改进的多层感知机在客户流失预测中的应用
2020-07-17夏国恩张显全
夏国恩,唐 琪 ,张显全
1.广西师范大学 计算机科学与信息工程学院,广西 桂林 541000
2.广西财经学院 工商管理学院,南宁 530000
1 引言
当代社会,随着各行业的市场趋近于饱和,行业之间的竞争愈发激烈,企业家开始意识到,减少老用户的流失应该作为公司的首要目标[1]。客户保留策略主要针对高风险的潜在流失客户,改善其现有服务,降低其流失可能性。另外,经研究表明,吸引一个新用户所需的成本远高于保留一个老用户的成本[2]。因此,及时并准确地识别潜在流失客户对于企业降低成本是至关重要的。
客户流失预测是客户管理关系中的一个重要组成部分,如图1所示,包括业务分析、数据分析、数据预处理、建模、评估和部署[3]。本文所关注的是客户流失预测的建模过程,该模块通过构建合适的机器学习算法拟合客户历史数据,来推断客户未来某个时期的特定状态。企业通过预测模型可以精准地识别存在流失风险的用户,及时制定有针对性的营销策略,挽留这部分客户。

图1 客户流失预测流程图
自20世纪90年代以来,客户流失预测的研究主要分为两个方向。第一个方向:研究者通过构造更加复杂的分类模型,来不断提升模型预测的表现及泛化能力。2008年夏国恩等人[4]提出了基于支持向量机的客户流失预测模型,该模型在预测精度方面表现较好,但缺乏可解释性。Huang等人[5]于2014年提出了可理解的支持向量机,该模型不仅在精度方面表现优异,而且通过构建朴素贝叶斯树,可以精准地分析客户流失的原因。文献[6]使用粒子群智能优化算法来代替多层感知机中的梯度下降优化算法,该模型避免了神经网络陷入局部最优的问题,大幅提高了预测精度。文献[7]使用遗传算法来进行建模并加入了利益最大化准则,在提高模型预测表现的基础上,还为企业选择利益最大化的方案。文献[8]提出了使用CUSUM算法构建自动化流失报警系统,利用当前与最近的过程数据来检验过程均值中不大的变化或变异性,累加样本偏差,在超过设定阈值时自动报警。
第二个方向:管理者通常想了解客户流失的真正原因,以此来改善企业的服务质量,避免产生更多的流失客户。2014年Verbeke W等人[9]通过社交网络分析来划分客户群体,针对不同的客户群体使用不同的分类模型,既提高了预测表现,又分析了不同社交群体的流失原因。2017年Amin A等人[10]使用穷举法(EA)、遗传算法(GA)、覆盖算法(CA)与LEM2算法(LA)这四个规则生成机制来提取客户历史数据中的隐藏准则,提取并组合成有用的客户特征。文献[11]使用了Logistic回归与决策树的混合算法来构建预测模型,该算法在预测表现与可解释性上都较好。文献[12]提出了一种基于帕累托多目标优化的特征组合方法,提高了对特征扩展空间的理解。
近些年,由于GPU运算速度的提升、数据量的不断增长和模型架构的优化[13],深度神经网络在计算机视觉[14]、语音识别[15]和机器翻译[16]等方面取得了巨大的进步,并且准确度远高于大部分传统模型。在客户流失预测领域,深度神经网络模型如多层感知机的应用大幅提高了模型的准确率和时效性,然而与图像、语音等非结构化数据不同的是客户数据中含有大量离散属性,这些离散数据是无法被神经网络拟合的,这就使得多层感知机不能充分发挥其优势。
针对上述问题,本文将分别使用堆叠自编码器与实体嵌入方法,对传统的多层感知机模型进行优化,并运用于客户流失预测模型,解决了one-hot编码后数据维度过高及数据稀疏带来的计算消耗等问题。
2 预备工作
2.1 离散属性与one-hot编码
离散属性指的是结构化数据中具有有限或无限可数个值,可以使用或不使用整数表示的属性,包括序数属性、二元属性和标称属性。例如,使用1,2,3,4来表示客户的职业(标称属性):教师、牙医、程序员和农民,自然不能说农民是教师的4倍或者教师加程序员等于农民,这些表征数字仅仅是名义上的数字,不具备实际的意义。
相对于传统机器学习算法来说,深度神经网络能够更好地拟合连续型数值函数[17]。然而,在客户流失预测中,用户数据中的离散特征几乎不存在连续性,极大地影响了损失函数的收敛,如果只是简单将这些离散数据用整数表征,那么神经网络的效果自然不理想。通常情况下,为了解决上述问题,通常使用one-hot编码来处理离散数据,如{性别:{男,女,未知}}编码为{男性{100},女性{010},未知{001}},但这种方式存在三个弊端:第一,在样本量较大的情况下,one-hot编码会产生大量稀疏数据,这会影响分类器的准确度;第二,完全独立地处理离散属性中不同的值,忽略了不同值之间的内在关系[18];第三,若离散属性或某些离散属性值过多,容易造成维度灾难。
2.2 多层感知机
多层感知机(MLP)是一种相邻层之间的神经元节点全连接,而同一层内的神经元节点无连接的神经网络模型。如图2所示,样本的训练数据由输入层输入,通过一个或多个全连接层,每一个全连接层中的神经元能对原始数据进行拟合,最后由输出层将数据输出,使用输出值与样本标签来构建损失函数,通过反向传播的梯度下降算法[13]迭代降低损失函数并更新模型的参数,使损失函数达到最小值,此时的多层感知机模型就具备了精确拟合样本特征的能力。

