互动认知视角下网络百科协同创作机理研究
2020-08-07刘丰军林正奎
刘丰军 林正奎 曲 毅
(大连海事大学航运经济与管理学院)
1 研究背景
Web 2.0时代,协同创作、协同计算、协同设计、协同研发等协同模式深刻改变了群体协作模式,创造了巨大的社会价值、商业价值和学术价值[1]。其中,以网络百科(维基百科、百度百科等)为代表的知识协同创作倡导“人人皆可编辑”的UGC知识生产模式,颠覆了传统的PGC知识生产模式,成为协同创作的成功典范[2]。
基于内容开放共享的网络百科协同创作(OECC),学者们从用户、内容和社区3个层面,对用户动机、内容质量和社区运作等方面进行了广泛深入地研究,以揭示知识协作的内在机理。例如,张薇薇等[3]基于活动理论模型,构建了互联网用户协同创作与内容共享的活动系统模型。CRESS等[4]及KIMMERLE等[5]基于社会系统理论和认知平衡理论,构建维基社会系统和个体认知系统协同演化模型。LI等[6]基于SECI模型提出了虚拟社区环境下的知识构建过程模型,描述知识建构的渐进过程。在研究方法上,OECC模式研究主要以理论分析为主,采用案例研究、社会网络分析、系统仿真等方法,对群体协作过程和模式进行阐述。例如,OEBERST等[7]以维基百科词条——福岛核电站事故为例,从系统建构主义观剖析群体协同知识建构的过程。JANKOWSKI-LOREK等[8]构建了多维行为社会网络模型,用于揭示维基百科知识协作的行为模式。WANG等[9]以中文维基百科为例,采用系统动力学方法构建了知识协作动机因素的系统动力学模型,以揭示群体知识协作的动力学机制。不可否认,现有研究成果增进了对OECC的认知和理解。但还存在一定的局限性:①在研究视角上,很多研究忽视了OECC动态演化的特点,采用静态视角,无法客观真实地反映系统因素间的动态关系;②在研究方法上,大多数研究仍停留在概念化或模型化的纯理论层面,缺乏严格意义上的实证研究。此外,现有研究普遍采用传统的横向研究法,无法对因素间的互动关系进行分析。
本研究拟从互动认知视角,基于皮亚杰建构主义理论,构建网络百科协同创作演化模型。在此基础上,以百度百科词条——NBA为例,综合运用向量自回归模型、Granger因果检验、脉冲响应函数、方差分解等方法进行系统地实证分析。本研究不仅在理论上丰富了对OECC内在机理的认知和理解,而且在研究方法上为该研究领域提供了新的思路和视角。
2 网络百科协同创作演化模型构建
