基于RNN的Webshell检 测研究
2020-07-17周龙,王晨,史崯
周 龙,王 晨,史 崯
1.武汉邮电科学研究院,武汉 430000
2.南京烽火软件科技股份有限公司,南京 210000
1 引言
Webshell是一种恶意代码,可用于网站管理,主要由PHP、asp、jsp等语言编写而成。一旦Webshell源文件被入侵者成功植入到服务器中,入侵者就可通过浏览器访问Webshell,获取相关操作权限,控制服务器,窃取重要数据。
Webshell可分为两类,一是小马,二是大马。小马,源文件代码量较少,通常是几行到几十行不等,其功能主要是文件上传、执行命令行程序等。大马,文件大小少则几KB,多则几百KB,甚至超过1 MB,功能复杂,包括执行命令行程序、上传文件、权限提升、端口扫描、数据库操作等。此外,大马要完成其功能还需要其他源文件的配合,协同作战,达到攻击目的。
2 相关工作
针对Webshell的检测方法,可分为3类:基于文件的检测、基于流量的检测以及基于日志的检测。
目前的研究集中于基于文件的检测,即直接分析源文件,提取文本特征,包括API函数名称、变量名称、信息熵、最长字符串、文件压缩比、重合指数、字符串长度差等。此外,还可针对具体脚本语言,根据其执行机制,提取编译结果的特征,比如字节码特征等。当前机器学习相关技术的应用也是学术界的研究热点,网络安全就是其中一个领域。正常web系统其源文件的编码命名规范有别于Webshell源文件。基于此想法,文献[1]提出将余弦相似度应用于Webshell检测,通过比较不同文件的余弦相似度,以及匹配特征关键词来判断Webshell,但是漏报率和误报率较高。文献[2]针对PHP源文件,进行语法分析,将生成的文件指纹用于Webshell检测,再进一步进行污点分析。该方法依赖于预先设定的样本库,且准确率较低。文献[3]将MLP(多层感知机)应用于检测Webshell,将源文件编译之后,根据TF-IDF提取Bi-Gram特征,此方法,需要将源文件预先编译,且准确率较低。文献[4]将MLP与word2vec相结合,提取100维词向量,来检测Webshell,在验证集上实现了平均准确率98.6%,取得了较好的效果,但是依赖于word2vec的预先训练好的词向量。此外,文献[5]将神经网络应用于获取样本的文本向量,再结合以SVDD(Support Vector Domain Description,SVDD)算法来检测Webshell,误报率较高。国外也有关于基于文件的检测研究。Wrench P M等人[6]提出了解除混淆,基于聚类的方法对PHP程序设计语言编写的Webshell源文件进行分类。而Tu T D等人[7]提出一种基于最优阈值的算法检测Webshell。
基于流量的检测,相对基于文件的检测而言,研究较少。赵运弢等人[8]分析了基于流量的检测方法,指出通过网络流量负载,提取具有明显攻击倾向的关键词来检测Webshell。文献[9]结合关键词、机器学习算法和手动校验,先匹配关键词,再使用机器学习算法检测关键词匹配之后的样本,最后手动校验。此方法严重依赖于校验人员的经验。
基于日志的检测,一般情况下针对系统日志信息进行统计分析。文献[10]针对http行为日志进行统计分析,对比分析了几种常规机器学习算法检测Webshell的性能。文献[11]利用日志数据,结合特征匹配和页面关联分析,来检测Webshell。
目前,关于Webshell的检测方法,常用的机器学习算法,比如SVM、KNN、MLP等,不能提取深层次的特征,存在准确率较低、误报率和漏报率较高等不足。基于特征匹配的检测算法,受限于特征,不能有效检测出Webshell。而深度学习方法则可以很好地解决此类问题。鉴于此,本文提出了基于RNN的Webshell检测方法。
3 基于RNN的Webshell检测
RNN[12](Recurrent Neural Network)是一种深度学习方法,具有循环结构,被广泛应用于语音识别、机器翻译、文本处理等领域。RNN中的循环结构,有多种选择,本文选取GRU(Gated Recurrent Unit)。GRU是LSTM(Long Short Term Memory)[13]诸多变体中的一个,在很多领域都得到了大量的使用。
