基于ANTLR的AltaRica 3.0模型平展化算法设计与实现
2020-07-13王立松
陈 朔,胡 军,王立松
1(南京航空航天大学 计算机科学与技术学院,南京 211106) 2(软件新技术与产业化协同创新中心,南京 210007)
1 引 言
目前随着工业系统的规模不断增加,系统故障往往会引起重大的生命和财产损失[1],因此安全关键系统的安全性和可靠性分析就显得尤为重要.但是传统系统工程无法很好的解决复杂安全关键系统的模型构建和分析问题[2],基于MBSA(Model-Based safety assessment)的安全关键系统分析方法在近些年来逐步受到业界的广泛关注[3].MBSA的核心是首先对整个系统进行模型构建,然后通过对整个模型的定性和定量分析,来发现模型中可能存在的安全缺陷和潜在的系统风险.MBSA通过在系统模型设计层级进行安全分析,消除这些风险可能导致的后果,提高整个系统的安全性[4].
AltaRica 3.0[5-7]是一种基于MBSA的多层次的模型语言,并结合形式化方法对系统的安全性进行分析,目前在航空航天系统安全分析领域有着较为广泛的应用.AltaRica 3.0模型中的层次结构S2ML是用来描述真实系统的复杂层次架构和相应系统中部件的关联信息,而要对AltaRica 3.0模型进行安全性验证,就要将AltaRica 3.0模型的层次结构转换成形式化语义模型,AltaRica 3.0的形式化语义模型是一类卫士转换系统GTS(Guarded Transition Systems)[8],由于GTS所具有的的形式化语义特征,就可以应用马尔可夫生成器[9]、随机仿真、模型检测等工具进行对AltaRica 3.0模型进行有效的安全性分析与验证.因此,将AltaRica 3.0的层次模型(S2ML)转换为语义等价的平展化模型(GTS)是进行系统安全分析的一个关键步骤.
本文的主要研究内容如下:第2节介绍本文的相关工作和国内外研究现状;第3节讨论了本文研究所涉及技术的基本概念和说明;第4节详细描述了AltaRica 3.0的ANTLR解析过程,进行AST验证,并给出本文所设计的平展化算法的思想和伪代码的描述,对算法进行复杂度分析,以及对算法的优化部分进行了说明;最后在第5节中,进行实验的评估,并在第6节中总结和讨论了未来的工作.
2 相关工作
目前,已经发布了三个AltaRica版本:AltaRica 1.0[10],AltaRica DataFlow[11,12]和AltaRica 3.0,其中第一版的AltaRica 1.0主要是根据约束自动机定义的[6],针对第一版的AltaRica模型,已经有几种评估工具被开发,例如模型检查器[13]和关键序列生成器[14].但是第一版的AltaRica模型在处理大型工业系统过程时,会消耗大量的资源.针对这个问题,第二版的AltaRica Data-Flow模型被创建,它的语义是基于模式自动机的[15].在这个版本中,断言中只允许数据流的分配,AltaRica Data-Flow已经在Cecilia OCAS,Simfia[16,17]和Safety Designer中得到广泛的应用.AltaRica 3.0是AltaRica的第三个版本,虽仍处于实验室的研究阶段,但相比于AltaRica Data-Flow,AltaRica 3.0增加了GTS和面向对象的概念,其中GTS是AltaRica 3.0的基础数学模型,可以对AltaRica 3.0模型进行安全性分析与验证,对象的概念使AltaRica 3.0更符合编程语言的语法思想.
国内对AltaRica 3.0的研究还是空白阶段,在航空电子系统进行安全验证的时候,我们只能对已有的AltaRica工具(如Simfia等)进行工具应用,同时国外对AltaRica工具的进行技术保密,无法掌握其核心技术和工作原理.因此了解AltaRica 3.0的平展化操作原理,实现AltaRica 3.0的GTS获取过程,是下一步开发基于AltaRica 3.0的自主安全分析软件的重要基础,对航空系统安全性分析有重大意义.国外已有的工作包括:文献[18]主要介绍AltaRica 1.0的平展化操作,文献[19]中的平展化工作是针对AltaRica Data-Flow而言,不能对AltaRica 3.0模型进行平展化操作,文献[20]中的只介绍了AltaRica 3.0平展化的基本思想和要求,没有进行详细的实现,目前没有针对AltaRica 3.0的平展化算法的实际实现.
为此,本文提出了一种基于ANTLR的AltaRica 3.0的平展化算法A2GTS,用来完成AltaRica 3.0的平展化操作,A2GTS利用ANTLR生成AltaRica 3.0的抽象语法树AST(Abstract Syntax Tree),然后使用树的遍历算法,可以快速准确的定位到存储信息的结点,从而获取到结点的存储信息,提高整个平展化系统的速度和精确度.
3 ANTLR与AltaRica 3.0概述
3.1 ANTLR概述
本文工作中涉及到模型语言的识别和转换,因此采用ANTLR平台来实施.ANTLR是一种基于EBNF的语法分析器工具,可用于读取、处理、执行和翻译结构化的文本或者二进制的文件[21],在学术领域和实际的工业生产中得到广泛的应用.在ANTLR中,首先需要将所分析语言的语法规则定义为ANTLR语法解析文件的格式(ANTLR的元语言(Meta Language)[22]),形成要解析语言的ANTLR语法文件;其次通过调用ANTLR的内置方法,生成对应的词法分析器和语法分析器.
词法分析器的功能是根据相应的词法规则将输入文件的字符流转换成由短语组成的标记流,得到具体语言的词法分析结果;然后利用语法分析器将这些标记流进行组合,生成一棵抽象语法树AST.所有的词法信息都是存储在AST的叶子结点上,可以根据具体语言处理的不同要求来制定相应的处理规则,获取最终的执行结果.
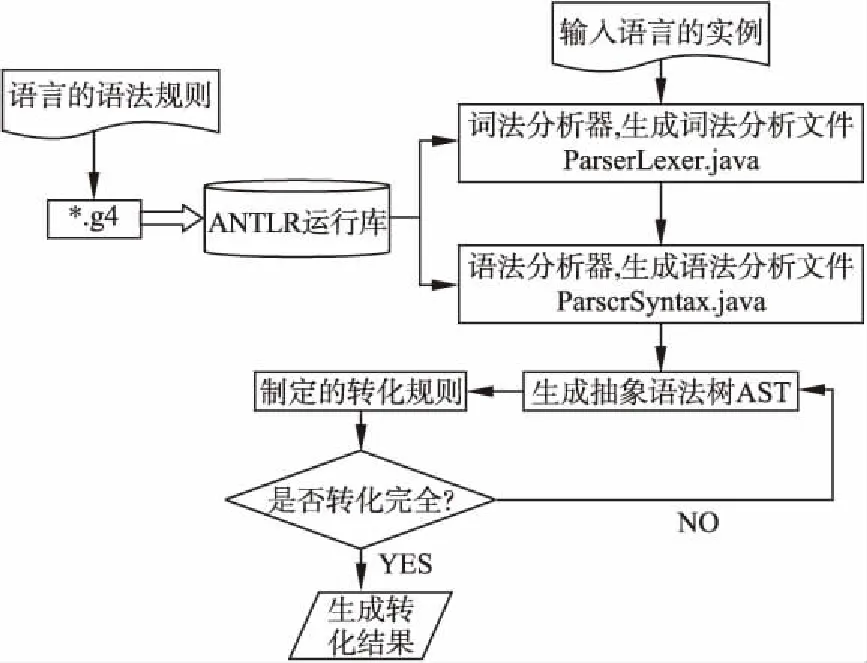
图1 ANTLR解析过程
如图1所示,ANTLR的主要解析过程分为词法分析,语法分析,AST分析和相关模板文件分析四个过程[23],具体过程如下:
1)词法分析过程:高级语言以输入文本的方式进入到词法解析器中,经过词法解析器的解析成为特定的标记流(token),缓存在内存中.
