基于符号规范化割的半监督学习与图像分割
2020-07-13刘先锋杨予丹
刘先锋,石 静,陈 明,杨予丹
(湖南师范大学 信息科学与工程学院,长沙 410081)
1 引 言
半监督学习(Semi-supervised learning,简称SSL)是机器学习的一个重要分支[1].SSL研究如何同时利用无标签的样例与部分监督信息改进学习性能.SSL的研究具有重要的实用价值,因为在实际应用中减少标记样本的使用能够大幅缩减人力、时间和资源的开销,从而降低生产成本[2].在过去的十几年时间里,涌现了许多基于图的SSL方法.基于图的SSL以监督信息为辅,用图来表达数据,通过对图的分析来完成学习任务.鉴于图的强大表达力以及关于图的成熟数学理论与庞大算法体系,这类SSL方法取得了大量成果[3].
基于图的SSL通常以非负权重的网络表达数据,基于图拉普拉斯来构建一个目标函数,将(弱)监督信息表达为目标函数的损失部分或者作为约束条件,通过优化该目标函数来训练学习器,从而预测出样本(簇)标签.图划分是在基于图的SSL上获得最多关注的一类图分析技术,典型的划分准则包括最小割、比率割、规范化割等[1].由于规范化割(Normalized cut,简称NCut)具有划分平衡性,在许多问题上(例如图像分割)具有较好的表现,因而获得了更多关注.对于类标签形式,基于图的SSL实际上是在图上将监督信息传播至未标记样本[1].自从Blum和Chawla[4]提出基于最小割法的SSL方法之后,相继涌现了比率割、规范化割等半监督方法[1].一些SSL算法假定(弱)监督信息可以表达为成对约束关系:必连和勿连关系,分别用于表达两(组)数据是否在同一个分组内.基于成对关系矩阵的图聚类模型能够自然地刻画这类成对关系,例如,Basu等人利用隐马尔科夫随机场(HMRF)表达必连和勿连约束[5];Kulis等[6]对成对约束进行了规范化处理以适应图聚类的比率形式,提出了经典的HMRF-半监督图聚类框架.
图像分割是数字图像处理、计算机视觉领域的基本问题之一,它是指根据图像的灰度、颜色、纹理等特征把图像划分为具有某种特性的若干区域.目前,在处理复杂和变化多端的现实世界图像上,尚无能够与人脑媲美的全自动分割算法.半监督分割利用box、划线等形式的提示信息来引导分割过程,一批典型的交互式图像分割方法以半监督NCut为内核.例如,Yu和Shi等[7]提出了可以处理必连约束的方法,Eriksson等[8]、Chew等[9]提出了可以同时处理必连和勿连约束的方法.
上述SSL方法需根据样例之间的关系预先构造图.这类方法通常采用无符号图(或称网络)表征数据,它用非负权重衡量节点之间的相似性,难以区分无关、消极/对立等关系.实际上,有许多真实复杂网络系统中本就包含着对立/消极关系,比如万维网、信任网络等[10].人们越来越意识到,边的符号属性在许多挖掘任务中体现了附加价值[11].对于非图型数据,在构图时引入边的符号属性,具有更强的表达力.缺失的边具有0权重,可能是由于两个节点的距离太远或者它们的特征具有极低的相似性,也有可能是它们本就相异、甚至相斥的.然而,无符号网络并不能区别对待这些情形,符号网络则可借助负边将所隐含的互斥关系显式地表达出来.
本文在符号网络的规范化割(Signed Normalized Cut,SNCut)基础上,提出了基于成对约束的半监督学习方法,并在典型数据集上验证了负边的附加价值.进一步的,将SNCut应用于半监督图像分割,展示了负边对分割效果的提升效果.为了提升边界对齐性,引入了马尔科夫随机场(Markov Random Field,MRF)正则化项,构建SNCut&MRF目标函数,并采用界优化思想和图割算法进行求解.实验结果表明,SNCut&MRF相比一些经典分割方法有更好的分割性能,在边界处表现良好.
