组合模型在电信客户流失预测中的应用*
2020-07-19沈江明曾志勇
沈江明,孙 凯,曾志勇
(1.中国电信股份有限公司云南分公司,云南 昆明 650000;2.云南财经大学统计与数学学院,云南 昆明 650000;3.云南财经大学信息学院,云南 昆明 650000;4.云南省高校数据化运营管理工程研究中心,云南 昆明 650000)
0 引言
客户流失一直都是很多行业需要关注的问题,在新客户开发面临瓶颈的时刻,如何对原有客户采取措施保留,是一项非常重要的问题。在20 多年以来,出现了大量关于电信客户流失的研究,主要包括对数据倾斜问题的处理和模型的构建。这其中多为传统算法或者是对算法改进的单一算法,而单一算法无法在复杂的客户流失问题上持续保持好的结果。针对这一问题,本文尝试将数据倾斜处理方法与模型构建相结合的策略进行系统构建,不仅可以有效解决数据倾斜的问题,而且模型分类效果要优于传统分类算法。
1 相关工作
通过对文献的了解发现,相关的研究多体现在两个方面:数据不均衡问题处理和模型构建。
在不均衡数据处理方面。国外的Ha 等人首次利用了遗传算法可以获取最优解的特点,利用该算法获取最优子数据集,来更好的反应多数类样本的信息[1]。国内的郭娜娜基于差异度的角度对数据不均衡处理方法进行改进并提出了IDBC 算法,对于数据倾斜问题的处理很有效[2]。
在分类算法改进方面。传统的模型多为单一模型的改进。比如张宇等通过决策树来构建模型,并将该模型应用到实际业务中,验证了该模型的有效性,可以为企业进行客户保留提供帮助[3]。马文斌等在客户流失模型构建中运用了深度神经网络,并将模型预测结果与逻辑回归和决策树等模型进行比较,发现神经网络具有更好的预测结果[4]。国外的Hung,xu,Chu 三位学者均利用BP 网络构建流失模型,并取得了非常好的预测效果[5-7]。随着分类算法的技术和理论不断改进,发现集成算法有更好的分类效果。比如国内学者王纯麟和何建敏就第一次应用了集成算法,构建了AdaBoost 模型,根据实际数据的验证结果显示,此模型较传统的BP 模型、贝叶斯模型、C4.5 模型和逻辑回归模型都有更好的预测结果[8]。
虽然上述研究中对不均衡数据的处理有一定的贡献,但是研究的焦点仅从单一维度进行处理,存在着很明显的问题。除此之外,在分类模型的构建中,由于优秀的分类能力,集成模型得到了广泛认可,但是对于基模型的选择仅为树模型,基模型的差异度过低,使得效果提升不明显。
为解决上述问题,本文综合了数据倾斜问题的处理以及组合模型的组合策略来构建一个模型。针对不均衡数据的处理,本文从两个方向进行数据采样,即对多数类欠采样,对少数类smote 过采样。针对算法改进,本文依旧基于差异性的原则,选择4 个差异性较大的基分类器进行线性组合,不同的是数据输入。具体过程:按照数据倾斜问题的处理方式,重复进行4次,每一次都会形成一个子数据集,并且根据抽样方法,每次得到的子数据集都不相同,而且这4 个子数据集几乎涵盖了原数据所有的多数类样本信息,将每一个子数据集用于一个基分类器的构建,然后对训练好的基模型进行融合,从而构建本文的组合模型。
本文构建的模型一方面充分利用了数据样本信息,有效解决了数据严重倾斜的问题;另一方面将数据处理方法与组合模型构建进行了有效结合。最后将构建的模型应用于实际的企业数据来评估模型。
2 数据挖掘理论
2.1 数据挖掘算法
2.1.1 逻辑回归算法
逻辑回归的本质是通过将线性回归结果进行非线性的转化来达到分类效果的。模型的返回值是处于0~1 之间的一个类别概率,通常以0.5 为分界点,概率值大于0.5 的归为类别“1”,反之归为类别“0”。
假设数据中有m个特征,分别用X´=(x1,x2,…,xm)表示;根据类别发生的对应概率为条件概率,用P(Y=1|x)=p表示,则逻辑回归的模型如式(1)所示,其中g(x)可以看作线性回归的预测函数。

