Generative Adversarial Network Based Heuristics for Sampling-Based Path Planning
2022-10-26TianyiZhangJiankunWangandMaxMeng
Tianyi Zhang, Jiankun Wang, and Max Q.-H. Meng,
Abstract—Sampling-based path planning is a popular methodology for robot path planning. With a uniform sampling strategy to explore the state space, a feasible path can be found without the complex geometric modeling of the configuration space. However, the quality of the initial solution is not guaranteed, and the convergence speed to the optimal solution is slow. In this paper, we present a novel image-based path planning algorithm to overcome these limitations. Specifically, a generative adversarial network (GAN) is designed to take the environment map (denoted as RGB image) as the input without other preprocessing works. The output is also an RGB image where the promising region (where a feasible path probably exists) is segmented. This promising region is utilized as a heuristic to achieve non-uniform sampling for the path planner. We conduct a number of simulation experiments to validate the effectiveness of the proposed method, and the results demonstrate that our method performs much better in terms of the quality of the initial solution and the convergence speed to the optimal solution.Furthermore, apart from the environments similar to the training set, our method also works well on the environments which are very different from the training set.
1. INTRODUCTION
ROBOT path planning is to determine a collision-free path from a start state to a goal state while optimizing a performance criterion such as distance, time, or energy [1].Many classic approaches have been proposed to solve the path planning problem in the past decades, such as potential field method [2], cell decomposition method [3], grid-based methods including A* [4] and D* [5] algorithms. However,there are some problems existing in these approaches, such as computational difficulty and local optimality.
In recent years, sampling-based algorithms have been shown to work well in practical applications and satisfy theoretical guarantees such as probabilistic completeness.Sampling-based algorithms can avoid discretization and explicit representation of the configuration space, resulting in good scalability to high-dimensional space. Probabilistic roadmap (PRM) [6] and rapidly-exploring random tree (RRT)[7] are two representative methods of sampling-based algorithms to solve path planning problems. RRT algorithms have gained popularity for their efficient single-query mechanism and easy extension to many applications such as kinodynamic path planning [8] and socially compliant path planning [9]. However, there are also some limitations of the RRT algorithms which still remain to be solved. For example,the solutions are usually far from optimal. Although RRT*[10] is capable of achieving asymptotic optimality by introducing near neighbor search and tree rewiring operations,it takes much time to converge to the optimal solution. The reason is that the RRT employs a random sampling mechanism. On one hand, it guarantees that one feasible solution can be found if it exists as the number of iterations goes to infinity. On the other hand, this mechanism affects the convergence speed because it uniformly searches the whole state space.
To overcome the aforementioned problems, we present a novel learning-based algorithm to leverage previous planning knowledge to generate a promising region where a feasible or optimal path probably exists. This promising region serves to generate a non-uniform sampling distribution to heuristically guide the sampling-based path planners to explore the state space more efficiently. As shown in Fig. 1, compared with RRT*, our proposed generative adversarial network (GAN)based heuristic RRT* can quickly find a high-quality initial path with fewer nodes.
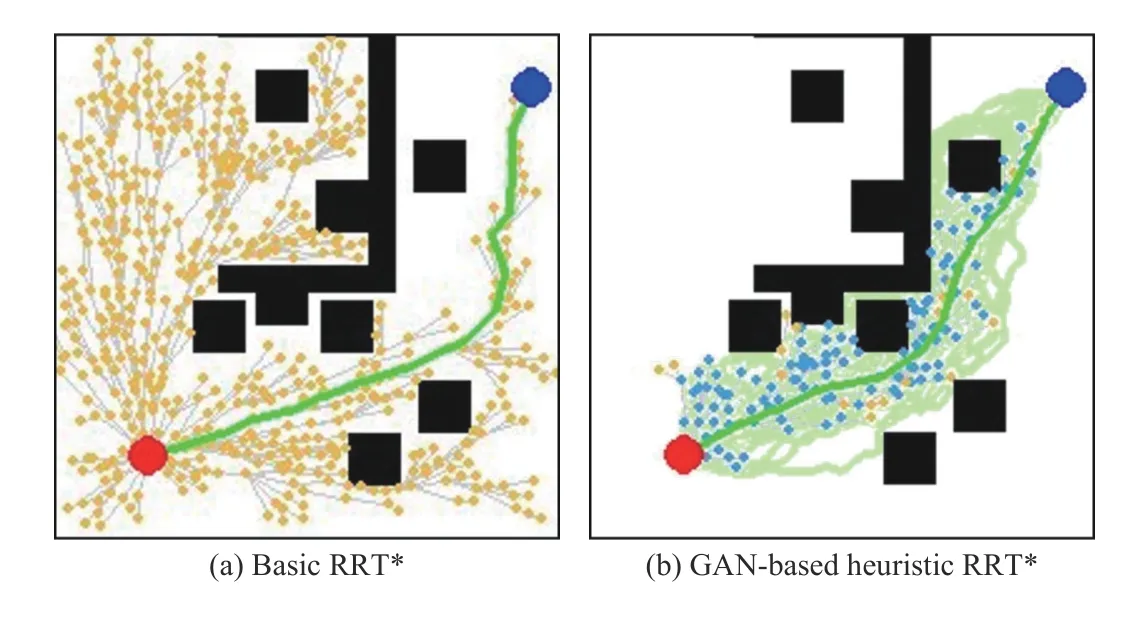
Fig. 1. A comparison of basic RRT* and GAN-based heuristic RRT* on finding the initial solution. The green area denotes the promising region generated by GAN. The yellow nodes are uniformly sampled from the whole state space and the blue nodes are sampled from the promising region.
Our main contributions include:
1) Propose a heuristic method for sampling-based path planning algorithm using GAN;
2) Design a GAN model to predict the promising region for non-uniform sampling;
3) Apply the GAN-based heuristic method to case studies to demonstrate the effectiveness of the proposed method.
The rest of this paper is organized as follows. We first review the previous work of the path planning and generative models in Section II. Then, the preliminaries of path planning problem are presented in Section III. Section IV describes the data generation method and the proposed GAN model for promising region prediction. In Section V, we conduct a series of simulation experiments to demonstrate the performance of the GAN-based heuristic path planning algorithm. At last, we draw conclusions and discuss the future work in Section VI.
II. RELATED WORK
Recently, many researchers have proposed different types of heuristic methods to improve the performance of basic RRT algorithms.
As the grid-based algorithms can guarantee to find aresolution optimalpath, one possible way is to combine the grid-based algorithms with sampling-based ones. In [11], the grid search process is employed to get an initial solution to guide the sampling process. Another way is to design some specific cost functions to change tree extension rules. Wang and Meng[12] utilize the generalized Voronoi graph (GVG)as the heuristic quality function to quickly extend the tree. Liuet al.[13] establish a set of partition heuristic rules for target and collision-free guidance. While these proposed cost functions accelerate the searching process, they tend to bias the searching towards a certain target, resulting in a local optimum easily or being stuck within complex obstacles.Moreover, the aforementioned methods are task-oriented and only demonstrate fine results on limited conditions, such as low-dimensional spaces or simple cost states. Their generality and performance cannot be guaranteed in complex environments. Controlling the sampling distribution is also a useful way to accelerate path planning. For example, Gammellet al.[14] shrink the sampling space into an elliptic region after a feasible path is obtained. However, its overall performance depends on the quality of the initial path.
