基于集合光滑的深度学习自动历史拟合方法
2020-07-29马小鹏陈昕晟曹庆平姚传进谷建伟
马小鹏, 张 凯, 陈昕晟, 曹庆平, 姚传进, 谷建伟
(1.中国石油大学(华东)石油工程学院,山东青岛 266580; 2.中国石油大港油田分公司石油工程技术研究院,天津 300450)
油气储层精细建模对于指导油气资源高效开发具有重要意义,中国油气资源以陆相沉积环境为主,陆相含油气盆地占陆上油资源总量的90%[1],另外超过80%油气藏采用注水开发,复杂的地质条件和开发动态导致油气藏精细描述十分困难。自动历史拟合技术[2]依据油气田开发生产动态对测井、岩心等静态数据建立的随机油藏模型进行动态反演调整是目前油藏精细建模的唯一有效手段。尽管发展了许多高效的自动历史拟合求解方法[3-14],但根据动态数据反演调整储层模型仍然是一项艰巨的任务,尤其是针对大规模复杂油藏建立高效的自动历史拟合方法依旧存在许多挑战[15]。大规模油藏数百万网格带来的维数灾难、复杂地质特征(如河流相分布)难以参数化表征等迫切需要行之有效的解决方法。近年来,机器学习的兴起为石油工程领域的发展带来新的契机,在地质建模[16]、测井分析[17]、产量预测[18]等多个领域取得成功应用。借助于机器学习理论方法,结合随机奇异值分解(SVD)[19-21]的深度变分自编码(DVAE)模型[22-26],笔者提出SVD-DVAE模型,将高维地质特征(如渗透率映射到低维连续高斯空间)进行重参数化表征,结合集合光滑多次数据同化(ES-MDA)方法[27-28]吸收生产历史,实现复杂大规模油藏反演建模[29-31]高效求解。
1 方 法
1.1 油藏自动历史拟合数学模型
油藏模型参数m和油藏开发生产动态响应dobs可以看作是油藏系统的输入与输出,表示为
dobs=g(m)+ε.
(1)
式中,g(·)为油藏系统的数值模型或油藏数值模拟器;ε为生产动态响应的观测误差。
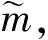

(2)
油藏生产开发是由状态方程、流动方程等偏微分方程组成的复杂非线性系统,难以直接建立油藏模型参数估计f,通常使用贝叶斯概率推理方法建立油藏模型参数估计数学模型。贝叶斯概率推理方法在水文地质、石油工程、天气预报等领域获得广泛使用,表示为
(3)
式中,P(m)为先验概率,表示模型参数的已知信息,如通过地震、测井等方式获得的静态数据;P(dobs|m)称为似然函数,用于量化观测数据与估计模型参数进行数值模拟预测之间的拟合误差;P(m|dobs)即后验概率,表示在已知观测数据dobs的情形下模型参数m的概率分布。后验概率越大表明估计模型参数接近真实模型参数的可能性越大。
基于贝叶斯概率统计,可以获得油藏模型参数的后验概率估计:

(4)
根据地震、测井、岩心取样等手段取得油藏的静态观测数据,使用随机地质统计建模方法可以建立大量的随机初始油藏模型mi(i=1,2,…,Ne),结合高斯概率模型可建立油藏模型参数的先验概率,表示为

(5)
为便于计算,假设观测误差ε服从高斯分布,即ε~N(0,CD)。根据式(1)可以推得似然函数为

(6)
结合式(3)、(5)、(6)可得到油藏模型参数的后验概率为

(7)
由于式(7)涉及数值模拟g(m),难以获得解析表达式,因此通常使用优化算法、集合卡尔曼滤波、蒙特卡洛模拟等方法进行数值求解。ES-MDA方法是Emerick和Reynolds 等提出的一种基于集合的数据同化历史拟合求解方法。相比于传统的集合卡尔曼滤波方法,ES-MDA方法具有收敛快速、不需要数值模拟多次重启动、模型不易崩溃等优点。ES-MDA方法通过使用观测数据的误差协方差矩阵Cd乘以一个膨胀因子α多次迭代进行数据同化,有效地避免了观测数据过拟合,从而解决集合卡尔曼滤波方法模型崩溃的缺陷。ES-MDA方法中油藏模型参数的估计表示为