OECC的过程,本质上是认知主体和知识客体通过认知交互实现双向知识建构的过程。根据皮亚杰建构主义理论,个体认识发展实质上是通过内化和外化双向建构活动,实现认知结构“平衡—不平衡—平衡”的动态建构过程[10]。鉴于此,本研究引用“平衡化”概念解析OECC的基本过程。当个体认知结构与系统知识内容存在认知差异,认知平衡被打破。此时,个体通过内部同化(在原有的认知结构中添加新的信息,定量知识学习)或内部顺化(改变原有的认知结构,定性知识学习),对原有认知结构进行调整或改变,重新恢复认知平衡,实现个体知识学习。同时,个体还会通过外部同化(对系统知识内容进行扩充或删减,定量知识建构)或外部顺化(对系统知识内容进行重新组织,定性知识建构),对系统知识内容进行编辑,实现系统知识建构[4](见图1)。图1中,Vi表示百科词条版本号,T表示时间。
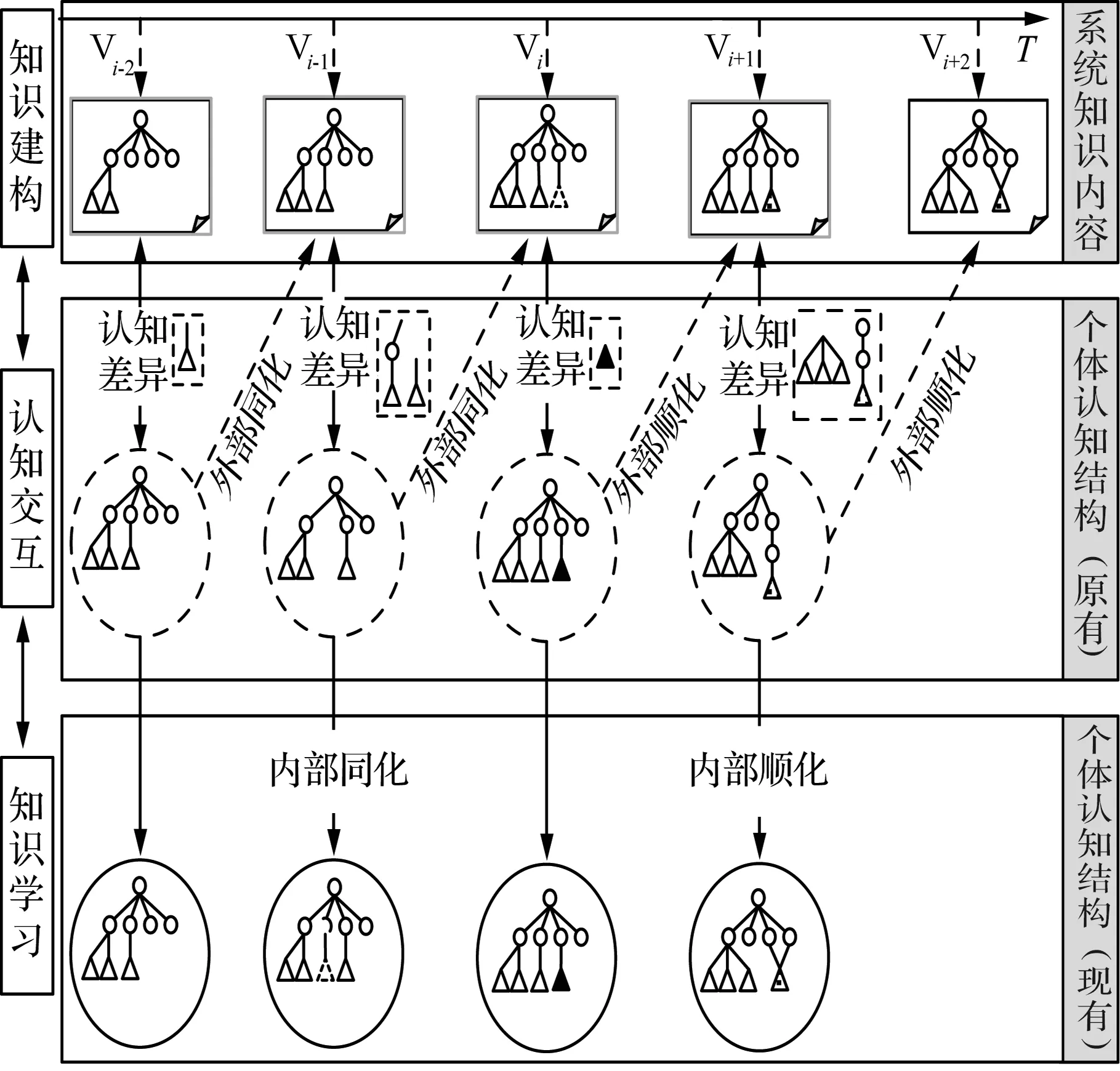
图1 网络百科协同创作过程
基于以上分析,本研究提出了网络百科协同创作演化模型(见图2)。OECC系统被划分为知识系统和认知系统,两个系统间的协同演化类似于双齿轮联动模型:两个齿轮沿各自的轴旋转(类似于模型中的知识系统和认知系统间的循环动力学),通过相互作用(类似于模型中的内驱力——认知差异),实现轨迹漂移(知识演化和认知发展)。信息质量是群体知识协作的结果和目的,是衡量群体绩效的关键指标,因此,信息质量属于知识系统的核心要素,知识系统的演化本质上体现了信息质量的动态变化过程。此外,OECC完美地诠释了群体智慧的理念,大量参与者拥有丰富的认知资源,成为知识协作的重要基础和根本保障。由此可知,群体规模是认知系统的核心要素,认知系统的发展主要依靠群体规模的不断扩大。简言之,认知差异与群体规模和信息质量之间的相互作用,推动了OECC系统的协同演化。
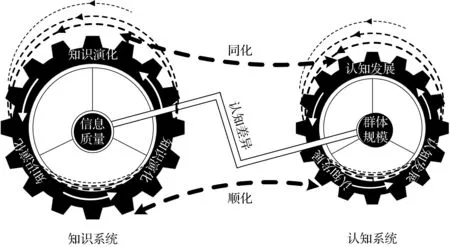
图2 网络百科协同创作演化模型
3 认知差异概念界定及分类
本研究将认知差异的概念定义为:认知差异发生于个体感知到自己的知识或态度,与个体在环境中所遇到的知识或态度之间存在差异或不匹配;这种差异或不匹配可能涉及数量上或质量上的差异[11]。知识学习通常被描述为一个概念改变的过程。概念改变最初是基于皮亚杰建构主义理论提出的,通过一个人对物质世界的心理模型的逐步补充或修改来实现[12]。概念改变中的补充和修改,是对皮亚杰建构主义理论中的同化和顺化的深化和扩展,两者间存在密切关联。基于概念改变与认知发展间的“同构”关系,本研究将认知差异划分为认知结构差异和认知风格差异两大类。其中,认知结构差异反映了个体间内在认知结构上的不同,主要体现于对事物或问题在概念、观点、态度等结构属性方面的差异,包括认知相容(包含关系和交叉关系)与认知不相容(反对关系、矛盾关系和全异关系)。认知风格差异则反映了个体在认知风格上的不同,具体体现在对信息加工、处理、表达等风格属性方面的差异[13],只包含全同关系一种概念间关系。此外,按照差异程度,将认知程度分为低等、中等、高等3个级别,分别对应认知风格差异、认知相容、认知不相容。
4 研究假设
4.1 认知差异与群体规模
