基于多种生理信号的情绪识别研究
2020-08-10陈沙利张柳依江锋陈婉琳缪家骏陈杭
陈沙利,张柳依,江锋 ,陈婉琳,缪家骏,陈杭
1 浙江大学 生物医学工程与仪器科学学院,杭州市,310027
2 生物医学工程教育部重点实验室,杭州市,310027
3 浙江省心脑血管检测技术与药效评价重点实验室,杭州市,310027
4 浙江大学 心理与行为科学系,杭州市,310027
0 引言
情绪是由某种特定的对象或情景所引发的一系列反应,通常由主观感受、肢体表达和生理状态的协调变化组成[1]。研究表明,情绪会影响人的解释、判断、决策、推理及风险认知等高层次的认知过程[2],在人的日常生活及沟通交流过程中扮演着非常重要的角色。近年来,情绪识别技术逐渐成为研究热点,在人机交互、医疗健康、社交媒体、游戏、智能教育、认知负荷[3]等领域拥有广泛的应用前景。
詹姆士(James)-兰格(Lange)[4]的情绪理论认为,情绪是自身对由刺激引发的循环系统、消化系统、内分泌系统、交感神经系统等机体变化的一种体验和感觉。因此,可以通过分析与每种情绪相关的生理变化的模式来检测情绪。同时,由于伴随情绪的生理变化具有自主性,不受主观意念控制,因此与直接观察面部表情和身体姿态等外部行为表现相比较,基于生理信号的情绪识别能获得更加客观真实的结果[5]。
目前常用的情绪识别方案多使用脑电信号来表征大脑皮层的神经活动,以反映情绪状态,已获得了较好的结果。但脑电信号采集困难,并且由于采集装置的复杂性,会对受试者造成不适,影响其情绪,最终影响信号采集效果。而外周生理信号采集简便,同时也能在一定程度上反映情绪状态,可作为一种有效的补充方案。
本研究提取了脉搏波、皮肤电反应、呼吸、体温等多种信号的时域、频域、非线性特征,采用一种基于支持向量机的可减少相关性偏差的递归消除特征排序(SVM-RFE-CBR)算法进行特征选择,并使用DEAP数据库进行验证,利用支持向量机分别对愉悦度、唤醒度和优势度进行二分类,实现了基于多种外周生理信号的情绪识别。
1 数据来源
DEAP是一个用于人类情绪分析的多模态数据库[6]。数据库共有32名参与者,每人观看40个情绪内容不同的音乐视频,其中17个视频具有来自last.fm网站的情感标签,每个视频持续1 min。采用512 Hz的采样率采集脑电、肌电、呼吸、皮肤电反应、眼电、脉搏波和皮肤温度等生理信号,同时记录了1~22号参与者观看视频时的面部表情。参与者在每次试验后对视频进行Valence(愉悦度,范围从消极到积极,表明情绪从令人不愉快到愉快)、Arousal(唤醒度,范围从被动到活跃,表明情绪的激烈程度)、Dominance(优势度,范围从受控到自主,反映了人在某种情绪中的控制能力)几个维度的评分,范围为1~9。
每位被试的生理数据按照观看不同视频时的状态被分为40段,每段包含3 s基线状态和60 s测试状态 (观看情绪视频时的状态)。对于采集了面部表情视频数据的参与者,选取观看带有情感标签的视频时采集的脉搏波、皮肤电反应、呼吸和皮肤温度4种信号的数据构建子数据集,便于由人工判断受试者是否被激发了相应的情绪。分别使用参与者所打出的Valence、Arousal、Dominance评分作为分类标准,将1~3分和7~9分分为两类,使用0和1进行标记。
2 情绪识别方案
情绪识别方案包含特征提取、特征选择及情绪分类三个部分。
2.1 特征提取
对选取的每种信号,进行低通滤波、去除基线漂移等预处理,取60 s测试状态下的数据进行特征提取。得到的序列记为PPS(PP interval sequence)。对预处理后脉搏波(photoplethysmography,PPG)、皮肤电反应(galvanic skin response,GSR)、呼吸(respiration amplitude,RSP)和皮肤温度(skin temperature,SKT)信号分别提取多种特征,具体如表1所示。

表1 提取的特征Tab.1 Extracted features
表1中,Picard参数[9]包括6个统计学参数:原始信号均值μs、标准差σs、一阶差分绝对值的均值δs、二阶差分绝对值的均值γs,标准化后信号的一阶及二阶差分绝对值的均值。小波分解后,用ca1表示低频(近似)系数,cd1~cd4分别表示1~4层高频(细节)系数,最大值、最小值、均值、中值、标准差及总和分别用max、min、mean、median、std、sum表示。此外,对每种信号均提取了谱熵SpeEn、小波熵WavEn、样本熵SampEn、近似熵ApEn等特征。
为了消除不同个体间的差异,提高数据可比性,对所提取的每个特征均采用Z-score标准化方法进行处理。计算式如下:

2.2 特征选择
所提取的多个特征中,有些特征之间可能存在相关性,会产生冗余,容易导致以下后果:①特征分析及模型训练时间过长;②引起过度拟合,泛化能力差,识别率低;③引发“维数灾难”,导致模型性能下降[10]。因此,进行特征选择十分必要。利用SVM-RFE-CBR方法进行特征排序后,采用步进法进行特征选择。
SVM-RFE(recursive feature elimination)是一种基于支持向量机(support vector machine,SVM)进行特征排序的方法。对于线性分类问题,进行特征选择时理想的目标函数是计算误差的期望值,即在无限个特征组合情况下计算误差率。在SVM-RFE中,这个目标函数由在训练集上计算的成本函数进行替代[11]。因此SVM-RFE的基本思想为,计算由于删除特征xi而导致的成本函数DJ(i)的变化。

可求得w的解为:

αi为拉格朗日乘子,则成本函数[12]:

通过构建的SVM分类器训练样本,计算每个特征的成本函数并对其进行排序,将得分最小的特征移入无效特征集Fout后,用剩余有效特征集Fin再次训练并进行下一次迭代,直到对所有特征完成排序。具体迭代步骤如下:①初始化有效特征集Fin为所有提取出的特征,无效特征集Fout为空;②利用特征集Fin训练SVM分类器,得到w;③计算DJ(i),找出min{DJ(i)},i∈Fin,将该特征移入Fout;④更新特征集Fin并进行下一次迭代;⑤得到排序后的特征集。
虽然SVM-RFE是一种有效的特征选择方法,在特征数量较大时,可有效地避免过度拟合。但是研究表明,当特征空间中存在大量高度相关的特征时,这种方法会产生较大偏差。即:若在一次迭代中,某一组高度相关的特征中有一部分特征的成本函数因得分较低而被移除,那么这整组特征都可能会被移出Fin。
因此采用了一种可减少相关性偏差(correlation bias reduction,CBR)的方法[13]。这种方法旨在将Fout中潜在的有效特征移回Fin,避免某些特征的重要性被低估而得出错误的特征排序,被证明可有效地提高特征选择的表现。具体过程为:①在每次RFE迭代完成后,找出Fout中得分最高的特征并标记为K;②找到所有与K的相关系数较高的特征;③若这些特征没有一个处在Fin中,就将K移回Fin并进行下一次迭代。
在利用SVM-RFE-CBR对所有特征进行排序后,采用SPSS(版本15.0)中的步进法选择特征,在每个步骤中,输入可以使总体威尔克Lambda 最小化的变量,再将最终选出的特征作为分类器的输入进行情绪分类。
2.3 情绪分类
SVM是目前情绪识别中最常用的一种方法,它在高维的小样本数据处理方面有独特的优势[14],且拥有优秀的泛化能力。SVM为有监督的学习模型,基本思想是:线性可分的情况下,在特征空间RD中构建一个超平面将不同种类的样本区分开来。对于预测类别yi,有:

为了尽可能地增大样本间的区分度,提高模型的分类准确率,需要将样本点到超平面的最小距离最大化。因此目标函数为:
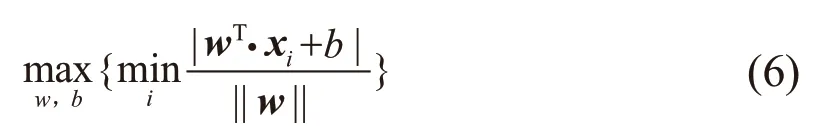
线性不可分的情况下,可通过一个非线性映射,把特征空间映射到一个具有核函数的高维空间,使得在原来的特征空间中非线性可分的问题转化为在高维空间中线性可分的问题。核函数可以降低维数增加带来的计算复杂性[10]。
采用K折交叉验证[15]进行检验以得到稳定可靠的分类模型,即将原始数据随机分成K份,保留其中一份作为测试集,其余K-1份作为训练集,重复K次并将分类准确率的结果取平均以得到一个单一的估测值。本研究中K=5。
3 结果
3.1 特征选择结果
经过特征排序和步进法进行特征选择后,最终选出分别用于Valence、Arousal、Dominance的分类,提取自不同信号的特征集如表2所示:

表2 用于愉悦度、唤醒度和优势度的分类特征Tab.2 Classification features for Valence,Arousal and Dominance
从表2中可知:
(1)特征集中对Valence轴进行分类的有效特征较少,表明Valence的区分难度更大;
(2)相比原始PPG信号,脉率变异性等特征包含了更多情绪方面的信息;
(3)PPG高频信号隐含的情绪信息比低频更多,因此更多的高频特征被选入特征集;
(4)特征集中包含了多个小波变换相关特征,表明小波变换是一种对于情绪特征的有效提取方法;
(5)与Valence有关的特征几乎来自于脉搏波信号;Arousal与脉搏波、呼吸、皮肤温度等信号有更大的关联;而Dominance则与脉搏波、皮肤电反应、呼吸等信号有更大的关联。
3.2 情绪识别结果
对于每个数据样本,根据参与者所打出的Valence、Arousal、Dominance评分,可分别标记不同的真实标签0或1。通过分类器进行分类后,SVM模型会判断该样本所属的类别,并输出结果标签0或1。使用TN(true negative)表示真实标签为0,结果标签为0的样本数量;FN(false negative)表示真实标签为1,结果标签为0的样本数量;FP(false positive)表示真实标签为0,结果标签为1的样本数量;TP(true positive)表示真实标签为1,结果标签为1的样本数量。
根据T N、F N、F P、T P构建分类结果矩阵,展示在每个类别中分类正确和错误的比例,结构如表3所示。此外,分类准确率(accuracy,ACC)被定义为:(TP+TN)/(TP+TN+FP+FN),表示正确分类的样本数占总体样本数的比例。阴性预测值(negative predictive value,NPV)和阳性预测值(positive predictive value,PPV)数值越高,分类准确率越高,表明分类效果越好。

表3 分类结果矩阵结构Tab.3 The structure of classification result matrix
表4展示了使用SVM分类器对Valence、Arousal、Dominance进行二分类的分类结果,表5展示了三种分类的准确率。
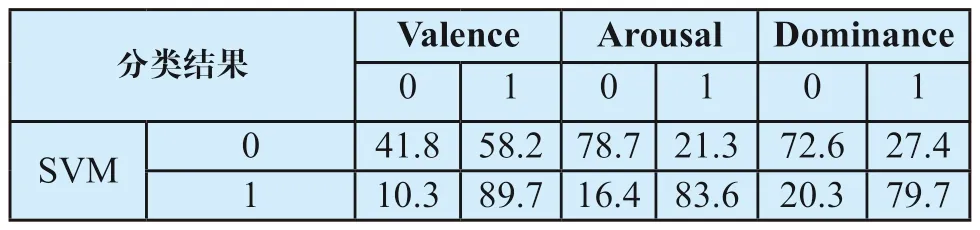
表4 支持向量机的分类结(%)Tab.4 Result of classification by support vector machine

表5 支持向量机的分类准确率(%)Tab.5 Classification accuracy of support vector machine
(1)在分类结果矩阵中,对Arousal进行分类的NPN、PPV以及ACC最高,表明对Arousal所提取的特征有最好的分类效果,对Valence和Dominance所提取的特征分类效果较差。这可能是由于Arousal所代表的情绪激烈程度的变化会更多地引起生理方面的变化;也可能是由于视频材料更多地诱发了在Arousal轴上区分度较大的情绪。
(2)整体的分类准确率不够高,原因可能是数据的不平衡。不同类别中的数据量相差较大导致构建的分类模型不够稳定,分类器倾向于将样本分到数据量较大的类别中。同时由于总体样本量较少导致模型性能下降,识别率低。
4 讨论
本研究提供了一种使用外周生理信号进行情绪识别的方案,采用DEAP数据库构建的子数据库进行验证,对Valence、Arousal、Dominance三个轴分别进行二分类,获得了最高81.3%的识别准确率。在没有使用脑电信号的情况下,获得了与使用脑电和多种外周生理信号进行情绪识别时近似的识别效果,为今后发展更加便捷有效的情绪识别方案提供了可能。
本研究所提出的情绪识别方案分类准确率不够高,主要有以下两个原因。首先,只使用了DEAP数据库的部分子数据集,因此用于模型训练的数据量不够大,导致构建的模型不够完善。其次,情绪识别过程受人体差异的影响较大,通常来说对于单个人不同情绪的识别准确率要远高于对不同人的情绪识别准确率。因此,在后续研究中需要增大数据量,以优化分类模型。也可将生理信号与语音、面部表情等与情绪有关的信息相结合,形成多模态、多特征融合的情绪识别方案,以进一步提高情绪识别的准确性和鲁棒性。