In recent years, learning-based algorithms show great advantages on path planning problems. Especially, they exhibit remarkable generalization to completely unseen environments and can easily be applied to different sizes of maps. Baldwin and Newman [15] propose to learn sampling distributions by using expert data and learn an estimate of sample densities around semantic regions of interest, then incorporate them into a sampling-based planner to produce natural plans. Wanget al.[16] use a reinforcement learning algorithm to improve the multi-RRT approach in narrow space. Even though the strategy enhances the local space exploration ability, the expansion of the searching trees is time-consuming. Ichteret al.[17] propose a general methodology for non-uniform sampling based on conditional variational autoencoder (CVAE). The weakness of this method is that sampling and planning are separated, so the planner cannot adapt to the environment during the planning cycle. Additionally, the construction of the sampling distributions requires lots of preprocessed conditional information, which demands huge effort on preliminary works. Moreover, the method is a multi-process generative model, which is time-consuming to predict the whole sampling distribution. Qureshi and Yip [18] present a neural network based adaptive sampler on generating samples for optimal paths. It contains an autoencoder to encode the environment from point cloud data and a dropout-based stochastic deep feed-forward neural network to mix the surrounding information and produce samples. However, their approach only focuses on path generation and requires some low-controllers to continuously track the generated paths,which may cause difficulty for robots to act in highdimensional space. Wanget al.[19] propose a convolutional neural network (CNN) based optimal path planning algorithm to generate a promising region used to guide RRT* sampling process. The CNN model is trained on a prior knowledge and can adapt to different clearances and step sizes. However,there are many disconnected parts in the generated regions.Mohammadiet al.[20] propose a GAN-based path planning algorithm for path planning. However, the model lacks universality as it is only trained and tested on very simple and small grided spaces. Choiet al.[21] employ GAN to predict multiple plausible paths to guide the driving intention.However, the method is used for intention generation, which can only predict simple and short-distance trajectories.
To step further in the learning-based algorithms for controlling the sampling distributions, we can first extract the promising regions of the bias sampling points. The process of obtaining promising regions can be regarded as a special problem of image semantic segmentation or domain transformation. A significant advantage of this image-based generation model is that it does not require any complicated preprocessing. In the past few years, different semantic segmentation networks are proposed, such as SegNet [22], UNet [23], Mask R-CNN [24], and so on. In general,segmentation nets are confined to certain tasks and require labels in the input pictures. Therefore, the CNN segmentation networks may perform poorly on generating promising regions. Wanget al.[19] apply a segmentation network into path planning problem. However, the success rate and connectivity of the promising region are unsatisfactory.
CVAE [25] is a popular generative model. By reparameterization technique, the target images and conditions are encoded and transformed into normal distributions. Given the specified condition and random latent variables, the decoder is capable of generating various expected images.However, the images generated from CVAE models are often blurred. More importantly, it is difficult to restore promising regions from normal distributions. Since the advent of GANs[26], it has been acknowledged as the most powerful generative model and widely used in various areas, such as image generation [27]–[29], image-to-image translations[30]–[32], and so on. Due to the flexibility of GANs, different architectures are proposed in recent years to tackle diverse problems. It is also suitable for generating promising regions of non-uniform sampling. Therefore, we design a novel GAN structure to learn promising regions for achieving heuristic non-uniform sampling to improve the performance of RRT*.Compared with the previous methods, our image-based model avoids complicated preprocessing works of the state space and shows good adaptability to various environments.
III. PRELIMINARIES
In this section, we first briefly introduce the path planning problem and then formulate our proposed GAN-based heuristic RRT* algorithm.
A. Path Planning Problem
The basic path planning problem can be defined as follows.Let X ∈Rnbe the state space, withn∈Nn,n≥2. The obstacle space and the free space are denoted as Xobsand Xfree=X/Xobs, respectively. Letxinitbe the start state andxgoalbe the goal state wherexinit∈Xfree,xgoal∈Xfree. Let Xgoalbe the goal region wherer}. The path planning algorithms aim to find a feasible path σ:[0,1]→Xfree, σ (0)=xinitand σ (1)∈Xgoal.
Let Σ be the set of feasible paths andc(σ) be the cost function. The optimal path planning problem is to find a path σ∗with the lowest cost in Σ

