不平衡数据分类中的数据重采样比较研究*
2020-07-19衷宇清陈文文李昭桦
衷宇清,陈文文,李昭桦
(1.广州供电局通信中心,广东 广州 510000;2.中国能源建设集团广东省电力设计研究院,广东 广州 510000)
0 引言
在大数据和人工智能时代,数据挖掘和机器学习已成为必不可少的关键技术,从各行各业的海量大数据中学习、挖掘有价值的信息用于决策支撑。数据分类与预测是一种常见的应用形式,如网络安全领域的异常检测[1,2]、金融领域的信用卡欺诈识别[3]、智能制造领域的产品瑕疵分析以及医疗领域的病理检测[4]等。在许多实际应用中会出现某一类别样本数量远少于其他类别的情况,如网络中的异常流量占总体流量的极少数、信用卡欺诈在信用卡交易中属于罕见行为以及某些特定的病变在正常人群中比例极低等,这种数据现象称为类别分布不平衡(Class Imbalance)。
不平衡数据分类问题是机器学习领域的一个重要挑战。许多传统的分类算法如决策树[5]、支持向量机(Support Vector Machine,SVM)[6]、k 近邻(k-Nearest Neighbor,k-NN)[7]等,在类别均衡的数据中能取得较好的分类结果,但在不平衡数据中的分类结果会偏向主导数据集的多数类。而往往在这些应用中,少数类才是重点关注的关键对象,如上述提及的网络异常、信用卡欺诈以及病理检测等,对少数类的漏识别和误识别代价极大。因此,不平衡数据分类问题多年来一直是机器学习领域的研究热点之一[3,8-9]。
解决不平衡数据分类问题的方法大致可以分为两类。第一类是从算法角度出发,通过调整代价给予少数类更高权重,从而避免分类模型偏向多数类,这类方法称为代价敏感学习[3]。它主要挑战是如何在各种实际应用中为少数类确定合适的代价值,因此不具备普遍适用性。第二类从数据角度出发,通过对类别分布不平衡的数据集进行重采样,使其类别均衡。重采样可分为过采样和欠采样,分别通过增加少数类样本和减少多数类样本来降低数据集的不平衡比例。数据重采样会改变原始数据的分布,但是由于其具有普遍适用性,得到了较多的应用,如学术界提出了SMOTE[10]、Borderline-SMOTE[11]、基于聚类的重采样算法[12-13]以及集成重采样算法[14]等一系列的算法。不同算法生成的数据集特性各不相同,对不同类型的分类器的影响也不同。哪一类型重采样算法更适合于哪一类型分类器,现有文献中缺乏系统性的理论框架或实验分析。
针对该问题,本文深入探索不平衡数据分类任务中的数据重采样算法和分类器模型的匹配适用性。具体地,采用不同类型的9 种数据重采样算法,对来自不同领域的14 个真实数据集进行训练集类别均衡化,比较C4.5 决策树、支持向量机和最近邻3 种经典分类器在其上取得的分类结果。
1 不平衡数据分类问题
1.1 不平衡数据集
