运行时间,结果见图9.增加系统中计算节点的数量,数据的运行时间均有所下降;数据规模越大,系统的运行时间下降的幅度越大,说明路网交通运行分析系统适用于不同规模数据处理,具有良好的可扩展性.
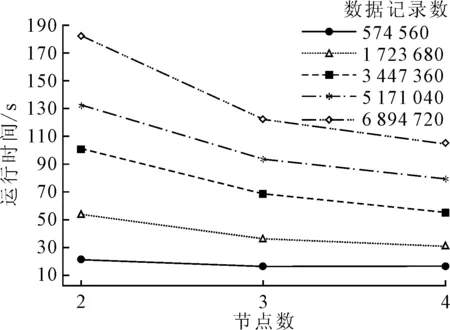
图9 路网交通运行分析系统可扩展性
4 结 论
1) 以交通流量、速度和占有率为基础进行交通运行状态评价,从而更加全面、准确的反映路网中的路网运行状态.
2) 经实验证明,相较于传统的运算系统,本文提出的并行运算系统结果依然可靠、准确,系统的加速比提升了近50%,并具有良好的可扩展性,能更有效的对大规模数据进行处理.
3) 本文采用定点检测器采集的交通流量、速度和占有率数据实现路网交通状态的判别,检测器的布设密度对实际结果具有一定的影响.因此,在未来的研究中,采用定点检测器数据与动态采集设备的数据相融合,能进一步提高交通状态判别的准确性和可靠度.