In this paper, the cost function between two statesxiandxjis defined as

B. Heuristic RRT*
Sampling-based algorithms solve path planning problems by constructing space-filling treesT(V,E) to search a pathσconnecting start and goal states. The tree is built incrementally with samples drawn randomly from the free space Xfree.
To reduce unnecessary sampling, we construct a heuristic non-uniform sampling distribution XH⊂Xfreeto improve the sampling process. A heuristic non-uniform sampling distribution refers to the state space where feasible paths exist with high probability. In order to obtain this non-uniform sampling distribution XH, we first generate a promising region S with GAN model and then discretize it. The outline of our heuristic methodology is shown in Algorithm 1. The process PRGenerator() generates the promising region S, and the Discretization() extracts sampling distribution XHfrom S.The sampling distribution XHis then fed into the heuristic sampling-based planning algorithm HeuristicSBP*().

Algorithm 1 Outline of GAN-based heuristic RRT*Input: , , T(V,E)xinit xgoalX Output: V=xinit,E=∅;1 2 S ←PRGenerator(xinit,xgoal,X);3 XH ←Discretization(S);T(V,E)←HeuristicSBP∗(xinit,xgoal,X,XH);4 5 Return T(V,E);
In this paper, we formulate our model in complex 2-D environments and use 2-D environment mapMapto represent the state space X. As for the sampling-based algorithm, we employ the most general optimal path planning method RRT*[10] as a representative. Algorithm 2 illustrates the detailed implementation of our heuristic RRT* algorithm(HeuristicSBP*() in Algorithm 1). To compare it with basic RRT* algorithm, we useUseHeuristicto show the difference:Lines 3–7 are adopted by heuristic RRT*, and Lines 8 to 9 are in basic RRT*. We modify the uniform sampling strategy into a biased sampling strategy to select a random samplexrand:Suppose thatNsamples are drawn in the sampling-based planning, and a parameterμis used to balance the uniform and non-uniform sampling strategies. In heuristic RRT*, µNsamples are randomly chosen from the non-uniform sampling distribution, while (1−µ)Nare sampled from the uniform sampling distribution (the whole state space). Oncexrandis determined, the following process is the same as basic RRT*:We first use Nearest() to find the nearest statexneareston the current treeT(V,E) toxrand, and then use Steer() to advance one step in the direction of the line connectingxnearestandxrandto find the new statexnew. If the connection betweenxnearestandxnewis collision-free,xnewwill be added to the treeT(V,E) and the rewire process Rewire() will be conducted to optimize the path. The process will be repeated until anxnewis located in Xgoaland the path cost converges to the optimal cost.
To sum up, the focus of our work lies in establishing an efficient generator to predict promising region S given the conditions start statexinit, goal statexgoal, and environment mapMap(shown in Algorithm 1, Line 2).
C. Probabilistic Completeness
Probabilistic completeness is essential for the samplingbased algorithm, which indicates whether the algorithm can find a feasible path if it exists.
The proposed heuristic RRT* employs both uniform and non-uniform sampling. As defined in Section III-B, there will be µNsamples drawn from the non-uniform sampling distribution and (1−µ)Nsamples drawn from the uniform sampling distribution. As the number of iterationsNgoes to infinity, the following equation will hold:

which means that the whole state space will be explored. In other words, if there is a feasible solution, it must be found as the number of iterationsNgoes to infinity. Therefore, the probabilistic completeness is guaranteed.

