线性驱动的分布式数据库容错性自动化测试
2020-08-04沈靖蔡鹏
沈靖 蔡鹏


摘要: 大规模的分布式数据库中, 诸如网络分区、信息丢失、节点宕机等软硬件故障无法避免. 为了提高分布式数据库的可靠性、验证容错协议的正确性, 分布式数据库应定期进行故障注入测试, 即在系统运行过程中人为引发故障. 然而各种故障的组合空间太大, 无法枚举. 已有的测试方法: 一类是随机式故障组合, 其实现方法简单但不能保证探索了所有的故障组合; 另一类是通过专业知识分析系统构成并设计的故障组合, 其测试结果更加完善但不具备普及性. 以线性数据驱动的故障注入测试LDFI (Lineage-DrivenFault Injection) 為原型, 在分布式数据库的基础上,实现了一种同时具有完备性和普及性的自动化故障注入测试工具. 实验结果表明, 该测试工具能够以更少的测试案例, 发现随机式故障注入无法发现的复合故障组合所引起的系统漏洞(bug), 提高了数据库的可信度.
关键词: 分布式; 线性数据; 自动化; 故障注入
中图分类号: TP392 文献标志码: A DOI: 10.3969/j.issn.1000-5641.201921011
0 引言
分布式数据库的复杂性使数据库系统无法避免故障发生. 针对分布式场景中可能出现的故障, 如网络延迟、丢包、节点宕机[1-2] 等, 开发人员设计了各类容错协议来应对这些错误的发生, 如数据备份[3-4]、领导者选举[5] 等. 尽管有这么多应对措施, 分布式数据库开发者依旧不能保证自身设计的协议能在故障发生时让系统继续正常提供服务, 实际使用过程中还是会出现很多bug[6-9]. 这就需要故障注入测试主动触发实际应用中可能出现的错误, 验证容错协议的正确性继而提高分布式数据库的可靠性.
故障注入测试主要由两部分组成: 故障注入框架和设计测试案例. 故障注入框架[10-12] 通过各种工具模拟分布式数据库可能产生的故障, 如最简单的方法就是通过强制进程下线来模拟节点宕机, 现在也有许多开源的故障注入框架. 而如何设计故障发生的场景是测试的重点. 主要的设计方式有两类:启发式和随机式故障注入. 启发式的方法, 如SAMC (Semantic-Aware Model Checking)[13] 依赖于测试人员对于整个分布式数据库的理解程度, 需要测试人员有足够深度和广度的专业知识, 因为测试人员知道了整个系统在什么样的场景下可能会发生错误, 才能够设计出特定的故障注入方案来验证容错协议的正确性. 启发式的前提要求太高, 一般测试人员不能保证对每个系统都有足够深的理解, 不具备普及性, 所以更为常见的是随机式故障注入. 随机式故障注入中具有代表性的是ChaosEngineering[14], 测试人员通常在实际的应用场景上随机地向数据库中注入故障, 以此检验容错协议的正确性. 随机式故障注入的主要优点是简单和通用, 但随机式注入故障不可能考虑所有可能发生的错误场景, 而且很难发现涉及多个节点和多个故障组合的复合错误场景. 随机测试只能提高系统的可信度, 不能保证容错协议的正确性.
理想的测试案例不仅能测试出系统bug, 还能保证通过测试的分布式数据库容错协议的正确性.任何生成的测试案例都应该针对容错协议的薄弱点, 而不是无意义的, 如LDFI[15] 就是针对分布式数据库中对正确结果有贡献的数据和操作所制订的测试案例. 本文在LDFI 的启发下, 通过分析分布式数据库运行过程中所产生的线性数据和操作流程, 在可能影响正确结果的步骤中注入故障, 检测容错协议能否保证系统依旧得到正确的结果. 本文主要的贡献如下.
(1) 将线性数据应用在故障测试工具上, 实现了具备更高可信度和普及性, 不需要太多专业领域知识的自动故障注入测试工具.
(2) 介绍了如何克服将理论模型实现在具体应用过程中所遇到的困难, 希望能为开发测试工具的研究者提供经验和教训.
本文后续内容是: 第1 章叙述LDFI 的原理; 第2 章详述测试工具是如何实现的、过程中所遇到的挑战有哪些; 第3 章介绍实验结果; 第4 章是结论和相关工作.
1 LDFI 原理
LDFI 原型系统(称为Molly) 使用Dedalus[16] (基于datalog 编写的可执行规范语言) 编写分布式程序和模拟分布式数据库在各种故障下的执行操作. 主要原理是, 容错协议通过冗余的方法预防系统某一组件出现问题, 即从初始状态到预期结果, 系统会有多种方式达到同样的结果. 这些冗余的操作如果全部枚举会花费大量时间, 且不能保证完全遍历了所有情况. 相对的, LDFI 选择从系统正确执行的结果反推到起始状态, 从中枚举出存在潜在问题的步骤, 在这些步骤中执行故障注入, 针对性地生成测试案例, 验证系统容错协议的正确性.