从认知心理学理论出发,皮亚杰认知发展理论认为,个体认知的发展就是“平衡—不平衡—平衡”的动态演进过程。当客体与自身的认知结构存在差异(即认知差异)时,认知平衡被打破,从而激发个体通过同化或顺化与客体进行相互作用,以恢复平衡状态[10]。CRESS等[4]基于皮亚杰平衡理论,认为个体参与维基百科的主要动机源于认知冲突。此外,根据费斯汀格的认知失调理论,当一个人持有两种或两种以上不一致的认知(思想、态度、信念、意见)时,会感到不愉快和不和谐,进而产生紧张感[14]。基于行为的认知失调模型可知,认知失调会促使个体通过改变行为或态度,或者引进新的认知元素等一系列行动导向,引导有机体有效地参与意图(承诺),消除不协调感,以恢复“心理平衡”[15,16]。WU等[17]研究发现,群体协作过程产生的认知差异能够驱动个体参与意愿,缓解认知失调带来的不适感。
不同程度认知差异对个体参与意愿产生不同的影响。在教育学研究领域,大量实验表明,中等难度任务更能激发个体学习的动机。根据成就动机理论,问题情境的难度在50%左右最有利于激发学习动机[18]。根据唤醒理论,个体一般偏好中等强度的刺激水平,不喜欢过高或过低的刺激,因为中等强度的刺激能引起最佳的唤醒水平[19]。此外,基于耶基斯-多德森定律,MOSKALIUK等[20]认为中等水平的认知差异导致认知冲突,进而激活“平衡”过程,促进个体参与学习和协作知识构建,并通过实验验证了这一观点。由此提出如下假设:
假设1a认知差异对群体规模存在正向影响。
假设1b认知差异与群体规模间存在倒U形关系,中等程度认知差异对群体规模的影响最显著。
4.2 认知差异与信息质量
认知差异在一定程度上反映了群体认知多样性。从信息/决策的观点出发,异质性群体优于同质性群体。异质性群体拥有更广泛的与任务相关的认识资源,包括知识、观点、经验和技能,不同认知和观点碰撞产生“创造性摩擦”,从而产出高质量的信息或做出科学的决策[21,22]。此外,中等程度的认知差异会导致认知冲突,大多数研究认为认知冲突会对团队绩效产生积极的影响。因为认知冲突可以避免集体的一致性思维,促进团队之间的信息交流,加深对任务和问题的理解,有利于团队创造出更好的绩效[23]。
耶基斯-多德森定律描述了压力(觉醒)和表现之间的倒U形关系,即中等强度的压力下个体表现最佳。耶基斯-多德森定律在行为科学领域中得到了广泛应用,有学者将其应用到认知差异与表现关系的研究中。LEE等[24]提出,认知冲突是概念转变的第一步。焦虑是认知冲突的重要组成部分,影响认知冲突与学习反应的关系。适当水平的认知冲突对个体学习产生积极的正面影响,而过低或过高的认知冲突将对个体学习产生消极的负面影响,因此,不同程度的认知差异对个体刺激和唤醒水平不同,进而激发不同水平的认知努力,并对信息质量产生影响。由此提出如下假设:
假设2a认知差异对信息质量存在正向影响。
假设2b认知差异与信息质量间存在倒U形关系,中等程度认知差异对信息质量的影响最显著。
5 研究方法与数据获取
