查询分割的用户协作隐私保护方法
2020-07-28王斌张国印张磊
王斌,张国印,张磊
(1.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001;2.佳木斯大学 信息电子技术学院,黑龙江 佳木斯 154007)
基于位置服务(location-based services,LBS)的普及,带来了个人的隐私泄露问题。针对该问题,研究者提出了中心服务器架构[1-9]和无中心服务器架构[10-18]2类隐私保护方法。在中心服务器架构中,一般使用可信的第三方来提供保护服务,包括k-匿名[1]、查询多样性[2]、语义多样性[3]和区域范围模糊[8]等多种方法。而无中心服务器模式又存在2种不同类型:一是对信息加密,利用隐私信息检索(private information retrieval,PIR)获取查询结果[18];另一种是通过移动设备,利用协作实现真实信息泛化[11],以及基于协作用户的查询迭代[12]、随机行走[16]、协作缓存[14]和协作轨迹[15]等。但是,中心服务器架构因其独立性致使该实体易成为攻击焦点或服务瓶颈,而加密方式又占用较大系统资源,因而用户协作的架构更为流行[17]。随着研究的深入,发现该架构存在个性化的隐私、连续隐私服务及协作用户可信问题。针对上述问题,本文提出查询信息分割随机交换的缓存隐私保护方法(query randomly exchange and results cached algorithm,QRERCA)。本文基于协作用户的群智感知,利用协作用户提供缓存查询结果,将真实用户隐藏到协作用户之后。该方法可实现个性化匿名、连续查询隐私保护和抵御不可信协作用户等功能。通过安全性分析和实验验证进一步证明了所提出的方法具有较高的隐私保护能力和较好的算法执行效率。
1 攻击模型与隐私保护模型
1.1 系统架构与攻击模型
由于中心服务器架构存在不足,本文使用协作用户和缓存的无中心的系统架构。该架构包含协作用户与基于位置服务(location-based services,LBS)服务器2个实体如图1所示。包括申请者在内的用户称为协作用户,可通过短距离通信完成分割加密后的信息交换。同时还可将结果缓存,并提供给连续查询的其他用户。基于位置服务存在2种服务类型,攻击者可针对服务类型提出2种不同的攻击方法。