1.1 线性数据
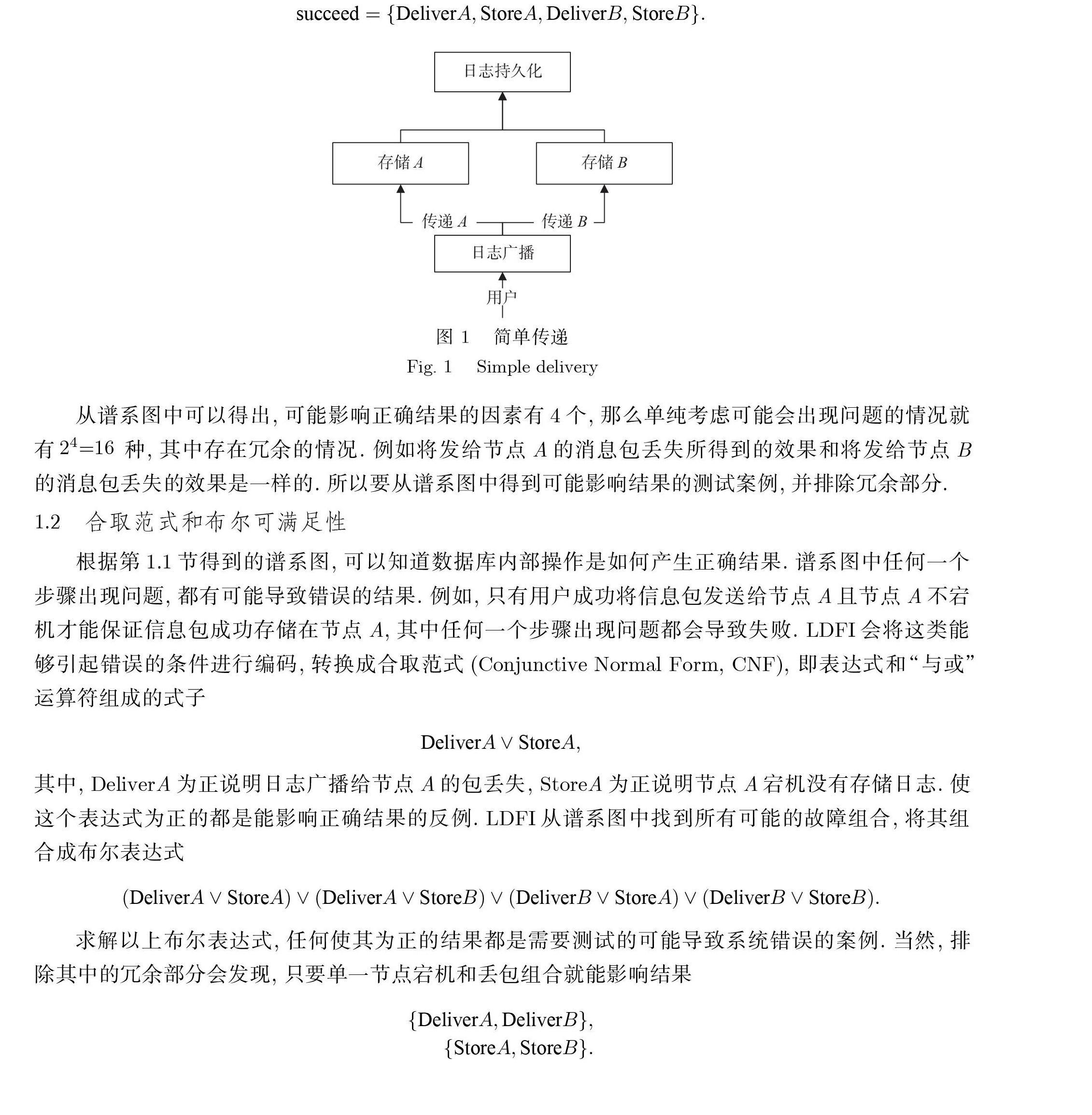
线性数据[12,17-18] 能抽象出分布式数据库节点间通信和数据持久化的过程, 并且能够更加直观地检测到系统为了确保结果正确而执行的冗余操作; 凭借线性数据, 能够知道所有对正确结果有贡献的操作和元数据. LDFI 利用线性数据的特点生成测试案例, 在分布式数据库正确运行后, 从执行结果不断回溯系统上一步的操作. 这样的递归过程最后会产生一个谱系图, 揭示所有对正确结果有贡献的操作和数据; 通过故障注入就能打断其中某一步骤, 从而得到容错协议为了确保系统正确性而执行的冗余操作. 举例说明, 图1 是一个简单的日志持久化的过程. 在分布式数据库中为了保证数据不丢失, 往往会在多台机器上备份数据. 衡量一条日志是否正确持久化的标准是, 这条日志是否在所有存活且和主机有联系的机器上被存储. 从这样一个正确的结果回溯: 这条日志被认为是持久化的原因是, 它既存储在节点A 上又存储在节点B 上; 这条日志能在节点上被存储是因为用户尝试了多次广播, 将日志发送给了节点A 和节点B. 通过这样的回溯过程, 就能得到图1 这样的流程图. 通过图1 可得出导致日志持久化的谱系图
4 结论和相关工作
本文根据线性数据的特点, 改造优化了故障注入测试工具; 尽管在细节方面为了确保Cedar 原有的架构兼容了部分操作, 如多次执行测试案例来近似的控制故障注入的时机, 但是确保了且没有改变利用线性数据的主要思想. 在以后的工作中, 要尽可能想办法去弥补这些缺点.