2)语法分析过程:词法分析器获取的标记流信息直接传递给语法分析器,根据语言的ANTLR解析文件,获取词法信息中包含的语法信息.
3)AST分析过程:生成抽象的语法树,AST主要包含两部分的内容:结构信息,包含整个输入的语法实例的结构信息;文本信息,词法分析中得到的标记流都存储在AST的叶子结点中,可以使用ANTLR的监听器和访问器方法对整棵树进行遍历.
4)自定义转换过程:通过制定的转化规则,就可以对获取的文本信息进行相应的转换,产生特定的输出文本,获取到转换后的文件.
3.2 AltaRica 3.0模型
AltaRica 3.0是基于事件的建模语言,主要由系统结构建模语言S2ML和卫士转换系统GTS组成[20],其中S2ML是描述AltaRica 3.0的层次结构的模型语言,GTS则用来对AltaRica 3.0进行安全分析的形式化语义模型.
AltaRica 3.0是层次化的语言,可以包含多个嵌套递归结构,直接使用多层次化的AltaRica 3.0模型来对整个系统进行安全性分析是非常复杂的.GTS模型本质上是由一个基于自动机同步交互网络的形式化模型,且目前已有较为成熟的基于自动机网络模型的形式化分析技术(如:支持模型检验的软件工具,NuSMV,SPIN等),因此将多层次的AltaRica 3.0模型转换成等价语义的平展化GTS模型,就可以很好的应用模型检验工具来进行有效严格的安全性分析.
AltaRica 语言有着严格的语法和词法定义[19].模型的基本组件是结点(Class/Block).主要由变量(Variable,包括流变量和状态变量)、事件(Event,事件发生后,会引起变量的转换)、转换(Transition,包括正常转换,同步转换和隐藏转换,对系统的状态变化进行说明)、断言(Assertion,描述流变量和状态变量、流变量之间的关系)组成[21].为了详细说明AltaRica 3.0的组成信息,图2给出了一个冷却系统的图示及其AltaRica 3.0模型表述.

图2
AltaRica 3.0利用面向对象的思想,将图2(a)的冷却系统中的具体组件抽象成类.水箱、泵和反应堆分别是Tank类、Pump类和Reactor类,类之间通过变量进行交互,Tank类实例化对象T的冷却液输出作为整个系统的输出变量outFlow,Pump类的两个实例化对象P1和P2分别有两个变量:输入变量inFlow和输出变量outFlow,Reactor的输入变量inFlow和P1、P2的输出变量outFlow相同.系统要保证至少有一个泵保持正常的运转状态,这样冷却液才能够准确地对反应堆进行冷却操作,但是泵可能发生故障,水箱也可能为空,这些原因都能导致整个系统的失效.图2(b)利用AltaRica 3.0对整个系统进行描述,定义了上述系统的组件信息和可能发生的失效事件信息.
GTS是一类支持安全分析的状态/转换形式的模型,可以用来表示具有即时环路的系统,描述系统组件在环路中的状态转换.GTS对系统进行描述的模型称为平展化的模型,AltaRica 3.0多层次模型转换为GTS模型的过程称为平展化操作.图2冷却系统的GTS模型表述如下.
block CoolingSystem
Boolean T.isEmpty(init=false);
Boolean T.outFlow(reset=false);
RepairableState LineOne.POne.s,
LineTwo.PTwo.s(init=WORKING);
Boolean LineOne.POne.inFlow,
LineOne.POne.outFlow(reset=false);
Boolean LineTwo.PTwo.inFlow,
LineTwo.PTwo.outFlow(reset=false);
Boolean Reactor.inFlow(reset=false);
event T.getEmpty;
event LineOne.POne.failure,LineOne.POne.repair;
event LineTwo.PTwo.failure,LineTwo.PTwo.repair;
transition
T.getEmpty:not T.isEmpty-> T.isEmpty:=true;
LineOne.POne.failure:LineOne.POne.s==
WORKING-> LineOne.POne.s:=FAILED;
LineOne.POne.repair:LineOne.POne.s==
FAILED-> LineOne.POne.s:=WORKING;
LineTwo.PTwo.failure:LineTwo.PTwo.s==
WORKING-> LineTwo.PTwo.s:=FAILED;
LineTwo.PTwo.repair:LineTwo.PTwo.s==
FAILED-> LineTwo.PTwo.s:=WORKING;
assertion
T.outFlow:=if not T.isEmpty then true else false;
LineOne.POne.inFlow:=T.outFlow;
LineTwo.PTwo.inFlow:=T.outFlow;
LineOne.POne.outFlow:=if LineOne.POne.s==
WORKING then LineOne.POne.inFlow else false;
LineTwo.PTwo.outFlow:=if LineTwo.PTwo.s==
WORKING then LineTwo.PTwo.inFlow else false;
Reactor.inFlow:=LineOne.POne.outFlow or
LineTwo.PTwo.outFlow;
end
对AltaRica 3.0的多层次结构模型S2ML进行平展化处理,利用面向对象的思想,将多个类编译成一个GTS模型,其中变量、参数、观察变量、事件按照调用关系重新命名,例如主类main中有一个对象a,a中有一个对象b,b中有一个变量s,那么s在GTS中可表示为a.b.s,例如Reactor中的inFlow变量在GTS中被表述为Reactor.inFlow,通过这种方式,AltaRica 3.0模型的层次结构信息被完整表达,但是对应的GTS模型只有一层结构,从而简化了整个模型的层次结构.
使用AltaRica 3.0模型描述的某复杂结构的系统模型都可以转换成等效的平展化GTS模型.本文根据AltaRica 3.0和GTS的语法规则,制定了相应的转换规则,设计了一套转换算法A2GTS,实现AltaRica 3.0模型自动转换成为对应的GTS平展化模型.