2.1.2 支持向量机算法
支持向量机分类性能优越,在企业中被广泛应用,模型原理是在众多的分类面中寻找边际最大的那一个,求解的方法是将问题转化为凸二次规划。若在二分类问题中,存在一条直线可以将数据点分成两类,若是在三维空间,则存在一个平面使得这些数据被分成两类,如果这些数据点属于n维空间,那么在n维空间有一个超平面,将数据点分为两类。
支持向量机通过调节核函数起到非线性拟合的作用,不同的核函数起到不同的拟合机制。因为仅与支持向量有关系,所以支持向量机具有分类效果好,性能鲁棒的特点。
2.1.3 XGBOOST 算法
XGBoost 算法是GBDT 的一种工程化实现,GBDT 算法每一次训练都会生成一个基模型,并且基模型是根据模型残差进行训练的,即一步步降低模型的分类误差,如此不断的迭代下去,形成若干个基分类器,并进行线性加权。通过这种训练方式来不断的降低损失。XGBoost 算法的表达式如式(2):
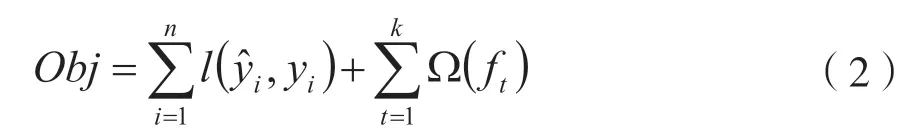
其中n表示样本数量。模型的好坏一方面取决于模型的方差,一方面取决于模型的偏差。
2.1.4 神经网络算法
神经网络以海量数据并行计算为基础,一般包括三个层级结构:输入层、隐藏层和输出层。层与层之间都存在权重,且神经元中都存在连接函数,进行非线性转化。图1 为典型的神经网络结构图。

图1 神经网络结构
BP 神经网络是应用最广泛的神经网络算法,其输出表达式如式(3)所示:

其中ωij为连接权系数;fi为激活函数;xi为神经元输入;θj为神经元阈值。BP 网络通过对维度的调整,实现将问题转化为更高维度进行处理,并通过不断的迭代来修正连接权重和阈值,使得输出误差达到最小。
2.1.5 组合预测算法
随着技术的发展,越来越多的学者选择将多种算法进行组合,充分发挥多种算法的优势。组合模型更加稳健,可以充分利用样本信息,预测结果也更加可靠。
假设有K个子模型,则线性集成的数学表达式如式(4)所示:

本文将重点研究线性集成和数据倾斜处理相结合的方式,来构建流失模型,权重是通过拉格朗日函数求解的。
2.2 评估方法
本文选择了多种评估方法进行模型比较,其中包括了F1 值、AUC 值、少数类样本的预测精确率和犯两类错误率:FNR 和FPR,其中FNR 表示错分为不流失的样本在总样本的占比,FPR 表示错分为流失的样本在总样本的占比。
3 实验分析
3.1 实验数据
模型所用的训练以及测试数据均来自于某电信公司的宽带客户行为数据,训练集和测试集的介绍如表1 所示。