5.1 VAR模型
传统的单变量自回归模型将一个随机变量(如国民收入)的动态变化,描述为其自身过去的线性函数,然而,现实社会经济系统中多个变量(如国民收入、就业、物价、货币供应量、利率等)间通常存在复杂的相互影响关系。向量自回归(vector autoregression,VAR)模型是一种非结构化的动态联立方程模型,用来分析一组宏观经济变量之间的联合动力学和因果关系,是单变量自回归模型向多变量情形的推广,在整个计量经济学体系中占据着重要地位[25]。VAR模型具备不以严格的经济理论为依据,无需事先区分变量的外生性和内生性,解释变量中不包括任何当期变量等优点,克服了传统联立方程模型(结构化)受制于经济理论而带来的诸如内生变量和外生变量的划分、估计和推断等复杂问题,在描述经济和金融时间序列的动态行为和预测方面有着广泛的应用[26]。
VAR模型的数学表达式如下:
yt=Ø1yt-1+Ø2yt-2+…+Øpyt-l+Hxt+εt,
(1)
式中,yt是k维内生变量列向量;xt是d维外生变量列向量;t是时间期数;l是滞后阶数;Ø1,Ø2,…,Øp和H是待估计的系数矩阵;εt是随机扰动项。在VAR模型的基础上,综合运用Granger因果关系检验、脉冲响应函数和方差分解等方法,对变量之间的短期因果关系与长期均衡关系进行分析。
5.2 样本选择与数据获取
百度百科是百度公司于2006年推出的一个内容开放、自由的网络百科全书平台,已经成长为国内最大最具代表性的网络百科平台。本研究选择百度百科词条——NBA作为研究对象,主要原因包括:①词条具有代表性。百度百科词条一般分为特色词条、专家词条和一般词条。尽管特色词条和专家词条属于高质量词条,但所占比例不到1.5%,所以选取NBA这样的一般词条更具一般性和普适性。②用户参与度高。截止到2019年7月29日,该词条历经13年的发展,共吸引了近1 340个用户,累计1 866次编辑。③话题关注度高。NBA作为全球四大体育联盟,是全世界最受欢迎的篮球联赛,同时也是中国最受欢迎的体育赛事,为该词条赢得了极高的关注度,浏览次数超1 290万次,点赞数近2万个,转发量近628次。总之,NBA作为百度百科最具代表性、高参与度、高关注度的词条,成为理想的研究样本。
鉴于百度百科不提供词条数据的开放获取服务(API接口),样本数据获取综合爬虫自动抓取(八爪鱼采集器)和人工手动采集两种方式。数据主要包括:①词条页面数据,主要获取编辑次数、图表数量、链接数量等数据;②历史页面数据,主要获取更新时间、贡献者、修改原因等数据;③用户页面数据,主要获取用户等级信息。
5.3 变量测度
(1)认知差异(D)对于低等(DL)、中等(DM)和高等(DH)认知差异类型的判别,主要采用人工标注法:一方面通过对词条修改原因进行文本分析判别,另一方面通过对比词条历史版本差异进行文本分析判别。为了减少主观性,提高判断的准确性,选取3名研究人员进行独立判断,对判断结果不一致的选项进行意见统一;同时,邀请2位该研究领域的专家对标注结果做进一步审核和修正。