本文的组织结构如下:第2节介绍了无符号网络与符号网络的规范化割;第3节在基于符号网络的规范化割基础上,提出了一种半监督学习途径,并在UCI数据集上进行了测试,验证了负边的附加价值;第4节将其应用于图像分割,进一步展示了负边的效应,并针对边界问题引入了MRF正则化项,提出了改进模型和相应的优化算法;第5节对本文所提出的方法进行了详细的实验分析.
2 规范化割
本节首先介绍了(无向的)无符号网络与符号网络上的规范化割,然后提出了基于符号网络的半监督聚类准则.与无符号图不同,我们以负边表达了勿连约束.这里,我们仅考虑2-way的划分问题.
2.1 无符号图的规范化割
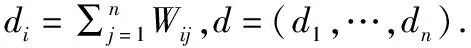
(1)
其中(X1,…,XK)∈I,I是分组指示矩阵取值空间,D=diag(d1,…,dn)为度矩阵,L=D-W为图G的拉普拉斯矩阵.
2.2 符号规范化割

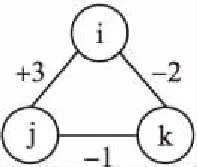
图1 符号网络示意
我们将符号网络上的规范化割称为符号规范化割(Signed Normalized Cut,SNCut).根据文献[12,13],SNCut定义为:
(2)
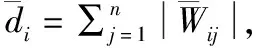
3 基于符号规范化割的半监督学习
NCut应用于标签预测问题时,将所有数据点视为图G上的顶点,构建数据点之间的权重矩阵W.在无符号网络中,权重大小是对结点间相似(或不相似度)的度量,无法同时表达相似性与相斥性.在许多的基于无符号网络的半监督学习方法中,结点之间的标签互斥性与缺失边通常均被处理为0权重,从而丢失了这种互斥信息.
3.1 基于符号规范化割的成对约束半监督学习
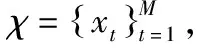
在无符号网络中,勿连约束所对应的连接权重为0,而缺失的连边也是0权重.这里,我们用负边相连cannotlink点对,显式地表达出了这种互斥关系,可以区分以上两种情形.通过构建符号网络,对χ的分类或聚类问题均可以转换为符号网络的划分问题来完成.
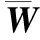
(3)
对上述目标的最小化,意味着最大化组内的正边权重之和且最小化组内的负边权重之和.也就是说,尽量使得必连的点对在同一组,勿连的点对不在同一组.与无符号网络相比,该目标显式地强化了勿连约束.
3.2 2-way符号规范化割的实验分析
我们从UCI数据库中选取了数值型属性的几个样本集,用于验证2-way符号规范化割在半监督学习上的有效性.表1描述了数据集的基本信息.部分数据集有少量缺失数据,我们对其进行了剔除.
表1 UCI数据集
Table 1 UCI datasets

数据集数据个数维数BreastcancerWisconsin(WBC)6999Haberman3063Sonar20860Ionosphere35134Jain3732Blood7485
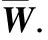
图2利用调整的RI指标(ARI)与互信息指标(NMI)来衡量聚类精度.这里,ML+Ncut即用M集合强化了必连约束,SNCut同时使用了M与C集合,从而出现了负边.从图上可以看出,使用M集合的表现略好于NCut本身.当引入负边后,SNCut的效果获得了显著提升.值得一提的是,在实验中我们观测到,在UCI的小数据集中,仅使用C集合的SNCut便可获得与SNCut几乎一样的效果.
4 基于符号规范化割的半监督图像分割
本节针对半监督图像分割问题,首先将图像映射为符号网络,然后利用谱松弛法优化SNCut,对图像像素进行聚类.对结果分析时,发现SNCut在目标边界处表现不够平滑,引入MRF平滑项以提升目标边界贴合度.
如图3所示,分别用两条线提示了前景与背景.本文通过将监督信息表达为成对约束从而构造加权符号图.假定划线所包含的前景像素点集为F,背景点集为B.在本文中构造M与C如图3所示,F与B上实线点对为M,F与B之间虚线点对为C.
