多特征融合的中文短文本分类模型
2020-07-13杨朝强邵党国杨志豪
杨朝强,邵党国,杨志豪,相 艳,马 磊
(昆明理工大学 信息工程与自动化学院,昆明 650504)
1 引 言
随着互联网的高速发展,快速准确地进行文本分类成为研究的热点之一.目前的文本分类算法大多数主要针对长文本,即所处理的文本信息片段较长,包含一定量的信息内容.然而在实际情况中,如何快速准确地实现短文本处理成为文本分类的首要问题之一.短文本指长度不超过160个字符的文本体,以网络文本居多,包括:短新闻、评论、博客、聊天记录等,在信息查询[1],内容推荐[2]和关系抽取[3]等领域具有一定的研究价值.
现阶段而言,短文本分类的研究难点之一在于文本特征提取.文本特征提取方法一般分为三种,传统的文本数据化表示,机器学习和模型融合方法,具体介绍如下:
传统的特征提取为基于空间向量模型(Vecto-r Space Model,VSM)[4],该模型将文本看作不同词的组合形式,未考虑词与词之间的相关性,且该方法存在数据高维稀疏性问题.针对VSM中存在的缺陷,一些研究者通过引入外部先验知识,来对短文本进行语义扩展[5,6],但该方法对引入知识的质量要求较高,同时极大地增加了模型的复杂度.也有学者通过分析文本自身的语义结构[7],来构建文本表示方法,如 LSA,pLSI 和 LDA[8-10],但由于模型构建中只考虑到了文本层面信息,缺乏对低层面信息的分析.
自Google2013年推出具有语义表示功能的Word2vec[11]词向量模型后,神经网络在分类任务中取得了飞速的发展Yoon Kim等人[12]提出的基于CNN(Convolutional Neural Network)的文本分类模型,实验结果显示该模型的分类效果优于传统模型.在CNN的基础上,Nal Kalchbrenner等人[13]提出了DCNN(Dynamic Convolutional Neural Network)文本分类模型,该模型用动态的K-max Pooling层代替了传统CNN中的Max Pooling层,有效提取了文本的部分结构信息.但是上述模型都存在长短距离依赖问题,为解决该问题提出了基于RNN(Recurrent Neural Network)[14]改进的LSTM(Long Short-Term Memory)[15]文本分类模型.Bansal等人提出了GRU(Gated recurrent unit)[16]模型,GRU模型将LSTM模型中的遗忘门和输入门用更新门来替代,有效减少了模型训练参数,提高了模型训练速度.为解决LSTM模型在进行文本分类时,状态只能由前向后单向传输的问题,Grave等人提出了Bi-LSTM(Bi-directional Long Short-Term Memory)[17]模型,该模型不仅考虑前面状态对当前状态的影响,同时考虑后面状态对当前状态的影响,能够更加全面有效的提取文本信息.
针对单一模型在文本特征提取中的局限性,Chunting Zhou等人[18]提出的C-LSTM(Contextual LSTM)特征融合模型,充分结合了CNN和LSTM模型的优势,将CNN训练得到的结果作为LSTM的输入,有效避免了单一模型文本分类的局限性.Siwei Lai等人[19]提出的RCNN(Recurrent and Convolutional Neural Networks)模型使用RNN作为CNN的卷积层,有助于CNN模型提取全局信息,但上述的特征融合模型可能存在特征冗余的问题.
上述的三种特征提取方法在解决短文本分类的问题上存在一定的局限性.首先,短文本中含有特征词较少,单一模型难以做到对文本信息的充分提取.另外,短文本的不规范性导致现有的分词工具难以保证分词结果的准确性,从而导致词向量的文本表示方法不够准确.针对上述问题,本文提出了Multi-feature fusion model(MFFM)中文短文本分类模型,该模型包含以下三个方面:
1)分别使用词向量和字向量从两个不同粒度对短文本进行表示,并通过Self-attention[20]模型对字向量进行有效融合,解决中文短文本中存在的特征稀疏和不规范特性等问题.
2)使用BILSTM、CNN和CAPSNET三个不同的模型对文本进行不同层面的特征提取,解决文本分类模型在特征提取中的局限性.