(2)群体规模(S)目前,学者们对群体规模的测度方法较为一致,主要通过计算参与人数来反映群体规模的大小[27]。据此,本研究通过计算NBA词条的月度参与者数量测度群体规模。
(3)信息质量(Q)鉴于信息质量评价的复杂性,词条信息质量的测度通常需要考虑多种因素,这些因素主要涉及用户维度(群体特征和用户属性)、内容维度(词条长度、词条年龄、图标数量、链接数量等)和网络维度(网络中心性、结构洞等)[27]。本研究借鉴STVILIA等[28]提出的信息质量的计算公式,并结合百度百科系统结构要素,提出信息质量的计算公式:
Qt=0.4Et+0.2EHt+0.4ELt-0.4DYt+0.6Rt+
0.03Ct+0.01LKt+0.001At+0.001LHt,
(2)
式中,E为编辑次数;EH为5等级以上用户编辑次数;EL为5等级以下用户编辑次数;DY为多样性;R为回退次数;C为图表数量;LK为链接数;A为词条年龄;LH为词条长度。
6 实证分析
6.1 描述统计与相关分析
基于上述方法,本研究获取了NBA词条2008年1月~2019年5月月度时间序列数据(1)百度百科正式版于2008年上线,为了保证数据可靠性,本研究以2008年1月作为时间序列数据获取和实证分析的起点。。对各个变量进行统计描述和皮尔森相关系数计算。其中,认知差异、群体规模和信息质量间的相关系数均在0.77以上,说明了三者间存在强相关性,初步验证了假设1a和假设2a。另外,从总量分布上来看,中等认知差异数量最多,几乎占据了认知差异一半数量,高达46.9%。同时,在3种程度认知差异与群体规模和信息质量相关性分析中,中等认知差异与群体规模(r=0.712)和信息质量(r=0.670)的相关性最高,初步验证了假设1b和假设2b。
6.2 单位根检验
为了避免产生“伪回归”,需要对变量进行单位根检验,判断其平稳性。本研究采用Eviews 10.0软件,通过ADF单位根检验对变量平稳性进行检测,结果见表1。表1中,①检验形式中的C、T和K分别表示常数项、趋势项和滞后阶数;②滞后阶数的选择标准是以SC值最小为准则;③为了消除时间序列异方差,对变量进行自然对数变换,分别记为lnD、lnS、lnQ、lnDL、lnDM和lnDH。由表1可知,所有变量在1%的显著性水平下的ADF统计值均小于其相应的临界值,表明3个变量原序列都是平稳序列。
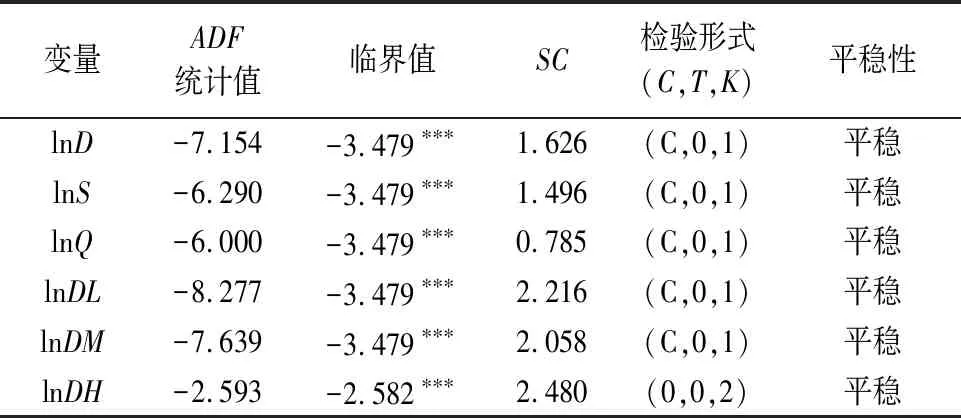
表1 单位根检验结果
6.3 VAR模型构建
在建立VAR模型前,需要先确定模型的最优滞后阶数。本研究同时参考序贯修正似然比检验(LR)、最终预测误差(FPE)、赤池信息准则(AIC)、施瓦兹准则(SC)、汉南-奎因准则(HQ)5个准则,最终选定模型的最优滞后阶数(Lag)分别为3、4、1和1,具体结果见表2。
