异常值检测在成品油零售客户消费行为分析中的应用
2020-07-27隋毅冯伟荣
隋毅 冯伟荣
(中国石油天然气股份有限公司规划总院)
1 异常值的发现
异常值通常被称为离群点、孤立点,其数值明显偏离所属样本的其余观测值。在大数据分析过程中,异常值检测是非常重要的一类分析方法,是从海量、不完整、有噪声的数据中发现与其他数据显著不同或有潜在价值的信息过程[1]。
异常值检测最早是数据预处理的一个步骤,但是在大数据分析的研究中越来越重要,逐渐发展为一个独立的领域。在成品油零售客户消费行为分析中,异常值检测亦是如此。一方面异常值可能会干扰数据分析的过程,过分夸大或缩小客户的消费行为特征,如对客户加油频次、加油间隔的分析产生误差,数据建模的过程通常会先剔除这些异常值,以免对数据分析的结果产生“反作用”,影响决策者的业务判断;另一方面异常值可能代表着特殊的业务涵义,传递着具有潜在价值的信息,如通过数据分析发现存在个别客户在单日单站使用同一加油卡高频高额消费的情况,显然不同于该客户的消费习惯,这种不符合业务规律的特殊情况,需要深入调研其中的原因,以提升成品油零售客户的精细化管理水平。本文重点对第二种情况进行探讨,通过数据挖掘和探索,揭开数据异常波动背后的业务原因,通过数据分析辅助业务管理水平的提升。
2 异常值检测常用方法
按照数据样本的特征和分布,异常值检测可以分为有监督、半监督和无监督三种方法[2]。
有监督的异常值检测,通常建立在包含有一个或多个目标变量的历史数据基础上,即在检测之初,构建标记为正常或异常标签的训练集。如,根据已知类别的客户样本数据建立客户特征与所属类别的映射关系,实现对新客户的分类预测,识别客户的正常或异常特征。
半监督的异常值检测,通常是有标记的样本较少,无标记的样本较多,如只有正常样本的标签数据,对于异常样本的特征是未知的,这种情况可采用半监督算法,通过正常的对象来推测异常对象的特征。
无监督的异常值检测,通常无目标变量,无法构建正常或异常标签的训练集,只有反映客户特征的样本数据,通过对这些未知标签类别的数据进行探索,寻找数据内在规律,基于样本间距离或密度,对客户归类,识别客户的异常特征。
一般在已标记样本量充足的情况下,可优先选择有监督学习;若只有少数标记样本,可考虑半监督学习;若没有标记样本数据或以往积累样本失效,建议先采用无监督学习来解决异常值检测问题,当捕获到异常且人工核查积累样本到一定数量后,可转化为半监督学习,逐步再转化为有监督学习。异常值可能总是在变化,还可能出现许多新的类型,需要反复训练模型和调整策略。
针对成品油零售客户的消费特征,首先尝试使用无监督的异常值检测方法,挖掘出大部分疑似异常客户,然后通过对数据和业务场景的洞察,对挖掘出的疑似异常客户进一步筛查,找出需重点关注的疑似异常客户,待人工核查后,进行相应异常标记,完成异常客户模式特征的构建。常用的异常值检测方法如下:
(1)基于统计分布的方法
基本原理:根据先验假设的概率分布模型,如数据服从正态分布模型,采用不一致性检验确定异常值,认为发生在统计分布低概率区域的点为异常值。典型的算法为ESD(极值学生化离差)离群检测算法[1,3]。
应用场景:若客户单笔交易金额服从正态分布,偏离均值三倍标准差以外的点可以大概率认为是一个异常值,即单笔交易金额过小或过大的客户都可判定为异常客户。
(2)基于邻近性的方法
基本原理:主要为两种,一种是基于距离的检测方法,即远离正常样本的点为异常值,典型的算法为KNN(K最近邻分类)算法;一种是基于密度的检测方法,即稀疏的样本为异常值,也可选择低密度区域且相对远离邻近样本的点为异常值,典型的算法为LOF(局部异常因子)算法[1]。
应用场景:若使用KNN算法,根据客户特征计算当前客户与已知类别(正常或异常)的客户之间的邻近距离,若当前客户与已知异常的客户距离较小,则判定该客户为异常客户,反之为正常客户;同理LOF根据当前客户与周围客户数据的距离以及邻域内的密度,判断该客户是否为异常客户。
(3)基于聚类的方法
基本原理:按照客户特征属性,使类内样本的相似性尽可能大,类间样本的相似性尽可能小,将客户聚成不同的类。通过考察样本点与类之间的关系,将不属于任何类的点或小的偏远类视为异常值。典型的算法为两步聚类和K-means算法[4]。
应用场景:使用不同算法将客户聚类,根据设定的异常参数,如异常测度指标,考察客户与类之间的关系,若显示该客户不属于任一类别或引起类内差异较大,则判定该客户为异常客户。
(4)基于分类的方法
基本原理:通过构建训练集,归纳和提炼出现有数据所包含的分类规律,总结输入变量与输出变量的内在关系,构建分类模型,再利用该分类模型对新样本进行分类预测。典型的算法为决策树和贝叶斯判别算法[1,4-5]。
应用场景:根据已标记正常或异常的客户训练样本进行分类模型的构建,得出异常客户的特征,如在特定时间内达到阈值以上高频高额消费的客户为异常客户,若新样本中的客户出现同一特征,则判定该客户为异常客户。
以上四类异常值检测方法在实际应用中各有利弊,如表1所示。