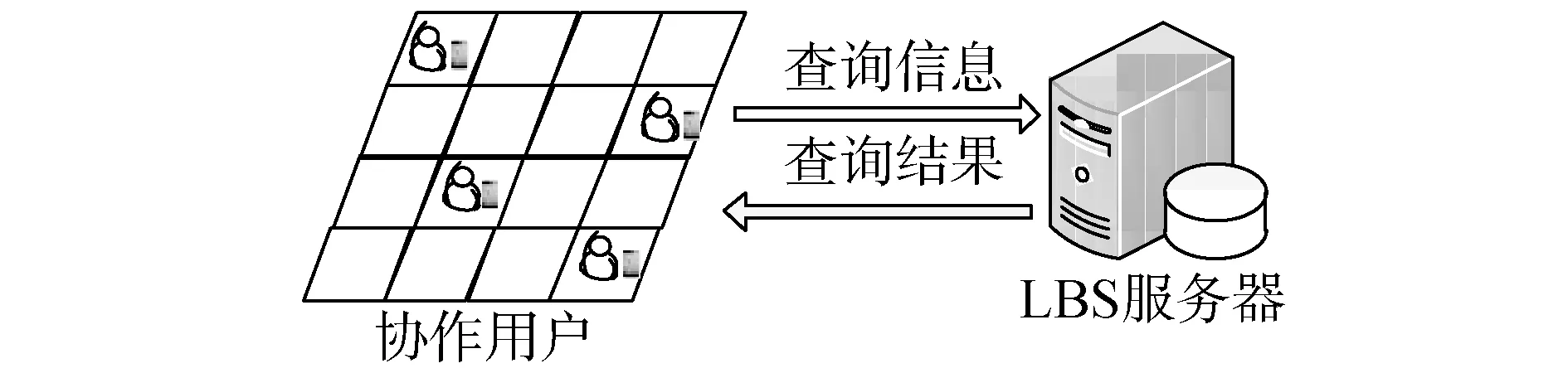
图1 基于用户协作的系统架构Fig.1 The system architecture based on collaborative users
在快照查询中,攻击行为表现为对获得的位置集合中真实位置的猜测概率。设p(i)为不确定位置集合中任意位置属于申请者的概率,通过申请者可能的查询,准确识别申请者位置的概率可表示为:
ps=maxp(i|q)
(1)
式中:当ps取最大值时,此时i所代表的位置是申请者提出查询时所处于的真实位置。
在连续查询中,攻击者对连续位置集合整合后可获得位置轨迹,设攻击者可利用隐私保护之前的部分轨迹作为背景知识,通过相似查询获得某一位置属于申请者真实轨迹的概率可表示为:
pc=max(p(li∈T|sim(qu,qi)))
(2)
式中:li表示连续查询中的不确定位置集合;T为可能的轨迹;qu表示查询信息;qi表示攻击者获得当前位置的查询信息。整个猜测概率在连续查询中转变为对当前查询和申请者查询之间相似性比较,进而通过最大值确定当前位置是否属于申请者。
1.2 隐私保护模型和基本思想
针对上述攻击方法,可采用的隐私保护思想为泛化攻击者的条件概率。具体为:针对快照查询,泛化每一位置与查询之间的关联关系,使得每个查询与当前位置之间存在相等关联关系;针对连续查询,泛化每一次连续查询所提供查询信息,同时减少在连续查询过程中与不可信服务提供者之间的信息交互。
基于以上思想,QRERCA算法可概括为:申请者将查询分割为至少k份,然后与一跳范围内的协作用户进行随机份数交换,在保留一份信息后再与其他协作用户交换,直至保存的任何信息均为一份或达到提交要求后将查询信息提交。在获得反馈结果后,所有用户均将全部结果保存在缓存中,当有其他用户申请查询结果时,该用户将全部结果发送给申请者。若执行过程中无法找到满足匿名值数量协作用户时,算法执行失败。
2 查询信息分割随机交换的缓存隐私保护算法
2.1 查询分割交换规则
QRERCA算法提供以下基本规则:1)最大最小交换次数:该规则用于终止查询分割交换,以保障服务效率。在未满足最小交换次数的情况下,用户必须与邻近用户进行查询分割交换,直到满足最小交换次数。如果经过多次交换后,仍未能满足查询分割仅为一份,但满足最大交换次数时,用户必须提交查询分割给LBS服务器。2)交换分割份数:为保障攻击者不能通过查询分割份数关联用户,算法规定在交换过程中,所交换的分割份数为1~k-1的随机数,增加用户查询信息的随机性。3)无查询的协作用户:在整个过程中完全作为参与的用户,本规则限定在初始交换时,该用户仅获取其他用户发送的查询分割而不进行交换。