4 基于ANTLR的AltaRica 3.0平展化算法框架
本节利用基于ANTLR的AltaRica 3.0语法解析文件和平展化操作的基本思想,提出了一种基于ANTLR的AltaRica 3.0模型平展化实现算法(A2GTS).首先介绍算法的基本思想,其次描述算法的基本步骤和伪代码说明,最后对算法进行复杂度和优化分析.
4.1 形式化转换过程
定义1.由AltaRica 3.0的S2ML模型转换成为AltaRica 3.0的GTS模型的过程叫做AltaRica 3.0的平展化操作.
一个简单的平展化过程如下所示.

block A中包含block B,平展化过程只保留一层结构信息,因此对block B进行平展化操作,同时也要保证模型结构信息的完整表达,对于B中的组件信息用B.p的形式保留其模型结构信息.由于S2ML和GTS的词法信息相同,仅仅是语法结构上的不同,因此对于两个模型信息中的词法信息可以直接对应,仅需考虑语法结构上的转换.
定义2.卫士转换系统(GTS)是一个五元组[20]:
G=
(1)
•V是一组变量,分为状态变量S和流变量F,S用来描述系统组件的状态信息,F是系统组件之间的交互流变量,其中V=S∪F,并且S∩F=Ø;
•E是GTS中所有transition事件的集合,为系统可能发生的一组事件,主要由正常事件Enor和同步事件Esyn组成,即E=Enor∪Esyn;
•T是一组转换(transition),即三元组
•A是断言(assertion),即建立在V变量上的指令,用于根据状态变量的值计算流变量的值;
•ξ是V的变量分配,是对状态变量和流变量的初始赋值,其中状态变量的初始化的关键字为“init”,流变量的初始化的关键字为“reset”.
转换e:G→P可以在给定的状态ε下,流变量和状态变量组合的布尔条件为真,G为真(即给定的流变量和状态变量赋值集合为ε):
ε(G)=TRUE
(2)
e:G→P的过程分为两步:首先,G的布尔条件为真,此时就可以通过P更新系统组件的状态变量;其次,断言A就可以根据新的状态变量的值,更新系统组件的流变量值.
定义3.系统结构建模语言(S2ML)是一个四元组:
S=
(3)
•A(Attributes)代表变量的属性信息,是一组变量的赋值,属性用于将信息与端口,连接和块相关联,表示S2ML模型中组件状态变量和流变量的属性信息,可用于描述组件之间的交互,即:name=value(name为变量名称,value为变量赋值);
•P(Ports)代表系统中组件的抽象类信息,AltaRica 3.0利用面向对象的思想将真实系统中的组件进行抽象,端口是模型的基本对象,包括variables,events和transitions,即:
P=Pv∪Pe∪Pt
(4)
•C(Connections)是描述Ports之间的交互信息,用来详细说明模型中组件之间的流变量交互行为.
•B(Blocks)相当于容器.包含了Ports,Connections和其他的Blocks,即:
B=BP∪BC∪Bsub
(5)
假设S1是一个真实的S2ML模型,其中S1=
第一,词法层面转换.S1中的变量的属性信息A1对应G1中的ξ1,即A1=ξ1;S1中的P1由变量信息、事件信息和转换信息组成,即P1=Pv1∪Pe1∪Pt1,因此Pv1对应G1中的V1,Pe1对应G1中的E1,Pt1对应G1中的T1,P1=Pv1∪Pe1∪Pt1可表述为P1=V1∪E1∪T1;S1中的C1描述P1中流变量的交互信息,因此C1=A1.
第二,语法层面转换.假设S1中的B1包含n层子模块Bsub1_j(0≤j≤n,0≤n≤+),每层Bsub1_j包含m个Bsub1_ji(0≤i≤m,0≤m≤+),即一个B1可由m×n个Bsub1组成,此时假设B1的模块名称为b1,Bsub1_j的模块名称为bsub1_j,Bsub1_ji的模块名称为bsub1_ji.则S2ML中的结构层次关系在GTS中表述为b1.bsub1_j.bsub1_ji,GTS由“.”来表达模型的层次关系.结合上述词法层面的对应原则,此时当0≤j≤n,0≤i≤m时,S1中的变量的属性信息A1对应G1中的ξ1,b1.bsub1_j.bsub1_ji.A1=ξ1;S1中的P1对应G1中的变量信息、事件信息和转换信息,即:
b1.bsub1_j.bsub1_ji.P1=V1∪E1∪T1
(6)
S1中的C1对应G1中的A1,即:
b1.bsub1_j.bsub1_ji.C1=A1
(7)
4.2 A2GTS算法总体框架
A2GTS算法主要由Block平展化算法、Class平展化算法和同步平展化算法三个算法组成,主要包括四个模块,如图3所示.具体步骤如下:
步骤1.利用ANTLR的元语言对AltaRica 3.0的语法规则进行详细的描述.获取对应的语法文件(altaRica.g4),运行ANTLR内置方法形成AltaRica的词法和语法解析器,可以对一个AltaRica 3.0的实例进行AST分析.
步骤2.对Block文件进行层次化平展操作.首先对AltaRica 3.0模型文件进行划分,找出其主模块Block和子模块Block,其中主模块Block是平展化程序入口;然后对主模块Block的语法树进行层次遍历,获取其嵌套的第一层的Class信息和子模块Block文件,将Block引用的Class信息存储到对应的GetClassMap数据结构中,同时定义一个不定长的字符串s,将上一层Block的实例名加入到字符串s中.此时,字符串s就是当前Block中元素的前缀标识符,将Block平展化的信息存入到Bflat中,再次进行层次遍历和深度遍历,重复上述的操作,直到获取到最深的结点.
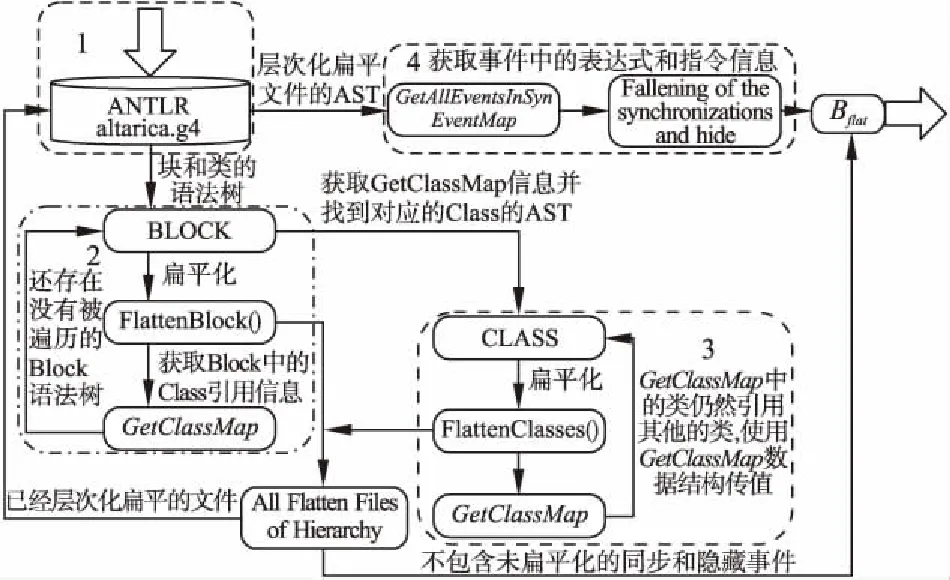
图3 AltaRica 3.0平展化算法框架
步骤3.对Class文件进行层次平展化操作.首先,根据步骤2获取到的主模块引用的Class信息,对GetClassMap数据结构进行遍历,由GetClassMap中存放的Class类名和实例名,自动寻找到类名相同的Class文件建立的AST,实例名就是当前Class的前缀标识符,确定Class的所属关系;然后获取当前Class文件引用的其他的Class文件信息,将Class类名和实例名存到对应的GetClassMap中,再重复上述过程,直到确定所有的Class的前缀标识符.