3)引入Self-attention模型动态调节各模型特征在最终特征构建中的权重系数解决模型融合方法中可能存在的特征冗余问题.
2 神经网络通路
2.1 BILSTM通路
BILSTM是由前向后和由后向前分别训练一个LSTM,然后将两个LSTM的结果拼接作为模型的输出.该模型能够同时保留“过去”和“未来”的文本信息,有效避免了LSTM模型在提取文本特征的过程中,只保留“过去”信息的弊端.BILSTM在进行文本处理时,原理如下:假设在t时刻输入向量为xt,前一时刻的输出为ht-1,前一时刻的隐藏状态为ct-1,则当前时刻的状态ct和输出ht如公式(1)、公式(2)所示.
ct=ft×ct-1+it×g(wcX+bc)
(1)
ht=ot×s(ct)
(2)
其中,当前时刻的输入X由输入向量xt与前一时刻的输出ht-1组成如公式(3)所示,w为权重,b为偏置,g、s分别表示输出和输出的激活函数,it、ft、ot分别表示输入门i、遗忘门f、输出门o在t时刻的激活值,如公式(4)、公式(5)、公式(6)所示.σ表示三个门的激活函数.
(3)
it=σ(wiX+bi)
(4)
ft=σ(wfX+bf)
(5)
ot=σ(woX+bo)
(6)
2.2 CNN通路
Yoon Kim 将CNN应用到文本分类领域,CNN主要包括卷积和池化两大部分.卷积的设计参考了局部感受野的思想,即当前层的节点只与前一层网络的有限个节点相连接,而不是与所有的输入节点进行连接.此外,卷积操作中将同一层中某些神经元之间的连接权重设置为共享参数,有效减少需要训练的权值参数.卷积层通过使用多个n×h卷积核对输入信息进行卷积操作,通过多个卷积核能够提取到文本不同层次的特征信息.最终,将提取到的多层次信息进行拼接融合,作为卷积层的最终输出,计算结果如公式(7)所示.
mi=f(w×Xi:i+h-1+b)
(7)
其中,mi表示第i个卷积核提取的文本特征,f表示激活函数,w表示卷积核的权重参数,在大小为h的窗口内,与输入特征X进行卷积获得新的文本表述,Xi表示X的第i个特征,b为偏置参数.
将上述的所有特征连接起来就得到了卷积层的输出特征M,如公式(8)所示.
M=[m1,m2,...,ml-h+1]
(8)
池化类似于对高维特征进行降维,常用的池化方式主要有:Mean-pooling,Max-pooling和Stochastic-pooling.本文中使用Max-pooling提取M中最显著的特征代替M中的所有特征,计算如公式(9)所示.
mj=max[m1,m2,...,ml-h+1]
(9)
将上述池化结果拼接起来构成池化层的输出,最终通过激活函数对提取到的特征进行分类.
2.3 Capsule Network通路
Hinton 等人[21]提出的胶囊网络(Capsule Network,CAPSNET),用向量来代替传统网络中的单个节点,以 Dynamic Routing 思路来更新网络参数,其中用新的网络向量输出代替传统的标量输出,用动态路由原则代替传统的池化操作,并在实验中证明迭代次数设置为3时性能较好.具体算法流程如表1所示.
在这里,bij是一个未经归一化的临时累积变量,初始值为0,bij的个数是由上一层和下一层的CAPSNET的个数决定的.
2.4 self-attention
自注意力机制(Self-attention)是注意力机制的一种,与其他的注意力机制相比,该机制不需要考虑下一层级的信息,能够以并行的方式快速实现同一层级内部信息之间相关性分析.具体计算公式如公式(10)~公式(12)所示.
(10)

(11)
(12)
表1 Dynamic Routing算法
Table 1 Dynamic Routing algorithm

Procedure1Routingalgorithm1.procedureROUTING(^uj|i,r,l)2. forallCapsuleIinlayerlandCapsulejinlayer(l+1):bij←03. forriterationsdo4. forallCapsuleiinlayerl:ci←softmax(bi)5. forallCapsulejinlayer(l+1):sj←∑icij^uj|i6. forallCapsulejinlayer(l+1):vj←squash(sj)7. forallCapsuleiinlayerlandCapsulejinlayer(l+1):bij←bij+uj|i^×vj Returnvj
在公式(10)~公式(12)中αi,j表示的是位置i处元素和位置j处元素之间的注意力权重系数,通过softmax函数对权重系数进行归一化操作,使得∑jai,j=1,score(xi,xj)是用来计算序列中任意两个元素之间的相关性,该过程通过MLP实现.