基于上述原则可得到QRERCA算法的执行过程,查询分割交换为:
Input:当前用户的查询分割Ma,其他用户的查询分割Mother,分割数量n,用户数量u_num
Output:交换后的分割集合Mexc
初始化:Mexc=Null;
if(不存在查询分割)
return;
else
for(i=1;i<=u_num+1;++i)
n=the blocks number ofMi;
if(n>1)
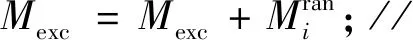
end if
end
end if
与其他用户交换Mexc with other user;
算法1在执行成功的最坏情况时,算法重复至少m次才能找寻到足够的协作用户参与匿名,此时的时间复杂度为O(mn),当m有限时,可认为算法的时间复杂度为O(n)。
2.2 匿名组建立与个性化匿名
个性化匿名如图2所示:设存在A、B、C、D、E 5个用户且匿名值为4、3、2、4、0,最小交换次数为2、2、1、3、2,m为查询信息。根据算法规则,所有用户将查询信息分割为4、3、2、4、0块。为便于对算法的理解设用户E为协作用户。如图2(a)所示,用户A和D同时与B、C交换,得到如图2(b)所示的结果。在图2(b)中,A的分割数量未满足提交要求,则发起新的申请并与C进行随机交换,结果如图2(c)所示。此时用户A和C均满足提交要求且满足最小交换次数,因此将查询分割提交给LBS服务器,而用户B和D则需要再次交换,在与协作用户E交换后,形成如图2(d)所示的交换结果。从图2(d)中可以看到建立了如[A,B,C,E]、[A,B,E]、[C,D]和[A,C,D,E]所表示的4个匿名组,分别代表不同用户所设定的匿名要求,由此实现个性化匿名。
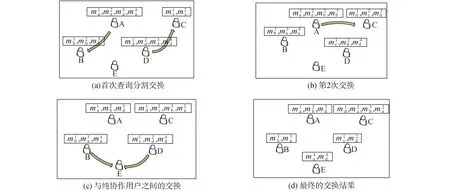
图2 实现个性匿名的步骤Fig.2 The steps of achieving personalized privacy
经过随机交换建立匿名组后,所有用户保存LBS服务器反馈的查询结果。当其他用户经过时,可从该用户获得其缓存的查询结果。