图2 多层感知机
2.3 堆叠自编码器
堆叠自编码器[19]是一种能将高维数据以低维形式表征的神经网络模型,该模型能有效地降低数据维度并保留绝大部分信息,相比于单层的自编码器,其保留的数据信息更多。如图3所示,数据由输入层输入,经编码层编码后,在隐藏层以低维向量表征高维数据,再通过解码层解码,最后由输出层输出,与传统神经网络模型不同,自编码器并不使用样本标签来构造损失函数,而是使用输入的样本数据与输出值来构造均方差损失函数:

其中,xi为第i个样本的输入数据,outi为第i个样本的输出值,γ为模型参数,m为样本个数。通过多次迭代降低损失函数,使模型输出值尽可能与输入数据相同,那么隐藏层中的向量就是样本数据的低维表征形式。

图3 堆叠自编码器
2.4 实体嵌入
实体嵌入[20]在神经网络中最早用于相关数据的表征,时至今日,应用范围越来越广泛,例如词嵌入[21]已经在自然语言处理领域占有重要的地位。实体嵌入方法不仅增加同一属性内不同值之间的相关性,而且在嵌入空间中不同的嵌入向量若相关性越高,则距离越近,反之则越远。对于嵌入前后的向量通常使用三元组(h,r,l)表示,h代表高维原始数据,l代表嵌入后的低维表征向量,r代表两个向量之间的联系。如图4所示,对于高维稀疏向量,将其映射到低维空间:

其中,xj为第 j个离散属性进行one-hot编码后的向量,Xi为映射后的向量。假设tj为第 j个离散属性的值的个数,则xj的维度为tj,进行映射后的向量Xj维度在1到tj-1之间。通过映射入低维空间,每一个离散属性的编码向量都降低了维度,并且增加了属性值之间的交互作用。

图4 实体嵌入
3 客户流失预测模型架构
3.1 多层感知机模型
在本文的客户流失预测模型中,如图5所示,使用单层网络模型,其全连接层节点使用Elu激活函数:

其中,α为超参数,需要调试。相比于Sigmoid、Relu等激活函数,Elu函数能有效解决梯度弥散和无法携带负值信息的问题[22]。输出层只有1个神经元,采用sigmoid激活函数:

该函数能将输出值压缩在0到1之间,当预测值大于等于0.5时,意味着该客户为潜在流失客户;当值小于0.5时,则该客户为正常客户。在反向传播过程中,使用Adam梯度下降算法[23]最小化交叉熵损失函数:
其中,m为样本个数,yi∈{0,1}为第i个样本的标签值,1代表该客户属于流失群体,0代表该客户属于非流失群体,predi∈(0,1)为第i个样本的预测值,θ为模型参数,a为任意自然常数。以单个样本为例:当yi=1时,若要使损失最小,则 predi→1;当yi=0时,若要使损失函数最小,则predi→0。通过多次迭代,使得损失函数达到小值,模型的参数趋于稳定,输出值与样本标签尽可能相同,以此实现模型预测的能力。