Algorithm 2 RRT* and Heuristic RRT*Input: , , , Map, and UseHeuristic T(V,E)xinitXgoalXH Output: V=xinit,E=∅;1 2 for do UseHeuristic=True i=1,...,N 3 if then<µ4 if Rand() then xrand ←Non-uniformSample(XH);5 6 else xrand ←UniformSample(Map);7 8 else xrand ←UniformSample(Map);9 10 xnearest ←Nearest(T(V,E),xrand);11 xnew ←Steer(xnearest,xrand);12 if ObstacleFree( ) then Extend(T(V,E),xnew);xnearest,xnew 13 14 Rewire();15 if then Return T(V,E);xnew ∈Xgoal 16 17 Return failure;
IV. GAN-BASED PROMISING REGION GENERATION
In this section, we introduce the proposed GAN model in detail. Trained with a large amount of empirical promising region data, the GAN model is able to generate promising regions for non-uniform sampling given the conditions start statexinit, goal statexgoal, and environment mapMap.Therefore, the inputs of the model are RGB images representing the environment mapMap, start statexinit, and goal statexgoal. The output of the model is also an RGB image where the promising region is highlighted.
A. Dataset Generation
Fig. 2 illustrates the dataset. The environment maps(2 01×201 pixels) are randomly generated. In the environment maps, the obstacles are denoted as black, and the free spaces are denoted as white. On each map, 20 to 50 start and goal states are randomly chosen from the free space and denoted as red and blue, respectively. To obtain the ground truth promising region for training, we use the set of feasible paths to represent the promising region, as shown in Fig. 2. Specifically,We run 50 times RRT algorithm on each condition and draw all the feasible paths with green lines on one image.

Fig. 2. An illustration of the dataset. Each row from top to bottom represents environment maps, start and goal states, and promising regions,respectively.
B. Model Structure
1) Theory of GAN
We first briefly introduce the theory of GAN, and then discuss the connection between our model and the theory. The basic framework of GAN includes a generatorGand a discriminatorD. The generator accepts a sample noisezfrom the noise space Z ∈Rnand outputs an imageG(z). The discriminator is fed with imagesufrom the training data space U and generates imagesG(z). The generator and discriminator are in an adversarial game: to be specific, the generator aims at fooling the discriminator while the discriminator tries to distinguish the real and fake images. The objective function can be defined as
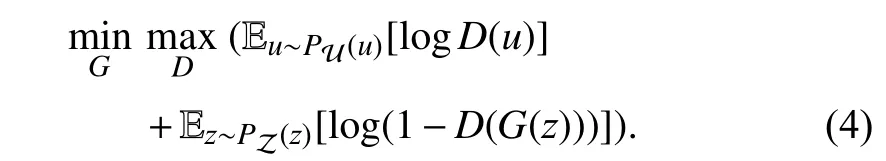
To control the generative process, the generator and discriminator can be conditioned on a giveny∈Y , where Y is the conditioned space. With the conditional variable input, the generated images can be represented asG(z,y). In this way,the objective function is modified into

During the training process, we first label U as real andG(z,y) as fake. Then the discriminator and generator are trained alternatively, which leads to the mutual growth of discernibility and generative capability.
In our model, we refer to the ground truth promising region imagess∈S as data space U. Environment map imagesm∈M and point images (start and goal states)p∈P are two conditions in space Ymapand Ypoint, respectively, and Z is 2-D noise data. The task is to parameterizeGto fit the distribution ofG(z,m,p) to S. To enhance the network’s ability to locate start and goal states, we use two discriminatorsDmapandDpointto judge whether the promising regions match the environment map and point conditions,respectively. Fig. 3 shows the overall architecture of our model.
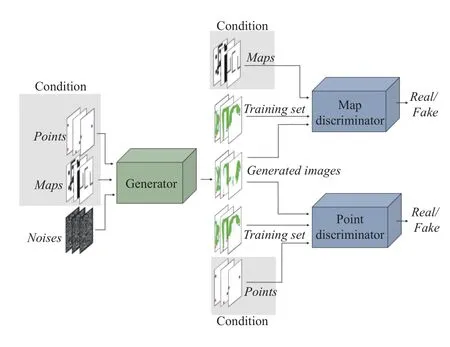
Fig. 3. The overall structure of GAN model for promising region generation.
2) Loss Function
Equations (4) and (5) show the object function of GAN.Herein, we introduce their implementations in the loss functions.
During the training process, we first fix the parameters in the generator and train the discriminators for 2 iterations. The loss functions of discriminators can be defined as
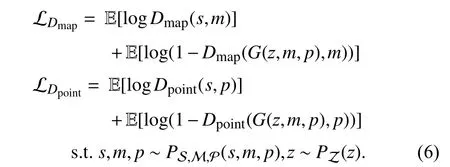
Then we train the generator with the following loss function:

As the start and goal states occupy small pixels in the images, the generator may ignore the semantic information of them. To enhance the generator’s attention to start and goal states, we design dynamic cross coefficients α1and α2to give a larger weight to the loss ofDpoint. The specific calculation formula is represented in (8).kis a hyperparameter. In our model, we setkto 3.
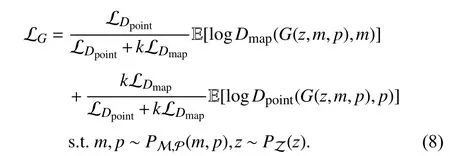
3) Detailed Model Structure
Fig. 3 shows the overall architecture of the GAN model for promising region generation and Fig. 4 illustrates the detailed structure of the generator and discriminators.
In the generator, the inputs are 6 4×64×1 dimensional noise image Z, 6 4×64×3 dimensional environment map image M and 64×64×3 dimensional point image P. The output is the 64×64×3 dimensional promising region image S. M and P are separately fed into a 16-channel convolutional layer, and Z is fed into a 32-channel convolutional layer, respectively.Then the feature maps are concatenated together along channel dimension and processed by the subsequent networks to encode the images into multi-channel features.
In our model, the generator obeys the encoder-decoder architecture. The encoding network containsblock1 toblock4,and each block is composed of a Convolution-BatchNormalization-ReLU layer and two Resnet cells [33].Herein, we store the feature maps derived fromblock1 and denote it asI1. The decoding network includesblock5 toblock7. Each decoder block is similar to the encoder ones,only replacing the convolutional layers with deconvolutional layers. Likewise, we denote the output feature maps of the decoding network asI2.Block8 is designed to improve the image quality by enhancing raw context information. The feature mapsI1andI2are concatenated along the channel and fed intoblock8. At the end of the network, the feature maps are compressed into a 3-channel image and activated by Tanh function.
The two discriminators have similar structures except for the number of the layers. The discriminators are mainly constructed by Convolution-BatchNormalization-LeakyReLU blocks. Inspired by the self-attention mechanism [34], [35],we add self-attention blocks at the first layer and the third layer of the discriminators to help them consider global information.
As shown in Fig. 4, self-attention blocks are added to the convolutional network through residual connection

where q refers to the output of self-attention mechanism, ocdenotes the output of the last layer, and oais the final output.γis a learned parameter to adjust the ratio of self-attention. The self-attention mechanism can be defined as

whereg(oc) is a linear embedding used to compress dimensions. θ(oc) and ϕ(oc) are used to calculate autocorrelation. Throughsoftmaxoperation, the weight coefficients are derived and added tog(oc). In this way, all positions are considered in the operation.
In the discriminators, the condition input layer is fed with 64×64×3 dimensional environment maps M or point images P, and the data input layer receives ground truth promising region images S and generated promising region imagesG(z,m,p). When the data is obtained from the training set S,we label the output of discriminators as 1 to mark it as real.When the data is from the generatorG(z,m,p), we label the output as 0 to mark it as fake.
V. EXPERIMENTS
A. Training Details
Our dataset contains a total of 61 768 sets of data. We randomly choose 49 416 among them for training and 3088 for test. As shown in Fig. 2, we mainly use five types of environment maps, each of which contains 100 to 300 different images. On each environment map, we randomly choose 20 to 50 different start and goal states. The training process is conducted for 50 epochs on NVIDIA TESLA T4 with PyTorch. We use Adam optimizer with parameters β1=0.5, β2=0.99 for training, and the learning rates of the discriminators and generator are 0.00001 and 0.0001,respectively.
根据上述讨论,SPP在图5所示的螺旋波导中传播一周,场分布在波前所在横截面中整体旋转B=-2π(1-cosφ)角度.显然,如果SPP传播N周,场分布会旋转NB=-2πN(1-cosφ)角度,这个旋转角度还不是相位,接下来我们从场分布的旋转和SPP本征模表达式出发推导出几何相位.上述波导中的n阶SPP场量都具有如下形式:

Fig. 4. The detailed structure of GAN model for promising region generation.
B. Evaluation Methods
We evaluate our model from two aspects. As an image generation problem, we evaluate the connectivity of the generated promising regions and generalization ability of the model. As a path planning problem, we apply the promising region to Algorithm 2 to compare several standard metrics between basic RRT* and our GAN-based heuristic RRT*.
1) Connectivity
Compared with the high similarity between the generated images and the ground truth images, the contribution of the generated regions to the planning tasks is more worthy of our attention. Therefore, we use connectivity to evaluate the quality of the image rather than other image similarity evaluation metrics, such as histogram-based method, SSIM,L1 loss, etc. For path planning problems, the best promising region is the unbroken area connecting the start and goal states. Therefore, we employ path planning algorithms to assist in testing the connectivity. Specifically, we set the promising region (green area) as free spaceXfree(test)and denote it as white. Then we execute the RRT algorithm inXfree(test): if feasible paths can be found, it means thatXfree(test)is connected.
Fig. 5 displays the process of our task-based connectivity evaluation method and its advantages. In Fig. 5(a), although the shape of the generated image and the image in the training set are very similar according to the image evaluation metrics,the quality of the generated image is not good because it does not achieve our task, which is to find the promising region connecting the start and goal states. In Fig. 5(b), even though the generated image looks very different from the image in the training set, the quality of the generated image is good because the start and goal states are well connected.
2) Generalization Ability
Another measurement for model quality is the generalization ability in completely different environments. Herein,we use two additional datasets for test. The first additional test set includes 6 types of unseen environment maps, as shown in Fig. 6(a). As the method shown in Section IV-A, we randomly set 20 to 50 pairs of start and goal states and run RRT to generate ground truth promising regions for comparison. In order to further test the generality of our model, we use more complex maze maps as another additional test set, which is shown in Fig. 6(b).