步骤4.对已经平展化的层次化文件进行同步事件平展化操作.AltaRica3.0模型文件的transition信息包含这个三种事件:正常事件,同步事件和隐藏事件,三者的关系就是包含关系,其中同步事件和隐藏事件包含正常事件.具体关系如图4所示.
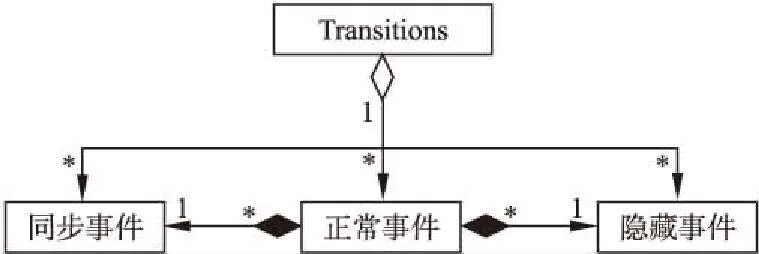
图4 事件之间的相互关系
在已经平展化文件形成的AST中,三种事件的存储方式的主要区别就是其存储结点的属性信息的不同.首先,可以根据结点的属性直接获取对应事件的类型,得到同步事件和隐藏事件子结点存储的值(正常的转换事件);然后根据得到的值,遍历AST,得到对应事件包含的表达式和指令;再依据同步的平展化规则和隐藏的平展化规则对事件中的表达式和指令进行操作,得到平展化后的同步事件和隐藏事件.
通过步骤2和步骤3 的不断迭代就能获取到嵌套层次结构的平展化的文件,完成垂直方向的平展化(结构层次的平展化),步骤4完成水平方向的平展化过程(同步过程的平展化).
4.3 AltaRica 3.0模型的语法解析过程
4.3.1 构建AltaRica 3.0的ANTLR语法模型
AltaRica模型是模型元素的集合,块、类、常量、域、记录和函数(blocks,classes,constants,domains,records and functions).其中基本元素是块Block和类Class.模型元素可以在声明之前使用.
Block或Class的内部元素可以按任何顺序声明,但必须在transition和assertion之前声明.Block或Class的内部元素的声明是不同的.inheritance(规则′ExtendsClause′),variables,events,parameters,observers在块和类中都能被定义,剩下的只能在块中定义的是:aggregation(规则EmbedsClause)和clone(规则ClonesClause).
根据AltaRica 3.0的整体架构,ANTLR可以将AltaRica3.0的结构信息划分为:1)词法结构定义,规定AltaRica 3.0中基本的构造元素;2)表达式定义,规定AltaRica 3.0中的符号,布尔和数字表达式;3)指令集定义,AltaRica 3.0中的指令规定具体的语法转换规则,描述转换和断言中的具体的转换动作;4)属性定义,一些模型元素使用属性的概念来定义一些特征;5)域定义,AltaRica 3.0中的域是命名常量的命名集.
由Block和Class的定义,AltaRica 3.0提供了层次模型的构造过程,即将实际系统的模型表述为组件之间相互嵌套的多层次结构,AltaRica 3.0的ANTLR元语言的概述说明如下所示.

literalValue:boolean1|integer|real|literalAttributeValue|pathIdentifier;//词法结构定义expression:expressionnOperatorexpression|uOperatorex-pression|operatorCall|ifThenElseExpression|switchExpression|curve|literalExpression;//表达式定义instruction:skipSituation|halfEquivalentSituation|allEquivalentSituation|ifSituation|switchSitu-ation|multiInstructionSituation|identifierSit-uation;//指令集定义attributes:′(′attribute(′,′attribute)∗′)′;//属性定义domainDeclaration:′domain′identifier′{′symbolicConstants′}′;//域定义blockDeclaration:′block′identifier(blockDeclarationClause_get)∗(blockDeclarationClause)∗(transitionsClause)?(assertionClause)?′end′;//块定义classDeclaration:′class′identifier(includeblockDeclarationClause_get)∗(declarationClause)∗(transitionsClause)?(assertionClause)?′end′;//类定义
4.3.2 生成AST示例
对AltaRica 3.0的ANTLR的语法解析文件的正确性进行验证.通过输入一段实际的AltaRica 3.0的代码进行验证,将代码输入到解析文件形成的词法和语法分析器中,如果解析文件正确,词法和语法分析器就会自动的识别输入代码的结构,形成一棵抽象语法树.输入图2(b)中描述的部分AltaRica 3.0模型语言,自动生成如图7所示的AST,证明AltaRica 3.0的ANTLR的语法解析文件是正确.
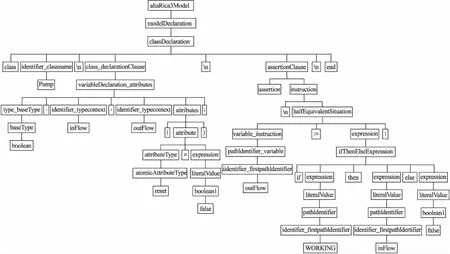
图5 AltaRica 3.0模型的语法树
4.4 Block平展化算法处理
Block的平展化过程.定义一个Block由八元组构成,B=
使用“.”来标识平展化过程中子组件的变量之间的所属关系.例如,BM中,子块BS的实例化对象为b,对象b中包含变量v,可以将其表述为b.v.以直观的方式将“点符号”扩展到变量集(即,如果V是一组声明元素,则b.V={b.v|v∈D}),定义FlatB()用于对BM进行平展化操作的递归函数,并使用FlatSonB()函数对子模块BS中嵌套的子模块的进行平展操作.如果B是BM中的主模块的信息,用B[Bi]来表示子模块BS中嵌套的子模块平展化的信息,用φ表示嵌套的层数.另外,用ChildEle(B)表示B的嵌套的模块集合.