表1 异常值检测方法比较
3 异常值检测应用案例
3.1 数据源选取
以某地市销售公司2018年交易数据为例,选用个人记名卡汽油客户进行分析,总客户数4.4万人,总交易频次65.5万笔。交易数据包括交易商品、交易时间、交易地点、交易量、交易金额等信息,其中交易商品包括92、95和98号油品。
3.2 数据预处理
选用数据挖掘软件SPSS Modeler对数据进行收集、清洗和建模,最终选取交易状态为正常,交易类型为消费,且交易卡号不为空的交易记录。
为挖掘客户的消费行为规律,需要先构建衍生变量,建立客户宽表。结合 5W2H(七问分析法)行为分析方法,将客户数据从金额、频次、时间、站点、产品等消费维度构建变量,并对变量进行相应转换生成一系列衍生变量,数据更直观,分析效果更明显。如根据单笔交易金额衍生月交易金额,根据交易频次、交易时间衍生深夜加油次数占比,根据交易站点衍生常去加油站等。衍生变量能更清晰地反映出客户的特征属性,更易于对客户消费行为进行分析比较。
3.3 异常值检测
由于目前成品油零售客户样本无目标变量,无法获得正常或异常客户的类别标签,因此采用无监督的异常值检测方法进行分析,主要是基于统计分布和聚类的方法。而异常客户的判定需结合业务人员的核查结果,才能明确客户是否为异常并进行标记,因此后续将采用基于邻近性和分类的方法做持续探索。
首先基于统计分布的方法对客户消费行为变量进行探索,按照 3σ准则(拉依达准则)和箱线图相结合的方法,初步筛选出发生在统计分布低概率区域的大部分疑似异常客户;再基于聚类的方法,通过两步聚类算法进行模型构建,按照设定的异常测度指标进一步筛选,最终两种方法相结合筛选出需重点关注的疑似异常客户。
(1)基于统计分布的疑似异常客户筛选
首先对衍生变量进行统计分布的检测,最常见的统计分布为正态分布。若数据不服从正态分布,可以通过对数转换等方式,使其服从正态分布。根据正态分布的特点,采用 3σ准则进行疑似异常客户的筛选,将均值±3倍标准差范围以外的点认为是异常值,但在实际应用中,判断标准(即标准差的倍数)通常根据实际业务需要选取。若数据转换后仍不服从正态分布,则采用箱线图法进行疑似异常客户的筛选。箱线图法认为在数据Q3(第三分位数)+1.5IQR(四分位距)和 Q1(第一分位数)-1.5IQR处为异常值截断点,称其为内限。将内限以外位置的点认为是异常值,实际应用中,判断标准(即IQR的倍数)通常也是根据实际业务需要确定。按照 3σ准则、箱线图法对衍生变量进行探索,筛选出疑似异常客户,如表2所示。表2给出各衍生变量的临界值,将临界值以外的客户筛选为疑似异常客户,如加油时间间隔小于15 min的客户。这里将触发任一变量临界值的客户都筛选为疑似异常客户,按照客户ID进行汇总和去重后合计1.6万人,数量较大,仍需进一步聚类排查。临界值探索结果详见表2。

