不同优化算法对于神经网络搭建模型的误差研究
2020-07-26兰孝文赵晓阳张晓琳
兰孝文 赵晓阳 张晓琳

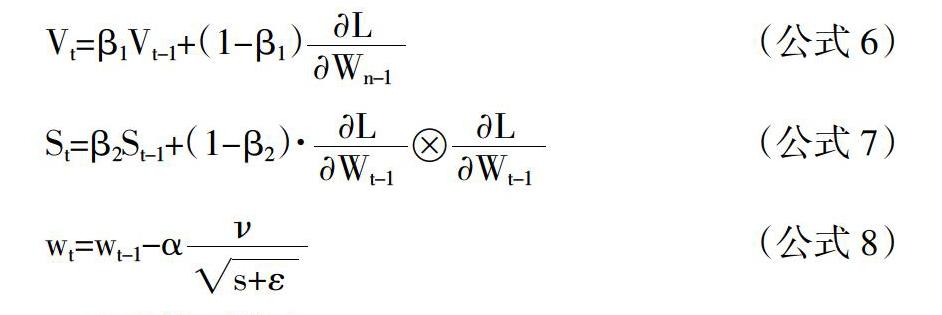
摘 要:影响一个模型预测效果的并不一定是所用的方法和所确定的参数,还有可能是在训练损失的过程中所选择的优化算法,它是预测模型搭建过程中所不能忽视的重要因素。在TensorFlow中提供了不同种类的优化器编程接口。文章以包头市空气污染物浓度预测为研究对象,在优化过程中通过综合对比不同优化算法在以LSTM神经网络搭建的预测问题上的误差,从中选取最合适模型的优化方法。
关键词:优化算法;预测模型;预测误差;LSTM
中图分类号:O212.1 文献标志码:A 文章编号:2095-2945(2020)22-0018-02
Abstract: The prediction effect of a model is not necessarily affected by the methods and parameters determined, but also by the optimization algorithm selected in the process of training loss, which is an important factor that can not be ignored in the process of building a prediction model. Different kinds of optimizer programming interfaces are provided in TensorFlow. This paper takes the prediction of air pollutant concentration in Baotou as the research object, comprehensively compares the errors of different optimization algorithms in the prediction problem based on LSTM neural network, and selects the optimization method of the most suitable model.
Keywords: optimization algorithm; prediction model; prediction error; LSTM
引言
不同的優化算法,对最后模型的预测效果会产生不同的效果。Adam虽说已经简化了调参,但是没有一种算法能一劳永逸地解决问题。最近就有研究表明Adam的训练时的收敛速度虽然比SGD要快,但最终收敛的结果并没有SGD好[1]。总之算法固然美好,但数据才是根基。只有在充分理解数据的基础上,根据训练样本的数据特性和算法特性进行一些必要的调参实验,从而才能找到模型的最优解。
1 优化算法介绍
1.1 Momentum
SGD算法的核心问题在于梯度指向的方向并非指向我们真正函数的最低点。为了规避这类问题呢?Hinton在提出了在SGD优化算法中加入Momentum。
Momentum在中文是动量的意思,它最先出现于物理学上。算法的核心思想是让一颗小球在一个坡里面施加一个外力,小球就可以在坡里面进行自由滚动,累积的动量越多,小球在其中就跑得越快,若小球的方向发生变化,动量也会随之衰减[2]。相关数学公式如下:
Wn+1=Wn-Vn+1 (公式2)
公式中,W相当于是路程,?坠参数等价于一个摩擦阻力系数,它指的就是使小球停下来的阻力系数,公式中要用?坠来近似衡量这种减弱。?浊■表示的是小球在梯度在梯度方向因受到外力的作用而产生的加速度,t代表的是单位时间。
1.2 Nesterov accelerated gradient
该优化算法也叫梯度加速法,在刚才引入Momentum的假设里,我们让小球在坡顶自由滚动, Nesterov就是相当于有个驾驶员在为我们指路,会对下一步要走的路进行预测。通过提前预测决定下一步该怎么走。Nesterov涉及到的公式如下[3]:
Wn+1=Wn-Vn+1 (公式5)
相对于Momentum,Nesterov不考虑梯度对速度的改变,以当前速度和位置,近似预计下一次要移动到的位置,根据下一步预测的近似位置,在此位置上求梯度,并对现在位置进行更新,最后用上一步得到的Vt来对位置进行真正的选择。
1.3 Adam
Adam中文全称为自适应性矩估计方法,它是一种自适应学习率的算法,该方法利用梯度的一阶和二阶矩对不同的系数计算不同的自适应学习率[4]。Momentum和NAG都是以相同的学习率更新模型参数的各个分量,但是在深度模型中,数据的维度越多,需要更新的参数的量也越大,而且参数的更新也有差异。在计算一二阶动量时就不会累计全部的历史梯度,而是只关注与它最近的时间窗口的梯度。这样设计的目的可以使每一个迭代的学习率都有一个固定的变化范围,可以让参数变化得更加平稳,该算法涉及的主要公式如下:
2 实验模型搭建
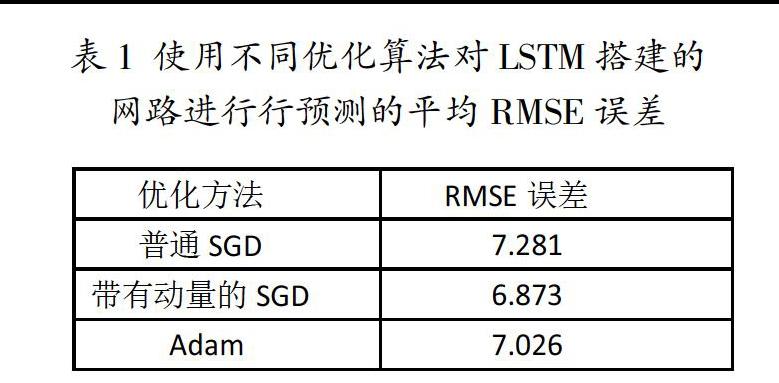
本次实验所需要的数据来源于中国空气质量在线检测分析平台,里面收录的数据包含PM2.5、AQI、PM10、SO2、NO2、O3_8h、CO等一些常见的监测指标,数据每小时自动更新一次,如果遇到某一天的数据有缺失的情况,我们用该天所在月的平均值来进行代替[5]。接下来,我们将实验数据除PM2.5浓度数据外所有数据作为模型的输入特征进行实验。迭代的次数epoch参数也是可以改变的,次数越大效果越精确,但是需要的时间也越长[6]。实验中发现把迭代次数设定为200,一方面能加快训练,另一方面也能减少预测误差。实验中还发现LSTM单元数越大,模型训练效果越不好。原因可能是由于忘记偏置参数设置得过大。因此,设置不同的忘记偏置参数的值,发现当减小忘记偏置的参数值,即适当忘记部分消息,网络的训练效果有些许提高,预测效果也越好;同时在LSTM单元数较大的情况下,应选取比较小的忘记偏置参数,以免记忆太多无关的信息。