FlatB(B)=
(8)
第一种情况:嵌套的层数为0,B表示主模块中的信息,直接可以作为平展化的文件信息;
第二种情况:主模块BM的嵌套层数只有一层,此时要调用FlatB()进行平展化获取转换后的信息;
第三种情况:主模块BM的嵌套层数大于一层,此时首先要调用FlatSonB()对子模块BS中嵌套的模块Bλ进行平展化操作,然后再利用FlatB()进行平展化操作.
可以将经过平展化操作后的Block表述为一个四元组,即:
Bflat=
(9)
其中,模块信息B′M由主模块BM和平展化的子模块BS构成,即:
B′M=BM∪(∪{b′s|b′s=FlatB(bs),bs∈BS})
(10)
声明元素D′为子模块中声明元素(要经过平展化操作)和主模块中声明元素的集,即:
D′=BS_Name.D∪BM.D
(11)
转换转换T′M为子模块中转换(要经过平展化操作)和主模块中转换的集合,即:
T′M=BS_Name.TS∪BM.TM
(12)
断言A′M为子模块中断言(要经过平展化操作)和主模块中断言的集合,即:
A′M=BS_Name.AS∪BM.AM
(13)
Block平展化算法是一个迭代形式的算法,输入Block的层次化语言,输出文本形式的平展化的文本Bflat,和Block引用的Class类的信息(存放在GetClassMap).Block平展化算法伪代码如算法1所示,第7到43行是一次完整的迭代过程.
算法1.Block平展化算法伪代码
输入:Block文件
输出:已层次化扁平化的Block文件和引用Class信息
1.functionFLATTENBLOCK(B,Bflat)
2.Bflat←∅;
3.Map
4.v←∅;
5.s←∅;
6.ast←ANTLR.getAST(altarica.g4);
7.functionFlattenIncludeBlock(B,Bflat)
8.ASTB←ast.ParseTreeWalk(B);
9.ifB∈BMthen
10.v← ∅;
11.elseifB∈BSthen
12.v←StringAppendBlockName(v,ASTB.getBlockName());
13.s←v;
14.endif
15.
16.functionGetContextFromMainAndSub(v,ASTB);
17.Bflat.add(v+ASTB.D);
18.forc∈CEdo
19.ifc.ClassNameis not inmap.keythen
20.map.key←c.ClassName;
21.map.get(key)←v+c.ObjectName;
22.else
23.map.get(c.ClassName)←v+c.ObjectName;
24.endif
25.endfor
26.
27.forallb∈Bdo
28. ifb∈BMthen
29.FlattenIncludeBlock(b,bflat,v);
30.bflat.add(Tm);
31.bflat.add(Am);
32.Bflat.add(bflat);
33.elseifb∈BSthen
34. FlattenIncludeBlock(b,bflat,s);
35.bflat.add(AddPrefixVariableAndEvent(s,b.D));
36.bflat.add(AddPrefixTransition(s,b.TS));
37.bflat.add(AddPrefixAssertion(s,b.AS));
38.Bflat.add(bflat);
39.endif
40.endfor
41.returnmap,Bflat;
42.endfunction
43.endfunction
44.endfunction
步骤1.对主模块Block中的声明元素D,CE,TM和AM进行平展化的操作.I,G,P,Q分别为D,CE,TM和AM的数量,遍历递归树的根结点(即主Block),根据平展化的规则,对于所有的Di,TMp和AMq不用添加前缀标识符,可以直接放入到Bflat1中,即:
Bflat1={ψ|ψ.add(Di,TMp,AMq),i∈I,p∈P,q∈Q}
(14)
当j∈G时,将CEj放入GetClassMapM中,CEj.ClassName作为key,getKey:keyj←CEj.ClassName表示将引用的类名作为键的过程,由于一个类可以被多次实例化使用,因此将对应的value定义为一个不定长的数组,存放引用的CEj.ObjectName;Λ为每个key对应的value中引用类的数量,当l∈Λ时,getValue:valuej∪{CEj.ObjectNamel}表示获取所有键名为CEj.ObjectName对应的value的过程,即:
(15)
步骤2.确定每一层子模块BS的前缀标识符.主模块中包含子模块BS,BS模块又可包含BS,形成一棵递归树.步骤二就是确定子模块之间的所属关系,将递归AST的层次深度作为循环条件,对于每一层BS进行操作,由于子块可以进行多层嵌套,对于每一层块的实例名都能作为下一层Block的前缀标识符,前缀标识符会随着嵌套结构和树的深度的增加而逐层进行记录,算法中使用StringAppendBlockName()的方法进行记录.
步骤3.对子模块Block中的声明元素D,CE,TS和AS进行平展化的操作.R为子Block的数目,对于某个声明的子块BS,其D,CE,TS和AS的数目分别为I,G,P,Q.第27行到40行是嵌套的子模块的递归平展化过程,FlattenIncludeBlock()为一个递归函数,对所有的子块进行操作.同一个Block根结点的Block子结点的前缀标识符都是相同的,对于一个Block根结点,其StringAppendBlockName()都是唯一的,并且只在这个子树中起作用.当r∈R时,就能获取的每一层每一个子Block的前缀标识符s,利用AddPrefixVarableAndEvent()方法对子Block的声明元素D添加前缀标识符s,即:
getD:AddPrefixVarbleAndEvent(s,BSr.Di)
(16)
每个子模块的TS添加前缀标识符s,即:
getT:AddPrefixTransition(s,BSr.TSp)
(17)
每个子模块中的AS添加前缀标识符s,即:
getA:AddPrefixAssertion(s,BSr.TSp)
(18)
将转换后的Block的D,TS和AS平展化文件添加到Bflat2中,即:
Bflat2={ψ|ψ.add(getD,getT,getA),i∈I,p∈P,q∈Q}
(19)
再把每一层BS引用的类的信息添加到GetClassMap中,重复第一步中添加引用类信息的过程.
4.5 Class平展化算法处理
Class的平展化过程.定义一个Class由一个五元组组成C=
类的平展化和块的平展化过程类似,FlatC()为对Class进行平展化操作的递归函数.首先对Class中的声明元素D,转换T和断言A进行平展化操作;然后对当前Class中引用的其他Class信息进行递归操作,其中c是一个Class的实例化对象,即:
(20)
五元组Cflat=
(21)
Class平展化算法是一个递归形式的算法,FlattenClass()为一个递归函数,对所有的类进行平展化操作.输入Class的层次嵌套语言,输出Class的引用类信息和平展化的Class文件.Class平展化算法的伪代码如算法2所示.
算法2.Class平展化算法伪代码
输入:Class文件和引用的Class信息;
输出:已经层次化扁平的Block文件;
1.functionFlattenClass(C,Cflat,map);
2.Cflat←∅;
3.ast←ANTLR.getAST(altarica.g4);
4.ASTC←ast.ParseTreeWalk(C);
5.forallB∈BAdo
6.FlattenBlock(b,bflat);
7.Cflat.add(bflat);
8.endfor
9.