本文的主要目的是分享如何将一个研究性的理论原型转换成实际的应用, 而在转换的过程中又遇到了哪些兼容性的问题, 又是如何在保证原有理论的主体思想不变的同时克服这些问题, 希望这些内容和经验能對相关工作者有所帮助, 有所借鉴.
实现故障注入测试工具所需要的基础条件之一是故障注入框架. 故障注入框架, 网上有很多的开源版本, 诸如阿里巴巴最近开源了一个名为Chao Blade 的故障注入平台, 相对来说容易实现. 值得注意的是, LDFI 实现自动化生成测试方案的关键取决于获取系统内部通信过程的细粒度的线性数据.鉴于这种特性, 在以后的工作中, 应该多考虑一些分布式数据库如何跟踪数据在系统中的传递过程.例如, 通过网络作为监控, 或者利用Open Tracing 的功能来监控元数据的变化过程. 细粒度的线性数据不仅能为故障注入测试提供帮助, 也能帮助开发人员更好地理解分布式数据库内部是如何运作的,运维人员也能更好地管理分布式数据库的状态, 及时发现数据库的异常问题.
近些年, 也有很多新的测试工具, 如Jepsen, 是开源社区比较公认的一个分布式测试框架, 它模拟实现了各类常见的系统软硬件故障, 其测试案例则是基于随机式的方法进行设计, 且达到了一个比较良好的覆盖率[20]; 除此之外, 还有FlyMC[21], 它为云系统提供了新的快速且可扩展的测试方法, 通过引入新的算法使测试工具能更快速地发现系统bug, 并且在多个系统中发现了新旧bug.
对比同类工作, 本文实现的故障注入工具专注于故障的发生对结果的影响, 与随机的故障注入不同, 它能更加充分地探索系统可能存在的错误空间, 而且摒弃了无效的测试案例; 不同于启发式的故障注入, 它不需要特定系统的专业知识, 而是从系统的结果回溯到初始状态, 探究能够影响系统正确结果的因素. 当然这也有一定的局限性: 因为彻底地探索分布式数据库所有可能存在的错误是不切实际的. 所以本文更关注容错协议对于分布式数据库的影响, 这就缩小了故障发生的范围. 尤其是对于Paxos[22]、Raft[23] 这类共识算法, 本文不能确认Paxos、Raft 在发生特定的故障组合后得到的结果是错误的, 因为故障的发生有可能破坏这两者为了达到节点间一致性而设定的前置条件. 所以, 单一的故障注入方法, 都不足以完全地保证分布式数据库的正确性, 最完善的方法应该是将诸如LDFI 和SAMC 这类启发式方法结合在一起, 先通过LDFI 快速发现可能影响系统的bug, 确保系统能正常运行, 之后再同步进行长时间的启发式故障注入测试证明分布式数据库的正确性.
[ 参 考 文 献]
[ 1 ] BAILIS P, KINGSBURY K. The network is reliable [J]. Communications of the ACM, 2014, 57(9): 48-55. DOI: 10.1145/2643130.
[ 2 ]DEAN J. Designs, lessons and advice from building large distributed systems [R/OL]. The 3rd ACM SIGOPS International Workshopon Large Scale Distributed Systems and Middleware.(2009-10-10)[2019-08-07]. http://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf.
[ 3 ]ALSBERG P A, DAY J D. A principle for resilient sharing of distributed resources [C]//Proceedings of the 2nd InternationalConference on Software Engineering. IEEE, 1976: 562-570.