3 安全性分析
3.1 快照查询下的用户隐私安全
根据攻击者可采用的关联概率攻击方法,使用信息熵对攻击成功率加以度量。通常,攻击者对不确定位置集合的猜测成功率可表示为pi,且所有成功率之和为1,由此针对至少k个不确定位置可得到攻击者猜测的信息熵H为:
(3)
根据Jaynes最大熵原理,可知在不确定性最大的情况下,即每一位置猜测的概率相等的情况下,信息熵可取最大值。为验证在快照查询下算法的安全性,本文将通过一个双方博弈加以验证。
挑战者A准备确定的查询(q1,q2),并发送给用户U;U随机选择c∈[1,2]所表示的查询qc,同时将收到的查询分割后混合发送给A;若A能准确的找到一个c′使p(qc′)≠p(qc)则A获胜。由此可得出算法满足定理1时可抵抗这种攻击。
定理1 若算法可抵抗基于概率ps=maxp(i|q)的关联攻击行为,当且仅当
p(qbi∈qc|qc∈U)=p(qbj∈qc|qc∈U),
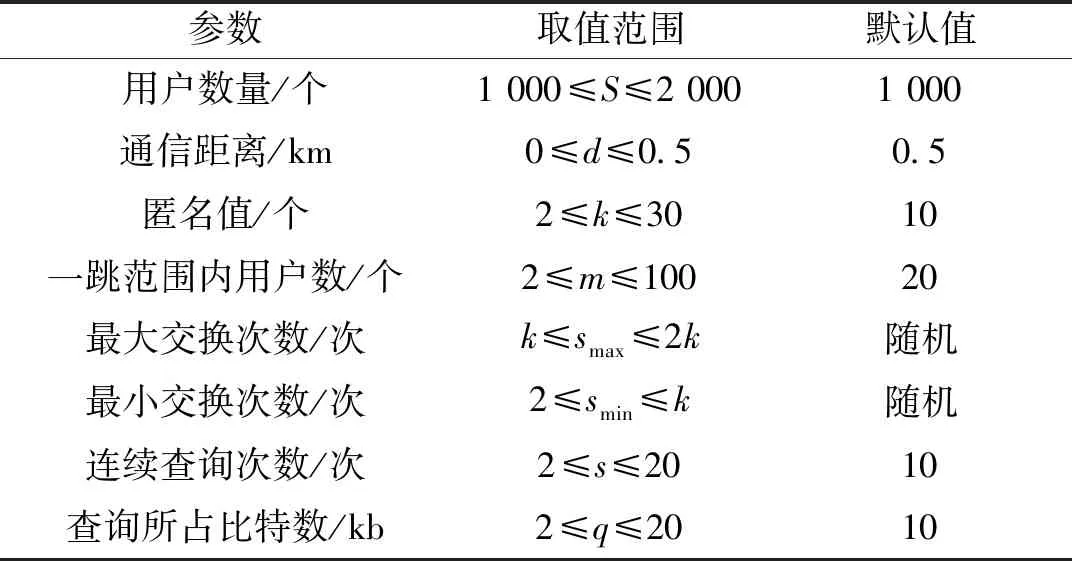
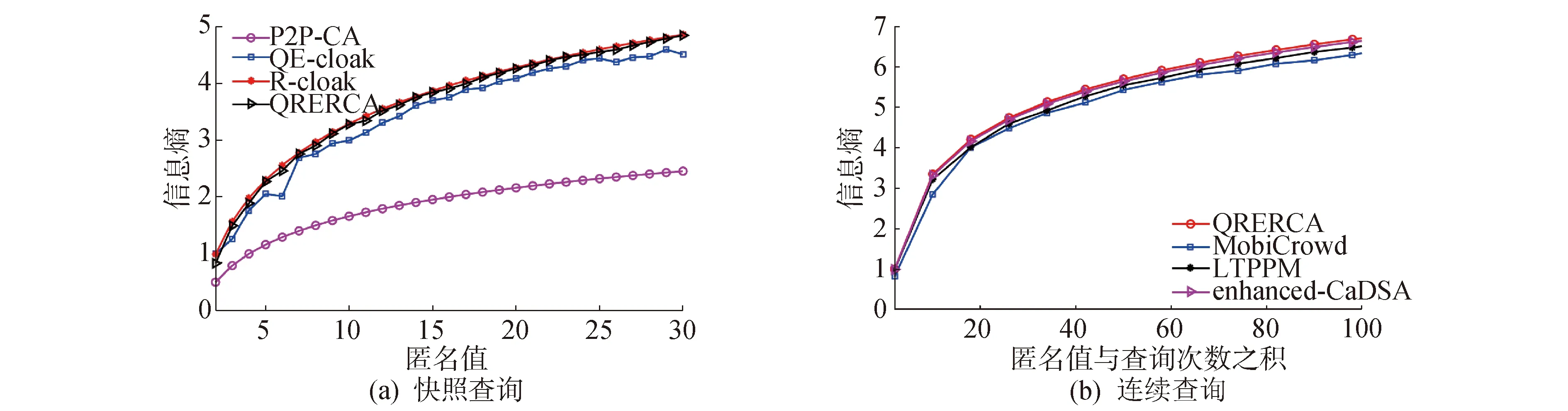
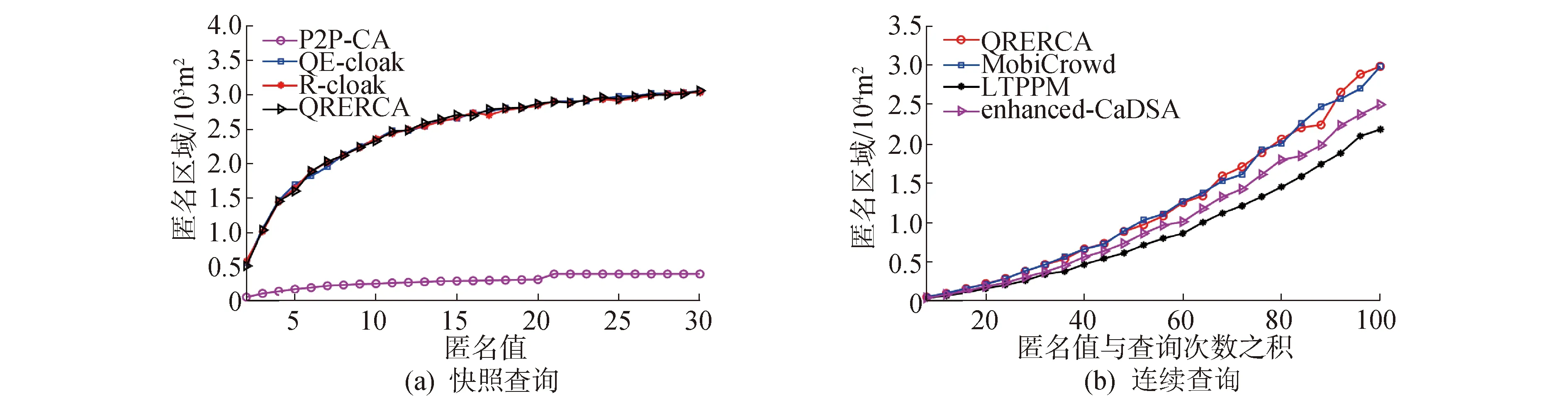
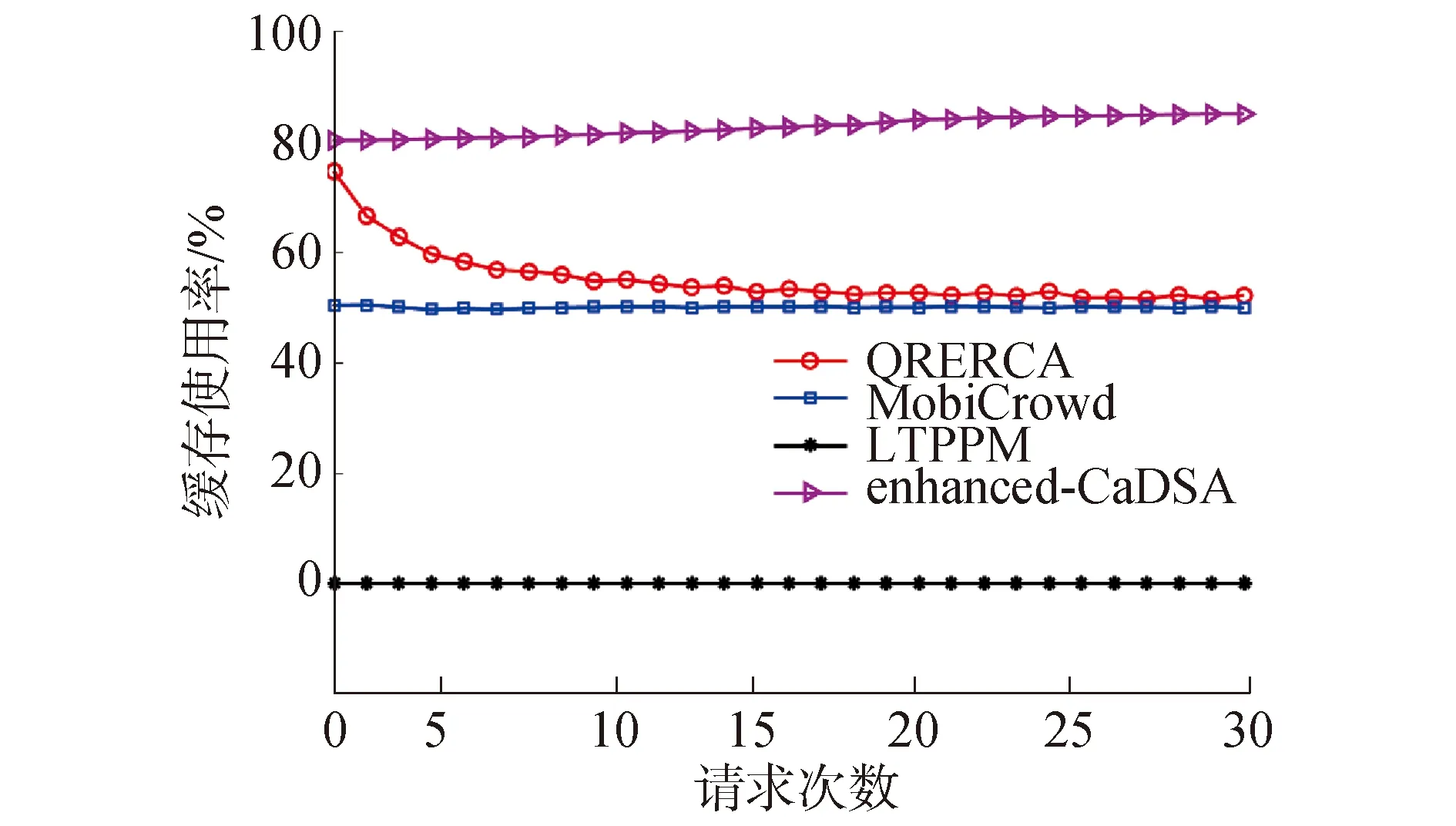
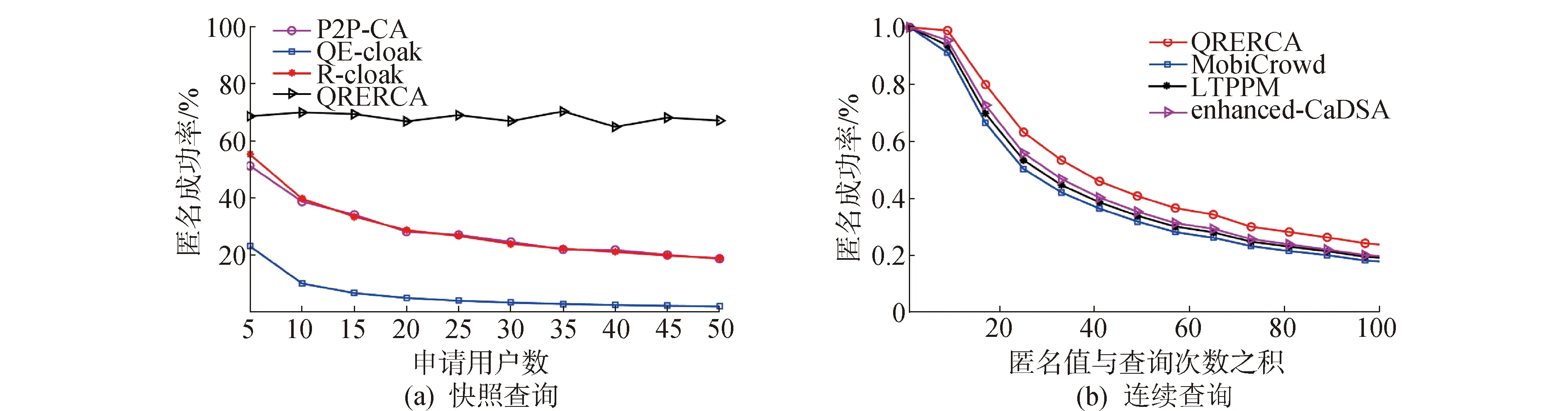
∀(0 (4) 推论1 QRERCA算法可抵抗这种基于概率的关联攻击。 证明:对于分割后的任一查询bi,攻击者通过该查询分割可准确识别申请者的概率为: (5) 同样,对于任一查询分割bj,其准确识别的概率可表示为: p(qbj∈qc|qc∈U)=pj/p(qc∈U) (6) 对于这样一对查询分割bi和bj,如果存在 pi=pj,∀(0 (7) 则满足定理1,此时该算法可抵抗基于概率的关联攻击行为。由于QRERCA算法将查询分割进行交换之后,使用户的每一个查询分割都可与该匿名组内真实用户的查询对应,因而攻击者获得的查询概率彼此相等,即pi=pj,由此可取得信息熵最大值,攻击者对当前位置集合具有最大不确定性,即用户的位置隐私可得到最大的安全保障。 对于连续查询下的用户隐私,假设攻击者可掌握部分子轨迹,通过子轨迹可获得以用户查询为代表的背景知识。因此攻击行为可表现为相似查询确定已知轨迹的概率。