本文Webshell检测方法的处理流程见图1。传统的Webshell检测方法多是将提取的样本的各种特征表示成一个向量,包括信息熵、重合指数、文件压缩比等特征,再使用机器学习算法分类。即使提取样本关键词,也将每个关键词对应一个特征,统计该关键词的词频等。而本文则从关键词集来近似样本的角度,通过提取关键词,使用样本对应的关键词集来近似表示样本,排除了样本中的无用噪声,在此基础上使用RNN对样本建模。
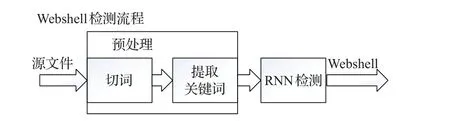
图1 Webshell检测流程
3.1 数据预处理
预处理是对源文件进行处理,以提高效率和识别准确率。预处理工作包括切词、提取关键词等。
切词,对文本数据进行切分,得到具有一定实际意义的词。
提取关键词,出于效率的考虑,以及并不是每个词都有助于识别,由此,需要对切词结果进行取舍。
总体上来说,源文件中的每一部分,都是为程序实现相关功能服务的,相辅相成。程序代码用来实现其功能,而注释是对程序代码的补充,依赖于具体程序而存在,以提高可读性,以及记录重要信息。不同的源文件,注释不尽相同。因此,在切词之前,保留源文件中的所有信息,包括注释等。
3.1.1 切词
切词,是根据某种规则对文本文件中的文本进行切割。程序代码是由自然语言编写的,因此,除了正常的英语之外,还可能存在其他语言,比如中文等。不同的语言,切词规则不同,英语是根据空格进行切分,中文是根据相关语法、语义等信息来切割。
鉴于PHP源文件中有英语和中文,以及大量的运算符和标点符号。中文字符一般作为注释或者变量值,数量远远少于英文字符。而英文字符是程序代码的主体部分,具有实现相关功能的作用。
因此,采用以非字母和非数字字符作为分割符来切分源文件。切词之后,存在大量的各种字母和数字字符串,包括单个字母、单个数字、字母组成的字符串、数字串等,这些字符串可能是变量名称、函数名称等。字符串字符长度范围变化较大,从1到1 000不等,甚至少量字符串超过1 000个字符。
按照上述方法对整个数据集切词,统计分析发现,约95.02%的字符串长度小于25,其中小于25个字符的字符串数量情况见图2。
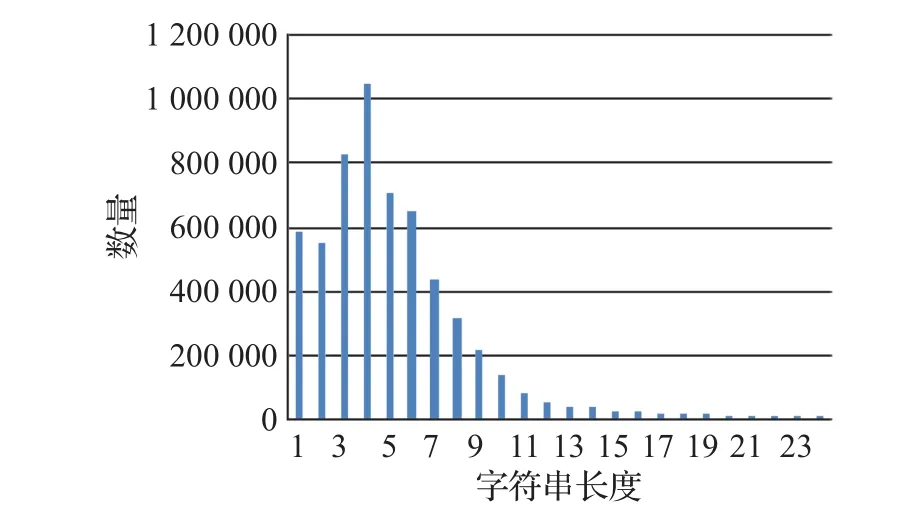
图2 不同长度的字符串数量
从图2中可见,字符串主要集中在长度小于15的短字符串。对于长度为小于4的字符串一般是没有实际意义的变量名或变量值的一部分,几乎在每个样本中都会大量出现。而字符串长度大于等于15的字符串大多是经过编码和加密处理之后的字符串,此类字符串词频极低,且对源文件几乎没有区分能力。因此,只保留字符串长度介于3到15之间的字符串。
3.1.2 提取关键词
由于各个源文件实现的功能有差异,导致源文件的大小不一。即使这些源文件实现的功能相同,但由于编写人员之间的差异性,包括编码习惯不同、编码水平差异等,其文件大小也不同。关键词提取,极大地减少了模型训练时间,在一定程度上屏蔽了编码人员之间的差异性,均衡样本之间字符串数量差异。
本文采用TF-IDF算法来提取关键词。TF-IDF算法是基于词频和逆文档频率。通常情况下,对于词频越高的词,其越能表示文本的信息,对分本的区分能力则越强。而逆文档频率越高,该词出现过的文档越少,对文本也有很好的区分能力。因此,TF-IDF算法偏向于选择词频高且出现过的文本少的词。
正常源文件和Webshell源文件,因实现的功能有差别,调用的API函数不同。正常源文件,总体上调用了几乎所有的API函数,而Webshell源文件中调用的主要是系统函数,包括文件操作、执行命令行程序等。对于变量名称,正常源文件一般是见名知意,可读性强,相比而言,Webshell文件这种特征不明显。因此,TF-IDF算法可有效地用于关键词提取。TF-IDF算法提取关键词示例见表1。
3.2 模型结构
本文使用的GRU参考于文献[14],GRU是对vanillaLSTM[15]复杂结构的简化,LSTM结构见图3,GRU结构见图4。