3 MFFM构建
3.1 文本预处理
对中文短文本分类,需要对短文本信息进行预处理,处理过程如下:
1)中文分词.本文使用结巴分词工具对文本进行分词操作,在分词的过程中,对文本中出现的标点和停用词进行过滤.
2)建立词向量字典.对数据集中出现的词语进行统计编码,建立相应的字典,然后将词语转换其对应的编码,初步实现文本数字化表示.
3)词向量训练.本文Word2Vec模型进行词向量训练,该模型训练的词向量具有一定的语义表示功能,同时有效的降低了向量的空间维度.
4)统一样本长度.由于数据集中每个样本的长度不一,在模型输入时需要统一样本长度,具体做法为:对于长度不足的用0补齐,对于超过规定长度的截断.
5)文本向量化.根据2)转换后的编码在3)中找出其对应的词向量,将4)中全部数字转换为对应的词向量,作为模型的输入.
3.2 MFFM融合建模
MFFM融合建模结构如图1所示.从图中可以看出MFFM模型包含三个阶段:1)分别采用基于字向量和词向量的文本表示方法,通过Self-attention模型对字词向量进行有效融合,对文本的原始信息进行充分表示;2)分别用BILSTM、CNN和CAPSNET模型对文本进行不同层面的特征提取,并将不同模型提取的特征送入Self-attention模型动态调节各模型特征在最终特征构建中的权重系数.3)将提取的文本特征送入分类器进行类别划分.
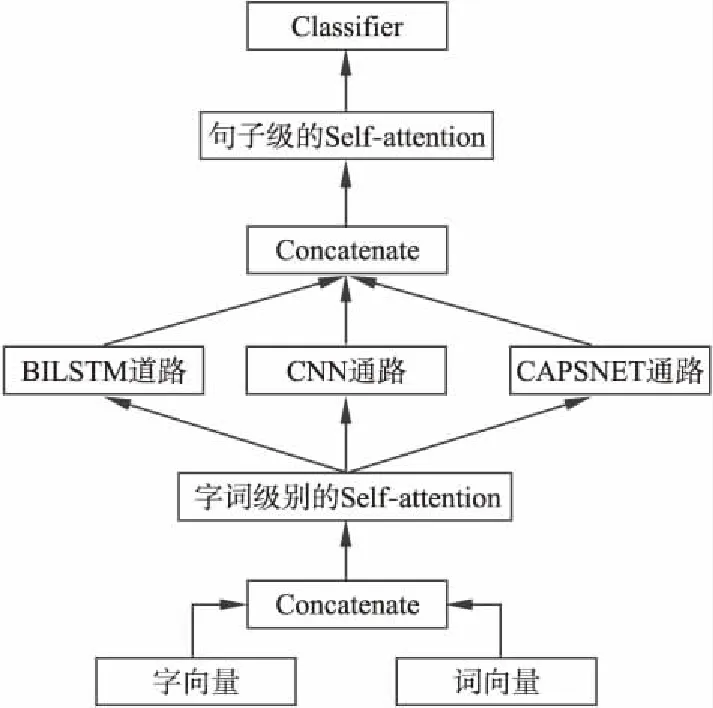
图1 MFFM融合建模过程图
3.2.1 字词向量融合的文本表示
在文本表示层面分别使用了基于字向量和词向量的两种不同表示方法.引入字向量的原因主要有以下两点:1)在中文中单个字是有其特定意义的,单个汉字也蕴含着丰富的语义信息;2)基于字向量的文本表示具有以下优点:能够在一定程度上解决短文本中特征词过少的问题;有效避免对文本中出现的不规则特征词的错误划分;字向量的文本表示方式可以有效避免词向量训练过程中词库数量过大的问题.字和词对文本而言是两个不同的粒度,词是一个较大粒度而字是一个更加精细的粒度,从不同粒度分析同一文本,能够提取到不同层面的文本信息.最终,将字向量和词向量对原始文本的表示送入 Self-attention模型进行融合,字词向量的融合能够有效结合字向量和词向量的各自优势,在一定程度上解决了短文本中存在的特征稀疏性和不规则特征词的错误划分问题.