设L和Q分别为攻击者获得的经过算法在快照查询下的位置和已知轨迹T获得的查询集合,则其中任一位置和查询之间的关联概率可表示为p(l,q),其边际概率分别用p(l) 和p(q)表示,此时集合L和Q之间彼此的互信息I(L;Q)可表示为: (8) 互信息表示2个随机变量之间的相互依赖关系,如果等于0,则表示两个随机变量不存在关联。 定理2 若算法可抵抗基于概率的关联攻击,当且仅当 I(L;Q)=0 (9) 推论2 QRERCA算法可抵抗概率的关联攻击。 证明:在算法泛化后的位置集合中,每一个位置都可与匿名组中其他用户相关联,同样每一个查询也可以与任意位置相关联,可得关于位置和查询之间的边际概率p(l)=p(q)=1/k,且其联合概率为p(l,q)=1/k2,集合L和Q之间的互信息为: (10) 经计算可得出式(10)的结果为0。此时,攻击者利用掌握的背景知识所表示的查询很难与当前经过QRERCA算法保护后的位置相关联。 对于不可信用户,在整个交换过程中,协作用户仅获得不确定的分割查询,这使得协作用户很难通过组合获得真实查询内容,假设申请者在建立查询分割时使用加密方法,使得在未获得全部分割的情况下协作用户无法解密。对于协作用户提供缓存服务的情况,其安全性取决于该用户缓存的查询结果份数,由于每个协作用户均可以获得满足其匿名值的多个查询结果,所以若该协作用户为不可信用户时,其猜测获得某一结果为申请者所需结果的概率为该协作用户收到查询结果的1/k。另外,在由于协作用户是随机选择的,在众多的协作用户中申请者选中攻击者的概率为1/k。因此,可认为不可信的协作用户很难获得申请者所需的真实查询结果。 为验证算法的隐私保护效力和执行效率,使用BerlinMOD Data Set提供的位置数据进行模拟,以该数据集中心部分并根据用户信息生成查询。所有实验均在处理器为Core i5 1.70 GHz、4 GB内存、Windows 7×64为操作系统的笔记本电脑上通过matlab 7模拟。实验中所涉及到的相关参数如表1所示。 表1 实验参数阈值设定表Table 1 Parameters setting in simulation 隐私保护效力的验证将通过信息熵、匿名空间以及缓存使用率等加以对比;执行效率则通过个性化匿名成功率、平均运行时间和通信量等加以验证。