10.forall
11.forallc∈Cdo
12.ifkey==c.getClassNamethen
13.foralls∈c.get(key)do
14.Cflat.add(AddPrefixVariableAndEvent(s,c.D));
15.Cflat.add(AddPrefixTransition(s,c.T));
16.Cflat.add(AddPrefixAssertion(s,c.A));
17.endfor
18.endif
19.endfor
20.endfor
21.map=new Map
22.fork ∈CEdo
23.ifk.ClassNameisnotinmap.keythen
24.map.key←k.ClassName;
25.map.get(key)←k.ObjectName;
26.else
27.map.get(k.ClassName)←k.ObjectName;
28.endif
29.endfor
30.forallp∈Cdo
31. FlattenClass(p,pflat,map);
32.Cflat.add(pflat);
33.Bflat.add(Cflat);
34.endfor
35.returnBflat;
36.endfunction
Class平展化算法具体步骤如下:
步骤1.Class文件的层次结构的平展化.首先获取所有的Class的AST,根据算法1对Class中引用的Block进行平展化操作;其次根据算法1获取的GetClassMap的key,寻找到类名和key相同的AST,以及对应key下对应的value,获取GetClassMap中引用类的数量K;然后对该AST进行深度优先遍历,获取到对应类中所有的D,T,A,其D,CE,T和A的数目分别为I,H,P,Q,当k∈K时,对Class中的声明元素D添加前缀标识符,即:
getD:AddPrefixVableAndEvent(vauek,Ck.Di)
(22)
对每个Class中的转化信息T添加前缀标识符,即:
getT:AddPrefixTransition(valuek,Ck.Tp)
(23)
对每个Class中的断言信息A添加前缀标识符,即:
getA:AddPrefixTransition(valuek,Ck.Ap)
(24)
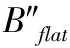
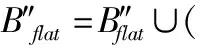
(25)
Bflat_hier=B′flat∪B″flat
(26)
步骤2.获取每个Class文件的引用的Class的信息.遍历当前Class的AST,找到当前Class的CE信息,重复上述递归函数FlattenClass()的过程,直到找到不引用其他类的Class,递归过程结束.
在类和块的平展化的过程中,转换和断言也存在对应的嵌套递归结构,由AltaRica 3.0语法定义的ANTLR语法文件altarica.g4可知,转换的主要形式为Ei:Qi->Pi,其中Ei为事件,Qi为表达式结构,在altarica.g4中定义为expressions,对应生成的AST的结点名称也为expressions,其中Pi为指令结构,在altarica.g4中定义为instruction,对应生成的AST结点的名称为instruction.
由4.2.1节的表达式和指令的解析过程,expressions中一共包含6种嵌套结构,可以产生6n种可能的结构,instruction一共包含5种嵌套结构,而且每个嵌套结构还和expressions结构进行嵌套,但是instruction和expressions生成递归的AST的过程是类似的,按照递归AST的递归原则(即expressions或instruction的语法嵌套规则)不断的进行递归,每递归一次,语法树就增加一层,直到树中结点的属性为curve或literalExpression(即所有的结点都为Terminal叶子结点,存放具体的数值),此时叶子结点的数值就是要进行平展化的变量,算法2和算法3 的过程就是确定该变量的所属关系.
4.6 同步平展化算法处理
同步(Sync)的平展化过程.该过程主要对已经层次化平展化的Bflat_hier进行同步的平展化操作.算法的伪代码如算法3所示:
算法3.Sync的平展化算法伪代码
输入:所有已扁平化的文件;
输出:已进行同步扁平化和隐藏扁平化的文件;
1.functionFlattenClass(C,Cflat,map);
2.Syncflat←∅;
3.ast←ANTLR.getAST(altarica.g4);
4.ASTBflat←ast.ParseTreeWalk(Bflat);
5.Map
6.Map
7.Map
8.forallb∈AllSynNamedo
9.ifbisnotinmapGrandson.keythen
10.mapGrandson.key←b;
11.mapGrandson.get(key)←b.getEventInSyncName();
12.else
13.mapGrandson.get(b)←b.getEventInSyncName();
14.endif
15.endfor
16.
17.forallb∈mapGrandsondo
18.ifb.keyisnotinmapSon.keythen
19.mapSon.key←b.key;
20.ifb.get(key).getValue()==”strong”then
21.mapSon.get(”strong”).append(b.get(key));
22.elseifb.get(key).getValue()==”weak”then
23. mapSon.get(”weak”).append(b.get(key));
24.endif
25.endif
26.endfor
27.
28.forallb∈mapSondo
29.ifb.keyisnotinmap.keythen
30.map.key←b.key;
31.ifb.get(key).getValue()==”strong”then
32.map.get(”ins”).append(b.getInstruction());
33.map.get(”exp”).append(b.getExpression());
34.elseifb.get(key).getValue()==”weak” then
35.map.get(”ins”).append(b.getInstruction());
36.map.get(”exp”).append(b.getExpression());
37.endif
38.endif
39.endfor
40.
41.forallb∈mapdo
42.Syncflat.add(TranslateSyncInRule(b));
43.Bflat←Bflat∪Syncflat;
44.endfor
45.returnBflat;
46.endfunction
Sync的平展化算法最重要的步骤就是遍历已经层次平展化的语法树ASTBflat.由3.2.1节的转换模块的ANTLR解析的过程,同步事件中transition和individualTransition只能包含一层循环.同步转换的形式为e:!a1&…&!aM&?b1&…&?bn&L1→R1& …&Lr→Rr,(m≥0,n≥0,r≥0,!为强同步事件,?为弱同步事件,Lr为布尔表达式,Rr为指令),平展化的过程是对a1,…,an,b1,…,bm中包含的表达式和指令信息进行转换.
步骤1.取出同步事件中包含的正常事件.首先遍历ASTBflat,根据树结点的属性获取其中的同步事件,为同步事件的数量,getSyn:keyφ←SynEventφ;取同步事件中的正常事件,M为正常事件的数量,normalEventλ是同步事件e中的[a1,…,an,b1,…,bm],λ∈M时,即:
getNormal:valueφ∪{normalEventλ}
(27)
然后就可以将e,[a1,…,an,b1,…,bm]的形式扩展为一个map映射,在算法中定义的是mapGrandson用于存放同步事件和同步事件中的正常事件,即:
(28)
步骤2.获取正常事件包含的表达式和指令信息.首先通过mapGrandson中包含的正常事件对语法树ASTBflat进行再次遍历,根据3.2节中转换事件的定义,强弱同步事件的内容直接由expressions和instruction组成,获取到属性为expressions和instruction的结点;然后遍历到叶子结点,获取到包含的内容,存入到mapSon中.