图5 多层感知机模型
3.2 融合堆叠自编码器的多层感知机模型
一般来说,堆叠自编码器用于数据的预处理,但在本文中,为了将低维表征数据与预测模型产生关联,将自编码器对于编码数据的低维表征过程与多层感知机模型的反向传播过程同时进行,目的是在保留离散数据绝大部分信息的同时,将高维的稀疏数据以一种低维的形式表征,并用于多层感知机的优化过程。

图6 融合堆叠自编码器的多层感知机模型
如图6所示,首先,将进行one-hot编码后的离散数据放入堆叠自编码器处理,得到低维表征向量:

其中,w2与b2分别为堆叠自编码器中隐藏层的权重与偏移量。然后,将数值型数据与低维表征向量合并:

最后,使用多层感知机处理合并后的向量:

并使用sigmoid函数将其概率化输出,该模块构造的损失函数及迭代优化算法与基于多层感知机的预测模型相同。
在训练的过程中,同时使用Adam优化算法迭代优化堆叠自编码器模块的均方差损失函数与多层感知机模块的交叉熵损失函数。这两个过程通过训练逐渐达到平衡,既实现了数据降维、解决了数据稀疏问题,也在一定程度上增加了离散数据间不同值的相关性。堆叠自编码器模块的编码层,隐藏层和解码层均使用sigmoid激活函数,目的是使低维表征后的数据尽可能接近于预处理后的数值型数据,以免影响模型分类效果。
3.3 融合实体嵌入的多层感知机模型
相比于传统感知机,融合了实体嵌入的模型并不直接将离散数据的编码向量与数值型数据合并输入多层感知机模型,而是如图7所示,首先在每个编码层后分别添加了一个嵌入层,即将k个离散属性编码后的向量进行映射:

其中,xj代表第 j个离散属性的one-hot编码,该过程使得每一个嵌入层都是原编码向量的复杂组合形式。然后,将嵌入后的所有表征向量与数值型数据合并:

最后将组合的特征向量放入多层感知机训练,该模块的构建方式与上述的两个模型相同。
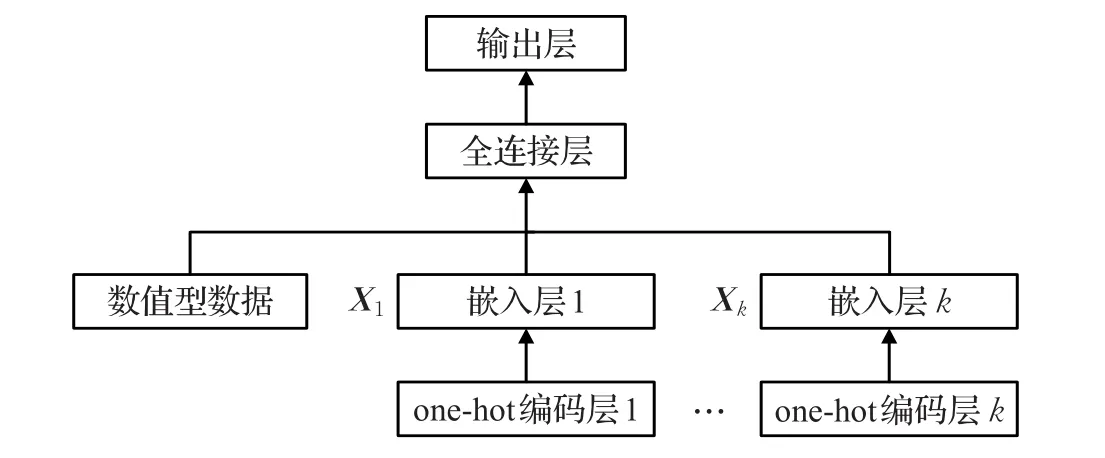
图7 融合实体嵌入的多层感知机模型
该模型在训练的过程中通过迭代使用反向传播能够同时优化实体嵌入过程与多层感知机模块,利用神经网络的分布式表征能力,将编码后的特征向量转化为低维表征向量,既解决了数据稀疏的问题也加强了离散数据不同值之间的交互作用。在实际操作中,Xj的维度,即嵌入层神经元的个数,对于二元属性,维度值取1,而其余嵌入层的维度,则需要在实验中不断地调试来确定。
4 对比模型
本文的对比模型使用CART、KNN、朴素贝叶斯和SVM,这些模型在客户流失预测中得到了广泛的应用,并且在准确性和健壮性等方面效果较好。
4.1 分类回归树
CART是一类决策树算法,采用二叉树结构,在分类预测中,通过计算基尼系数选出最优特征及特征值,来划分数据集并建立左右结点:

其中,k表示第k个类别,pk为第k个类别的概率。
相比于ID3和C4.5,CART的计算复杂度较低,且实行剪枝策略,能有效解决过拟合问题,提高模型的泛化能力:

其中,α为正则化参数,Cα为损失函数,C(T)为训练数据的预测误差, ||T为子树T的叶子结点数。
4.2 K-近邻
在分类预测中,KNN算法通过计算闵可夫斯基距离,来选择最接近预测样本的k个样本的多数类别作为预测值输出:

其中,xp、xq为样本中的两个样本,n为样本的属性个数。
4.3 朴素贝叶斯
朴素贝叶斯是一种生成式机器学习分类算法。该算法首先计算样本标签与样本属性之间的联合概率密度,再通过贝叶斯公式计算条件概率密度,最后选择概率最大的类别作为预测输出:
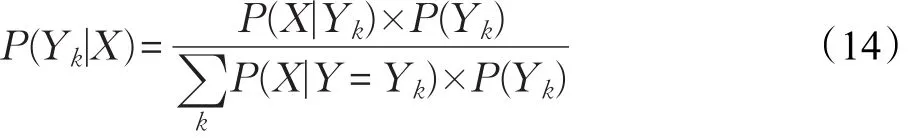
其中,k表示第k个类别。
4.4 支持向量机
SVM虽然诞生时间不久,但凭借其在分类精度和泛化能力方面的优异表现,得到了极为广泛的应用。
对线性可分的数据集来说,SVM首先构造带约束的优化问题:

其中,m为样本数,αi为拉格朗日乘子。通过SMO算法可以计算出α向量,进而得到切分数据集的最优超平面。然而,在现实中,数据集一般是线性不可分的,这时则需要通过核函数将低维不可分数据映射到高维可分空间,然后计算出最优的超平面,用来划分数据集。
5 实验结果及分析
5.1 实验环境
本文实验使用ubuntu18操作系统,工程软件为Jupyter Notebook。使用深度学习框架TensorFlow构建基于多层感知机的模型,机器学习库Sklearn构建对比实验。硬件为16核32线程2.1 GHzCPU(E5-2620),6 GB显存的显卡(Quadro M5000),64 GB内存。
5.2 数据集及数据预处理
本文实验使用两个不同的真实电信用户数据集:
(1)数据集1选自kaggle数据科学大赛。该数据集包含了7 043个样本,其中流失客户数为1 869,非流失客户数为5 174;属性个数为19,其中离散属性15个,数值属性4个。由于该数据集样本数较少,且流失客户数量远小于正常客户,所以属于非平衡型小样本数据集。
(2)数据集2选自kaggle数据科学大赛。该数据集包含了100 000个样本,其中流失用户数量为49 562,非流失用户数量为50 436;属性个数为100,其中有79个数值型属性和21个离散型属性。由于该数据集样本数较多,且流失客户数量与正常客户基本持平,所以属于平衡型大样本数据集。
5.3 评判指标及模型参数
对于二分类的预测模型来说,一般使用准确率(accuracy)、精准率(precision)、召回率(recall)和F1值(F1)作为模型评判的主要指标,公式如下:

其中,TP为正确划分为流失客户的样本数;TN为正确划分为非流失客户的样本数;FP为错误划分为流失客户的样本数;FN为错误划分为非流失客户的样本数。为了直观地分析模型优劣,实验使用了ROC曲线与PR曲线[24],其中ROC曲线纵坐标为TPR(正确预测的流失客户数与总流失客户数的比值),横坐标为FPR(错误预测的流失客户数与总流失客户数的比值);PR曲线的纵、横坐标分别为精准率与召回率。
在客户流失预测中,如果分类模型预测某一客户会流失,但实际上没有,这类错误是可以接受的。然而,如果分类模型预测某一用户会留下,但该用户却属于流失群体,这类错误是无法接受的。因此,对于流失客户数较少的非平衡型数据集1,最重要的指标则是召回率;对于均衡型数据集2,最重要的指标则是精准率和召回率。另外,考虑到预测模型的实效性,实验指标还增设了测试集的总拟合时间。
实验中的MLP,融合自编码器的MLP及对比模型的参数如表1所示,融合实体嵌入的MLP的部分嵌入层维数如表2所示。