实验结果将分别与针对快照查询的P2P-CA[11]算法、QE-cloak[13]算法以及R-cloak[16]算法相比较;同时与针对连续查询服务的enhanced-CaDSA[5]算法、MobiCrowd[14]算法以及LTPPM[15]等算法相比较。 在快照查询中,信息熵可表示为: (11) 在连续查询中,这种不确定性表现在对信息交互所带来的位置猜测概率上,此时隐私级别可表示为: (12) 匿名空间表示协作用户的分散程度,在本文中使用匿名组所组成的矩形区域面积。 缓存的使用率表明申请者与LBS服务器之间的信息交互程度,缓存使用率越高则与LBS服务器之间的信息交互越低,缓存使用率为: λ=Rc/(Rc+RL) (13) 式中:Rc表示从协作用户的缓存中获得,RL表示查询结果从LBS服务器的信息交互获得。 个性化匿名的成功率为: CSR=∑|US|/|S| (14) 式中:US表示成功实现匿名操作的人数总和,在连续查询中表示n次查询均实现个性化匿名的人数总和。S表示快照查询下所有申请人数总和,在连续查询时表示为所有快照查询中的总次数。 平均运行时间表示为快照查询中的匿名组建立时间,连续查询中表示为匿名组建立时间和连续查询时获得结果所消耗时间的平均值。 通信量表示在不考虑协作用户彼此之间进行短距离通信的情况下,申请者与LBS服务器之间的总得通信量,可表示为: (15) 图3为不同算法产生的信息熵。在图3(a)中,QRERCA和R-cloak算法均达到最大熵,这是由于这2种算法既能保护查询隐私又能保护位置隐私,因而攻击者具有最大的不确定性。QE-cloak算法利用顺序拓扑选择协作用户,其信息熵随用户位置的差异性而随机波动。P2P-CA算法由于申请者具有最小用户间距离,攻击者可利用距离差识别位置,因而其信息熵最小。在图3(b)中,连续查询的信息熵取值随匿名值与查询次数之积逐渐上升。在该图中QRERCA和enhanced-CaDSA算法均可达最大熵,这是由于这2种算法最大程度的利用缓存提供间接查询服务,降低了信息交互。LTPPM算法由于仅利用相似的移动方向和移动速度,致使后续服务很难找到足够协作用户。最后,MobiCrowd算法在无法缓存用户结果时需要直接提交查询,因此该算法的信息熵最低。 图3 快照和连续查询下的信息熵Fig.3 The entropy in snapshot and continuous query 图4给出了不同算法产生的匿名空间。