(8)
膨胀因子αt是ES-MDA方法中唯一需要确定的辅助参数,对求解结果具有显著影响,Emerick等提出了自适应膨胀因子的ES-MDA方法。本文中使用标准ES-MDA方法中膨胀因子的设置,即αt=1/N,N为膨胀因子,通常取4~10。
1.2 深度自编码变分模型
复杂大规模油藏的地质特征(如渗透率、孔隙度等)通常需要数十万乃至上百万维的网格变量进行地质建模,而且非连续的地质属性参数化表征(如河流相等复杂相分布参数)是自动历史拟合领域的关键难题,研究使用深度学习模型对复杂大规模油藏地质特征进行参数化表征。深度生成模型是近年来深度学习领域的研究热点之一,在机器视觉、图像生成、自动驾驶汽车等领域得到广泛关注。变分自编码模型以及对抗性神经网络模型是深度生成模型领域最重要的两种模型,其中变分自编码模型假设数据是由随机过程产生的,并涉及一个未观察到的或不可观察到的连续随机变量z,称为潜变量,这个随机过程由两步组成:①根据先验分布p(z)生成潜变量z;②给定z,根据条件分布p(x|z;θ)生成相应的数据x。
根据贝叶斯理论,x的边际似然为

(9)
根据式(9)的解析表达即可直接生成数据x。但是,P(x|z)通常涉及复杂的非线性方程,导致不可解析求解。对于这种不可解析求解的概率分布问题最常用的方法有蒙特卡洛采样和变分推理。蒙特卡洛采样方法计算十分昂贵,变分自编码模型从变分方法进行推导,得到边际似然P(x)的变分下界:
logP(x)≥L(θ,φ;x)=Εqφ(z|x)[-logqφ(z|x)+
logPθ(x|z)].
(10)
最大化式(10)即可获得边际似然P(x)的最大似然估计,变分自编码模型采用随机梯度技术以及自编码神经网络结构进行优化求解,对式(10)进行随机梯度变分贝叶斯估计:
(11)
式(11)右侧KL散度作为正则项,第二项是负重构误差的期望。图1为变分自编码模型的结构示意图。编码器(encoder)作为qφ(z|x),解码器(decoder)作为Pθ(x|z),通过对数据集进行训练即可获得合适的模型参数θ和φ。

图1 变分自编码模型结构示意图
使用初始油藏模型集合进行训练,潜变量z是油藏模型的低维表征,输入解码层可实现从低维表征重构相应的油藏模型。VAE模型需要确定的超参数包括隐藏层的层数、神经元个数以及最关键的潜变量z的维数。
1.3 奇异值分解本征维数估计方法
奇异值分解方法(singular value decomposition,SVD)是一种无监督学习方法,在数据降维、消除冗余、特征提取和噪音消除等领域都有广泛应用。另外,SVD方法还可用于高维数据的本征维数估计,如确定线性模型中的变量数或确定动力系统的自由度等。提出使用SVD方法对渗透率、孔隙度等高维模型参数进行本征维数估计,作为变分编码模型潜变量层的维数。
SVD方法原理见图2。任给M×N的矩阵A,可以分解为UM×M、ΣM×N和VN×N三个矩阵:

图2 奇异值分解原理示意图
A=U∑VT.
(12)
矩阵Σ是一个对角矩阵,对角线元素的值σi称为奇异值,且奇异值具有沿着对角线逐渐减小的性质。通过保留r≪min(M,N)个奇异值可实现分解矩阵的压缩,并用压缩后的分解矩阵乘积近似原始矩阵A:

(13)
计算奇异值所能保留矩阵A的信息贡献率,确定矩阵的本征维数为

(14)
该方法适用于小样本情形,对于大量样本情形,由于样本数量增加导致次要奇异值部分被高估,无法真实反映奇异值的信息保留贡献率。因此提出奇异值差分谱方法,确定矩阵本征维数,奇异值差分谱定义为
λi=|σi+1-σi|,i=1,…,k-1.
(15)

(16)
通过式(15)差分操作,可以有效消除次要奇异值干扰。通过式(16)计算相应的信息保留贡献率,可确定本征维数。
1.4 结合ES-MDA和VAE-SVD方法的综合自动历史拟合流程
整合奇异值分解方法、变分编码模型以及ES-MDA数据同化方法形成综合的自动历史拟合求解方法,如图3所示。首先根据初始油藏模型计算地质特征的本征维数,并训练变分编码模型。其次使用变分编码模型的解码器对油藏模型进行降维参数化表征,ES-MDA迭代同化油田历史观测数据,更新降维潜变量;使用变分编码模型的解码器重构油藏模型并进行数值模拟计算,用于下一次潜变量迭代更新,多次迭代求解,直至满足收敛条件,如达到提前设定的迭代次数,输出最终拟合模型。