将图像映射为图时,我们并不会为每两个像素建立边,因为过稠密的图会使得计算复杂性大幅度增加.此时,导致边权为0的因素,可能是两点颜色特征相似性低,也可能由于两点之间的空间距离过大.在无监督图像分割中,F与B的点对之间距离较大,权重很可能为0.然而,实际上它们是属于相斥的类别.引入辅助信息后,必连约束指示了颜色等特征的相似性极强,用强化的正边相连.勿连约束则表达了相异性,用负边连接勿连点对,从而将其与空间距离过大区分开来.
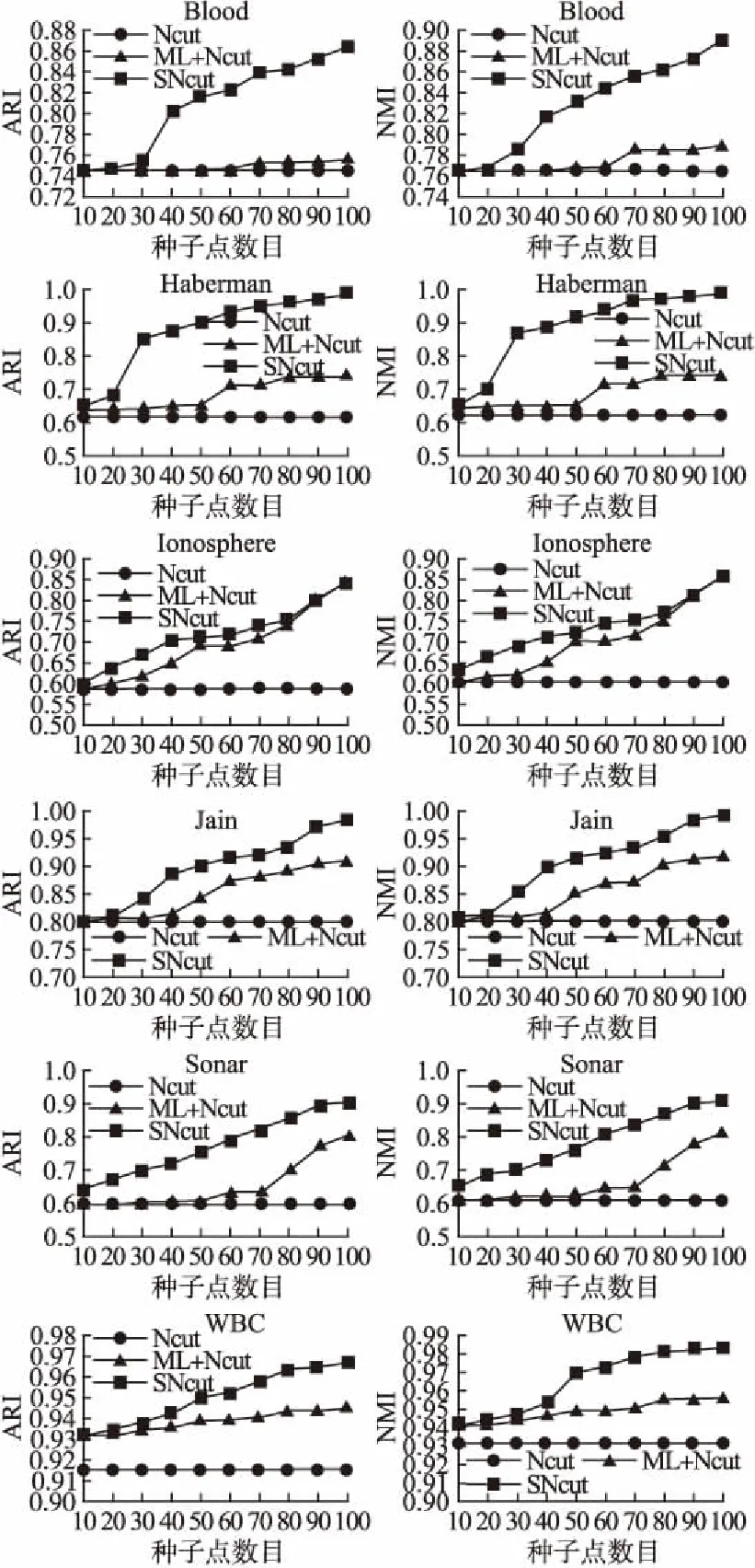
图2 不同种子点数目下的ARI与NMI

图3 监督信息的成对约束表示
4.1 基于符号图谱的半监督图像分割
我们首先构建无符号网络,然后引入监督信息,转化为符号网络.以某种方式构建非负权重矩阵W,满足Wij∈[0,1].在本文的实验中,采用了文献[13]的W生成方式.符号网络的权重矩阵构造如下:
(4)
其中,
⊙表示Hadamard乘积;βant、β为参数,它们的增大会引起负边.