考虑一个二元分类数据集,其中一个类别样本较为稀缺,称之为少数类(Minority Class)。因为它往往是期望识别的类别,所以又称为正类(Positive Class)。数据集中的大多数样本属于另外的类别,称之为多数类(Minority Class)和负类(Negative Class)。例如,在网络异常检测应用中,大多数样本属于正常流量,异常流量样本稀缺属于少数类,是待检测类别。类别分布的不平衡比例定义为:

在不同领域的数据集中,不平衡比例差别极大。例如,在社交网络中垃圾消息和正常消息不平衡比例约为1:20[2],在其他实际应用中可达到1:1 000 甚至更大[8]。
1.2 不平衡数据分类结果评价
对于不平衡数据集,传统机器学习常用的总体准确率(Overall Accuracy)和错误率(Error Rate)等评价指标并不适用。例如,对于不平衡比例为1:1 000 的数据集,分类器将所有样本判别为多数类即可取得高于99.9%的总体准确率,但该分类结果在实际应用中没有价值。因此,不平衡数据分类一般采用针对少数类的评价指标。
二元分类混淆矩阵(Confusion Matrix)如表1 所示,真正例(True Positive)表示正类样本被正确识别为正类,假正例(False Positive)表示负类样本被错误识别为正类。对应的,假负例(False Negative)表示负类样本被错误识别为正类,真负例(True Negative)表示负类样本被正确识别为负类。

表1 混淆矩阵
在混淆矩阵的基础上,可以计算少数类的精确率(Precision)、召回率(Recall)和F值(F Measure)等指标。
精确率又称查准率,表示被分类模型识别为正类的样本中真正例所占的比例,计算方法为:
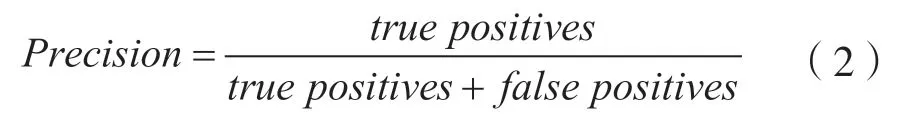
召回率又称查全率,表示测试集中所有正类样本中被正确识别正类的样本的比例,计算方法为:
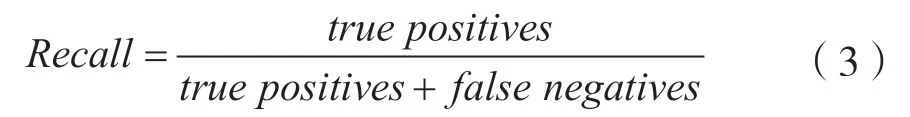
F值是精确率和召回率的加权调和平均,本文采用最常用的F1值,计算方法为:

1.3 机器学习算法
C4.5 算法[5]是一种流行的决策树分类算法,基于信息量增益率(Gain Ratio)最大化的分割原则,采用分治法分割训练集从而构建决策树。在构建过程中,C4.5 算法采用剪枝方法处理由训练数据中的噪声和离群点等异常导致的分枝,从而避免过拟合问题。C4.5 决策树分类模型的节点对应训练集中的样本子集,其中内部节点代表对一个属性取值的测试,分支代表测试的两种不同结果,而叶节点代表一个类别。给定一个待测试样本,从根节点出发对样本的属性值进行一系列测试,直至到达某个叶节点。因为在生成树过程中的分割原则会考虑到所有类别,所以一般认为决策树算法对不平衡数据集的适应能力较强,但是不平衡比例较高的数据集仍然会对算法的分类效果产生影响。