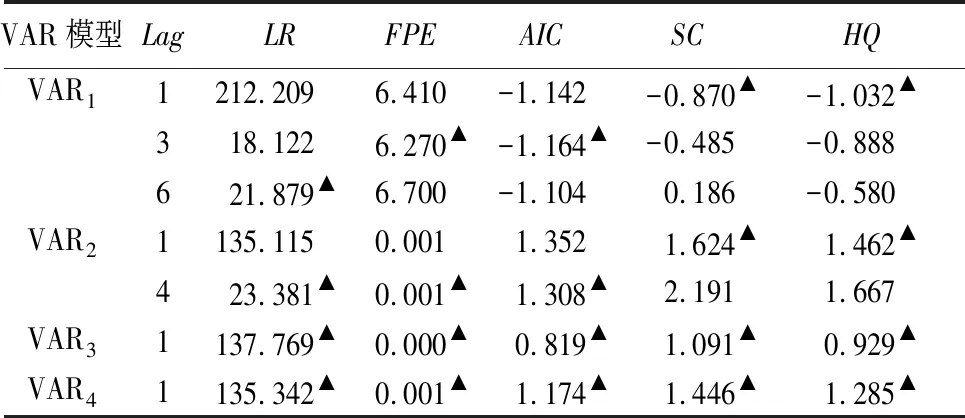
表2 最优滞后阶数检验结果
根据最优滞后阶数建立VAR模型,并对模型进行估计。鉴于VAR模型固有的复杂动力学特性,参数估计值所包含的信息量较少,其经济解释很困难,因而单纯分析模型估计结果意义不大,通常更多地关注Granger因果检验、脉冲响应函数和方差分解的结果[29]。鉴于此,仅列出模型估计的主要参考指标(见表3)。整体来看,VAR模型估计的AIC和SC值都较低,拟合效果较好。此外,为了检验VAR模型的稳定性,对VAR模型的AR特征多项式的逆根进行计算,所有圆点全部落在单位圆内,表明4个VAR模型均是稳定的。

表3 VAR模型估计主要参考指标
6.4 Granger因果检验
Granger因果检验作为判断变量间因果关系的一种方法,为揭示认知差异、群体规模和信息质量间因果提供了理想的方法。
Granger因果检验结果见表4。剔除检验结果不显著的VAR3模型后,由表4可知,其他模型变量间存在显著的因果关系。具体分析如下:①从认知差异对群体规模的因果检验来看,VAR1模型中,认知差异在1%的显著性水平下拒绝了不是群体规模的Granger原因的原假设,同时联合检验也拒绝原假设,说明认知差异是群体规模的Granger原因。此外,在VAR2模型和VAR4模型中,低等和高等认知差异分别在1%和10%的显著性水平下拒绝了不是群体规模的Granger原因的原假设,同样支持了认知差异是群体规模的Granger原因,进一步验证了假设1a。②从认知差异对信息质量的因果检验来看,VAR1模型中,认知差异在1%的显著性水平下拒绝了不是信息质量的Granger原因的原假设,同时联合检验也拒绝原假设,说明认知差异是信息质量的Granger原因。此外,在VAR2模型和VAR4模型中,低等和高等认知差异在1%的显著性水平下,均拒绝了不是信息质量的Granger原因的原假设,同样支持了认知差异是信息质量的Granger原因,进一步验证了假设2a。
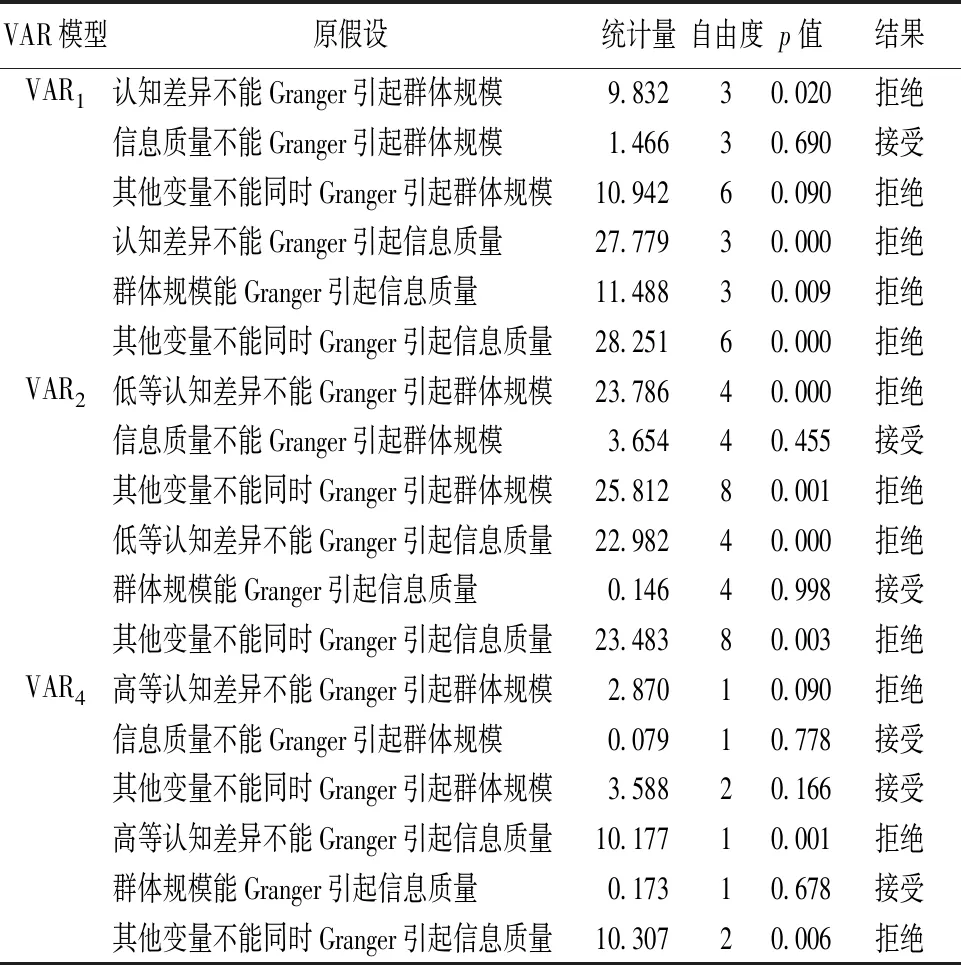
表4 Granger因果检验结果
6.5 脉冲响应函数
脉冲响应函数(impulse response function, IRF)描述了随机扰动项的一个标准差大小的冲击对其他变量当期值和未来值的影响,为揭示各变量间动态交互作用关系提供了更为直观的描述。

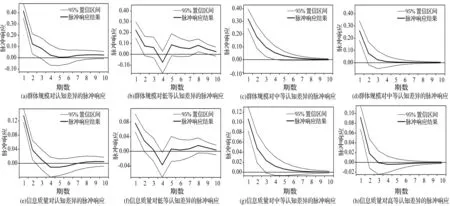
图3 脉冲响应函数图