图3 基于深度学习与数据同化方法的综合自动历史拟合流程
2 算 例
对一个二维河流相油藏进行自动历史拟合研究,拟合参数为渗透率。该油藏真实渗透率分布如图4(a)所示,低渗透背景相的渗透率为500×10-3μm2,高渗透河流相为5 000×10-3μm2。图4(b)为初始模型集合中随机抽取的28个模型,初始模型可根据训练图像采用多点地质统计随机建模方法生成。不同于常规油藏,河流相油藏地质相之间存在明显的不连续边界,因此渗透率的反演更具挑战性。该油藏模型有45×45网格,每个网格30.5 m×30.5 m,厚度是8 m;含有3口注水井、4口生产井,采用Eclipse软件作为油藏数值模拟器。为增加历史拟合预测模型的挑战性,仅使用300 d共10个时间步的生产数据进行自动历史拟合测试,以4口生产井的日产水量和日产油量数值模拟结果添加5%的高斯噪音作为观测数据。
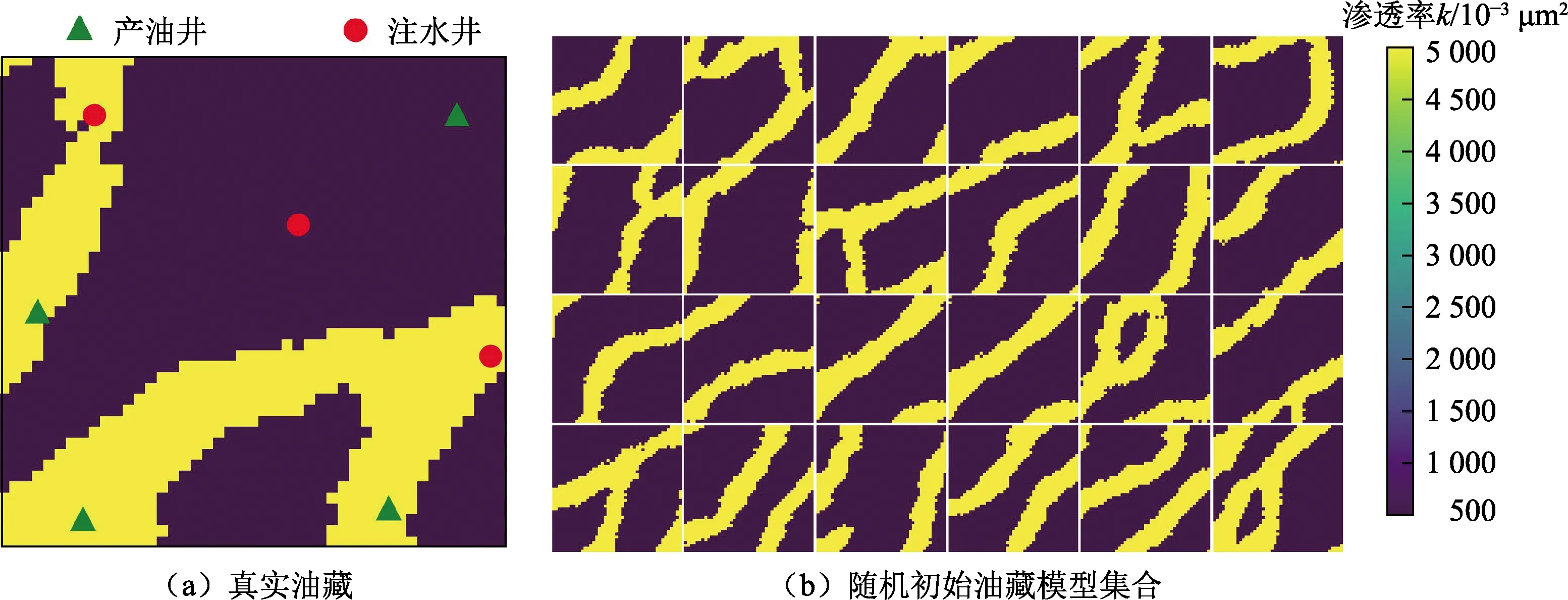
图4 河流相油藏算例
2.1 SVD方法估计本征维数
利用SVD方法对2 000个随机初始油藏模型进行处理,计算初始油藏样本的奇异值,如图5(a)所示,少量的奇异值明显突出。根据式(14)和式(16)计算奇异值贡献率如图5(b)和(c),可以看出,式(14)对样本数量敏感,无法准确估计奇异值对信息保留的贡献率;式(16)中通过差分计算能够显著剔除次要奇异值的干扰,可以更加准确地估计本征维数。