支持向量机[6]是一种线性分类模型,将训练样本视为n维特征空间中的点,算法寻找一个以最大间隔分开两类样本的n-1 维超平面,即其到两边最近样本点的距离最大化。该超平面称为最大间隔超平面,两类中最靠近该超平面的样本点称为支持向量。对于线性不可分数据,可通过核函数进行非线性特征变换,将数据映射到更高维的特征空间,然后在该空间中寻找最大间隔超平面实现数据分类。在不平衡数据集中训练SVM 分类器,经典算法寻找的最优超平面会倾向于少数类,使得分类结果偏向多数类。
k近邻(k-NN)算法[7]是非参数机器学习算法的另一个代表。k-NN 算法没有复杂的训练过程,只需保存训练样本的特征向量和类别标签。给定一个待测试样本,从训练集中找出距离其最近的k个样本,将在它们之间占最多数的类别标签赋予测试样本。本文使用欧氏距离计算样本间距离,并在实验中将k值设为1,即采用最近邻分类器。k-NN 分类器的泛化误差不超过贝叶斯分类器的两倍,具有良好的特性。但是,在不平衡数据集中,该算法将受到极大影响,即出现频率较多的多数类样本有较大可能出现在测试样本的k邻域,从而主导测试样本的预测结果。
2 数据重采样算法
2.1 数据过采样算法
数据过采样算法通过增加少数类的样本来调整数据集类别分布。增加的基本方法包括重复采样少数类样本或增加人工合成样本。
随机过采样(Random Oversampling)算法通过随机从少数类现有样本中重复抽取数据,增加样本数量,降低类别不平衡比例。它简单复制样本的策略,容易导致模型过拟合问题。
SMOTE(Synthetic Minority Oversampling Technique)[10]是经典的基于人工合成样本的过采样算法。算法思路:对每个少数类样本使用k-NN算法在数据集中搜索距其最近的另外k个样本(可能属于少数类或多数类),从中随机选择一个样本进行随机线性插值构造一个新的少数类样本,根据采样倍率重复n次,即可生成一个原有样本数量n倍的少数类样本集。该算法的缺陷是可能使得类别边界变得模糊。于是,研究人员提出了很多改进方法[15-16],其中Borderline-SMOTE[11]算法的思路是先搜索出特征空间的类别边界,然后在边界区域生成少数类样本。具体地,对于每个少数类样本,先考察距离其最近的m 个样本,若其中有半数以上属于多数类,则认为该样本是少数类边界样本。最后,该算法使用SMOTE 算法从少数类边界样本中构造合成样本。
为兼顾类别间不平衡性和类别内不平衡性,基于聚类的过采样算法(Cluster-based oversampling)[12]先对原始数据集中的多数类和少数类分别进行聚类,然后在每个类别的聚类簇中进行过采样实现类别均衡化。集成(Ensemble)过采样[14]算法基于集成学习的思路,对数据集进行多次采样并训练分类器,最后通过多数表决得到最终分类结果。本文集成过采样算法实现采用随机过采样、基于聚类的过采样和基于信息分解的过采样[2]作为基本算法。