Fig. 5. An illustration of the method for connectivity evaluation. In each subfigure, the left sets of images are the ground truth promising region and its corresponding environment map, and the right images are the generated ones.
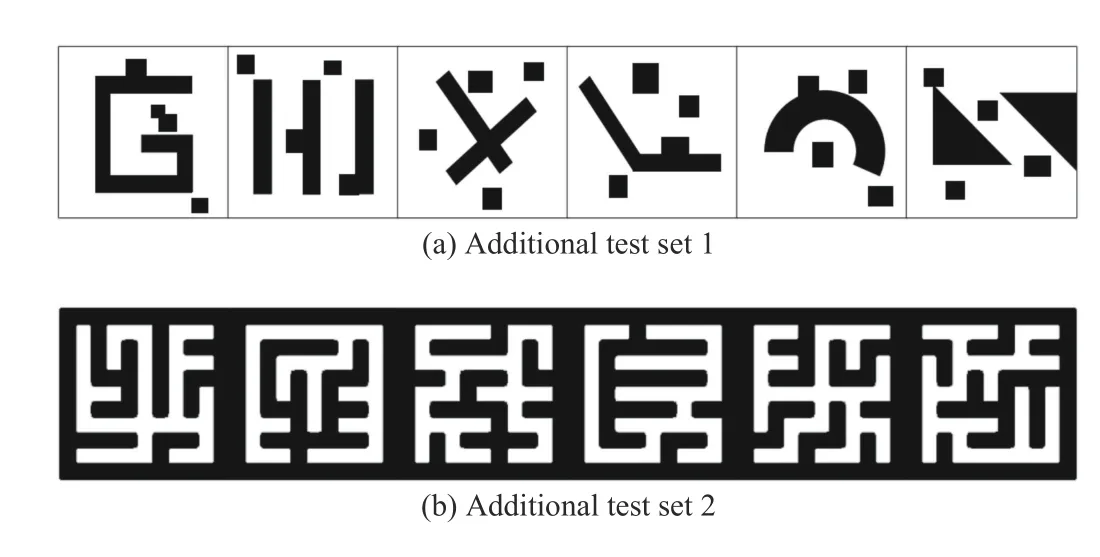
Fig. 6. Examples of different maps for generalization ability test.
3) Improvement for RRT*
We compared three indexes in the process of finding the initial path and the optimal path, including path cost, number of nodes, and computing iterations. Path cost represents the quality of the path, and we use the Euclidean distance as the cost function (shown in (2)). The other two indexes reflect the availability of the algorithm when applied to practical applications. The number of nodes indicates the requirement of memory space, and computing iteration refers to the time consumption of finding a feasible path or an optimal path.Instead of the running time, we use computing iterations to represent time consumption to avoid time differences caused by different operating platforms.
C. Experiment Results
1) Connectivity
In our experiment, the success rate reaches 89.83%. Some of the results are represented in Fig. 7. It demonstrates that our model can generate high-quality continuous promising regions on different conditions.
2) Generalization Ability
As shown in Fig. 8, our model shows good adaptability in completely different environments. It predicts accurate continuous promising regions in the two additional test sets,and the success rate can achieve 81.93% and 75.56%,respectively.
3) Improvement on RRT*
To illustrate the improvement on RRT*, we randomly choose one result from each type of the environment maps in the test set, which is represented in Fig. 9. As RRT* has strong randomness, we run the GAN-based heuristic RRT*and the basic RRT* 100 times on Python 3.8 to get the statistics of evaluation results. Figs. 10–12 show the comparison results of our GAN-based heuristic RRT* and the basic RRT* during the initial stage and optimization stage.
a) Initial stage
The initial stage refers to the period from the beginning to the moment when the first feasible path is found. Fig. 11 displays the initial expansion of RRT* trees. In Fig. 11(a), the non-uniform sampling distribution guides RRT* to search in the space with the high possibility of feasible paths, resulting in lower path cost within the initial planning stage. Fig. 11(b)represents a more difficult task and highlights the time advantage of the GAN-based heuristic RRT*. The result shows that the basic RRT* needs 1352 more iterations than the GAN-based heuristic RRT* to find the goal.

Fig. 7. Examples of the generated promising regions in the test set. In each subrow, The upper images are the ground truth promising regions, and the lower images are the generated promising regions.

Fig. 8. Examples of generated promising region images in the additional test sets. The upper images are the ground truth promising regions, and the lower images are the generated promising regions.
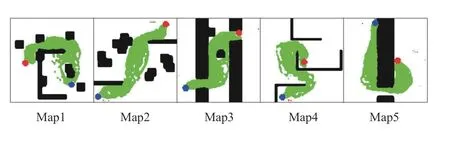
Fig. 9. Five conditions for testing the improvement of GAN-based heuristic RRT*.