图5 随机初始油藏模型集合SVD计算奇异值及信息保留贡献率
根据式(16)计算奇异值贡献率D,并选取贡献率为0.8、0.9及0.95时对应的奇异值个数,对应的油藏模型渗透率场的本征维数估计分别为13、33和65。使用估计的本征维数作为变分编码模型的潜变量层神经元数,建立深度变分编码模型,模型结构见表1。使用2 000个先验随机油藏模型中1 800个模型作为训练样本,另外200个模型作为验证样本对模型进行训练。

表1 变分自编码模型结构
随机选取初始油藏模型中的一个渗透率场,对变分编码模型重构结果进行分析,见图6(a)。图6(b)~(d)为不同本征维数时变分自编码模型对图6(a)所示渗透率场的重构结果。可看出高渗相的分布趋势均能够得到较好的重构。主要差异在于相边界,本征维数r为13时相边界模糊,而r为65时相边界重构的更好。网格渗透率的分布频率直方图能更加直观地说明重构差异,如图6(e)所示,初始模型的渗透率显著地集中在高渗相和低渗相。而重构模型都存在中间过渡,图6(f)中r=13时,存在较多的网格渗透率分布在高渗和低渗值之间,r=65时对应的网格渗透率分布在高、低渗两端更加集中。

图6 不同潜变量维数对应的变分自编码模型重构渗透率场与参考样本对比
图7对VAE模型随机生成渗透率场的能力进行了对比。r取13和65时都能够很好地重构具有河流相特征的渗透率模型,但r取65时河流相边界更加清晰。

图7 不同潜变量维数变分自编码模型生成渗透率场效果对比
2.2 历史拟合测试
对提出的ES-MDA结合VAE-SVD方法同化生产观测数据进行的自动历史拟合进行了测试,并与ES-MDA结合SVD的传统降维方法进行了对比。图8(a)展示了保留前65个奇异值的SVD方法结合ES-MDA方法进行历史拟合的预测模型,可看出,SVD方法能够粗略地捕捉河流相的分布,但是无法预测河流相的准确分布。如图8(b)和(c)所示,ES-MDA结合VAE-SVD方法均能够很好地预测高渗相的大致分布及形状。另外对比取不同的本征维数拟合效果,可以看出,r取65时高渗相的相边界预测更加清晰,对高渗相的分布能够做出准确预测。

图8 自动历史拟合渗透率场反演结果对比
图9对4口生产井的日产油量历史拟合结果进行了说明,其中绿色菱形点表示观测数据点,灰色曲线是初始油藏模型集合的数值模拟预测结果,红色曲线是历史拟合更新模型集合的数值模拟预测结果。与初始随机油藏模型集合相比,ES-MDA结合VAE-SVD自动历史拟合方法预测的油藏模型集合能够很好地反映真实观测数据的变化。

图9 ES-MDA结合VAE-SVD方法生产观测数据拟合结果
3 结 论
(1)使用奇异值分解方法对高维油藏模型参数进行本征维数估计可以指导深度变分自编码模型潜变量维数的设定。直接基于奇异值计算贡献率方法在大样本数量情形下估计的本征维数偏高,而奇异值差分谱可以消除样本数量带来的偏差,计算的贡献率与奇异值分布规律保持一致,有助于深度学习等大样本情景下准确估计本征维数。
(2)参数场保留信息贡献率与相应的估计本征维数成正比,保留信息越多深度变分自编码模型重构效果越好,但是相应地潜变量维数也越高;考虑到数据同化算法对于参数维数敏感性较低,因此保持尽可能高的信息贡献率有助于精确地反演油藏模型参数。
(3)基于神经网络结构的深度变分自编码器能够将高维网格变量压缩至低维连续变量,为大规模油藏历史拟合求解提供了思路。与基于传统的奇异值分解等矩阵分解自动历史拟合方法相比,综合数据同化算法与深度学习模型构建的自动历史拟合综合流程能够更好地保持油藏地质特征。