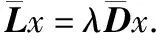

图4 不同约束下的分割结果图
4.2 利用MRF正则化子改进SNCut
考虑到SNCut的分割结果在目标边界处表现不够平滑,本文在其上引入了典型的MRF正则化项,以加强其边界对齐性.MRF将图像映射为随机场,图中每个像素点都与某个随机变量相关.而MRF中的每个随机变量只与其邻域的随机变量有关.MRF势函数作为正则化子已广泛应用于计算机视觉领域.本文使用可保证边界对齐的二阶Potts模型:
(5)
其中,二元因子F和N包含了相邻结点所组成的边f={pq}.[•]为艾弗森括号,Bpq是p与q的标签不连续时的罚值.
定义新的能量函数:
(6)
其中,常数γ为MRF项的相对权重.我们将此模型称为:SNCut & MRF.该目标函数不能使用谱方法求解,本文采用界优化思想[14]来构造式(6)的一个更易求解的辅助函数,在迭代过程中,利用图割算法求解该辅助函数,以逼近式(6)的最优解.式(6)的辅助函数为:
At(x)=
(7)
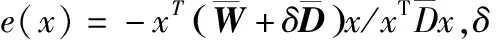
5 参数设置与图像分割实验分析
在MSRA1K数据集上实验,共1000张图片,每张图片均有人工标记真值图.为定量分析实验结果,采用四个评估指标进行衡量,分别为Error rate(ER)、F1-measure(F1)、Jaccard系数(JC)、修正的Hausdorff距离(MHD).若ER、MHD越小,F1、JC越大,则表示图像分割效果越好.
5.1 基于SNCut的半监督图像分割
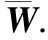
在图表中,ML、CL分别是指必连约束和勿连约束,对权重矩阵的构造采用了式(4),其中勿连约束会产生负边.式(4)中βant与β的不同取值对应不同的相似矩阵,对最终分割结果有较大影响.如表2所示,对βant与β统一取1、10、102、103、104、105、106,比较SNCut在各取值下的评价指标值.从对比结果可以看出,βant与β取值为100时,各项指标均值较优,故取βant=β=100.
为验证添加负边所带来的附加价值,图4和表3展示了4种方法的分割效果.ML+Ncut强化了同组约束,分割效果比Ncut强.SNCut和CL+Ncut都引入负边表征像素间相异性.表3前4行列出了基于以上四种算法的评价指标值.量化结果显示,SNCut表现最优,CL+Ncut次之,与未引入负边的ML+Ncut和Ncut相比,SNCut更接近真值图.相比添加正边,添加负边能带来更多的提升.SNCut在ML+NCut基础上,我们与ICCV2015的SSNCut进行了比较,该方法也可以同时处理必连与勿连约束,是一个较为新颖的谱聚类方法.分割图片与量化结果分别展示于图5与表3.总体上来说,SSNCut具有优势,尤其是在评价指标上表现较好.但是,本文所利用的SNCut则可以轻易的与其它正则化项相结合,而SSNCut的复杂谱分析过程则难以扩展.