Fig. 10. Comparison of path cost, computing iterations, and the number of nodes between GAN-based heuristic RRT* and basic RRT* during initial stage and optimization stage. The red boxes refer to the GAN-based heuristic RRT* and the blue boxes indicate basic RRT*.
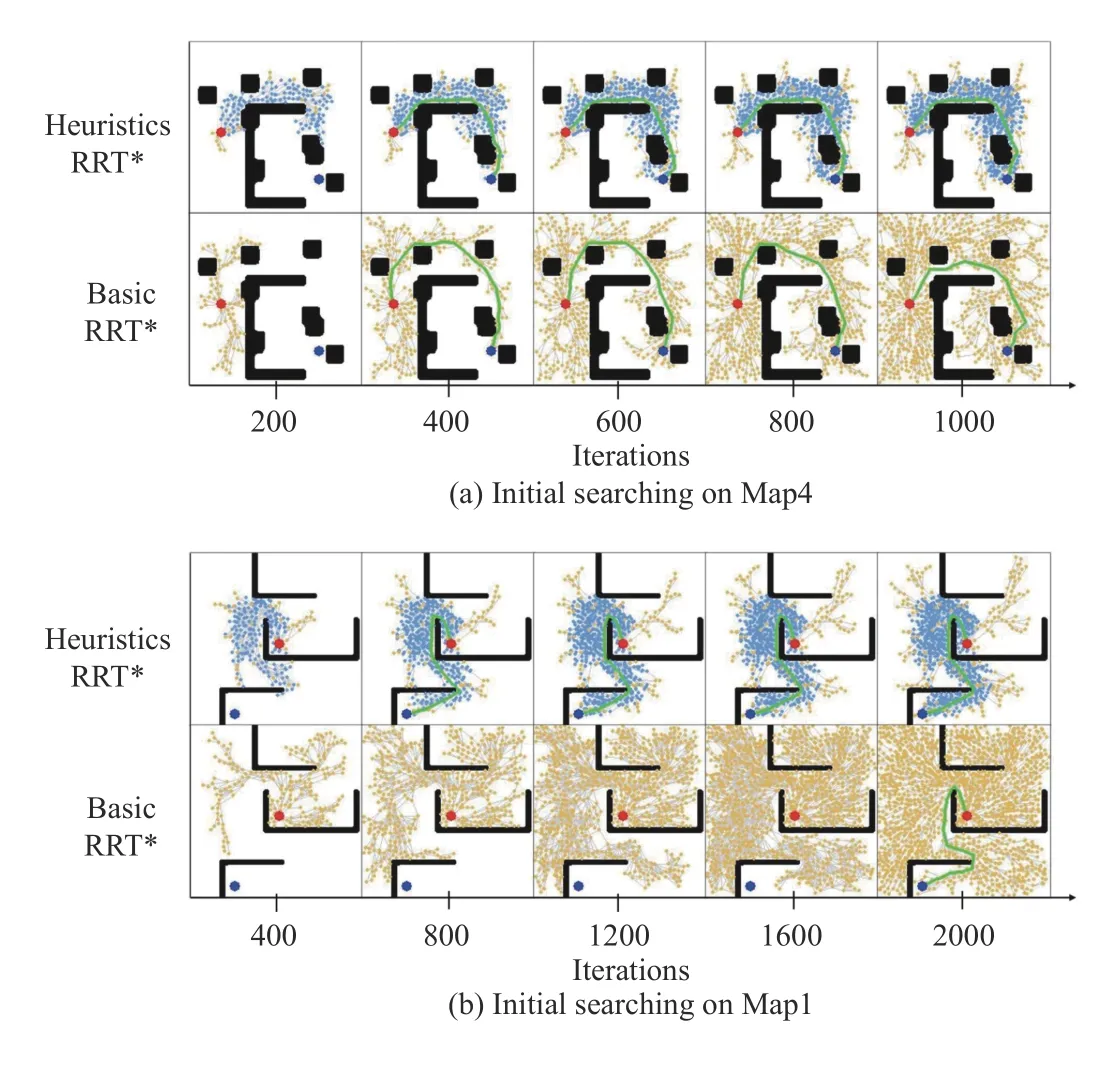
Fig. 11. Comparison of the searching process between GAN-based heuristic RRT* and basic RRT* at the initial stage of planning. The X-axis refers to the number of searching iteration in RRT*. The yellow nodes are uniformly sampled from the whole state space, and the blue nodes are sampled from the non-uniform sampling distribution, respectively. The initial paths are marked as green.