表1 关键词示例
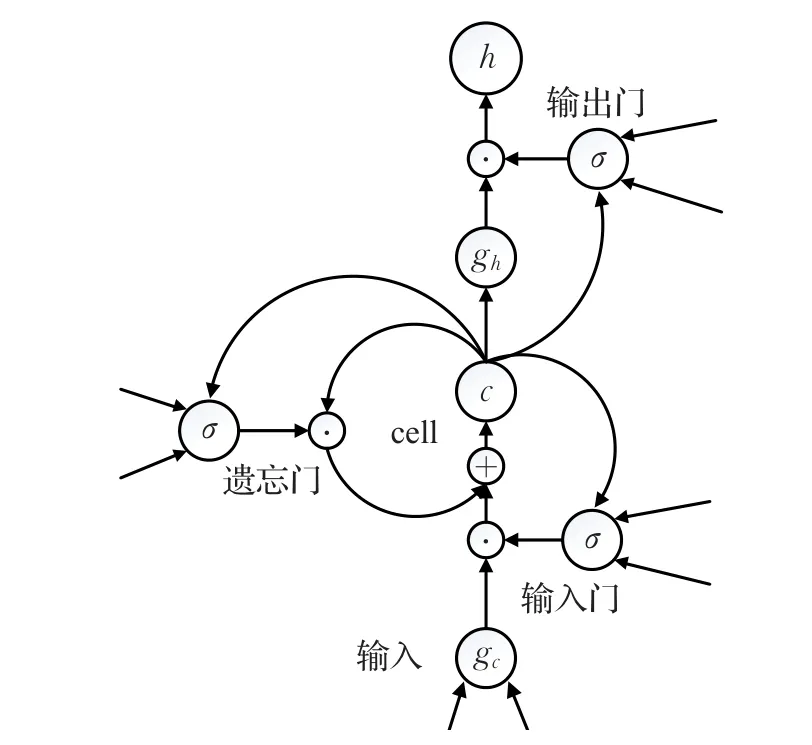
图3 vanilla LSTM结构图
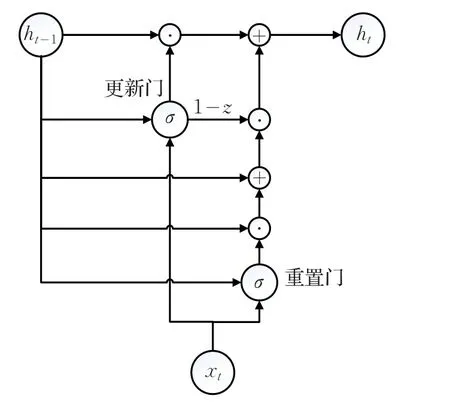
图4 GRU结构图
原始的LSTM中有3个门,输入门、输出门、遗忘门,而GRU只有更新门(update gate)和重置门(reset gate)2个门。此外,LSTM有cell状态的循环更新,而GRU中则去掉了cell,取而代之的是更多的直接依赖于GRU的输出h的加法和乘法运算。
GRU结构中信息流向见方程(1)~(4)。其中重置门和更新门计算方式见方程(1)和(2),可见两个门都依赖于上一时刻的输出和当前时刻的输入,两者之间是加法关系。GRU的输出计算方式见方程(3)和(4),两个门通过其值域限制了上一时刻信息的通过量,即上一时刻的输出,因为门的存在部分信息流向当前时刻的输出,而剩余的信息则被当前时刻的输出丢掉。另外,方程(4)是对中间状态和加权平均,根据门的取值偏向于两者中的一个。重置门的计算方程:

更新门计算方程:

GRU输出计算方程:

其中,符号⊙表示对应元素相乘,x表示输入,h表示某时刻的输出,t表示时间,取值范围[1,T],l表示层,取值范围[1,L],W,U分别表示对应的权值矩阵,σ是sigmoid函数,值域为[0,1],分别对应于各个门。
从方程中可见,GRU的相邻时刻的输出联系紧密,上一个时刻的输出贯穿了当前时刻的输出的整个计算流。
一般情况下,对于这种分类问题,通常是取RNN的最后一层的最后一个时刻的输出,即hLT。而多层RNN的每一层都提取不同的特征[16],简单地使用最后一层的特征,利用的信息量较少。因此,本文利用每一层的特征表示,即将每一层的最后时刻的输出hlT合并,见方程(5),然后通过一个线性映射到一个特征向量hG,维度与hl T相同,矩阵W是线性映射的系数,见方程(6)。

3.3 实验参数设置
实验使用的RNN结构由2层GRU构成,其隐层单元数量取200,见图5。经过多次迭代,多层GRU的每层的最后输出映射到一个向量,该向量通过一个全连接层映射到一个2维向量,通过一个softmax函数输出样本所属类别的概率。实验采用Adam[17]优化算法,学习率初值取0.001,每1 000步指数衰减,衰减比率取0.8。损失函数选择交叉熵,为防止过拟合,选择L2损失,系数取0.001。
在RNN模型之前还有一个词嵌入层,用于将词映射成词向量,参数是一个随机初始化的矩阵。针对预处理之后的训练集,建立一个词表,将所有词加入到词表,若某个词不在词表中,则加入到词表;反之,不作处理。每个词表中的词都有一个唯一的索引。通过词嵌入层,可将样本中词序列根据词索引映射成一个词向量序列,词的索引对应于矩阵行号。该矩阵初值每个元素服从0均值,方差为1的高斯分布。

图5 网络结构图
4 实验
4.1 数据来源
实验数据都来自于Github,其中Webshell样本是在GitHub中搜索Webshell,取前6个搜索结果,取其中的PHP源文件,而正常样本是在GitHub中搜索web,编程语言选择PHP,排除其中Webshell相关搜索结果,选择前50个,取其中的PHP源文件。所有样本都是PHP源文件,数量情况见表2。