3.2.2 多模型融合的特征提取模型
多模型融合通过将多个短文本分类器进行结合,获得比单一的分类器显著优越的泛化性能.现有的BILSTM模型对于不同位置的信息提取特征的过程中,相对而言更偏重于文本后面信息,可能忽略文本重要信息.CNN模型在进行卷积操作时,受卷积核大小的限制,只考虑到了卷积核范围内的特征间的相互影响,提取到的特征缺失了部分全局信息.CAPSNET用动态路由取代传统的池化层能保证位置信息的保留性,且针对特定问题调整相应的参数,使得模型参数的调整更加快速合理.因此本文使用BILSTM、CNN和CAPSNET模型对文本进行不同层面的特征提取,以便获取全面有效的文本特征,原因如下:
1)BILSTM在对文本进行特征提取时,充分考虑到了文本前后文信息之间的相互影响,通过分析文本中所有词之间的相关性,并根据特征的重要性构建最终的特征提取模型.
2)CNN模型在对文本进行特征提取时,在进行卷积操作时卷积核的长度是固定不变,始终与输入文本的词向量维度一致,宽度可以根据自身的需要进行设置.
3)胶囊网络(Capsule Network)在对文本进行特征提取时,用神经元矢量替换传统神经网络中的单个神经元节点,用动态路由取代传统的池化层.相比CNN网络,由于它不再使用最大池,所以位置信息得以保留.并且动态路由可以在一定程度上形成推理机制,并针对特定问题调整相应的参数,使得模型参数的调整更加快速合理.
在对三个模型提取到的特征进行融合时,本文引入了Self-attention模型.通过该模型对BILSTM、CNN和CAPSNET三个模型提取的特征动态分配权重,将各模型特征与对应的权重相乘构建最终的文本特征.相比传统的特征融合方法,Self-attention模型将各模型提取的特征作为一个整体进行权重划分,避免将各模型特征拼接后对每一维特征进行权重分配时,可能存在的特征冗余问题.
4 实验和结果
4.1 实验数据集和评价指标
本文使用中文冶金短文本数据集、淘宝评论数据集和谭松波酒店评论数据集来验证MFFM模型的性能.三个数据集均为二分类数据集,其中中文冶金短文本数据集包括:冶金新闻和非冶金新闻两大部分;淘宝评论数据集包括:买家对购买商品的正面评论和负面评论两大部分;谭松波酒店评论数据集包括:住宿者对酒店服务的正面评论和负面评论两大部分,对比数据集的基本属性如表2所示.
表2 数据集特征
Table 2 Datasets feature

数据集正向样本负向样本样本长度(char)样本长度(word)字典大小词典大小中文冶金短文本数据集17388156283618407944327淘宝评论数据集106791042810050465347858谭松波酒店评论数据集6000300015075347027005
本文分别使用Precision、Accuracy、Recall值及F1评价指标对MFFM模型的性能进行评价.其中,令A,B,C和D分别代表正阳性、假阴性、假阳性和正阴性的分类数量,则四个评价指标具体的计算公式如公式(13)~公式(16)所示.
(13)
(14)
(15)
(16)
4.2 实验模型搭建及参数设置
本文中实验操作环境为Intel核心i5-7500 CPU,8 GB RAM,所有的实验都是基于Keras架构搭建,使用Python3.6的运行环境.本文参数设置如表3所示.