2.2 数据欠采样算法
随机欠采样(Random Undersampling)算法通过随机从多数类样本中抽取一个子集作为代表,降低类别不平衡比例,代价是可能丢失多数类的重要信息。基于聚类的欠采样算法(Cluster-based Undersampling)[13]对原始数据集中的多数类进行聚类,将得到的每个聚类簇都和少数类样本结合成为一个新的训练集并训练分类器,然后从中选择最优分类器。
基于Wilson 编辑法的欠采样算法[17]使用k-NN分类器对训练集进行分类,然后去除分类错误的多数类样本。单边选择法(One-sided selection)[18]使用多数类的随机子集与少数类合成初始训练集,然后用最近邻分类器分类原始数据集,将分类错误的多数类样本加入训练集,从而去除多数类冗余样本,再用Tomek links 方法(即数据集中距离最近的两个样本分别属于少数类和多数类)去除多数类中的类别边界及噪声样本。

图1 各数据集的精确率结果
3 实验设计与结果分析
3.1 数据集
表2 列出了本文使用的数据集,其中包含了属于生物医疗、软件工程以及网站统计等不同专业领域的14 个公开数据集,均可在PROMISE 软件工程库[19]、UCI 机器学习库[20]等公开数据库中获取。表2 中数据集按不平衡比例排序,可见在现实世界的真实数据集中类别分布不平衡现象普遍存在。其中,只有diabetic 和pima 两个数据集相对平衡,有8 个数据集的不平衡比率在1:2~1:10,而onehr、pc5、mc1 和pc2 这4 个数据集的不平衡比例则高于1:30。此外,各数据集的大小也相差悬殊,样本数量在253~17 186 不等。
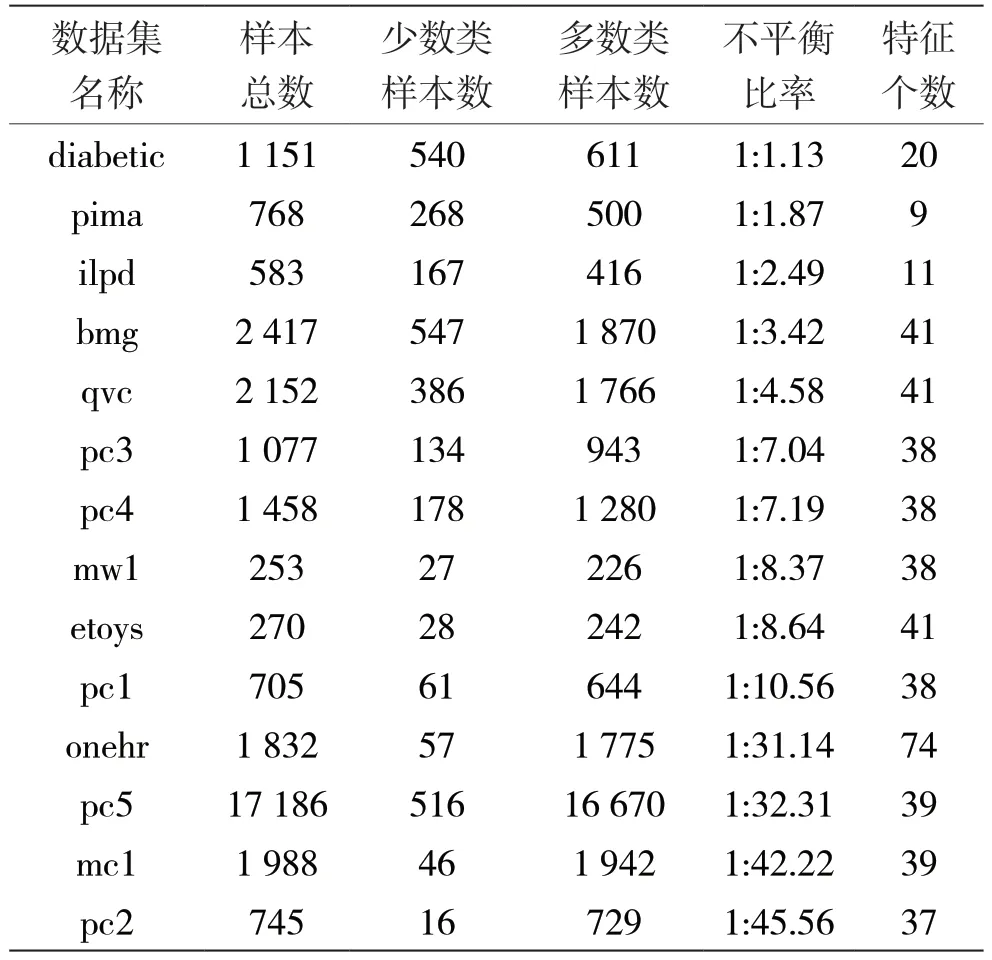
表2 实验数据集信息
3.2 实验设计
对于每个数据集,随机选择原始数据的60%构成训练样本集,并将另外40%用作测试样本集。本文探讨的数据重采样方法仅应用于训练样本集,用以训练不同的分类模型。测试数据集未作其他处理,保持了与原始数据集相近的不平衡度,因此分类结果可以反映真实情况。
对于数据重采样的采样率参数,欠采样方法使用多数类的20%、50%、70%和90%等参数,过采样方法使用少数类的200%、500%、700%和900%等参数。此外,对于两类采样方法比较了均衡采样率,即进行欠采样或过采样直至两类数据样本数量一致,后文分析中取各算法最优参数的结果。最后,原始的不平衡数据集也用于训练分类模型,提供对比基线。