步骤3.获取平展化后的事件.由同步的平展化规则,主要针对第二步中获取的mapSon中存储的expressions和instruction进行相应的操作.算法首先利用同步的平展规则函数,即TranslateSyncRule()对mapSon的内容进行操作,将平展化的结果放入mapAll中;然后遍历mapAll的内容,和之前进行层次平展化的文件(不包括未平展化的同步事件)合并,得到相应的平展化文件;其次由hide的规则进行相应的隐藏操作,由此平展化过程执行完毕;最后输出经过隐藏操作后的平展化文件,即:
Bflat=Bflat_hier∪Bflat_syn_hide
(29)
4.7 算法分析
4.7.1 算法时间复杂度分析
通过实验数据可得整个算法的时间消耗发生在算法1和算法2的递归,以及Block和Class中转换和断言的嵌套递归上:
第一,主模块Block中的子模块Block的嵌套递归.假设一个Block中能嵌套m个子模块Block,则嵌套的子模块Block最多有mn-1个,其中n为主模块文件形成的AST树的层数(即最多的嵌套层数可以达到n层),而且每个Block嵌套的子Block的数目可能不一样,m是最大嵌套数的情况.
对算法1的时间复杂度分析可以直接看成对形成的递归AST树的时间分析,初始的递归树只有一个结点,主模块的权值标记为T(n),然后按照递归树的递归规则不断地进行递归,每递归一次递归树增加一层,直到获取到最大深度的子模块Block所在的层.由于在实际的应用过程中,一个系统是由有限个子系统组成,所以可以设置一个衰减函数T(n/b),限定子模块的数量,规定最深层的Block的权值标记为T(1),由此可以得到一个递归方程:
分析可知其时间复杂度为O(nlogbm).
第二,在引用类的嵌套上,假设每个Block能引用k个Class,每个Class最多可以扩展c个Class,则每个Block最多可以包含k×cr个Class,其中r为遍历到的无引用扩展类的最大树的深度,此时也是对一个递归树进行分析,此时算法2 的时间复杂度为O(k×rlogbc).
第三,同步的平展化过程,主要是线性分析,假设每个同步事件都有t个强弱事件组成,则依次对这t个事件进行分析,相应的时间复杂度为O(t).
4.7.2GetMapClass数据结构
GetMapClass数据结构由队列和map映射组成,将Block和Class的平展化过程有效的进行分割,降低整个算法的复杂度.平展化算法的入口主模块Block包含了初始递归条件.如果在ANTLR的遍历过程中,遍历到其中引用的类,就开始查找引用类的AST,此时就变成多棵树同时进行遍历查找.从结构上来说,这个过程可看成是主模块Block的AST和引用类的AST进行了合并,形成了更大的一棵存在嵌套递归结构的AST.分析可知,对该AST进行相应的平展化操作,无疑会增加额外的时空开销.
对此,本节提出Block和Class之间的传值结构GetMapClass,使Block和Class之间的平展化操作在空间上不会相互影响.对于建立的Block树,利用设计的遍历算法对Block进行有效的平展化操作.在遍历过程中,不会有停顿操作,对于Block中引用的类,会自动放入到GetMapClass数据结构中,保证Block的遍历能一直到最深Block所在的层次.同时,对于属于同一根结点的子Block,利用队列的功能进行关系标注,确保属于同一根结点的子Block的前缀标识符相同.最后利用GetMapClass进行传值操作,根据GetMapClass中包含的引用信息自动找到已经建立的Class的AST,取出GetMapClass中包含的value信息,对Class进行相应的平展化操作的同时,将当前Class中包含的引用类信息加入到GetMapClass,直到GetMapClass中不包含任何信息(即,遍历到不包含任何引用信息的Class),同时层次结构的平展化过程结束.
4.7.3 AST遍历算法设计
层次平展化最重要的过程是获得最外层模块和内层模块之间的所属关系,确定它们各自的前缀标识符.模块之间层次结构可以利用AST进行表示,对整个AST树进行遍历获得当前模块的前缀标识符.
根据AST的特性,一个父模块可能包含多个子模块,此时的遍历方法宜采用层次遍历的方法,而根据前缀标识符的规则确认这宜于采用深度遍历的方法.结合上述两种特性,A2GTS算法将深度遍历和层次遍历相结合,对整棵AST自上而下进行遍历,获取相应的前缀标识符,而对于隶属于一个父模块的子模块进行层次遍历,确定子模块中所有组件的前缀标识符.然后将所有的子模块确定为父模块,分别寻找它们所属的子模块,重复以上过程,直到所有的Block都不包含任何的子模块,整个遍历过程结束.
5 实验结果和分析
本节主要描述算法的工具架构设计,并对算法的有效性进行验证.对四个不同复杂度的AltaRica 3.0模型进行实验分析,将A2GTS算法实现平展化获取的结果和实际的平展化文件相比较,验证得到结果的正确性.
5.1 实验描述和环境
实验采用3.2节所描述的冷却系统(CoolingSystem)、文献[22]中的机轮刹车系统(WBS)、文献[23]中的供电系统(ElectricalSystem)和文献[20]中的灌溉系统(IrrigationSystem)进行平展化算法的验证.表1中从左向右,每列分别表示Block的嵌套层数、Class的引用层数、Block数量和Class数量.
表1 AltaRica 3.0模型信息
Table 1 AltaRica 3.0 model information
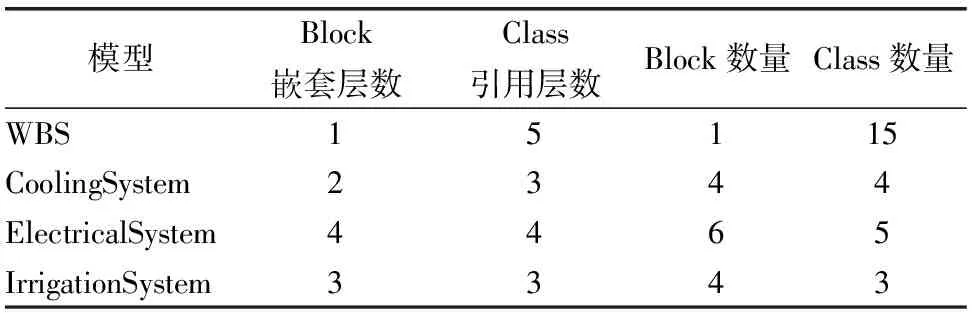
模型Block嵌套层数Class引用层数Block数量Class数量WBS15115CoolingSystem2344ElectricalSystem4465IrrigationSystem3343
本实验运用基于ANTLR的AltaRica 3.0的平展化算法A2GTS对四个模型进行平展化操作,四个模型的主要区别是Block和Class的嵌套层不同,以验证在不同的主树嵌套复杂度的情况下整个算法的平展化效率.