表3 模型的参数设置
Table 3 Model parameter settings
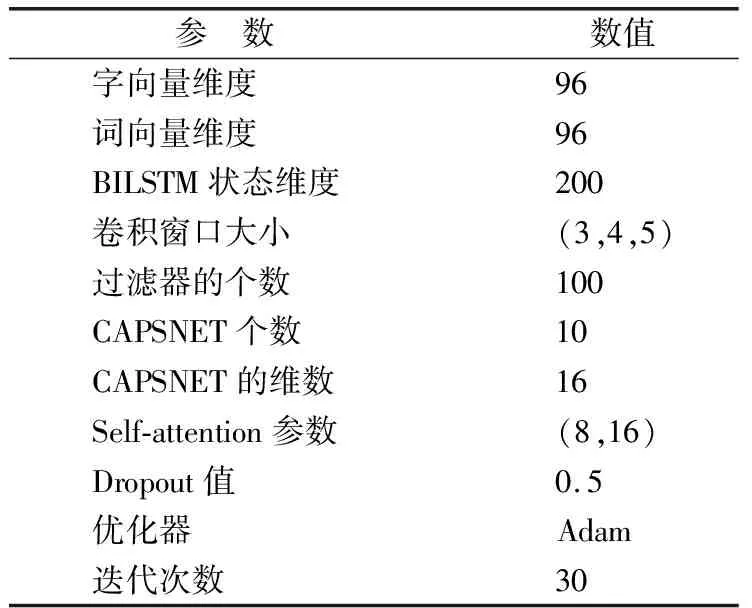
参 数 数值字向量维度96词向量维度96BILSTM状态维度200卷积窗口大小(3,4,5)过滤器的个数100CAPSNET个数10CAPSNET的维数16Self-attention参数(8,16)Dropout值0.5优化器Adam迭代次数30
实验中各模型参数的选择依据来源于两方面:
1)参考已有的经典模型,CNN模型的参数设置参考了Yoon Kim等人[12]的工作,使用窗口大小分别为3、4、5卷积核各100个;CAPSNET模型的参数主要了参考Hinton等人[21]的工作,胶囊的个数和胶囊的维数分别为10和16;Self-attention模型的参数主要参考了Ashish Vaswani等人[20]的工作.
2)在谭松波酒店评论数据集上,通过多组对比实验来确定BILSTM模型中隐藏层神经元的节点个数和词向量维度,具体结果如表4和表5所示.根据表4可以看出在隐藏层神经元节点个数为100时,模型性能最佳,因此在BILSTM模型中将隐藏层神经元设置为100.根据表5可以看出在词向量维度分别为:64、96、128和160时,本文提出的模型相比基准模型中的最优模型F1值分别提升:0.75%、1%、0.9%和1.6%.从而,在一定程度上证明了MFFM模型的有效性和稳定性.同时词向量维度为96时,模型性能最佳,因此实验中将词向量维度设置为96.
表4 BILSTM模型不同节点的实验结果
Table 4 Experimental results of different nodes of the BILSTM model

BILSTM隐藏层神经节点数F1RecallPrecisionAccuracy500.91420.91380.91470.91431000.91710.91710.91710.91711500.91570.91640.91500.91602000.91510.91550.91470.91502500.91400.91430.91380.9136
4.3 实验结果及分析
为验证MFFM的性能,本文与短文本分类中的四个经典模型CNN、BILSTM、CAPSNET和CNN-BILSTM作为基准模型进行对比实验,实验结果如表6所示,模型的F1值如图2所示.通过对表6和图2的分析,可以看出MFFM在三个中文短文本数据集上的分类性能均优于四个基准模型.其中,在谭松波酒店评论数据集上MFFM相比基准模型中的最优模型BILSTM-CNN的F1值提升了1%;在淘宝评论数据集上,相比BILSTM-CNN模型F1值提升0.93%;在中文冶金短文本数据集上,相比BILSTM-CNN模型F1值提升0.94%.为了进一步证明本文提出模型的有效性,本文在实验部分对中文短文本数据集、谭松波酒店评论数据集和淘宝评论数据集三个数据集的正负样本进行合并构建新的数据集,合并后的数据集含有不同领域之间的正负样本,相比单个数据集具有更好的兼容性,通过表6可以看出,本文提出的模型在融合后的数据上,相比基准模型中的最优模型BILSTM-CNN的F1提升了1.55%,通过在单一领域数据集和多领域数据上的实验结果可以看出本文提出的模型相比基准模型均有一定程度的提高,从而有效的证明了本文提出模型MFFM的有效性.