表2 SNCut在βant与β各取值下的图像分割结果评价
Table 2 Image segmentation results evaluation of SNCut under differentβantandβ
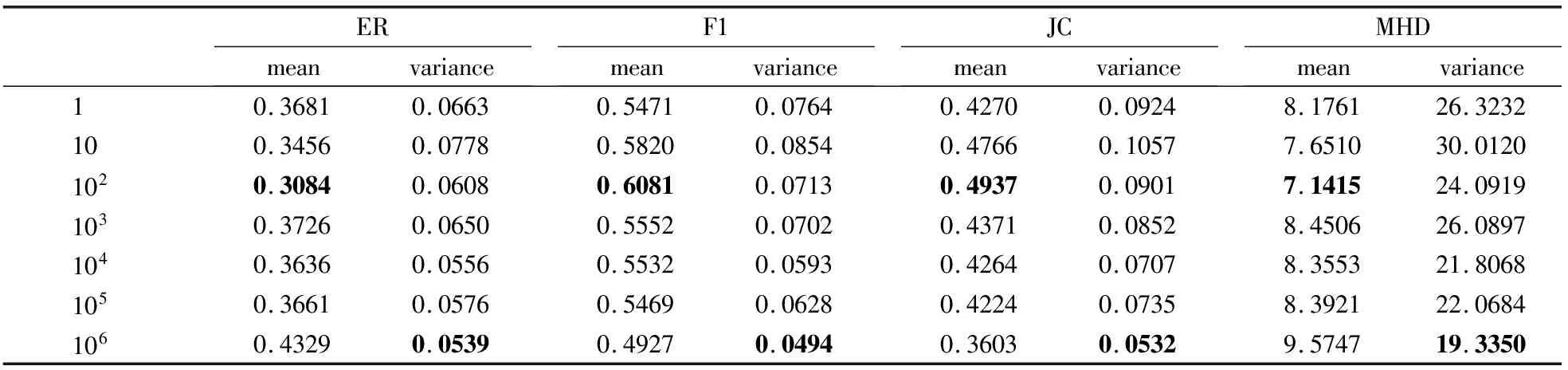
ERmeanvarianceF1meanvarianceJCmeanvarianceMHDmeanvariance10.36810.06630.54710.07640.42700.09248.176126.3232100.34560.07780.58200.08540.47660.10577.651030.01201020.30840.06080.60810.07130.49370.09017.141524.09191030.37260.06500.55520.07020.43710.08528.450626.08971040.36360.05560.55320.05930.42640.07078.355321.80681050.36610.05760.54690.06280.42240.07358.392122.06841060.43290.05390.49270.04940.36030.05329.574719.3350
5.2 基于SNCut&MRF的半监督图像分割
表3 分割结果的评价指标值
Table 3 Quality measurements of image segmentation results
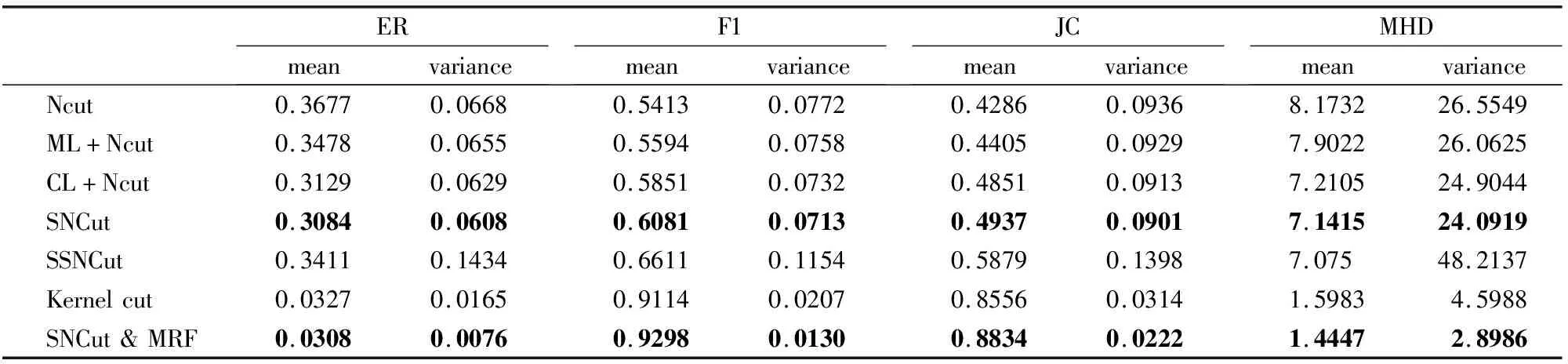
ERmeanvarianceF1meanvarianceJCmeanvarianceMHDmeanvarianceNcut0.36770.06680.54130.07720.42860.09368.173226.5549ML+Ncut0.34780.06550.55940.07580.44050.09297.902226.0625CL+Ncut0.31290.06290.58510.07320.48510.09137.210524.9044SNCut0.30840.06080.60810.07130.49370.09017.141524.0919SSNCut0.34110.14340.66110.11540.58790.13987.07548.2137Kernelcut0.03270.01650.91140.02070.85560.03141.59834.5988SNCut&MRF0.03080.00760.92980.01300.88340.02221.44472.8986