[ 4 ]STONEBRAKER M. Concurrency control and consistency of multiple copies of data in distributed INGRES [J]. IEEE Transactionson Software Engineering, 1979(3): 188-194. DOI: 10.1109/TSE.1979.234180.
[ 5 ] GARCIA-MOLINA H. Elections in a distributed computing system [J]. IEEE Transactions on Computers, 1982(1): 48-59.
[ 6 ]LEESATAPORNWONGSA T, LUKMAN J F, LU S, et al. TaxDC: A taxonomy of non-deterministic concurrency bugs in datacenterdistributed systems [J]. ACM SIGPLAN Notices, 2016, 51(4): 517-530. DOI: 10.1145/2954679.2872374.
[ 7 ]GAO Y, DOU W S, QIN F, et al. An empirical study on crash recovery bugs in large-scale distributed systems [C]//Proceedings ofthe 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of SoftwareEngineering. ACM, 2018: 539-550.
[ 8 ]FONSECA P, ZHANG K, WANG X, et al. An empirical study on the correctness of formally verified distributed systems[C]//Proceedings of the 12th European Conference on Computer Systems. ACM, 2017: 328-343.
[ 9 ] GANESAN A, ALAGAPPAN R, ARPACI-DUSSEAU A C, et al. Redundancy does not imply fault tolerance: Analysis of distributedstorage reactions to single errors and corruptions [J]. ACM Transactions on Storage, 2017, 13(3): Article 20. DOI: 10.1145/3125497.
[10]DAWSON S, JAHANIAN F, MITTON T. ORCHESTRA: A fault injection environment for distributed systems [C]// Proceedings ofthe 26th International Symposium on Fault Tolerant Computing. IEEE, 1996: 404-414.
[11]GUNAWI H S, DO T, JOSHI P, et al. FATE and DESTINI: A framework for cloud recovery testing [C]// Proceedings of the 8thUSENIX Conference on Networked Systems Design and Implementation. ACM, 2011: 238-252.
[12]KANAWATI G A, KANAWATI N A, ABRAHAM J A. FERRARI: A flexible software-based fault and error injection system [J].IEEE Transactions on Computers, 1995, 44(2): 248-260. DOI: 10.1109/12.364536.
[13]LEESATAPORNWONGSA T, HAO M Z, JOSHI P, et al. SAMC: Semantic-aware model checking for fast discovery of deep bugs incloud systems [C]// Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation. USENIXAssociation. 2014: 399-414.
[14] BASIRI A, BEHNAM N, DE ROOIJ R, et al. Chaos engineering [J]. IEEE Software, 2016, 33(3): 35-41. DOI: 10.1109/MS.2016.60.
[15]ALVARO P, ROSEN J, HELLERSTEIN J M. Lineage-driven fault injection [C]//Proceedings of the 2015 ACM SIGMODInternational Conference on Management of Data. ACM, 2015: 331-346.
[16]ALVARO P, MARCZAK W R, CONWAY N, et al. Dedalus: Datalog in time and space [C]//International Datalog 2.0 WorkshopDatalog 2.0 2010: Datalog Reloaded. Berlin: Springer, 2010: 262-281.
[17]BUNEMAN P, KHANNA S, TAN W C. Why and where: A characterization of data provenance [C]//International Conference onDatabase Theory. Berlin: Springer, 2001: 316-330.
[18]CUI Y, WIDOM J, WIENER J L. Tracing the lineage of view data in awarehousing environment [J]. ACM Transactions on DatabaseSystems (TODS), 2000, 25(2): 179-227. DOI: 10.1145/357775.357777.
[19]ALVARO P, CONWAY N, HELLERSTEIN J M, et al. Consistency analysis in bloom: A CALM and collected approach [C]// 5thBiennial Conference on Innovative Data Systems Research (CIDR 11). 2011: 249-260.
[20]LUKMAN J F, KE H, STUARDO C A, et al. FlyMC: Highly scalable testing of complex interleavings in distributed systems[C]//Proceedings of the 14th EuroSys Conference 2019. ACM, 2019: Article number 20.
[21]MAJUMDAR R, NIKSIC F. Why is random testing effective for partition tolerance bugs? [J]. Proceedings of the ACM onProgramming Languages, 2018, 2(POPL): Article number 46. DOI: 10.1145/3158134.
[22]LAMPORT L. The part-time parliament [J]. ACM Transactions on Computer Systems (TOCS), 1998, 16(2): 133-169. DOI: 10.1145/279227.279229.
[23]ONGARO D, OUSTERHOUT J. In search of an understandable consensus algorithm [C]// Proceedings of the 2014 USENIX
Conference on USENIX Annual Technical Conference. USENIX Association, 2014: 305-320.
(責任编辑: 李 艺)