表1 模型参数
5.4 实验结果分析
本文使用5折交叉验证进行实验,将测试集实验结果的平均值作为模型评判的标准,各指标如表3所示,ROC曲线与PR曲线如图8所示。
CART在两个数据集上的实验效果表现良好,即使是非平衡型数据集,也能很好地处理。总的来说,该算法擅长处理结构化数据,计算复杂度较低,在实效性方面有优势,但在处理大样本多属性的数据集时,如果样本中某些特征的样本比例过大,那么模型精度会受到较大的影响。

表2 部分嵌入层的维度
KNN通过计算欧氏距离来选择预测样本附近的部分样本,即划分客户群体,选择该群体中的多数类别作为预测值输出。这种方法等同于默认了样本各属性属于同一数据分布与范围,但实际上,每一个属性都有各自的数据分布与范围,仅仅通过计算欧氏距离所得到的客户群体是极为不准确的,特别是在属性值较多或者处理非平衡数据集的情况下,会极大地影响模型精度。另外,该算法计算量太大,导致模型时效性很差。
朴素贝叶斯通过先验概率和数据来得到后验概率,所以在给定输出类别的情况下,默认假设样本属性之间是相互独立的,但在实际中,这个假设是不成立的,各个属性之间必然存在相关性,所以一旦属性个数较多或者属性之间相关性较强,则分类效果会很差。另外,在处理非平衡型数据集时,该算法的表现较差。
SVM通过各类核函数将低维线性不可分的样本映射到高维可分空间,该算法在模型精度方面优势较大,但随着样本量的增加,核函数映射的维度会越来越高,这就使得计算量不断增加,大大影响了预测模型的时效性,所以SVM不适合处理大样本数据集。
在模型精度和时效性方面,使用GPU运算的神经网络模型有较大的优势。即使是处理深度神经网络所不擅长的小样本数据集,改进后的多层感知机模型也能很好地学习样本属性的内在特征。与传统的多层感知机模型相比,自编码器与实体嵌入解决了one-hot编码造成的问题,将高维编码数据向低维空间映射,降低了神经网络收敛于局部最小值的可能性,增加了数据之间的关联度,将离散属性以数值表示,改善了离散属性的度量方式,提高了各项评判指标。相比于自编码器对所有离散属性的编码数据进行映射,实体嵌入则是分别将每一个离散属性向低维空间映射,对数值间关联的表征能力更强,因此,其分类准确度更高。

表3 实验结果
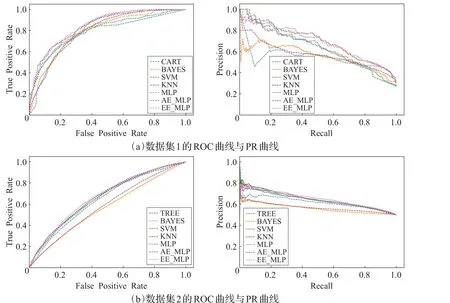
图8 ROC曲线与PR曲线
6 结束语
多层感知机模型在客户流失预测的应用中,由于用户数据存在大量的离散属性,使得模型无法很好地拟合数据,而自编码器和实体嵌入能有效解决这个问题,改进后的模型效果提升明显。然而,本文的研究依旧存在一些不足,未来的重点工作将包含以下两个方面:
第一,由于多层感知机能拟合数值型离散数据,所以在本文的实验中,只是对非数值型离散数据进行编码,而将数值型离散数据与非数值型离散数据以相同方式处理,是否能够进一步提高模型准确度是一个值得研究的问题。
第二,在实体嵌入的实验中,每个离散属性对应的嵌入层大小需要不断调试,如果数据集存在大量离散数据又或者每个离散属性包含大量的值,那么调试的工作量无疑是巨大的,因此,一个确定嵌入层大小的方法是至关重要的。