表2 各类样本数量及占比
样本总量为1 307+11 746=13 053个,由表2可知,Webshell样本和正常样本之比接近1∶10。
4.2 数据集划分
将数据集划分成测试集、训练集,具体情况见表3。
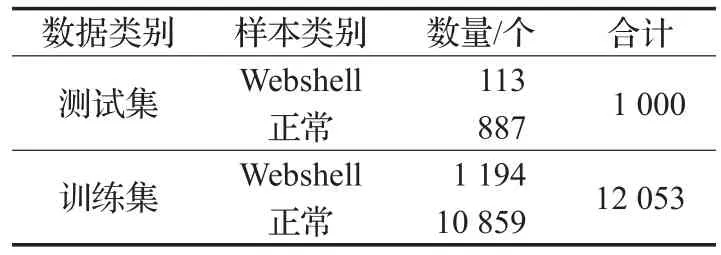
表3 各数据子集样本数量
表3中测试集用于最后测试模型在未知样本的情况下的预测性能,而训练集又进一步划分为2个子集,用于模型的训练和验证。由于数据集中Webshell样本和正常样本之比接近1∶10,因此,随机过采样至1∶1。
4.3 评级指标
Webshell的检测是个二分类问题,选择准确率、漏报率、误报率3个指标来综合评价算法的性能。相关符号表示见表4。
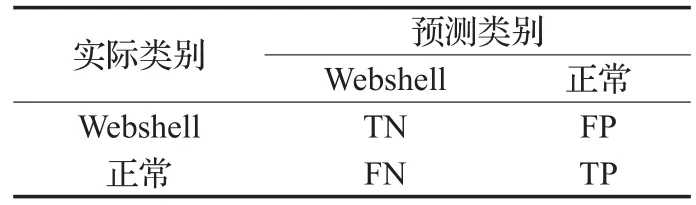
表4 实际类别和预测类别符号标记
准确率(Accuracy,Acc),正确分类的样本比例,方程如下:
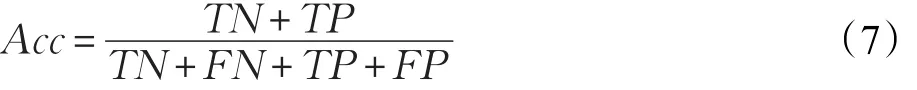
漏报率(Rate of missing report,Rmr),在实际是Webshell的样本中,被预测为正常样本的比例,方程如下:

误报率(False alarm rate,Far),在预测为Webshell的样本中,实际是正常样本的比例,方程如下:

4.4 实验结果
本文主要从算法的角度来评价Webshell的检测性能,对比分析了不同算法对PHP源文件的检测性能。
对于GRU(本文方法)、SVM、GBDT(Gradient Boosting Decision Tree)和CNN 4种算法,训练10 000步,每种算法都取验证集上准确率最高的模型参数,其中GRU验证集准确率为99.34%,明显要优于其他3种算法。
针对测试集中的未知样本,Webshell样本113个,正常样本887个,4种算法的具体检测情况见表5。

表5 测试集检测结果
综合来看,针对未知样本,GRU明显优于其他3种算法。GRU的分类准确率明显高于CNN、GBDT、SVM。虽然GRU的误报数量多于GBDT达23个,但是漏报数量明显低于GBDT,并且GRU的准确率为97.4%,高于GBDT约4%,误报率高于GBDT约2%。其中CNN中所使用的卷积是5×5,提取文本的局部特征,可能由于数据本身的字符串数量不同,以及提取关键词之后,又不同程度地丢掉了信息,导致根据从数据中提取的特征不能有效区分Webshell。GRU将文本当作序列数据来处理,提取样本的顺序特征,并结合不同层的不同特征,即使预处理丢掉了较多没有实际意义的字符串和对文件区分能力较弱的字符串,包括少量的变量名称、较多的变量值,以及函数的部分名称等,但是保留了可用于区分正常文件和Webshell文件的字符串。因此,可有效识别出Webshell,且识别率最优。
以上实验结果,TF-IDF提取了每个样本的200个关键词。可通过调整字符串长度取值范围来为关键词提取提供更多的字符串,增加关键词数量来减少每个样本预处理丢掉的信息,减少原始样本和近似样本的差异,但是增加关键词数量,模型的训练时间会延长。
5 结束语
本文提出的一种基于RNN的Webshell检测方法,采用GRU网络结构,有效地解决了Webshell的检测。对样本的主要成分PHP程序代码切词,根据TF-IDF算法提取关键词,关键词保持原始顺序不变。实验结果表明,在准确率、漏报率等指标上,该方法要优于其他检测算法,比如CNN、GBDT、SVM等。但是,误报率还有提升的空间。
在下一步的研究中,可提取更多的关键词,结合BiRNN(Bidirectional Recurrent Neural Network),提取样本数据两个方向上的特征。此外,切词对Webshell的检测结果有重要影响,需要调整切词方法,使得切出来的词具有实际意义,进一步提升算法的检测性能。