在图4(a)为QRERCA、QE-cloak和R-cloak算法可取得最大匿名空间。由于协作用户在多跳范围内扩散,将位置空间泛化为多跳位置空间。而P2P-CA算法由于协作用户位于单跳范围内,其位置空间远小于其他算法。在图4(b)给中,MobiCrowd算法由于每次查询均需从协作用户处获取结果,其查询空间与查询次数相互关联,可产生较大匿名空间。QRERCA算法在无法获得缓存结果的情况下需重建匿名组,但并不影响匿名空间。enhanced-CaDSA算法使用中心服务器缓存,申请者主要从中心服务器获得结果而不需建立匿名空间,其连续查询下的匿名空间较小。LTPPM算法仅利用相似的移动方向和速度进行泛化,致使整个连续查询过程中协作用户变化最低,因此产生的匿名空间最小。 图4 快照和连续查询下的匿名空间Fig.4 The anonymous space in snapshot and continuous query 本文只考虑在连续查询下的缓存使用率。在图5中,enhanced-CaDSA算法的缓存使用率最高,这是由于中心服务器可提供更多的缓存服务,可最大程度的获得缓存后的查询结果。由于最大区域范围内匿名组包含的协作用户众多,并且协作用可提供缓存结果。因此QRERCA算法利用率较高。MobiCrowd算法无法确定协作用户是否缓存所需的查询结果,因此其缓存使用相对较低。最后,由于LTPPM算法没有使用缓存,其缓存使用率最低。 图5 连续查询下的缓存使用率Fig.5 The cache hit ratio in continuous query 图6为各算法的个性化匿名成功率。在图6(a)中,QRERCA算法可实现最大的个性化匿名,这是由于查询分割交换可建立适应每个用户的个性化匿名组。而R-cloak和P2P-CA算法仅在较小匿名值时可实现预设的匿名值。而QE-cloak算法必需所有用户共享相同的匿名值,其个性化匿名成功率最低。在图6(b)中,QRERCA算法仍可取得高于其他算法的个性化匿名率。enhanced-CaDSA算法由于中心服务器匿名调配,也可获得相对较好的个性化匿名率。LTPPM算法由于假设协作用户具有相同的匿名值要求,其个性化匿名成功率相对较低,而MobiCrowd算法未考虑协作用户的隐私,导致其个性化匿名成功率最低。 图6 快照和连续查询下的个性化匿名率Fig.6 The success ratio of achieving personalized privacy in snapshot and continuous query 从图7为不同算法的执行时间。