表2 不同的模型在平展化过程中的内存和时间消耗
Table 2 Memory and time consumption of different models during flattening
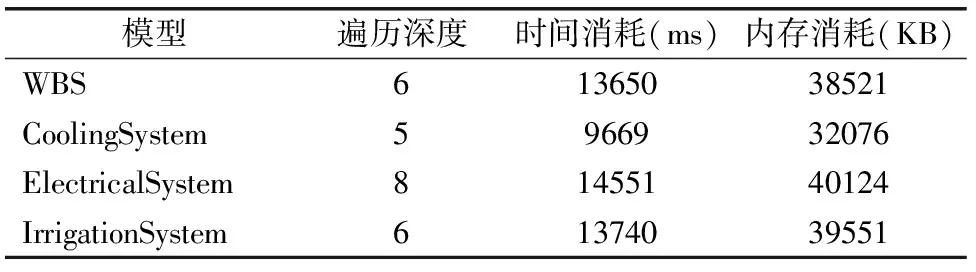
模型遍历深度时间消耗(ms)内存消耗(KB)WBS61365038521CoolingSystem5966932076ElectricalSystem81455140124IrrigationSystem61374039551
本文所涉及的试验数据均是在一台CPU为Intel(R)Xeon(R)CPU E5-1603 0 @ 2.80GHz、内存为8GB、操作系统为Windows 10 Enterprise的计算机上得到的,算法利用Java语言实现,实验的消耗信息如表2和图8所示.
由于篇幅限制,仅选取冷却系统和灌溉系统的平展化结果进行说明,实验的结果信息如图6和图7所示,本文所用到的模型说明,平展化结果和平展化过程在网盘中展示1.
5.2 实验结果和分析
对图6和图7分析,图6详细的描述了3.2节描述的冷却系统的组件的平展化信息,每个泵类Pump的失效事件failure和修复事件repair均用其所属关系进行表示(LineOne.POne.failure,LineTwo.PTwo.repair等),变量的信息也被完整地表述出来,水箱类Tank的空事件getEmpty在GTS中仍然保持只被Tank类所有(T.getEmpty).A2GTS将冷却系统的多层次复杂结构在一层模型上进行了很好地描述,也表示出了组件之间的流变量的交互(LineOne.POne.inFlow,LineTwo.PTwo.inFlow)等,同时冷却系统的层次信息保持不变.图7分析过程类似.
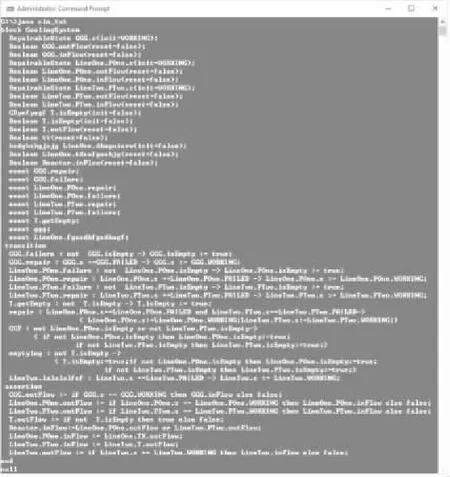
图6 平展化的冷却系统
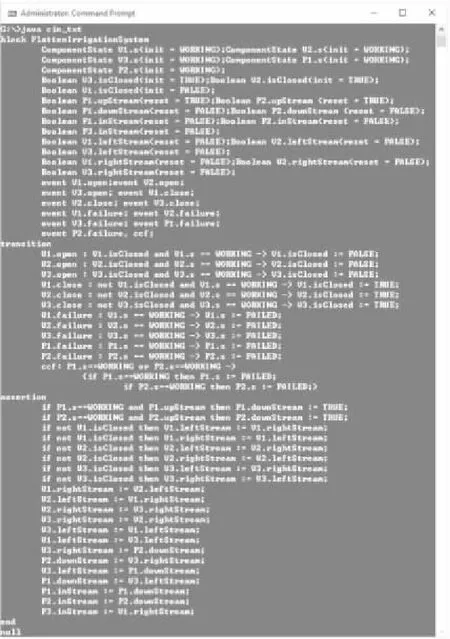
图7 平展化的灌溉系统
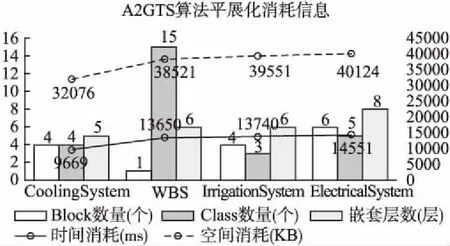
图8 A2GTS算法平展化消耗信息
1https://pan.baidu.com/s/1UB7dHeSS25pTZMqkGuF5yQ
由图6和图7分析可知,A2GTS可以完成复杂的多层次嵌套结构的AltaRica 3.0模型的平展化过程,对冷却系统进行平展化操作得到的结果和图3所示的实际平展化系统主要差别是在于平展文件的颗粒度不同,实际平展化的系统模型可以将具有相同属性的变量或者事件合并,而A2GTS算法得到的结果是将每个变量和事件单独说明,相比于原来的平展化系统,A2GTS得到的结果更加的详细.由表2和图8分析可知,算法的主要时间消耗和内存消耗在整个AltaRica 3.0系统的层次结构复杂度上,具体是Block的嵌套层数和Class的引用层数,层数越多,遍历深度就越深,A2GTS消耗的时间和内存也就越多.下一步可以针对复杂的多层的AltaRica 3.0模型系统通过初步的平展化操作减少层数.例如将第一层的组件信息直接剥离,剩下内部包含的系统组件信息,这样就减少一层嵌套信息,从而降低了空间复杂度,这也是本文下一步的工作内容.
6 结论和展望
本文主要工作包括:首先对整个AltaRica 3.0模型进行语法解析,根据AltaRica 3.0语法规则定义AltaRica 3.0的ANTLR元语言文件,通过ANTLR的内置方法对AltaRica 3.0的元语言进行解析,得到其语法解析器和词法解析器;其次,对输入的某个实际的AltaRica 3.0模型系统按照Block和Class进行分割,分别提出其中的Block和Class信息部分,将信息以字符流的形式输入到词法和语法解析器中,获取到字符流中的词法和语法信息,建立对应Block和Class的AST;然后根据设计的算法对这两个语法树进行操作,获取结点信息,利用已经制定的平展化的规则和算法,不断地递归获取平展化信息,得到最终的GTS平展化模型信息.
目前A2GTS算法的版本已经能够完成对一般AltaRica 3.0模型的分析和平展化,进一步的研究工作包括:第一,AltaRica 3.0的ANTLR元语言颗粒度细化定义,颗粒度问题要在实际的工程系统应用过程中,按照实际的语法规则识别需求进行颗粒度的细化,实现语法解析的精确定位;第二,增加对大规模层次系统的分析,提高算法通用性;第三,设计AltaRica 3.0模型到NuSMV模型的转换算法,应用模型检验技术来进行形式化分析;第四,A2GTS算法暂时还不能识别domain中的符号常量,是下一步算法改进的方向.第五,进行GTS模型的故障树自动生成的研究.