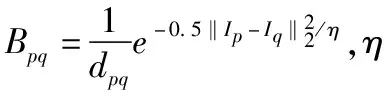
图5展示了几种方法的分割结果图.SSNCut与SNCut的分割效果相当,在前景边界复杂的图像上表现较差,不能很好地识别边界位置.但是,SNCut比SSNCut的优化过程更为简单.在加入MRF项之后,SNCut & MRF能够显著提升边界对齐性.在分割结果图上,SNCut & MRF与Kernel cut效果相当.表3的后几行则可以量化比较三种算法的优劣.由于Kernel cut没有很好的利用监督信息,在评价指标上,劣于SNCut & MRF.表4中,我们列出了图5的几张图片所需的计算时间,以秒为单位.括号(without)是指不包含超像素生成的时间.由于SSNCut与SNCut均以超像素为结点构建无符号(符号)网络,即便调用了特征值函数,其所需时间仍然较少.其中,SNCut所需的时间则更少.SNCut & MRF与Kernel cut均比前两种谱方法的时间长,因为它们迭代地使用了最大流/最小割算法.SNCut & MRF以负边表达半监督信息,在程序中多执行了约束信息的处理代码,因而比Kernel cut的执行时间稍多.

图5 分割结果比对
表4 典型图片的计算时间
Table 4 Runtime of different algorithms
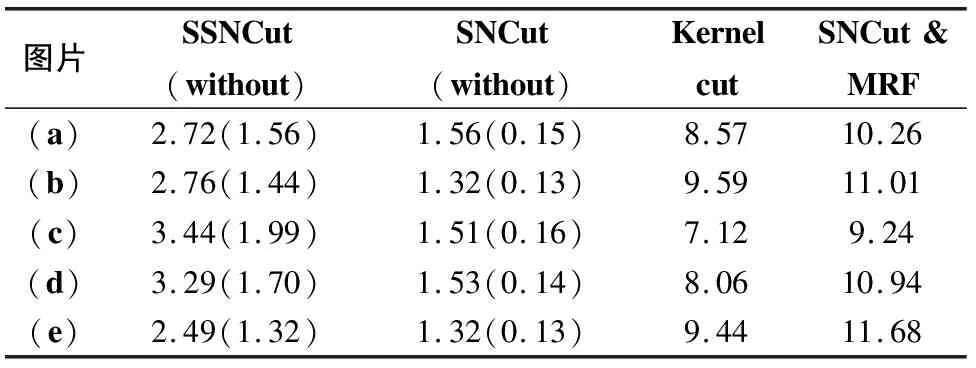
图片SSNCut(without)SNCut(without)KernelcutSNCut&MRF(a)2.72(1.56)1.56(0.15)8.5710.26(b)2.76(1.44)1.32(0.13)9.5911.01(c)3.44(1.99)1.51(0.16)7.129.24(d)3.29(1.70)1.53(0.14)8.0610.94(e)2.49(1.32)1.32(0.13)9.4411.68
6 结束语
本文基于符号网络上的规范化割(SNCut),提出了成对约束的半监督学习算法.将SNCut应用于UCI数据集与图像分割,验证SNCut用于半监督学习问题的有效性.SNCut引入少量负边,聚类性能有明显提升,但在分割问题上目标边界处表现不理想.为了进一步提升分割精度,将SNCut与MRF正则项结合,并利用图割法迭代优化.下一步将本文方法应用于分组数K>2的其它数据集以及多相分割,以进一步验证其有效性.同时,引入一些预测算法,获得更多的负边,进一步提升负边的价值.