在该图中,所有算法均随匿名值的增加其平均运行时间线性上升,这是由于这几种基于协作用户的算法需要随着匿名值的变化寻找协作用户,且寻找方法基本相似,因此平均运行时间基本相同。而在连续查询中,由于不同算法使用缓存的频率以及中心服务器和协作用户计算能力的差异,导致平均运行时间稍显不同。 图8为不同算法在快照和连续查询下的通信量。在图8(a)中,QE-cloak算法的通信量最大,这是由于该算法利用最大信息熵用户进行查询提交,因而其通信量远高于其他几种算法。在其他算法中,QRERCA算法的通信量相对较高,这是由于申请者具有一定概率获得大于自身查询信息的分割集合,导致通信量稍高。其他两种算法由于仅提交自身查询,因此其通信量变化较小。在图8(b)所示的连续查询结果中,MobiCrowd算法由于每次查询均需要执行该算法,因此其通信量最大。QRERCA算法在无法提供缓存的情况下需重新发起查询,其通信量随着查询次数的增多而增大。LTPPM算法由于移动过程中协作用户逐渐无法满足相似性,因而需重新运行算法以寻找协作用户,因此其通信量较小。enhanced-CaDSA算法由于利用中心服务器提供隐私服务,且由中心服务器提供缓存服务,其连续查询下的通信量最小。 图8 快照和连续查询下的通信量Fig.8 The communication cost in snapshot and continuous query 综上,可认为QRERCA算法尽管在执行时间和通信量上稍差,但可提供远好于其他算法的隐私保护能力,同时可提供个性化隐私和连续隐私保护。 1)通过安全性分析,相比于当前较为流行的其他同类算法,QRERCA算法在隐私保护能力和算法执行效率等方面具有优势。 2)QRERCA算法在提供隐私保护能力和服务质量的平衡之间具有更好的优势,因此更适于部署在实际的隐私保护设施当中。 由于基于统计分析和预测的方法盛行,使得现有k-匿名模型的隐私保护能力逐渐捉襟见肘,今后的工作将在如何利用基于统计隐私保护的模型与用户协作架构结合等方面展开。3.2 连续查询下的用户隐私安全
4 实验标准与比较实验结构分析
4.1 实验评价标准
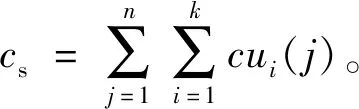
4.2 实验结果

5 结论