表1 电信宽带数据集的数据描述
3.2 组合预测模型的建立
针对4 种单模型的特点,模型在输出类别“0”和“1”时伴随着类别概率,为了提高模型的分类准确率,本文拟将类别概率作为各基模型的预测得分,用于线性组合。为了防止模型将少数类样本过多的预测为少数类,引入了第I 类分类错误率,作为权重系数的惩罚项。构造的损失函数[9]如式(5)所示。
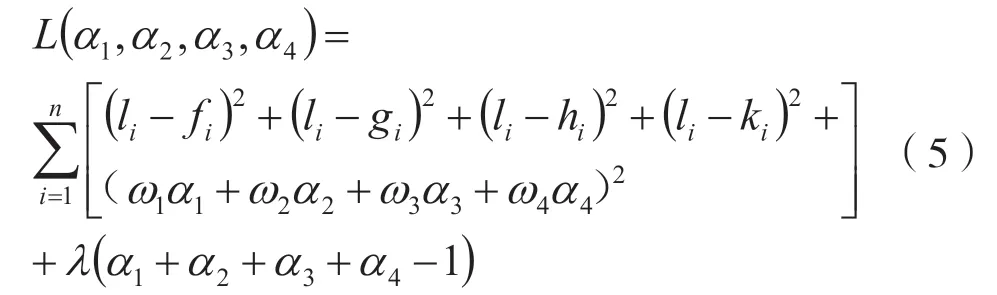
通过极小化损失函数来获取组合模型的最优权重。fi,gi,hi,ki分别为LR、SVM、BP 网络和XGBOOST 模型的预测得分值,且预测得分表示的模型在输出类别时对应的类别概率;λ为拉格朗日算子;αk为单模型对应的的权重,且k=1,2,3,4;ωi犯第I类错误率,且i=1,2,3,4;由于函数L(α1,α2,α3,α4)为二次凸函数,故有唯一的极值,即最小值,并利用python 求出最优权重,设为组合模型的类别预测概率,则结果如式(6)所示:
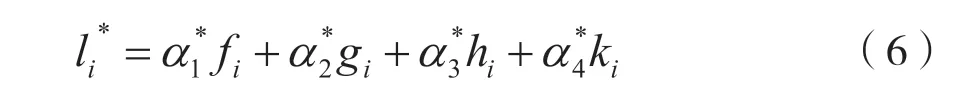
本文组合模型的流程图如图2 所示。

图2 模型训练流程
该方法的好处在于通过从两个方向对数据进行抽样,可以缓和抽样本身的缺点。此外,四次抽样的数据集均不一样,尤其对多数类样本的利用更加充分,丢失的信息也非常少。最后通过组合模型的构建,对单模型进行整合,使得最终的组合模型具有很好的效果。
3.3 模型评价
分别对单模型、投票模型和本文模型进行结果比较,从模型的F1 值、AUC 值以及对少数类样本的预测命中率三个指标对模型的预测结果进行评价,结果如图3 所示。

图3 各模型预测结果分析
图3 结果显示:在所有指标中,组合模型均表现出更好的结果,其中组合模型的F1 值提高了2.3%(相比较较其他最优模型,下同),对少数类样本的预测命中率提高了2.1%,AUC 值也提高了0.01。组合模型表现出更加稳定优越的性能,大大提升了客户流失的预测能力,对少数类(流失类)客户预测的命中率达到了78.7%,高于该企业之前模型达到的76.3%。
为了更直观的比较各模型的分类性能,本文引入了两类分类错误率,从另一方面对模型进行评价,结果如图4 所示。
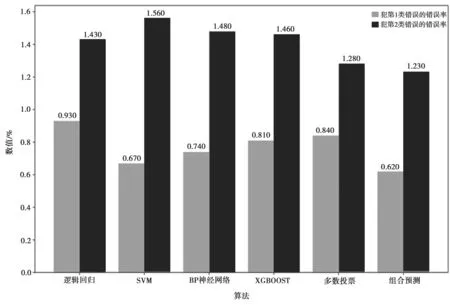
图4 各模型的两类分类错误率
图4 的结果显示,组合预测模型犯第一类错误的错误率仅为0.62%,远低于其他模型,犯第II 类错误的错误率为1.23%,也是优于其他模型。综合比较上述结果,可以发现本文的组合模型是合理有效的。
4 结语
现阶段下,客户流失已不仅仅存在于通信业,在其他行业同样是一个需要面临的问题。利用数据挖掘技术,通过对数据的认识,来发现新的信息,通过对信息的利用,进而帮助企业制定一些决策,挽留客户,达到盈利的目的。本文对模型的构建综合考虑了数据倾斜问题的处理和组合模型的构建,基于差异性选择了四种基分类器,在抽样数据集的基础上对基分类器一一进行训练,并将训练好的单模型进行加权求和,来构建本文模型。将组合模型用于真实的企业数据,实现隔月预测。并且结果显示,本文构建的模型表现出更加优越的效果,大大挽回了企业的损失,具有很大的现实意义。