此外,针对不同程度认知差异对群体规模和信息质量的脉冲响应进行对比分析:①群体规模的脉冲响应。从冲击强度来看,对于低等、中等和高等认知差异的冲击,群体规模当期均达到最高值,分别为0.222、0.320和0.261。同时,10期内群体规模脉冲响应函数的平均值分别为0.065、0.072和0.039。由此可见,中等认知差异对群体规模的冲击力度最大。从冲击时效来看,对于低等、中等和高等认知差异的冲击,群体规模前期均表现为显著的正向响应,但持续时间不一,分别为2期、4期和2期。由此可见,中等认知差异对群体规模的冲击时效最长。整体来看,相比低等和高等认知差异,中等认知差异对群体规模的促进作用更为显著,进一步支持了假设1b。②信息质量的脉冲响应。从冲击强度来看,对于低等、中等和高等认知差异的冲击,信息质量当期均达到最高值,分别为0.077、0.106和0.092。同时,10期内信息质量脉冲响应函数的平均值,分别为0.012、0.020和0.009。由此可见,中等认知差异对信息质量的冲击力度最大。从冲击时效来看,对于低等、中等和高等认知差异的冲击,信息质量前期均表现为显著的正向响应,但持续时间不一,分别为2期、3期和2期。由此可见,中等认知差异对信息质量的冲击时效最长。整体来看,相比低等和高等认知差异,中等认知差异对信息质量的提升作用更为显著,进一步支持了假设2b。
6.6 方差分解
方差分解是将任意一个内生变量的预测均方误差,分解成系统中各变量的结构冲击所做的贡献,根据每个变量冲击的贡献度,评估一个变量的冲击对另一个变量的影响程度。
下面通过方差分解来分析认知差异对群体规模和信息质量的相对重要性,结果见图4。具体来看,由图4(a)可知,除自身外,其变动的贡献度主要源自于认知差异,从第1期的74.47%逐渐下降到第10期的55.13%,平均贡献度高达61.93%。这说明认知差异对群体规模的增长具有很大的促进作用,再次支持了假设1a。由图4(b)可知,除了自身外,其变动的贡献度主要源自于认知差异,从第1期的83.91%逐渐下降到第10期的52.53%,平均贡献度高达64%。这说明认知差异对信息质量的提升具有极大的推动作用,再次支持了假设2a。
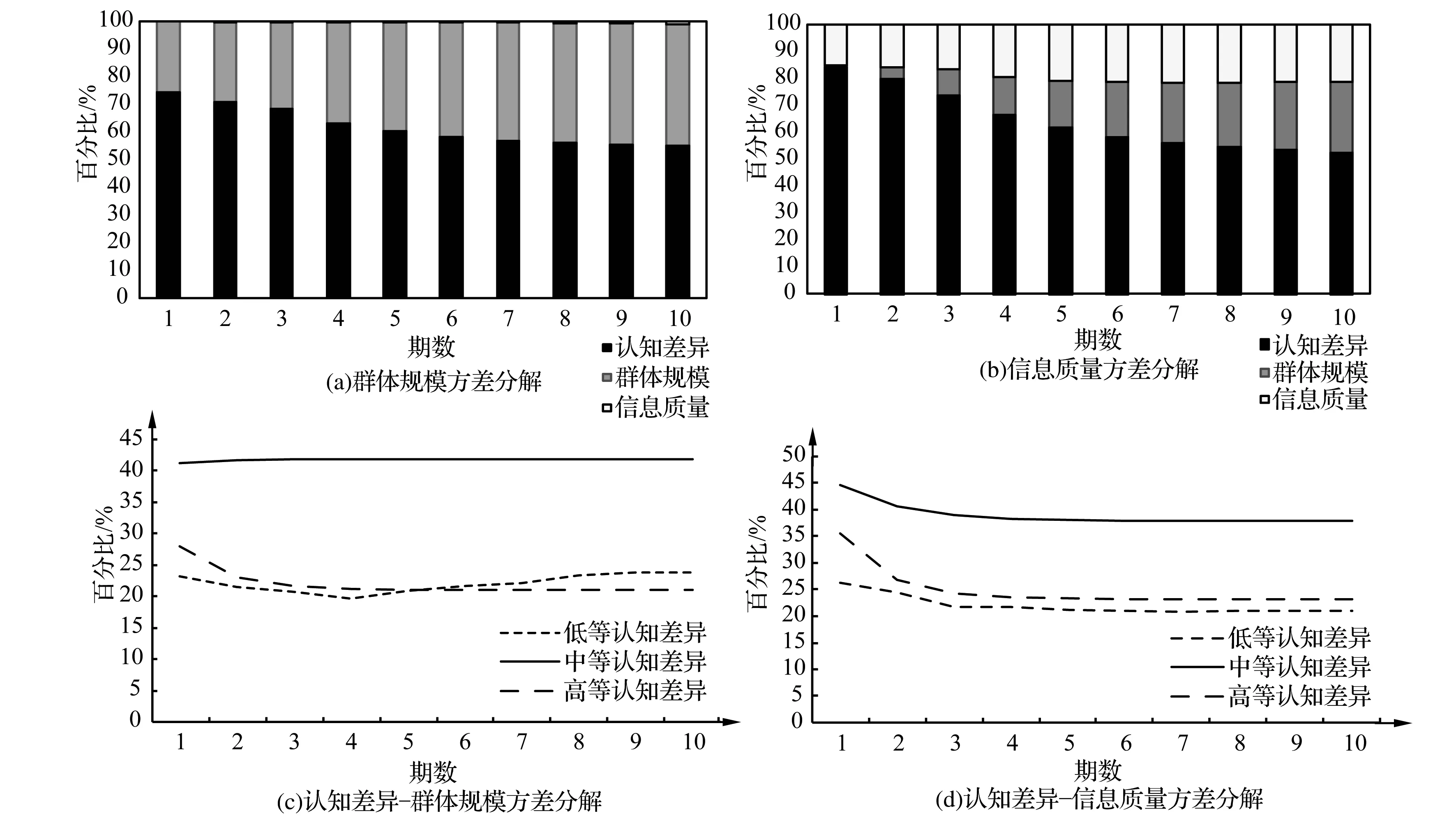
图4 方差分解图
此外,针对不同程度认知差异对群体规模和信息质量的贡献度进行对比分析。由图4(c)可知,中等认知差异对群体规模的贡献度明显高于低等和高等认知差异;低等、中等和高等认知差异对群体规模的平均贡献度分别为22.10%、41.84%和22.05%。由此可见,相比低等和高等认知差异,中等认知差异对群体规模的促进作用更加显著,再次支持了假设1b。由图4(d)可知,中等认知差异对信息质量的贡献度明显高于低等和高等认知差异;低等、中等和高等认知差异对信息质量的平均贡献度分别为22.02%、38.98%和24.92%。由此可见,相比低等和高等认知差异,中等认知差异对信息质量的提升作用更加显著,再次支持了假设2b。
6.7 预测分析