如图2 所示,实验中的C4.5、SVM 和k-NN 等分类算法采用了WEKA[21]提供的实现版本,且均使用了默认参数,未做特殊优化。
3.3 结果与分析
图1 和图2 给出了3 种分类器在各数据集中取得的精确率和召回率结果,其中各灰度条代表不同数据重采样方法处理过的训练集。由直接从原始不平衡数据学习(imbalanced)结果可见,数据集不平衡度越高,3 种分类器的精确率和召回率受影响越大,整体呈现下降趋势。此外,数据集大小对分类结果也有一定影响,如bmg、qvc 和pc5 数据集虽然不平衡比例较前列数据集更高,但是由于数据量较大、少数类样本数较充足,仍能取得更好的结果。总体而言,类别分布不平衡和少数类样本稀缺对分类结果造成了极大影响。
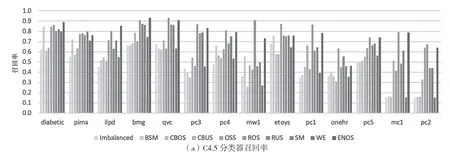

图2 各数据集的召回率结果
从结果中还可看到,不同数据重采样方法对3种分类器的影响各不相同。对于C4.5 分类器,随机过采样(Random Cversampling,ROS)、随机欠采样(Random Undersampling,RUS)、SMOTE(Synthetic Minority Cversampling Technique,SM)和集成过采样(Ensemble Oversampling,ENOS),在大部分数据集中均可以有效提高精确率和召回率。对于SVM 分类器,基于聚类的过采样(Cluster-based Oversampling,CBOS)、欠采样(Cluster-based Undersampling,CBUS)、ROS 和ENOS,对精确率提高较为明显,但是对召回率并没有明显改善,在一些数据集中反而有负面影响。对于k-NN 分类器,ROS、RUS 和ENOS 对精确率和召回率均有显著提升。例如,在不平衡比例较高的pc3、pc4、mw1、pc1、onehr、mc1 以及pc2 等数据集中,直接使用不平衡数据作为训练集的精确率均在30%以下,而经过上述几个算法重采样后,精确率可提升至60%~80%。
图3 给出了3 种分类器在各数据集的F 值结果,反映了精确率和召回率的加权调和平均。对于C4.5分类器,ROS、RUS、SMOTE 和ENOS 在所有数据集中均能够有效提高不平衡数据分类的F值。对于SVM 分类器,在diabetic、pima、ilpd 等不平衡比例不高的数据集中,数据重采样对分类结果影响不大,在其他数据集中ROS 和ENOS 对分类结果的提升较为明显。对于k-NN 分类器,除了etoys 数据集以外,ROS、RUS 和ENOS 均能够大幅提高分类F值结果。
图4~图6 使用箱线图更直观地展示了各个数据重采样算法对3 种分类器精确率、召回率和F值的提升效果,即基于重采样数据训练得到的分类器精确率与原始不平衡数据中训练得到的指标差值在14 个数据集中录得的统计值。