表2 临界值探索结果
(2)基于聚类的重点关注疑似异常客户筛选
在确定疑似异常客户范围后,采用两步聚类算法,完成异常客户的进一步筛选。先将客户聚成若干类,再在聚类的基础上,计算所有样本的异常测度指标,确定重点关注的疑似异常客户,并探索在哪个变量方向上导致呈现异常。
两步聚类分为预聚类和正式聚类两个步骤。第一阶段预聚类采用贯序方式将客户粗略划分成若干子类,第二阶段正式聚类根据亲疏程度决定哪些子类可以合并,最终形成K个类。关于聚类数目,算法自动计算,通常第一阶段使用 BIC(贝叶斯信息准则)准则判定,BIC减少幅度最小时为聚类数目的粗略估计值;第二阶段利用类合并过程中,类间差异性最小值变化的相对指标对第一阶段粗略估计的聚类数目进行修正。异常测度指标包括异常指标(AI)、变量差异指标(VDI)等。对于样本点S,AI定义如下:
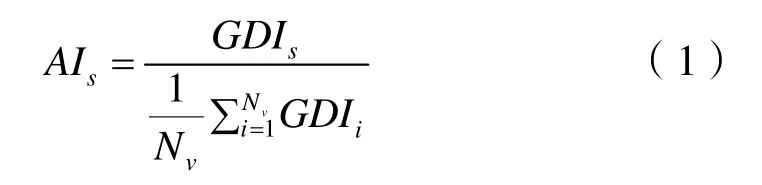
式(1)中:GDIs——样本点S与所属类v的对数似然距离,反映样本点S引起的类内差异;而——类v内其他样本点所引起差异的平均值,Nv为类v的样本量。AI是一个相对指标,反映客户所引起的类内差异与类内其他客户所引起的类内差异平均值的比值。通常认为样本点引起类内差异是其他样本点引起类内差异平均值的2倍以上时,则该样本点为异常客户。AI值也可根据实际业务需要设定。VDI为样本点各变量所引起的类内差异,反映样本点S加入类v所引起的类v内部差异量中各聚类变量的贡献大小,将异常客户的VDI按照降序排序,排在前m的变量是导致该样本点异常的主要原因,默认为3个变量,可进行参数设定。
按照上述分析思路,对统计分布筛选出的疑似异常客户进一步聚类筛选,选取31个聚类变量,使用异常聚类节点,在节点中设置参数AI值为2,节点通过自动迭代,最终聚成四类,如表3所示。

表3 聚类结果 单位:人
表3给出了从各类疑似异常客户中分别筛选出的需重点关注的对象,合计431人,排查对象的范围大幅缩小。从中筛选出需重点关注的疑似异常客户,并显示出引起客户异常的主要原因变量,如表4所示。

表4 聚类1异常客户变量贡献
表4以聚类1重点关注的98个疑似异常客户为例,列出各变量对异常产生的贡献情况,其中有13人主要由平均加油时间间隔引起,这类客户在该变量上出现显著异常,VDI值高达0.311。表5提供了判定为重点关注的疑似异常客户的AI值、引起该客户异常的前 3位变量以及相应VDI值,以便后续人工核查。

表5 重点关注的疑似异常客户分析结果
以客户A为例,其异常测度AI值达到22.546,远大于设定值 2,说明该客户异常的可能性很大,引起该客户异常的第一主要变量为月交易频次均值,VDI值为0.217,贡献度最高;第二主要变量为月交易频次最大值,VDI值为0.163;第三主要变量为月交易金额均值,VDI值为 0.154。根据客户 A的异常原因,查看其具体变量值,分别为变量1(月交易频次均值)为78次,变量2(月交易频次最大值)为123次,变量3(月交易金额均值)为19 717.6元,说明客户A在月交易频次和月交易金额上显著高于其他客户,需重点关注,查明原因。通过对以上数据分析结果的解读,可以大幅提高人工核查的效率和准确度。
目前成品油零售客户消费特征的异常值检测结果可通过可视化的方式固化在客户关系管理系统中,根据业务需求定期监控排查。基于与加油站的调研结果和监控视频的比对发现,异常客户的产生有两种情况。一部分情况是属于“一卡多车”,即由加油站代管加油卡,供机构客户的车队司机统一使用,因此出现客户在单日单站使用同一加油卡高频高额消费的情况。这种情况反映出办卡过程的规范性有待提高,不能将车队卡办理为个人卡,已办理的需尽快变更卡片属性,若同时还缺少加油卡代管协议,双方应尽快补充签订。另一部分情况属于个别加油员利用加油卡折扣套现套利,这种情况就会为企业带来营销成本的损失,应及时发现、及时处理。针对有加油卡代管协议的客户将在客户关系管理系统中通过添加白名单加以管理,减少无效的异常监控,同时对于其他不符合业务管理要求的情况,将针对数据挖掘的结果详细核查,进一步规范加油站的客户管理,提升企业的精细化管理水平。
4 结束语
本文是基于大数据分析技术进行成品油零售客户消费行为异常值检测。 首先基于统计分布的方法对衍生变量进行探索,初步锁定疑似异常客户的范围,其次进一步基于聚类的方法,对初步筛选的疑似异常客户进行细分,根据异常测度指标的设定,筛选出需重点关注的疑似异常客户,并列出引起该客户数据异常的原因。经过层层筛选,最终确定的重点关注疑似异常客户将更加精准,能够有效辅助业务人员核查,不仅节约人力成本,更从最大限度上避免了企业不必要的损失。