表5 不同词向量维度的实验结果
Table 5 Experimental results of different word vector dimensions

字、词向量维度评价指标BILSTMCNNCAPSNETBILSTM+CNNMFFM(本文)F10.91710.90840.91470.92600.933564Recall0.91710.90900.91660.92470.9337Precision0.91710.90710.91270.92730.9332Accuracy0.91710.90830.91450.92610.9334F10.91850.90440.91660.92700.937096Recall0.91800.90530.91620.92700.9384Precision0.91890.90360.91700.92700.9358Accuracy0.91850.90430.91660.92700.9370F10.91260.90610.92230.91950.9313128Recall0.91240.90670.92280.91660.9313Precision0.91280.90540.92190.92240.9313Accuracy0.91260.90600.92230.91970.9313F10.91420.90550.91990.91960.9356160Recall0.91570.90530.91900.92180.9356Precision0.91270.90570.92080.91750.9358Accuracy0.91400.90550.91990.91950.9356
表6 三个数据集上的实验结果
Table 6 Experimental results on three datasets

数据集评价指标BILSTMCNNCAPSNETBILSTM+CNNMFFM(本文)F10.91850.90440.91660.92700.9370谭松波酒店评论数据集Recall0.91800.90530.91620.92700.9384Precision0.91890.90360.91700.92700.9358Accuracy0.91850.90430.91660.92700.9370F10.90000.89940.90440.90500.9143淘宝评论数据集Recall0.90000.89990.90300.90000.9162Precision0.90000.89900.90580.91020.9125Accuracy0.90000.89950.90450.90560.9141F10.95640.95520.95700.95820.9676中文冶金短文本数据集Recall0.95670.95550.95670.95250.9679Precision0.95610.95490.95730.96420.9673Accuracy0.95640.95520.95700.95850.9676F10.93880.93090.93760.93950.9550合并数据集Recall0.93880.93100.93750.93910.9552Precision0.93880.93080.93770.94000.9547Accuracy0.93880.93090.93760.93960.9549
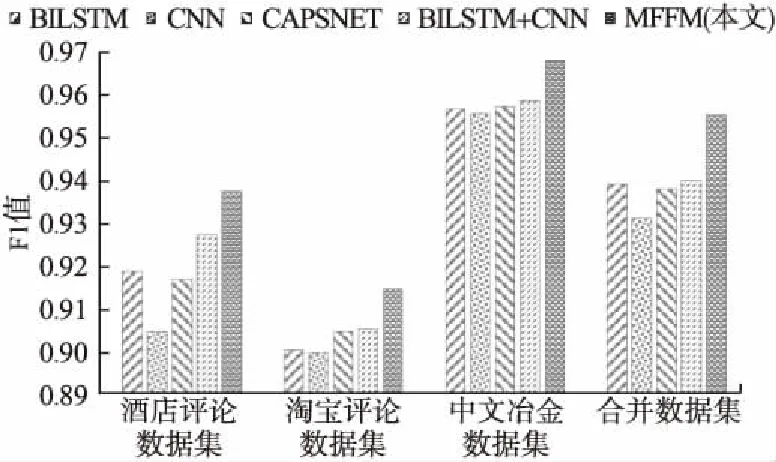
图2 模型在不同数据集上的F1值对比图
5 结 论
短文本分类的研究难点之一在于文本特征提取.文本特征提取方法一般分为三种,传统的文本数据化表示,机器学习和模型融合方法,但是这些方法都存在局限性.为解决这些问题,本文提出了MFFM模型,旨在提取更有效的文本特征,提高模型的分类性能.
首先分别基于词向量和字向量从不同粒度对短文本进行表示,并通过Self-attention模型实现字词向量的融合,融合后的文本表示方式能够在一定程度上,解决短文本中存在的特征稀疏性和不规范性问题.然后用BILSTM、CNN和CAPSNET三种模型从不同层面提取文本中蕴含的信息.最终,将三个模型提取到的特征送入Self-attention模型,通过自注意力机制动态分配各模型特征在最终特征构建中的权重系数.
在实验中,可以看出MFFM模型的性能在三个数据集下优于对比的四个算法(CNN、BILSTM、CAPSNET和CNN-BILSTM),并利用数据融合来进一步验证了MFFM模型的有效性.不可否认,本文现在的工作仅仅是这个主题的开端,在未来,更低复杂度、更优的融合模型会出现,例如,进化式压缩MFMM模型.