从图4 可见,对于C4.5 分类器,ROS、RUS、SM 和ENOS 算法在各数据集中均显著提高了精确率,平均提升幅度在20%~38%;相比之下,CBOS 和CBUS 没有明显改善,而Borderline-SMOTE(BSM)、One-side Selection(OSS) 和Wilsons Editing(WE)等算法降低了其精确率。对于SVM分类器,CBUS、ROS 和ENOS 在几乎所有数据集中都提高了精确率,平均幅度在13%~24%。CBOS 在大部分数据集中能够提高精确率,但是在少数几个数据集中得到了反效果,总体平均提升幅度为5%。OSS、RUS、SM 和WE 对SVM 精确率几乎没有影响,而BSM 会降低其精确率。对于k-NN分类器,ROS、RUS 和ENOS 在各数据集中平均提高精确率约34%,而BSM、CBOS、CBUS、OSS、SM 和WE 算法对精确率没有明显的提升。

图3 各数据集的F 值结果


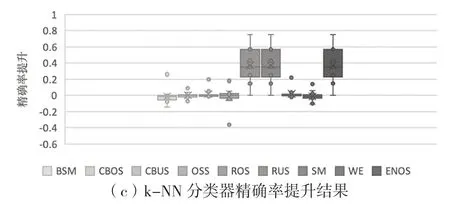
图4 各分类器精度提升结果
图5 结果显示,对C4.5 分类器,除了CBOS 以外,其他重采样算法均能不同程度提高召回率,平均幅度在2%~29%不等。SVM 分类器的情况有所不同,结果显示只有RUS 能够小幅提高SVM 的召回率,平均约为5%,其他重采样算法均为不同程度的降低或持平。对于k-NN 分类器,各个重采样算法几乎在所有数据集中都提高了召回率,平均幅度在1%~37%不等。
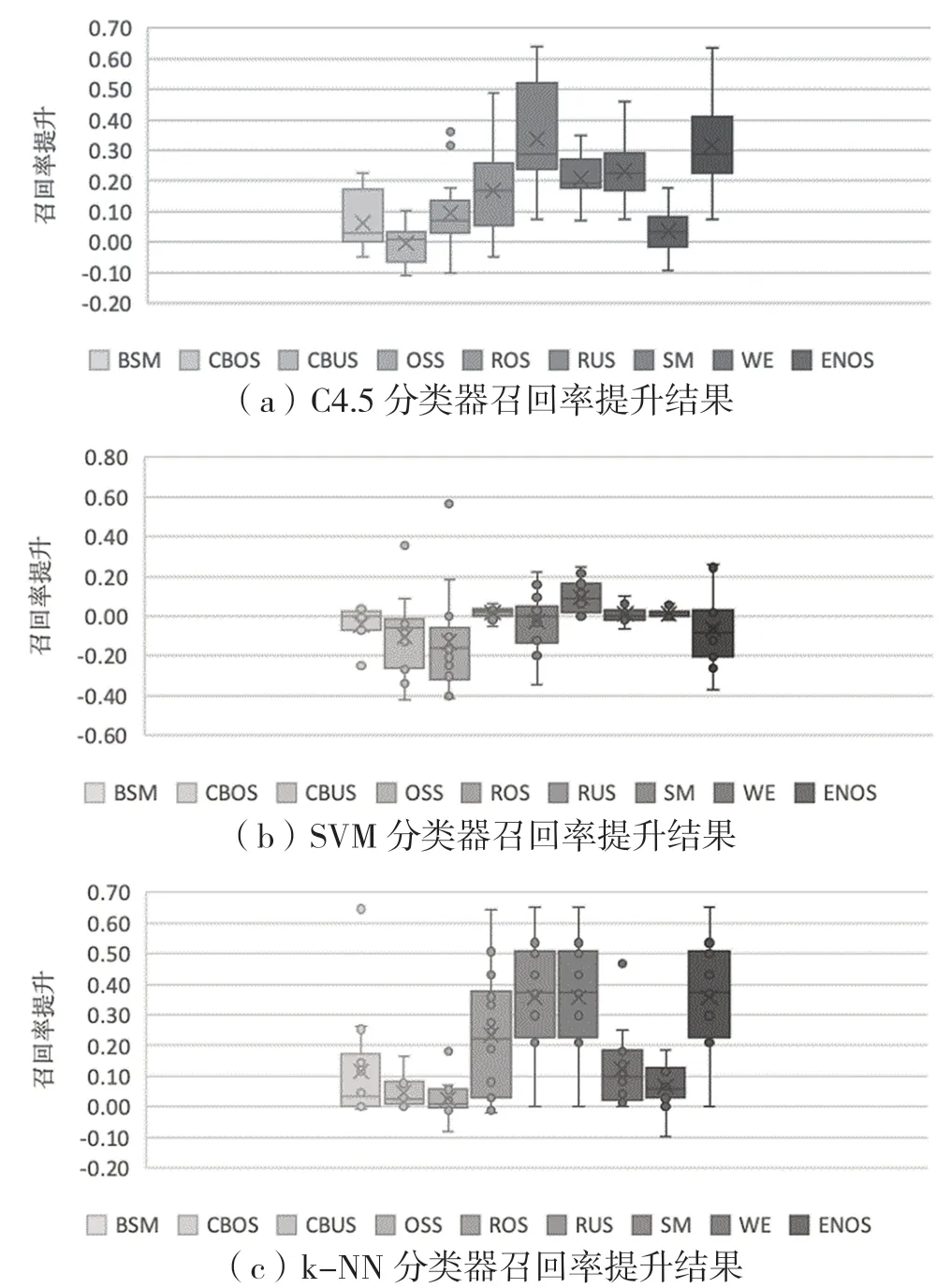
图5 各分类器召回率提升结果
图6 给出的F值结果结合了前文讨论的精确率和召回率情况,可见ROS、RUS、SM 和ENOS 适用于C4.5 分类器,CBOS、CBUS、ROS 和ENOS 适用于SVM分类器、而ROS、RUS和ENOS适用于k-NN分类器。此外,值得注意的是,数据重采样对SVM分类器的影响是在降低了召回率的基础上提高了一定的精确率,在召回率作为关键指标的应用中应当避免使用。

图6 各分类器F 值提升结果
从上述结果中可以得出结论:不同数据重采样方法产生的训练集数据分布特性各不相同,对不同类型的分类算法和模型会产生不同的效果,实际应用中应该根据数据特性和分类算法综合考虑选择。
4 结语
数据重采样方法是解决在现实世界中普遍存在的不平衡数据分类问题的常用方法。本文系统地比较了过采样、欠采样等不同类型的9 种数据重采样方法,在来自不同领域的不平衡数据集中研究对C4.5 决策树、SVM、k-NN 这3 种经典分类器分类效果的影响。实验结果表明,不同重采样算法生成的数据集对不同的分类器产生不同的效用。最后,从精确率、召回率和F值等评价指标的角度,给出了适用于3 种分类器的重采样算法。