Fig. 12. Comparison of RRT* expansion. The figures are the final moments of RRT*. The yellow nodes are uniformly sampled from the whole state space and the blue nodes are from the non-uniform sampling distribution. Start states, goal states and optimal paths are marked as red, blue, green,respectively.
Figs. 10(a)–10(c) display the box-plot of the comparison on initial path cost, computing iterations, and the number of nodes. The midpoint of the boxes refers to average value, and the height of boxes refers to variance. According to the results, the GAN-based heuristic RRT* has better performance on the three indexes. Additionally, the effectiveness is more obvious on difficult tasks (such as Map4). Furthermore,the heuristic non-uniform sampling distribution reduces the variance of different iterations, which means that it increases the robustness of RRT* to find a feasible path in a short time.
b) Optimization stage
The optimization stage refers to the period from the beginning to the time when the optimal path is found. Fig. 10(d)–10(f) compare the statistical results of the three metrics in the optimization process. As shown in Fig. 10(d), the cost of optimal path remains the same between the basic RRT* and GAN-based heuristic RRT*, which implies that taking most of the sampling nodes from our non-uniform sampling distribution will not affect the cost of the optimal path. Figs. 10(e) and 10(f) illustrate the significant decrease in time consumption and the number of nodes: our GAN-based heuristic RRT*achieves 4 to 12 times faster, and the number of nodes is reduced by about 30%.
The advantage of our GAN-based heuristic RRT* is more obvious during the optimization stage, for the non-uniform sampling distribution guides RRT* to avoid sampling in low possibility region, resulting in fewer nodes to search during the optimization process of RRT*.
Figs. 12 and 13 demonstrate the above-mentioned benefits more intuitively. Fig. 12 displays the final expansion of RRT*trees when optimal paths are found. The nodes of basic RRT*flood the whole state space. In comparison, the number of the nodes of GAN-based heuristic RRT* is much less than the basic RRT*, and the nodes distribute in the regions of high possibility. Fig. 13 shows the convergence process of the basic RRT* and GAN-based heuristic RRT*. Figs. 13(a) and 13(c) exhibit the convergence of path cost over time, and Figs. 13(b) and 13(d) display the increment of nodes. The comparison demonstrates that our GAN-based heuristic RRT*can significantly reduce the planning time and quantity of sampling nodes.

Fig. 13. Convergence process of path optimization. The blue translucent scatters refers to the multiple experiments of GAN-based heuristic RRT*, and the red scatters refer to basic RRT*’s. The solid line of each color is a demo of the searching process. The dotted line connecting the solid line and the Xaxis marks the end moment of the search.
D. Discussions
Herein, we make some extended discussions on the current model and propose some promising improvements.
1) Extensions
Our model is applicable to large, complex, and dynamic situations. When the environment maps are much larger than the current input size, we can resize the large maps into smaller ones and use the same network to generate promising regions, and then interpolate the maps into the original size.On the other hand, our model can also directly process largerscale environment maps by increasing the scale of the network. Furthermore, our method can also be extended to three-dimensional space.
In dynamic environments, each frame of the dynamic process can be seen as a static map, so we can use the same method to process each frame (or take a frame at intervals),and generate the sampling distribution in real time. The generator of our model takes 20 ms to generate the promising region of a map in Python 3.8, which meets the real-time requirement. When facing very different environment maps,the accuracy of the trained GAN model will drop, but we can add this type of maps to the training set, and the accuracy will get improved.
2) Improvements
As for GAN model, its architecture can be further improved in a few aspects to increase the success rate of prediction. For example, the current model performs imperfectly on generating promising regions that cross long distances. This is mainly because the long-distance paths account for a small ratio in the whole randomly-generated dataset, resulting in difficulties for the model to learn distant connections. In addition, there is enough room for improvement, such as simplifying structure for lightweight network, repeating cycles for more accurate predictions, and so on.
In terms of the implementation of sampling-based planning algorithms, heuristic rateμmay have better value to balance randomness and guidance. Furthermore, more intelligent sampling strategies can be applied to the heuristic samplingbased algorithm to avoid redundant node selection when moving towards the goal.
VI. CONCLUSIONS AND FUTURE WORK
In this paper, we present an image-based heuristic methodology to guide non-uniform sampling-based path planning algorithms. In particular, we design a GAN model to predict the promising region and apply it to generate heuristic non-uniform sampling distribution for the heuristic RRT*algorithm. We evaluate the GAN model from the image generation aspect and path planning aspect. As an image generation problem, the model shows a high success rate and strong adaptability. As a path planning problem, our method shows significant improvement in the quality of initial paths and greatly accelerates the convergence speed to the optimum.Our heuristic method is more human-intuitive, which can avoid complicated preprocessing on the state space, thus not confining to a specific environment.
Much research can be continued based on this work. One extension is to add kinodynamic conditions (such as step size,rotation angle, etc.) as inputs to improve regional accuracy and enable the network to adjust the promising region according to these constraints. Another promising extension is to apply the model to dynamic environments. Specifically, the small black blocks in our environment maps can be considered as moving pedestrians and vehicles. Through computing our model on each frame (or take a frame at intervals), it is feasible to guide sampling-based planning in dynamic environments. The third promising work is to expand the methodology into high-dimensional configuration space to guide sampling on more complicated conditions.
猜你喜欢
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Survey of Underwater Multi-Robot Systems
- Robotic Knee Tracking Control to Mimic the Intact Human Knee Profile Based on Actor-Critic Reinforcement Learning
- Dynamic Event-Triggered Scheduling and Platooning Control Co-Design for Automated Vehicles Over Vehicular Ad-Hoc Networks
- Data-Driven Human-Robot Interaction Without Velocity Measurement Using Off-Policy Reinforcement Learning
- Integrating Variable Reduction Strategy With Evolutionary Algorithms for Solving Nonlinear Equations Systems
- PID Control of Planar Nonlinear Uncertain Systems in the Presence of Actuator Saturation