为了检验模型的合理性,对模型的预测能力进行分析。本研究对数据进行了分类,将2008年1月~2018年5月的数据作为实验数据,2018年6月~2019年5月的数据作为预测数据,分别对群体规模和信息质量时间序列进行静态预测。群体规模和信息质量的真实值和预测值对比见图5。由图5可知,绝大多数预测值在90%的置信区间内包含真实值,初步证明了协同演化模型的合理性和VAR方法的适用性。

图5 真实值和预测值对比
为了进一步评估模型的预测性能,对不同模型的预测效果进行对比分析(见表5)。①利用群体规模和信息质量时间序列的自相关系数(AC),与偏自相关系数(PAC)建立时间序列模型;②通过平均绝对误差(MAE)和均方根误差(RMSE)两个预测评价指标,对VAR模型和AR模型进行预测精度对比。由表5可知,相较于AR模型,VAR模型在群体规模和信息质量的预测精度上均有显著的提升,充分证明了协同演化模型和VAR方法的结合具有明显的优越性。
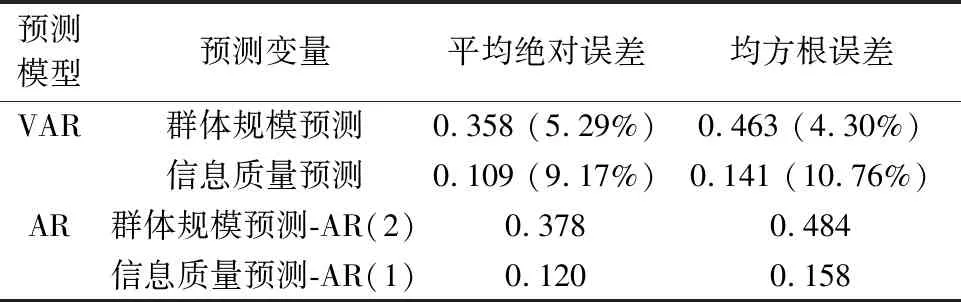
表5 模型预测对比
7 结语
本研究主要结论如下:①认知差异对群体规模存在显著的正向影响。目前尚未有学者考虑认知差异对群体规模的影响,本研究填补了这一研究空白。此外,认知差异对群体规模存在明显的“区间效益”,处于“居中”水平对群体规模的影响最大。尽管有研究表明认知差异可能会引发冲突,导致用户流失[30]。但整体而言,绝大多数用户参与协作的动机是友善的。此外,网络百科平台建立了科学的冲突管理机制,能够有效防范和解决各类冲突。②认知差异对信息质量存在显著的正向影响。不可否认,群体协同创作的过程中存在恶意冲突,但恶意冲突不属于认知差异的范畴。此外,中等程度的认知差异对信息质量的影响最显著,支持了CRESS等[4]提出的“中等程度的不一致最有利于知识建构”观点。综上,认知差异是OECC系统的内驱力。特别是中等程度的认知差异,对于群体智慧的形成和网络百科平台的发展尤为重要。
本研究的理论意义在于:①研究内容上。本研究提出的协同演化模型,不仅体现了因素间的相互作用关系,弥补了现有研究中只关注因素间单向作用关系的不足;还考虑了时间因素,有效捕捉了因素间的动态关系,开拓了OECC的研究思路。②研究方法上。VAR模型具备很多优良特性,无需严格的理论限制,并具备对多个相互关联时间序列进行预测的能力,为探究OECC系统因素间的互动关系提供了新的方法。本研究的实践价值在于:①网络百科平台需创新协作模式,努力营造开放、自由的协作环境,吸引用户参与协同创作;②网络百科平台应强化交互功能,方便用户沟通交流,解决冲突矛盾,提高协作效率。
本研究还存在一些不足:①样本数据局限性。本研究选择单个词条作为研究样本,尽管该词条极具代表性,但可能会影响结论的准确性;后续研究可通过扩大样本量,以更加准确地反映因素间的关系。②研究情境局限性。本研究仅以百度百科作为研究对象,有必要在其他网络百科(如维基百科)检验模型的普适性。
